
混合深度CNN 联合注意力的高光谱图像分类
2023-02-18 07:16吕艳萍
计算机与生活 2023年2期
王 燕,吕艳萍
兰州理工大学 计算机与通信学院,兰州730050
高光谱图像(hyperspectral image,HSI)是由高光谱遥感传感器或者成像光谱仪获得的,与传统的RGB 图像相比,高光谱图像包含二维空间信息,在第三维中包含丰富的光谱信息[1],大量的光谱波段可以区分各种具有高细节的材料。此外,利用图像的形状、纹理和几何结构等空间特征,可以提高识别率,非常有助于分类和识别任务,因此高光谱数据被广泛地应用到矿产资源开发[2]、农业实验[3]、异常检测[4]和食品分析[5]等领域。
尽管HSI 中具有丰富的光谱信息,但是也带来了新的问题。随着高光谱数据的不断增加,导致了新的实际和理论问题。在实际问题方面,高维数据与有限训练样本之间的不平衡,导致分类结果随维数的增加而下降[6]。人工标记HSI的成本较高而导致标签样本短缺。HSI 的空间布局比较复杂,不同的光谱材料分类难度更大。理论方面,在高维空间中,为高光谱图像开发的传统算法可能不再适用。
传统的高光谱图像分类方法大多基于光谱信息,例如主成分分析(principal component analysis,PCA)[7]、线性判别式分析(linear discriminant analysis,LDA)[8]和流行学习(manifold learning)[9]都是基于光谱信息的分类方法,但是只依赖光谱特征进行分类会导致“椒盐现象”的发生,高光谱图像中的像素并不是相互独立的,忽略了相邻像素间存在的空间相关性。因此,为进一步提高分类性能,将空间特征纳入分类方法中,例如基于手工制作的Gabor 滤波[10]、形态学属性轮廓[11]、三维离散小波[12]等方法被相继提出。虽然手工制作的空间特征有助于改善椒盐现象并在一定程度上提高了分类精确度,但是手工特征通常仅具备某种特定类型的空间结构信息,无法呈现高光谱图像低级空间属性的多样性。之后提出了光谱-空间特征融合的方法,如基于对象或像素分割、决策融合、特征融合的方法。在特征融合方法中,基于深度学习的算法在HSI 分类中应用广泛。与之前的分类模型相比,深度学习最显著的特点是在端到端的分层框架中学习高级特征。
典型的深度学习方法有自动编码器(autoencoder,AE)[13]、深度信念网络(deep belief network,DBN)[14]和卷积神经网络(convolutional neural networks,CNN)[15]。在这些深度网络模型中,CNN 在HSI 的特征提取和分类中表现出更好的性能。Yao 等提出了聚类算法和2D CNN 的深度学习模型[16]。魏祥坡等使用2D CNN提取HSI 的深层空间特征,同时利用1D CNN 提取深层光谱特征,通过两个网络模型全连接层的连接完成空间特征和光谱特征融合[17],但是基于1D 或2D 的深度学习网络无法同时利用三维数据中的光谱和空间信息。它们大多是分别获取空间和光谱这两种不同类型的信息,然后通过某种融合方法或简单堆叠的方式获取空谱联合特征。因此上述方法并没有考虑和利用不同频带之间的关联性。
在此基础上,基于3D CNN 的各种分类方法取得了不错的分类结果[18]。3D CNN 可以联合提取光谱和空间特征以保持HSI 立方体的相关性质,其中光谱和空间信息被独立并联合地包含在3D 结构中。Zhang等提出了一种深而宽的3D CNN 模型SSDANet[6],虽然取得了很高的分类精度,但模型复杂度很大,在Indian Pines 数据集上的训练时间达到25 814.89 s。Zhang 等提出一种多通道网络[19],利用3D 密集连接网络提取空谱特征,密集连接性使模型更深入,但是忽略了网络的宽度,这将导致细节特征随着模型的加深而逐渐丢失。
近几年来,注意力机制被引入CNN 中。Lu 等提出了一种基于三维通道和空间注意力的多通道光谱-空间残差网络(channel and spatial attention-based multiscale spatial-spectral residual networks,CSMS-SSRN)[20],其中的三维通道和空间注意力机制更多地关注空间特征而忽略了光谱特征。Sun等提出了一种空间注意力机制网络(spectral-spatial attention network,SSAN)[21],将光谱-空间网络(spectral-spatial network,SSN)与SSAN 相结合提取空谱特征。Fang 等引入光谱注意力机制来增强光谱特征的可区分性,从而提高了训练模型的分类性能[22]。上述基于注意力机制的方法仅利用光谱特征或空间特征,忽略了HSI的特殊结构。
尽管上述模型在HSI 分类上取得了一定的结果,但是提取有效且具有辨识性的空谱特征仍然是一个相当大的挑战。由于HSI 标签样本数量短缺,不同标记样本的不平衡也降低了HSI 分类的准确性,同物异谱和异物同谱现象的普遍存在也增加了分类的难度。
针对上述问题提出了混合深度卷积联合注意力(hybrid deep CNN-Attention,HDC-Attention)网络模型。具体地,该方法首先利用核主成分分析(kernel principal component analysis,KPCA)[23]和小批量K均值(mini batchK-means,MBK-means)来压缩HSI 中的光谱特征,然后将处理后的数据输入HDC 网络进行光谱-空间提取,再利用光谱-空间注意力(spectralspatial attention)进一步增强关键的光谱-空间特征。最后利用Softmax 进行分类任务。由于该模型可最大限度地提取光谱和空间特征,在受限的样本下表现出较好的分类性能。
1 相关工作
1.1 高光谱图像的降维处理
高光谱图像具有高维度和高特征冗余的特点,维数的降低可以缓解维数灾难问题,在计算资源有限的情况下,也可以避免内存不足的问题。
利用PCA 对高光谱图像进行降维,是将数据集投影在一个空间中,沿着每个正交向量的方差最大化,没有考虑图像的空间结构和特征,而且PCA 适用于数据的线性降维,而高光谱数据由于其成像过程中如电磁波和大气的复杂作用、临近地物反射的电磁波的干扰、光谱仪的空间分辨率的限制等,这些因素是非线性的。KPCA 在继承线性PCA 优点的基础上通过引用核函数增强了高光谱数据的非线性信号处理能力,从而检索更高阶的统计信息,可以更好地处理遥感图像。
KPCA 是利用核方法对PCA 的一种非线性扩展,其基本思想是:对于输入矩阵X,通过一个非线性映射函数将X映射到高维甚至是无穷维的特征空间F,然后在特征空间F中进行PCA 处理。
给定一组高光谱数据集X={X1,X2,…,XN},X的每一列表示一个样本,其中{Xi∈RK,i=1,2,…,N}。设一个非线性映射ϕ将X映射到特征空间F(D维):

将矩阵X映射到F中得到一个D×K的新矩阵ϕ(X)={ϕ(X1),ϕ(X2),…,ϕ(XN)}。然后在F中对ϕ(X)进行降维。F的协方差矩阵为:

由于ϕ(X)可能是超高阶或者无限阶,将对角化CF的操作转化为求解核函数k的特征问题:
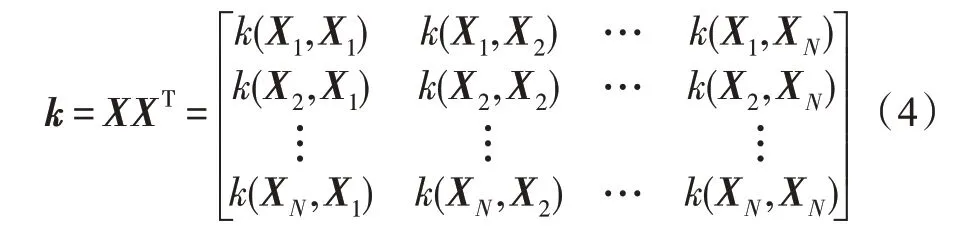
求解k的特征值和特征向量:

其中,P为矩阵k的特征向量(特征空间中的权重向量),λ为矩阵k的特征值。
将式(5)左右同时乘XT,得到:

由于N∙CF=XTX矩阵k和CF的特征值都为λ,CF的特征向量为XTP,将特征向量归一化:
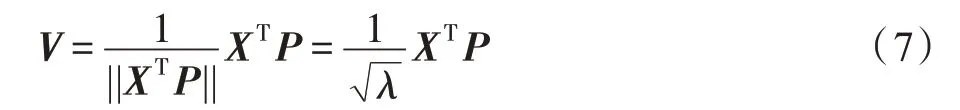
在上式中,λ和P可以通过矩阵k求解,XT仍未知,但求解X在V上的投影即可解出,即:
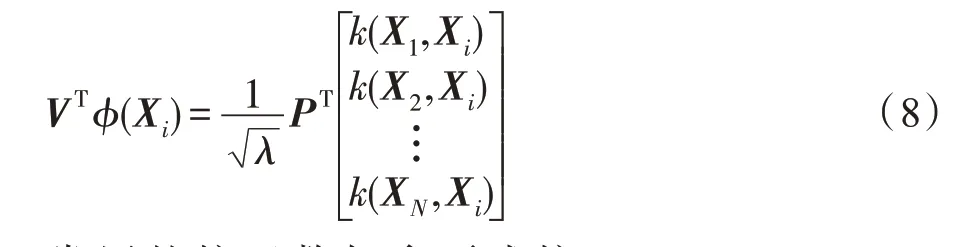
常用的核函数如多项式核(polynomial kernel,Poly 核):

径向基函数核(radial basis function kernel,RBF核):
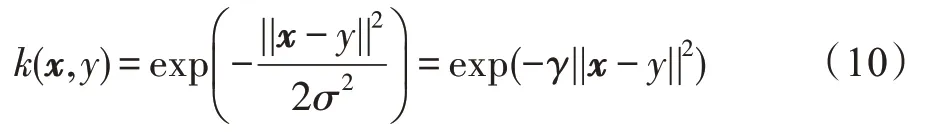
线性核(linear kernel):

使用KPCA 进行降维操作时,核函数的选择和参数设置是影响结果的重要部分。
MBK-means 聚类算法是K-means 算法的改进,其思想是随机从整体特征中做一个抽样,选取出一小部分数据来代替整体。修瑛昌等证明在进行大数据量的遥感影像分类时,MBK-means 算法比K-means算法更具优势[24]。通过抽样不仅可以提高迭代的效率,正确率也可以达到标准。
KPCA 在保持高光谱数据的空间特征结构的同时,压缩光谱信息并减少了光谱冗余,MBK-means 通过抽样的方法将经过KPCA 降维后的特征进行进一步的降维,同时也减少了运算时间。
1.2 3D CNN 和2D CNN
基于CNN 的深度学习模型之所以能够有如此优秀的性能,是因为不同卷积层所学习的图像特征之间有着非常清晰的层次结构。最前面卷积层的神经元主要被颜色激活,说明光谱特征是特征学习过程的基础。中间层学习的特征对应于图像中的角、边缘和纹理,而最后一层特征则是针对类别的,主要对应于对象和部分的对象。
实际上,自然图像和遥感图像的特征本质上是按层次组织的。特征学习是光谱-空间的学习过程,和3D CNN 学习光谱-空间特征的过程相吻合,因此,以顺序方式处理光谱特征和空间特征是合理的。光谱特征是高层次空间特征的基础,空间特征用于分类决策。3D CNN 在三个维度上同时工作,其中两个维度为空间维,剩下的一维为光谱维,高光谱图像也是三维的立方体,3D CNN 联合提取的光谱和空间特征被独立并联合地包含在3D 结构中。因此3D CNN更加适合提取高光谱图像的特征。
3D CNN 的卷积层利用三维卷积核对三维输入进行运算。表示为第l层第j个特征映射(x,y,z)位置的神经元,其计算公式如式(12)所示。

利用2D CNN 可以提取高光谱遥感图像目标像素周围的局部空间信息。2D CNN 提取空间特征,卷积层利用二维卷积核对二维输入进行运算。第l层第j个特征图上神经元在位置(x,y)的值可通过式(13)计算。
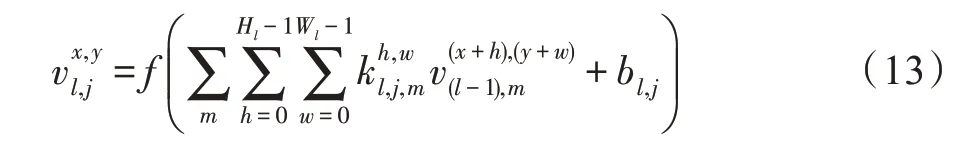
其中,m为第(l-1)层的特征图索引。卷积核的高度和宽度分别用Hl和Wl表示。表示第l层第m个特征图上(h,w)位置的第j个卷积核的权重。第(l-1)层第m个特征图上神经元在位置(x+h,y+w)上的值表示为。bl,j是偏置。
2 模型框架
2.1 整体框架
图1 展示了用于HSI 分类的HDC-Attention 框架图,主要由三部分组成:KPCA 和MBK-means 组合降维模块、HDC 特征提取模块、Spectral-Spatial Attention 模块。

图1 HDC-Attention 网络框架Fig.1 Network framework of HDC-Attention
本文以Indian Pines 的数据集为例,说明所设计模型的实现细节。原始高光谱数据立方体像素大小为145×145×200,其中145 表示高度和宽度,200 表示光谱维度。首先对原始高光谱数据沿光谱维进行KPCA 降维。将光谱维数的数量从200 减少到15,同时保持原始立方体完整的空间维度(宽度和高度),再将降维后的特征通过MBK-means 聚类算法聚为20 簇,用簇中心的平均光谱特征来标记不同的簇。这样,高光谱图像中的光谱特征得到很大程度的压缩。KPCA 和MBK-means 的组合方法减少了HSI 的光谱冗余,保留了主要特征,为后续卷积神经网络进行特征提取打好了基础。
然后,选择25×25×15 像素邻域作为输入样本。第一,分别通过3 个改进的3D CNN 模块,得到通道数为32 的25×25×15 特征图。改进的3D CNN 网络可以依次增强光谱-空间特征,产生具有代表性的特征,增强模型的泛化能力。第二,通过两个2D CNN 进一步提取深度空间特征。通过有64 个滤波器的5×5 的2D CNN,生成64 通道的21×21 特征图。然后,对生成的特征图进行2×2、步长为2 的最大池层的二次采样,以降低网络的计算量,得到64 通道的10×10 特征图。同样,再通过有64 个滤波器的3×3 的2D CNN,生成64 通道的8×8 特征图。然后,对生成的特征图进行2×2、步长为2 的最大池化处理,得到64 通道的4×4 特征图。
再将上述特征图输入Spectral-Spatial Attention模块,得到64 通道的2×2 特征图。最后,将上述特征图输入两层全连接层提取判别特征,Softmax 进行最终分类,得到各个类别的分类精度。
2.2 改进的3D CNN 模块
如图2 所示对输入特征先进行BN 操作,以加速网络的收敛。将输入特征每个通道分别卷积,从而捕获每个通道的光谱和空间特征,为了实现多尺度特征提取,将输入特征输入到1×1×1 和3×3×7(可设置)的双通道卷积核中,每个通道有16 个滤波器。不同大小的卷积核会带来不同的感受野,既提取全局特征,又提取局部细节特征。之后,将两通道的特征进行级联(concatenate),最后利用添加ReLU 的1×1×1 3D CNN 增加网络的非线性,使得网络可以表达更加复杂的特征。在本文中,3 个改进的3D CNN 模块的可设置卷积大小分别为3×3×7、3×3×5、3×3×3。
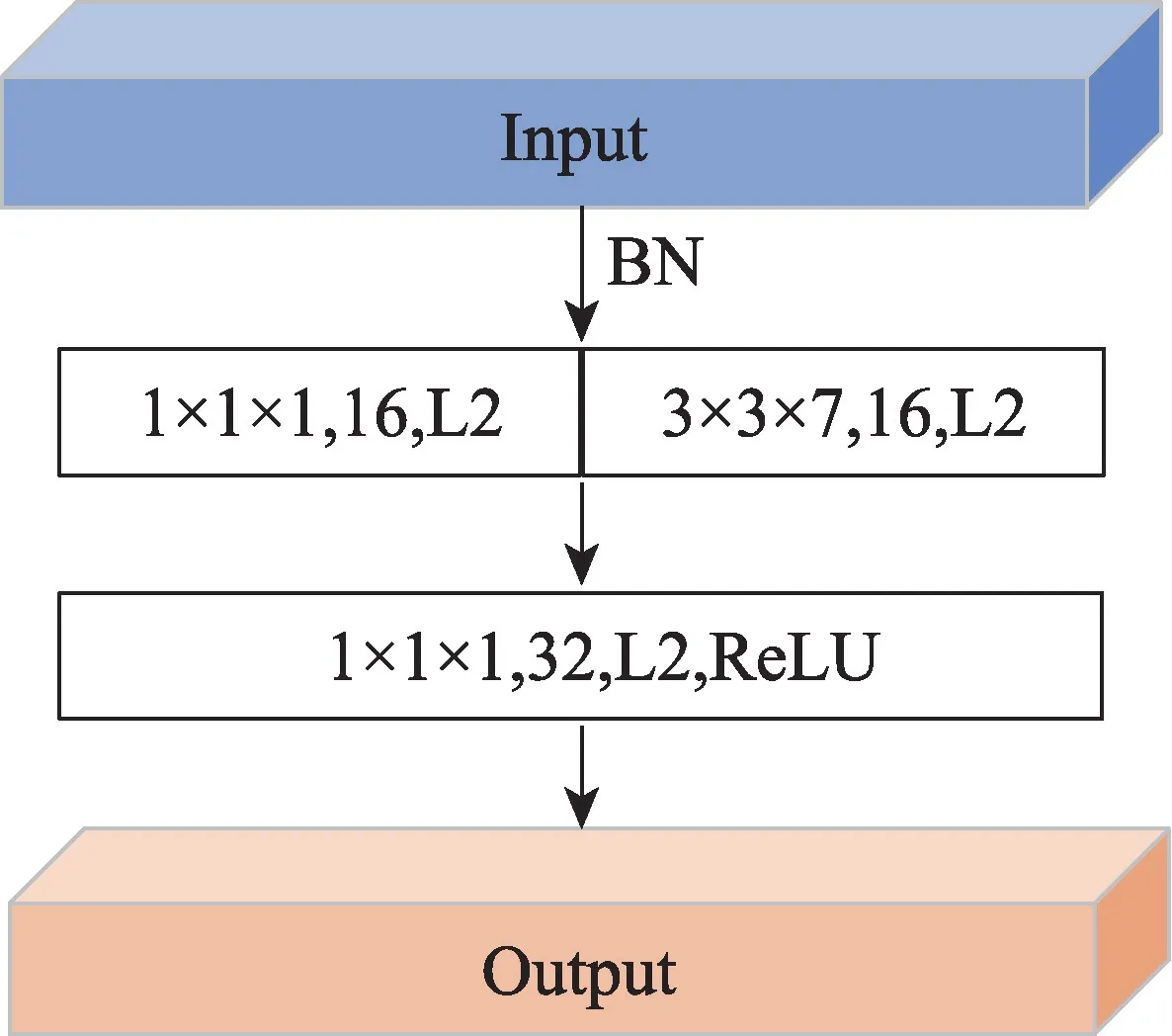
图2 改进的3D CNN 模块Fig.2 Improved 3D CNN module
为了防止过拟合,提高模型的泛化能力,对于该模块中的所有卷积层使用L2 正则化,步长为1 并且使用填充,每个特征映射的空间大小在输入任何卷积层后都不会改变,方便后续模块的叠加。相较于单个3D CNN,该模块既提取了多样化特征,又增强了模型的泛化性。
2.3 Spectral-Spatial Attention 模块
同一物体在不同波段的光谱响应可能有很大差异,这表明不同波段的分辨能力是不同的。除此之外,HSI 的不同位置也有不同的语义信息。例如,物体边缘通常比其他位置更有区别。光谱-空间注意力模块可以从HSI 中自动学习不同波段和位置的重要性,从而提升有用的光谱-空间信息,抑制无用的信息。
光谱注意力模块(Spectral Attention)如图3 所示。给定一个中间特征图F∈RC×H×W,其中C、H和W分别表示F的通道数、高度和宽度。首先分别应用全局平均池化(global average pooling,GAP)和全局最大池化层(global max pooling,GMP),并级联为特征图FG。GAP 对整个网络从结构上做正则化处理防止过拟合,同时也是聚合其空间维度的过程,GMP 可以补充GAP 的全局特征,其计算如式(14)所示。然后,依次通过两个有64 个滤波器、长度为5 的1D CNN,得到64 通道的长度为m的光谱注意图Spe(F),其计算公式如式(15)所示。之后将光谱注意图与中间特征图相乘,得到沿空间维度扩展的特征图F′,其计算公式如式(16)所示。最后添加两层全连接层来捕获光谱间的相关性,提高了细化后的光谱特征图的区分能力。

图3 Spectral Attention 模块Fig.3 Spectral Attention module

其中,σ表示Sigmoid 函数,δ是ReLU 函数。FGAP为特征图F经GAP 处理后的特征图,FGMP为特征图F经GMP 处理后的特征图,⊗表示元素乘法。
空间注意力(Spatial Attention)模块如图4 所示。使用1×1 卷积将通道数减为1 的特征图FC,其计算公式如式(17)所示。然后分别使用滤波器为1,5×5、3×3 的2D CNN 导出空间注意图Spa(F),其计算公式如式(18)所示。然后Spa(F)的值沿通道维度扩展为F′,其计算公式如式(19)所示。最后使用最大池化层使输出为固定大小。

图4 Spatial Attention 模块Fig.4 Spatial Attention module
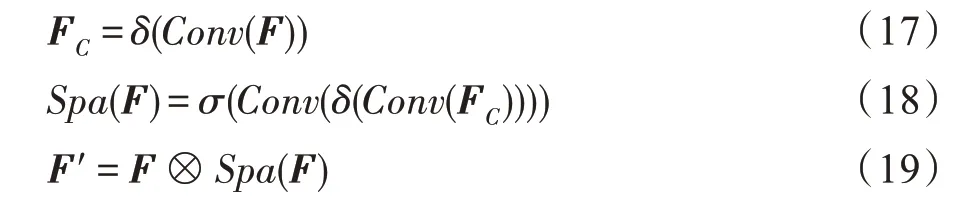
光谱注意力模块更关注哪些波段是有意义的特征,空间注意力模块更关注哪些位置的特征具有代表性。给定中间特征图,Spectral-Spatial Attention 模块按顺序推导出沿光谱和空间两个独立维度的注意力图,然后将注意力图输入特征图重新分配光谱-空间特征的权重,进一步增强了有用的光谱-空间特征。
3 实验及结果
在性能评估方面,对3 个著名的HSI 数据集Indian Pines、Pavia University、Salinas scene 进行了大量的数据分类实验,使用了3 个定量指标,包括平均准确度(average accuracy,AA)、总体准确度(overall accuracy,OA)和Kappa系数(Kappa)。
所有的实验都是在Intel®Xeon®Silver 4116 CPU@2.10 GHz,内存为128 GB 的PC 机上运行,具体程序由Pycharm2019 编写,在Windows 10 系统下基于Python3.7.6 的Tensorflow2.1 框架实现。
3.1 实验数据集介绍及实验细节描述
3.1.1 高光谱数据集
Indian Pines 是由AVIRIS 传感器收集的印第安纳州西北部的印度松树试验场的图像,数据集的大小为145×145 像素,剔除20 个噪声波段,剩余的200个波段作为研究对象。空间分辨率约为20 m,很容易产生混合像素,因此增加了分类的难度。它包含16 个类别,主要是自然植被,包括超过60%的农业,超过30%的森林和其他多年生自然植被。图5(a)、(b)分别为数据集的彩色图像、地面基准图。

图5 不同方法在Indian Pines上的分类图Fig.5 Classification maps of Indian Pines using different methods
Pavia University 是由德国的机载反射光学光谱成像仪在意大利的帕维亚城附近所拍摄的高光谱数据。数据集的大小为610×340,其中12 个波段由于受噪声影响被剔除,因此一般使用的是剩下103 个光谱波段所成的图像。该光谱所成图像的空间分辨率为1.3 m,这些像素中共包含9 类地物,包括沥青道路、砖块、牧场等。图6(a)、(b)分别为数据集的彩色图像、地面基准图。
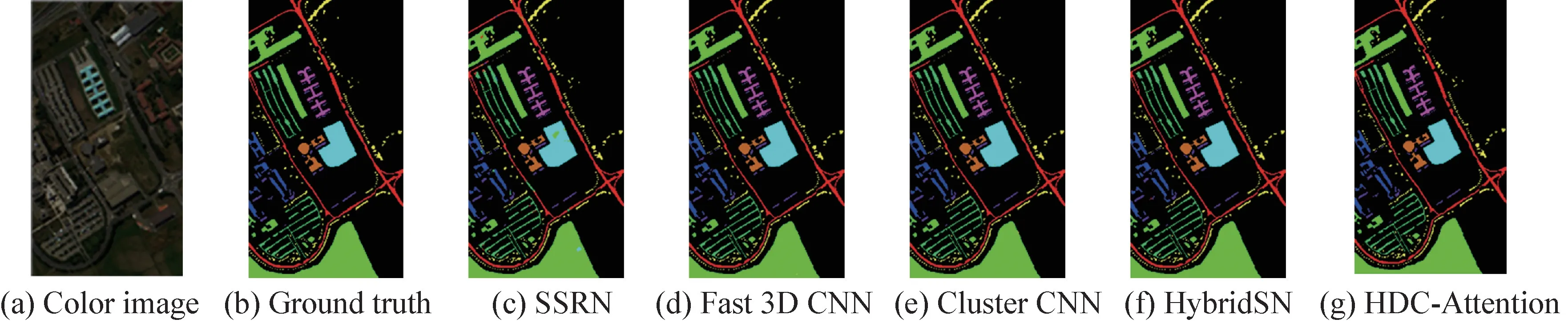
图6 不同方法在Pavia University 上的分类图Fig.6 Classification maps of Pavia University using different methods
Salinas scene 是由AVIRIS 传感器拍摄的加利福利亚萨利纳斯山谷的图像,数据集的小大为512×217,剔除20 个噪声波段,对剩下的204 个波段进行研究。空间分辨率为3.7 m。该数据包括花椰菜、耕地、芹菜等16 类地物。图7(a)、(b)分别为数据集的彩色图像、地面基准图。

图7 不同方法在Salinas scene上的分类图Fig.7 Classification maps of Salinas scene using different methods
3.1.2 实验细节描述
在实验中,经过多次运行实验,将batch size 设为128,epoch 设为100。学习率为0.001,分别随机选取3 个数据集的20%为训练数据量,80%为测试数据量进行实验,并且重复实验10 次,最后取这10 次的平均值。
3.2 实验结果及分析
3.2.1 KPCA+MBK-means的实验性能
表1 表示数据集Indian Pines、Pavia University、Salinas scene 在不同核函数(Poly 核、RBF 核、Linear核)和不同参数下的性能表。Poly 核善于提取样本的全局特性,具有很强的泛化能力,核函数的参数d取为1~8 的正整数,本文选取1、2、3、5。从表中可以看出,3 个数据集上OA、AA、Kappa 呈现先增大后减小的趋势,当d=2 时取得最大值(加粗字体标出),当d=5 时,三个数据集的Kappa 降为0,因此d的选取非常关键。RBF 核函数善于提取样本的局部信息,具有很强的学习能力,参数γ取值在(1/50,1/0.1)范围内,本文选取0.02、1.25、10.00。从表中可以看出,3个数据集上OA、AA、Kappa 也呈现先增大后减小的趋势,但变化趋势较Poly 核较小。

表1 不同数据集上KPCA 的不同Kernel及参数分类性能Table 1 Different kernels and parameter classification performance of KPCA on different datasets
3 个数据集加入MBK-means 方法所需要的训练时间分别为1 367 s、6 430 s、8 059 s,去掉MBKmeans 方法所需要的训练时间分别为1 926 s、9 070 s、10 508 s,减少的运算时间分别是559 s、2 449 s、2 640 s。
3.2.2 改进的3D CNN 以及HDC 的实验性能
表2 表示不同数据集上改进的3D CNN、HDC 的分类性能表。可以看出,仅通过3D CNN 提取特征表现较差,但是通过改进3D CNN 可以更好地提取到光谱-空间特征。在Indian Pines 数据集上,OA、AA、Kappa分别增加了3.1 个百分点、4.1 个百分点、4.26 个百分点。因为Indian Pines 数据集的噪声相对较大,多尺度特征也为数据去噪提供了很好的优化,使模型更稳定,因此,多尺度特征在HSI 的深度特征提取中起着重要的作用。
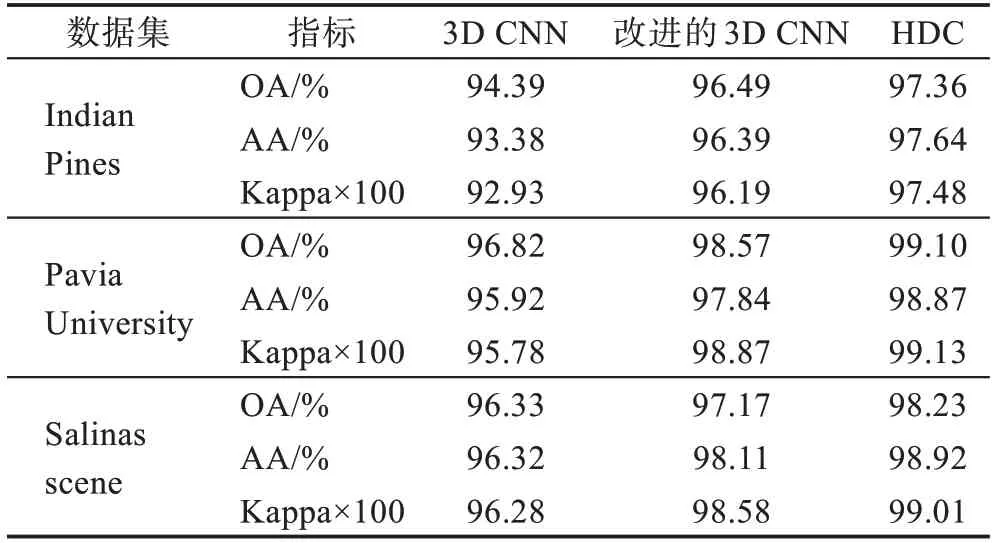
表2 不同数据集上改进的3D CNN、HDC 的分类性能Table 2 Improved 3D CNN and HDC classification performance on different datasets
3 个改进的3D CNN 模型的叠加融合了深度和尺度信息,特征提取效率提高。HDC 模块在后续添加了2D CNN,2D CNN 在3D CNN 的基础上进一步学习了更多抽象级别的空间表示,同时降低了模型的复杂性。在Indian Pines 数据集上,OA、AA、Kappa 分别增加了0.87 个百分点、1.52 个百分点、1.29 个百分点。
3.2.3 Spectral-Spatial Attention 的实验性能
表3 表示不同数据集上Spectral-Spatial Attention的分类性能。可以看出,在3 个数据集上,注意力模块进一步提高了模型的精确度,体现了该模块的有效性。从表中可以看到,Indian Pines 数据集仅添加Spectral Attention 模块,OA、AA、Kappa 分别增加0.94个百分点、1.13 个百分点、0.95 个百分点;仅添加Spatial Attention 模块,OA、AA、Kappa 分别增加1.05个百分点、0.67 个百分点、0.94 个百分点;添加Spectral-Spatial Attention 模块,OA、AA、Kappa 分别增加2.04 个百分点、1.69 个百分点、1.83 个百分点。这主要是因为Spectral Attention 模块主要由1D CNN更多地关注光谱特征,Spatial Attention 模块主要由2D CNN 更多地关注空间特征,两个注意力的组合进一步关注更典型的光谱-空间特征,从而进一步提高了分类的精确度。
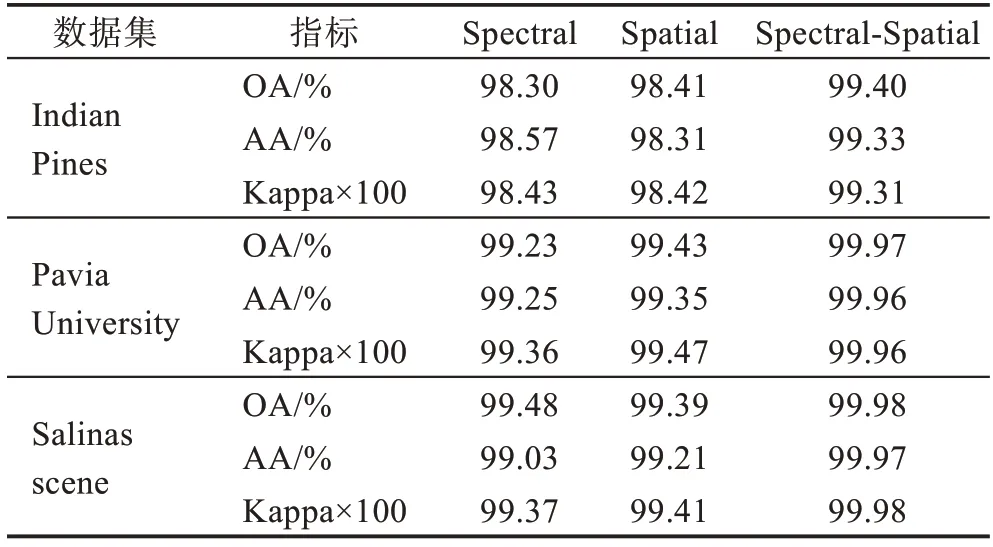
表3 不同数据集上Spectral-Spatial Attention 的分类性能Table 3 Classification performance with Spectral-Spatial Attention module on different datasets
3.2.4 不同方法下的实验性能分析
为了验证所提出模型(HDC-Attention)的有效性,将HDC-Attention 方法与其他方法进行比较,比较方法包括HybridSN[25]、SSRN[26]、Cluster CNN[16]、Fast 3D CNN[27],这五种方法都是基于深度学习的分类方法。表4~表6 分别表示了Indian Pines、Pavia University、Salinas scene 数据集上的不同分类方法以及每一类的分类结果,每类中将最高精度用加粗标出。从表中可以看出,HDC-Attention 在3 个数据集上的分类精度普遍高于其他方法,特别是Pavia University 数据集,有6 类地物分类完全正确。Pavia University 和Salinas scene 数据集的分类精度均高于Indian Pines,这是因为这两个数据集本身的数据清晰度高于Indian Pines 数据集,所以分类难度相较于Indian Pines 数据集也低。在训练时间方面,Fast 3D CNN 模型更有优势,在3 个数据集上的训练时间均为最少,HDC-Attention 方法的训练时间较长,因为HDC 模块保留了更为丰富的光谱-空间特征,所以需要更长的计算时间。
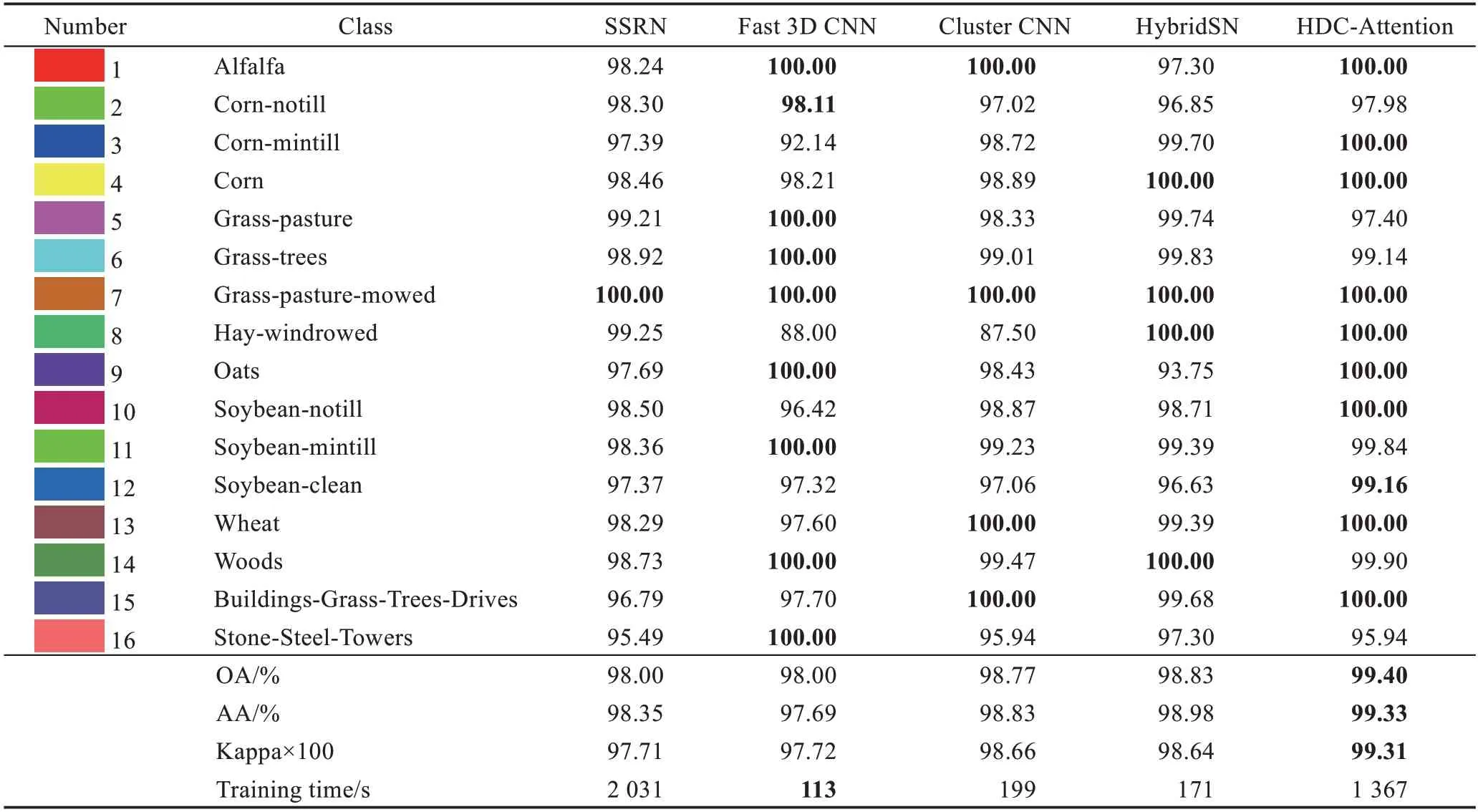
表4 不同方法下Indian Pines每类分类精度对比Table 4 Comparison of classification accuracy of each category of Indian Pines under different methods
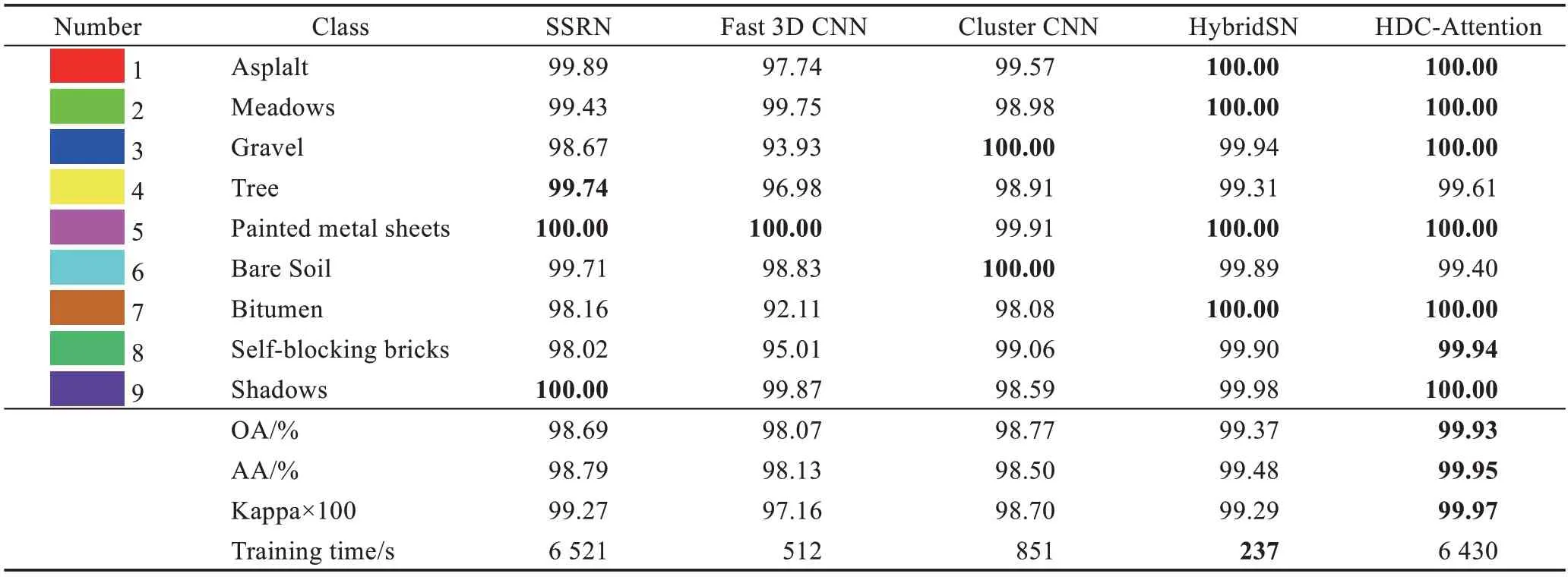
表5 不同方法下Pavia University 每类分类精度对比Table 5 Comparison of classification accuracy of each category of Pavia University under different methods
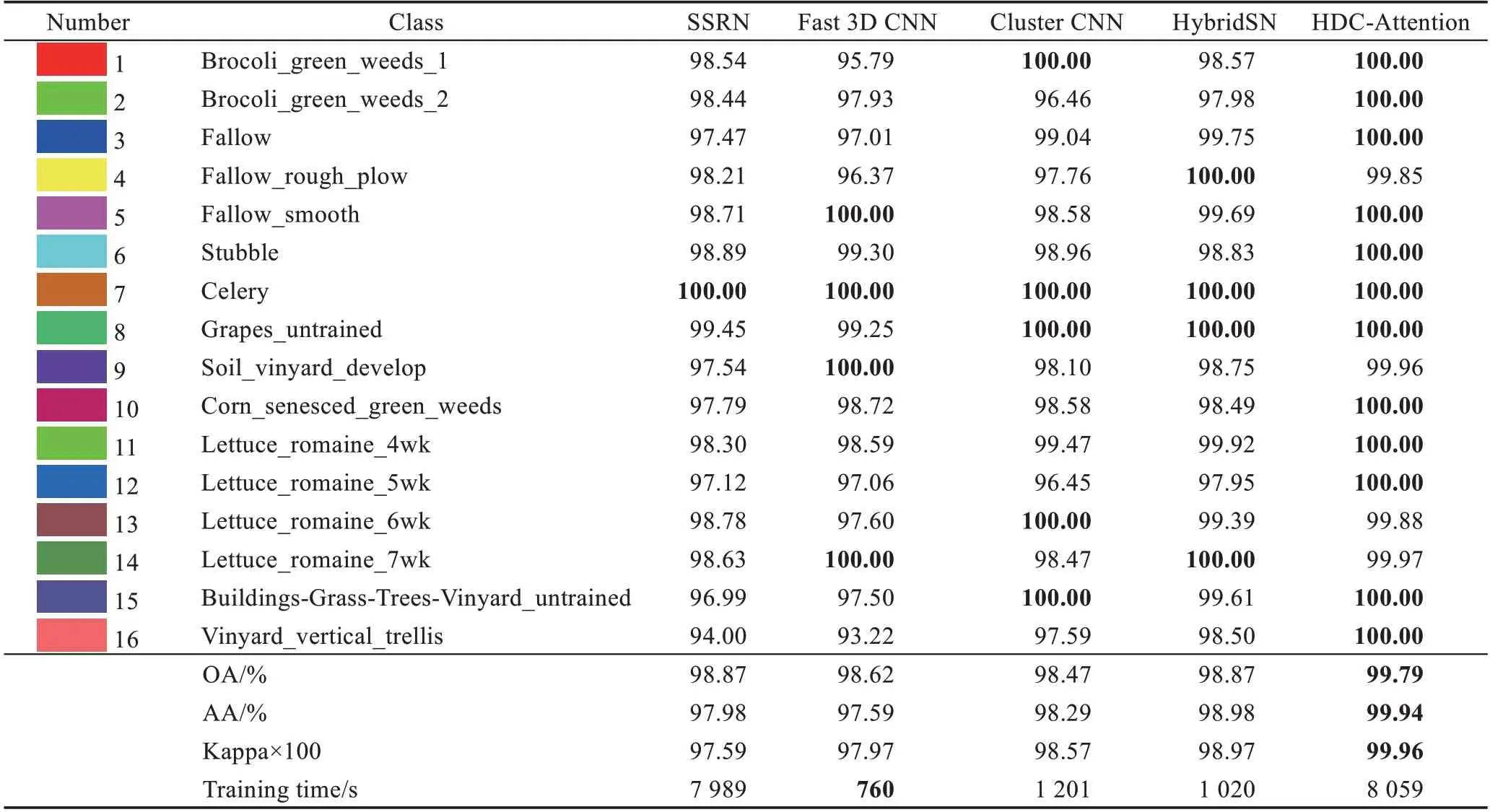
表6 不同方法下Salinas scene每类分类精度对比Table 6 Comparison of classification accuracy of each category of Salinas scene under different methods
图5~图7 的(c)~(g)给出了不同方法在三个数据集上的分类图谱。从图中可以看出,在Indian Pines数据集上,SSRN、Fast 3D CNN、Cluster CNN 方法最终的分类结果图中含有一些斑点,并且存在小区域内错分的情况,HybridSN 方法的结果相对较高一些,已没有大量的斑点,而HDC-Attention 模型斑点非常少。Indian Pines 数据集中类别2 的“Corn-notill”和类别4 的“Corn”一些像素被错误地分类为彼此,因为这两个土地覆盖区域有相似的光谱-空间特征,可以观察到通过提出的模型获得的分类图是最平滑和最清晰的。特别是与其他模型相比,由于椒盐噪声最少,分类结果更接近实际情况。原因有以下两点:首先,混合深度网络能够提取有效且具有辨识性的空谱特征,这可以使模型更好地识别不同类型的地物特征,甚至是具有相似光谱-空间信息的土地覆盖物。其次,Spectral-Spatial Attention 模块增强了有用的空谱特征,这有利于更好地分类。可以看到HDC-Attention方法在所有数据集上比其他方法具有更少的误分类,特别是对于一些相似的类。
总的来说,与其他四种方法相比,HDC-Attention方法取得了比较好的结果,分类结果图含有非常少量的斑点,且在同类的小区域内相对平滑,好几类地物几乎完全正确分类。
4 结束语
本文提出的HDC-Attention 分类方法,首先利用KPCA 和MBK-means 对高光谱图像进行组合降维,然后将降维后的数据输入HDC 网络,不仅进行充分的光谱-空间特征提取,还加强了空间特征。最后利用Spectral-Spatial Attention 模块,在HDC 模块的基础上,增强有用的光谱-空间特征,抑制无用的特征进行分类任务。
本文首先做了KPCA 和MBK-means 的组合降维,证明了KPCA 降维的有效性,MBK-means 进一步降维,减少了计算时间。然后利用基于改进的3D CNN 模块构建了HDC 模块,充分证实了HDC 能够有效提取光谱和空间的特征,此外还做了加入Spectral-Spatial Attention 模块的对比实验,证明了该模块能够进一步增强有用的空谱特征。所提出的方法不仅在有限的样本下表现出了较好的分类性能,而且降低了模型复杂度。
虽然所提出的方法和其他方法相比,分类的性能较好,但是还存在不足之处。之后将进一步优化模型继续提高模型效率和鲁棒性,用更少的训练样本来达到更高的分类精度,继续探索优化KPCA 的参数问题。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通(1-2年级)(2021年4期)2021-06-09
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
北京航空航天大学学报(2018年1期)2018-04-20
初中生世界·七年级(2017年9期)2017-10-13
中国光学(2015年5期)2015-12-09
