
基于深度对比网络的印刷缺陷检测方法
2023-02-03 03:02王佑芯
计算机应用 2023年1期
王佑芯,陈 斌
(1.中国科学院 成都计算机应用研究所,成都 610213;2.中国科学院大学 计算机科学与技术学院,北京 100049;3.哈尔滨工业大学(深圳)国际人工智能研究院,广东 深圳 518055;4.哈尔滨工业大学 重庆研究院,重庆 401100)
0 引言
印刷品质量检测是印刷品生产过程中的一个重要环节,作为印刷品质量检测环节的一项重要技术,印刷缺陷检测是工业检测领域的一个经典问题。目前,基于机器视觉的工业检测技术[1]已取得了较好的发展,并且已经应用于金属表面划痕检测、印刷电路板缺陷检测等问题中。相较于人工抽样检测,基于视觉的自动化检测技术在保证产品全覆盖的同时,还具有速度快、精度高、人力成本低等优点,因此具有较高的研究与应用价值。
然而,即使在人工智能领域迅速发展的今天,现有的印刷缺陷检测技术依旧没有达到完全令人满意的水平。在现有技术中,依赖传统图像处理技术的视觉检测系统[2-4]对成像时的光照条件、机械误差等影响因子极度敏感、鲁棒性较差,并且需要专业人员不断根据真实环境对系统参数进行调整,往往难以达到预期的检测效果。近几年来,得益于卷积神经网络(Convolutional Neural Network,CNN)[5]强大的表征能力,基于深度学习[6]的通用目标检测方法[7-9]在诸多工业缺陷检测问题中都取得了较好的结果;但对于具有内容相关性的印刷缺陷检测问题,这些方法依旧面临着无法解决的语义矛盾。内容相关性引起的语义矛盾可以理解为:当缺陷与印刷内容的视觉特征相同时,YOLOv3(You Only Look Once v3)[7]等基于深度学习的通用目标检测方法无法在只检测图像信息的条件下完成检测。例如,模型无法将印刷内容缺失处的背景判别为缺陷,因为背景本身并非缺陷。图1 展示了两种具有内容相关性的印刷缺陷。

图1 具有内容相关性的缺陷样例Fig.1 Defect samples with content correlation
针对上述问题,本文将传统模板匹配技术中的对比思想与深度学习中的语义特征结合,提出了一种基于深度对比神经网络的印刷缺陷检测方法,并在两个不同数据集上对该方法进行了全面评估。本文的主要工作如下:
1)基于孪生卷积神经网络设计了一个端到端的印刷缺陷检测模型——深度对比网络(Deep Comparison Network,CoNet)。该模型在语义空间对比检测图像与参考图像,不仅解决了传统方法鲁棒性较差的问题,而且避免了基于深度学习的通用目标检测方法在印刷缺陷检测问题中面临的语义矛盾问题。
2)提出了一种非对称的双通路特征金字塔结构,并将其用于CoNet 的多尺度变化检测模块(Multi-scale Change Detection Module,MsCDM)。该网络结构可以在尽可能少地增加计算量的条件下,为检测模块引入更多的有效信息,提升检测性能。在公开的印刷电路板缺陷数据集DeepPCB[10]和本文收集的立金缺陷数据集上的实验结果表明,相较于目前性能最优的两种印刷缺陷检测方法,CoNet 的检测精度更高,并且检测速度也可以满足工业检测任务的实时性要求。
1 相关工作
1.1 传统工业检测算法
作为机器视觉领域的一个重要分支,基于传统图像处理技术的工业检测系统已取得了较好的发展,并且已成功应用于大量的工业场景中,如印刷品[11-14]、电路板[15]、纺织和纹理[16-17]检测等。
在印刷缺陷检测问题上,Shankar 等[12]利用动态滤波器检测图像边缘,然后通过阈值化与变换算法进一步分析,实现了可用于卷筒胶印设备的实时检测系统;Sun 等[13]通过增量主成分分析算法建模不同模式的正样本,并利用主成分为不同的测试样本重建模板,进而将测试样本与重建模板的差异视作印刷缺陷;Wang 等[14]针对传统差值方法存在的伪残差问题,提出了灰度差值和梯度差值相结合的方法,有效消除了伪残差,该方法的检出率明显高于传统差值方法。此外,针对印刷电路板缺陷检测问题,Malge 等[15]基于形态学算法提出了图像分割与局部像素对比相结合的缺陷检测方法;而Tsai 等[16]则利用傅里叶变换在频域对图像进行分析,通过一维霍夫变换检测并过滤高频分量后,再反变换得到只有缺陷区域被清晰保留的重构图像。
整体上看,基于传统图像处理技术的方法通常在像素空间或低维特征空间进行检测,例如直接计算检测图像与参考图像之间的差值[12],或者在检测时增加梯度[14]、频率[16]等信息。可以发现,这些方法无法建模图像的语义信息,而图像的灰度、梯度等信息容易受成像条件等因素影响,因此鲁棒性低。
1.2 基于深度学习的目标检测方法
近年来,基于深度学习的计算机视觉算法发展迅猛,尤其在目标检测问题上取得了惊人的进展。
Ren 等[8]提出的二阶段模型Faster R-CNN(Faster Regionbased CNN)以CNN 提取的语义特征图为基础,先利用两个1×1 卷积层生成粗粒度的候选框,再通过感兴趣区域池化(Region of Interest Pooling,RoIPooing)提取候选框内特征,最后将所得特征用于预测目标的类别与边界框。与Faster R-CNN 不同,Redmon 等[7]提出的YOLOv3 直接以骨架网络提取的多尺度特征图为输入,利用三个相互独立的1×1卷积层分别预测三种尺度目标的置信度、类别与边界框;得益于不用预先提取候选框,该方法不仅能保证检测精度,还可以满足实时检测的需求。
基于经典Faster R-CNN,He 等[9]提出的Mask R-CNN(Mask Region-based CNN)将Faster R-CNN 的骨架网络改进为Lin 等[18]提出的特征金字塔网络(Feature Pyramid Network,FPN),并增加了一个全卷积掩码预测头用于分割检测结果中的目标与背景,提升检测性能的同时还较好地解决了实例分割问题。马佳良等[19]基于其提出的有效交并比(Effective Intersection over Union,EIoU)和特征重分配模块(Feature Reassignment Module,FRM)设计了改进的目标检测框架。而Yang 等[20]则利用关键点检测的思路,设计了一个不依赖锚框的目标检测模型RepPoints(Point set Representation),该模型为特征图的每个位置预测一组点集,并利用该点集输出检测框,是一种与上述基于锚框的方法完全不同的范式。此外,Sparse R-CNN(Sparse Region-based CNN)[21]等候选框稀疏的目标检测方法也逐渐被关注,它们不用像大多数方法一样设置稠密分布的候选框,因此更符合人类思维。
上述方法在公开目标检测数据集上已经取得十分优秀的结果,并在许多工业检测问题中得以应用,例如Liong 等[22]将Mask R-CNN 用于皮革缺陷检测问题;He 等[23]将改进后的Faster R-CNN 用于钢表面缺陷检测问题;冯涛等[24]将提出的角度加权交并比与Mask R-CNN 结合后,较好地解决了染色体实例分割问题。
基于深度学习的方法能全面超越基于特征描述子和形态学算法等技术的目标检测方法是因为CNN 具有更强大的表征能力。通过卷积层、池化层与激活层等线性与非线性变换运算的堆叠,CNN 将图像从像素空间映射到语义空间,然后利用反向传播算法[5]优化模型参数,使模型可以在语义空间自适应地表征各种复杂的模式。
但在印刷缺陷检测问题上,上述以单张图像为输入的方法因为缺少参考图像的信息,所以无法完全检测具有内容相关性的缺陷,例如印刷内容的偏移、缺失,以及与印刷内容视觉特征相同的缺陷。与通用目标检测方法相比,本文提出的CoNet 通过孪生的网络结构让模型得到正样本(即参考图像)的信息,然后通过在语义空间比较检测图像与参考图像完成缺陷检测,从而解决了内容相关性缺陷带来的问题。因此,CoNet 相较于Faster R-CNN 等通用目标检测方法更适合解决依赖参考图像的检测问题。
1.3 变化检测与印刷缺陷检测
与目标检测问题不同,变化检测的目标是对图像之间的差异进行判别与定位,需要以两张或多张图像为输入。一直以来,变化检测都是遥感图像分析领域的一个重要研究问题,并且也有许多优秀的研究成果。
Zhao 等[25]首次将深度学习用于变化检测问题,通过比例对数算子计算输入图像之间的差异图,然后利用深度学习完成差异图的后续判别。相反地,Zhan 等[26]将孪生卷积神经网络用于图像对特征图提取阶段,然后以欧氏距离作为相似性度量计算特征图之间的距离,最后通过阈值化和K近邻得到检测结果。与前两种方法不同,Caye Daudt 等[27]基于U-Net[28]提出了三种变化检测模型,这三种模型分别采用原图拼接、特征图拼接与特征图差值三种信息融合的方式,并且都是端到端的全卷积神经网络。而黄平平等[29]则通过构造基于改进相对熵与均值比的融合差异图提出了无监督的变化检测方法,并将其用于洪灾前后的变化趋势估计。
可以发现,变化检测方法正好可以用于印刷缺陷检测问题,因为印刷缺陷本质上就是检测图像相较于参考图像的变化之处。因此,Tang 等[10]基于变化检测的思路,以VGG-tiny(Visual Geometry Group network-tiny)[30]作为骨架网络提取检测图像和参考图像的特征图,通过特征图差值进行信息融合后,再使用分组金字塔池化(Group Pyramid Pooling,GPP)完成印刷电路板缺陷检测。Tang 等[10]分别测试了使用最大池化和平均池化两种方法的GPP 模型,实验结果表明,最大分组金字塔池化(Max-Pooling Group Pyramid Pooing,MP-GPP)方法的性能更好。相似地,Haik 等[11]针对动态数据打印提出了两种缺陷检测方法:一种是在像素空间进行信息融合的伪彩色单次检测器(Pseudo-color Single Shot Detector,Pseudo-SSD);另一种是在语义空间进行信息融合的变化检测单次检测器(Change-Detection Single Shot Detector,CD-SSD)。
与上述同样基于变化检测思路设计的印刷缺陷检测模型相比,本文提出的CoNet 具有以下特点:
1)在骨架网络部分,CoNet 采用一对只包括三次下采样的轻量化网络提取图像对的中层语义特征。因为工业检测问题并不过分依赖高层语义特征,该设计可以更好地平衡检测精度和速度。
2)头部网络MsCDM 采用了非对称的双通路特征金字塔结构。该结构通过增加一个运算量极低的次通路,将检测特征图通过类残差结构传递给各个尺度的输出模块,在几乎不降低速度的条件下提升检测精度。
2 深度对比网络模型CoNet
本文采用变化检测的思路,将孪生卷积神经网络与非对称的双通路特征金字塔结构结合,提出了一个端到端的印刷缺陷检测模型——CoNet。如图2 所示,该模型以检测图像和参考图像组成的图像对为输入,首先通过深度对比模块(Deep Comparison Module,DCM)得到检测图像与参考图像的语义关系图;然后利用MsCDM 对语义关系图进行后处理;最终输出大、中、小三个尺度的预测结果,其中包括置信度、边界框与缺陷类别三部分的预测值。最后,本文采用基于广义交并比(Generalized Intersection over Union,GIoU)[31]的多目标损失函数训练模型,引导模型更好地学习图像对比的能力。

图2 CoNet模型结构Fig.2 Structure of CoNet model
2.1 深度对比模块
如图3(a)所示,DCM 主要由两个步骤组成:1)将检测图像与参考图像组成的图像对映射到语义空间;2)通过特征融合算子在语义空间中挖掘检测图像与参考图像之间的语义关系。DCM 是CoNet 的核心,因为本文的目的就是将模板匹配方法中的对比思想和深度学习中的语义特征结合,通过在语义空间中进行图像对比增强模型鲁棒性。
2.1.1 孪生骨架网络
与残差网络(Residual Network,ResNet)[32]等CNN 不同,DCM 中的骨架网络是一个只包括三次下采样的轻量化CNN,共18 个卷积层。采用浅层网络的主要原因如下:
1)工业缺陷检测问题对模型的计算复杂度要求较高,需要保证实时性。在采用孪生结构的情况下,网络过深会成倍地增加计算量,因此DCM 采用轻量化网络。
2)本质上,深度对比就是对检测图像与参考图像的对应局部进行特征提取与相似度计算,而局部区域的大小则是模型的感受野。感受野过小会导致模型无法获取足够的语义信息,过大则会令不相似区域的语义特征相似度过高,因此DCM 采用只有三次下采样的浅层网络控制感受野。
如图3(b)所示,骨架网络由卷积层和残差模块组成。卷积层包括卷积、批归一化与激活三个步骤,参数k、s、c分别表示卷积核大小、步长、卷积核个数,步长为2 时,卷积层具有下采样的功能;残差模块由两个卷积核大小分别为1 和3的卷积层组成,并采用跳跃结构将输入值短接到第二个卷积层的激活函数前。具体地,卷积层和残差模块的运算过程可以分别记为式(1)和式(2):
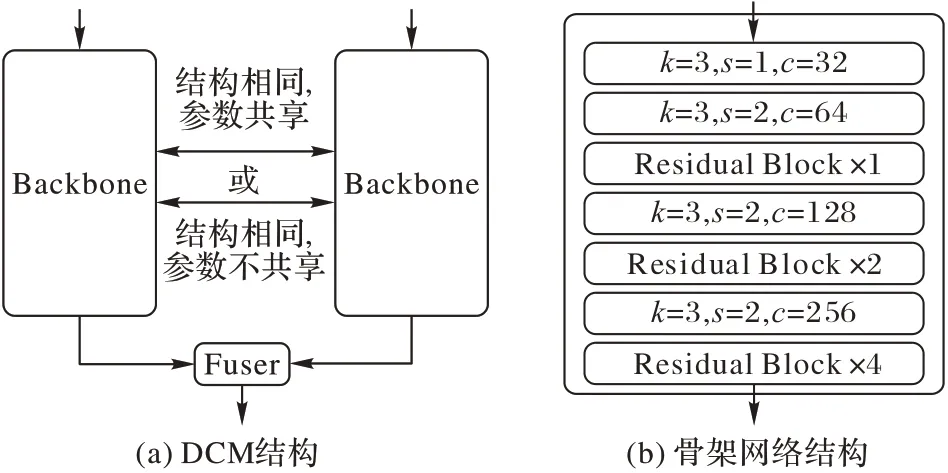
图3 DCM示意图Fig.3 Schematic diagram of DCM

其中:带泄露修正线性单元(Leaky Rectified Linear Unit,LeakyReLU)的参数α为0.1。
为了同时处理输入图像对,CoNet 采用孪生的网络结构,使用一对结构完全相同的骨架网络分别处理检测图像和参考图像,从而保证图像对的特征图维度相同。但是,因为CNN 是有参数模型,在参数不同时,两个网络结构完全相同的模型在本质上依旧是两个不同的映射函数。因此,如图3(a)所示,本文提出了以下两种不同的方案:
1)结构相同,参数共享。该方案的核心目标是通过相同的非线性映射函数E,将原始图像从像素空间投影到语义空间,令投影后的图像具有可度量的语义相似性。可度量的语义相似性是指原图的局部区域经过映射函数E后,被投影为语义空间中的一个点,该方案希望投影点的距离就是局部区域之间的语义相似性。
2)结构相同,参数不共享。相较于参数共享方案,该方案的缺点在于,两个参数不同的模型本质上是两个不同的非线性映射函数E1、E2,未训练的模型所得投影点的相似性关系无法得到保证。但是,该方案通过减少约束条件扩大了训练时的搜索空间,令模型拥有更强的表征能力,只是训练难度有所增加。
因此,两种方案各有优劣。
2.1.2 特征融合算子
以孪生骨架网络输出的语义特征图Fdet和Fref为输入,特征融合算子的目标就是整合二者的信息,并挖掘它们之间的相关性。这种相关性可以是显式的相似性,也可以是隐式的不可解释的相关性。因此,针对特征融合算子,本文也提出了两种方案:一种是引入先验信息设计的语义差分算子;另一种是基于卷积层设计的卷积融合算子。
1)语义差分算子。由2.1.1 节可知,原始图像经过孪生骨架网络投影后具有可度量的语义相似性,当局部区域语义相似时,投影点距离足够近,反之投影点距离足够远。基于这一先验信息,语义差分算子可以由式(3)定义。输出结果越接近0.5 表示语义相似度越高;越接近0 或1 则表示相似度越低。
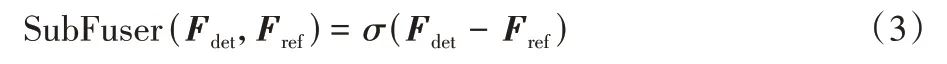
2)卷积融合算子。不同于语义差分算子,该算子不进行显式的语义相关性挖掘,而是在特征通道维度拼接图像对的语义特征图后,使用两个卷积核大小分别为1×1 和3×3 的卷积层进行特征融合。该算子虽然可解释性不足,但得益于卷积层参数的可学习性,经过大量数据训练之后,其表征能力相对更强。

2.2 多尺度变化检测模块
本文采用非对称的双通路特征金字塔结构,设计了一种多尺度变化检测模块(MsCDM)。该模块由两个独立的信息通路组成:语义关系图通路、检测特征图通路。其中,语义关系图通路是必须存在的,该通路以DCM 输出的语义关系图Fdiff为输入,并对其中的差异信息进行判定、定位与分类,因此是检测模块的主通路;而检测特征图通路是可选的次通路,该通路以检测图像的语义特征图为输入,通过残差模块和步长为2 的卷积层,将特征图变换后作为辅助信息传输至三种尺度的输出模块中,用于提升检测性能。
2.2.1 MsCDM网络结构
如图4(a)所示,MsCDM 的主通路由2 个下采样过程和2个上采样过程组成,形成一个完整的特征金字塔结构。金字塔的下采样分支和上采样分支之间,信息的交互通过跳跃连接和特征通道拼接完成。以Fdiff为输入,该通路首先在下采样分支上得到三种尺度的中间值Fs、Fm、Fl,分辨率分别为原图的1/8、1/16、1/32;然后,从Fl开始,模型先通过输出模块得到大尺度预测结果Ol,再用缩放因子为2 的双线性插值层处理中间值,并将上采样后的值与Fm拼接得到下一尺度的输入值;最后,循环上一步骤得到中、小尺度的预测结果Om、Os。
与主通路不同,检测特征图通路只包括一个轻量级的下采样分支,由图4(a)可知,该分支只包括3 个残差模块和2个步长为2 的卷积层。因为该通路的作用只是将检测特征图作为辅助信息用于输出模块,所以在尽量地增加运算量的前提下,此处采用了与主通路不同的轻量级网络。
连接以上两个通路的模块是输出模块(Output Block)。如图4(b)所示,输出模块由若干参数不同的卷积层堆叠而成,主通路输入值经过5 个卷积层之后,同时进入两个分支:一个作为中间值被输入到上采样模块;另一个与次通路的检测特征图拼接,并用于预测结果计算。根据输出模块的网络结构可知,次通路的检测特征图只参与预测结果计算,并不会进入主通路的特征金字塔中。

图4 MsCDM示意图Fig.4 Schematic diagram of MsCDM
2.2.2 预测结果解码
由图4(b)的输出层参数可知,MsCDM 的输出值的通道数都是3(5+N)。假设原图的分辨率为(H,W),那么CoNet 预测结果的维度分别是:
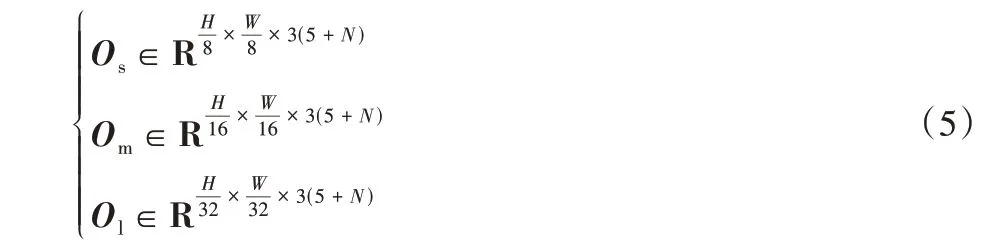
以小尺度预测结果Os为例,如图5 所示。该结果分辨率为原图的1/8,一共包括个长为3(5+N)的向量,每个向量又分为三部分,每部分对应一组预测结果。具体地,一组预测结果共包括5+N位数,分别代表三种预测值:

图5 解码过程示意图Fig.5 Schematic diagram of decoding process
1)置信度。预测结果的第1 位用于表示对应位置是否存在缺陷,也就是说,将原图划分为的网格后,使用模型预测值表示对应网格中存在缺陷的置信度。如式(6)所示,解码过程就是使用Sigmoid 函数将预测结果的第1 位映射到(0,1)区间。

2)边界框。
①边界框中心点。预测结果的第2~3 位用于表示缺陷边界框中心点相对网格中心点的偏移量。假设网格中心点为(xc,yc),解码过程可以记为式(7)。首先用系数为0.5 的双曲正切函数将预测值映射到(-0.5,0.5)区间,与基准中心点相加后,再乘以当前尺度的下采样倍数s。因此边界框中心点最多只会比网格中心点向任意方向偏移半个网格,不会落在当前网格之外。
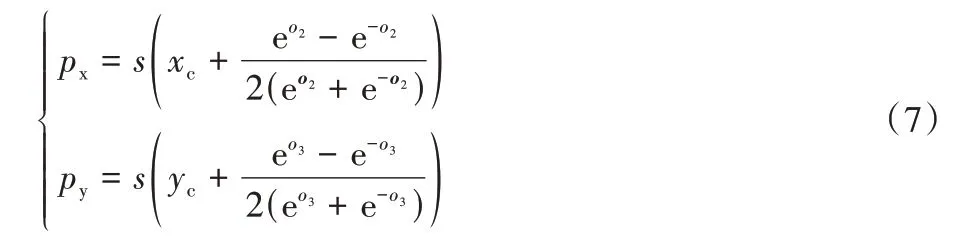
②边界框大小。预测结果的第4~5 位用于表示缺陷边界框的宽、高。本文为每个尺度预设了三种宽高比的锚框,每个锚框的面积与当前网格的面积相等。假设锚框的宽、高为wa、ha,如式(8)所示,边界框大小的解码过程就是将指数函数激活的预测值作为系数对锚框的宽、高进行缩放。

3)缺陷类别。预测结果中剩余的N位分别表示缺陷属于某种类别的概率,其解码过程就是使用Softmax 函数激活预测结果后N位,令它们的和为1。

此外,得到预测边界框后,还需要使用非极大值抑制(Non-Maximum Suppression,NMS)算法进行边界框去重。
2.3 损失函数
与预测结果解码相同,模型训练时的损失函数同样分为置信度、边界框与缺陷类别,三者之间的关系为:

其中:gconf表示置信度真值,当锚框为阴性时取值为0,边界框和缺陷类别的损失函数不参与模型训练;反之则在训练时同时计算三部分损失函数。
置信度和缺陷类别预测是分类问题,因此本文采用交叉熵函数作为这两部分的损失函数,计算方法如下:
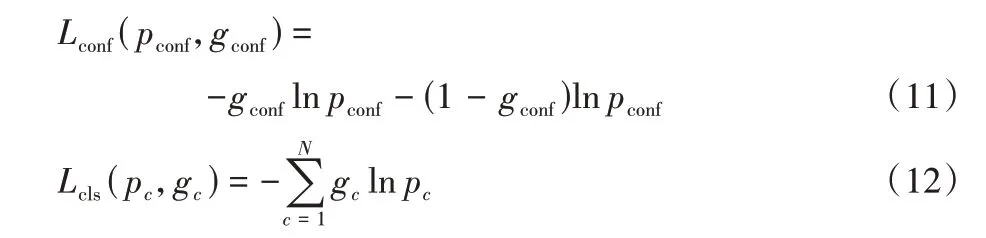
边界框的中心点与大小预测则是回归问题,在该部分,本文采用了基于GIoU 设计的损失函数。GIoU 的计算方法如式(13)所示:
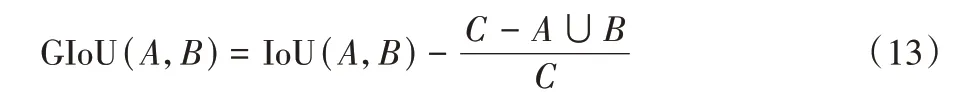
其中:交并比(Intersection over Union,IoU)表示两个边界框交集与并集的比值。A和B表示两个边界框;C表示二者的最小闭包。由式(13)可知,GIoU 的取值范围是(-1,1),当两个边界框的距离无限远时,其取值为-1;当二者重合时,取值则为1。因此,GIoU 损失函数可以记为式(14),当预测框与真实框重合时,损失为0。

3 实验与结果分析
3.1 数据集与评估指标
本文在两个数据集上进行了实验,一个是公开的印刷电路板缺陷数据集DeepPCB[10];另一个是本文收集的真实工业场景下的立金缺陷数据集。
DeepPCB 是一个包括6 种缺陷的数据集,它通过图像对的形式组织数据,并采用边界框的方式标注缺陷,因此适用于测试本文提出的CoNet 模型。该数据集共3 000 张分辨率为640×640 的图像,正、负样本各1 500 张,二者一一对应后组成1 500 个图像对。为了与现有印刷缺陷检测方法对比,本文采用Tang 等[10]使用的方式,将数据集划分为训练集和测试集两部分,前者1 000 个图像对,后者500 个图像对。
立金缺陷数据集是一个真实的银行卡表面印刷缺陷数据集,共包括6 个印刷区域,1 384 张图片,缺陷类别包括5种,分别是:残缺、偏移、漏印、多印、划痕。与DeepPCB 不同,立金缺陷数据集将每个印刷区域的所有图像划分为正、负样本集,而非图像对。同一区域的正、负样本集中的所有图像可以交叉组合。由于立金缺陷数据集的负样本较少,为了得到更可靠的实验结果,本文在数据集划分时采用五折交叉验证的方式,将各区域的正、负样本划分为5 份后,每次实验选4 份作为训练集,剩余1 份则作为测试集。如此重复5次,最终结果取5 次实验的均值。
本文将目标检测任务中常用的平均精度均值(mean Average Precision,mAP)作为评估指标,当检测边界框与标注边界框的交并比(Intersection over Union,IoU)大于0.5 且类别相同时,该检测边界框为阳性。
3.2 实验细节
本文所有实验的运行环境相同,包括:Xeon Platinum 8163 2.5 GHz CPU ×1,Tesla P100-16G GPU ×1。
为了与其他性能优秀的变化检测方法进行对比,本文复现了Tang 等[10]提出的MP-GPP 和Haik 等[11]提出的CD-SSD,并在两个数据集上进行了对比实验。与本文提出的CoNet相似,MP-GPP 和CD-SSD 都采用变化检测思路进行印刷缺陷检测,其中MP-GPP 是DeepPCB 的基线模型,而CD-SSD 则是基于变化检测思路解决印刷缺陷检测问题的较新模型。
同时,本文还与模板匹配方法、Faster R-CNN[8]进行了对比,二者在DeepPCB 上的实验结果来自文献[10],而在立金缺陷数据集上的实验结果则是本文的真实测试值。其中,模板匹配方法是本团队已商业化的方案,因此可以保证其精度是有意义的;Faster R-CNN 的实验则基于开源的MMDetection[33]完成。
对于DeepPCB,本文将输入图像的分辨率设置为640×640,并将训练批次大小设置为4;对于立金缺陷数据集,本文首先采用长边切分与短边填充结合的方式,将原图转化为320×320 的图像块,然后将训练批次设置为8。训练时,这两个数据集都会进行数据增广,并且每个图像对中的两张图像通过的数据增广是一致的。
所有实验都用Adam 优化器训练,初始学习率为0.000 3,并且采用热启动和余弦衰减策略动态调整学习率,终止学习率为0.000 006。每次实验总共训练50 轮,前2 轮学习率处于热启动阶段,后48 轮学习率再进入余弦衰减阶段。最终用于测试的模型为第50 轮保存的模型。
3.3 实验结果分析
首先,本文在DeepPCB 上评估CoNet 模型,并与模板匹配方法、Faster R-CNN[8]、MP-GPP[10]和CD-SSD[11]进行对比,对比结果如表1 所示。

表1 在DeepPCB上的各类别AP与mAP 单位:%Tab.1 Average value of mAP and mAP on DeepPCB unit:%
在采用孪生骨架网络参数共享、差分融合算子和双通路结构的配置情况下,CoNet 模型的mAP 为99.1%,相较于现有的四种方法都取得了更好的检测结果。与模板匹配方法相比,CoNet 的mAP 提高了9.8 个百分点,在性能上全面领先。与Faster R-CNN 相比,CoNet 的mAP 提高了1.5 个百分点,尤其在Open 和Short 缺陷类别上,CoNet 的AP 分别高出了2.2 和3.3 个百分点。与同类型的变化检测方法MP-GPP和CD-SSD 相比,CoNet 依旧取得了更好的检测结果,其mAP在超过了99%的情况下相较于MP-GPP 和CD-SSD 分别提升了0.4 和0.7 个百分点,并且在各种类型缺陷上的AP 都等于或者高于这两种方法。综上可知,相较于对比方法,本文提出的CoNet 具有更优的性能。
然后,考虑到DeepPCB 的难度较小,实验结果可能不足以反映它们的真实性能,本文又在更复杂的立金缺陷数据集上进行了类似的评估,实验结果如表2 所示。

表2 在立金缺陷数据集上的检测结果 单位:%Tab.2 Detection results on Lijin defect dataset unit:%
在采用孪生骨架网络参数共享、差分融合算子和双通路结构的配置情况下,CoNet 的mAP 平均值为69.8%,相较于两种思路类似的方法MP-GPP 和CD-SSD,分别提升了3.5 和2.4 个百分点;相较于模板匹配方法和Faster R-CNN,分别提升了12.0 个百分点和5.3 个百分点。除了CD-SSD 得到了比MP-GPP 更高的mAP 外,表2 的整体结果与DeepPCB 上的结果基本一致。值得注意的是,在立金缺陷数据集上,如果只输入检测图像训练Faster R-CNN 会出现不收敛的情况;但如果将检测图像和参考图像进行堆叠,组成6 通道的伪图像,则训练收敛,表2 中的Faster R-CNN*就是通过该方法训练所得。分析训练数据发现,立金缺陷数据集中存在较多的内容漏印和偏移缺陷,这可能就是Faster R-CNN 在正常训练时不收敛的原因,同时也与前文提出的内容相关性缺陷的概念相吻合。根据Caye Daudt 等[27]提出的变化检测模型可知,堆叠检测图像和参考图像在本质上就是一种图像对信息融合的方式,因此可以在一定程度上解决内容相关性问题。
此外,通过比较各个方法在五折交叉验证中的最大和最小mAP 差值可以发现,CoNet 具有更稳定的性能表现,其最大和最小mAP 的差值为1.2 个百分点,而MP-GPP 和CD-SSD则分别是2.3 个百分点和1.7 个百分点。这表明,CoNet 不仅精度更高,而且对训练数据的自适应性也更强
除了定量分析CoNet 的检测精度,本文还通过可视化方法更直观地比较了对比实验中的5 种方法。图6 是3 种变化检测方法在DeepPCB 上的检测结果可视化,相较于MP-GPP和CD-SSD,本文提出的CoNet 在没有漏检的情况下,还避免了印刷内容边缘处的误检。类似地,图7 是立金缺陷数据集上的可视化结果。相较于图7(a)~(b)两个非变化检测方法的结果,图7(c)~(e)的漏检更少,这说明变化检测方法对印刷缺陷检测任务是有效的;相较于MP-GPP 和CD-SSD 两种变化检测方法,本文提出的CoNet 进一步提高了检出率,并且依旧没有出现误检。该结论与表1~2 的结果基本一致。

图6 3种变化检测方法在DeepPCB上的检测结果可视化Fig.6 Visualization of detection results of three change detection methods on DeepPCB

图7 表2中的五种方法在立金缺陷数据集上的检测结果可视化Fig.7 Visualization of detection results of five methods in Table 2 on Lijin defect dataset
3.4 消融实验与复杂度分析
本节首先通过消融实验对CoNet 的两个主要模块及其不同方案进行分析;然后再对CoNet 的参数量、浮点运算次数和单次检测的耗时进行分析。
3.4.1 针对DCM中各组件的消融实验
由2.1.1 和2.1.2 节可知,孪生骨架网络和特征融合算子分别存在两种不同的方案,在MsCDM 采用双通路结构时,将这两个组件的可行方案交叉组合,然后在DeepPCB 和立金缺陷数据集上进行对比,结果如表3 所示。

表3 采用不同方案的DCM检测结果Tab.3 Detection results of DCM with different schemes
在DeepPCB 上,4 种组合方案中的mAP 最高值为99.1%,在参数共享和语义差分算子(SubFuser)组合时取得。当该组合的骨架网络改为参数不共享时,mAP 下降了0.5 个百分点。当采用卷积融合算子(ConvFuser)时,不论骨架网络是否参数共享,mAP 都是98.8%。
在立金缺陷数据集上的实验也取得了类似的结果。当使用语义差分算子时,骨架网络参数共享与不共享两种情况下的mAP 分别为69.8%和68.1%,后者相较于前者下降了1.7 个百分点。当使用卷积融合算子时,两种骨架网络方案的mAP 接近,只相差0.2 个百分点。
根据两种融合算子在不同情况下的性能表现可以得出结论:差分融合算子需要与参数共享的孪生骨架网络组合才能取得更好的效果;而卷积融合算子则可以适应不同类型的骨架网络。合理的解释是:差分融合算子基于强先验信息设计,希望原始图像间的语义相似性可以转化为语义空间中投影点间的距离,因此参数共享的方案更加适合;而卷积融合算子因为其可学习的特性,对输入数据的自适应能力更强,所以不会过分依赖骨架网络输出的语义特征。虽然在表3中卷积融合算子的性能略低于差分融合算子,但这并不完全表示卷积融合算子就不可取,因为可学习的模型往往需要更多的数据训练,而本文使用的数据集规模都较小。
3.4.2 针对MsCDM中双通路结构的消融实验
本文在DCM 采用骨架网络参数共享与语义差分算子组合的前提下,分别测试了MsCDM 采用单通路结构与双通路结构时的性能,结果如表4 所示。相较于只有主通路的单通路结构,增加次通路的双通路结构在DeepPCB 上的mAP 提升了1.2 个百分点,在立金缺陷数据集上则提升了2.1 个百分点。因此,双通路结构是有效的。
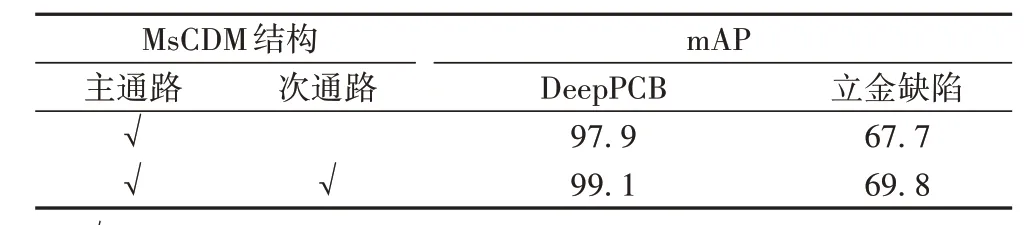
表4 不同MsDCM结构下的检测结果 单位:%Tab.4 Detection results under different structures of MsCDM unit:%
3.4.3 CoNet复杂度分析
作为工业检测任务的一种,印刷缺陷检测问题需要算法具有一定的实时性。本节在采用孪生骨架网络参数共享与差分融合算子组合的前提下,分别测试了MsCDM 采用单通路结构与双通路结构时CoNet 的复杂度,结果如表5 所示。实验时输入图像的分辨率为640×640,硬件设备为:Xeon Platinum 8163 2.5 GHz CPU ×1;Tesla P100-16G GPU ×1。

表5 不同结构MsCDM下CoNet的复杂度Tab.5 Complexities of CoNet under different structures of MsCDM
在MsCDM 采用单通路结构时,CoNet 的参数量约为49.8×106,浮点运算次数约为96.0×109,在指定设备上完成前向运算和NMS 的总耗时约为32.3 ms(1 000 次实验均值)。增加次通路后,参数量和运算量分别增加了12.8×106和10.1×109,耗时则增加了3.4 ms。可见,增加次通路并不会过分影响检测速度,CoNet 的最终耗时为35.7 ms,具有较好的实时性。
4 结语
本文将变化检测用于印刷缺陷检测问题,将对比思想与语义特征结合,提出了一种通用的印刷缺陷检测方法CoNet。具体地,CoNet 首先通过深度对比模块挖掘图像对的语义关系图;然后再利用双通道的多尺度变化检测模块在语义关系图上定位并识别印刷缺陷。得益于深度对比模块强大的表征能力与多尺度变化检测模块利用双通道结构引入的更多有效信息,CoNet 最终在DeepPCB 和立金缺陷数据集上都取得了优于现有基于深度学习的变化检测方法的性能。实验结果表明,在语义空间进行图像对比并用于解决印刷缺陷检测任务的思路是可行的,但依旧存在可优化的部分。后续的研究可以从两方面展开:一方面是进一步提高CoNet 在弱小缺陷上的检测性能;另一方面是引入弱监督、自监督等方法,解决基于深度学习的变化检测方法需要大量有标注数据训练的问题。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
北京航空航天大学学报(2022年8期)2022-08-31
河北地质(2021年1期)2021-07-21
数学物理学报(2021年2期)2021-06-09
数学物理学报(2021年1期)2021-03-29
印刷工业(2020年4期)2020-10-27
印刷工业(2020年4期)2020-10-27
应用数学(2020年2期)2020-06-24
印刷工业(2020年5期)2020-03-29
中国生物医学工程学报(2019年5期)2019-07-16
