
基于随机森林模型的黑龙江省地表温度降尺度的研究
2023-03-04 07:08:52赵丽
农业灾害研究 2023年1期
赵 丽
哈尔滨师范大学,黑龙江哈尔滨 150025
地表温度(LST)是全球气候系统中的一个重要参数,是地表和大气之间能量和水交换等过程的重要参数之一,也是驱动土壤热状态的主要因子。准确了解地表温度有助于在全球和区域层面评估(模型中的)地表—大气交换过程,并且当其与植被、土壤水分等物理特性相结合时,可提供有价值的地表状态度量。地表温度目前被广泛应用于全球气候变暖研究、城市热岛(城市热环境)效应评估、地表蒸散量计算和干旱监测等领域。然而,受卫星遥感成像技术发展水平的制约,现有的LST数据产品在时间分辨率和空间分辨率上存在着矛盾。因此,通过使用单一卫星产品无法获取兼具高时间、高空间分辨率的LST数据[1]。过境周期为16 d的Landsat卫星遥感影像数据有着比较高的空间分辨率,空间分辨率为1 000 m的MODIS/LST影像数据却可以每天获取4次。因而热红外遥感应用研究中的首要问题是提升高时间分辨率LST影像数据的空间分辨率,为此,对低空间分辨率的LST数据进行降尺度研究以提高数据质量是当前研究中的常规方法。
其中以建立地表温度与回归因子之间的统计关系,并假定地表温度与回归因子之间关系存在“尺度不变性”的统计回归方法,和通过低空间分辨率高时间分辨率图像与高空间分辨率低时间分辨率图像有效融合以得出高空间高时间分辨率数据的图像时空融合方法[2]。国内外学者对地表温度降尺度的研究方法众多,这些方法也是在前人研究基础上逐步优化改进而得到的。其中,较为被大家熟知的算法有Breiman[3]于2001年提出的随机森林算法,它是以决策树算法为基础而改进的一种机器学习模型,建立LST与驱动因子间的非线性回归关系。2003年,Kustas等[4]提 出 了DisTrad算 法,利用植被指数与辐射地表温度之间的关系估计地表温度亚像素变化。Agam等[5]在2007年提出了TsHAPR算法,证实了植被覆盖与地表温度之间的线性关系。
选取黑龙江省作为研究区,以提高MODIS/LST产品的空间分辨率为研究目的,并选取NDVI、地表覆盖、地表反射率及高程数据,通过随机森林算法构建地表温度降尺度模型。对选取的地表温度进行回归预测,通过均方根误差评价随机森林模型对地表温度降尺度的效果,以期为东北地区地表温度研究提供参考。
1 研究区与数据源
1.1 研究区概况
黑龙江省是中国最东北部的省份,南北长约1 120 km,东西宽约930 km,辖区面积47.3万km2。位置介于43°26′N~53°33′N,121°11′E~135°05′E。地势呈西北部、北部和东南部高,东北部、西南部低,中部山区多,东部次之,西、北部较少,气候为温带大陆性季风气候。
黑龙江地貌特征为“五山一水一草三分田”。地势呈西北部、北部和东南部高,东北部、西南部低,由山地、台地、平原和水面构成;地跨黑龙江、乌苏里江、松花江、绥芬河四大水系,属寒温带与温带大陆性季风气候。黑龙江省位于东北亚区域腹地,是亚洲与太平洋地区陆路通往俄罗斯和欧洲大陆的重要通道,是中国沿边开放的重要窗口。黑龙江省是我国重要的商品粮基地,农用耕地1 187.1万hm2,占农用地的30%。黑龙江省也是我国最大的林业省份之一,其中分布在大小兴安岭的天然林是黑龙江省森林资源的主体(图1)。
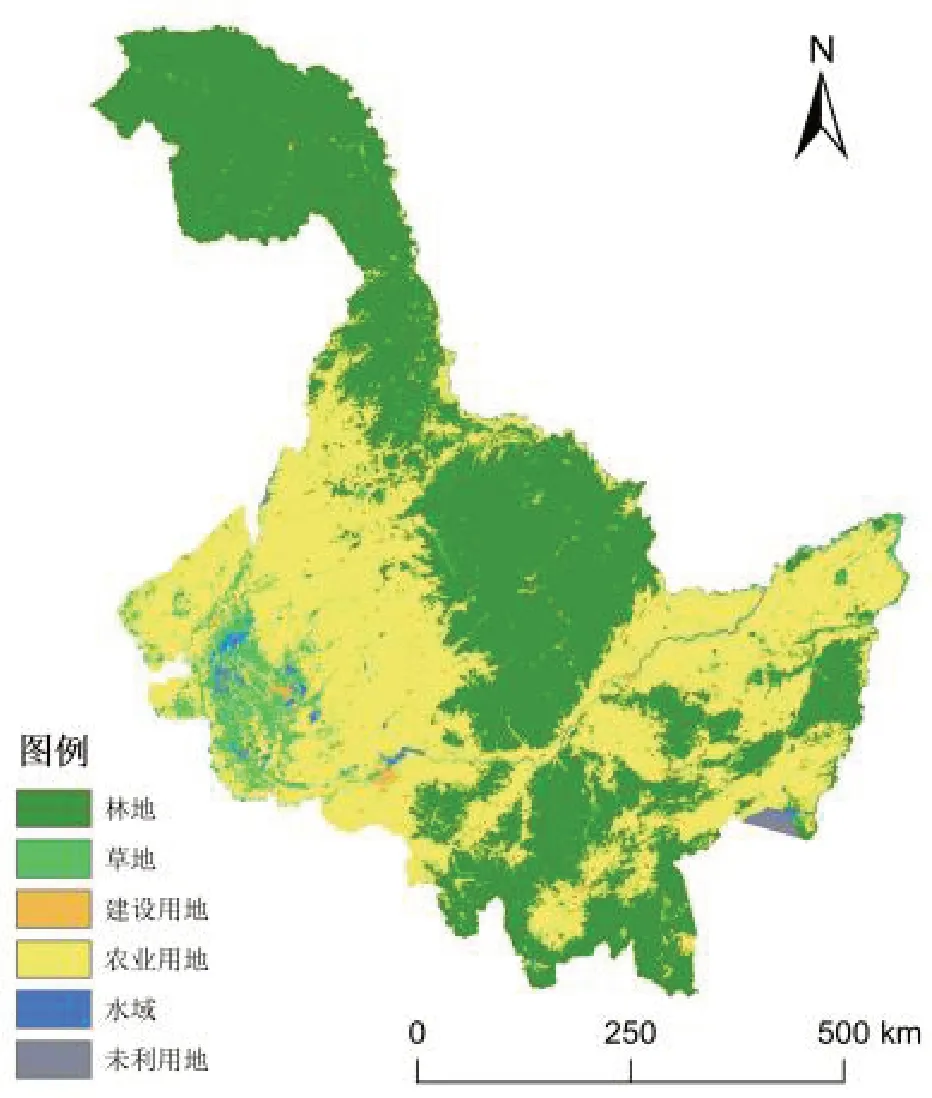
图1 黑龙江省2020年的土地覆盖分类
1.2 数据来源与处理
遥感图像选取对应区域的2020年MODIS LST地表温度产品、植被指数NDVI产品、地表覆盖产品、地表反射率产品以及高程数据,MODIS数据如表1所示。其中,MODIS数据需要使用MODIS数据预处理工具MRT(MODIS reprojection tool)对产品进行提取、重投影,根据研究的需要对处理后的数据进行裁剪处理。高程数据经投影转换后进行裁剪、重采样后提取坡度坡向数据。其中,MODIS 数据的预处理需要在MODIS的专门处理工具MRT(MODIS Reprojection Tool)中进行。基于MODIS原始数据进行拼接、重投影,并将数据的坐标系转换为WGS_84坐标系,同时提取所需要的波段(表1)。其 中,MOD11A2数 据 提 取LST_白 天_1km、LST_夜 间_1km波 段,MOD13Q1数据提取16_days_NDVI波段,MOD09Q1数据提取sur_refl_b02波段,MCD12Q1数 据 提 取LC_Type1波段,并且将数据的格式由HDF格式更改为GEOTIFF格式。随后利用黑龙江省边界矢量图在ArcGIS软件中对研究区进行裁剪。DEM数据通过ArcGIS软件进行合并、投影转换后,再利用黑龙江省边界矢量图进行裁剪和重采样,并通过软件中的工具计算出坡度坡向。从CRU TS数据官网(https://crudata.uea.ac.uk/cru/data/hrg/)下载温度数据用于降尺度后的误差验证。

表1 MODIS数据产品
2 研究方法
2.1 随机森林算法
随机森林算法是一种非线性统计集成算法,由多科分类与回归决策树CART组合构成。是一种基于决策树算法改进的高级算法,它的基本单元是决策树,可用于回归分析和分类。随机森林模型是由Breiman于2001年提出的一个机器学习模型,一个树型分类器,是通过集成学习的思想将多棵树集成的一种算法,它的本质属于机器学习中的集成学习,是将多棵决策树进行集成的算法,在变量数量远大于观察数量的环境中体现出了优越的性能。
随机森林主要体现在2个方面:一是随机选取训练集,随机森林随机且有放回地从训练集中抽取样本作为每棵树的训练集,保证了每棵决策树有不同的训练集;二是随机选取特征变量,避免某个特征变量与结果之间具有强相关性,因为特征变量全部被选取会导致所有决策树的相似性加强。随机森林模型的构建从每一棵CART决策树的根节点开始,持续输入特征变量进行测试,被正确分类后构建叶节点,将其分类到对应的叶节点;它的构建是对大量随机、不相关的决策树进行平均,用于分类或回归的目的[6],最后的结果是由多棵树共同决定的。此外,它的通用性足以应用于大规模问题,适应各种临时学习任务。
2.2 模型的构建
构建随机森林模型,首先要从原始数据集中随机抽取多个样本生成训练集,在此基础上生成决策树,从而构成随机森林(图2)。假设RF模型中共有M个风险指标,随机抽取m个(m≤M)作为节点指标,选取基尼最小值当作分支标准,依照决策树的预测结果,以投票方式决定新样本的类别[7]。每次抽样未被抽中的数据构成了袋外数据(Out of bag,OOB),利用袋外数据估计内部误差,称之为袋外误差(Error of out of bag,EOOB),公式如下:
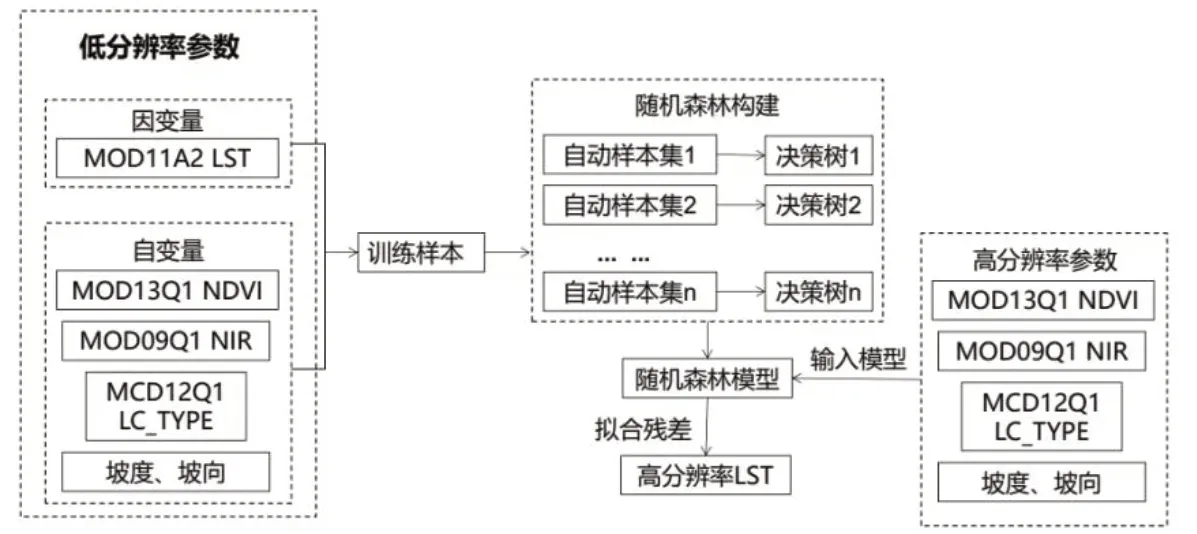
图2 随机森林模型的建立过程
式(1)中:n为OOB样本个数:为根据给定样本Xi基于RF模型的输出数据;Yi为观测数据。
此外,该模型通过对算法中OOB误差的估计评价特征变量的重要性。先计算每个决策树的袋外误差,然后在对风险指标的数据随机中加入噪声并计算袋外误差,风险指标的重要性公式如下:
式(2)中改变指标i造成的袋外误差EOOB2越大,表明变量i越重要。
2.3 精度评价
为了检验随机森林模型的降尺度效果是否可行,将黑龙江省的气温数据作为真实的LST数据,选取均方根误差(Root Mean Square Error,RMSE)检验指标。RMSE用以衡量观测值与真实值之间的偏离程度,RMSE值越小,则拟合精度越高,即
式(3)中:n为参与评价的像元数目;Toi为第i个像元的真实LST;Tei为第i个像元对应的降尺度算法模拟的LST。
3 结果与分析
通过随机森林算法对黑龙江省地表温度进行降尺度,以MOD11A2数据作为因变量,植被指数、地表覆盖、地表反射率和高程数据作为解释变量,建立随机森林降尺度模型,对地表温度进行回归预测,并评价随机森林算法在地表温度降尺度中的表现。降尺度效果较好(图3),纹理清晰,降尺度后地表温度的均方根误差(RMSE)为2.13 K,误差在可接受范围内。
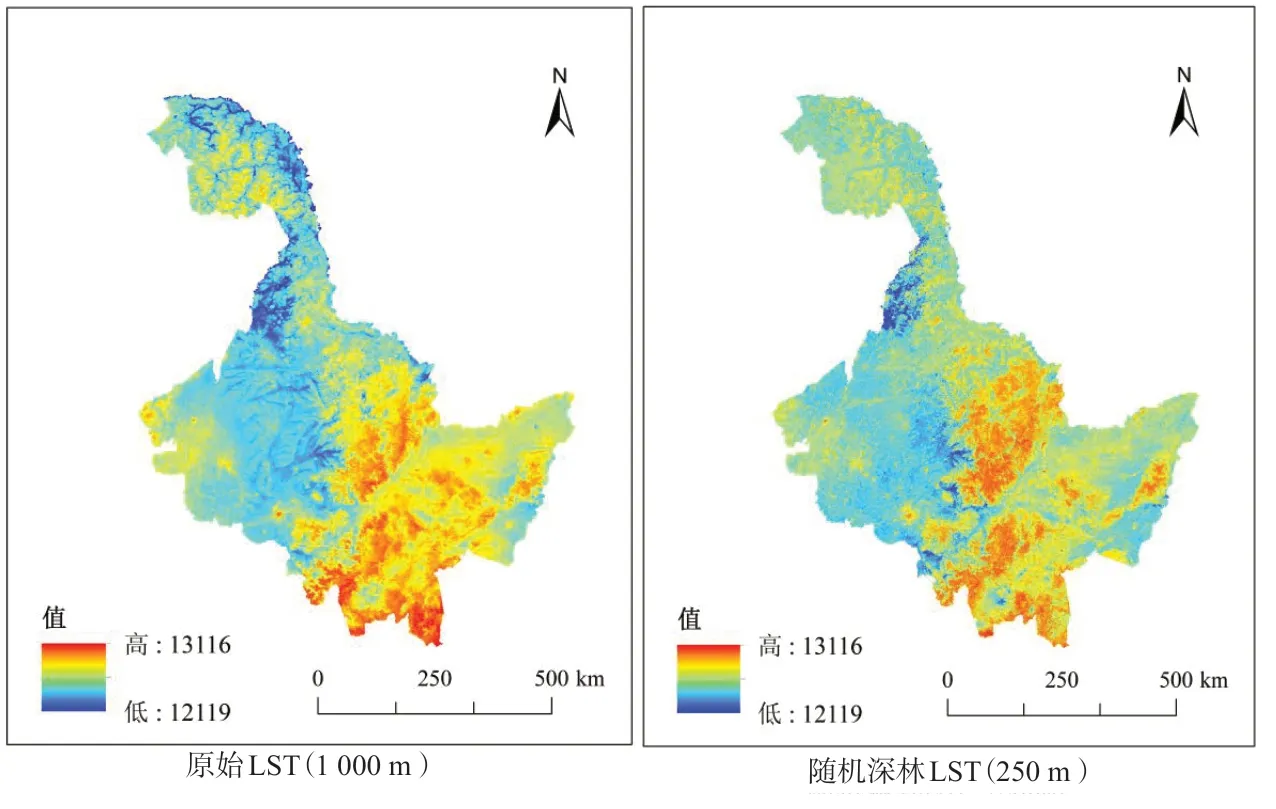
图3 黑龙江的省原始LST与降尺度结果对比
4 结论与讨论
利用黑龙江省MO11A2/LST遥感图像数据,通过建立随机森林模型对1 000 m分辨率的LST数据进行降尺度,得到250 m分辨率的LST数据,效果较好,证明了以黑龙江省为研究区,使用随机森林对MODIS/LST数据进行降尺度处理的可行性。但不同土地覆盖类型区域的降尺度效果存在差异,在植被覆盖区、水域和城镇地区降尺度的精度也存在着细微的差别,在今后的研究中有待进一步讨论。
猜你喜欢
应用能源技术(2020年11期)2021-01-26 00:16:50
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
数学物理学报(2019年3期)2019-07-23 01:15:40
家庭影院技术(2018年9期)2018-11-02 05:31:32
电子制作(2018年16期)2018-09-26 03:27:06
黑龙江省人民政府公报(2017年6期)2017-07-25 09:26:34
自动化学报(2017年5期)2017-05-14 06:20:52
黑龙江省人民政府公报(2017年22期)2017-03-26 08:20:10
黑龙江省人民政府公报(2017年21期)2017-03-20 05:29:12
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
