
基于深度卷积生成对抗网络的半生成式视频隐写方案
2023-02-03 03:02林洋平张明书杨晓元
计算机应用 2023年1期
林洋平,刘 佳*,陈 培,张明书,2,杨晓元,2
(1.武警工程大学 密码工程学院,西安 710086;2.网络与信息安全武警部队重点实验室(武警工程大学),西安 710086)
0 引言
互联网的迅速发展产生了海量的数据,如何保证这些数据的保密性、完整性和可用性等成为学界所关注的问题。密码学和隐写术都提供了维护公共信道上机密数据安全的方法。相较于传统的加密技术,信息隐藏技术更加注重秘密通信而不是加密信息,适用于军事通信、金融交易等涉及敏感信息传输交互的领域,具有广阔的应用前景[1]。
当前的视频信息隐藏方案主要利用某种修改策略进行信息嵌入,以最小的代价来达到隐写目的。最低有效位(Least Significant Bit,LSB)隐写术是一种常见的隐写方法[2],主要通过将秘密信息隐藏在载体图像的最低有效位来实现信息嵌入。还有许多研究学者从视频压缩编码标准入手,实现对秘密信息的嵌入[3-5]。这些方案的隐写视频质量虽没有明显下降,但仍改变了载体视频的底层统计数据,容易受到针对特定嵌入域的隐写分析算法[6]的攻击。针对传统载体修改式隐写方案存在的问题,许多学者将生成对抗网络(Generative Adversarial Net,GAN)[7]引入信息隐藏中,提出了基于GAN 的隐写方法。该方法主要可分为3 类:载体选择、载体修改和载体合成[8]。
目前在视频隐写中,王婷婷等[9]利用短视频资源的分类与时长,提出了一种基于载体选择的视频信息隐藏方法,但该方法的嵌入率较低。基于神经网络的视频隐写算法大都属于载体修改式方案,Weng 等[10]提出一种基于深度卷积网络的视频隐写方法,利用连续视频数据之间的时间冗余将视频帧图像分为残差帧与参考帧,并分别利用两种嵌入与提取网络实现对秘密视频中的残差帧与参考帧的分类与提取;该方案是一种将秘密视频隐藏在载体视频的隐写方法。Jaiswal 等[11]与Abdolmohammadi 等[12]利用三维卷积神经网络(3D-Convolutional Neural Network,3D-CNN)具有增强特征学习的特点,提出了基于3D-CNN 的隐写模型架构,对载体视频样本进行信息嵌入。为了解决传统方法不能同时处理多种恶意攻击的问题,Luo 等[13]提出了一种基于深度学习的鲁棒视频水印(Deep multiscale framework for Video waterMarking,DVMark)方案,DVMark 在编码器与解码器网络中结合了一种多尺度设计,将消息的嵌入跨越多个时空尺度;与前两种方案相比,DVMark 通过使用不同的可微失真层,提高了水印视频的鲁棒性。上述三种方法都是采用了神经网络的载体修改式隐写方案,经过大量训练,逐渐缩小载密视频与原始视频之间的差异;但实际上仍会对载体信息进行一定的修改,易受隐写分析算法的攻击,并且无法将秘密消息无损地提取出来。而在视频隐写中,基于GAN 的载体合成式隐写方法还处于探索阶段。
结合载体修改式与载体合成式的特点,本文提出了一种基于深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Net,DCGAN)[14]的半生成式视频隐写方案。本文的主要工作如下:
1)半生成式方案使用基于DCGAN 的双流视频生成模型,并不是直接构造出完整的含密视频,而是将含密视频的生成分为前景信息、后景信息与时空掩模三部分;通过设定一定的概率阈值,在时空掩模中自适应地生成数字化卡登格,在视频前景中对信息有选择地进行嵌入,通过三者的组合生成含密视频。
2)在原有判别器的基础上,增加了一个隐写判别器来对含密视频与原始视频进行判定。通过博弈论的思想,利用大量视频数据进行对抗性训练,使得生成的含密视频在视觉上更加符合自然语义。
1 相关知识
1.1 生成对抗网络
生成对抗网络(GAN)是Goodfellow 等[7]于2014 年提出的基于零和博弈思想的神经网络模型,其结构如图1 所示。

图1 GAN的结构Fig.1 Structure of GAN
GAN 从某种分布中采样得到随机噪声,然后输入到生成器中,输出一个“伪”样本,将其与“真”样本一同传给判别器,给出判别结果。理想情况下,生成器能完全学习到真实数据分布,使判别器无法准确识别数据来源[15]。因此在GAN 的训练过程中优化目标函数为:

其中:D(x)是判别x为真实样本的概率;G(z)是从输入噪声z产生的生成样本。
深度卷积生成对抗网络(DCGAN)参考原始GAN 的原理,卷积神经网络(Convolutional Neural Network,CNN)为其结构主体。网络模型中使用全卷积结构代替了全连接层与池化层,批量标准归一化层的使用解决了模型的训练问题,这样生成样本的质量和收敛速度都得到很大的提升。
1.2 半生成式隐写
生成式信息隐藏指在没有预先指定原始载体的条件下,含密载体由秘密信息按照一定规则直接生成,而含密载体可以不表示真实的客观世界,但与正常内容相比应具有不可区分性。生成式方案往往不会预先指定原始载体;而半生成式信息隐藏方案会事先设定载体构造的预设条件,然后根据秘密消息并遵循相应的生成规则生成含密载体。所生成的含密载体属于特定类型[16],如图2 所示。

图2 半生成式隐写Fig.2 Semi-generative steganography
与载体修改式隐写方案不同,视频半生成式隐写方案以秘密信息为驱动,利用生成器直接生成含密视频样本,避免了对原始载体的修改。该方案适用于某种特定的视频载体类型,拥有自身特有的信息隐藏理论基础与方法,同时也结合了目前载体修改式隐写方案中的一些成果。视频半生成隐写方案可应用于社交软件、流媒体平台与网上存储工具,利用视频媒介作为秘密信息的伪装,达到隐蔽通信或隐蔽存储的目的。
2 本文方案
本文提出的基于DCGAN 的半生成式视频隐写方案主要由视频生成、数字化卡登格生成与信息嵌入三部分组成。视频的生成需要包括生成器网络与两种判别器网络的参与,数字化卡登格的生成与信息嵌入以掩模与前景的生成为基础。

其中:g为样本;m为时空掩模;f与b分别为前景(foreground)信息和后景(background)信息;⊙为Hadamard 乘积[17]。
本文含密视频的生成过程如图3 所示,信息隐藏的过程符合传统卡登格的基本思想。发送方通过设定隐写阈值自适应地定义了一个被称为数字化卡登格的掩码,以确定消息隐藏在前景信息的具体位置;而秘密消息将直接嵌入到这些位置的像素点的最低有效位,实现了从传统卡登格到数字化卡登格的转换。然后采用Hadamard 乘积[17]通过式(2)进行样本g合成。含密视频将通过公共通道传输给接收方,接收方利用事先从秘密信道中获取的卡登格提取秘密信息。这样既保证了秘密信息的安全性,又保证了在视频合成前后的逻辑合理性。

图3 含密视频的生成过程Fig.3 Generation process of video with secret
2.1 数字化卡登格的生成与信息嵌入
基于卡登格的信息隐藏方法中,卡登格作为秘密信息嵌入与提取的密钥,但传统卡登格对秘密信息处理比较简单。针对双流视频生成模型的特点,提出了一种数字化卡登格隐写方案。
本文通过分析掩模中对应每个像素运动与位置信息的数字特性,设定具体的隐写阈值对掩模进行修改,以生成数字化卡登格。由于生成网络的最后一层采用了Sigmoid 函数,掩模对应的像素运动信息对应的数值处于0 到1 之间。由式(2)可知,运动信息数值与对应前景中的像素运动幅度成正比,从嵌入合理性与嵌入容量两方面考虑,对掩模的修改方式如式(3)所示。

因为在嵌入过程中只对视频帧图像的第一个通道进行嵌入,所以对前景与掩模的处理也只在其最后一个维度中进行。假如前景与掩模的大小为32×64×64×3,则要对二者进行数据处理的部分的大小为32×64×64×1。每次生成的掩模是根据随机噪声驱动生成的,通过设定阈值∂对嵌入位置进行选择,将大于概率阈值的置于1,自适应生成数字化卡登格,再对应前景的具体位置进行LSB 嵌入。为了减小修改前景像素信息带来的特征变化,采用随机加减1 的方式进行嵌入,从而达到最优化嵌入的目的。具体嵌入方式与流程如式(4)和图4 所示:

图4 数字化卡登格的生成与嵌入流程Fig.4 Flow of digital Cardan grille generation and embedding

当前景所需修改位置的值为0 或255 时,修改时跳过该点,在下一个位置进行嵌入。传输时消息发送方无需将网络训练模型传输给接收方,只需将生成的数字化卡登格通过秘密信道传输给接收方;待消息接收方收到公共信道传输的隐写视频时,利用数字化卡登格对视频中的每一帧进行覆盖,即可将秘密信息无损地从视频帧中提取出来。
2.2 生成器结构
生成器网络的输入是一个低维噪声z,该噪声可以从一个分布(如高斯分布)中采样。本文生成器网络的架构在设计时考虑了以下需求:首先,本文希望通过低维的噪声能够产生具有高维信息的视频;其次,视频相较于图像注重于客观事物产生位移的动态属性,因此生成器需要对物体动态信息的建模;最后,本文希望生成器直接在时空关系上进行建模,不将时间与空间关系分割开来。通过分析当前已有的不同神经网络的视频生成模型,本文采用了基于DCGAN 的视频双流生成网络,网络中使用了转置卷积网络,卷积核为3×3×3,步长为2,具体结构如图5 所示。其中,括号中的数字代表通道维数。

图5 生成器网络结构Fig.5 Generator network structure
视频中物体所处的环境一般是静止的,通常只有被拍摄的物体在移动,因此在建模信息时,双流架构利用这一特性设计视频生成的流程与原理,如式(2)所示。
对于视频中每个像素的位置和时间步长,利用时空掩模选择前景信息或后景信息,这里的前景代表视频中运动的信息,而后景代表了视频中静止的背景。为了在视频时间序列中生成背景信息,后景通过二维卷积学习视频图像中静止的像素信息,生成一个随时间复制的平面图像。这里前景是一个代表每个像素的时空信息的四维时空张量。生成前景的网络结构,本文使用与文献[14]中单流架构相同的网络;而对于后景,使用了与图像生成网络类似的生成器架构。为了区分时空掩模与前景的生成过程,在进行最后一次卷积操作时使用了与前景参数不同的卷积层,而其余卷积层中掩模与前景共享权重。
2.3 判别器结构
本文使用一个5 层三维卷积网络,卷积核为3×3×3,步长为2。本文设计的判别器与生成器中的生成前景的结构相反,输入为真实视频样本与生成的含密样本,输出为类别标签label与分类概率logit。其中:类别标签为1 时,代表真实样本;标签为0 时,代表生成样本。判别器网络中除了最后一层卷积层后使用Sigmoid 函数以外,每一层卷积操作后都使用LeakyReLU 作为激活函数进行处理。loss是判别器的损失函数,采用了Sigmoid 交叉熵用来训练判别器。
在对抗性训练思想的启发下,在模型中增加了一个隐写判别器,其结构与DCGAN 的判别器结构相同,但不与判别器共享权重参数,在嵌入秘密信息时单独对其进行学习训练,输入为真实视频样本与含密视频样本。损失如式(6)所示。

3 实验与结果分析
3.1 实验设置
本文实验使用了来自MPII、UCF101 数据集与YUV 标准视频库中的不同环境下、各类动作类型的视频数据,作为真实视频样本。实验前利用FFmpeg 软件对视频样本进行预处理,将视频样本处理为分辨率64×64 的32 帧短视频序列。网络模型的输入与输出皆为32 帧分辨率64×64 的视频序列。本文实验是在Tensorflow-gpu1.9 深度学习框架下进行,CPU为INTEL Xeon E5-1603,内存为16 GB,显卡为NVIDIA TITAN XP。随机噪声的参数设置为均值为-1,标准差为1 的100 维高斯噪声。神经网络模型采用了文献[18]中的DCGAN 结构,其中优化器选择了Adam 优化器,学习率为0.000 2。在训练过程中,总共对视频生成网络进行训练周期为1 500 轮次的训练:前1 200 轮不进行嵌入,只训练模型中的生成视频模块,同时隐写判别器也未对生成的视频进行识别训练;后300 轮增加隐写判别器,并进行对信息嵌入模块的训练。
3.2 实验结果
3.2.1 嵌入位置的选择
本文所采用的视频生成模型中,掩模、后景与前景三个部分的生成都需分析视频帧图像之间的时空关系,以大量视频样本对生成网络进行迭代训练,使生成视频中物体的时空信息足够真实。原始视频帧与前景之间的对比见图6。

图6 生成样本与原始帧Fig.6 Generated samples and original frames
在嵌入信息的过程中,视频中静止的信息是从原始训练的视频样本中学习而来的。从图6 中可以看出,后景代表了视频中静态背景,而前景代表了运动信息是由噪声驱动的;前景较后景而言,具有一定的随机性,说明对前景进行信息的嵌入,视觉上可以提高所生成的含密视频样本的安全性。
图7 是生成视频与后景像素直方图之间的统计信息对比。从统计信息的角度也可以说明两者之间的像素关联度高,对后景进行嵌入,嵌入容量小且会对视频每一帧都造成相同失真。因此本文采用在前景中进行信息的嵌入,这样对嵌入信息后的视觉质量影响最小。

图7 后景和生成视频的像素分布直方图Fig.7 Pixel distribution histograms of background and generated video
3.2.2 隐写视频质量
本节展示了在隐写阈值为0.99 的条件下,迭代训练所生成的含密视频。随机抽取三帧含密视频与原视频进行主观质量对比,使用训练视频与随机生成的含密视频的像素分布直方图作为无参考客观质量评估手段进行对比分析,如图8~9 所示。从视觉效果来看,在视频中物体运动较小的情况下,能生成质量较好的含密视频,其语义信息都能被较好地表达出来,只是在一些细节方面略有不足;从统计信息分布来看,生成视频基本服从原始训练视频的像素分布。

图8 含密视频帧Fig.8 Video-with-secret frames

图9 生成视频和训练视频的像素分布直方图Fig.9 Pixel distribution histograms of generated video and training video
Frechet Inception 距离(Frechet Inception Distance score,FID)值是评估原始样本与生成样本之间的分布特征相似度的标准。FID 值越小,证明二者之间的像素分布特征越接近。本文选择了不同隐写阈值下的含密样本与IcGAN(Invertible conditional GAN)[19]、MonkeyNet[20]两种网络的生成样本作为对比对象,使用FID 值衡量不同网络的生成效果,结果如表1 所示,可见本文方案的生成样本质量较高。
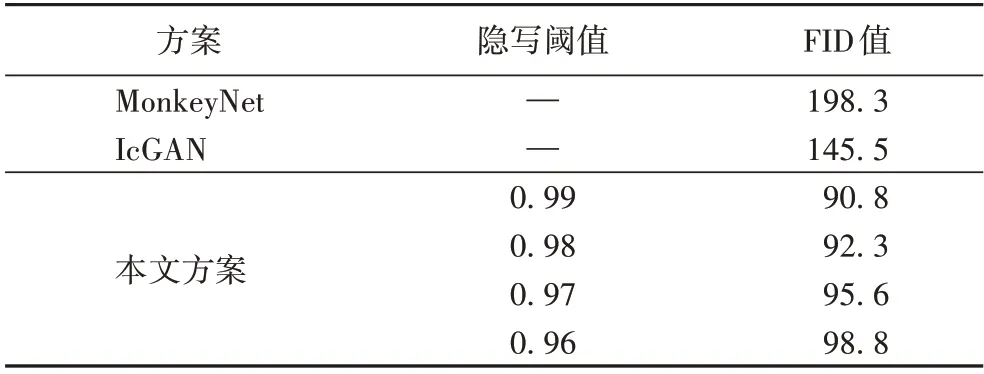
表1 生成样本质量对比Tab.1 Generated sample quality comparison
3.2.3 嵌入容量
训练过程中每段视频的运动信息与统计特性各有不同,因此针对YUV 标准视频库中的视频训练样本,不同的隐写阈值对应会生成不同隐写容量的含密视频样本。
从表2 可看出,隐写阈值越大,对应视频所能嵌入的消息比特数也就越小,但嵌入消息对视频质量的影响也越小。如图10 所示,当阈值为0.99 时,视频的自然语义能够较好地保持,并且嵌入容量的大小也足够多。因此在现实场景中可根据需要秘密传输的消息内容的大小,具体选择隐写阈值的大小调整嵌入容量。

表2 不同隐写阈值下的嵌入容量Tab.2 Embedding capacities under different steganography thresholds

图10 隐写阈值对视频质量的影响Fig.10 Influence of steganography threshold on video quality
表3 列出本文方案与一些视频信息隐藏方法的嵌入容量与嵌入率。嵌入容量是指在视频的某一帧载体或某一段视频中能够嵌入的信息长度;相对容量为平均每一像素嵌入的信息比特数;max 与min 代表了在不同视频样本下,本文方案嵌入容量的最大、最小值;n代表视频长度(帧数)。
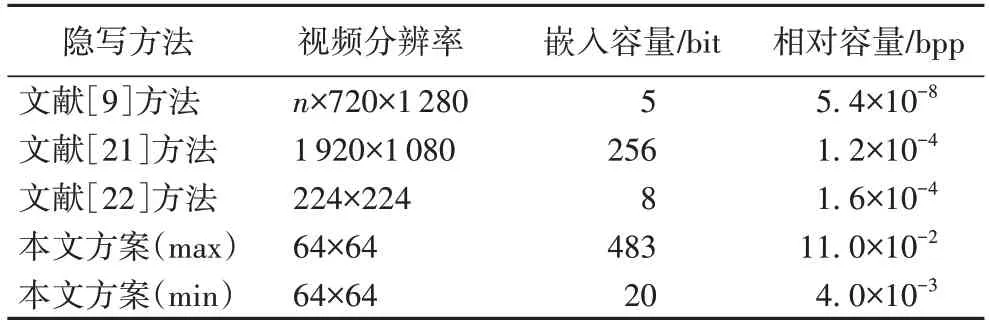
表3 不同方法的隐写容量对比Tab.3 Steganographic capacity comparison of different methods
3.2.4 安全性分析
由于本文采用了半生成式视频隐写的方法,攻击者无法通过原始载体与含密视频之间进行对比分析,且不注重于某一种信息隐藏技术与分析检测技术之间的博弈,方案的先验知识若发生泄露或算法公开,并不会严重威胁其安全性。半生成式隐写方法通过学习与模拟真实样本的数据分布,使得含密样本与真实样本之间的数据分布差异最小,以保证二者之间的不可区分性,避免陷于隐写与隐写分析对抗[8]。
本文方案可应用于高互动多媒体与社交应用中,使含密视频能够以较高传输速率和视觉保真度在网络中实时传播;并且可以利用互联网中大量视频媒介,对模型进行训练,以丰富含密视频的视觉表现能力,使其不会引起第三方的察觉与怀疑。其次通过与传统密码学技术卡登格的结合,将其作为发送方与接收方的嵌入与提取信息的密钥,即使攻击方知晓获得生成视频样本中存在有秘密信息,因发送方采用秘密信道传输数字化卡登格,攻击方无法正确提取含密载体中的秘密信息,能保证秘密消息不被泄漏。因此本文隐写方案满足Kerckhoffs 准则,提高了传输过程中秘密信息的安全性。
4 结语
本文利用DCGAN 生成真假难辨的伪视频,结合数字化卡登格的思想,提出了基于DCGAN 的半生成式视频隐写方案。所提方案主要包括视频生成过程、数字化卡登格生成过程与信息嵌入过程三部分,通过三者的结合实现秘密信息的嵌入。实验结果和理论分析表明,本文方案可以生成具有良好自然语义特征的视频序列,并且拥有较高的隐写容量,能通过修改隐写阈值来调节可嵌入容量的大小;根据应用场景的不同,可在含密视频的质量与隐写容量进行合理的取舍。卡登格的运用将密码学方案与信息隐藏方案相结合,也使其在隐蔽通信中具有良好的安全性。下一步拟对生成器的网络结构进行优化,以提高生成视频的分辨率,并引入Wasserstein 损失来优化判别器的性能,在提高生成质量的同时又增加视频中每帧的可嵌入比特数。
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
北京航空航天大学学报(2021年9期)2021-11-02
建材发展导向(2021年6期)2021-06-09
今日农业(2020年17期)2020-12-15
电子制作(2019年13期)2020-01-14
中国外汇(2019年11期)2019-08-27
电子制作(2019年11期)2019-07-04
传感器与微系统(2019年7期)2019-06-25
北京航空航天大学学报(2018年1期)2018-04-20
自然资源遥感(2017年2期)2017-04-27
