
双流网络的水下视频客观质量评价模型
2023-02-18 07:16杜艳玲张明华
计算机与生活 2023年2期
宋 巍,肖 毅,杜艳玲,张明华
上海海洋大学 信息学院,上海201306
在水下环境中获取清晰图像是海洋工程中的一个重要问题[1]。水下视频在海洋生物探测跟踪、海洋种类研究和海洋生态研究中发挥着关键作用,是海洋研究的载体。视频在经过采集、压缩、处理、传输等步骤中都可能产生质量退化的情况。针对水下视频的质量评价方法可对水下视频的质量进行评估,保证水下视频质量将为水下研究提供一个良好的开端。评估水下视频的质量是计算机视觉领域中重要的研究问题。视频质量评价(video quality assessment)根据其类型可以分为主观质量评价和客观质量评价。主观质量评价是通过测试者对不同质量的视频做出评价并进行处理得到主观视频分数。由于主观视频质量评价需要人工标注,具有效率低下和成本高等问题。客观质量评价通过建立算法模型来自动计算视频质量,能够快速、低成本、稳定地进行评价。国际电信联盟(International Telecommunication Union)[2]根据对原始视频的需要程度,将客观视频质量评价分为全参考视频质量评价(full-reference)、部分参考视频质量评价(reduced-reference)和无参考视频质量评价(no-reference)。
光在水介质中传播时介质的物理特性导致了水下拍摄的视频存在退化效应[3]。一方面,光线在水中传播时呈指数衰减导致水下视频质量损失;另一方面,受到水下复杂拍摄环境(例如水流和水压等)的影响造成视频的不稳定性。考虑到水下视频的这两个特性,通常无法获得理想的参考图像/视频,全参考和部分参考评价方法在水下视频质量评价中的实用性有限,因此在水下视频质量评价中一般采用无参考评价的方法。
目前自然场景的评价方法在评价水下视频时适应性差,水下场景质量评价方法只考虑了空间维度,忽视了时间维度的不稳定性对于视频质量的影响。本文旨在将水下视频特有的时空特征和运动特征进行分析并与深度学习的理论思想结合,发展基于深度特征学习的水下视频质量评价模型。本文的贡献可以概述如下:(1)通过实验分析设计了一个双流网络对水下视频特征进行提取,从时空特征和运动特征的角度获取视频质量的相关特征,考虑多种特征融合方式,建立了TS-UVQA(two-stream underwater video quality assessment)模型。(2)验证了光流图对水下视频质量分析的有效性。(3)与多种优秀的质量评价模型进行了对比实验,取得了更高的相关系数。
1 相关工作
水下场景不同于传统自然场景,水介质对光具有特殊吸收和散射特性,这些特性使得在自然场景的图像视频质量评价方法不能直接应用在水下场景中,针对自然场景提出质量评价方法在水下数据集中通常表现出不适应性。相关工作将从自然场景质量评价方法和水下场景质量评价方法两方面展开。
1.1 自然场景质量评价方法
目前,许多学者对自然场景的质量评价进行了研究,为研究水下场景质量评价提供了大量的理论基础。Saad 等人[4]设计了一个依靠离散余弦变换域中视频场景的时空模型以及表征场景中发生的运动类型的模型来预测视频质量。Xu 等人[5]提出了一种用于无参考视频质量评价的可感知系统,通过无监督学习提取特征应用到支持向量回归(support vector regression,SVR)上计算视频质量。Men 等人[6]使用自然视频质量数据库KoNViD-1k 提出一种无参考视频质量评价方法,该方法组合视频的模糊性、色彩性、对比度、空间和时间信息多种特征来形成特征向量,最后通过SVR 映射到主观质量分数。Kang等人[7]提出一个卷积神经网络(convolutional neural networks,CNN)预测图像质量并以图像patch 作为输入,该网络由一个具有最大池和最小池的卷积层、两个完全连接层和一个输出节点组成,将特征学习和回归集成到一个优化过程中从而形成更有效的图像质量估计模型。Jia 等人[8]提出基于PCANet进行图像质量评价,取得比CNN 网络更高的精度。Bianco 等人[9]以CNN 网络架构将图像分块进行质量评价,使用平均池化对分块质量分数进行处理得到总体质量评价。Yan 等人[10]采用双流CNN 网络分别捕获输入图像和梯度图像的信息进行质量评价。Li 等人[11]将视频序列进行分块,借助3D-shearlet 变换提取特征,基于这些特征向量,采用CNN 和logistics对视频质量进行预测。Liu 等人[12]在视频多任务端到端优化神经网络(video multi-task end-to-end optimized neural network,V-MEON)使用了一个多任务神经网络框架,同时对视频感知质量和编码类型的概率进行预测,能够适应于各种编解码器压缩的视频。Varga 和Szirányi[13]利用预先训练的CNN和LSTM(long short-term memory)网络提取深度特征并将特征映射到质量分数上。Li等人[14]提出了一种客观的无参考视频质量评估方法,将内容依赖性和时间记忆效应集成到一个深度神经网络中来预测视频质量。这些基于深度学习的质量评价方法都能取得与人类视觉感知相关性很高的预测结果。
1.2 水下场景质量评价方法
许多学者也对水下场景的质量评价做了研究。Schechner 等人[15]提出了将对比度应用于度量水下图像质量。Hou 等人[16]提出了基于加权灰度尺度角(weight gray scale angle,WGSA)的图像清晰度评价标准对受噪声影响的水下图像进行评价。Yang等人[17]提出水下彩色图像质量评价指标(underwater color image quality evaluation,UCIQE),该指标提取CIELab空间统计特征中与观察者感知相关度最高的三个质量度量:色度、饱和度和对比度。将这些参数线性组合用来预测图像质量。Panetta 等人[18]提出了一种无参考的水下图像质量评价方法(underwater image quality measure,UIQM),采用三种水下图像属性测量(水下图像色彩测量UICM、水下图像清晰度测量UISM、水下图像对比度测量UIConM)来表征水下图像质量。Moreno-Roldán 等人[19]针对水声网络传输的水下视频,提出了一种基于自然视频统计的矢量量化算法,该方法将6 个自然视频统计(natural video statistics,NVS)特征作为评价指标。郭继昌等人[20]将深度学习网络框架与随机森林回归模型相结合,无需参考图像就能得到与观察者感知质量相关性很高的预测结果。宋巍等人[21]考虑水下视频特性,提出一种适用小样本的结合空域统计特性与编码的水下视频质量评价方法NR-UVQA(no-reference underwater video quality assessment)。该方法针对空间域计算图像失真统计特性,结合视频编码参数训练线性模型。
目前传统场景的质量评价方法的研究已经有数十年的发展,但针对水下场景的质量评价研究比较缺乏,并且传统场景的方法不能很好地适应水下场景,相关研究只是提取简单的手工特征和浅层特征,无法反映水下场景的特点。另外,大部分研究只考虑了空间维度,未将时间维度对于视频质量的影响考虑在内。因此,设计针对水下视频场景的质量评价方法是目前一个待解决的问题。
2 方法
针对目前研究的不足,考虑到光线在水下传播时导致的质量损失以及水下复杂的拍摄环境的影响造成的不稳定性特点,根据不同特点分别做不同的处理,设计双流网络分别从时空维度和运动信息维度中提取特征,学习视频质量与特征间的关系并预测视频质量。
视频可以看成由空间信息和时间信息组成,单帧图像体现的是视频的空间信息,例如空间场景和主体;时间信息则由多帧的图像组成,帧间变化体现了视频主体的运动情况,帧间光流是体现帧间变化的一种方式。为了充分提取视频的相关信息,本文借鉴了Two-Stream[22]方法的双流结构概念,针对时空特征和运动特征分别设计相应的网络来提取对应的特征,并考虑多种特征融合方式将特征进一步融合,提出具有双流结构的水下视频质量评价模型(TS-UVQA)。网络结构如图1 所示。
2.1 数据预处理
由于原始视频四周含有人工添加的文字标注等,为避免对模型效果的影响,同时提高特征学习的效率,将视频统一裁剪为224×224 像素大小。原始视频的绝大部分信息分布在视频的中间部分,故裁剪围绕视频中心进行。光流场图进行相同裁剪。
以双流网络学习水下视频中的特征,需要对原始水下视频进行不同的处理。图1(a)中Spatialtemporal Net 从原始视频流中学习时空特征。为此,将原始视频流按一定的间隔抽取视频帧,组成视频帧组。由于本文数据集中的视频序列均为10~13 s,为获得相同长度的视频帧组,以1.0~1.3 s为间隔进行抽取,获得10 帧。为了加快模型的训练,将数据转化成标准模式,对输入图像做归一化处理。
图1(a)中的Motion Net 的目的是从能够描述整个视频运动信息的光流场块中学习视频的运动特征。光流图的获取通常使用光流法对帧间光流进行提取,光流法是利用图像在时间域上相邻帧之间相关性计算物体的运动信息的一种方法。本文计算视频的稠密光流(dense optical flow)[23],将每5 个相邻帧的稠密光流信息叠加,得到能够描述短时视频运动变化的光流场图,对于整个视频序列,按一定间隔T提取10 帧光流场图,获得一个维度为10 的光流场块以描述整个视频运动信息。
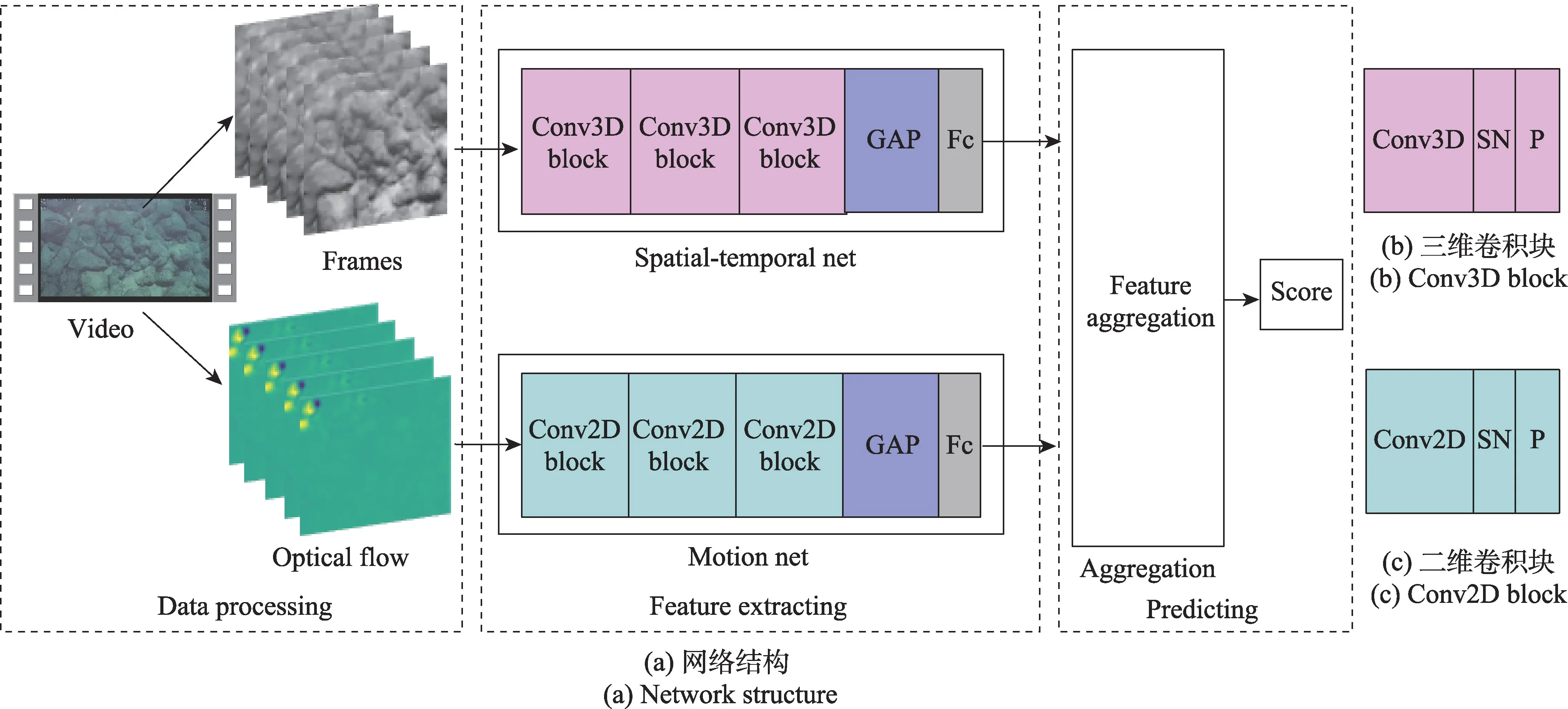
图1 双流网络的水下视频质量评价框架Fig.1 Two-stream network structure for underwater video quality assessment
2.2 时空特征提取
为了提取到视频的时间维度信息,需要将包含时间信息的多视频帧堆叠在一起输入到神经网络中。通过预处理获得的视频帧组是从连续帧之间按照一定间隔提取的,具有一定的时序性。二维(2D)卷积网络能够很好地捕获空间上的信息,但缺乏捕获时序信息的能力。相较于二维,三维(3D)卷积神经网络更适合提取处理带时间维度的信息。研究已经表明三维卷积神经网络能够通过堆叠连续的多视频帧学习部分时间信息。因此,本文根据时空特征特点设计了一个学习视频时空特征的卷积神经网络,命名为Spatial-temporal Net,结构如图1(a)所示。该网络由3 个Conv3D Block,1 个全局平均池化层(global average pooling,GAP)以及1 个全连接层(Fc)组成。
(1)Conv3D Block 模块
Conv3D Block 模块如图1(b)所示,包含Conv3D层、SN(switchable normalization)层[24]和MaxPooling 3D层。Conv3D 层通过三维卷积能够同时提取视频中的空间和时间维度的特征。在Spatial-temporal Net中,3 个Conv3D Block 中的Conv3D 层卷积核数分别为8、16 和32。
数据归一化对模型的性能提升有重要的影响。SN 归一化方法使用可微分学习,为深度学习网络中的每一个归一化层确定合适的归一化操作。SN 相较于其他的归一化方法,如BN(batch normalization)[25]、IN(instance normalization)[26]和LN(layer normalization)[27]鲁棒性更好,对batch size 的设置不敏感,使模型能够在各种batch size 的设计下保持稳定。SN算法如式(1)所示:
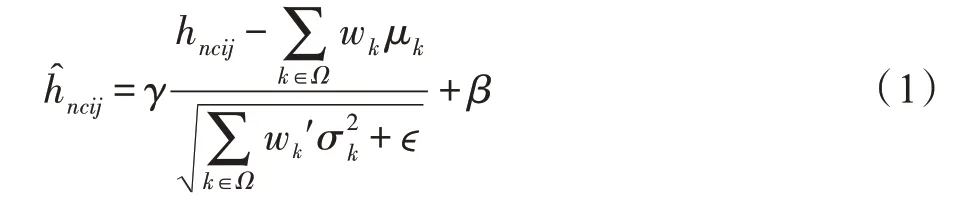
其中,hncij和分别是归一化前后的像素点的值;γ和β分别是位移变量和缩放变量;ϵ是一个非常小的数,用以防止除0;μk和σk分别是均值和方差;Ω={in,ln,bn}是三种归一化方法的集合。
(2)慢融合策略
为了更有效地融合时间维度的特征,本文采用了一种在时间维度上卷积的慢融合策略[28]来更有效地学习长时间序列数据与视频质量分数之间的相关性。
慢融合策略如图2 所示。区别于一次性通过Conv3D 对10 帧进行特征提取,该策略将时间信息在3 维卷积层中逐渐融合。具体来说,第一个卷积层将10 帧压缩为5 帧,第二个卷积层将5 帧压缩为3 帧,第三个卷积层将前一层的3 帧融合为2 帧。通过这种方式融合复杂的时间维度特征。通过该策略控制卷积核在时间维度的步幅,缓慢地融合时间维度特征,使得模型能够提取到更复杂的特征。
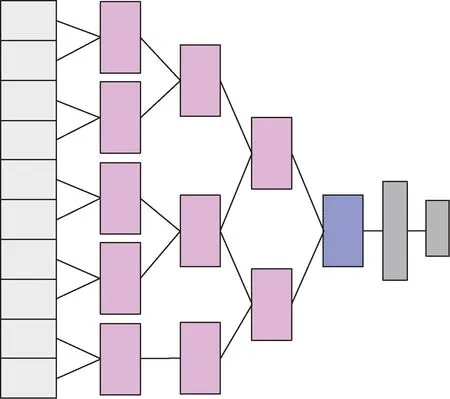
图2 慢融合策略图Fig.2 Slow fusion strategy diagram
2.3 光流特征提取
与2.2 节中的时空特征提取不同,光流特征主要表达的是视频中主体的运动特征。虽然Conv3D 结构可以通过三维卷积核同时提取视频帧组中的时空特征,但在时间维度信息的描述上,本质是通过局部卷积来表达时间关系,这种时间特征提取对于水下视频质量的评价是不充分的,因此从光流场块中提取运动特征是更加合理的选择。在光流特征提取中,输入的是叠加的光流场块,通过二维卷积神经网络提取其中特征。因此,本文根据运动特征的特点设计了一个Conv2D Block 模块,如图1(c)所示,包含Conv2D 层、SN 层 和MaxPooling2D 层。在Conv2D Block 的基础上设计了一个包含3 个Conv2D Block模块的二维卷积神经网络Motion Net,如图1(a)所示。同时将Motion Net 网络与经典的二维特征提取网 络——AlexNet、VGG16、InceptionV1、ResNet50、ResNet18 进行了对比实验。
本文通过实验对比(详见3.3.2 小节)表明了Motion Net 网络作为运动特征提取器的优势。相较于VGG16、InceptionV1、ResNet18 来说,Motion Net网络使用了3×3 的卷积核和SN 层,具有参数量小和自适应选择正则化的优点。而ResNet50 网络太深,需要更多的数据量才能很好地训练。Motion Net 网络能够有效提取光流场中的特征,所提取的特征与主观质量分数有较高的相关性。
2.4 特征融合
为了获得更有效表达水下视频质量的特征,需要将双流网络提取的不同类型的特征进行融合。本文考虑了三种融合方式对实验结果的影响,分别为:决策级平均融合、决策级线性融合和特征级SVR(support vector regression)融合。决策级平均融合如式(2),将双流模型得到的预测结果作平均池化得到决策级平均融合的结果。决策级线性融合如式(3),双流模型结果通过线性加权得到融合后的预测结果,加权权重通过训练得到。特征级SVR 融合如式(4)。取双流模型中最后一层全连接层的输出作为特征向量,将两个特征向量做拼接操作后输入到SVR 中(使用RBF(radial basis function)核函数),由SVR 进一步融合特征信息,并建立与质量评分之间的映射关系,实现视频质量预测。
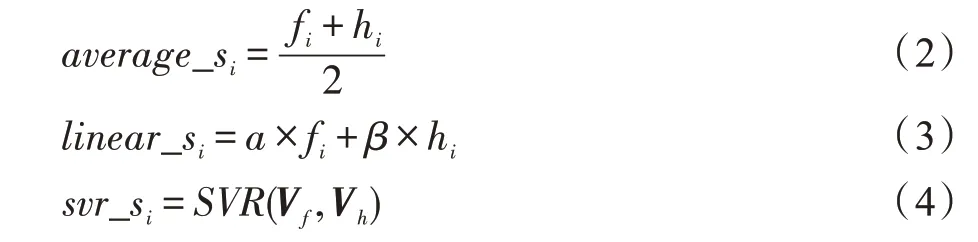
其中,i∈1,2,…,N,N为测试集的大小;si为第i个视频的预测结果;fi为时空特征提取网络的预测结果;hi为光流特征提取网络的预测结果;α、β为权重系数;V f为时空特征提取网络最后一个全连接层输出的特征向量;Vh为光流特征提取网络最后一个全连接层输出的特征向量。
网络的总体损失函数为Logcosh,该函数应用于回归任务,相较于L2 损失函数更加平滑。Logcosh 损失函数公式如式(5):
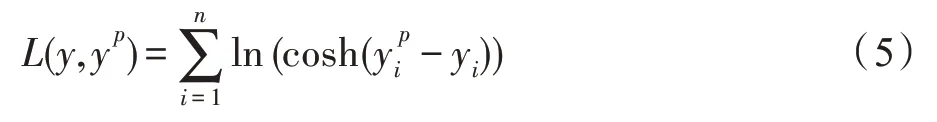
其中,y表示label值,yp表示模型的预测值。
3 实验
本章通过综合实验对本文提出的TS-UVQA 方法的性能进行了全面分析。首先,针对TS-UVQA 的三个主要模块——时空特征提取网络、运动特征提取网络和特征融合策略,通过实验分析了特征提取网络的有效性,以及不同特征融合方式对于实验结果的影响(实验结果见3.3.1~3.3.3 小节)。其次,通过对比光流运动特征在水下视频和自然场景视频质量评价的不同表现,验证了光流对于水下视频质量评价的作用(实验结果见3.3.4 小节)。最后,与目前最先进视频质量评价方法进行对比实验,检验了本文方法在水下视频评价方面的优良性能,以及用于其他自然场景视频质量评价的泛化能力(实验结果见3.3.5 小节)。
3.1 数据集
目前,针对水下场景的视频客观质量评价模型的构建缺乏公开的水下视频数据集。本文使用了之前研究中建立的水下数据集[21]。该数据集中的视频序列涵盖了水下动态、静态动植物以及海底岩石等场景,包含广泛的时间空间维度变化。该数据集对25 个原始视频选择不同比特率(96 Kbit/s、200 Kbit/s、500 Kbit/s)和不同帧率(5 FPS、10 FPS、25 FPS)参数采用H.264 进行模拟失真压缩。由15 名观测者为水下视频进行质量打分,将每个视频的平均意见得分(MOS)作为视频的质量标注。除了上述水下数据集外,本文将方法在公开的非水下视频数据集ECVQ[29]、EVVQ[30]、LIVE[31-32]上也进行了实验。ECVQ 包含8 个原始CIF 视频,通过H.264 和MPEG4-Visual 压缩成90个视频。EVVQ包含8个VGA原始视频,通过H.264 和MPEG4-Visual压缩成90个视频。LIVE 数据集包含15 个原始视频,通过无线失真、IP 失真、H.264 和MPEG-2 失真压缩成150 个视频。
3.2 实验设置及评价指标
为评估视频客观质量评价网络的性能,将每个数据集随机划分为80%的训练集和20%的测试集,实验重复10 次取平均值作为实验的最终结果。训练阶段采用Adam 优化,参数为beta1=0.9,beta2=0.999,epsilon=1E-07。初始学习率为0.000 3,采用早停(Early-Stopping)策略。
视频客观质量评价的评价指标是基于预测值与主观评分之间的相关性。本文采用的评价指标为:皮尔森线性相关系数(Pearson linear correlation coefficient,PLCC)和斯皮尔曼秩序相关系数(Spearman rank order correlation coefficient,SROCC),PLCC 和SROCC 在质量评价领域广泛使用。
PLCC 描述两个变量之间的线性相关性。
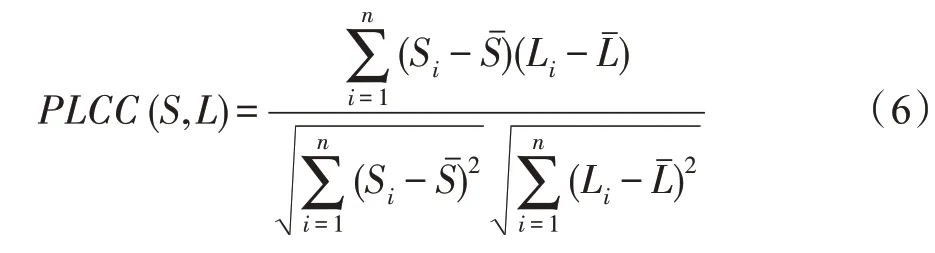
其中,集合S和集合L分别表示视频数据集的质量预测值和标签值。Sˉ、Lˉ为S和L的平均值。
SROCC 是非线性相关指标,描述序列中元素的排列关系。

3.3 实验结果
3.3.1 时空特征提取网络性能分析
为获取与水下视频主观质量分数相关性高的时空特征,对Spatial-temporal Net 中的Conv3D Block 模块进行探索,开展了消融实验,实验结果如表1 所示。表中的模型名称分别为:(1)c3d,仅使用三维卷积神经网络Conv3D 提取特征并预测;(2)c3d-sn,在三维卷积网络的基础加上SN 层;(3)c3d-sn-slow,在三维卷积神经网络加上SN 层的基础上再加上慢融合策略。同时,实验也对比了输入图像为灰度图和RGB 图的情况,其中,灰度图是模型的默认输入,rgb表示输入图像为RGB 图。
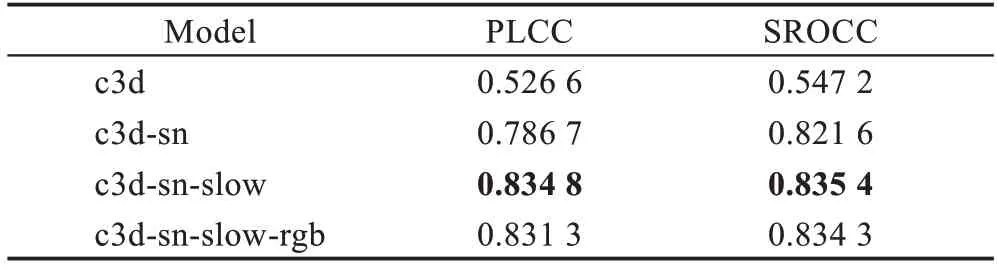
表1 不同策略下时空特征提取网络的评价结果Table 1 Results of spatial-temporal feature extraction networks under different strategies
从表1 中给出的结果可见,仅使用三维卷积神经网络提取的特征(c3d)不能很好地反映水下特征,在相关系数上取得了最低的分值。SN 层能自适应选择正则化方式,缓解梯度消失问题加快模型收敛,因此c3d-sn 方法加快了模型的训练,并大大提升了模型的性能,取得了比c3d 更好的效果。添加慢融合策略的c3d-sn-slow 加强了时间信息的学习,使得时空维度的特征更丰富,能够更准确地反映视频的质量特征,因此取得了最佳的评价结果。
表1 中c3d-sn-slow 和c3d-sn-slow-rgb 的对比,显示了输入为灰度图和RGB 三通道彩色图对结果的影响。实验表明,RGB 彩色图像和单通道灰度图像对于视频质量的影响无显著变化,但使用灰度图可以减少模型参数的计算量,加快模型的训练速度,因此,本文在数据预处理中将RGB 图转化为灰度图。
3.3.2 运动特征提取网络性能分析
为了提取能够反映水下视频运动的特征,以光流场的帧流作为输入,选择二维卷积神经网络获取其中的信息。实验对比了所设计网络Motion Net 与经典的二维特征提取网络——AlexNet、VGG16、InceptionV1、ResNet18 和ResNet50,结果如表2 所示。
从表2 中可以知道,AlexNet、VGG16、Inception V1、ResNet18 等网络预测结果与主观质量评价的相关性均低于Motion Net(PLCC=0.822 0 和SROCC=0.825 6)。ResNet50 模型太过复杂,而所使用数据的量太小,导致模型不能很好地拟合,得到了最低的相关性系数。
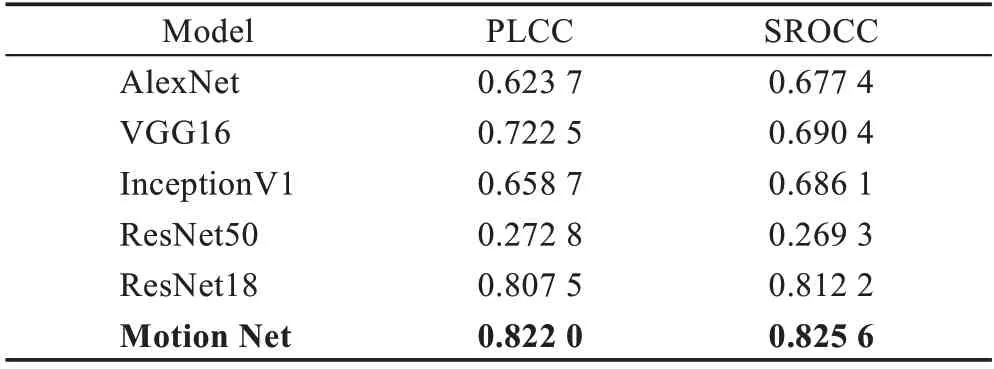
表2 不同网络对于光流特征提取的对比结果Table 2 Comparison results of different networks for optical flow feature extraction
3.3.3 融合策略分析
在3.3.1 小节和3.3.2 小节中分别验证了时空特征和运动特征对于水下视频质量评价的有效性,本小节进一步对时空特征和运动特征进行融合,期望获得更高精度的质量评价模型。
在特征融合前,先以热力图的形式对两个网络提取的特征进行直观展示,如图3 所示。图3(a)中,左图为Spatial-temporal Net 输入视频帧组中的一帧,右图为第二个ConvBlock 块中卷积层后输出的特征图;图3(b)中,左图为Motion Net 输入的光流场图,右图为第二个卷积块后输出的特征图。可以观察到,时空特征图关注了视频空间上的细节特征以及部分时间信息(如变化的数字),而运动特征图关注了视频中主体对象的运动轮廓,二者具有一定的互补性。
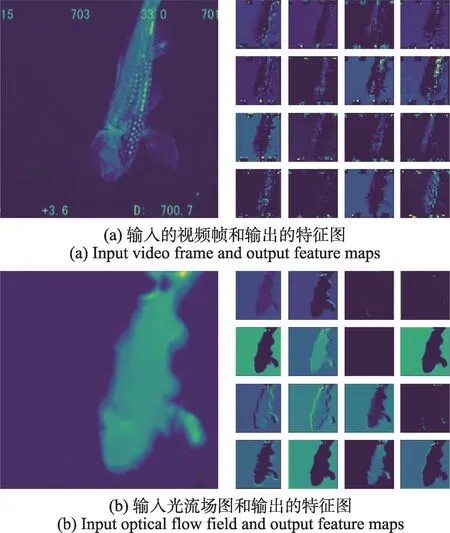
图3 特征图Fig.3 Feature maps
本文对比了三种融合方式的效果:决策级平均融合(average decision fusion)、决策级线性融合(linear decision fusion)、特征级SVR融合(SVR feature fusion)。三种融合方式的比较结果如表3 所示。
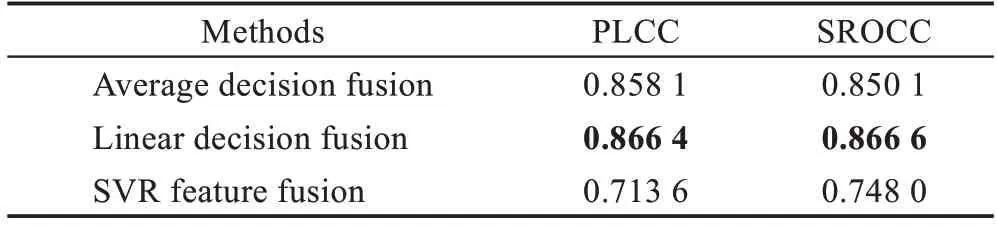
表3 不同融合策略的PLCC 和SROCCTable 3 PLCC and SROCC of different integration strategies
从表3 中可以知道,特征级SVR 融合取得相关系数较低,决策级平均融合与决策级线性融合结果相近,决策级线性融合取得了最高的相关性系数(PLCC=0.866 4,SROCC=0.866 6)。同时,线性融合的结果优于未融合的结果。相较于Spatial-temporal Net 的结果,PLCC 提高了0.031 6,SROCC 提高了0.031 2;相较于光流特征提取网络的结果PLCC 和SROCC 分别提高了0.044 4 和0.041 0。
3.3.4 运动特征对水下视频质量评价的影响
为进一步验证基于光流图的运动特征对水下视频质量评价的作用,在自然场景数据集上开展了对比实验。实验结果如表4 所示,其中Spatial-temporal Net 代表只提取时空特征,Motion Net 代表只提取光流特征,Aggregate表示融合时空特征与光流特征。
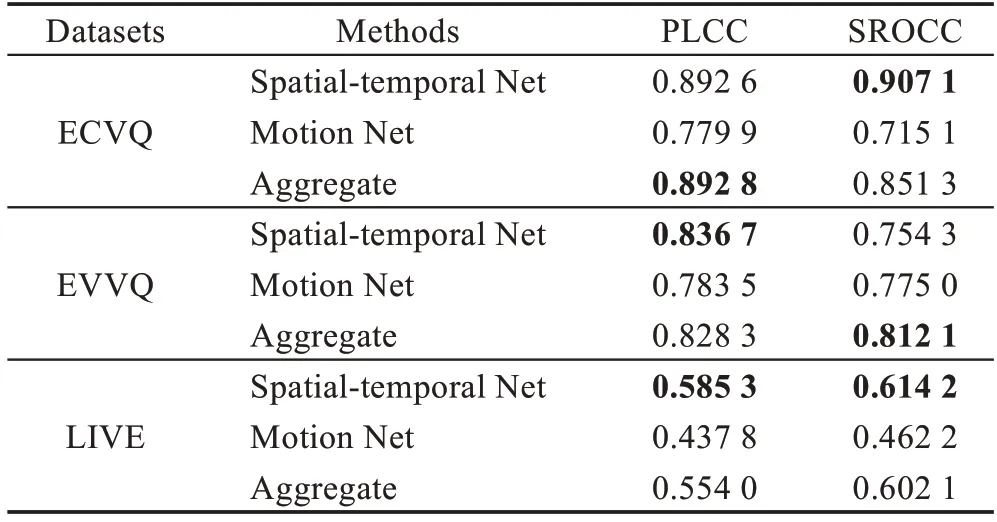
表4 自然场景数据集上不同网络模型的评价结果Table 4 Evaluation results of different networks on natural scene datasets
根据表4 中的相关系数PLCC 和SROCC 可知,在不同的自然场景数据集(ECVQ、EVVQ 和LIVE)中,时空特征(由Spatial-temporal Net 提取)对视频质量预测的贡献远远大于运动特征(由Motion Net 提取),且运动特征与时空特征相融合后也未能取得比原始仅时空特征更好的预测结果。但是,在水下数据集中,基于光流图的运动特征与水下视频质量有很强的相关性(如表2 所示),且与时空特征结合后进一步提高了模型预测精度,这说明本文所设计的双流网络对于水下视频质量评价的有效性。
3.3.5 对比实验
(1)模型性能对比
为验证本文所提出的双流水下视频质量评价模型的整体性能,与13 种目前最先进的自然场景图像/视频质量评价方法和水下场景的图像/视频质量评价方法进行了比较。其中,包括3 种针对水下图像的质量评价方法,2 种针对水下视频的质量评价方法,8 种针对自然场景的图像/视频的质量评价方法。图像质量评价方法包括:通用彩色图像的质量评价方法CIQI 和CQE[33],基于NSS 特征的无参考空间域图像质量评价方法BRISQUE[34],针对水下彩色图像质量评价方法的线性模型UCIQE[17]和UIQM[18],基于深度学习的图像质量评价方法PCANet[8]和水下图像质量评价方法Guo[20]。视频质量评价方法包括:通用失真视频的质量评价方法VIIDEO[35]和V-BLIINDS[4],基于NVS 特征的水下视频质量评价方法Moreno-Roldán[19],基于统计和编码特征的水下视频质量评价模型NR-UVQA[21],基于深度学习框架的视频质量评价模型V-MEON[12]和采用CNN+LSTM 相结合视频质量评价方法[13]。所有对比方法将在相同的水下视频数据集中以随机划分的80%的训练集和20%的测试集重新训练,实验重复多次取平均值。所有的测试数据未出现在训练数据中,保证方法间的公平比较。需要说明的是,V-MEON 方法是面向视频失真类型判定和视频质量评分多任务的网络,根据不同的失真类型对视频质量损失的评价进行了优化。由于本文使用的水下视频没有相应的失真类型标签,本文仅复现V-MEON 基于C3D 慢融合的特征学习网络和质量分数预测的部分。对比实验结果如表5所示。
从表5 中可知,大部分图像质量评价模型,如CIQI、CQE、UCIQE、UIQM 等,虽然是针对大气图像和水下图像的质量评价方法,但由于图像和视频存在显著差异性,对于水下视频质量的评价都不能取得与主观分数很好的相关系数(PLCC<0.5),基于图像统计特征的评价指标,如BRISQUE 能获得相对较高的相关系数,这说明水下视频质量与自然场景下的统计特性有强关联。视频质量评价模型中,除VIIDEO 方法最差外,总体上优于图像质量评价模型,PLCC 和SROCC 相关系数均大于0.5,这表明仅依赖空间维度特征的图像质量评价不能充分表达视频的质量特征。
基于深度学习的方法,不论是图像质量评价模型Guo 和PCANet,还是视频质量评价模型V-MEON、CNN+LSTM 及本文方法,均取得较其他方法更好的结果。其中,Guo 的方法采用了VGG 和随机森林相结合,在充分提取空间特征的情况下,用集成学习方法对决策进行了优化;V-MEON 模型直接学习视频帧的时空联合特征;CNN+LSTM 方法先使用预训练CNN 提取视频帧的空间特征,再用LSTM 进一步提取时间特征。本文方法在多重特征(时空和运动特征)学习和信息融合方面更优秀。表5 中NR-UVQA方法同样取得了很高的相关系数,且方法较为简单,但该方法是否具有普适性待验证。
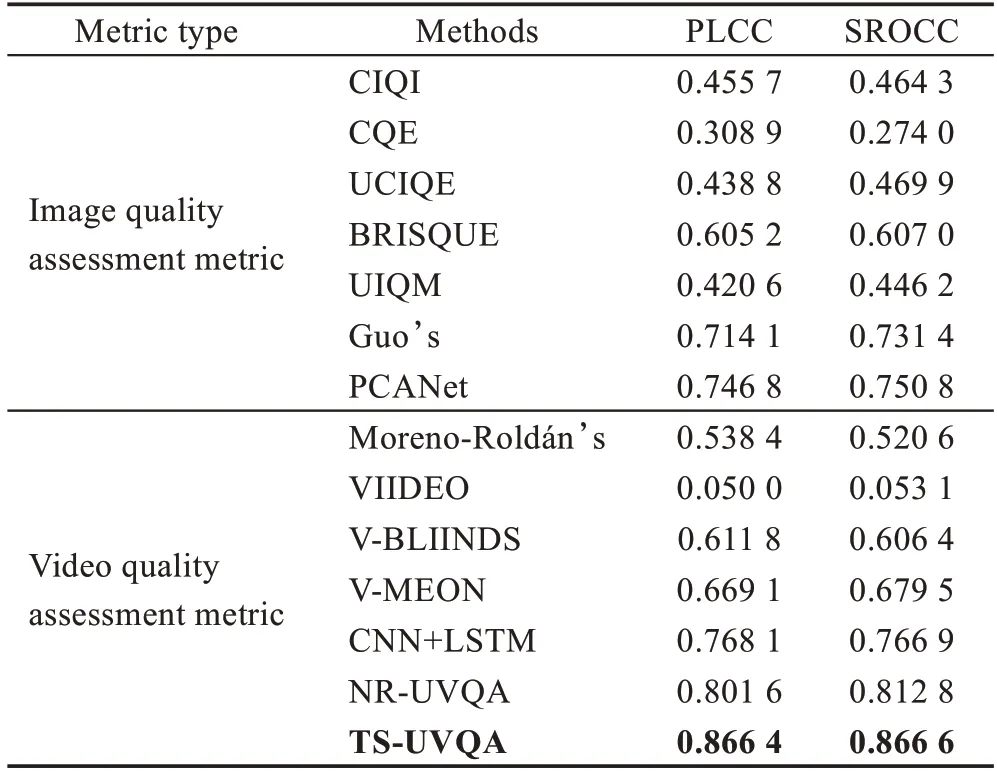
表5 14 种图像、视频质量评价方法的结果Table 5 Results of 14 quality assessment methods for image and video
(2)泛化性能分析
为验证各类方法的泛化性能,选择了五种视频质量评价方法,在自然场景的数据集ECVQ[29]、EVVQ[30]和LIVE[31-32]上分别做了实验,结果如表6 所示。从表6 中可以看出,通用的视频质量评价方法VIIDEO 在ECVQ 和EVVQ 中表现较差,在LIVE 上表现较好,VBLIINDS 在ECVQ、EVVQ、LIVE 数据集中表现稳定,且在LIVE 数据集上取得了最高的相关系数。NR-UVQA 方法在水下视频质量评价中获得了很高的相关系数,但在几个自然场景数据集中表现不太稳定。针对自然场景的V-MEON 方法在ECVQ、EVVQ 数据集上取得了最高的相关系数,在LIVE 上表现一般。TS-UVQA 方法在三个自然场景数据集中都能表现稳定,且在自然场景数据集中能够取得和其他优秀方法相近的结果。综上所述,本文方法不仅适用于水下数据集,在自然场景数据集中也能取得和其他最优秀方法相近的相关系数。
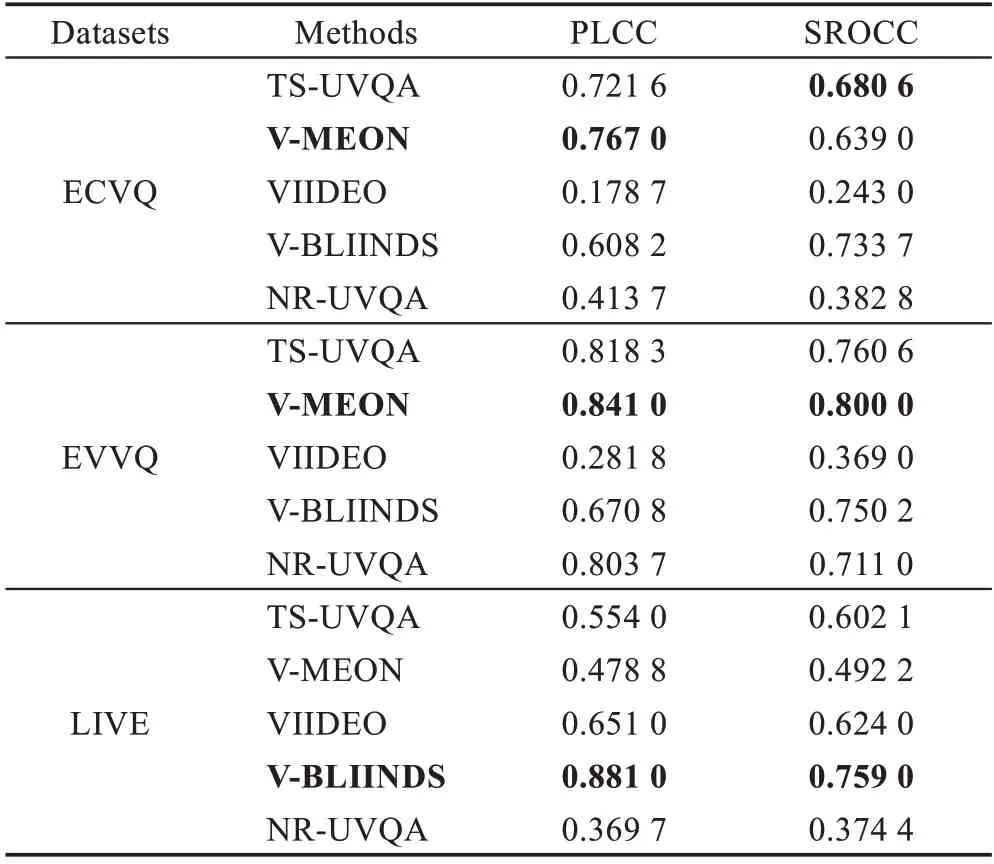
表6 自然场景数据集上的视频质量评价结果对比Table 6 Comparison of video quality assessment results on natural scene datasets
4 总结与展望
通过建立水下视频客观质量评价模型,有利于解决自然场景质量评价方法在水下场景中表现不适用性问题,推动当前水下视频质量评价的优化。本文针对水下视频的质量损失和视频不稳定性特点,提出了一种面向水下视频的客观无参考质量评价方法TS-UVQA。TS-UVQA 从时空维度、运动信息维度方面提取相关特征,利用三维卷积、自适应正则化和慢融合策略从多视频帧中提取时空特征,用二维卷积和自适应正则化对光流场块提取相关运动特征。使用决策级融合策略将时空特征和运动特征相融合,建立了能够快速高效预测水下视频质量的评价模型,同时验证了光流图对于水下视频质量评价的有效性。模型预测结果与主观质量评分取得了很高的相关性。
由于实验条件的限制,本文还存在许多不足。本文用于训练的数据集量比较小,不能涵盖水下视频各种各样的情形,不能很好地评价极端环境下的水下视频,如果有更大的数据量以供学习,模型将取得更好的性能。下一步工作将深入研究水下视频的特点,优化网络,提取更加能反映水下视频质量的特征,增强模型的性能。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
自然资源遥感(2014年3期)2014-02-27
