
多尺度注意力机制DenseNet网络的表情识别方法
2023-03-08 10:57郑伟
软件导刊 2023年2期
郑 伟
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引言
面部表情识别方法是人机交互领域的重要核心,已经广泛应用于在线教育、疲劳驾驶检测等领域[1-3]。关于面部表情识别的研究历经了两个阶段:基于传统手工特征的表情识别和基于深度神经网络的表情识别。在传统手工特征的表情识别研究阶段,针对图像的几何、纹理和轮廓等方面设计手工特征算子作为后续表情分类判别的依据,在特定的场景下取得了较高的识别效果。比如KARANWAL 等[4]通过对图像纹理特征LBP 进行改进并引入正交编码,能够提取更具判别性的图像纹理特征,取得较好的表情分类效果;LIN 等[5]对图像轮廓特征HOG 进行改进,通过对表情敏感区赋予更高的权重来提高表情识别率。然而面对复杂的实际应用场景,如光照条件复杂、脸部局部遮挡等情况,基于传统手工特征的表情识别率就会出现大幅下降的问题。因此,随着深度学习理论的不断突破和大数据时代的到来,将神经网络应用于表情识别领域成为可能。其中卷积神经网络在图像识别领域表现优异,代表性的卷积网络有VGG19[6]、ResNet[7]等网络,并诞生了许多对卷积网络的改进以更适用于表情识别领域,如LIU 等[8]对Le-Net5 网络进行了改进,引入高低层跨连接思想,丰富网络提取的特征,提高了网络的识别率;ZHANG 等[9]针对VGG19 因叠加过多卷积层造成识别率下降的问题进行了改进,引入空间金字塔池化来提高特征表达能力。然而以上神经网络虽然都通过改进网络结构提高了识别率,但采用的网络都存在网络层数过浅,在面对其他不同数据集时无法保持较强的泛化能力。
针对上述问题,本文选择DenseNet121[10]进行改进,通过简化网络层数、引入多尺度结构和通道注意力模块MECANet,提高了DenseNet网络在表情识别领域的识别能力。
1 DenseNet121网络模型
DenseNet121 网络模型是Gao 等[11]于2017 年提出的密集连接卷积神经网络模型。该网络模型通过设计密集连接的稠密块加强了特征的传播,减少网络的参数量,缓解了网络模型过深导致的“梯度弥散”问题,从而提高了深度神经网络的识别率。DenseNet121 网络模型结构如图1 所示,整个网络模型由一个7×7 的卷积核构成的初始化卷积层、4 个稠密块、3 个过渡层、一个7×7 的全局最大池化层以及一个输出层组成。
1.1 稠密块
DenseNet121 网络模型与一般的卷积神经网络结构不同,其特有的稠密块让网络不再依赖最后一层输出的高语义特征向量作为分类识别的唯一依据,每个稠密块包含不同数量的卷积块,其独特的密集连接结构实现了其包含的每个卷积块的输入值都是向前所有卷积块输出值的并集,具体实现如图2 所示。假设稠密块中的卷积块1 的输入特征向量为X0,通过卷积块1 中的非线性转化函数H1,输出特征向量X1,因稠密块特有的密集连接的结构,故卷积块1输出特征向量为[X0,X1]并作为卷积块2的输入向量,以此类推,稠密块中第n 个卷积块的输出特征向量可以表示为:
这种密集连接结构加强了特征的传播,有利于提高提取特征信息的丰富性,并且由于每层输入都包含了前层所有的特征信息,在提取下层的特征时只需要提取很少的特征图,因而也在一定程度上减少了网络模型的参数量。

Fig.1 DenseNet121 network model structure图1 DenseNet121网络模型结构
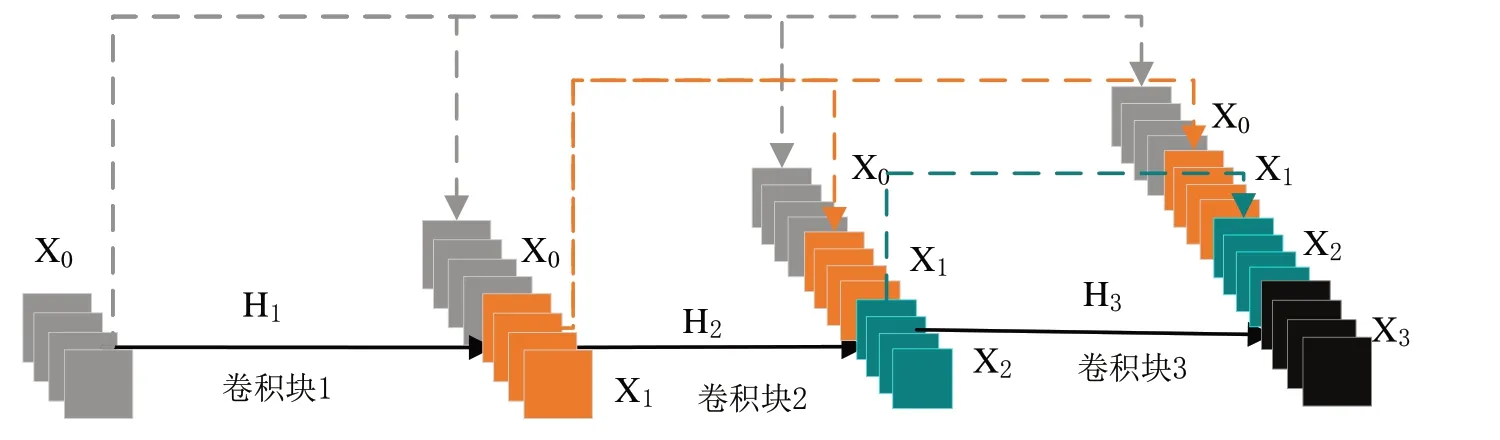
Fig.2 Dense block structure图2 稠密块结构
1.2 过渡层
DenseNet121 网络模型中的稠密块之间都会插入过渡层,其主要作用是对稠密块提取出的特征向量在通道维度和空间维度两个方面进行降维,其具体实现结构如图3 所示。每个过渡层主要由两个部分组成:瓶颈层[12]和池化层,瓶颈层的作用相当于滤波器,对输入的特征向量在通道维度上进行压缩,池化层的作用是对每个通道上的特征向量进行空间维度上的降维。

Fig.3 Transition layer structure图3 过渡层结构
2 多尺度注意力机制的DenseNet网络模型
本文针对DenseNet121 网络进行三个方面的改进:第一,DenseNet121 包含4 个稠密块,每个稠密块包含的卷积块个数分别为6、12、24、16,实现1000 种图像的分类。而本文仅需要实现对7 类表情图像的分类,采用的表情数据集若直接应用于DenseNet121 网络,会造成因模型参数得不到充分训练而导致的过拟合问题,因此对DensNet121 的网络层数进行一定程度的简化。第二,DenseNet121 输入的图像大小为224×224×3,初始化卷积层采用的卷积核大小为7×7,本文输入的图像大小为48×48×1,为了提取图像更为细腻和丰富的特征,将初始化卷积层替换为Inception网络[13]中的多尺度结构。第三,针对每个稠密块提取出的多通道特征向量,需要对不同通道特征向量依据对表情分类的贡献程度赋予不同的权值,因此引入本文设计的新型通道注意力模块MECANet。改进后的DenseNet 网络模型如图4所示。

Fig.4 Multi-scale attention module DenseNet structure图4 多尺度注意力模块DenseNet结构
2.1 多尺度卷积层
本文采用的多尺度卷积层的具体结构如图5 所示。该结构通过并行执行不同尺度大小的卷积核来获取不同尺度上的图像特征信息,然后通过整合不同尺度的图像特征信息,获取更丰富的表情特征。此外,该结构在不同尺度大小的卷积核之前都插入了一个1×1 的卷积核,该卷积核的作用相当于一个滤波器,缓解了使用不同尺度卷积核带来的模型参数量增加的情况,提升了网络的训练速度。

Fig.5 Multi-scale convolution layer structure图5 多尺度卷积层结构
2.2 新型注意力模块:MECANet
MECANet 模块是对通道注意力模块的ECANet[14]的改进,具体结构如图6 所示。原始的ECANet 只依赖全局平均池化(Global Average Pool,GAP)来获得各通道全局空间信息的特征描述符,接着再经过一维卷积层和非线性的激活函数Sigmoid 来建立各通道的依赖关系。为了更为完善的提取有价值的特征,减少压缩空间信息过程中的损失,本文提出了MACANet 通道注意力模块,首先分别对各通道特征信息进行全局平均池化、全局最大池化(Global Max Pool,GMP)和全局随机池化(Global Stochastic Pool Pool,GSP)来压缩全局空间信息,然后再分别送入一维卷积网络和激活函数层获得各通道依赖关系,最后融合各通道提取出的依赖关系并对多通道特征信息进行赋值,获得更具判别性的表情特征。具体计算公式如下:
其中,Wc表示经过MECANet 模块后生成的通道权重矩阵,F、FC分别表示经过通道权重矩阵加权前后的特征向量,σ(·)表示激活函Sigmoid 函数的运算公式。

Fig.6 MECANet structure图6 MECANet结构
多尺度注意力机制的DenseNet 网络模型的具体模型参数如表1所示。

Table 1 DenseNet model parameters of multi-scale attention mechanism表1 多尺度注意力机制的DenseNet网络模型参数
3 应用实验
3.1 实验环境
本实验基于Windows10 操作系统,使用的深度学习框架为tensorflow 2.1.0,选用的Python 版本为3.7,CPU 为InterCorei7,显卡为 NVIDIA RTX 2060。
3.2 数据集及数据增强
本实验采用CK+和FER2013 数据集对模型进行训练。其中,CK+数据集收集了981 张,包含anger、disgust、fear、happy、sad、surprise 和contempt7 种表情;FER2013 数据集由35886 张人脸表情图片组成,训练数据集有28708 张图片,公共验证测试集和私有验证测试集各有3589 张图片,包含anger、disgust、fear、happy、sad、surprise 和neutral7 种表情。
由于CK+数据集训练样本不足,为了防止网络模型因训练样本过小出现过拟合问题,对CK+数据集进行数据增强操作,通过对CK+数据集中每张图像进行翻转、旋转、模糊和锐化,将数据集扩充为原来的5 倍。具体数据增强示例如图7所示。
3.3 实验结果及分析
为了验证本文提出的多尺度注意力机制DenseNet 的有效性,首先与DenseNet121 在CK+数据集和FER2013 数据集上进行表情分类对比实验,并使用识别准确率和混淆矩阵来衡量网络模型性能。
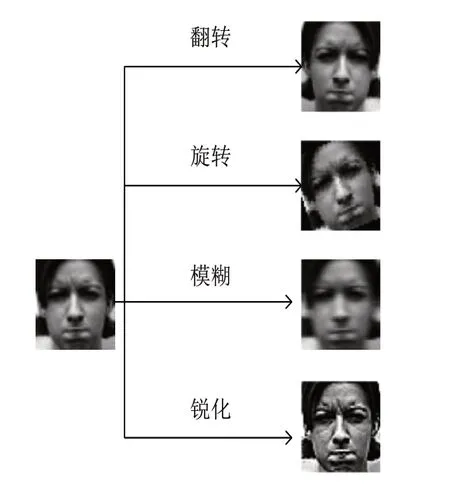
Fig.7 Data enhancement example of CK+dataset图7 CK+数据集数据增强示例
CK+数据集上,通过五折交叉验证实验获得网络模型的最终识别准确率,实验结果如表2 所示,改进后的DenseNet 网络模型在5 次实验中,最高识别准确率高达98.1%,最低识别率也达到了93.9%,平均识别率为96.2%。相较于DenseNet121,改进后的DenseNet 识别率平均提高了8.4 个百分点。从图8 所示的混淆矩阵可知,改进后的DenseNet 网络模型在fear、sad 和contempt 三类表情识别率都获得了较大的提高,特别是最难分辨的contempt 表情也从原来的0.5 的识别率提高到了0.62,由此可见,改进后的DenseNet 网络模型相较于DenseNet121 在表情识别领域具有一定的优势。

Table 2 Recognition accuracy of improved DenseNet and DensNet121 on CK+dataset表2 改进的DenseNet与DensNet121在CK+数据集的识别准确率(%)
FER2013数据集上,改进后的DenseNet与DenseNet121的识别准确率为两个测试集上识别准确率的平均值,具体实验结果如表3 所示。从表中可以看出,改进后的DenseNet 在较难分类的Fer2013 数据集上也取得了较佳的识别率,达到了85.3%,相较于DenseNet121 提高了8.6 个百分点,证明了改进后的DenseNet 在不同表情数据集上的鲁棒性。从图9 所示的混淆矩阵可知,DenseNet121 对anger、fear、surprise、neutral 这4 类表情识别效果不佳,改进后的DenseNet 提高了对这4 类表情的分类能力,其中对surprise、neutral 这两类的表情识别效果更是达到了100%,进一步验证改进后的DenseNet 相较于DenseNet121 具有提取更具判别性特征的能力。

Fig.8 Confusion matrix of DenseNet121(left)and improved DenseNet(right)on CK+dataset图8 DenseNet121(左)与改进的DenseNet(右)在CK+数据集上的混淆矩阵

Fig.9 Confusion matrix of DenseNet121(left)and improved DenseNet(right)on FER2013 dataset图9 DenseNet121(左)与改进的DenseNet(右)在FER2013数据集上的混淆矩阵
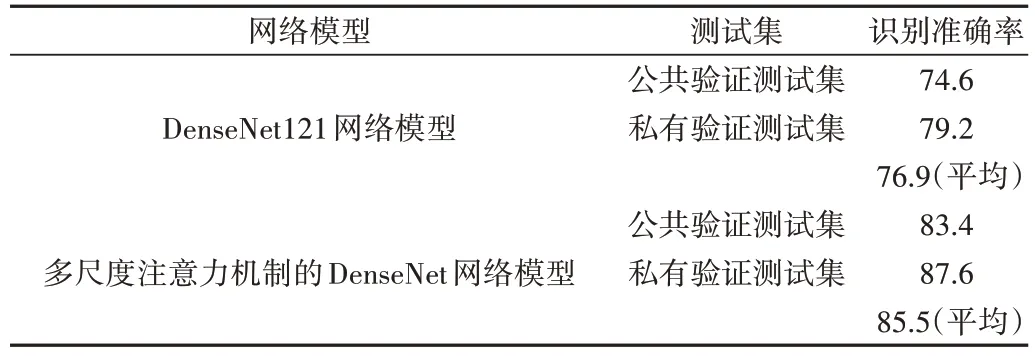
Table 3 Recognition accuracy of improved DenseNet and DensNet121 on FER2013 dataset表3 改进的DenseNet与DensNet121在FER2013数据集的识别准确率(%)
为了进一步验证本文设计的网络模型在表情识别领域的优越性,将其与近几年表情识别领域出现的网络模型进行了比较实验,实验结果如表4 所示。通过对比不同网络模型的识别准确率可知,本文设计的多尺度注意力DenseNet网络模型在表情识别领域具有一定的优势。
4 结语
本文基于DenseNet121 的网络模型基础上进行了三个方面的改进:减少网络层数、引入多尺度卷积层和设计了一种新型通道注意力模块MECANet,提出一种适合于表情识别领域的多尺度注意力机制的DenseNet 网络模型。接着从识别准确率和每类表情的混淆矩阵两个方面衡量改进后的DenseNet 与DenseNet121 两个网络模型性能,验证了改进后的DenseNet 网络的有效性;最后,将改进后的网络模型与不同网络模型进行准确率的对比实验,进一步验证了本文提出的网络模型在表情识别领域的优越性。但本文的研究工作依然存在不足,即基于静态图像提取表情特征,忽略了表情变化的动态信息,下一步工作将研究基于图像序列的表情分类。

Table 4 Comparison of recognition rates of different network models on CK+and FER2013 datasets表4 不同网络模型在CK+、FER2013数据集上的识别率对比(%)
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
太空探索(2016年5期)2016-07-12
中国交通信息化(2016年2期)2016-06-06
