
高分遥感影像云雪共存区轻量云高精度检测方法
2023-02-18 01:12张广斌高贤君冉树浩杨元维李丽珊
测绘学报 2023年1期
张广斌,高贤君,2,冉树浩,杨元维,3,4,李丽珊,张 妍
1. 长江大学地球科学学院,湖北 武汉 430100; 2. 自然资源部环鄱阳湖区域矿山环境监测与治理重点实验室,江西 南昌 330013; 3. 湖南科技大学测绘遥感信息工程湖南省重点实验室, 湖南 湘潭 411201; 4. 城市空间信息工程北京市重点实验室, 北京 100045
遥感卫星通过长时间对地观测记录表征地表信息,对农业、气象、人文及环境等研究具有重要意义[1]。然而,年均约66%的地表会被云层覆盖[2],云会模糊甚至遮挡地面目标,严重限制光学卫星影像的利用[3]。因此,在多数遥感影像的处理中,精确的云检测工作是不可或缺的。然而,在高海拔、高纬度地区或是冬季的云检测任务中,下垫面中具有相似反射特征和局部纹理的雪将会成为主要噪声源干扰云检测结果[4]。这使得在云雪共存区域开展高效且精确的云检测工作具有重要的研究价值。
多年来,研究者已经提出了多种云检测的方法,可大致分为基于规则的方法以及基于统计的方法。首先,基于规则的算法常利用红外波段与其他光谱波段的派生值捕获云与其他地物的电磁波反射或辐射特性差异,进而结合恒定的或者自适应的阈值进行云与背景像素的区分,如ACCA[5]、Fmask[6]及改进的LCCD算法[7]。但是此类方法仅考虑了低层次的光谱与空间特征,并且,它们都过于依赖红外波段,缺乏面向不同传感器的泛化能力[8]。这使得基于规则的云检测方法泛化能力较弱,应用限制性较强。其次,基于统计的方法对云的光谱、纹理、轮廓等更高层次的特征进行提取利用,进而实现自动云检测,如支持向量机[9]、随机森林[10]与神经网络[11]。由于这些分类器的性能与可训练参数有限,在复杂的任务中其精度受到限制[12]。
近年来,基于统计的深度学习方法获得了巨大的发展,其准确性、泛化能力及推理速度均得到进一步提升[13]。目前,基于深度学习的云检测工作获得了丰硕成果,主要从注重快速响应能力或提高精度两方面开展。在追求快速推理方面,轻量级的RS-Net[13]与Cloud-U-Net[8]基于U-Net[14]架构进行了特征图的深度减半处理,在确保云检测精确性的同时,减少了大量神经网络参数量与内存占用量,从而实现了对遥感影像云掩膜的快速输出。RS-Net在Landsat-8全波段产品上的平均处理时间提升到了18 s左右。同时,Cloud-U-Net的预测时间减少为Fmask方法的1/60。在提高模型性能方面主要是通过改变网络主干结构或载入先进组件的方式,以提高云检测精度。例如,MSCFF[15]将网络解码部分上的多级特征图进行融合输出,该机制促进了多层级语义信息的聚合,从而在多种数据集上均显示出了良好的精度。CDnetV2[16]向网络内部添加了自适应特征融合模块与高级语义信息引导模块,分别为网络赋予了有效的特征鉴别提取能力以及面向高级语义信息的空间位置信息补充能力,使得该网络在云雪共存缩略图中获得了极佳的云检测精度。
尽管上述方法显著提高了云检测的效率和精度,但仍存在着一些亟须解决的问题。首先,现存方法多是基于中低分辨率的遥感数据集设计并验证的。然而,近几年高分辨率卫星影像获得广泛的发展,针对高分辨率遥感影像的云检测需求激增,基于中低分辨率的云检测数据集无法满足高分辨率遥感影像的高精度云检测需求。其次,目前的云检测方法均未详细探讨在高分辨率云雪共存场景中开展云检测任务的适用性。再者,常用的云检测模型难以平衡效率与精度提升两方面,如RS-Net和Cloud-U-Net过于强调执行效率,在准确性方面仍有欠缺[16]。优先考虑精度的网络,却具有大量的参数量与运算量,导致计算成本急剧增加、运行速度降低。因此,本文创建了一套基于WorldView2影像的高分辨率云雪共存区云检测数据集,同时,提出了一种基于双重自适应特征融合及可控深层梯度指导流的参数可重构多尺度特征融合网络,用于高分辨率以及云雪共存的场景中的云检测,该网络既能保证精度最优又注重可轻量化部署。
1 方 法
1.1 高精度轻量级云检测网络RDC-Net
本文提出一种云检测网络RDC-Net(图1),其整体构成如下:首先,具有并行通道的可重构多尺度特征融合模块(Re-MFF)贯穿网络的编解码部分,驱动整个网络的运行。该模块在训练阶段能够捕获与聚合网络中不同层级的多尺度云特征,并且在测试应用阶段能够进行无损重构与轻量化部署。其次,双重自适应特征融合结构(DAFF)部署于等效特征图的跳层连接之后,可对输入特征进行自适应地强调或者抑制信息,从而动态地改善特征的可用性,促进有效信息在网络中的传播流动。最后,可控深层梯度指导流(CDGGF)分布在解码部分,有利于融合解码部分中相邻层级的可用特征,并对网络内部的梯度流进行无偏指导。
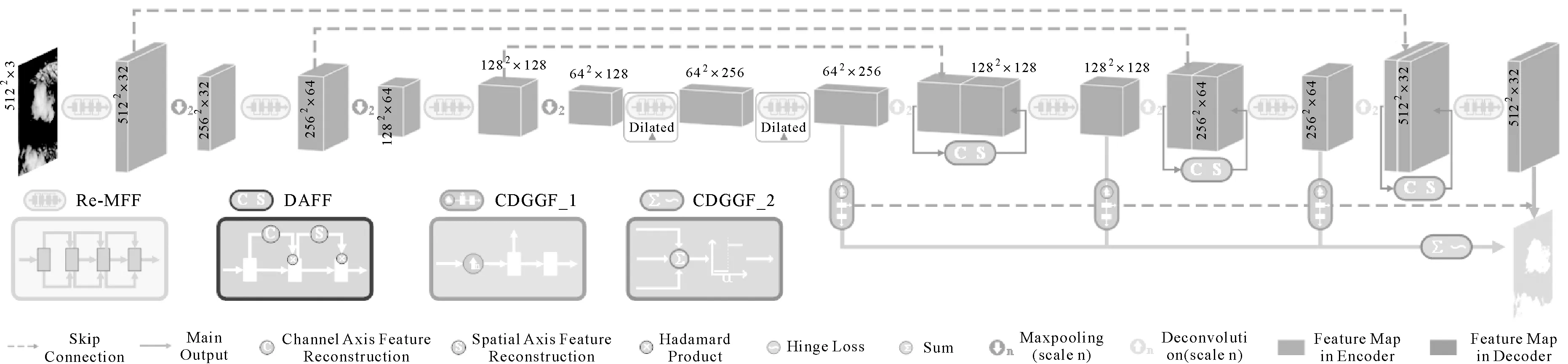
图1 RDC-Net网络模型结构Fig.1 The architecture of RDC-Net
1.2 可重构多尺度特征融合模块
多分支拓扑结构能够有效地提升网络的表征能力[17-19],应用于云检测任务中,有利于多尺度特征的聚合,以提升网络对云与雪等易混淆地物的判别度[20],进而提高云检测精度。但是,复杂的多分支拓扑结构为网络带来了大量的参数量、计算量与访存量,延迟了网络的推理速度。因此,基于结构重参数化技术[21],本文设计了全新的可重构多尺度特征融合模块(reconstructible multiscale feature fusion module,Re-MFF),将网络的训练与推理过程解耦,以保证网络不仅在训练阶段具有良好特征捕获能力,而且在部署阶段具有极佳的推理速度,以更好地达到精度与速度的平衡。
Re-MFF模块在训练阶段的具体结构如图2(a)所示。该模块由3个多通道单元及相应的线性激活层(ReLU)构成。多通道单元中具有不同体系的映射通道将浅层特征表征于更深层,以使网络获得更为丰富的特征空间。此外,值得注意的是,为进一步加大网络中卷积核的感受野,RDC-Net中的两个Re-MFF(图1中框体处)做了细微调整。具体而言,这两处Re-MFF中所有的3×3卷积通道(可见图2(a)中的三角标注处)分别被更换为具有d1和d2膨胀率的3×3空洞卷积通道。
在对Re-MFF进行无损重构的过程中,多通道单元中的各个通道分支将会首先聚合为一个卷积层,其过程如算法1中FuseBranch函数所示。该函数中,k和d分别代指重构前卷积核的卷积尺寸与膨胀率,ω和b分别为该卷积核的权重向量与偏移向量,μ、σ、γ、β和eps分别为卷积层后标准归一化层中的累计平均值、标准偏差、学习权重、学习偏差及稳定动量,C1与C2分别为输入与输出特征图的通道数。计算所得的W与B分别为通道分支重构为单个卷积后的权重向量与偏移向量。各个通道分支转换为单个卷积之后,进一步将多通道单元构置为单一卷积核。具体的操作流程如算法1中FuseUnit函数所示,其中Ψ与Φ分别代表着重构后的卷积核权重向量与偏置向量。将所得到的Ψ与Φ分别加载于图2(b)中对应的卷积中便完成了对多尺度特征融合模块的无损重构。

图2 Re-MFF的重构过程Fig.2 Reconstruction process in Re-MFF model
根据以上描述以及算法1中的FuseUnit函数可知,Re-MFF中具有膨胀率d的多通道单元在无损重构后将会获得具有同样大小膨胀率d的单个卷积核。因此,RDC-Net中不同位置的Re-MFF虽有一些细节差异,但这并不影响重构过程。
Algorithm 1:The implementation of reconstruction for Re-MFF
Input:M-Unit Multi-channel unit in Re-MFF
Output:S-Unit Single channel unit reconstructed by multi-channel
function FuseUnit(M-Unit)
Ψ,Φ,k,d=0,0,0,0
for Branch in M-Unit do
Ψ+=FuseBranch(Branch)[0]
Φ+=FuseBranch(Branch)[1]
end for
k,d=GetKD(M-Unit)
S-Unit=torch.nn.Conv2d(C1,C2,k,d))
S-Unit.weight,S-Unit.bias=Ψ,Φ
return S-Unit
end function
function FuseBranch(Branch)
if Branch hasattr convbn then
k,d=Branch.conv.kernelsize,Branch.conv.dilation
ω,b=Branch.conv.weight,Branch.conv.bias
μ,ν,eps=Branch.bn.mean,Branch.bn.var,Branch.bn.eps
γ,β=Branch.bn.weight,Branch.bn.bias
W,B=t*ω,beta+b-mean*gamma/std
ifk==1 then
W=PadTensor(W)
end if
returnW,B
else if Branch hasattr identity then
W,B=zeros(C2,C1,3,3),0
foriinC2do
W[i,i%C1,1,1]=1
end for
returnW,B
end if
end function
function PadWeight(Weight)
Weight=torch.nn.functional.pad(Weight,[1,1,1,1])
return Weight
end function
function GetKD(M-Unit)
k,d=0,0
for Branch in M-Unit do
ifk k=Branch.conv.kernelsize end if ifd d=Branch.conv.dilation end if end for returnk,d end function 在卷积神经网络中,通常使用特征元素求和或是串联的方式来融合多层次/多尺度的特征[14,17,19,22],以提升网络的特征表征能力。但是该操作所得的特征图中所蕴含的特征信息量大且冗余度较高,后续的映射变换操作中难以对有效信息进行高效利用。受混合域空间注意力[23-24]的启发,本文提出了轻量级的双重自适应特征融合模块(dual adaptive feature fusion module,DAFF)并运用于RDC-Net的跳层连接结构中。当网络的底层空间信息与抽象的高级语义信息进行融合后,DAFF能够基于特征图的空间域与通道域进行重要特征的筛选,以促进网络对重要特征的关注,并抑制贡献较小的冗余特征。 网络中浅层的等效特征图在与深层特征图建立跳层连接关系后,DAFF则会对其邻域空间上特征间的相互依赖性进行显式的建模,来自适应地重新校准特征质量。如图3所示,这一处理过程包括如下两个步骤: 图3 双重自适应特征融合结构Fig.3 The architecture of dual adaptive feature fusion model 首先,给定的输入特征图F∈RH×W×C将会首先沿着通道轴进行特征表示的重建,具体过程可表示为 Fc=σ(Conv(kc,dc)⊙AvgPool(F))⊗F (1) 式中,Conv(k,d)指代核为k、膨胀率为d的卷积核;⊙代表着卷积核与特征图的滤波响应;⊗为哈达玛积;σ是Sigmoid函数。 其次,所得的通道特征重建图Fc∈RH×W×C将会再次沿着空间轴进行特征表示的重建,见式(2),最终获得空间特征重建图Fs∈RH×W×C Fs=σ(Conv(ks,ds)⊙cat(AvgPool(Fc),MaxPool(Fc)))⊗Fc (2) 标准的卷积神经网络仅在输出层提供监督反馈,其中间层在训练过程中很难直接、透明地面向目标特征进行学习,并且随着网络深度的增加,梯度消失或爆炸的可能性会大大增加。因此,RDC-Net在解码层添加了可控深层梯度指导流(CDGGF)作为网络训练的附加约束,使隐藏层参数的更新更具梯度动量,从而加快收敛速度并提升网络特征表征能力。 图4 深层梯度指导流模块结构Fig.4 The structure of deep gradient guided flow module (3) (4) 式中,Zm是第m层滤波器核函数与前层特征图的滤波响应;σ指代Sigmoid激活函数;h、w分别代表输入影像的高和宽;L为损失函数计算所得损失值。 在CDGGF的反卷积处理过程中,大尺度的上采样与维度压缩会导致精细信息的损失。由于CDGGF能够直接连接到目标特征,并被用作特征学习质量的反馈,这会为前层参数的更新带来误差,并最终影响网络的学习能力。因此,CDGGF采取了一系列策略来抑制这种情况所产生的负面影响。 一方面,如式(5)所定义,不同的权重系数ωl被加权到与不同层级特征图耦合的CDGGF中,可以权衡不同分支路径中梯度流的重要性,以便抑制具有误差性的反向传播 (5) 另一方面,改进的铰链损失(hinge loss)被应用于CDGGF,即如果所有分支中交叉熵函数所得损失之和小于阈值α,则梯度下降算法将忽略这些值,如式(6)所示 (6) 这一机制可以防止在训练后期网络梯度趋于稳定时,低分辨率的特征图过于直接从目标特征中学习而增加了学习错误信号的可能性,将不确定性引入网络。 目前遥感影像中云检测的研究工作已经取得显著进展,且一系列的云检测数据集被创建并公开[11,15,25-26]。现存的云检测数据集多为中低分辨率,并无开源的专门面向于云雪共存区域的云检测数据集。 因此笔者创建了一套具有高分辨率的开源云检测数据集,数据集中包含了37幅视场内可以同时观测到云区与雪区的影像。同时为保证场景的多样性,数据集中的影像采集于2014—2018年的不同时段,且分布于欧洲、亚洲及北美洲的不同位置区,以使得场景中包括不同季节的高原、山区、城市及水域等下垫面信息。 对该数据集进行手动标识云区的操作是在Adobe Photoshop及ENVI中使用相应的绘制功能来进行的。此构建过程存在着两方面的问题,一方面,高分辨率遥感影像中云的形态多样性与边界模糊性被放大,浅薄云与冰雪等高亮下垫面具有相似的光谱反射率和局部纹理特征,因此在影像中难以定性地对每个像素进行精准的云标识。另一方面,分析师的主观判定差异会导致制作标签的平均误差达到7%[27]。因此,为了保证样本数据的精准性与一致性,在整个处理过程中只采用一种云像素解释判定标准,即只要云像素在视觉上能够分辨,或者说判定该像素与云的相似度为50%及以上,其就会被标识为云,如图5(a)所示。这一标准同样适用于在雪上空的云像素,如图5(b)所示。此外,人工标记云标签的过程仅由两位经过统一指导培训的分析师执行,其中一位分析师进行云像素的标记,另一位分析师则负责对标记工作进行检查,从而确保标注工作质量达到最佳。 图5 CloudS数据集中原始影像与云标签的对比Fig.5 The comparison of original images and cloud label in the CloudS dataset 总的来说,在整个数据集的制作过程中,由于能够严格按照云判定标准执行,并且进行合理的工作分配,因而能够进一步确保该数据集的云标注质量。 为了评估不同的方法在亚米级和米级高分辨率遥感影像上的稳健性,该数据集被进一步划分。37幅场景中有13幅0.5 m的分辨率影像,并将其命名为亚米级分辨率云检测数据集(CloudS_Y13)。通过对其余24个场景的原始影像进行下采样操作,使其分辨率保持在5 m左右,从而构建了一个米级分辨率云检测数据集(CloudS_M24)。图6给出了CloudS_M24和CloudS_Y13的标注示例。此外,有关两个数据集的详细对比信息见表1。由于原始影像中云雪共存区域的可见面积不定,因此每幅影像的尺寸也是不定的。值得注意的是,该数据集已在https:∥github.com/zhanggb1997/RDC-CloudS上公开,以帮助其他研究人员进行相关研究。 表1 数据集详细信息对比Tab.1 Comparison of dataset details 图6 CloudS_M24与CloudS_Y13中的部分标注示例Fig.6 Some annotation samples from CloudS_M24 and CloudS_Y13 本文试验分别基于CloudS_M24与CloudS_Y13数据集开展,以评估云检测方法在米级和亚米级分辨率遥感影像上的稳健性。在对CloudS_M24与CloudS_Y13中原始数据进行处理时,CloudS_M24数据集中的6幅影像被分配到测试子集中,其余的18幅影像被归纳为训练与验证子集。在CloudS_Y13数据集中,其中的3幅影像被归纳到了测试子集中,其余的10幅影作为训练与验证子集。在原始数据的分配完成后,两个数据集中所有的场景均会被512像素大小的裁剪步幅切割为5122像素尺寸的无重叠图像块。然后,训练与验证子集中所获得的裁剪图像块将会按照一定的比例划分到训练子集与验证子集中去。由于两个数据集图像块数量差距明显,划分过程中未规定各数据子集的固定占比,其中较小的CloudS_M24数据集为了避免模型预测结果的偶然性,其验证子集与测试子集的数量占比要更高一些。最后,所有的图像块被划分为训练集、验证集和测试集3个数据子集,用于卷积神经网络的学习调优、无偏评估以及最终评价。值得注意的是,在数据集的划分过程中,每个子集合都严格保证数据的独立性与随机性。表2给出了详细的数据集划分信息。 表2 不同数据集的训练细节Tab.2 The training details in different datasets 本文所有试验均运行于64位Windows10操作系统的计算机上,该设备配有AMDRyzen5 5600X 6-Core Processor处理器,具有24 GB显存的NVIDIA GeForce RTX 3090 GPU。基于以上配置,进一步搭建了Python3.8+Pytorch1.8.0+CUDA11.1深度学习环境。训练过程中采用Adam优化算法进行梯度下降,选择交叉熵函数作为损失函数,学习率设置为0.000 1,迭代次数分别设置为100和50,每次迭代的批量数为8。 本文中选用了广泛运用于图像语义分割领域的U-Net[14],以及适用于云检测任务的RS-Net[13]、CloudSegNet[12]和CDnetV2[16],总共4种具有代表性的方法与本文方法,基于上述数据集进行对比试验。将试验结果与真值进行像素级的差异性与一致性评估,选用交并比(IoU)、综合分数(F1score)、精确率(OA)、查准率(Precision)和查全率(Recall)作为评价指标。同时,综合运用浮点运算数及参数量对网络的复杂度进行定量评估。 图7显示了不同方法基于CloudS_M24数据集的云检测结果。其中U-Net,CloudSegNet和CDnetV2极易将裸露的浅色地表识别为薄云。同时,位于厚云边缘的一些不连续的稀薄云被这两种方法所遗漏。此外,这3种方法在高亮的积雪区域产生了大量的云漏检与误检现象。RS-Net尽量顾及场景中的薄云,且对雪域上空的云具有一定的稳健提取能力,但是其在云边界细节处理中比较粗糙,与标签中的真实云掩膜仍存在较大出入。RDC-Net能较好地保留薄云细节信息,检测到雪上空的云,同时能够防止裸露地面及浅色地物的影响。 图7 多种深度学习方法基于CloudS_M24数据集的云检测结果可视化对比Fig.7 On the CloudS_M24 dataset, the visual comparison of cloud detection results for several deep learning methods 表3展示了基于CloudS_M24数据集的各种云检测方法的定量评估值:RDC-Net获得了最高的IoU、F1score、OA和Precision值,在IoU与F1score两个关键性指标上分别得分82.71%和90.54%,相对于次优的RS-Net分别高1.22%与0.74%。其他方法精度评估值较低,不适用于精确云检测。 表3 CloudS_M24中不同方法的云检测结果定量比较Tab.3 The quantitative comparisons of cloud detection results using various methods on the CloudS_M24 dataset (%) 图8为基于CloudS_Y13数据集的试验结果:参与试验的所有方法的检测结果在云边缘上没有很大的误差,然而,在云层内部与明亮地表区域可以发现更为明显的问题。U-Net、RS-Net与CloudSegNet在云内部极易出现漏检。此外,所有的对比方法均容易将阴影覆盖的雪地、浅色的裸露土地以及高亮的建筑物顶部误判为云。相比之下,RDC-Net能够避免易混淆地物的干扰,得到几乎无噪声点的检测结果。 图8 多种深度学习方法基于CloudS_Y13数据集的云检测结果可视化对比Fig.8 On the CloudS_Y13 dataset, the visual comparison of cloud detection results for several deep learning methods 基于CloudS_Y13的定量评价结果见表4,具有最佳可视化结果的RDC-Net精度评估值具有明显优势。该方法的IoU和F1score分别为86.94%和93.02%,这要比次优的CDnetV2相关指标分别要高出3.74%及2.2%。U-Net在多项评估指标上均为最低值,其IoU与F1score值分别仅为81.12%和89.57%。其他几种参与试验的对比方法的定量评估值则相对于U-Net要好一些,但要远低于RDC-Net。 表4 CloudS_Y13数据集中不同方法的云检测结果定量比较Tab.4 The quantitative comparisons of cloud detection results using various methods on the CloudS_Y13 dataset (%) RDC-Net在参与试验的两个子数据集中均能够获得极佳检测结果的主要原因是:首先,RDC-Net中的Re-MFF不断收集和融合来自不同特征域的多尺度特征,以加强不同尺度的特征间的相关性。这有利于对非局部性的空间和光谱特征差异进行学习,以此达到对具有相似性特征的云雪对象以及背景地物的高精度辨别。其次,DAFF将更有效的低级空间和光谱特征传播到网络的深处,以补偿最大池化和卷积过程中的特征丢失问题。再者,CDGGF聚合来自解码器中不同层级的特征映射,并且使得网络内部特征直面目标特征进行拟合,以获得最优收敛。该结构有助于捕获保留更为精细的云特征,并且减少低级错误分类。 此外,CloudS_M24数据集的分辨率较低且样本量少,其中云与其他相似地物的空间和光谱特征区分度较低,这使得参与试验的对比方法难以从有限的训练样本中学习具有良好区分性的特征。而轻量级的RDC-Net具有有限数量的参数,有助于针对小样本数据集进行无偏学习以防止过拟合问题的产生。在CloudS_Y13中,随着空间分辨率的增加,小尺寸图像块可表达传输的信息量减少。对于网络来说,从具有有限信息的图像块中捕获区分特征更加困难。而RDC-Net中具有膨胀率的Re-MFF与DAFF使网络的感受野大大扩展,有助于网络在高分辨率图像中接收有关大尺度对象的更完整信息。 除了精度的硬性要求外,遥感影像的处理时长同样为云检测应用中的重要指标,且这一指标在应急响应中更为突出[27-28]。以往的云检测工作中,多数方法都强调了在原始场景中瞬时推理并快速获取云掩膜的重要性[8,13]。因此在相同试验环境下,以CloudS_M24与CloudS_Y13中的测试集作为数据基准,进一步对所有参与试验的方法的效率进行评估。评估过程中将模型的前向推理时长、浮点运算次数以及参数量作为评价标准进行比较,详细的评估结果见表5。 表5 不同方法的推理时长、浮点运算数量和参数量Tab.5 The value of reasoning time, floating point operations and the number of parameters for various methods 由表5可知,RDC-Net具有最少的参数量以及极低的浮点计算量,其参数量与浮点计算量分别为585万与66.63GFlops,这是由于RDC-Net限制了整个网络以及网络中特征图的深度。由于Re-MFF结构中的并行卷积通道大量增加了网络的访存量与计算量,这使得其前向推理时间在参与试验的几种方法中最长。重构部署后的RDC-Net将网络的参数量与浮点计算量分别缩减至534万与59.75GFlops,这要远低于CDnetV2、U-Net与CloudSegNet。与此同时,在CloudS_M24与CloudS_Y13测试集中的前向推理时长也分别减少到0.89、22.68 s,远低于U-Net与CloudSegNet。 参与试验的其他几种方法中,CDnetV2为了提取密集的高层语义信息,具有大量的残差单元和特征融合模块,从而导致CDnetV2的参数数量是RDC-Ne的十余倍。U-Net与CloudSegNet具有许多深且高分辨率的特征图,导致其在参数量与浮点计算量上均较高。与重构后的RDC-Net相比,U-Net与CloudSegNet的浮点计算量几乎是RDC-Net的4倍,参数数量分别是RDC-Net网络的6倍与8倍。 多数方法的浮点运算数量和参数量远远超过RDC-Net网络,因此,RDC-Net网络在轻量化部署应用方面具有显著的优势。 RDC-Net面向于不同数据集时,网络中的关键参数需要展开进一步的讨论分析,如具有空洞卷积的Re-MFF的膨胀率、DAFF的卷积核尺寸与膨胀率、CDGGF的铰链损失阈值以及CDGGF中不同分支路径的权重系数。 图9所列结果显示,具有空洞卷积的Re-MFF为网络带来了精度提升。而在不同分辨率的数据集中,空洞卷积的膨胀率需要进一步微调,以实现精度最优。在CloudS_Y13为基准的试验中,具有较大膨胀率的网络在检测精度上获得了进一步的提升。但在CloudS_M24数据集中这一数值应相应缩小,才能保证更为精确的检测结果。图10同样显示出,DAFF沿着空间轴方向上进行特征重建的卷积核尺寸与膨胀率也应做出适当的调整,即在CloudS_Y13数据集中适当调大这些参数。原因是地表对象在影像中所表现出的空间尺度会随着影像空间分辨率的改变而不同,在CloudS_Y13中云对象会大比例填充甚至占满整个图像块,而在CloudS_M24中这种情况很少见。具有较大膨胀比率的网络能够进一步扩大感受野,这对面相于大目标的分割任务极为有利。因此,结合试验结果,RDC-Net中两个空洞卷积Re-MFF的膨胀率(d1,d2)分别设定为(1,2)与(2,4),以面向于CloudS_M24与CloudS_Y13数据集进行云检测。同时选择(7,1)与(7,2)分别作为CloudS_M24与CloudS_Y13数据集中DAFF在空间轴方向上的卷积核尺寸ks与膨胀率ds。 图9 具有不同膨胀率的Re-MFF测试精度对比Fig.9 Test accuracy of Re-MFF with different dilated rates 图10 在空间轴方向上具有不同尺寸卷积核与膨胀率的DAFF测试精度对比Fig.10 Test accuracy of DAFF in the direction of spatial axis with different kernel sizes and dilated rates 本文对CDGGF中的铰链损失阈值同样进行了一系列微调和比较(图11):显示当考虑铰链损失时,该方法的精度得到了提高。但是,当α高度倾斜时,网络的性能会受到影响。根据试验结果,基于CloudS_M24与CloudS_Y13的铰链损失阈值分别被确定为0.024和0.009。 图11 具有不同铰链损失阈值α的CDGGF测试精度对比Fig.11 Test accuracy of CDGGF with different hinge losses 此外,RDC-Net中CDGGF的不同分支路径分别赋予了不同的权重系数ωl,并进行了单独的训练与测试,其相应的评估结果如图12所示。当各分支路径的权重系数ωl近于相等时,网络精度较低。而当主输出路径权重系数较高,其他输出路径的权重系数逐渐降低时,网络的精度则呈逐步上升的趋势,并且在ω0、ω3、ω2、ω1分别为0.50、0.25、0.15、0.10时,达到最佳检测精度。因此,分别将0.50、0.25、0.15、0.10设定为CDGGF中主输出路径以及其他各层级分支路径中的损失函数权重系数。 图12 具有不同权重系数ωl的CDGGF测试精度对比Fig.12 Test accuracy of CDGGF with different weights 多种创新性技术组件构成了兼具效率与精度的RDC-Net。在本节中将把这些组件单独或组合安装于网络主干架构上,以构成具有不同组件的网络(表6)。针对这些网络开展了一系列的训练与测试,以评估网络精度与效率收益的有效性与合理性。试验过程中为了保证变量的唯一性,只对网络进行组件的更换或者添加,其余的训练配置保持不变。参与消融试验的网络具体结构如下: 网络(a)采用了基于RDC-Net的网络架构,删除了全部的DAFF与CDGGF模块,并使用两个串联的3×3卷积来代替Re-MFF模块以驱动整个网络。处理后所得的网络(a)作为基准将与其他具有创新性组件的网络进行对比。 网络(b)、(c)、(d)在网络(a)的基础上分别安装了Re-MFF、DAFF与CDGGF模块,将这些网络分别与基准网络(a)进行对比,以验证各组件的性能。 网络(e)、(f)、(g)在RDC-Net的基础上分别删除了Re-MFF、DAFF与CDGGF模块,用于论证结合多种不同组件的网络在性能提升方面的有效性。 网络(h)为具有Re-MFF、DAFF与CDGGF 3个组件的网络,具有全部创新性组件的标准RDC-Net的云检测性能。 网络(a)—(h)的精度与复杂度评估结果见表6。可以看出,随着各种创新性组件基于主干结构的逐步添加,网络的精度效益及前向推理计算复杂度均不断提升。 表6 具有不同组件的网络的定量化精度与复杂度评估Tab.6 Quantitative accuracy and complexity evaluation of various networks with different components 网络(a)、(b)的定量评估结果对比显示Re-MFF在精度提高的同时,其参数量及浮点运算数量增长明显。值得注意的是,具有Re-MFF的网络(b)在无损重构后能够将其复杂度降低,与网络(a)复杂度一致。这说明载有Re-MFF组件的网络在无损重构后,可以简化网络结构并提升网络执行效率,以适应轻量级部署或追求快速响应的云检测任务。 通过网络(a)与网络(c)、(d)的比较可以看出,DAFF与CDGGF分别集成于网络中,均能显著提升网络对云像素的判定准确性,并且这两种创新性组件并没有显著增加网络的参数量与浮点运算数量,因而能够避免对网络的计算时间和空间复杂度产生显著影响。 网络(e)、(f)、(g)及(h)的测试结果表明,各种创新性组件的组合均能有效提升网络的稳健性。尤其是具载有全部组件的网络(h)(即完整的RDC-Net)获得了最佳的检测精度,并且受益于这3个组件,其参数量与浮点运算数量均保持在了较低的水平,这进一步验证了本文所提出的3种创新性技术组件的有效性与合理性。 总的来说,集成有Re-MFF、DAFF与CDGGF组件的RDC-Net能够较好地适用于高精度且轻量级的云检测任务。 基于3.2节所得的试验结果可以发现,相同的方法在CloudS_M24和CloudS_Y13数据集中存在着极为明显的检测精度差异,且所有的方法均能够在CloudS_Y13数据集中获得更高的精度(图13)。例如,CloudSegNet在CloudS_M24中的IoU值为73.26%,而这一值在CloudS_Y13中则为82.55%,差值达到11.31%。出现这一现象的主要原因在于以下两点: 图13 多种方法在不同数据集上的精度对比Fig.13 Accuracy comparison of various methods on different data sets (1) CloudS_Y13数据集中场景的分辨率要高于CloudS_M24中场景的分辨率,因此在数据处理后具有相同大小的图像块中CloudS_Y13能够为网络的学习调优提供更为充足且明确的地物特征信息,而CloudS_M24却因分辨率的降低难以为网络提供丰富的地面细节信息。 (2) 虽然CloudS_Y13中的场景数量要少于CloudS_M24,但是CloudS_Y13的场景并未采取下采样处理操作,这使得其原始影像的尺寸要远大于CloudS_M24,进而导致在数据处理后CloudS_Y13数据集中的图像块数量要远多于CloudS_M24(见表2)。因此,在CloudS_Y13中充足的数据量能够保证网络进一步学习数据域中的不变性,从而使网络更具稳健性。而CloudS_M24数据集中的样本数量有限,容易导致网络在训练过程中出现过拟合情况。 总而言之,相对于CloudS_M24来说,CloudS_Y13分辨率更高且数据量更大,可为网络的特征学习提供大量数据与丰富的细节信息,因而相同的方法能够在CloudS_Y13数据集中获得更高的精度。 针对云检测工作极易在高分辨率云雪共存复杂场景中出现漏检与误检的情况以及缺少相应训练样本数据的问题,本文创建了CloudS数据集并提出了一种卷积神经网络RDC-Net。通过大量试验验证得知,相较于其他方法,集成有Re-MFF、DAFF和CDGGF模块的RDC-Net极大地提升了对薄云以及雪上云的检测成功率,降低了对高亮地物的误判率。这使得该网络在CloudS两个子数据集上均获得了最高的IoU值,分别为82.71%与86.94%。此外,重构后的RDC-Net参数数量仅为534万,前向推理的浮点运算数仅为59.75GFlops,这使得该网络的内存占用与计算成本进一步减少,从而适合于广泛的部署运用。接下来,将通过探索知识蒸馏与半/自监督训练策略来进一步改进方法,以达到更为轻量化的部署并减少对样本标注工作的依赖性。本文创新点如下: (1) 创建并公开了基于WorldView2影像的高分辨率云雪共存区云检测数据集,其中包含了37幅视场内可以同时观测到云区与雪区的影像与对应的云掩膜数据。关于数据集详细内容可见https:∥github.com/zhanggb1997/RDC-CloudS。 (2) 设计了可重构多尺度特征融合模块(Re-MFF),在训练阶段能够捕获与聚合网络中的多尺度云特征,有利于对非局部性的空间和光谱特征差异进行学习,以此达到对具有相似性特征的云雪对象以及背景地物的高精度辨别。此外,在测试应用阶段能够进行无损重构,从而促进网络的轻量化部署。 (3) 构建并引入了双重自适应特征融合结构(DAFF),通过对蕴含丰富细节信息的浅层特征进行处理,增强了有效特征表达,抑制了无效特征学习。从而将低级空间和光谱特征传播到网络的深处,来补偿最大池化和卷积过程中的特征丢失问题。 (4) 在网络的解码阶段添加了可控深层梯度指导流 (CDGGF)作为网络训练的附加约束,使隐藏层参数的更新更具无偏差的梯度动量,加快收敛速度并提升网络特征表征能力。同时,由于CDGGF能够聚合来自解码器中不同层级的特征映射,该结构有助于捕获保留更为精细的多层级云特征,减少低级错误分类。1.3 双重自适应特征融合模块

1.4 可控深层梯度指导流模块




2 数 据
2.1 高分辨率云雪共存区云检测数据集

2.2 数据集的进一步划分


3 试 验
3.1 试验设计

3.2 试验结果与分析




3.3 网络复杂性分析

3.4 参数敏感性分析




3.5 消融试验分析

3.6 数据集对比分析

4 结 论
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19摄影世界(2022年1期)2022-01-21一重技术(2021年5期)2022-01-18北京航空航天大学学报(2021年9期)2021-11-02电子制作(2019年13期)2020-01-14中学生数理化·八年级物理人教版(2019年9期)2019-11-25电子制作(2019年11期)2019-07-04中学生数理化·八年级物理人教版(2019年12期)2019-05-21知识经济·中国直销(2018年12期)2018-12-29电子制作(2018年11期)2018-08-04
