
基于聚类分析的网络异常流量入侵检测方法
2023-01-31 11:28:10陈晓燕
科学与信息化 2023年2期
陈晓燕
濮阳市公安局情报指挥中心 河南 濮阳 457000
引言
网络互动已经越来越成为人类生活中必不可少的部分。但在互联网使人类生活越来越便捷的同时,我们也不可忽视它给我们带来的风险,网络异常流量入侵已经成为严峻的挑战。如何获得更优的网络流量预测结果,以避免拥塞、保护网络安全逐渐成为重要议题[1]。传统的检测方式简单地分为异常入侵检测系统和误用入侵检测系统,面对不断变化的入侵形势时,难以检测到不断变化发展的攻击类型,存在检测效率低、扩展性较差等问题。
为了解决异常入侵检测系统和误用入侵检测系统中存在的问题,本文提出了基于聚类分析算法的网络异常流量入侵检测方法,以实现更加精准地检测网络异常流量的目标。
1 基于聚类分析的网络异常流量入侵检测方法
1.1 采集网络流量数据样本
网络流量数据样本的采集是检测网络异常流量入侵的基础。本实验网络数据样本采集过程,是在TCP/IP模型下,对互联网中的UDP和TCP报文进行数据采集检测。大概率情况下,采集过程为:主机网卡获得报文→操作系统协议栈接收→操作系统协议栈进行层层识别、丢弃、分析。最终获得数据包,如图1所示。
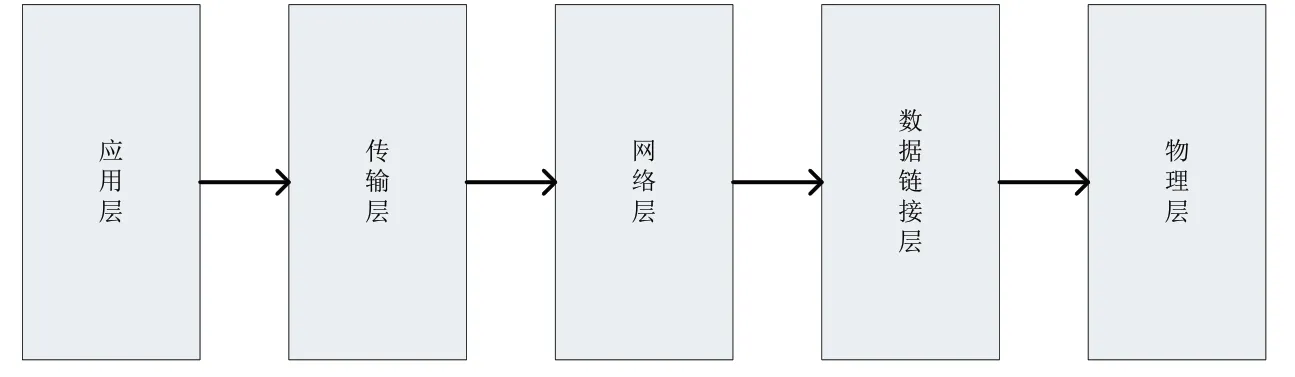
图1 TCP/IP网络架构模型
但是按这种程序采集到的数据包对于流量分类来说是不够完善的,因为流量信息在协议栈进行识别、丢弃、分析的过程中容易出现缺失。因此需要一种能够捕获初始数据包的工具。WinPcap很好地满足了此要求。
WinPcap的内核模式驱动包含了Netgroup Packet Filte,在常规操作系统下开放、便捷、面向大众的网络的系统[2]。同时,WinPcap可以使得Win32平台下的程序在Unix平台运行。并且即便是非常复杂的函数,只要经过WinPcap的简单重新编译,都可以在Win32平台下运行。并且面对网络监听风险,WinPcap有独特的函数调用方式。WinPcap的齐全功能,使它得到了广泛的运用。本文的网络数据流量采集也是基于WinPcap的函数库开展的。
1.2 分类网络流量类型
上一节对网络流量数据样本进行采集之后,就要对网络流量进行分类。在对流量进行分类时,通常运用“流”来描述从源发送到目的地的一组分组,从更加细微的角度体现了流量状态,这为异常检测提供了便利。IP流是网络中的一组分组或帧,在一个时间间隔内可以在网中的某个点截获。同属一个流的数据包若干公共属性相同。由此可以概述单播流 的定义:
定义1:一个IP流可以做如下定义:

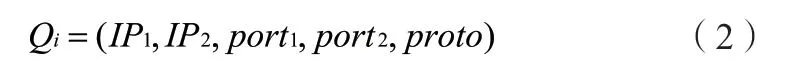
其中,Proto是传输协议,Port1,2代表源和目标传输端口;IP1,2则是IP源和目标地址。具体可以通过图2来说明。
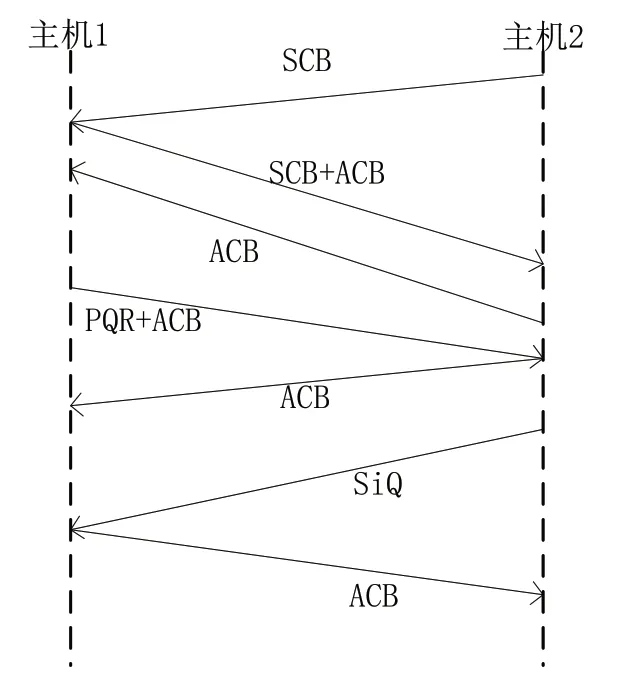
图2 TCP连接通信示例
根据传输原则,我们可以非常清晰地划分一条流的开始和结束。由于一个TPC链接包含了从主机端到客户端和从客户端到主机端两条不同方向的流。因此,只要搜索第一个数据包的标志位,分析是SCB还是SCB+ACB,就可以对流进行区分[3]。当传输层协议并不为我们提供明确的起始信号和结束信号时,我们就要利用不同UDP流持续时间不同这一特点,人为地进行划分。
1.3 基于聚类分析计算相似度
聚类分析法侧重于对变量之间相似性的研究,在将相似的变量归为一类后,得到的结果是不同类的变量差异度大,同一类的变量差异度低。矩阵通常是表现聚类分析数据结构的方式,常用的矩阵分为两种,具体如下。
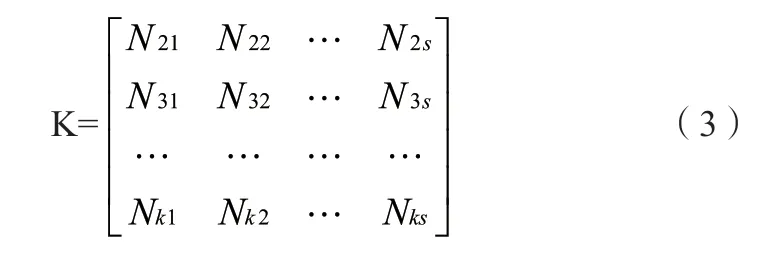
第一种是数据矩阵。在数据矩阵中,如果被分析的数据包含a个对象,而这a个对象有s个变量。那么数据矩阵就可以由以下矩阵表示。可以将以下矩阵看作是数据关系表的结构。
第二种是相异度矩阵。相异度矩阵大多数情况下被用来表示不同对象的相似程度,n个对象的相似程度可以用一个矩阵n表示。用表示第g个对象和第l个对象之间的相似程度,如果对象g与l的相似度大,则的数值小;如果对象g与l的相似度小,则的数值大;如果对象g与l没有差异,则相似度用半角矩阵的形式表示如下:
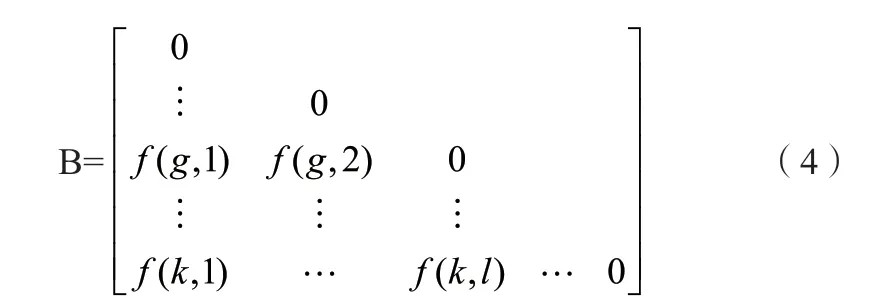
在聚类算法中,数据矩阵要转化为相异度矩阵,比较常见的距离量化方法是马氏(Mahalanobis)距离。马氏距离表示如下:马氏距离全面的考虑了数据之间的相似程度,并且其计算方式与数据的量纲无关,关注到了每一个微小的变量。
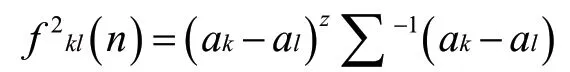
1.4 检测入侵的网络流量
入侵分析是网络入侵检测中最为核心的部分,其中算法的选择直接决定了入侵检测的结果。因此,本论文在基于聚类分析的基础上,提出了基于Fuzzy ART算法的改进K-means算法。
使用聚类分析计算相似度,将数据矩阵转化为相似度矩阵,再用Fuzzy ART网络进行初聚类,由此可以得到符合数据特征分布的n个中心和聚类个数n。再将处理结果输入K-means[4-5]。详细处理过程为:输入向量→初始化网络→Fuzzy ART聚类→网络收敛(不符合则再次进行Fuzzy ART聚类)→获得n及n个中心→K-means聚类→退出程序,输出结果。改进的FART K-means能获得相对合理的n值和起始中心,且不必大量调整参数,算法的复杂程度为:

其中,q为Fuzzy ART训练集数据个数,l是聚类个数,b是数据维数。由此可见改进的FART K-means保存了原始K-means简单快速的优点。一定程度上提高了聚类正确率。
2 应用测试
2.1 实验准备
为了验证改进的FART K-means算法检测网络入侵的效果。将传统的算法和的FART K-means算法在两种入侵数据集KDD CuP99h和 ne tattack上进行对比实验。实验环境参数配置如下:CPU、主频、内存、硬盘、操作系统、编程工具的参数分别为:Inter Core15、2.66GHZ、 4GB 、Windows 8、MATLAB R2009a。
对KDD CuP99进行数据分析,得出land等九种属性取值是字符型的结果。再使用C++提取具有这九种属性的全部值,再进一步进行编码数值化。使用PCA对样本进行处理,把多维数据压缩为少维数据。PCA的处理过程如图3:
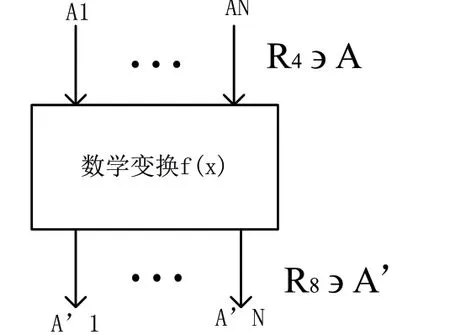
图3 CPA过程表示
原始多维数据集A=(A1,A2,…,AN)p*N经过主成分提取函数f(x)得到少维数据集A’=(A’1,A’2,…,A’N)q*N,PCA提取后的数据维数Q远少于P。运用PCA分析KDD CuP99h,得到18维用于实验的数据,实现标准化及归一化预处理。
2.2 实验结果
从中选择了neptune、smurf、satan、portsweep、warezclient这五类最为常见的攻击方式作为实验的优先选择。实验数据共采集4000条。一部分实验数据用于训练,剩余作为测试使用。在此次实验过程中,训练数据样本共采集3000条,测试数据样本700条,样本分配情况如下表:
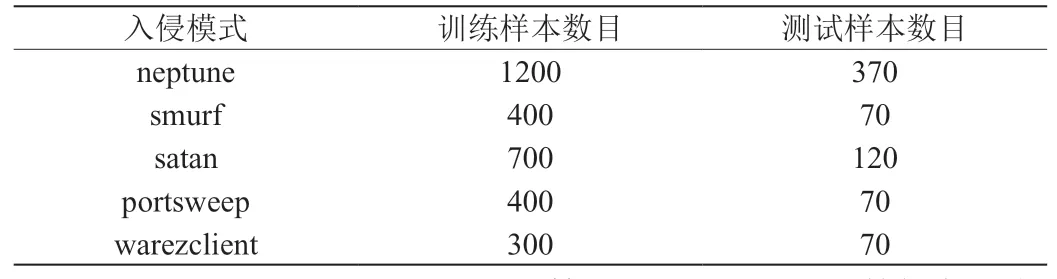
表1 样本分布
用K-means、FART K-means算法对KDD CUP99数据集进行聚类,实验结果如下表:
由表2可知,传统的K-means 算法,平均检测正确率为75.3%,而FART K-means的平均检测正确率达到了87.9%。相比之下提升了12.6%。在此前提下,改进后的K-means算法的平均运行速度也比传统的K-means算法提高了4.3s。综合实验结果,验证了ART K-means聚类分析检测,可以更高效的检测网络异常流量入侵。

表2 两种K-means算法对数据集的聚类结果
3 结束语
本文对聚类分析算法在网络异常流量入侵的应用进行了初步的研究。在阐明了流量的采集和分类之后,阐述了如何运用聚类分析计算相似性,并且提出了FART K-means在网络异常流量入侵情况下的应用。实验证实了FART K-means算法相比于传统算法更为高效和准确。但与此同时,FART K-means算法也不可避免地存在样本数据不够丰富的问题,实验结果容易出现误差。今后可以加大样本采集规模,进行多次测试,将误差控制在最小的范围内,为实验分析提供更为准确的数据。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22 09:52:26
玩具世界(2022年2期)2022-06-15 07:35:36
房地产导刊(2021年8期)2021-10-13 07:35:16
微型电脑应用(2021年3期)2021-03-31 08:56:46
出版人(2020年4期)2020-11-14 08:34:26
电子测试(2017年15期)2017-12-18 07:19:27
北京航空航天大学学报(2017年7期)2017-11-24 05:27:28
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
自动化博览(2014年12期)2014-02-28 22:34:45
