
基于确定性系数与支持向量机的滑坡易发性评价
2023-02-27 11:51:02陈芯宇师芸温永啸史瑞遥米晓梅
科学技术与工程 2023年2期
陈芯宇, 师芸*, 温永啸, 史瑞遥, 米晓梅
(1.西安科技大学测绘科学与技术学院, 西安 710054; 2.自然资源部煤炭资源勘查与综合利用重点实验室, 西安 710021)
中国地质条件复杂,不同地区的地理环境存在较大差异,崩塌、滑坡、泥石流等地质灾害频发[1]。滑坡灾害分布范围广、发生频率高、灾害损失严重,是主要地质灾害之一,给社会经济带来巨大损失,对滑坡灾害发生的预测及防治是当下的首要任务。
滑坡易发性评价主要目的是识别出极易发生滑坡的危险区域,其结果可为滑坡灾害风险管理以及防治提供重要理论依据和技术支撑。目前中外学者常用的评价模型包括定性和定量模型。其中定性主要有专家经验法及层次分析法[2],定量主要为统计模型(信息量模型[3]、确定性系数模型[4])和机器学习模型(支持向量机[5]、随机森林[6]、人工神经网络[7]、逻辑回归[8])。Farooq等[9]采用证据权、信息量、频率比、确定性系数4种统计模型建立滑坡易发性评价模型,所应用的模型对喜马拉雅山脉的杰赫勒姆谷地的滑坡易感性评估取得了较好的效果。Akgun等[10]采用逻辑回归和稳定性指数的方法对土耳其北部一个水坝库区进行滑坡敏感图的制作。谭玉敏等[11]采用信息量模型对重庆市涪陵区进行了地质灾害易发性评价。单一模型能较好运用于滑坡易发性评价中,但仍存在评价因子的量纲不统一、不能确定评价因子权重及建模过程中人为主观因素干扰等缺陷。因此,将两种模型甚至多模型耦合能取长补短,提高模型评价精度,以便更适用于滑坡易发性评价中。徐胜华等[12]采用熵指数模型融入支持向量机模型制作易发性分区图,IOE模型消除量纲等误差影响,ROC曲线结果表明耦合模型(IOE-SVM)预测准确率高于单模型(SVM)。邓念东等[13]分别采用自适应提升模型和随机森林模型以及基于两者模型耦合进行滑坡易发性评价,结果表明耦合模型训练集准确率和验证集的预测率均为最高。
前人诸多经验表明,多模型耦合精度高于单模型。其中,确定性系数模型可以解决多个复杂因子之间的同区间定量化的问题,根据滑坡点在各因子分级类别下的分布情况,可以计算出各因子分级类别下与滑坡的相对权重,但是难以确定各个因子在高维空间中与滑坡点的关系[14-15],支持向量机(SVM)能够通过引入核函数将样本值从低维映射到高维空间中,适用于较少样本数据集,但输入数据评价因子之间量纲不统一的问题会影响评价的结果。
因此,现将CF模型与SVM模型相结合,将评价因子的CF作为SVM模型输入值,解决了量纲不统一问题。在研究区地质灾害孕育基础上,选取了高程、坡度、坡向、地形曲率、距河流距离、距路网距离、降雨量、归一化植被指数(normalized difference vegetation index, NDVI)、地层年代、土地利用共10个评价因子对略阳县进行滑坡易发性评价,但在以往研究区中非滑坡点的选取多数采用全区域随机选点或缓冲区以外选点[16-17], 此种采样方法都难以保证所选的非滑坡点发生滑坡的概率极低,具有误差性。为了提高模型精度,更好用于易发性评价中,现采用CF模型对研究区进行易发性分区,在剔除极高、高易发区外选取非滑坡点,尽量保证所选的栅格单元发生滑坡的概率极低[18-19]。最终构建CF-SVM易发性评价模型,以为当地防灾减灾提供参考。
1 研究区概况
略阳县位于汉中市西北部,秦岭山脉南麓,地理坐标105°42′E~106°31′E,33°07′N~33°38′N,地势由南向北逐渐增高,海拔高度介于559~2 399 m,降水多集中在7—9月,平均气温在6~13 ℃。区内水系较为发达,县境从北到南有嘉陵江主流线与脊岭线两条高度不等的相对平行线贯穿。区内地质结构复杂,分布的岩层主要在古生代完成,变质岩、千枚岩分布于主要分布于城北,灰岩分布于城南,第四系堆积物主要分布在河谷两岸。研究区地质灾害主要以滑坡为主,区内滑坡隐患点为186个(图1),为了便于统计及计算,将研究区按照30 m×30 m的栅格单元进行划分,共计3 133 823个栅格单元。

图1 略阳县滑坡分布图Fig.1 Distribution map of landslides in Lueyang county
2 数据来源和研究方法
2.1 数据来源
本文研究中滑坡易发性评价数据源主要包括:①滑坡灾害点数据是由中国科学院资源环境科学数据中心的“地质灾害点数据分布数据”提供;②ASTER GDEM 30 m分辨率数字高程模型(digital elevation model,DEM)用于提取高程、坡度、坡向、地形曲率、水系;③OpenStreeMap提取该区矢量路网;④1∶200 000地质图矢量化得到地层年代;⑤2019年降雨量来源于中国气象数据进行插值得到年累计降雨量;⑥土地利用类型数据来源FROM-GLC,分辨率为30 m;⑦30 m分辨率Landsat8 OLI用于提取NDVI因子图层。
2.2 研究方法
2.2.1 确定性系数模型
确定性系数模型是一种概率模型,最早由Shortliffe等[20]在1975年提出,后来由Heckerman[21]对其进行改进。根据已有的滑坡灾害点,计算各个因子不同区间滑坡发生的概率,该模型属于双变量统计分析。CF计算公式为

(1)
式(1)中:PPa为地质灾害在因子分类a中发生的条件概率,可以用因子分类a中滑坡点个数与该类单元面积之比表示;PPs为地质灾害发生的先验概率,在研究区中为滑坡总个数与研究区总面积之比。由式(1)可得CF取值为[-1,1],当CF>0时,表示在该分类a下发生滑坡的概率较大,值越接近1发生滑坡的可能性越大;当CF<0时,表示在该分类a下发生滑坡概率较小,越接近-1表示该区间发生滑坡的可能性越小;当CF=0时,无法确定该分类a下是否有利于滑坡的发生。
2.2.2 支持向量机
支持向量机是一种分类器,于20世纪90年代中期发展起来、基于统计学习理论的一种机器学习,通过寻求最小化结构风险来提高学习泛化能力,实现经验风险和置信范围最小化,能够在样本较少的情况下,将低维非线性数据映射到高维空间中,解决非线性转化为线性求解问题,寻找最优超平面将正负两类数据分开,并保持间隔达到最大,使得支持向量机具有较好的鲁棒性[22-23]。
假设滑坡训练样本数据xi,其中i=1,2,…,n,n为训练样本的数量,xi包含10个评价因子输入向量,yi∈[-1,1]为输出值,表示滑坡与非滑坡。SVM是寻找一个最优超平面将两类数据正确区分开,超平面计算公式为
wΤx+b=0
(2)
式(2)中:w为法向量;x为样本点特征向量;b为常数。为了保证划分间隔最大化,最大间隔表示为

(3)
为方便求解,将其转化为最小值问题:

(4)
s.t.yi(wΤxi+b)≥1,i=1,2,…,n
(5)
计算过程中引入松弛变量ξi≥0和惩罚因子C:
s.t.yi(wΤxi+b)≥1-ξi
(6)
引入拉格朗日公式得
(7)
式(7)中:ai为Lagrange函数,ai>0;xi、xj为空间上的点。
最后得到最优分类函数为
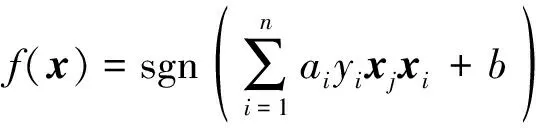
(8)
对于非线性问题,可以通过引入核函数将样本值从低维空间映射到高维空间,在空间中求得最优分类超平面。将x做非线性映射φ:Rn→H将输入的空间样本Rn映射到高维的特征空间H中得到
x→φ(x)=[φ1(x),φ2(x),…,φn(x)]Τ
(9)
对于高维空间的最优分类函数变为

(10)
3 评价因子选取与分级
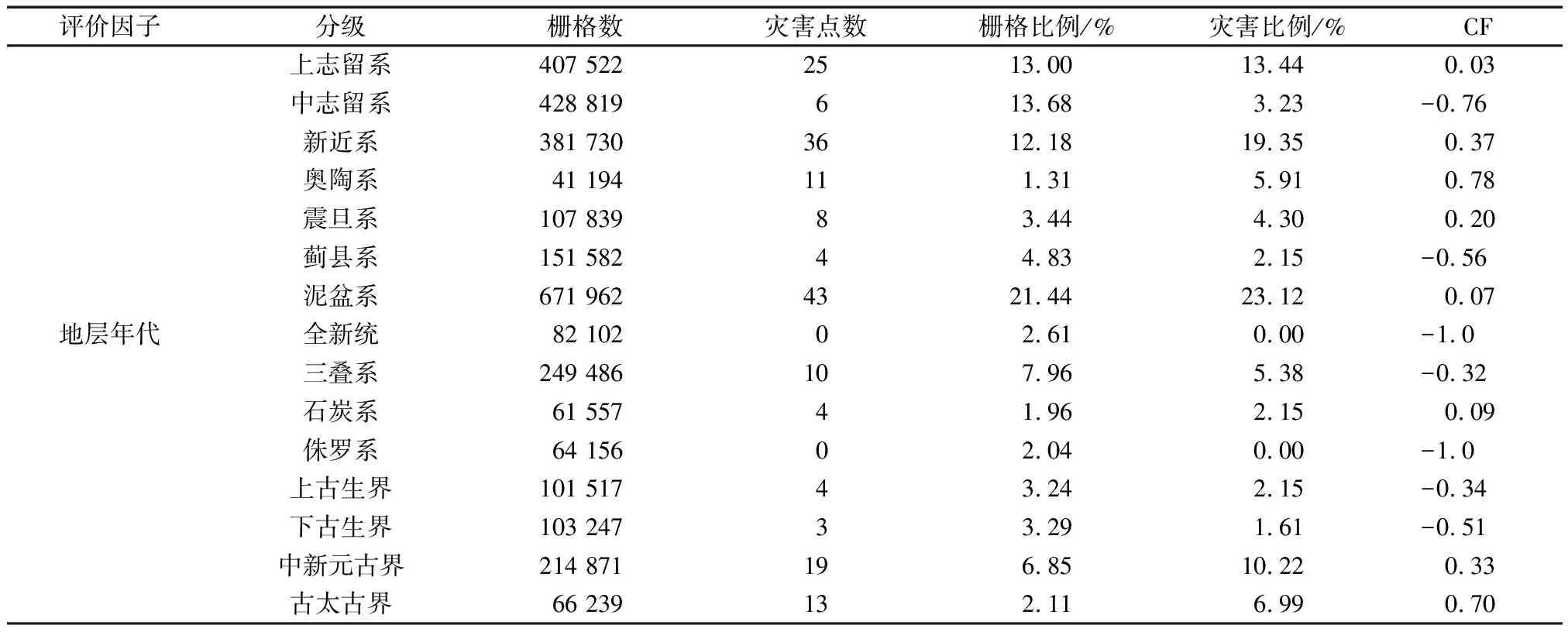
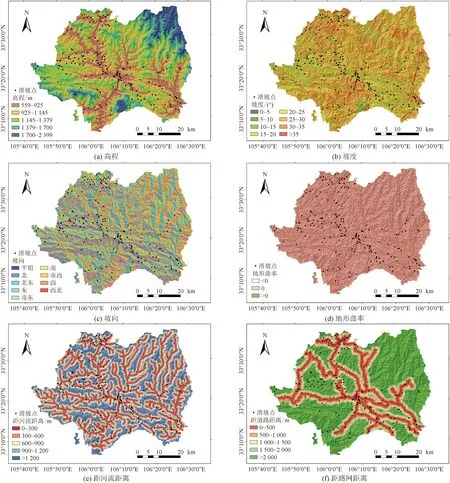
本研究区选取了高程、坡度、坡向、地形曲率、距河流距离、距路网距离、降雨量、NDVI、土地利用、地层年代共10个评价因子。其中土地利用和地层年代为离散型因子,离散型数据按照野外调查进行划分;剩余8个因子为连续性因子,连续型数据划分标准较难把握。根据前人经验,各因子分级图与分级表如表1和图2所示。
高程是影响滑坡的一个重要因素,不同高程范围具有不同植被类型及植被覆盖度,与降雨量也有高度相关性,高程间接影响滑坡灾害的发育[24],研究区高程599~2 399 m,按照自然间断法将其分为5类。坡度是决定斜坡体应力的大小和方向,是影

表1 评价因子分级Table 1 Evaluation factor classification
续表

地层年代1为上志留系;2为中志留系;3为新近系;4为奥陶系;5为震旦系;6为蓟县系;7为泥盆系;8为全新统;9为三叠系;10为 石炭系;11为侏罗系;12为上古生界;13为下古生界;14为中新元古界;15为古太古界图2 评价因子分级图Fig.2 Evaluation factor grading chart
响滑坡的一个重要因素,由于平坡应力小发生滑坡概率较小,随着坡度的增加应力也会增加,发生滑坡概率也会增大[25]。研究区坡度最高75°,按照5°等间隔划分8类,大于35°分为1类。坡向决定了坡体受到阳光照射的方向,不同坡向受太阳辐射强度不同,导致温度、降水也有所不同,将会影响土地覆盖度、岩石风化速度等差异,研究区坡向0~360°,以45°为间隔划分为9类。地形曲率是对地表凹凸变化的反映,正值表示凸坡,负值表示凹坡,地形曲率为0或者接近于0表示平坦[26]。由于地形曲率为0面积很小,将-0.2~0.2看成平面坡,<-0.2为凹坡,>0.2为凸坡。河流对两岸存在不同程度的冲刷、侵蚀影响滑坡灾害的发育,将研究区河流300 m等距离提取缓冲区,得到 6 个类别。道路工程中的开挖、路基拓宽等工程活动,改变了斜坡应力状态,降低了斜坡的稳定性。根据研究区道路的分布情况,以500 m为间隔对道路进行缓冲区分析,得到5个类别。NDVI反映植被覆盖度,取值在[-1,1],值越接近1表示植被覆盖越茂盛,研究区NDVI取值在[-0.34,0.9],将其按照自然间断法分为5类。降雨量在地质灾害的发生中起到诱发作用,突发强降雨,土质受到侵水后会发生软化,降低岩土体强度[27]。研究区降雨量927~1 032 mm,按照自然间断法分为5类。土地利用对滑坡灾害也有着十分重要影响,不同类型的土地利用,对滑坡灾害影响不同,将研究区土地利用分为8类:耕地、森林、草原、灌木、湿地、水体、建筑用地、裸地。地层岩性控制着滑坡的分布,地层年代影响着岩石的风化程度,岩石古老程度由出露时代决定,时代越久远,风化越严重。研究区按照地层年代实际分布分为15类:上志留系、中志留系、新近系、奥陶系、震旦系、蓟县系、泥盆系、全新统、三叠系、石炭系、侏罗系、上古生界、下古生界、中新元古界、古太古界。
研究区采用CF模型计算出每个因子分级区间的CF,CF越接近1,说明对应区间对滑坡的发生促进作用越大,反之,CF越小,对滑坡发生促进作用越小。如表1所示。
4 滑坡灾害易发性评价
4.1 多重共线检查
在模型计算之前,避免各因子之间存在高度相关性,导致模型分类结果准确率下降,为了保证各因子间的独立性。提取样本点的CF,采用SPSS软件对10个因子进行多重共线性检查。统计膨胀因子(VIF)和容忍度(TOL),当容忍度小于0.1或者方差膨胀因子大于10,表示各因子共线性程度高[28]。由表2可知各因子容忍度大于0.1,膨胀因子小于10,各因子之间不存在多重共线性问题,可参与模型训练。

表2 多重共线性检查Table 2 Multiple covariance check
4.2 SVM模型滑坡易发性评价
对于SVM模型易发性评价,为了降低数据集的不平衡性,提高模型的预测精度,按照1∶3比例在研究区随机选取非滑坡点558个与已有的滑坡点186个组成样本点,将样本点划分为训练集和测试集两部分:70%用于训练,30%用于测试。采用灰狼优化算法优化SVM参数得到最优参数惩罚因子C和核参数σ,将最优参数组合放入模型进行训练,将训练好的模型用于整个区域预测,最终得到略阳县易发性指数。按照自然间断法分为5类:极高易发区(4.74%)、高易发区(8.55%)、中易发区(14.40%)、低易发区(40.46%)、极低易发区(31.85%),结果如图3和表3可知,SVM模型从极低易发区到极高易发区频率比值逐渐增大,有58.06%的滑坡点落在极高和高易发区,仅有5.38%的滑坡点落在极低易发区中,说明SVM模型能较好评价略阳县滑坡易发性。

图3 SVM模型易发性分区图Fig.3 SVM model susceptibility partition map
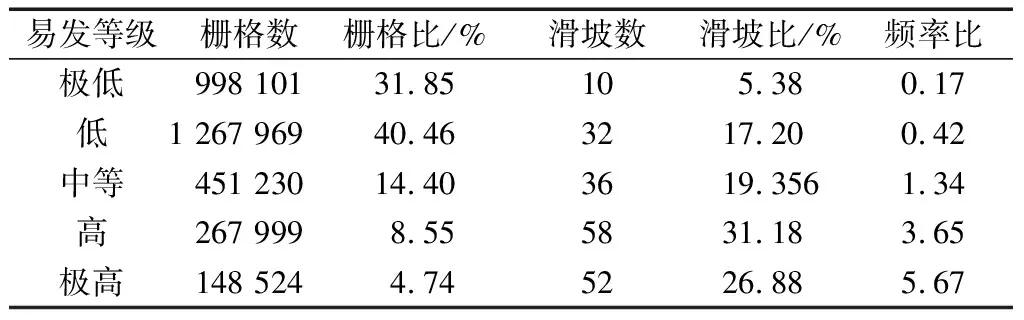
表3 基于SVM模型的易发性分区统计Table 3 Statistics of susceptibility partition based on SVM model
4.3 CF-SVM模型易发性评价
采用CF-SVM进行易发性分区,先将10个因子计算出各分级类别下CF,采用ArcGIS栅格叠加得到CF模型的易发性指数,采用自然间断法,将整个区域分为 极低易发区、低易发区、中易发区、高易发区、极高易发区,在剔除极高、高易发区外随机选取非滑坡点(图4),同样采用1∶3进行选取非滑坡点,将非滑坡点与滑坡点组成样本点,将其70%作为训练集,30%作为测试集。经过灰狼优化算法优化模型参数得到最优C和σ,将训练好的模型用于整个区域预测得到略阳县滑坡易发性指数。按照自然间断法分为5类:极高易发区(9.04%)、高易发区(15.74%)、中易发区(23.31%)、低易发区(29.55%)、极低易发区(2.6%)。如图5和表4所示,极高和高易发区频率比为4.58、2.08,其余频率比小于1,符合事实,约有74.2%的滑坡栅格单元落入极高和高易发区,表明CF-SVM模型具有更好的预测精度。

图4 非滑坡点选取图Fig.4 Non-landslide point selection map

表4 基于CF-SVM模型的易发性分区统计Table 4 Statistics of susceptibility partition based on CF-SVM model

图5 CF-SVM模型易发性分区图Fig.5 CF-SVM model susceptibility partition map
5 结果评价与分析
5.1 模型评价
为了更好地评价两种模型的预测能力,采用受试者特征曲线(receiver operate curve,ROC)曲线对略阳县滑坡灾害易发性模型进行检验,真阳率为纵坐标(敏感度),假阳率为横坐标(1-特异性),ROC曲线下的面积(AUC)取值范围为[0.5,1],AUC越大表示模型预测能力越好[29],由图6可知随机选取的非滑坡点SVM模型曲线下的面积(AUC)为0.83,在CF模型下剔除高易发和极高易发选取的非滑坡点CF-SVM模型曲线下的面积(AUC)为0.95,说明CF-SVM模型略优于SVM模型,证明了非滑坡点的选取会影响模型的精度,从而会影响模型易发性评价结果。CF模型基础上能更准确地选取非滑坡点,使CF-SVM模型具有更好的预测性能。

图6 ROC曲线结果Fig.6 ROC curve results
5.2 易发性分区分析
(1)以略阳县为研究区,基于SVM模型得到易发性分区图,并做出ROC曲线下AUC面积为0.83,在CF模型基础上,在剔除极高和高易发区外选取非滑坡点与已知滑坡点组成样本点训练出来的模型用于整个区域得到CF-SVM易发性分区,ROC曲线下AUC=0.95,说明CF-SVM模型具有较好的评价精度。
(2)基于SVM模型易发性分区图可知,从极低易发区到极高易发区频率比分别为0.17、0.42、1.34、3.65、5.67,频率依次增高,CF-SVM模型频率比分别为0.05、0.16、0.85、2.08、4.58,高和极高易发区最高,符合事实。且SVM模型和CF-SVM模型计算极高频率比分别占总频率比值的50.0%和59.3%,表明CF-SVM模型要比SVM模型预测效果要好,在CF基础上剔除极高和高易发区后更能准确地选取非滑坡点。
(3)由易发性分区图可知,极高和高易发区主要分布在河流及道路附近,这些区域植被覆盖较少,高程较低,人类活动频繁,坡体易受到人为活动影响,导致边坡不稳定,极低易发区主要分布在高程较高,植被覆盖度高,人为活动较少,边坡稳定,结果符合实际,能够用于滑坡易发性评价。
6 结论
(1)采用SVM模型和CF-SVM模型得出易发性分区图,将CF作为SVM模型输入值能有效解决各因子之间量纲不统一问题,SVM模型与CF-SVM模型都能较好地评价略阳县滑坡易发性,SVM模型在极高和高易发区涵盖了58.06%滑坡点,CF-SVM模型在极高和高易发区涵盖了74.2%滑坡点,只有1.7%滑坡点落在极低易发区,表明CF-SVM模型评价结果更准确,剔除高、极高易发取选取非滑坡点的可行性。
(2)对易发性结果检验可知,CF-SVM模型AUC为0.95,优于随机选取非滑坡点的SVM模型AUC为0.83,能够有效反映出CF-SVM模型具有更好的评价精度。表明在CF模型易发区分区基础上,剔除极高和高易发区后在剩下区域随机选取非滑坡点,避免了少量非滑坡点选在高易发区,从而影响模型预测准确率。
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23 00:30:46
大众科学(2022年5期)2022-05-18 13:24:20
今日农业(2021年10期)2021-11-27 09:45:24
河北地质(2021年1期)2021-07-21 08:16:08
今日农业(2021年1期)2021-03-19 08:35:32
吉林农业(2017年9期)2017-09-09 02:57:57
北方交通(2016年12期)2017-01-15 13:52:59
现代园艺(2016年7期)2017-01-09 18:10:55
现代园艺·综合版(2016年7期)2017-01-09 06:27:04
水利科技与经济(2016年6期)2016-04-22 05:07:30
