
基于FPGA的TCP/IP协议卸载引擎设计
2023-01-31 01:47:06杨阳周思远王舒鹏
电子制作 2023年1期
杨阳,周思远,王舒鹏
(扬州万方科技股份有限公司,江苏扬州,225006)
0 引言
随着云计算、大数据、物联网等技术的广泛应用,数据规模呈现爆炸式增长,导致对于网络带宽、延时等性能的依赖性日益增强。网络带宽每年以2~3倍的速度增长,目前10G网络已普及到各个领域,40G/100G甚至400G网络也在数据中心等流量集中的关键领域开始大规模运用。而TCP/IP协议族作为一种网络协议标准,占据着网络协议主流标准地位,其应用最为广泛。传统的TCP/IP网络协议处理由操作系统内核完成分组转发、校验、传输控制、数据分片等流程,并且对于大数据量的网络传输,会产生频繁的I/O中断以及数据拷贝,大幅增加处理器上下文切换开销和系统总线负载[1,2]。根据Thumb定律,处理1bit网络数据需要消耗1Hz的CPU处理周期,网络带宽的快速增长必将消耗大量的处理器资源,最终导致网络IO成为系统性能瓶颈。
为解决高速网络通信中,对于TCP/IP网络协议的处理导致的处理器资源过载问题,通信技术领域提出了多种网络协议优化技术,其中TOE(TCP/IP Offload Engine,TCP/IP卸载引擎)技术[3],通过将传统TCP/IP网络协议的处理流程由操作系统内核卸载至网卡,由网卡硬件执行协议栈处理,从根本上减轻了处理器工作负载,释放出更多的处理器资源。TOE技术的应用不仅能够降低主机处理器资源消耗,同时能够提升网络吞吐量及缩短网络延时[4],具有TOE功能的网络设备将成为未来数据中心构建高性能、低功耗网络基础设施的首选。而基于FPGA设计实现TOE网卡兼具灵活性及成本优势,适应于数据中心网络环境。
基于FPGA硬件化实现TCP/IP协议栈,需要综合考虑FPGA资源占用率、网络性能以及可支持的连接数。目前,商用TOE网卡支持的连接数在千条量级,基于FPGA的TOE网卡使用多TCP/IP协议栈实例实现多连接,支持的连接数相对更少,且资源占用率较高。此外,对于大数据块的通信传输,主机仍然需要与TOE网卡进行频繁的交互,跟踪、控制数据发送的过程,占用了大量的处理器资源、降低了数据吞吐量,对于多连接情景、大数据量传输,情况将更加严重。
云计算、大数据等业务场景下,多连接,大数据量传输频繁发生,在进行TCP/IP协议卸载的同时,还需要减少主机对于数据传输的管控频次,进一步降低网络IO对于处理器资源的占用,充分释放PCIe带宽优势,从而提升网络性能。本文提出了一种基于FPGA构建TCP/IP卸载引擎的设计方法,采用数据发送通道与接收通道分离的架构,由协议共享模块统一管理连接状态及网络通信事件,控制数据收发过程,能够处理万条量级的网络连接。同时,设计了一种大数据块自动分片传输机制,有效降低大数据块发送的延时及对处理器资源的占用。
1 设计与实现
■ 1.1 系统架构
TCP/IP卸载引擎面向多连接TCP/IP网络传输,以可扩展的架构形式实现TCP/IP协议处理的硬件化,从而大幅提高传输协议处理性能,降低对于主机处理器资源的消耗。TOE引擎设计采用发送路径与接收路径相互独立的基础架构。发送路径包括处理组包等工作的发送协议引擎以及发送数据缓冲区;接收路径包括处理拆包等工作的接收协议引擎以及接收数据缓冲区。协议引擎采用流水线模式,用于处理TCP/IP协议,数据缓冲区Buffer用于缓存网络发送或接口的数据。发送路径与接收路径共享连接状态等公共信息,为保证公共信息的一致性,采用一种基于模块的锁方法,有效降低FPGA资源消耗。
发送、接收引擎相互独立且使用流水线模式,具备良好的多链接并行处理能力;同时基于FPGA片外存储实现发送/接收缓冲区,能够容纳数以万计的链接并存。
基于FPGA的TCP/IP卸载引擎设计框架[5]如图1所示,TCP/IP卸载引擎由发送接口、发送缓冲Tx Buffer、发送引擎组成发送路径;由接收接口、接收缓冲Rx Buffer、接收引擎组成接收路径。发送路径与接收路径相互独立,共享TCP状态管理器、事件引擎等公共组件能力。

图1 TCP/IP协议卸载引擎设计框架图
■ 1.2 缓存控制
每个TCP连接在建立时都会被分配一个发送缓存TxBuffer以及一个接收缓存Rx Buffer。Tx Buffer为环形缓冲区,根据应用场景预先配置环形缓冲区容量及数量。尤其对于数据中心分布式存储场景,如Glusterfs存储集群采用128KB数据条带、Ceph存储集群采用4MB数据分片,在此类场景下,缓冲区容量设置为128KB及以上,可以有效降低主机与卸载引擎的交互消耗。Tx Buffer缓存负载数据用于超时确认重发及流量控制。发送缓存控制器用于维护发送缓存状态表,包括读取、写入、删除、更新操作。发送缓存状态表用于记录对应发送缓存的状态,属性包括:
(1)SessionID:TCP链接对应的会话ID;
(2)Add:发送缓存地址;
(3)Producer:生产者指针,标识应用写入发送缓存的尾部地址;
(4)Consumer:消费者指针,标识已经被发送并确认的数据尾部地址;
(5)Send Window:发送窗口大小;
(6)ACK:ACK号;
(7)Transmitted: 已发送指针,标识已经被发送尚未被确认的数据尾部地址;
(8)Active:标识对应的发送缓存是否处于激活使用状态。
图2所示为发送缓存示意图,从外部网络接收的数据将由接收引擎进行校验拆包等协议处理操作后,放入接收缓存Rx Buffer,通知接收缓存控制器移动Producer指针。在应用程序通过DMA操作取走接收数据后,Consumer指针将会被移动。对于乱序发送的数据段,接收引擎根据计算其段序号计算Offset,放入乱序段数据后,移动对应的Length指针,乱序段数量、及Offset相对Producer的偏移量是预先设定的,当数量或偏移量超出设定范围时,相关数据段将被丢弃,发送端由于发送确认超时,将重新发送。

图2 发送缓存示意图
Rx Buffer同样采用环形缓冲区,根据应用场景预先配置环形缓冲区容量及数量。Rx Buffer缓存接收负载数据。接收缓存控制器用于维护接收缓存状态表,包括读取、写入、删除、更新操作。接收缓存状态表用于记录对应接收缓存的状态,属性包括:
(1)SessionID:TCP链接对应的会话ID;
(2)Add:接收缓存地址;
(3)Producer:生产者指针,标识接收数据的尾部地址;
(4)Consumer:消费者指针,标识被应用取走的数据尾部地址;
(5)Offset:乱序段偏移地址;
(6)Length:乱序段长度;
(7)Active:标识对应的接收缓存是否处于激活使用状态。
图3所示为接收缓存示意图,从外部网络接收的数据将由接收引擎进行校验拆包等协议处理操作后,放入接收缓存Rx Buffer,通知接收缓存控制器移动Producer指针。在应用程序通过DMA操作取走接收数据后,Consumer指针将会被移动。对于乱序发送的数据段,接收引擎根据计算其段序号计算Offset,放入乱序段数据后,移动对应的Length指针,乱序段数量、及Offset相对Producer的偏移量是预先设定的,当数量或偏移量超出设定范围时,相关数据段将被丢弃,发送端由于发送确认超时,将重新发送。

图3 接收缓存示意
■ 1.3 连接状态管理
TCP/IP协议的网络连接状态包括Port状态、Conne ction状态,Port状态包括Listening、Active、Closed,Connection状 态 包 括 CLOSED,SYN-SENT,SYN-RECEIVED等,连接状态管理由TCP状态管理器完成。TCP状态管理器基于表数据结构管理Port及Connection状态,同时维护SessionID与由源IP地址、目的IP地址、源Port、目的Port组成的四元组之间的映射。如图4所示为TCP状态管理器对于Connection状态表的管理,Port状态表采用同样的管理方式。由于TOE中的接收引擎、发送引擎、发送接口的工作流程中都涉及了状态表的查询、更新等操作。状态表作为多模块共享数据结构,一方面需要保证并行访问能力及数据一致性;另一方面为适应多连接、高性能网络应用场景,需要提高访问操作性能,降低资源消耗。

图4 TCP状态管理器实施框图
状态表采用FPGA片上双端口BRAM存储,提供数据共享及高性能数据操作;状态管理器通过模块读写锁机制,为访问共享状态表的模块分别创建对应的锁结构,包括读写锁RWLock及表项索引,从而避免为每一个表项创建锁,降低存储资源消耗。外部模块通过相应的访问接口首先获取锁状态,对于同一表项的访问操作,需要进行加锁操作,加锁成功后进行读写操作。
■ 1.4 计时器
TOE根据TCP协议使用四个计时器,包括重传计时器Retransmission Timer、 坚 持 计 时 器 Persistent Timer、保活计时器Keeplive Timer、时间等待计时器Timer_Wait Timer。计时器实现基于表结构,通过遍历操作计时。计时器表结构每一表项代表一个TCP连接会话,表属性包括会话ID用于唯一标识TCP连接;时间戳Timestamp用于记录遍历次数;活跃标志Active用于表示该连接是否在计时中。
对计时器表结构的操作包括两种:一是设置/清空计时器;二是遍历计时器表。针对预先设置的TOE支持连接数,计时器表包含对应数量的表项,一个硬件时钟周期执行一个表项遍历,在连接计时器有效的情况下,如果Timestamp大于0,则减1,当Timestamp为0时,触发相应事件并撤销计时。
■ 1.5 事件引擎
根 据 TCP协 议,TOE定 义 了 TX、RT、ACK、ACKNODELAY、SYN、SYN-ACK、FIN、RST事件,事件包括SessionID、类型,并携带相关参数,用于构建网络包。图5所示为事件引擎的设计框图,TOE事件来源于接收引擎、定时器,以及发送接口,事件引擎相应的设置3个FIFO队列用于事件缓存。调度器根据预定义调度策略进行事件调度处理,默认为优先级策略,为避免接收路径背压导致数据丢失,设置接收引擎事件为高优先级,优先调度。事件路由针对不同的事件类型将事件路由至不同的后续模块。对于ACK事件,由ACK-DELAY模块进行处理,该模块检查ACK-DELAY计时器相应的计时表项是否为Active,如果是,ACK事件会与之前被延迟发送的ACK事件合并,由输出模块传送至发送引擎;如果计时表项不是激活状态,则该表项被设置为Active,ACK事件延迟发送。对于除SYN与RST外的其他事件,被直接路由至输出模块,由输出模块将延迟的ACK事件与其合并,推送至发送引擎,同时撤销延迟ACK事件的计时。

图5 事件引擎设计框图
对于由应用程序通过发送接口触发的数据发送事件,到达事件路由后,由事件路由获取发送缓存状态,比较未发送数据Producer-Transmitted、可用窗口Send Window-Transmitted,以及预定义的MTU。为减少主机端与TOE网卡的交互频次,从而有效降低交互开销,应用触发的发送事件携带的数据长度如果数据发送事件要求发送的数据长度大于未发送数据、可用窗口、MTU三者的最小值,则发送事件将被路由至发送事件切分模块,否则发送事件直接输出。发送事件切分模块记录原始发送事件数据长度,循环执行子事件构建、发送操作。子事件构建操作获取未发送数据、可用窗口、MTU大小,取三者的最小值为数据长度,替换原始发送事件数据长度,形成子事件。子事件重新送入发送接口事件队列调度执行,对于子发送事件,事件路由将直接转发至输出模块。
■ 1.6 接收引擎
接收引擎面向数据流采用流水线模式设计TCP/IP协议接收处理流程,如图6所示。接收引擎使用数据通道及元数据通道将网络传输数据与网络控制数据分离,通过调整数据通道宽度,可以实现不同网络带宽的数据传输。
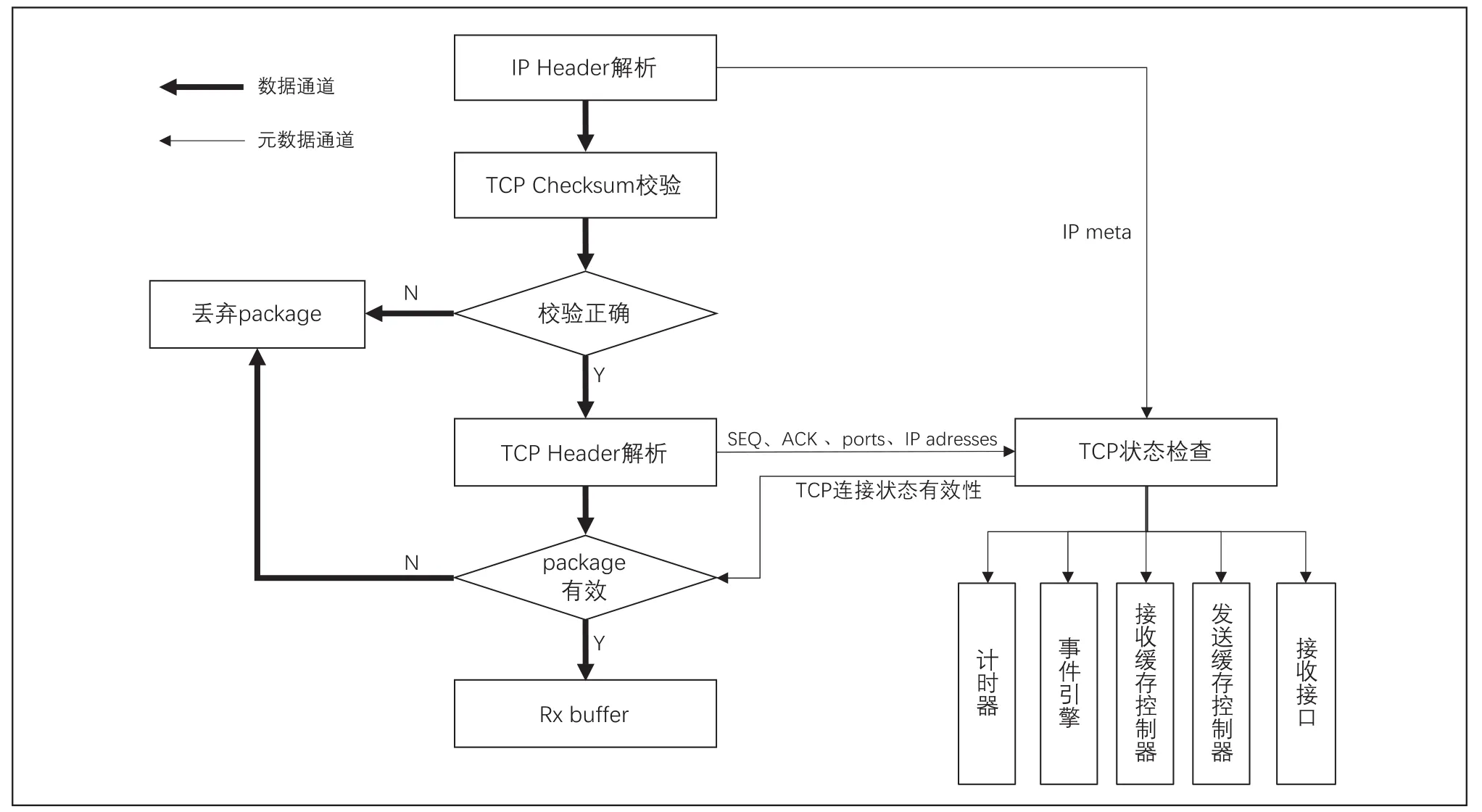
图6 接收引擎实施框图
由物理链路接口传入TCP/IP卸载引擎的IP Package首先进行IP Header的解析,抽取出IP地址及Package长度等IP元数据。第二步进行TCP Checksum校验,对于校验不一致的Package将被丢弃,对于校验一致的Package将进行TCP Header的解析,抽取数据段序号SEQ Number,确认序号ACK Number,发送窗口尺寸Window Size以及SYN,ACK,RST等标志Flags。TCP状态检查步骤根据Port端口号访问TCP状态管理器,检查Port是否处于有效状态;如果Port有效,根据IP地址、Port端口号检索链接SessionID;根据SessionID查询Connection状态;如果Package有效,负载数据将会被放入Rx Buffer,并通过接收缓存管理器更新接收缓存状态表。同时,接收引擎会更新ACK Number、发送缓存状态表的Window Size、设置或清空计时器。接收引擎向事件引擎发送数据接收确认事件,由事件引擎根据ACK策略,立即通知发送引擎发送ACK信息或控制延迟ACK。最后,接收引擎生产数据到达中断,通过接收接口发送至主机端。
■ 1.7 发送引擎
发送引擎面向数据流采用流水线模式设计TCP/IP协议发送处理流程,如图7所示。

图7 发送引擎实施框图
发送引擎由事件驱动,事件源包括由发送接口传递的应用层数据发送事件、请求建立新连接事件、超时重传事件等。发送引擎通过元数据加载模块抽取事件参数构建TCP Header、获取缓存数据、进行Checksum计算、构建IP数据报,最后通过物理链路接口发送[6]。
■ 1.8 FPGA 实现
TOE网络协议栈系统在Xilinx Kcu115 FPGA板子上实现,该板子有四个10G网络接口,4个4GB DDR4,网络接口与TOE的工作频率为156 25 MHz。资源使用见表1。

表1 资源使用表
2 验证实验
■ 2.1 实验方法
为了验证基于FPGA的TCP/IP协议卸载引擎的设计,搭建如图8所示的实验环境:两台陪试服务器分别安装1块Intel 82599ES 10G以太网卡,接入万兆交换机;FPGA板安装在一台服务器,作为被试品接入万兆交换机。在FPGA内部实现Iperf3兼容程序,用于多并发Iperf测试,每次测试时间均为180s,测试次数为5次,取平均值。

图8 实验环境示意图
■ 2.2 吞吐量实验
在TOE接收路径上,两台陪试服务器作为Iperf客户端产生输入压力流量;在TOE发送路径上,使用2台陪试服务器机器作为Iperf服务端,使用FPGA产生发送流量,测试结果如图9所示。

图9 吞吐量实验结果
从图9可以看出,在接收路径上,对于100个网络连接,接收带宽达到9 5GB/s,随着连接数的增加,直到连接数达到1万,接收带宽稳定在9GB/s左右;在发送路径上,对于100个网络连接,发送带宽达到9 5GB/s,随着连接数的增加,发送带宽略有下降,连接数达到1万时发送带宽约为8GB/s,这主要是因为状态管理器通过模块读写锁机制提供共享状态表访问服务,随着连接数的增加,锁竞争会带来部分延时,但万条并发连接,带宽维持在8GB/s,仍然满足数据中心常规使用场景。
吞吐量实验结果表明,基于FPGA的TCP/IP协议卸载引擎的设计可以支撑高并发网络连接场景,提供稳定的高带宽网络吞吐量。
■ 2.3 延时实验
如图10所示为延时实验的结果。由于网络发送、接收路径上的校验和计算都需要存储和转发完整的数据段,因此延迟随有效负载的大小而线性增加,实验结果表明总体延时控制在3 5μs以内。接收路径上的延迟稍高,因为它需要哈希表和端口表查找,导致比发送路径上更多的数据结构访问。

图10 延时实验结果
为了进一步减少延时,采用了两种方式接收DDR旁路和TCP节点无延迟进行优化,DDR旁路将片上RAM资源而不是DDR用于接收缓冲区,通过对比,可以将延时减少到0 5~1 6μs之间。同样,使用TCP节点无延迟标志,即直接将有效负载不经过DDR缓存而直接转发到发送引擎,可以避免DDR内存在发送路径上的延迟。因此,延迟降低了0 3~1 5μs。忽略存储和转发的时钟周期,带有DDR旁路的接收路径上的处理时间为恒定的85个周期,带有TCP节点无延迟的发送路径上的处理时间为70个周期,两种优化方式将延迟减少了近50%。
3 结束语
随着网络带宽迅速增长以及数据规模的指数级增长,依赖操作系统内核的TCP/IP网络协议栈处理TCP/IP网络通信流程的方式,导致网络IO占用过多的处理器资源、网络吞吐量受限、通信延时增加等问题。本文提出了一种基于FPGA的TOE设计方法,充分利用FPGA片上资源,采用状态共享、通道分离的架构,支持高并发连接场景,并能有效控制网络延时。对基于FPGA实现的TOE网卡进行实验验证,结果表明:TOE网卡支持万条TCP/IP网络连接,网络带宽维持在较为稳定的状态,512字节的数据发送、接收网络延时低于1μs。
猜你喜欢
科技与创新(2023年17期)2023-09-17 12:26:12
作文周刊·小学一年级版(2022年12期)2022-03-19 12:35:56
中学生数理化·八年级物理人教版(2019年9期)2019-11-25 07:33:06
网络安全和信息化(2019年1期)2019-02-15 02:45:42
商周刊(2017年22期)2017-11-09 05:08:31
妈妈宝宝(2017年2期)2017-02-21 01:21:22
电脑爱好者(2015年15期)2015-09-10 07:22:44
河南电力(2015年5期)2015-06-08 06:01:46
皖西学院学报(2015年5期)2015-02-28 17:52:46
中小学实验与装备(2014年1期)2014-05-26 18:30:08
