
双线性内卷神经网络用于眼底疾病图像分类
2023-02-03 03:02杨洪刚陈洁洁徐梦飞
计算机应用 2023年1期
杨洪刚,陈洁洁,徐梦飞
(湖北师范大学 计算机与信息工程学院,湖北 黄石 435002)
0 引言
在当代医学诊断的过程中,医疗影像作为临床上病症检测的客观依据,为医生诊断提供支持[1]。眼底图像的应用目前已经较为成熟,但医生通过它进行眼部疾病的判断需要大量的临床经验作为积累。对于医疗资源较差的地区,通过眼底图像进行诊断的精度并不理想,而使用计算机技术对眼底图像进行分类能有效提高诊断精度[2]。
深度学习的出现为基于眼底图像的分类问题提供了一种有效的方法:王宇光等[3]提出一种基于5 个深度卷积模型的集成训练结构,通过正则化随机性,增强了模型面对不同眼底数据集的鲁棒性;姜声[4]提出用卷积神经网络(Convolutional Neural Network,CNN)作为底层模型对眼底图像进行特征提取,用长短期记忆(Long Short-Term Memory,LSTM)[5]作为上层模型输出关于该图像的文本描述信息;Li等[6]利用多示例多模态网络学习思想,解决了眼底图像分辨率太大不利于深度神经网络训练的问题。因类间差异和样本差异都很细微的特性,眼底图像分类可被视作细粒度分类问题[7],传统的CNN 模型对眼底图像细粒度的特征提取有限[8],因此如何提高模型的特征提取能力是眼底图像的分类模型的研究重点。
双线性卷积神经网络(Bilinear Convolutional Neural Network,BCNN)[8]是针对细粒度问题提出的分类模型,该模型使用两个经过预训练的VGG16[9]网络提取图片的特征信息,并使用双线性池化进行二阶信息融合。这虽然提高了精度但也造成参数量爆炸式的增长。针对上述问题,Gao 等[10]采用线性核机器的思想,提出了Random Maclaurin 和Tensor Sketch 两种低维投影函数对二阶特征融合矩阵的计算进行降维。Kong 等[11]运用矩阵的特征值分解来进行低秩计算,在没有明显降低精度的情况下,将参数量降低了99.6%。Zheng等[12]首先对输入图片进行语义分割,然后对语义联系紧密的区域进行二阶融合,最后删除非关联部分的融合过程。通过上述操作,对比原始BCNN 模型在CUB200-2011 数据集上提高了4%的精度的同时将参数量降低了96%。
Transformer[13]是基于注意力机制来提取内在特征联系的模型,具有强大的全局表达能力,开始被广泛地应用在NLP、视觉任务等领域中。TransFG[14]是Transformer 第一个用于细粒度的分类任务的基于注意力机制的模型。通过滑动提取图块和增加有效区域选择模块使最后一层注意力层只输入对分类有意义的部分图块,判断过程更能集中注意力。在前期工作中,笔者团队提出了TransEye(Transformer Eye)[15]来解决眼底图像分类问题,在输入端增加CNN 模块提取底层语义信息和降低图块维度,另一方面利用自注意机制的权值积来定位有效区域。
为了进一步提高眼底图像分类任务的精度,本文提出基于involution 算子[16]实现注意力结构,并以这种结构作为子网络模型之一改造BCNN,设计了注意力双线性内卷神经网络(Attention Bilinear Involution Neural Network,ABINN)模型,如图1 所示。ABINN 是CNN 和注意力机制结合的模型,打破了BCNN 模型的对称性,两个子网络由CNN 架构和注意力架构组成,分别完成底层语义信息提取和空间结构信息关联两个任务,并统一由involution 算子实现。这不仅可以同时提取到输入图片的局部特征和长距离语义关系,也简化了模型结构,使双线性池化的计算不再需要进行维度上的缩减。
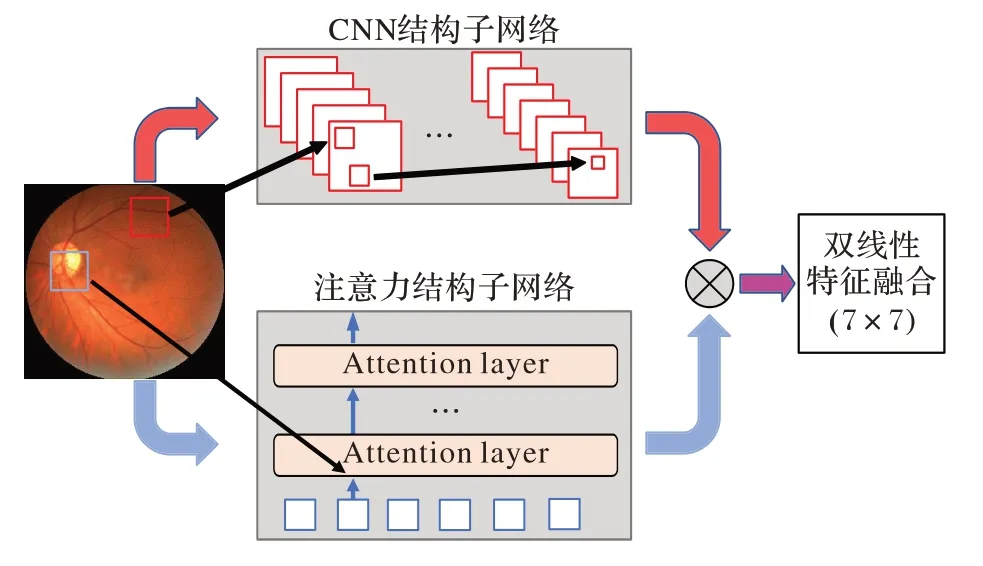
图1 ABINN模型的结构Fig.1 Structure of ABINN model
综上所述,本文主要工作如下:
1)提出了两种基于involution 算子实现注意力计算的方法,分别为基于像素的注意力子网络(Attention Subnetwork based on PiXel,ASX)和基于图块的注意力子网络(Attention Subnetwork based on PaTch,AST),该方法可以将注意力的思想用CNN 结构的网络实现。
2)使用ASX 和AST 改进BCNN,提出了针对眼底图像细粒度分类的ABINN,该网络是卷积和注意力机制的有效结合,能实现语义信息二阶融合。
3)针对眼底图像识别任务特点对双线性池化计算进行了优化,使模型参数量仅为BCNN 的11%。
4)在OIA-ODIR 数据集[17]进行了实验,实验结果显示ABINN 模型在精度上优于TransEye、TransFG 等模型。
1 相关工作
1.1 BCNN
BCNN 是解决细粒度分类问题的模型,与一阶CNN 模型相比,BCNN 通过双线性结构完成特征融合,提取输入图片的二阶特征用于分类。首先由两个VGG-16 网络作为子网络提取输入图片的特征映射;然后使用双线性池化操作融合两个子网络提取的特征;最后通过一层全连接分类器进行分类。BCNN 模型可以定义为:

其中:fA和fB是两个用于特征提取的子函数,P是双线性池化函数,C是分类函数。两个VGG-16 网络作为骨干网络在ImageNet 数据集[18]上使用相同的预训练手段,并去除最后一层全连接层。
BCNN 是一个端到端训练的模型。使用长步骤、多结构的组合模型解决细粒度分类问题时,各模块训练目标的不一致会导致某个模块的目标函数与系统的宏观目标有偏差。因此,在统一模型下使用单独目标函数进行训练的端到端模型更符合眼底疾病图像分类任务的需求[19]。
1.2 involution算子
involution 是一种有效的视觉表征学习算子,扭转了卷积的设计原则,完成了从空间一致性和通道特异性到空间特异性和通道一致性的转变。这在一定程度上解决了感受野在一次卷积中无法捕获长距离信息的挑战。不仅如此,卷积过程内部通道间冗余突出成为了一个共识,而involution 算子有效避免了这个问题。在网络中,involution 算子可以直接替换卷积操作从而更新现有的卷积神经网络。
具体来说,involution 算子的前馈过程[16]如图2 所示,对应位置的特征向量通过G(X)非线性函数生成只属于此位置的involution 核,并在所有通道上进行共享。将展平的involution 核与对应位置周围的图块在通道上作乘法广播计算,在空间上作向量加法计算即M(X),最终得到一个与输入维度完全一致的特征映射。对于对应位置来说,它可以是一个图块也可以是一个像素。这样的设计非常方便上下游任务中输入不同分辨率特征映射的参数交流。

图2 involution算子的前馈计算过程Fig.2 Involution operator feedforward calculation process
另外,involution 的结构与注意力机制的计算方法类似。在基于注意力结构的视觉模型中,价值矩阵V的值通过计算查询矩阵Q和关键内容K之间的对应关系得到。直观上讲,自注意力算法通过计算对应图块与周围部分的关系得到了自己包含的信息。然而,在involution 算子中,将生成函数设置为类似形式,也可以产生相应效果。由于通道共享的设计理念,整体过程并不会产生巨大的参数量。
involution 算子的出现将注意力的思想集成在CNN 框架下实现,为本文后续的工作提供了支持。
2 ABINN模型设计
ABINN 沿用了BCNN 的双线性框架,但对内部结构进行了重构。本章主要从CNN 子网络设计和注意力子网络设计两个部分来介绍该模型。
2.1 基于CNN的子网络设计
ABINN 类似BCNN 结构用两个子网络模块对输入图片进行特征提取,然而不同的是,这两个子网络不再使用完全相同的结构。研究认为相同结构提取的特征本质上是高度相似的,使得后续的池化融合过程中丢失了二阶特征融合的优势[19]。因此,受CNN 与注意力机制结合的启发,本文提出分别用基于CNN 模型和注意力模型做子网络。
基于CNN 的模型使用了中间层截断的ResNet18[20]和RedNet18[21]两种具有残差结构的网络,其中,ResNet18 的参数在ImageNet1K 数据集[18]上进行了预训练。通过预训练,当领域特定数据稀缺时可以从额外的训练数据中获益,这对于从大物体分类到细粒度分类的许多任务都是有益的。使用CNN 的另一个优点是,CNN 被证明是提取图像底层语义信息的有效手段,经典的深层CNN 模型在过去一直被认为是处理细粒度问题的主要方式。无论ResNet18 还是RedNet18,本文实现中都去除了最后的分类层并使最后一层卷积的输出通道固定为7(因为在OIA-ODIR 数据集的眼底图像分类是一个7 分类任务),同时保留了全局平均池化操作。总之,CNN 的输出X是一个1 × 7 维度的向量。
2.2 基于注意力的子网络设计
ABINN 没有直接将类似视觉Transformer(Vision in Transformer,ViT)[22]的基于注意力机制的网络直接作为另一个子网络,而是采用了基于involution 算子下实现的类注意力机制网络。原因如下:
1)ViT 网络的输出不利于做全局平均池化操作,这使得池化融合操作之前需要进行维度的修剪,必然会造成信息的丢失。
2)ViT 网络的参数量已经相当庞大,直接集成到ABINN中会使整体的模型体积成倍增加。
3)involution 算子下实现的注意力网络具有类似ViT 的功能,而且是在CNN 基础结构上完成的,这使得两个子网络可以在一个框架下进行训练,更好地进行信息传递。
本文给出了两种involution 核函数的实例化方法,分别以像素和图块作为函数的输入,称其为Gpix函数和Gpat函数。Gpix函数如下:

其中:Xij表示维度为1 × 1 ×C对应输入图像中所有第i行j列的像素组成的一个向量;WQ(维度K×K×C)和WK(维度G×C)表示两个线性变换,G是一个超参数,表示将所有通道分成G个组,每个组共享核参数(根据involution 论文[16]中的结论,所有的实验中G均设置为4),并且没有使用ResNet中的通道压缩技术。为了构建具有注意力性质的完整网络结构,该子网络同样通过堆叠块状结构来镜像地复制ResNet设计,其中ResNet 的残差结构也能够匹配注意力编码器结构中的思想。在网络设计方面,替换了ResNet 中“茎”的部分(使用K=7 的involution 核)和主干部分中所有瓶颈位置(使用K=3 的involution 核)的3 × 3 卷积,但保留所有的1 ×1 卷积进行降维和通道融合。简称上述结构为ASX。ASX 的计算流程与RedNet 保持一致,如图2 所示。
Yu 等[23]在MetaFormer 结构实验中证明,注意力机制能有效实现分类工作的本质是像素之间的信息交互而并非特定的注意力计算方式。Liu 等[24]提到在指定大小的区域内完成注意力计算再进行区域间的交互可以在不影响精度的前提下降低计算复杂度。ASX 在3 × 3 的区域内计算注意力,并使用1 × 1 的降维融合一个计算单元中区域间的信息。通过多层计算单元的堆叠,实现了在CNN 结构中插入注意力机制。
尽管延续involution 思路的ASX 能完成类似注意力机制的计算,但有一个问题不能被忽视,即几乎所有基于注意力的视觉网络都是以图块作为输入单元实现的。因此,设计了AST 算法模拟上述结构,如图3 所示。AST 拥有和ASX 不同的计算过程,以在第t层任意一个输入图块Xt∈RK×K×C为例,具体前馈算法如下所示:
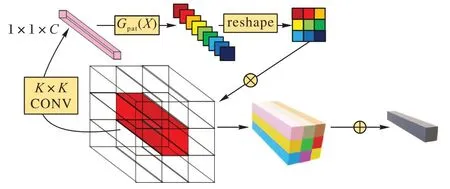
图3 AST前馈计算过程Fig.3 AST feedforward calculation process


AST 和ASX 替代的位置相同。另外,AST 在所有层都将输入划分为9 × 9 个图块,在尺寸不能整除的层中会有一些像素的重叠。
2.3 参数量
对比传统双线性卷积神经网络,ABINN 主要在3 个方面进行了降参:
1)使用ResNet18 为子网络主干网络代替了VGG16。
2)使用involution 算子代替卷积计算。在一层卷积计算中,由于空间不变性和通道特异性,卷积核的参数量可以表示为:

其中:Cinput是本层输入特征图的通道数,Coutput是本层输出特征图的通道数,K是卷积核的尺寸。involution 算子具有空间不变性和通道特异性,相同位置的参数量可以表示为:

其中:H和W是输入特征图的高和宽,G是共享通道的数量。在深层神经网络中C≫G。
3)保留全局平均池化层,用两个长度为7 的向量代替BCNN 中两个长度为1 024 的向量做双线性池化计算。
3 实验与结果分析
实验在GPU 服务器上进行,运行系统为ubuntu18.04.5,GPU 为NVIDIA Tesla P100,显存为16 GB。实验全部使用Python 作为开发语言并使用PyTorch 深度学习框架。
3.1 实验设计及对比结果
实验使用OIA 的 子数据集OIA-ODIR[17]。OIA-ODIR 数据集共包含10 000 张高清眼底图像,其中训练集占比70%,测试集占比30%。图像来自全年龄段人群,包含7 种疾病标签和正常标签,分别为:正常标注N 共4 322 张;糖尿病标注D 共2 311 张;青光眼标注G 共390 张;白内障标注C 共428张;老年黄斑病变标注A 共368 张;高血压视网膜病变标注H共177 张;病理性近视标注M 共323 张;其他疾病及异常图片标注O 共1 381 张。所有实验均去除了标注为O 的图片。除了未使用指数移动平均对可训练的参数进行测试,实验中保持了自注意力机制和轴向注意力机制的所有训练方案[20]。
表1 总结了一系列基于CNN 和注意力机制以及广泛应用的细粒度分类模型的精度,并与ABINN 进行了对比,其中AlexNet[25]、VGG16、InceptionV3[26]、ResNet18、BCNN、ViT 均使用了预训练参数,AcNet[27]和TransEye 则是完全初始化训练。由表1 可知,传统的基于CNN 的分类网络,无论是通用的ResNet 还是针对细粒度设计的BCNN,在OIA-ODIR 上的精度最高仅为72.6%。基于自注意力架构的网络如ViT 等精度大幅优于CNN,其中将CNN 和注意力机制结合的TransEye 精度为84.1%。这说明区域间的互信息对眼底图像分类任务至关重要。ABINN 的精度为85.0%,超过了以上所有对比模型。与TransEye 相比,ABINN 模型用非对称网络提取了输入图像的二阶信息是精度提高的关键。

表1 10种模型的精度对比 单位:%Tab.1 Accuracy comparison of ten models unit:%
表2 对比了ABINN 模型和传统用于眼底图像分类任务模型的参数量。在OIA-ODIR 数据集上的测试结果显示,通过三种降参操作使ABINN 模型更轻量化,参数量是BCNN 模型的11%。

表2 4种模型的参数量对比Tab.2 Comparison of parameter amount of four models
3.2 消融实验
在消融实验部分主要针对RedNet、ResNet、ASX 和AST四种结构在子网络的选择上进行了测试,结果如表3 所示:其中ABINN-1 和ABINN-2 是由两个基于CNN 的网络作为子网络搭建的,是BCNN 的一个残差结构版本。实验结果表明,精度的提高主要来自于将对称结构转换为非对称结构,其中“CNN+注意力”的组合要大幅优于不同CNN 结构之间的组合。这是因为CNN+注意力的非对称结构既能同时兼顾底层细节特征的提取和长距离空间位置的融合,又能在训练防止两个网络学习到相同的内容。

表3 6种子网络组合的精度对比Tab.3 Comparison of combination accuracy of six sub-networks
对比ASX 和AST,AST 对最终分类效果的增幅更大。这是因为细粒度的眼底图像中更需要较大尺寸的核去提取特征来保证关键区域内的相互信息不受破坏。显然,ASX 中对图块的卷积操作能更好地完成这项任务。
实验同时还测试了四种对输入图像预处理方法对ABINN 灵敏度的影响,结果如表4 所示。

表4 ABINN-D模型输入图像的4种预处理方法对比 单位:%Tab.4 Comparison of four preprocessing methods for input image unit:%
根据王晓华等[28]、王萍等[29]的实验结论选择了预处理方法中的超参数,其中线性对比度增强参数值为2、伽马变换中伽马值取1.5。实验结果表明,三种预处理方法均对判断精度有一点提高。相较于直接将原始图片作为输入,直方图均衡化将准确率提高了0.4 个百分点。直方图均衡化能使图像全局各区域之间的像素化能使图像全局各区域之间的像素对比差异增大,这对用于提取空间总体特征的注意力子网络的工作起到了促进作用。而在前期工作的实验中发现,直方图均衡处理会在OIA-ODIR 数据集上降低CNN 的分类精度。因此直方图均衡处理的图片仅用在基于注意力的子网络一侧。
3.3 热力图分析
图4 显示了AST 子模型不同层输出横切面热力图[30]的可视化效果,其中Layer2 和Layer4 分别是倒数第二层和最后一层的输出,Layer3 是倒数第一层的第一次involution 计算。颜色越接近红色的区域,ASX 网络就越关注。可以清晰地看到,随着层数的不断加深,提取到的特征逐渐由分散到集中,并最终汇集在视盘、黄斑、血管和其他病变区域。这与临床眼科医生诊断疾病的经验是一致的。

图4 热力图Fig.4 Heat maps
4 结语
本文提出了轻量化改进模型ABINN 用于细粒度眼底图像分类。其中两个子网络分别由CNN 结构和自注意力结构搭建并统一使用involution 算子实现。与BCNN 相比,ABINN打破了网络的对称结构,参数量是前者的11%。本文还提出了两种具体的使用involution 算子在CNN 结构上实现注意力计算的方法,并通过热力图给出了直观的展示。实验结果显示,在OIA-ODIR 数据集上的最佳预测精度远超BCNN 模型并比TransEye 提高了0.9 个百分点。用involution 算子实现的CNN 和注意力机制的结合在细粒度图像分类领域有着巨大的潜力,实现了底层语义信息提取和空间结构信息的二阶融合,可以用于改进端到端的细粒度分类网络。ABINN 将是这一系列工作的起点,未来将尝试更多有效结合的方法。
猜你喜欢
红外技术(2022年11期)2022-11-25
数学物理学报(2022年5期)2022-10-09
小雪花·成长指南(2022年1期)2022-04-09
数学物理学报(2021年2期)2021-06-09
数学物理学报(2021年1期)2021-03-29
应用数学(2020年2期)2020-06-24
安阳工学院学报(2020年2期)2020-06-05
电脑知识与技术(2017年26期)2017-11-20
传媒评论(2017年3期)2017-06-13
信息安全研究(2016年3期)2016-12-01
