
基于门控循环单元神经网络的测井曲线预测方法
2023-02-17 12:29滕建强杨明任申辉林孙启鹏
油气地质与采收率 2023年1期
滕建强,邱 萌,杨明任,申辉林,曲 萨,孙启鹏
(1.中国石化西北油田分公司石油工程技术研究院,新疆乌鲁木齐830011;2.中国石化碳酸盐岩缝洞型油藏提高采收率重点实验室,新疆乌鲁木齐830011;3.中国石油大学(华东)地球科学与技术学院,山东青岛266580)
测井资料在储层描述和油气储集能力评价中具有十分重要的作用,通常只能在钻井后通过测井工程获取,而在随钻测井过程中需对未钻地层的测井资料提前预测,这对随钻测井具有重要意义。如果能够提前预测到未钻地层深度序列的测井数据,则会有效提高钻探过程的可靠性和安全性,且节约生产成本。在钻探前预测未钻地层测井曲线方法与测井曲线重构方法具有一定的相似性,前人研究中曾使用传统BP 神经网络预测未知深度序列方向的测井曲线[1-5],以上方法虽然能够学习到测井曲线之间的非线性关系,但由于测井信息受地层沉积特征的影响具有时序渐变性,曲线深度序列的变化趋势和测井曲线的前后关联性将会发生改变[6]。因此,基于传统BP神经网络的方法极大简化了地质沉积渐变过程,与实际地层参数相比,该方法构建的测井预测模型误差太大,导致预测未钻地层测井曲线质量难以保证。
近年来,机器学习快速发展,在科学和工程领域应用广泛并获得了突破性的进展,为预测未钻地层测井曲线提供了新思路和方法,且已将一些常规的机器学习算法应用到测井曲线预测,如支持向量机(SVM)[7-8]、模糊逻辑模型(FLM)[9-10]、随机森林[11]、极端梯度提升[12]等,在一定条件下取得了较好的效果,但这些常规的机器学习算法网络结构简单,无法解决地层复杂的非线性问题。由于测井曲线与地质参数间的非线性关系复杂,用简单的机器学习算法无法明确其数学关系,因此,应用这些方法具有一定的局限性[13]。深度学习方法是当前机器学习领域最热门的方向之一,其网络结构复杂且具有多个隐含层,不仅能通过提取每一项特征将样本的原始空间特征转换成新的高维空间特征表征,还能为数据建立更加抽象的特征描述,从而将预测或分类问题简单化且提高准确性[14]。长短期记忆神经网络(LSTM)和门控循环单元神经网络(GRU)模型作为深度学习的研究热点之一,是一种具有记忆功能的神经网络模型,较适用于未钻地层测井曲线预测,与其他网络结构的不同之处在于增加了自循环体,可以将前一个深度序列的样本输出并与下一个深度序列的样本进行运算,使模型处理得到的测井数据不仅具有前一个深度序列的特征信息,还具有样本自身的特征信息,能较好地预测未钻地层测井曲线。王俊等研发一种基于深度双向循环神经网络的储层孔隙度预测方法,有效解决了孔隙度预测中的空间尺度问题和传统神经网络无法提供前后序列信息的问题,提高了孔隙度预测的准确性和稳定性[15],但该网络对数据量需求过大,且容易出现过拟合现象。宋辉等将卷积神经网络与门控循环单元网络相结合,有效地提取测井数据特征,提高了储层参数的预测精度[16],但该网络结构复杂且训练时容易出现局部最小值,池化层也会丢失大量有价值信息,忽略局部与整体之间的关联性。
测井数据是具有非线性和序列化特性的数据结构,为此,应用GRU 模型对新疆油田和南海西部油田进行实际测井数据预测,并与LSTM 模型进行对比分析,结果表明,GRU 模型预测效果更好,可有效预测未钻地层地球物理测井特征并指导钻井和测井工程。
1 方法原理
1.1 LSTM 模型
循环神经网络是一类专门处理深度序列数据的深度学习模型,在不同深度序列数据的步长上,该网络模型能够循环共享权重,并进行跨越深度序列链接,这在处理测井深度序列数据上具有较大优势。LSTM模型新增加了遗忘门、输入门、tanh层、输出门4个交互层(图1),使自循环的权重成为变化的参数。各个门限可以对前一时刻的单元状态进行处理,并将新的测井信息添加到当前时刻的单元状态。因此,在模型参数不变的情况下,不同时刻的积分尺度可以动态变化,从而解决了梯度消失或梯度爆炸问题,也无需确定窗口的延迟长度[17]。
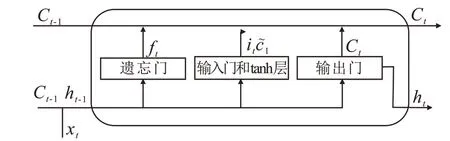
图1 LSTM模型结构Fig.1 Structure of LSTM model
第1 个交互层为遗忘门,决定哪些测井信息需要被忘记(丢弃),即上一时刻的单元状态有多少测井信息传递到当前时刻的单元状态,当前时刻的输入值和上一时刻的隐含层节点的输出值组合成一个新的特征向量,然后乘以权重,最后输入到sigmoid函数中。其表达式为:
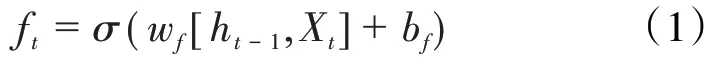
第2 个交互层为输入门,决定当前时刻的输入值中有多少测井信息保存到当前时刻的单元状态,其表达式为:

第3 个交互层为tanh 层,决定当前时刻的候选值。与输入向量相乘,以确定候选值中有多少新的测井信息被存放到单元状态中,其表达式为:
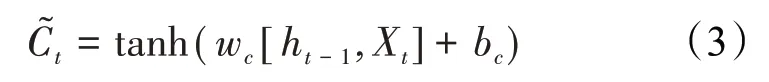
将携带记忆信息的单元状态与携带新的测井信息的候选值相结合,t时刻的遗忘门决定忘记t-1 时刻的单元状态中的哪些测井信息,t时刻的输入门决定保留和添加t- 1 时刻的单元状态中的哪些测井信息。t时刻的单元状态表达式为:
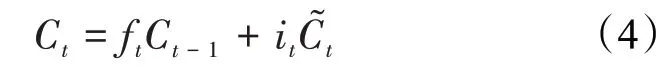
第4 个交互层为输出门,决定当前时刻需要输出的测井信息,其表达式为:
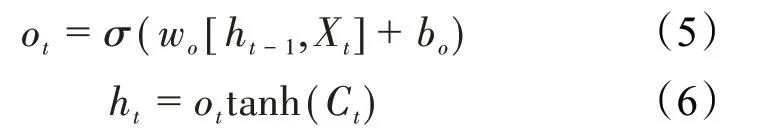
LSTM 模型不仅能从序列数据中提取测井信息,还能够记忆先前步骤的长期相关性的测井信息,这反映了该模型能较好地考虑到前期的测井曲线对未钻地层的影响。
1.2 GRU模型
GRU 模型是对LSTM 模型的改进和优化,保留了LSTM 模型处理深度序列方向测井数据的能力,使其在保留长期记忆功能的同时简化了网络结构,且训练参数减少,收敛速度加快,预测精度提高。由图2 可以看出,GRU 模型将LSTM 模型中的输入门、遗忘门和输出门用更新门和重置门代替。GRU模型将原来的输入门和遗忘门变成单一的更新门,决定了当前时刻的输入值中有多少测井数据将被保留,更新门的值越大,当前时刻测井数据保留越多;重置门决定前一时刻的输出值对当前时刻的输入值的影响,重置门的值越大,当前时刻的输入受前一时刻的输出影响越大[18]。这说明GRU 模型不仅结构更简单,收敛速度更快,而且还避免了过拟合现象发生。
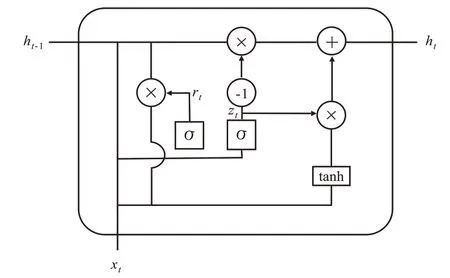
图2 GRU模型结构Fig.2 Structure of GRU model
更新门和重置门在t时刻的状态定义分别为:
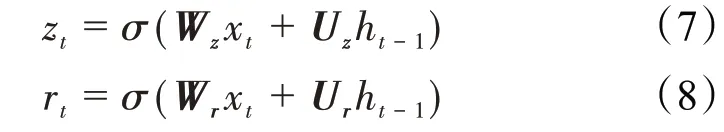
当前神经元的特定输出值表达式为:

GRU模型的输出值表达式为:
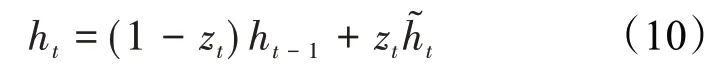
2 基于GRU模型的预测方法
利用已钻地层的测井数据作为训练模型,预测下一深度序列方向的测井数据,其预测模型为:

首先选取已钻地层的测井数据及邻井的数据(图3中深度井段为M的测井训练数据)并将其输入到GRU 模型中用于训练模型,优化网络模型参数,更新隐含层节点单元的状态,然后将训练好的模型用于预测未钻地层的测井数据(图3 中深度井段为N的测井测试数据)。图3中,h0是GRU 模型隐含层节点的初始状态,ht-1和Ct-1是深度井段为M的测井训练数据t-1 时刻的输出值和单元状态,当前时刻的输出被传递到深度井段为N的测井测试数据作为第一步预测的输入数据。预测数据段的起始数据序号为t,则在t- 1 时刻可用GRU 网络基于深度井段为M的测井训练数据获取输出节点的单元状态和内部状态,再结合t时刻的邻井测井数据预测t时刻的单元状态和内部状态,进而预测t时刻的值。最后结合t时刻的单元状态和t- 1时刻的邻井测井数据就可获得t- 1时刻的单元状态和预测值。
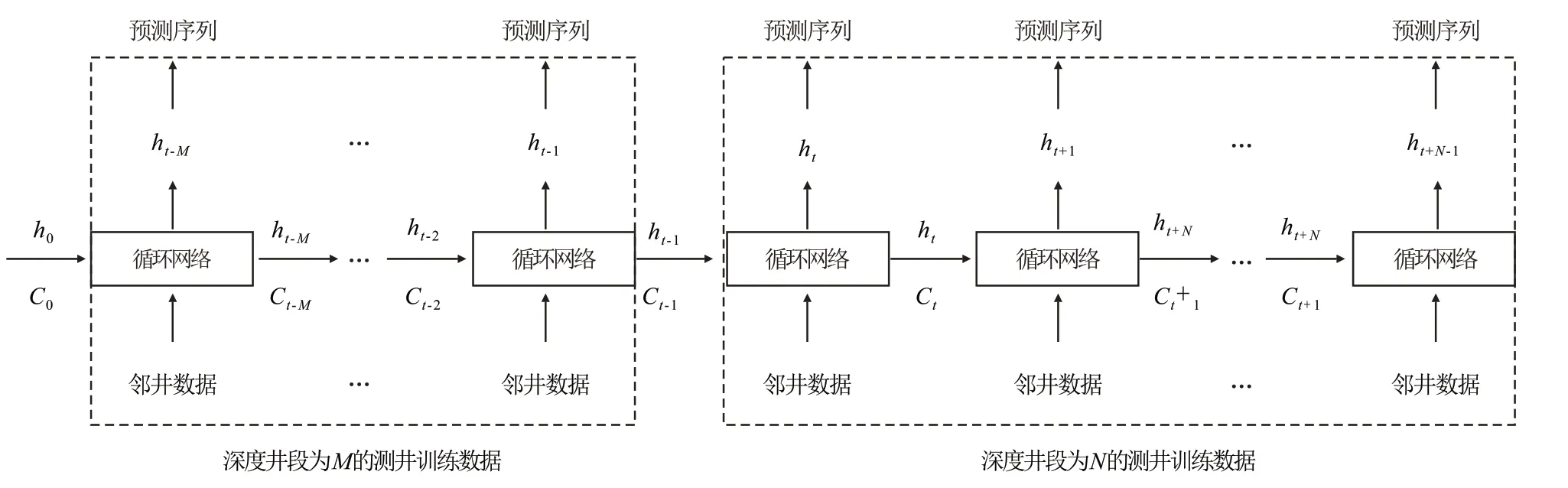
图3 GRU模型流程Fig.3 Flow chart of GRU model
2.1 数据预处理
数据预处理工作将确保各测井参数处于规范的分布范围内,这样能够使网络模型更易学习到各参数之间的关联性。数据标准化是机器学习中最基本的预处理工作,为了减小不同测井参数间的量纲影响,采用分数归一化方法对测井数据进行标准化处理,以期各参数间具有可比性,处理后的测井数据须服从标准正态分布,数据标准化表达式为:

2.2 优化算法
为了加快网络收敛速度,优化学习率,减少迭代次数,需要选择优化算法进行网络模型训练。常用的优化算法包括SGD,RMSProp,Adam,AdaGrad等,其中SGD 算法简单,收敛速度快,但容易陷入局部最小值,导致无法获得最优解。为此,采用Adam算法,并结合RMSProp和AdaGrad两个算法的优点,这样不仅适用于稀疏梯度,还具备解决非平稳数据的特性[19]。
2.3 模型训练
GRU 模型训练过程大致包括以下步骤:①以测井曲线作为输入参数,输入到LSTM 和GRU 模型中进行训练,沿着深度前向传播方向有序计算GRU 单元的输出值。②将测井曲线输出值与实际值进行比较,沿着反向传播方向计算每个GRU 单元的误差。③根据反向传播计算的误差,计算每个权重梯度,并用Adam 算法更新权重,使测井曲线预测值与实际值逐步逼近。④不断重复上述步骤,使GRU 模型不断得以训练并优化。
2.4 预测结果与评价
以测井曲线的实际值与预测值之间的均方根误差和相关系数作为评价预测方法的标准,即均方根误差越小,相关系数越大,则测井数据预测方法更优,预测精度更高,其计算公式如下:

3 应用实例
为了验证上述两种方法预测测井曲线的应用效果,对多个油田的测井曲线进行预测,均取得了理想的应用效果。以新疆油田已钻直井电缆测井曲线和南海西部油田水平井随钻测井曲线为例进行预测效果和精度分析。
3.1 新疆油田电缆测井
新疆油田A1井为直井,对常规电缆测井曲线以及邻井测井数据中的自然伽马(GR)、深感应电阻率(Rt)、声波时差(AC)、密度(DEN)、井径(CAL)5 条测井曲线数据进行预测处理,将其分别输入到GRU 和LSTM 模型中进行预测,以评价两种模型利用已钻地层测井数据以及邻井测井数据预测未钻地层深度序列测井曲线的能力,并分析两种模型预测结果的精度和优劣。
实际预测搭建的GRU 模型由2 个GRU 层和1个全连接层组成,其中每个隐含层的节点数为10,批处理大小为20,退出率为0.3,测井序列长度为20,可以通过改变序列长度调整GRU 模型的记忆范围,学习率为0.01,学习率是网络模型中重要的超参数。学习率过低,会减缓模型收敛速度;学习率过高,在梯度下降时易错过最低点,导致模型收敛效果不佳。此外,与其对应的LSTM 模型也采用相同的预测参数和算法进行测井曲线预测。
图4 为新疆油田A1 井常规电缆测井曲线GRU和LSTM 模型训练-预测结果,1 895~1 928 m 井段为模型的训练拟合层段,1 928~1 940 m 井段为模型的预测层段。从图4 中可以看出,GRU 和LSTM 模型在训练阶段实际测井值与预测值基本重合,说明两模型均已学习训练完成,且GRU 模型学习训练效果更好。两种模型在预测深度序列方向未钻地层测井曲线上均取得了较好的预测效果,虽然存在一定误差,但总体上能够逼近实际测井曲线,尤其是在测井曲线没有发生大幅度突变时,GRU 模型预测效果更好。尤其是新疆油田A1 井在埋深为1 930~1 935 m 处GR和Rt测井曲线发生较大幅度突变,由于该井训练阶段学习过程有类似的曲线特征趋势变化,因此两种模型均比较好地预测到岩电曲线以及其他测井曲线这一变化趋势,但GRU 模型能够综合考虑测井曲线随深度序列的变化趋势和曲线前后的关联性,使得预测结果比LSTM 模型更接近实际测井曲线,这表明GRU 模型的长时记忆功能在预测未钻地层深度序列测井曲线上应用效果更佳。其余三条测井曲线AC,DEN和CAL训练阶段模型学习也充分,训练效果也不错,使两种模型预测结果更加逼近实际测井曲线,且GRU 模型的预测效果同样比LSTM模型更好。

图4 A1井常规电缆测井训练-预测结果Fig.4 Prediction results of regular logging training in Well A1
由GRU和LSTM模型的相关系数和均方根误差评价参数计算结果(表1)也可以看出,GRU 模型预测未钻地层深度序列的测井曲线效果比LSTM 模型好,因此,相对于LSTM 模型,新疆油田A1 井应用GRU模型预测的GR,Rt,AC,DEN和CAL曲线的相关系数分别提升了5.13%,33.33%,7.87%,16.67%和5.88%,均方根误差分别下降了3.14%,47.99%,19.96%,50%和14.29%。其中,GRU 模型比LSTM模型平均相关系数提高13.78%,平均均方根误差下降27.08%。这些预测结果均表明,GRU 模型预测对具有深度序列特性的测井数据效果好、精度高、适用性更强。
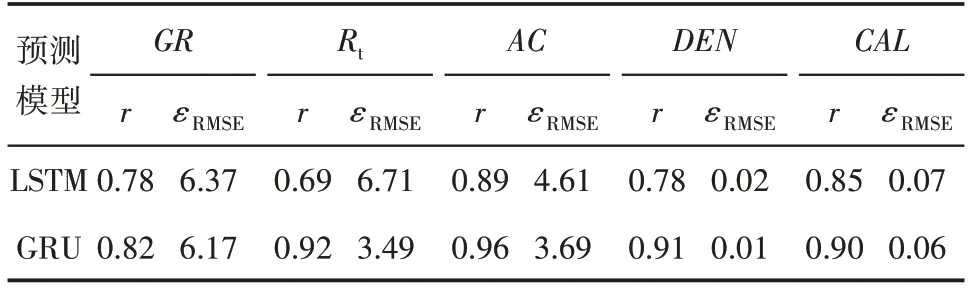
表1 A1井GRU和LSTM模型相关系数和均方根误差对比Table1 Comparison of correlation coefficient and root mean square error between LSTM and GRU models in Well A1
3.2 南海西部油田随钻测井
南海西部油田B6井为水平井,本次实际预测搭建的LSTM 和GRU 模型结构与新疆油田A1 井所用模型具有相同的预测参数和算法,这样能够保证训练与预测的曲线具有可靠性与对比性。
图5 是南海西部油田B6 井随钻测井曲线GRU和LSTM 模型训练-预测结果。1 260~1 290 m 井段为模型的训练拟合层段,1 290~1 306 m 井段为模型的预测层段。由图5 可知,发现GRU 和LSTM 模型同样在训练阶段预测值与实际值基本重合,且GRU模型的预测效果同样比LSTM 模型更好,说明GRU模型适用性比LSTM模型更强。

图5 B6井随钻测井训练-预测结果Fig.5 Prediction results of logging-while-drilling(LWD)training in Well B6
由南海西部油田B6 井GRU 和LSTM 模型处理的相关系数和均方根误差评价参数计算结果(表2)可知,GRU 模型预测的GR,Rt,AC,DEN和CAL曲线的相关系数分别提高8.14%,18.52%,20.78%,6.67% 和6.52%,均方根误差分别下降23.18%,54.64%,49.68%,33.33%和50%。其中,GRU 模型比LSTM 模型平均相关系数提高12.13%,平均均方根误差下降42.17%。这些预测结果再次表明,GRU模型处理对具有深度序列特性的测井数据可靠性强、精度高、适用性强。
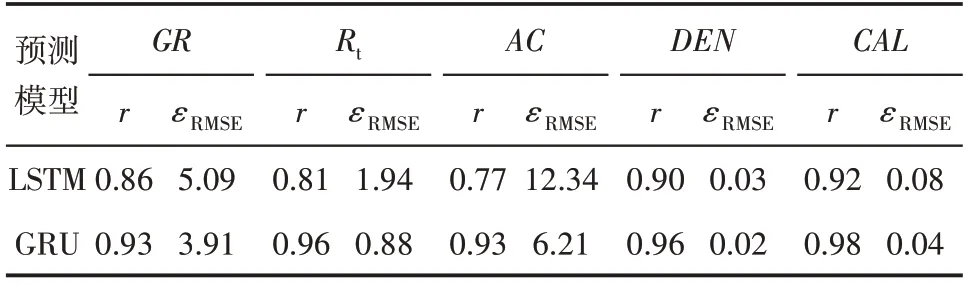
表2 B6井LSTM和GRU模型相关系数和均方根误差对比Table2 Comparison of correlation coefficient and root mean square error between LSTM and GRU models
4 结论
以新疆油田已钻直井电缆测井曲线和南海西部油田水平井随钻测井曲线为例,利用GRU 和LSTM 模型进行了预测效果和精度分析,结果表明,两种模型在直井常规电缆测井和水平井随钻测井中均能提前获取未钻地层的测井信息,可有效指导钻井和测井工程,为地质导向提供科学依据。受井眼环境特别是扩径影响严重的测井曲线,如DEN和AC曲线,可应用GRU 模型预测测井曲线的方法进行井眼影响校正,有助于提高测井解释精度。但GRU 模型的预测效果比LSTM 模型更好、适用性更强、精度更高。另外GRU 模型还可以应用于测井曲线重构,有助于降低测井费用,可达到降本增效的目的。
符号解释
b——偏置项;
bc—候选值状态下的偏置项;
bf——遗忘门状态下的偏置项;
bi——输入门状态下的偏置项;
bo——输出门状态下的偏置项;
——候选状态;
C0——初始时刻的单元状态;
C1——第1时刻的单元状态;
Ct——t时刻的单元状态;
——t时刻的候选值;
Ct+1——t +1时刻的单元状态;
Ct-1——t- 1时刻的单元状态;
Ct-2——t- 2时刻的单元状态;
Ct-M——t-M时刻的单元状态;
ft——t时刻的遗忘门;
f——GRU模型;
h0——GRU模型隐含层节点的初始状态;
ht——测井序列t时刻隐含层节点的输出值;
——测井序列t时刻隐含层节点的候选状态;
ht-1——测井序列t- 1时刻隐含层节点的输出值;
ht-2——测井序列t- 2时刻隐含层节点的输出值;
ht-M——测井序列t-M时刻隐含层节点的输出值;
ht+N-1——测井序列t+N- 1 时刻隐含层节点的输出值;
i——当前时刻的输入值;
it——t时刻的输入门;
M,N——分别为测试样本的采样数目;
n——深度序列长度;
ot——t时刻的输出门;
p——测试样本的采样数目;
r——测井曲线实际值与预测值之间的相关系数;
rt——GRU模型的重置门;
t——测井序列的测试时刻;
Ur——重置门的权重矩阵;
Uz——更新门的权重矩阵;
wc——候选状态的权重参数;
wi——输入门的权重参数;
wo——输出门的权重参数;
wf——遗忘门的权重参数;
Wh——隐含层的权重矩阵;
Wr——重置门的权重矩阵;
Wz——更新门的权重矩阵;
xt——测井序列t时刻隐含层节点的输入值;
xi——各输入参数;
Xi——测井曲线各参数的实测序列;
Xt——t时刻的输入值;
——t时刻测井曲线的预测值;
yt-1,yt-2,yt-3,yt-n+1——GRU模型t时刻之前输入值;
yi,——测井曲线各参数的实际值和预测值;
Yi——测井曲线各参数的生成序列;
zt——GRU模型的更新门;
Z*——标准化后的参数;
σ——sigmoid函数;
*——哈达玛积;
μi——各输入参数的平均值;
δi——各输入参数的标准方差,其分布范围为[-1,1];
εRMSE——测井曲线实际值与预测值之间的均方根误差。
猜你喜欢
测井技术(2022年3期)2022-11-25
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
中国煤层气(2021年5期)2021-03-02
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
中国煤层气(2015年4期)2015-08-22
中国质量与标准导报(2015年2期)2015-02-28
