
基于节点相似度与影响力的CCN社区划分方案
2023-03-08 10:57张建伟崔梦梦蔡增玉
软件导刊 2023年2期
张建伟,崔梦梦,蔡增玉
(1.郑州轻工业大学 软件学院;2.郑州轻工业大学 计算机与通信工程学院,河南 郑州 450002)
0 引言
传统基于TCP/IP 的网络架构不能很好地满足日益增加的网络流量需求[1-4],用户在请求内容时,往往不知道内容提供者,从而造成无法将目的地址嵌入到兴趣包中进行转发的问题。以内容为中心的网络(Content Centric Network,CCN)从提供商驱动的端到端通信模式转换到了兴趣驱动的内容检索通信模式,这使得CCN 不能像TCP/IP那样根据源、目的IP 地址采用逐跳返回的方法进行路由,因此,怎样设计更高效的CCN 路由方案是CCN 网络架构亟需解决的一个问题。近年来,CCN 路由机制得到了广泛的研究[5-7],为解决CCN 的可扩展性和大规模部署问题,有两个较为有效的方案:一是与SDN 的结合[8-10],因为SDN作为未来互联网的一种独特的模型,实现了控制平面与数据平面相分离;另一个方案是进行社区划分[11-14],但在进行社区划分时社区的大小和内容很难确定,给社区划分带来了新的挑战。
现有若干社区发现算法,如Girvan 等[15]的基于边介数的分裂GN 算法,每次删除边介数最大的边,直到所有的边都被移除;Blondel 等[16]提出模块度最大化的louvain 算法,将每个点看作独立社区,计算社区折叠后社区间和社区内的连边权重,直到最后合为一个社区;Raghavan 等[17]提出标签传播算法(LPA),相比前两种算法,该算法具有线性的时间复杂度,适合用于大型网络中的社区划分。
LPA 算法的核心思想为:给途中每个节点分配标签值,以代表节点所在的社区。找出邻居节点中标签传播值最大的节点(最大值不唯一时,随机选择一个),将该节点加入该社区,并更新节点的标签传播值,当节点标签传播值不再变化时,停止迭代;否则重复上述步骤。
在传统LPA 算法中,初始标签值的确定具有随机性,这使划分好的社区存在稳定性差和准确性低的缺点,为解决该问题,很多学者提出了改进措施。Luo 等[18]通过优化目标函数来提升社区划分的质量,但LPA 的稳定性较差;张猛等[19]通过计算标签重要性,改变标签更新序列,但未考虑节点之间的相似性;Song 等[20]通过计算节点相似性,改变标签更新序列,但未考虑节点的重要性。
目前,LPA 算法在社区划分实际应用中仍存在不足之处,为进一步提高社区划分的稳定性和准确性,本文提出一种基于节点兴趣相似度和社交影响力的CCN 社区划分方法(SI-LPA),综合考虑节点相似性和重要性对于社区的影响,并引入特征向量中心性优化初始社区结构,使其划分的社区更具有代表性与稳定性。
1 SI-LPA算法
1.1 兴趣相似度
兴趣权重表示节点对一个兴趣字段的历史请求次数,用Wik表示节点vi对兴趣字段fk的兴趣权重,当vi生成一个包含fk的请求时:
节点的兴趣相似度为两个节点的兴趣集合中相同兴趣字段的兴趣权重集合对应的Tanimoto系数相关性。假设节点vi与vj相同的兴趣字段个数为p,则节点vi与vj的兴趣相似度为:
1.2 节点社交影响力
节点之间的社交距离与通过这两点时间的数据流量成正比,与两节点间距离成反比,且与节点的度有关。
其中,dij为流经节点vi与vj数据流量的总和,Γ(i)与Γ(j)分别为节点vi与vj邻居节点的集合,ki与kj分别为节点vi与vj的度,dis(i,j)为节点vi与vj之间的欧氏距离。
1.3 特征向量中心性
用A=(eij)n×n表示无向图对应的邻接矩阵,X=(x1,x2,…,xn)表示该矩阵的一个特征向量。对于任意路由节点vi,其对应的特征向量值为xi,λ为邻接矩阵A的特征向量X对应的特征值,则:
利用上述公式,当对特征向量值进行多次迭代,其值达到稳态时,此时的xi为节点vi对应的特征向量中心性。为方便计算,在区间(0,1)内对特征向量中心性进行标准化,用表示标准化后特征向量中心性的值,则:
1.4 标签传播值
对n个特征向量中心性的值降序排列,选择其中前k个值对应的节点作为初始社区,用C1,C2,…,Ck表示,对k个社区以并行方式基于层次便利的方法发展其它节点作为其社区成员。其中标签传播值的更新规则如下:
其中,Ni为节点vi的邻居节点的集合,laj为邻居节点vj的标签活性值,kj为邻居节点vj的度,wij为节点vi与节点vj之间兴趣相似度和社交影响力的拟合,α为相应的常数系数,反映节点兴趣相似度和社交影响力所占的权重。
2 社区划分方案
社区Cx不能无限制地发展其社区成员,因此在进行社区决策时需要一些限制条件,以此来确定划分的社区个数以及每个社区中包含的节点个数。
关于划分社区个数的问题,初始化k个社区,在社区划分层次遍历过程中,若两个社区中新遍历的待加入节点vi与vj直接相连,则将这两个社区合并为一个社区;若存在η个相似的情况,则最终划分好的社区个数为k-η=p。
关于社区中包含节点个数的问题,首先给定一个社区中成员个数的上限lim,在层次遍历过程中,若一个社区中节点个数超过该上限值,则不再加入新的节点,终止对该社区的成员开发。也就是说,在社区成员开发的过程中,一个节点会被不同的社区竞争,而这个节点的最终归属权根据该节点在不同社区的标签传播值来确定,因为在层次遍历过程中,同一节点会因对应社区的不同拥有不用的标签传播值。假设节点vi对于分别从Cx和Cy遍历的两个社区,若从社区Cx遍历节点的标签传播值大于从Cy遍历的标签传播值,且社区Cx的成员个数未达到上限值,则节点vi从属于社区Cx,继续社区Cx的成员发展;若社区Cy的成员数未达上限,节点vi从属于社区Cy。
基于特征向量中心性和改进标签传播算法划分的网络社区是非重叠的,且最终划分好的社区个数已知。根据描述,社区划分的伪码算法如算法1 所示。算法1 的时间复杂度取决于计算特征向量中心性值、特征向量中心性值排序、层次遍历、计算标签传播值和社区合并。其中,特征向量中心性值排序只需要找到前k个最大值,相当于Top k问题,算法时间复杂度为O(nlogk),其余部分的时间复杂度均为O(n)。由于这5 个部分是串行工作的,因此算法1的时间复杂度为O(n)。
算法1社区划分算法

3 社区管理
对于每一个划分好的社区Cx,要在社区中选择一个竞争力最大的节点vi,在该节点上部署一个控制器Sx,以方便管理本社区中的信息和拓扑结构以及与其他社区之间的交互。
3.1 控制器部署
控制器的部署基于社区中节点的竞争力确定,通过对节点的数据转发能力和通信代价等方面进行研究,将SDN控制器分配到竞争力最大的社区节点。对于社区Cx,用Cpxi表示社区节点vi的竞争力,可以得到:
其中,Dfxi为节点vi数据转发能力,Coxi为控制器Sx部署在社区Cx的节点vi上的通信代价,φ为调节系数。节点的竞争力与数据转发能力成正比,与通信代价成反比。
节点的数据转发能力与其标签传播值和网络带宽有关,用表示标准化后的标签传播值,用Bwi'表示标准化的网络带宽。则:
节点数据转发能力可以表示为:
其中,β为标签传播值和网络带宽所占的权重。
通信代价可用路由器的传输时延和能量耗损表示,传输时延与通过节点路由器vi的请求次数Nui和路由器固定的时延消耗Csi有关;能量消耗与流经路由器vi的数据流量Tfi与处理每比特数据的能量消耗Eci有关。则:
对通信代价进行标准化,将值分布在区间(0,1)之间,则可以将Coix'标准化后的通信代价:
控制器部署节点Vi选择的伪码算法如算法2 所示。算法2 的时间复杂度取决于计算数据转发能力、通信代价和节点竞争力,每个部分计算的时间复杂度均为O(n),且每一部分并行工作,因此算法2总的时间复杂度为O(n)。
算法2控制器部署节点选择

3.2 控制器信息管理
为使控制器有效地管理社区内容,提升内容检索速度,为每个控制器设计信息索引表(SIT),记录社区内的内容所在节点的映射并为社区内路由提供支持;设计社区拓扑结构表(SCT),帮助维护社区拓扑信息并进行社区间路由。
信息索引表由三个字段组成:内容名称前缀(PRE)、内容名(CNA)、内容持有者(CHL)。其主要作用是在控制器上建立社区中各节点上内容的映射,以使控制器能清晰地掌握社区成员的内容持有情况,以方便准确转发内容给请求者。在一个社区中一个节点可以存储多个不同的内容(但对同一个内容不会存储多次),同一个内容也可能被多个不同的节点持有。
拓扑结构表由相邻社区(ACS)、内容名称前缀(PRE)、内容传输次数(NCT)三个字段组成。其中,相邻社区指与当前社区相邻的社区;内容名称前缀指在两个社区间传输的内容的前缀标签;内容传输次数指两个社区之间总共传输数据的次数。主要功能是记录社区之间不同类型内容传输的总次数,为后续的兴趣包在社区间的路由查询提供支撑。
4 实验及性能评价
实验使用的对比算法包括LPA-h、S-LPA 和HPILPA,实验结果采用100 次不同运行结果之后的平均值,在Intel(R)Core(TM)i7-9700CPU@3.00GHzCPU、32GBRAM的Windows 系统上进行。实验数据选取karate、dolphins、polbooks和football等4个真实网络数据集及仿真网络。
4.1 真实网络实验
采用模块度标准差(Qsd)作为社区划分稳定性的评价指标,标准差越接近于0,则划分社区结构越稳定。其中t表示算法运行次数,Qi表示第i次运行得到的模块度的值。
从表1 可见,在模块度标准差上,SI-LPA 算法的Qsd值均为0,说明本文提出的SI-LPA 算法具有较强的稳定性。
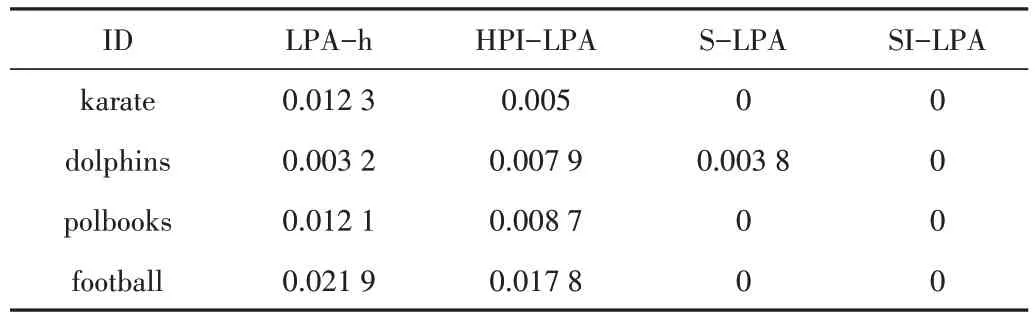
Table 1 Comparison of network stability表1 网络稳定性比较
4.2 仿真网络实验
采用ndnSIM 进行数据仿真与性能分析,使用由100 个点、474 条边构成的人工合成网络拓扑结构,其中98 个为路由器节点,2 个为服务器节点。初始状态下,所有的数据内容仅存储在服务器节点上,路由器节点不存储内容。实验采用的社区划分对比算法为LPAh、HPI-LPL、S-LPA 等,统一采用蚁群算法进行CCN 数据路由。对每个划分算法进行100 次实验,在不同的兴趣请求次数下计算各社区划分算法的平均路由跳数以及缓存命中率。
4.2.1 仿真环境与参数设置
本文涉及到的所有参数及其值如表2 所示。通过在不同参数设置下进行模拟实验,确定一个具体的数值,使得整个路由决策能够达到最优性能。在所有参数中,社区内成员个数上限lim是绝对关键的,将直接影响到路由的性能。

Table 2 Parameter value setting表2 参数值设置
为评价社区划分结果的好坏,引入模块度Q 的概念来衡量社区划分的质量,其值越接近1,社区的划分质量越好,但通常很难达到1。对于不同的lim值,对应的模块度值变化如图1 所示。观察到图1 出现了一个峰值,当lim=20 时,模块度最接近于1。此外,在达到峰值之前,模块度值的变化迅速增加,峰值之后模块度降低逐渐变缓。这说明,强模块度的建立过程是快速的,而破坏相对缓慢。
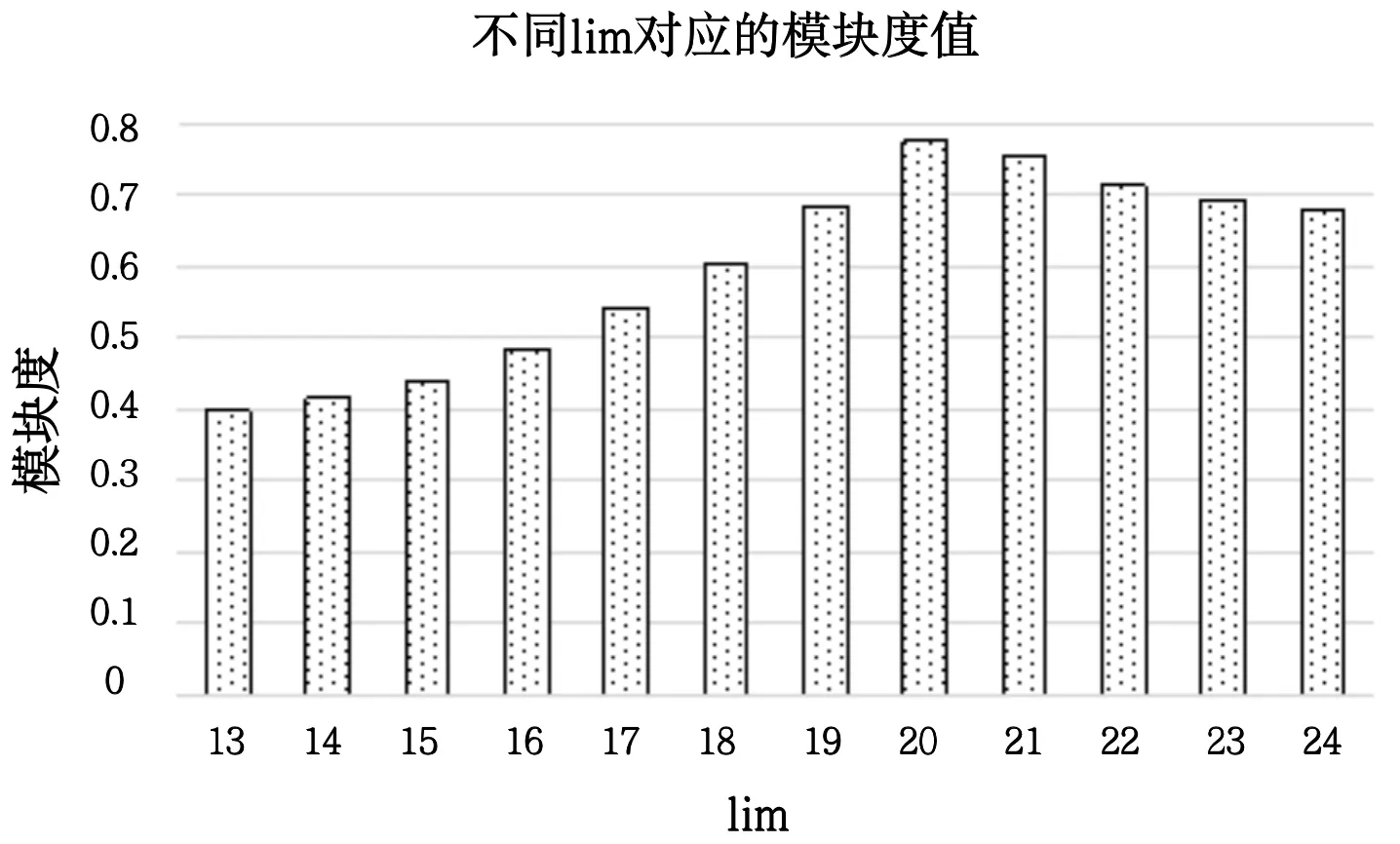
Fig.1 Modularity values corresponding to different lim values图1 不同lim值对应的模块度值
4.2.2 平均路由数
在不同的兴趣请求次数下,观察平均路由跳数,结果如图2 所示。由图2 可知,①随着兴趣请求次数增加,SILPA 算法的平均路由跳数明显低于S-LPA、LPAh 与HPI_LPA。这是因为SI-LPA 引入了SDN 控制器对社区进行管理,随着请求次数的增加,同一个内容再次请求的概率增加,此时便直接根据控制器在社区内获取相应内容,减少路由的跳数。且SI-LPA 综合使用节点的兴趣相似度和社交影响力,所以每次划分的社区结构趋于稳定;②SILPA、S-LPA 和HPI-LPA 的路由跳数最终趋于稳定,但是LPAh 的路由条数一直处于波动状态。这是因为LPAh 利用目标函数优化社区划分质量,但未解决稳定性差的问题。
4.2.3 平均缓存命中率
对社区内的不同节点请求相同的内容,观察不同的兴趣请求次数,得到社区内的缓存命中率如图3 所示。由图3 可知,随着请求次数增加,各个划分策略的缓存命中率上升,且SI-LPA 具有最高的缓存命中率。这是因为SDN 控制器的管理功能为SI-LPA 策略的社区内内容的缓存提供了较好支撑,使社区内请求内容具有较高优先级,从而增加了缓存命中率。
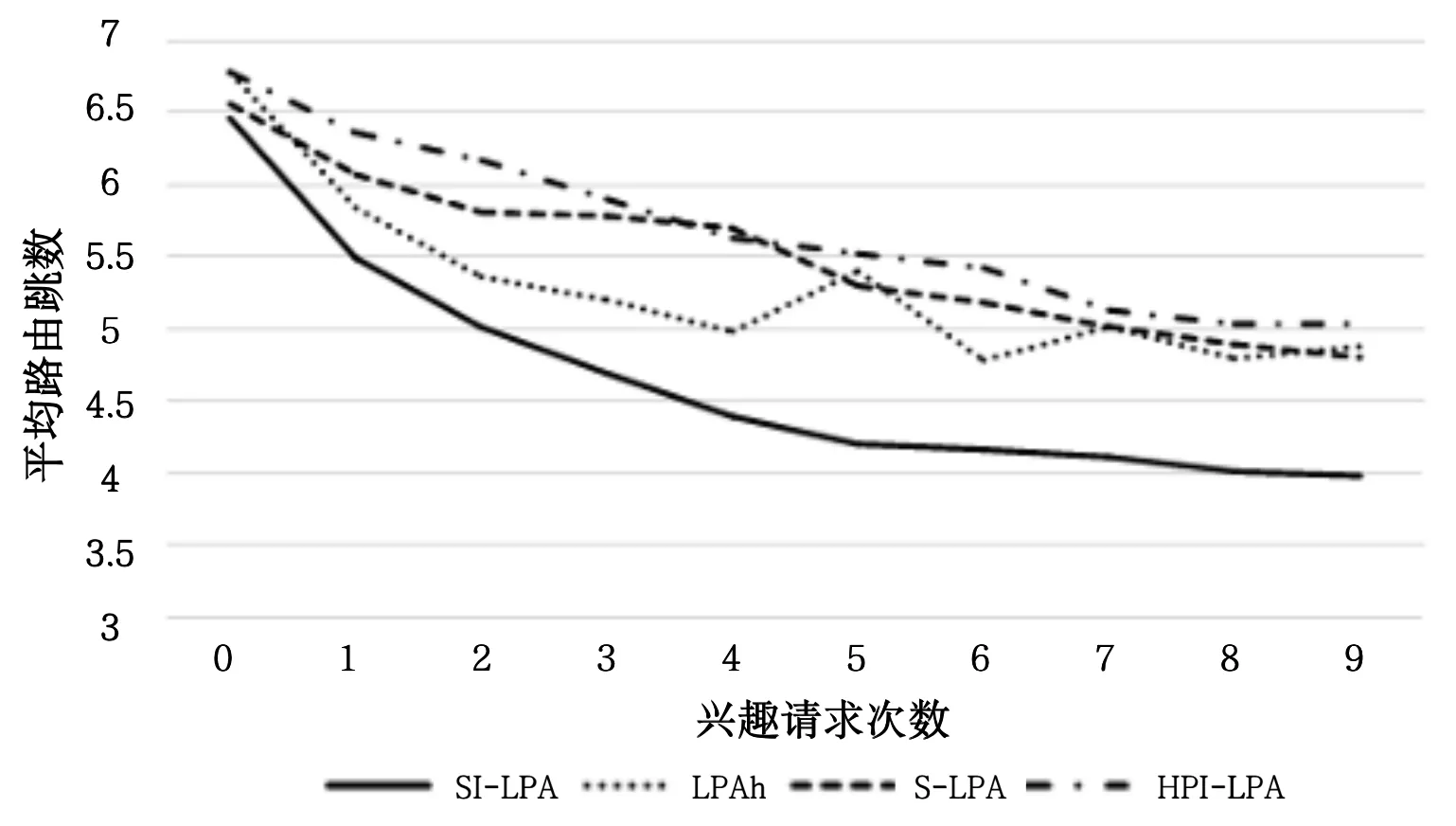
Fig.2 Average routing hops under different interest requests图2 不同兴趣请求下的平均路由跳数
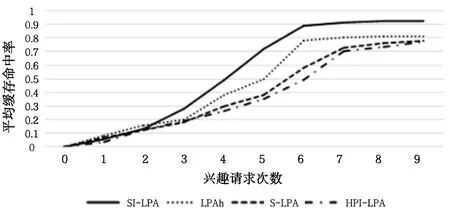
Fig.3 Average cache hit rate under different interest requests图3 不同兴趣请求下的平均缓存命中率
5 结语
本文通过引入SDN 控制器和社区划分对CCN 路由进行研究。结合特征向量中心性和标签传播两种主流方法进行社区划分,并通过部署控制器,进行网络信息维护和拓扑管理,对提出的方案进行了稳定性验证与仿真。实验结果表明,利用该方案能够获得较好的社区划分结果,在此基础上的路由策略能够降低路由条数并提升缓存命中率。然而,随着网络流量的剧增,CCN 中采用的路由策略会造成PIT 表的爆炸式增长,从而导致大量的路由冗余,路由策略的优化成为CCN 研究的重点。在今后的研究工作中,希望能够在此基础上进一步提升CCN 的性能。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
网络安全和信息化(2018年3期)2018-11-07
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
电测与仪表(2014年16期)2014-04-22
