
双向信息交互的道路场景全景分割网络
2023-02-23 08:29刘博林黄劲松
导航定位学报 2023年6期
刘博林,黄劲松
双向信息交互的道路场景全景分割网络
刘博林,黄劲松
(武汉大学 测绘学院,武汉 430079)
为了进一步研究道路场景的全景分割功能,为自动驾驶车辆全面感知环境提供支持,提出一种双向信息交互的全景分割网络:通过主干网络进行特征提取,并将特征分别输入到语义分割分支和实例分割分支;然后在分支间增加实例增强信息模块、语义增强信息模块以增强信息交互;最后采用改进的融合算法将语义结果和实例结果融合,得到全景分割的预测结果。实验结果表明,设计的双向信息交互模块能够提高全景分割网络的性能,在Cityscapes数据集上采用512×1 024个像素分辨率的图像情况下得到了46.8的全景质量(PQ)分数。
全景分割;自动驾驶;多任务学习;信息交互;语义分割;实例分割
0 引言
全景分割[1]旨在识别图像中的所有事物,赋予其类别标签和实例标识(identification,ID)。在全景分割任务中,图像类别标签可分为2类,即things和stuff。things是可计数的物体,例如车辆、行人等。而stuff是由剩余类别组成,一般不可计数,例如天空、道路和水。全景分割可以看作实例分割和语义分割结果的融合。语义分割与实例分割是计算机视觉中的经典任务,语义分割任务是将图像中的每个像素分类,赋予每个像素类别标签,既包含things类,也包括stuff类;实例分割更关注图像中物体级别的检测,其目标是检测每个物体并用分割掩码来表示,实例分割任务只关注图像中存在的things类,而不考虑stuff类。
随着图像处理技术的发展,数字图像已经成为日常生活中不可缺少的媒介,每时每刻都在产生图像数据。对图像中的物体进行快速准确的分割变得愈发重要[2]。在自动驾驶场景中,全景分割的结果可以为导航定位系统提供丰富的语义信息。通过将场景分割成不同的语义区域,可以识别出道路、建筑物、行人、车辆等重要的道路场景信息。这些信息可以帮助自动驾驶车辆全面地感知环境,从而帮助其进行场景理解和语义推理,为进行更高级别的决策和规划提供支持。
2018年,文献[1]首次提出了全景分割概念,使用了一种融合方法,将当时最好的实例分割网络掩码区域卷积神经网络(mask region-convolutional neural network,Mask R-CNN)[3]和语义分割网络金字塔场景解析网络(pyramid scene parsing network,PSPNet)[4]的结果合并为全景分割结果,为后续研究提供基准。文献[5]首次提出了统一的全景分割网络框架,引入了公共特征提取网络以减少计算量,在不降低精度的情况下缩短了推断时间。全景特征金字塔网络(panoptic feature pyramid networks,Panoptic FPN)[6]在实例分割网络Mask R-CNN的基础上增加了语义分支全卷积网络[7](fully convolutional networks,FCN),通过融合FCN的语义分割结果和Mask R-CNN的实例分割结果得到全景分割结果。这种利用子网络独立分割,再对结果进行融合的方法成为一种十分经典的方法。但上述方法未考虑子任务间存在的相关性。由于语义分割和实例分割任务间存在一定的互补性,一些研究提出利用任务间的信息交互来改善全景分割结果。文献[8]提出了2个实例增强信息模块,利用实例分支的物体结构信息补充语义分支,有效利用了实例分支的背景信息,提升了全景分割质量。文献[9]针对道路场景提出了一种使用语义信息增强实例分支的网络,利用语义分支的像素信息增强实例分支的识别能力。文献[10]提出了一种信息聚合的网络,利用语义分割和实例分割间进行的特征交流,提升了全景分割效果。文献[11]设计了一个分支间加入了结果一致性(things and stuff consistency,TASC)模块的方法,用实例分割结果和语义分割结果融合来监督任务的一致性,一定程度上解决了子分支间的冲突问题。上述网络表明多任务全景分割网络分支间必要的信息交互能有效改善全景分割结果,但这些方法大多是单向的信息交互方法。一些研究方法从其他方面入手改善全景分割网络性能。文献[12]基于图卷积网络提出了一种全景分割网络,利用边界信息来增强监督信息并帮助区分相邻对象。文献[13]提出一种基于分组卷积进行特征融合的全景分割算法,提升了网络的运算速度。文献[14]将图卷积网络和传统全景分割网络相结合,研究前景things和背景stuff的关系,提出了双向图形连接模块(bidirectional graph reasoning module),它可以在前景物体和背景区域之间进行信息传递和交互。文献[15]提出了一种无参数的全景分割头来融合语义和姿态分割预测以代替传统的启发式方法,借助其全景分割头,产生了一个高性能的分数。文献[16]基于文献[15]在残差网络和特征金字塔之间添加一种三重态注意力机制,提升了网络性能。文献[17]提出了空间排序模块,以解决分数较高的物体对分数较低物体的覆盖问题。
本文针对多任务全景分割网络中语义分割和实例分割子网络间的信息交互问题,设计一种双向信息交互的全景分割网络,网络通过引入语义增强信息和实例增强信息模块实现分支间的信息交互。该网络并行进行语义分割、实例分割,最终通过改进的融合算法将二者结果合并为全景分割结果。
1 网络结构
对于一幅输入图像,首先提取特征;然后将提取的特征输入语义分割与实例分割的子任务分支进行处理,产生语义分割与实例分割输出;最后是子任务融合,将语义与实例分支产生的结果通过适当的策略进行融合,产生最终的全景预测。
本文提出的全景分割网络包括特征提取部分、实例分割分支、语义分割分支和融合模块4部分,为了增强实例和语义信息之间的交互,在语义分支和实例分支间引入了实例增强信息模块和语义增强信息模块,实现了双向信息传递和融合。整体框架结构如图1所示,图中RPN为区域提议网络(region proposal networks),ROI为感兴趣区域(region of interest)。
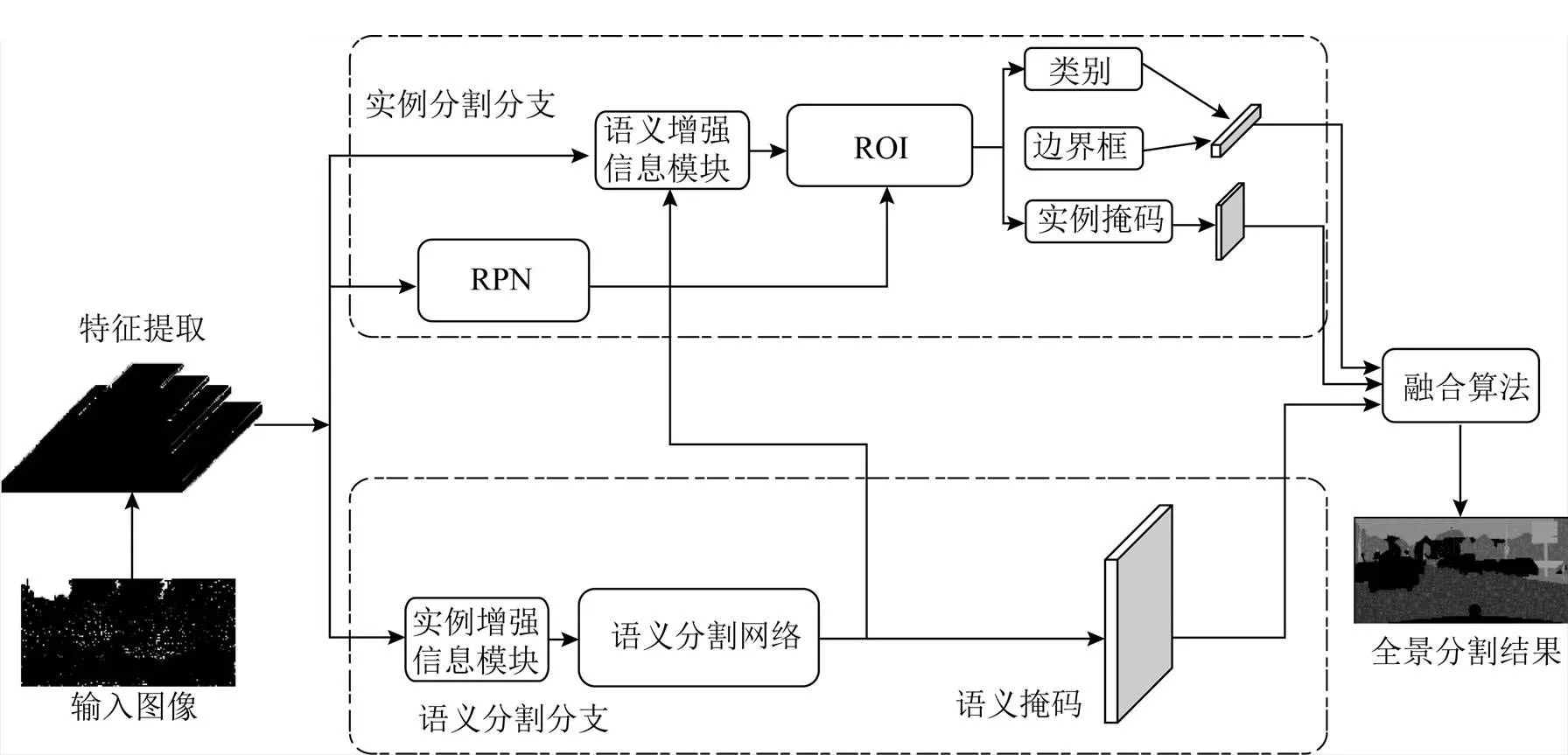
图1 本文全景分割网络框架
输入图像首先通过带有特征金字塔网络(feature pyramid networks,FPN)[18]的主干网络残差网络(residual network,ResNet)进行特征提取;其次每层的特征图分别输入于语义分割分支和实例分割分支;接下来先将提取的多尺度特征输入至RPN输出ROIs,同时利用RPN丰富的前景背景信息采用实例增强信息模块提取上下文信息,并与语义分支的特征融合,进行语义预测,语义分支采用普通的FCN以实现;然后将语义结果通过语义增强信息模块增强实例特征表示,实例分支则遵循经典的Mask R-CNN方法进行实例预测;最后将得到的语义掩码和实例掩码经过改进的融合算法得到最终的全景分割结果。
1.1 实例增强信息模块
在Mask R-CNN中,RPN能够为检测任务提供预测的二值标签(things和stuff标签)和包围框(bounding box)坐标。这表示在RPN中蕴含着丰富的前景和背景信息,这些上下文信息能够提供额外的语义分割类别信息,减少语义分支的分类错误。因此设计了实例增强信息模块来增强语义分支。
实例增强信息模块使用RPN分支的上下文信息和语义分支进行信息交互。首先提取RPN的上下文信息,计算公式为

式中:R为R×"×"维度第层的RPN输入特征图,其中R为RPN层通道(channel,C),"、"分别为第层RPN特征图的宽(width,W)、高(height,H);θ,1θ,2为卷积层的参数;(•)为卷积(convolution,Conv)操作;1为修正线性单元(rectified linear unit,ReLU)激活函数;2为S型(Sigmoid)激活函数;M为RPN的上下文信息权重。
为了突出第层RPN的上下文信息M对语义分支的影响,将M与来自第层的语义特征图S进行计算。计算公式为
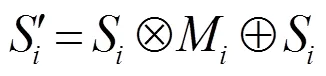

为了减少无用的背景层对语义分割结果的影响,受文献[19]启发,设计了一个重加权模块以降低上下文信息M中无用权重的影响。重加权模块计算公式为
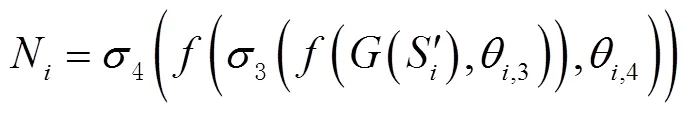
式中:(•)为全局平均池化(global average pooling,GAP);θ,3、θ,4为卷积层的参数;3为ReLU激活函数;4为Sigmoid激活函数;N为重新加权的结果。
最终将重加权结果N和实例增强后的语义特征图相乘得到语义结果,计算公式为
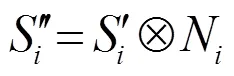
实例增强信息模块的整体流程如图2所示。图中s为语义分支通道。
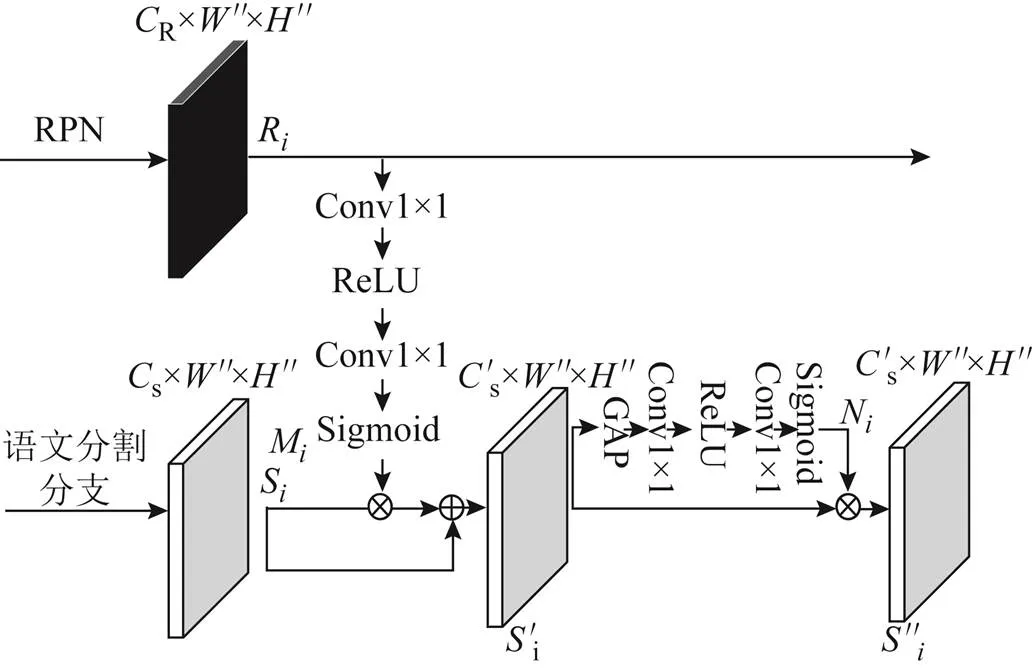
图2 实例增强信息模块
1.2 语义增强信息模块
在针对某些things的预测中,语义分割的预测结果会优于实例分割对该things的预测结果;而在本文所示的网络结构中,如图1所示,为避免2个分支对things预测的冲突,只选择实例分割分支的结果作为things类别的预测。因此这种算法会导致语义分割分支的某些潜在的有价值信息的损失,从而导致模型性能降低。所以在这些原因的启发下,本文添加了一个额外的模块,其采用语义分支丰富的上下文信息以提高实例分支对things类别预测的精度。
提出一个语义增强实例模块来实现上述想法。首先在语义分支结果部分和ROI阶段增加了一个额外的信息交互通道,该通道首先提取语义结果信息,计算公式为
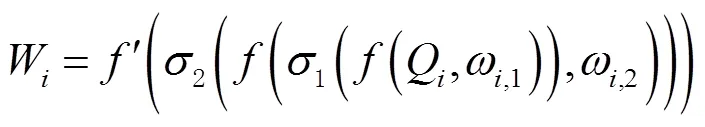

然后将第层得到的语义分支权重W和来自实例分支的第层的特征图P进行计算,计算公式为

同样地,考虑到实例分支只关注things类别的检测和分支,为了减少无用的背景信息对实例分支精度的削弱,设计了一个与1.1节相同的重加权模块以降低W无用权重的影响,计算公式为
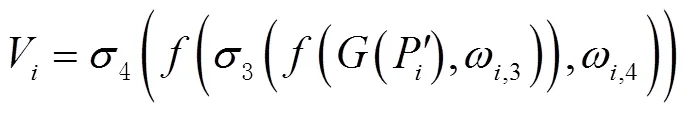
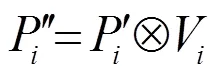

语义增强信息模块的整体流程如图3所示。

图3 语义增强信息模块
1.3 融合模块
由于本文的网络是并行独立地输出语义分割结果和实例分割结果,因此需要进行后处理操作以将2种预测结果合并为全景分割结果。全景分割结果分为2部分,即类别标签和实例ID。在进行融合时,需要处理2个问题,即重叠问题和冲突问题。本文在传统启发式方法的基础上做出改进。
重叠问题:实例分割会出现同一个像素点可能被多个实例或者类别同时覆盖的结果。对于目标检测、实例分割任务来说,像素点的重叠问题不会影响预测结果,而对于全景分割任务,需要对于单一像素输出单一类别及唯一实例ID,因此掩码重叠问题是全景分割任务必须解决的问题。本文采用文献[1]提出的基准方法,该方法流程与非极大值抑制(non-maximum suppression,NMS)方法类似,即按分类置信度分数对实例分割结果进行降序排序,选择分数最高的预测结果,计算与其他预测框的交并比(intersection over union,IOU),当IOU大于设定阈值时,去除该预测结果,直到没有剩下的预测结果为止。一般地,阈值设置为0.5。
冲突问题:对于stuff的类别预测,仅需要语义分支结果;对于things类别的预测,实例分支、语义分支都进行了不同的预测,因此2种预测结果不可避免地存在预测冲突。而考虑到语义分支的预测结果不能有效区分同一类别的不同实例,不能直接对2种预测结果进行比较。本文在文献[1]的方法上做出改进,对于things类别预测,优先选择实例分割预测而不是语义分割预测结果,同时为了避免不必要的信息损失,将语义分割预测分数最高的things类别替换为预测分数最高的stuff类别。
融合策略如图4所示。对于实例分支预测,首先采用类似NMS的方法去除实例预测重叠,得到实例掩码;对于语义分支预测,先将所有的things预测替换为stuff预测,最终将二者获得的预测结果合并,得到全景分割结果。

图4 融合策略
1 实验与结果分析
1.1 数据集、评价指标及实验环境
1.1.1 数据集
本文使用自动驾驶数据集城市景观数据集Cityscapes[20]作为实验数据集。Cityscapes是道路场景的常用数据集,包含了50个欧洲城市,春夏秋3季数个月的街道场景,人工选择出视频中含有的大量动态物体、不同的场景布局、不同背景的帧,不包含黑夜、恶劣天气环境等场景。
数据集包括5000张精细标注的全局语义分割图片(训练集2975张、验证集500张、测试集1525张)和20000张粗略标注的图片。在本文的实验中,选择5000张精细标注的图片,包括8个things类别、11个stuff类别。所有图像的分辨率均为1024×2048个像素,实验中将输入图像调整为512×1024个像素。本节的实验结果是训练后的网络在验证集上的测试结果。
1.1.2 评价指标
实验使用全景质量(panoptic quality,PQ)作为主要评价指标。PQ可以衡量全景分割结果的分割准确度,定义为
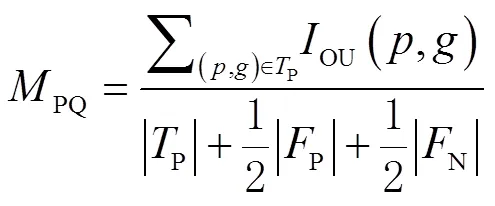
在二分类或多分类任务中,常常需要计算模型预测结果和真实标签的差异,可以分为TP、FP、FN、真阴性(true negative,TN)4种,其中TP、FP、FN分别表示预测标签和真实标签中的已匹配部分、不匹配的预测部分和不匹配的真值部分。IOU计算只包含已匹配的部分(即为TP的部分);当IOU大于0.5时,一般定义为匹配。如图5所示为区分TP、FP、FN的原理。
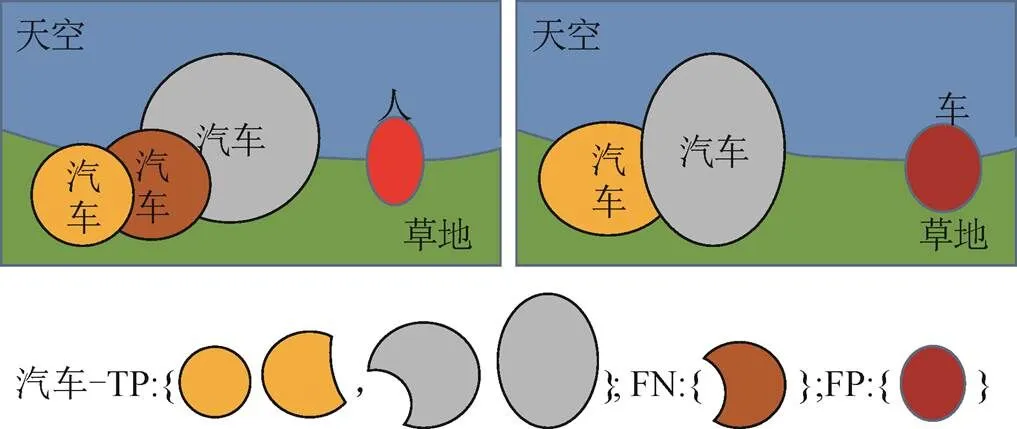
图5 TP、FP、FN概念
PQ同时可以分解为分割质量(segmentation quality,SQ)和识别质量(recognition quality,RQ)的乘积,计算公式为

式中:SQ能体现模型对正确预测的匹配物体实例分割的准确度,RQ用来衡量所有类别物体的检测准确度。
1.1.3 损失函数
为了实现单一网络的联合训练,在训练阶段,使用一个联合损失函数对网络进行优化。联合损失函数分为6个部分,计算公式为
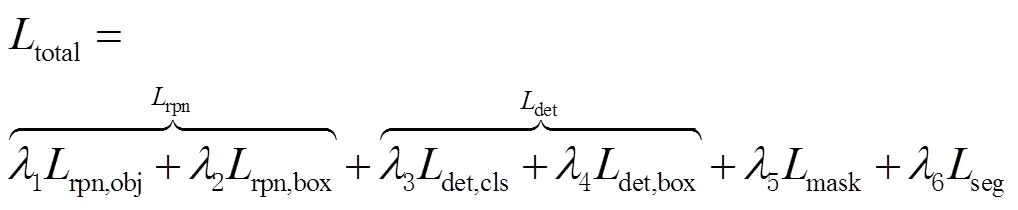
式中:total为联合损失函数;rpn为RPN损失;rpn,obj为RPN类别的交叉熵(crossentropy loss)损失函数;rpn,box为RPN平滑的最小绝对值偏差损失函数(smooth1 loss);det为检测损失;det,cls为目标检测任务的分类损失,使用交叉熵损失函数;det,box为目标检测任务的包围框回归损失,使用smooth1 loss;mask为实例掩码的二分类交叉熵(binary crossentropy loss)损失函数;seg为语义分割任务损失,使用交叉熵损失函数;1、2、3、4、5、6分别表示对应损失函数权重。
1.1.4 实验环境及设备
本文基于深度学习框架Pytorch1.10实现网络结构。实验以8个批量大小训练模型,损失权重根据式(11)1~6分别设置为1、1、1、1、1、0.75,优化器选择随机梯度下降(stochastic gradient descent,SGD),动量(momentum)设置为0.9,权重衰减1×10-4,初始学习率0.01,迭代100个历元,学习率在第66、88个历元时衰减10倍。
1.2 消融实验
为了检验本文提出的信息交互模块的效果,在确保相同的实验环境和配置的条件下,针对1.1、1.2节提出的2个信息交互模块设计消融实验以验证其有效性:1)不包含2个模块的基准网络;2)仅加入语义增强信息模块;3)仅加入实例增强信息模块;4)包含2个模块的双向信息交互网络。分别在Cityscapes数据集进行训练,并在Cityscapes验证集评估结果,结果如表1所示。为了验证各个模块对对应任务的促进作用,另统计PQth、PQst指标,其中PQth、PQst分别为PQ在things、stuff类别上的结果。
如图6所示为双向信息交互网络的损失函数和学习率随历元变化的情况,图中红色的曲线表示训练损失变化,左边的纵坐标为损失函数值,蓝色的线条表示训练学习率的变化,右边纵坐标为学习率值,横坐标表示训练的历元个数。
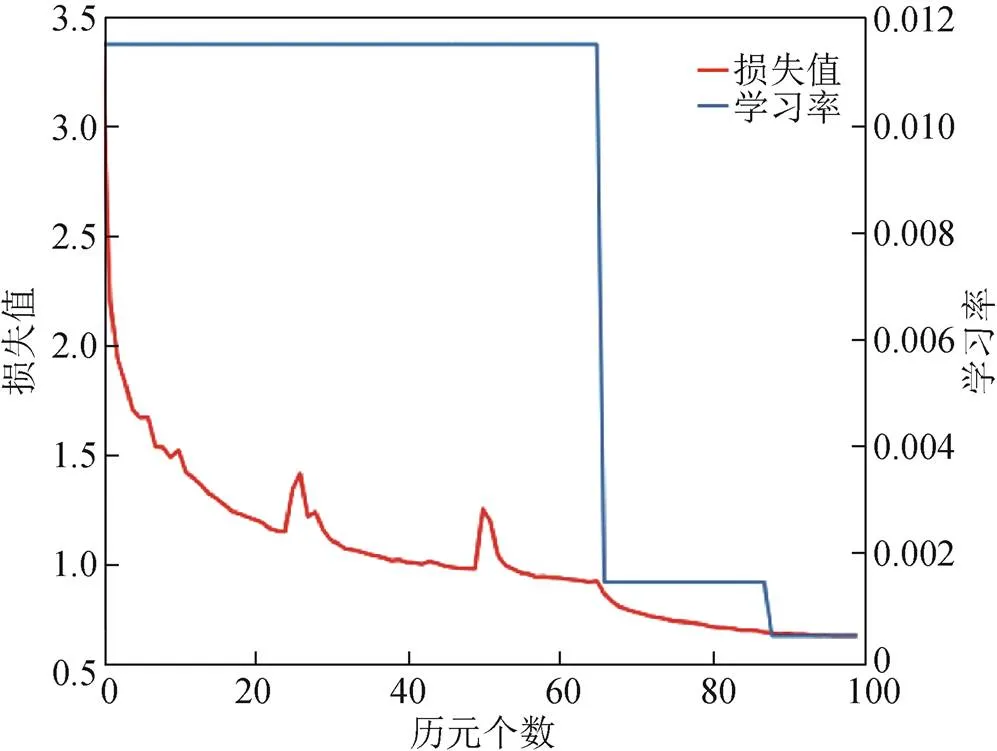
图6 Cityscapes数据集上损失函数收敛曲线
如表1所示为不同模型在Cityscapes验证集中的实验结果。对比基准网络,提出的网络在PQ分数上得到了3.1%的提高。可以看到语义增强信息模块、实例增强信息模块均有效地提升了网络全景分割质量。语义增强信息模块使用了语义分支的结果信息为实例分支的目标检测器提供了更多的细节信息,提升了检测器对things类别的分类能力,在things分支的PQ提高了2.2%。实例增强信息模块相较于基准网络提升了1.8%,表明该模块通过RPN中的二值标签为语义分割任务提供了更多的上下文信息识别things和stuff。同时注意到2个模块均使得PQth、PQst获得了提升,这表明联合训练中的信息交互能够为网络训练提供更多的细节信息,有效地减少了things和stuff的错误分类。实验表明,提出的网络有效地利用了多任务全景分割网络的信息间交互,通过设计语义增强信息、实例增强信息模块提高了网络各分支对things和stuff的识别能力。
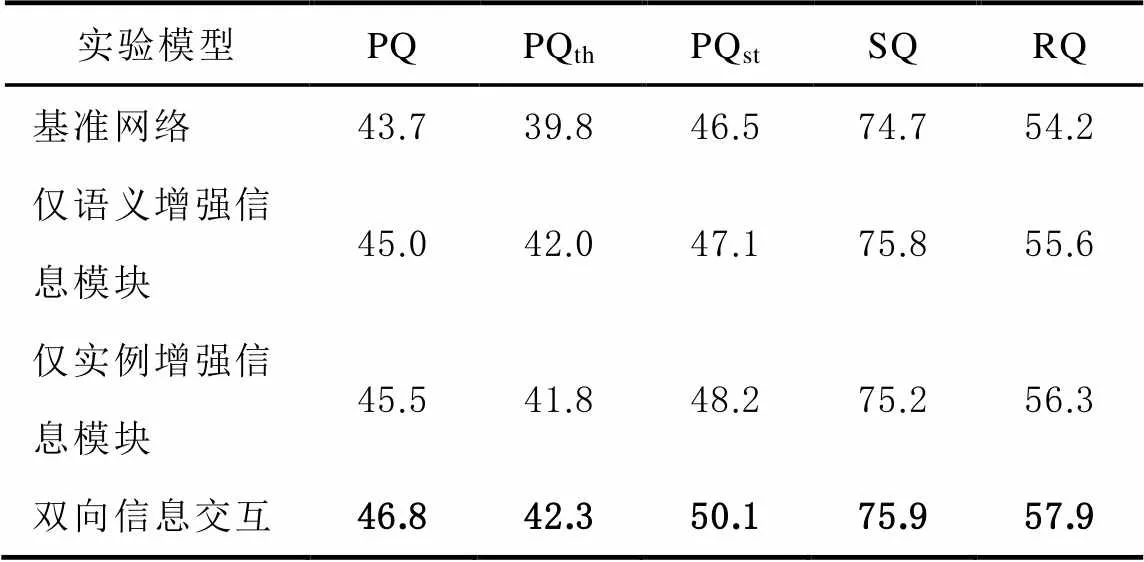
表1 不同模型在Cityscapes验证集的实验结果 %
1.3 结果分析
如图7~图9所示为在Cityscapes验证集上节选的全景分割可视化结果对照。考虑到呈现的全图结果图由于图片压缩某些目标较小不容易对比,本节在展示出全图可视化结果的同时,将图像的部分裁剪出来以便更直观地进行对比。可以看到:相比基准网络,图像1裁剪部分中,信息交互网络对交通标志、交通灯信息的分割更加细节、规则,同时检测出较小目标的自行车,表明提出的网络在things和stuff类别的信息交互上均取得了一定的效果;图像2中对栏杆的分割更好,同时行人和路面、栏杆等stuff类别的边界问题处理得更自然;图像3对汽车的边界分割更加精细,还能利用信息交互模块提供的额外信息检测出道路中的行人,这表明网络对于细节信息和相邻物体的边界问题处理得更好,噪声更小,证明提出的信息交互模块提供的额外信息能够有效地提升全景分割效果。

图7 示例图1
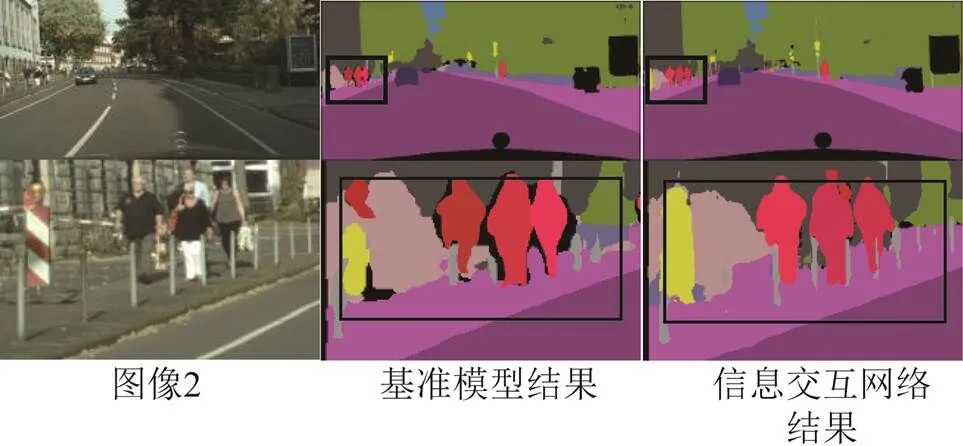
图8 示例图2
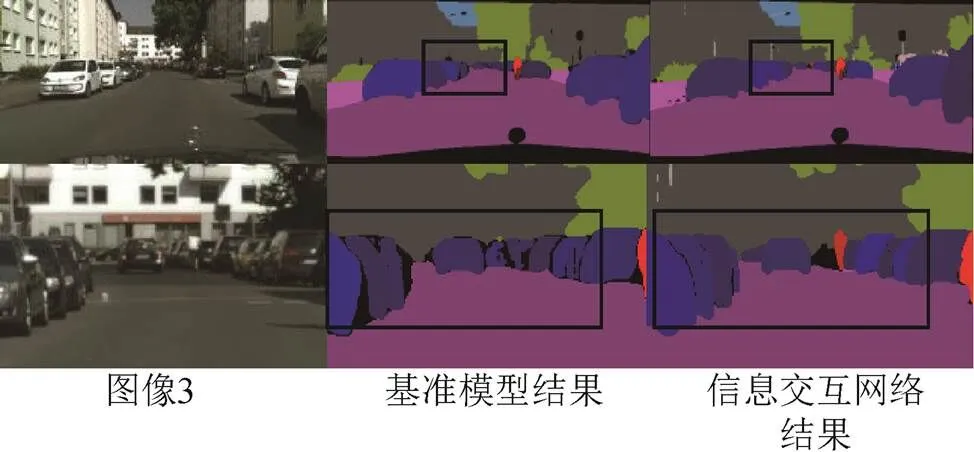
图9 示例图3
2 结束语
本文针对自动驾驶车辆全面感知环境的需求提出了一种基于信息交互的全景分割网络,网络由实例分割和语义分割2个任务组成。考虑到2个任务间进行信息交互的互补性,提出了语义增强信息、实例增强信息模块,通过RPN、语义分割结果分别为对应任务提供了物体级别和像素级别的隐式信息,能够更好地捕捉图像中的实例和语义信息。通过实验验证了提出的双向信息交互网络能够有效提高全景分割的性能,获得更精确的全景分割结果。对于多任务的全景分割网络,传递互补的信息对于各个模块通常是有益的,额外信息能帮助各任务更好地理解场景。提出的全景分割网络更加高效、鲁棒和精确,在道路场景中能够有效识别出各类信息,这些信息能够为自动驾驶提供更精确的定位、导航等功能,还可应用于事后建图、图像标注等自动驾驶相关领域。
[1] KIRILLOV A, HE K, GIRSHICK R, et al. Panoptic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 9404-9413.
[2] 徐鹏斌, 瞿安国, 王坤峰, 等. 全景分割研究综述[J]. 自动化学报, 2021, 47(3): 549-568. DOI:10.16383/j.aas.c200657.
[3] HE K, GKIOXARI G, DOLLÁR P, et al. Mask r-cnn[C]// Proceedings of the IEEE International Conference on Computer Vision. 2017: 2961-2969.
[4] ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2881-2890.
[5] DE GEUS D, MELETIS P, DUBBELMAN G. Panoptic segmentation with a joint semantic and instance segmentation network[J]. arXiv Preprint arXiv:1809.02110, 2018.
[6] KIRILLOV A, GIRSHICK R, HE K, et al. Panoptic feature pyramid networks[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 6399-6408.
[7] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 3431-3440.
[8] LI Y, CHEN X, ZHU Z, et al. Attention-guided unified network for panoptic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 7026-7035.
[9] DE GEUS D, MELETIS P, DUBBELMAN G. Single network panoptic segmentation for street scene understanding[C]// 2019 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2019: 709-715.
[10] CHEN Y, LIN G, LI S, et al. Banet:Bidirectional aggregation network with occlusion handling for panoptic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 3793-3802.
[11] LI J, RAVENTOS A, BHARGAVA A, et al. Learning to fuse things and stuff[J]. arXiv Preprint arXiv:1812.01192, 2018.
[12] ZHANG Xiaoliang, LI Hongliang, WANG Lanxiao, et al. Real-time panoptic segmentation with relationship between adjacent pixels and boundary prediction[J]. Neurocomputing, 2022, 506: 290-299.
[13] 冯兴杰, 张天泽. 基于分组卷积进行特征融合的全景分割算法[J]. 计算机应用, 2021, 41(7): 2054-2061.
[14] WU Y, ZHANG G, GAO Y, et al. Bidirectional graph reasoning network for panoptic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9080-9089.
[15] XIONG Y, LIAO R, ZHAO H, et al. Upsnet:A unified panoptic segmentation network[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 8818-8826.
[16] 雷海卫, 何方圆, 贾博慧, 等. 基于注意力机制的全景分割网络[J]. 微电子学与计算机, 2022, 39(1): 39-45. DOI:10.19304/J.ISSN1000-7180.2021.0263.
[17] LIU H, PENG C, YU C, et al. An end-to-end network for panoptic segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 6172-6181.
[18] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2117-2125.
[19] HU J, SHEN L, SUN G. Squeeze-and-Excitation networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7132-7141.
[20] CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 3213-3223.
Road scene panoptic segmentation network with two-way information interaction
LIU Bolin, HUANG Jingsong
(School of Geodesy and Geomatics, Wuhan University, Wuhan 430079, China)
In order to further study the panoptic segmentation function of road scenes, supporting for autonomous driving vehicles to fully perceive the environment, the paper proposed a panoptic segmentation network with two-way information interaction: the features were extracted through the backbone network, and input into the semantic segmentation branch and the instance segmentation branch, respectively; then, an instance enhancement information module and a semantic enhancement information module were added between the branches to enhance information interaction; finally, semantic results and instance results were fused by using an improved fusion algorithm, and the prediction results of panoramic segmentation were obtained. Experimental result showed that the proposed bidirectional information interaction module would help improve the performance of the panoptic segmentation network, and a panoptic quality (PQ) score of 46.8 could be gained on the Cityscapes dataset using 512×1024 pixel resolution images.
panoptic segmentation; autonomous driving; multi-task learning; information interaction; semantic segmentation; instance segmentation
刘博林, 黄劲松. 双向信息交互的道路场景全景分割网络[J]. 导航定位学报, 2023, 11(6): 49-56.(LIU Bolin, HUANG Jingsong. Road scene panoptic segmentation network with two-way information interaction[J]. Journal of Navigation and Positioning, 2023, 11(6):49-56.)DOI:10.16547/j.cnki.10-1096.20230607.
P228
A
2095-4999(2023)06-0049-08
2023-03-13
刘博林(1998—),男,河北唐山人,硕士研究生,研究方向为深度学习。
黄劲松(1969—),男,湖南长沙人,博士,副教授,研究方向为自主移动机器人技术。
猜你喜欢
家庭影院技术(2020年11期)2020-12-28
学生天地(2019年28期)2019-08-25
英美文学研究论丛(2018年1期)2018-08-16
数学物理学报(2018年1期)2018-03-26
家庭影院技术(2017年12期)2017-02-06
特别文摘(2016年21期)2016-12-05
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
疯狂英语·口语版(2013年1期)2013-01-31
