
注意力机制LSTM虚拟机能耗建模方法
2023-02-21 12:54李丹丹席宁丽田红珍
计算机工程与设计 2023年2期
陈 俊,李丹丹,席宁丽,田红珍
(贵州师范大学 教育学院,贵州 贵阳 550025)
0 引 言
随着云计算廉价资源池日益扩容,云计算能耗问题已成为急待解决的热点问题。而云计算以虚拟机技术为核心技术,虚拟机技术的应用使云计算拥有集中计算属性,从而实现将空置物理机置为等待状态,进而节约电能。实现虚拟机技术层面能耗优化的前提是针对云计算实现虚拟机层次的能耗测量[1],只有在测准的情况下,方可进一步分析能耗组成从而优化云计算能效。但因云计算资源池资源的分布式属性,不能采用电量仪直接获取能耗数据,又因云计算采用的虚拟机在线迁移技术会导致虚拟资源与物理资源的非一致性,从而造成云计算能耗测量精度的较大误差[2]。Hypervisor可监测虚拟机详尽的运行状态参数。因其直接针对虚拟机运行状态参数进行检测,故可用于虚拟机运行能耗测量从而避免因物理资源与虚拟资源的非一致性导致的虚拟机运行能耗测量精度下降。
近年,在能耗预测建模算法方面,相关研究热点皆指向了机器学习领域。如有支持向量机(SVM)[3]、多层感知机(MLP)[4]、K近邻[5]等。但相关研究用以测量云计算功率能耗,平均误差为21%~15%之间,误差较大,研究考虑云计算能耗数据带有时间序列属性,故更倾向于使用长短时记忆模型(long short term memory,LSTM)进行能耗建模,而注意力机制的加入能够使模型有选择性的关注数据的特征部分,以期获得较高精度的云计算功率能耗值。
本文针对计算机能耗消耗中起决定因素的计算密集型(WordCount)125个Hypervisor监测运行状态参数;I/O密集型(Sort)108个Hypervisor监测运行状态参数构建建模算法,提出了一种改进注意力机制的LSTM云计算能耗建模方法。
1 注意力机制LSTM虚拟机能耗模型设计
注意力机制LSTM虚拟机能耗模型框架如图1所示。
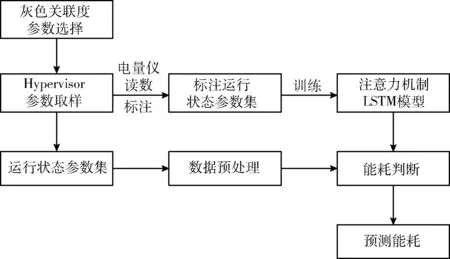
图1 注意力机制LSTM虚拟机能耗模型框架
1.1 能耗建模运行状态参数选择
虚拟机在线迁移技术存在虚拟资源与物理资源非一致性属性,故实验建模采用Hypervisor采集虚拟资源运行状态参数用以构建能耗数据。实验可采用Apriori、FP-Growth、灰色关联度分析等方法[6]对相关虚拟机资源运行状态参数与能耗数据的关联性进行分析。相比灰色关联度分析,Apriori计算量大且所需存储空间大,适用于布尔型数据处理;FP-Growth则受数据结构模型影响较大。运行任务的随机特性变化将造成虚拟机能耗波动,导致能耗数值不服从特定的概率分布,且灰色关联度分析对样本数据量要求较小,故使用灰色关联度分析效果较好。灰色关联度分析步骤见下[7]:
据序列距离测度因素变化相似性形成x0=(x0(1),x0(2),……,x0(m)) 特征序列
(1)
注:x0为参考序列,此处定义为虚拟机能耗,x1~xn为各虚拟机运行参数影响比较序列。
对参考序列与比较序列进行无量纲化处理。下一步定义灰色关联系数γ(x0(k),xi(k))

(2)
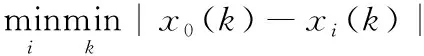
则:xi(i=1,2,……,m) 与x0的灰色关联度γi(x0,xi) 为
(3)
实验对灰色关联度取值γi≥0.6, 以此为阈值选择虚拟机运行状态参数进行能耗建模。经灰色关联度分析最终选择计算密集型125个Hypervisor监测运行状态参数;I/O密集型108个Hypervisor监测运行状态参数。
1.2 云计算能耗框架
云计算可看作由多个同构节点构成的网络计算平台,而能耗则可视为对实时功率的时间累积。此处,实验令第i节点第j个虚拟机在t时刻实时功率为Pij(t), 则定义能耗E(T) 为
(4)
式(4)中Pij(t) 为第i节点第j个虚拟机的实时功耗,在实验中可令运行的物理机节点仅运行1个虚拟机从而通过电量仪直接测量获得实时功耗数值。
式(4)中E(T) 数值的确定关键点在于Pij(t) 值的确定。因运行环境物理机众多,且每一物理机皆可运行多个虚拟机,采用电量仪直接测量方法不适于获取实际数据中心虚拟机实时功耗。Hypervisor可采集丰富的虚拟机运行状态参数数据,故研究采用Hypervisor技术进行虚拟机运行状态参数采样用以建立虚拟机实时功耗模型,从而计算虚拟机实时功耗数值。
1.3 Hypervisor虚拟机运行状态参数采样
虚拟机的运行特征带有绿色计算属性,且支持单个虚拟机划分物理机进行物理资源的独立使用,但这一方式采用的物理资源映射技术又将带来虚拟资源与物理资源的非一致性,从而造成基于物理资源运行能耗测量精度的下降。Hypervisor可监测虚拟机详尽的运行状态参数。因其直接针对虚拟机运行状态参数进行检测,故可用于虚拟机运行能耗测量从而避免因物理资源与虚拟资源的非一致性导致的虚拟机运行能耗测量精度下降[8]。
实验将虚拟机运行状态依据硬件调用特征划分为计算密集型与I/O密集型,并使用Hypervisor进行虚拟机运行状态参数采样。实验使用电量仪获取对应于Hypervisor采样的云计算平台实时功率。
Hypervisor虚拟机运行状态参数丰富,为验证相关虚拟机运行状态参数与计算机功率之间的数学关系,研究进行了实验设计,令计算机系统运行在计算密集型状态。此时,计算机系统功耗模型可看为CPU运行状态的线性回归模型[9],而除CPU外其它设备功耗可看作常数。项目组在研究CPU使用率、CPU频率与虚拟机功率之间的关系实验中,将ω设定在0、0.25、0.5、0.75、1这5个百分率上,并在Userspace模式设定CPU工作频率为1.6 GHz、1.8 GHz、2.0 GHz、2.2 GHz、2.4 GHz、2.6 GHz、2.8 GHz,实验数据如图2所示。
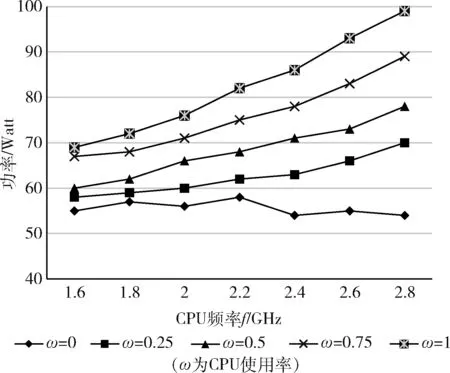
图2 CPU使用率、CPU频率与虚拟机功率关系
由图2可知,当CPU使用率为0时,功率基本保持常数值,而当CPU使用率非0时,频率越大则功率越大。其与计算机功率呈现线性相关性,故可用虚拟机运行状态参数描述计算机计算密集型时功率数值。
再令计算机系统运行在I/O密集型状态。此时,可选用硬盘读写总字节数,令为drw与内存读写总字节数,令为mdr建立数学模型[10]。
文中设定drw与mdr皆与计算机实时功率P数值密切相关。为验证硬盘读写总字节数与内存读写总字节数对计算机实时功率的数学关系,我们每间隔Δt时间(Δt取值为0.1 s)针对计算机硬盘读写总字节数与内存读写总字节数进行断点采样。为保证结果的精确性,以上采样皆基于Sort运算任务环境进行。Sort运行环境为I/O密集型运算环境,可最大限度避免CPU运行所带来的计算功率波动。我们引入式(5)
(5)
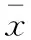
我们分别将Sort运算置为主硬盘读写方式与主内存读写方式,获取采样数据,部分数据表列见表1与表2。

表1 Sort运算节点P,drw配对取样

表2 Sort运算节点P,mdr配对取样
通过式(3),我们分别求取计算机实时功率P的相关系数,见表3。
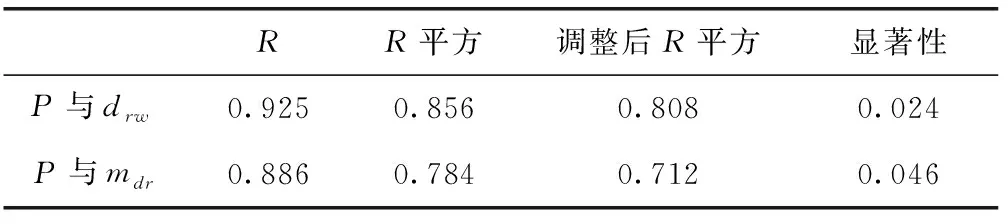
表3 变量线性关系参数分析
P与drw、P与mdr调整后相关系数为
相关系数值均在0.75相邻波动,可验证其硬盘读写总字节数与内存总字节数皆与计算机实时功率P具备线性相关性。故可用虚拟机运行状态参数描述计算机I/O密集型功率数值。
Hypervisor虚拟机运行状态参数的选择参照上文1.1节灰色关联度分析过程。实验选用Tensorflow平台,学习率定义为0.0009,学习轮次为2000次[11]。
为避免因虚拟机运行机制导致的物理资源与虚拟资源的非一致性问题,实验选择Hypervisor直接采样虚拟机运行状态参数用以能耗建模。
采样样本数据集在实验建模中被划分为互不相容的训练集、验证集与测试集,每个数据集由5000个采样数据构成。各数据按时间序列排序为x1,x2,……,xt, 并对其进行标准化处理
(6)
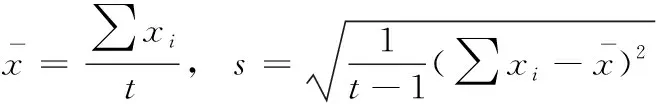
针对神经网络参数训练,实验采样时间序列的前n个能耗数据与当前Hypervisor监测运行状态参数(划分为计算密集型与I/O密集型)用以预测时间序列第n+1个能耗数据。实验中对误差的计算使用均方根误差(root mean squared error,RMSE)法作为损失函数
(7)
式中:P为前n个采样能耗数据;H为Hypervisor监测运行状态参数数据;yi与y′i分别为时间序列第n+1个测量值与计算预测值。
1.4 改进注意力机制LSTM虚拟机能耗模型
人工神经网络(ANN)包括输入层、隐藏层、输出层,其输出由当前输入数值决定,与输入时序无关。但虚拟机能耗数值是一个连续变量,数值变化与虚拟机运行状态参数之间的关系存在较强的时序性。RNN(recurrent neural network)技术可以解决序列数据问题,故RNN在处理能耗数据建模方面具备应用价值,但RNN存在对长期依赖数据处理的缺陷。对于RNN技术而言,当较长阶段能耗数据存在相互关联关系时,如何度量能耗数据间的相互影响关系变得不可实现,故单纯使用RNN建立能耗模型存在较大误差。
LSTM是RNN的变体,用于处理较长时序差序列数据。
LSTM采用门机制消除梯度消失问题[12],其作用机制原理如图3所示,其由3个控制门与1个存储单元构成。门控制数据的筛选,存储单元对数据进行保存和传递。控制门为input gate,it,forget gate,ft与output gate,ot;g,h为tanh() 的激活函数;σ为sigmoid()激活函数;zt为标准输出[13]。故,此处选择LSTM神经网络,其可反应虚拟机能耗时间序列数据的时序特征。

图3 LSTM虚拟机能耗模型架构
Tang等[14]学者对时序数据两个方向使用LSTM,后对两个LSTM的输出进行连接完成数据建模。Song等[15]学者采用LSTM中的门限神经网络对时序数据的具体物理意义及关联信息进行数据建模。这些LSTM数据建模方法都取得了较好的分类结果。但由于LSTM倾向于分析近期输入的自身特性,故仅基本的LSTM方法不能较好获取复杂时间序列数据中相对时间差数据之间的潜在关系。故引入注意力机制可望解决该问题。
注意力机制的引入可使建模过程中对重要信息给予更多关注,尽可能获取其细节信息,抑制无关信息。故,注意力机制引入可减轻计算机处理高维度数据的运算量,使其更关注输入数据与输出数据关联性更强的信息,提高输出质量。
1.4.1 注意力能耗因素编码
能耗建模为获取某一维度的能耗信息,对于注意力机制LSTM的输出权重需做出以下计算
α=softmax(Wα2tanh(Wα1HT))
(8)
式中:α∈R1×n,HT∈Rd×n为对输出矩阵的转置,Wα1∈R1×dα则为权重矩阵,dα为调整参数。
式中HT状态的计算见式(9)
(9)
为保证所有权重之和为1,需对权重做归一化处理。并可由式(10)得出能耗向量Ei
Ei=α×H
(10)
式中:Ei∈R1×d。
上式中α表示对于隐藏层单元赋予的不同能耗关系权重,该能耗向量会直接关联到相应Hypervisor监控的特殊虚拟机能耗运行状态参数,如CPU使用率、内存读写字节数、硬盘读写字节数等。
注意力机制的引入可帮助能耗模型把握能耗数据的重点信息、略去次要信息,可以将运算能力更好放置在能耗的重要组成环节,故注意力机制的加入能进一步提高建模精度并减少加入建模运算的虚拟机运行状态参数的数量从而缩短能耗模型训练时间。如,有输入维度为256,输出维度为128的LSTM神经网络,则对其3个门结构与候选值而言,权重维度为[256+128,128×4];而引入注意力机制后,其权重维度则变为[256+128,128×2]。综上,权重参数由196 608变成98 304,显著降低了参与能耗建模的虚拟机运行状态数据规模。
1.4.2 注意力机制LSTM虚拟机能耗模型实现
实验建模中激活函数选择LeakRelu函数[16],其具备较好的收敛速度。函数形式为[17]
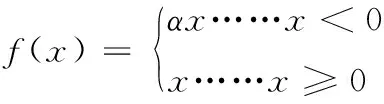
(11)
为避免模型过拟合效应,在引入惩罚项的同时进一步采用Dropout方法(随机剔除隐藏层中的某些隐藏单元)。
LSTM虚拟机能耗模型代码基于keras实现,其对虚拟机运行状态参数处理的核心代码为[18]:
From keras.lavers import LSTM
model=Sequential()
modeladdEmbeddingVirtual machine,1000))
model.add(LSTM(1000))
model.add(Dense(1,activation=‘sigmoid’))
model.compile(optimizer=‘rmsprop’,loss=’binary_crossentropy’,metrics=[‘acc’]
history=model.fit(input_train,y_train,epochs=10,batch_size=128,validation split=0.2
2 训练数据集
能耗建模需针对大量具备特征行为的训练数据对模型进行训练,为保证云计算能耗任务特征行为的完备性,实验设计选用Apache hadoop构造,选择计算密集型(WordCount)任务与I/O密集型(Sort)任务进行虚拟资源运行状态参数采样。采样每间隔Δts(Δts取值1 s)对全网进行一次电量仪功率同步采样。采样数据进行采样分组后通过了正态分布性与方差齐性检验,并以设置较大Δts的方式保证样本独立性[19]。
3 能耗模型分析
实验采样值实时功耗误差用测量功耗与计算实时功耗之差除以测量功耗度量。
实验数据针对WordCount任务与Sort任务,并以间隔采样值法呈现了200个采样点数值,如图4与图5所示。
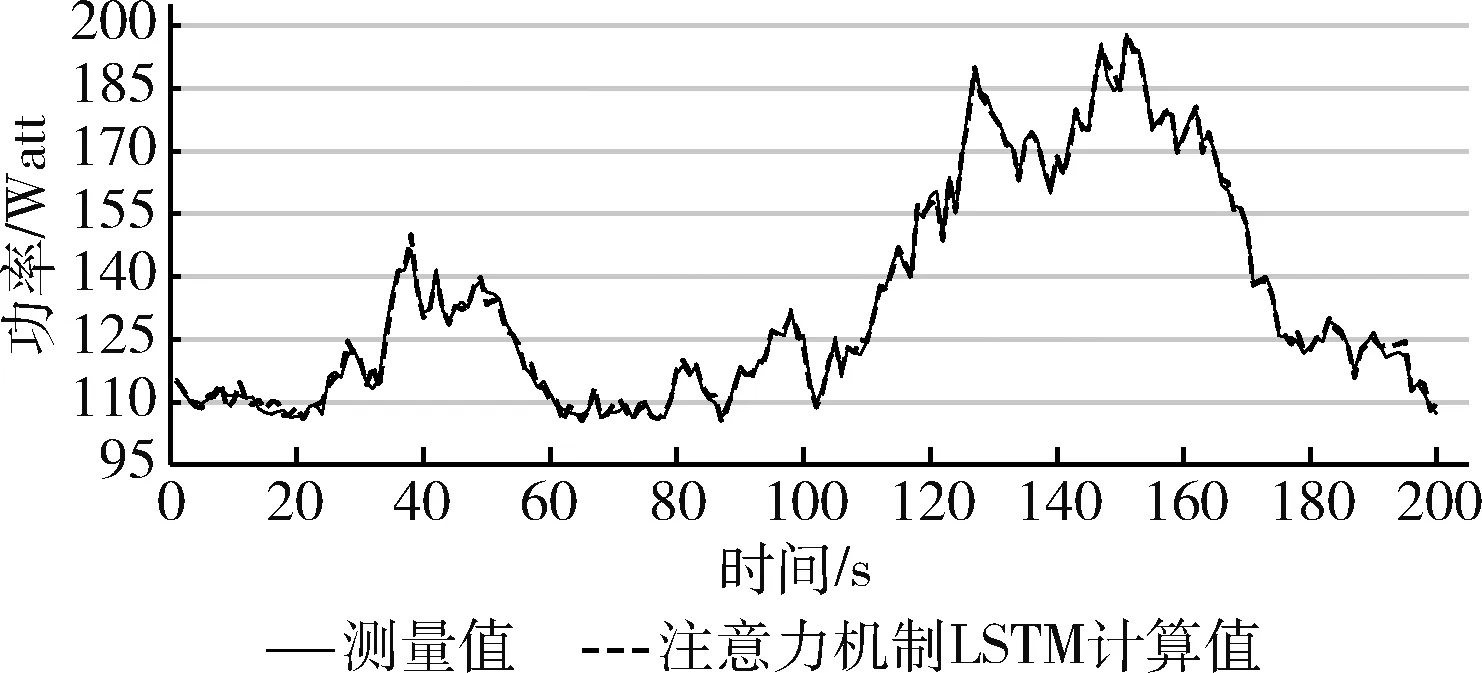
图4 WordCount 任务注意力机制LSTM计算值与测量值比较
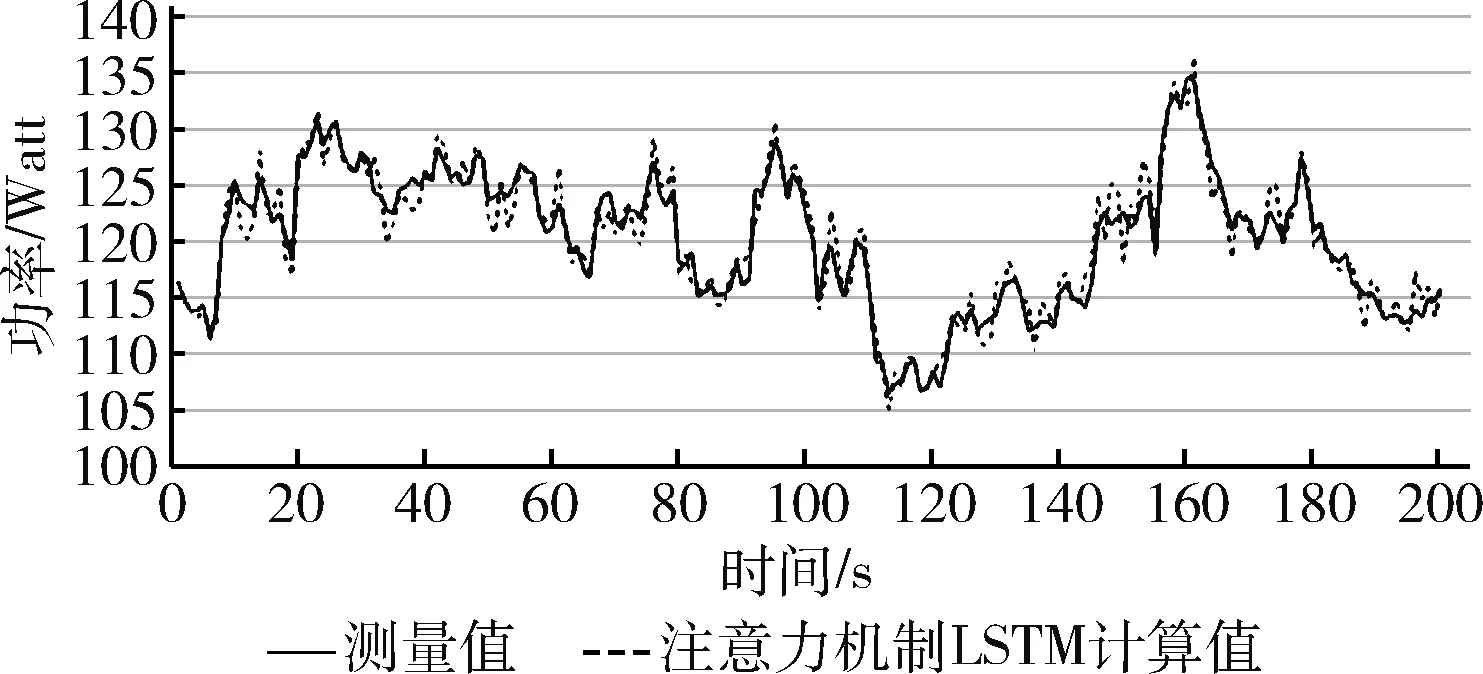
图5 Sort任务注意力机制LSTM计算值与测量值比较
实验针对多层感知机MLP(该机制算法简单,训练速度较快,但未考虑相近数据的依赖性)、支持向量机SVM(该机制算法的优点在于优秀的泛化效果,算法对数据样本量较小的数据常能取得优于其它算法的效果)、K近邻(该机制算法优点在于对训练数据集中异常值的容忍度较高,但对于高维度数据的计算容易导致维度灾难,在样本数据不平衡时容易造成较大预测偏差)及未引入注意力机制的LSTM这4种机器算法对虚拟机能耗进行了能耗预测值计算,如图6~图9所示。

图6 WordCount 任务MLP计算值与测量值比较

图7 WordCount 任务SVM计算值与测量值比较
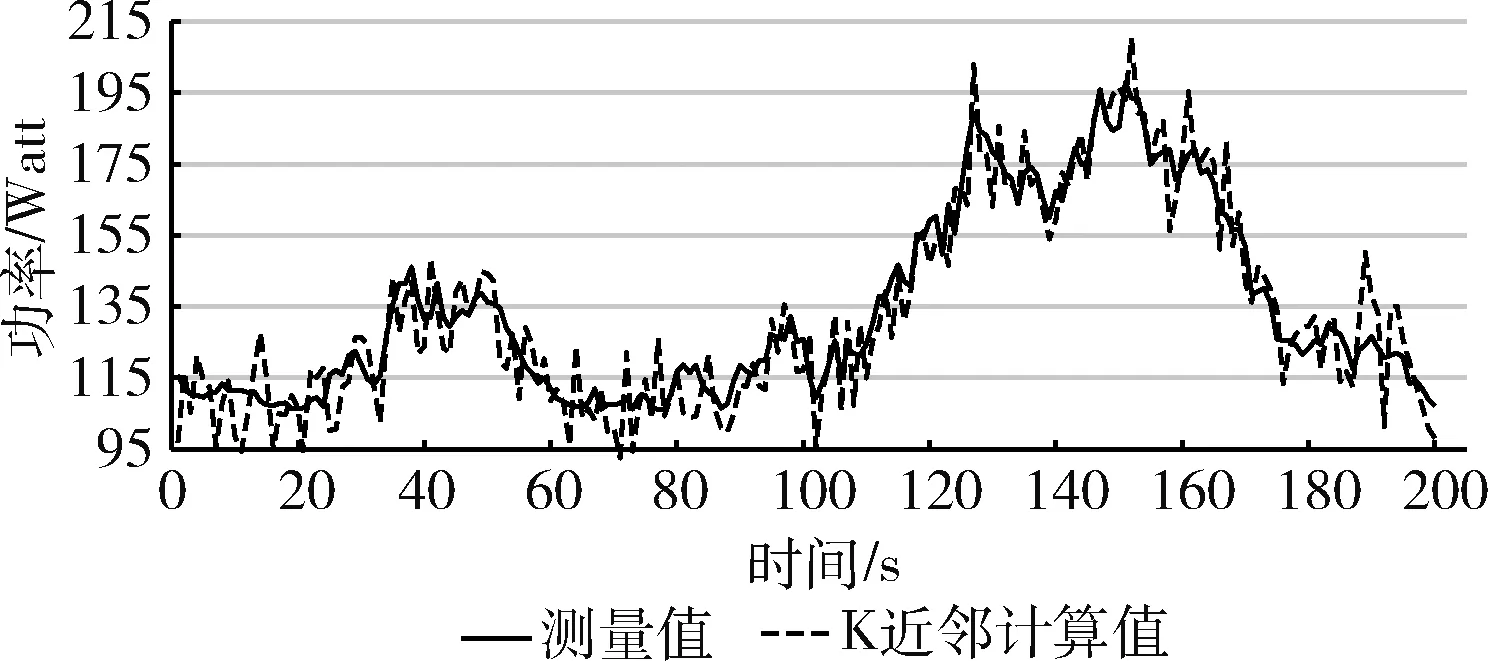
图8 WordCount 任务K近邻计算值与测量值比较
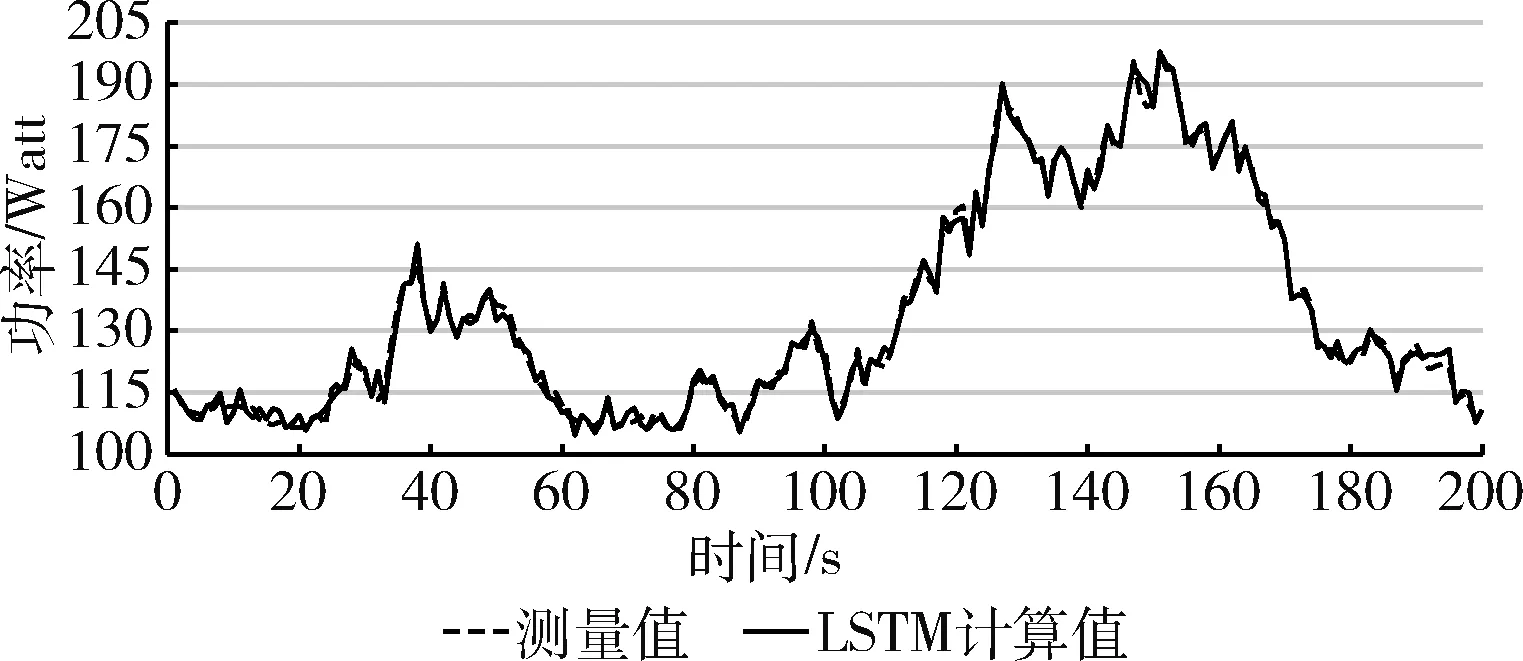
图9 WordCount 任务LSTM计算值与测量值比较
图6、图7与图8可知,在WordCount任务下MLP、SVM与K近邻算法计算值与测量值存在明显误差,而使用LSTM算法后WordCount任务的计算值与测量值误差明显变小。在图4中则显示误差进一步减小,表4数据验证了这一现象。
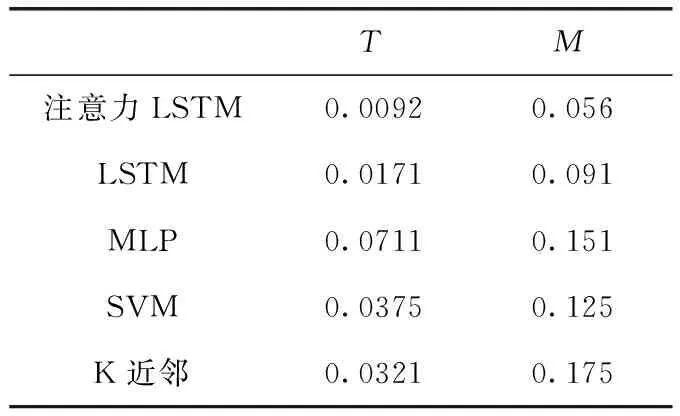
表4 虚拟机能耗误差比
实验使用不相等系数T与平均绝对误差M判别能耗模型质量。不相等系数T用以判别计算值与测量值的区间差异;绝对误差M则可用于衡量计算值与测量值对比测量值的比例
(12)
[0,1]间取值,T为0表示完全拟合,T为1则完全不拟合
(13)
实验结果见表4。
表4数据结果显示,用LSTM进行能耗建模质量优于MLP、SVM及K近邻算法。其原因为浅层机器学习算法易形成过拟合,且无法获取能耗数据的时序特征。而引入注意力机制的LSTM能耗模型优于单纯LSTM能耗模型,则是因其凸显了相对时间距离较远的关键因素间能耗相关性,从而提升了能耗模型精度。
4 结束语
研究提出了一种注意力机制的LSTM循环神经网络建立虚拟机能耗模型的方法。方法以虚拟机为粒度,使用灰色关联度分析选择Hypervisor监控的虚拟机运行状态参数,并引入了注意力机制进行LSTM虚拟机能耗建模,注意力机制的引入有助于获取时间间隔序列较远的关键因素的能耗相关性,从而获得更好的建模精度。实验数据显示,引入注意力机制的LSTM能耗模型质量优于LSTM,且两者建模质量皆高于MLP、SVM以及K近邻算法。
猜你喜欢
南京工程学院学报(自然科学版)(2022年2期)2022-08-16
土木建筑与环境工程(2022年4期)2022-05-14
小雪花·成长指南(2022年1期)2022-04-09
农业工程(2021年6期)2021-07-29
中国民间疗法(2021年1期)2021-04-20
山东冶金(2019年3期)2019-07-10
酒·饮料技术装备(2018年1期)2018-04-28
实验流体力学(2018年6期)2018-02-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
