
基于半监督学习和特权信息的多任务算法研究
2023-01-31 11:28:10陈启航
科学与信息化 2023年2期
陈启航
广东工业大学自动化学院研究生 广东 广州 510000
引言
多任务学习是机器学习领域中的一部分,相对于传统的单任务学习,有其独特的优势和应用场景。在现实很多的问题中,往往需要思考不同方面带来的影响。单一的考虑一两个任务太过于局限,并且相关任务之间的共性有助于特定任务的学习过程。而多任务学习恰恰能够通过不同任务之间的联系,找到数据的共性和特性,更好地提升分类器的性能。多任务学习方法主要是这两类:共享相同的参数和共享隐藏的数据特征。目前来说,多任务学习广泛应用在多个领域,比如医疗建模,图像分类,自然语言研究和人工智能等[1-3]。
特权信息是一类带有指导信息的数据,一般都是从训练时获得的。一般来说,附加数据比常规数据更具有信息性,能够带来更多的预测结果。因此,特权信息具有辅助学习的效果,作为模型学习的补充信息,可以用于学习更好的识别系统或者分类系统。现今许多领域的研究中,人们致力于寻找带有特权信息的数据,用以增强各项对应任务的模型学习。实验表明,加入特权信息的分类方法能够提升模型的精度[4-6]。
半监督学习是一种机器学习的方法,用于解决数据很多但带标签的数据较少的问题。在实验中,很多目标函数都是需要使用带标记的数据来预估的,但是往往能获取到的标记实例是费时费力的。面对这种情况,如何将未标记数据和标记数据相结合成为一个至关重要的课题。因此。半监督学习能够利用较少的标记数据来进行标记,能够有效提升数据的使用率,提升分类器的精度[7-8]。
当下很多研究方法都使用了多任务学习的方法,建立相关的模型方法,但是大多数方法都没有考虑到特权信息和半监督学习。因此,为了解决带有半监督学习和特权学习的多任务算法相关问题,本文提出一个基于半监督学习和特权信息的多任务学习算法模型。
1 基本定义
本文基于多任务学习的方法,首先,我们设定任务数为T,同时加入特权信息的研究方法,我们设定数据集合为:
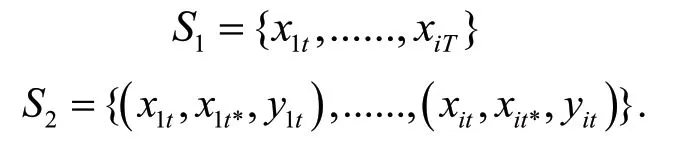
2 研究内容
几十年来,支持向量机一直被认为是数据学习的强大工具,因此支持向量机被广泛应用于多种模型架构之中。根据支持向量机的基础模型,很多学者提出了许许多多的框架,比如根据共同训练风格框架下的互补原则,设计了MVL算法等等。支持向量机本质上是一种二类分类模型,可以理解为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。相对于其他的分类方法,比如决策树,贝叶斯分类等,支持向量机能够体现出更好的分类性能,而且能够解决高维度的分类问题。因此,本文把支持向量机当作基本的分类方法,建立多任务学习的模型。因此,建立一个基于半监督学习和特权信息多任务学习算法模型,如下:
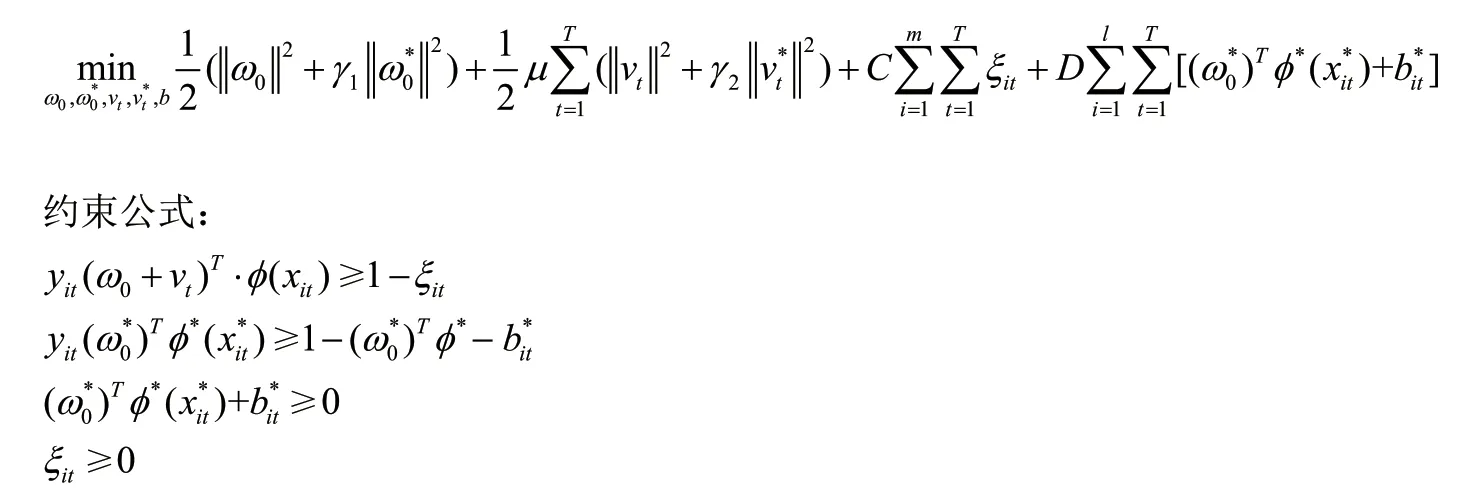
接着对公式进行求解。先把问题转变为一个对偶问题,因此引入拉格朗日乘子进行计算,然后利用对偶形式进行求解优化得到和,再通过KKT(Karush-Kuhn-Tucker)条件求出bt,因此第t个任务中,样本的正负可以由以下方式确定:
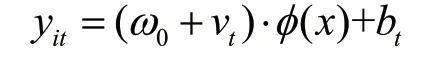
3 实验结果
为了验证模型的准确性,选取了3个数据集合进行实验,以精度来作为评判标准。所选取的3个集合分别为MNIST数据集和NUS-WIDE数据集,设置如表1。
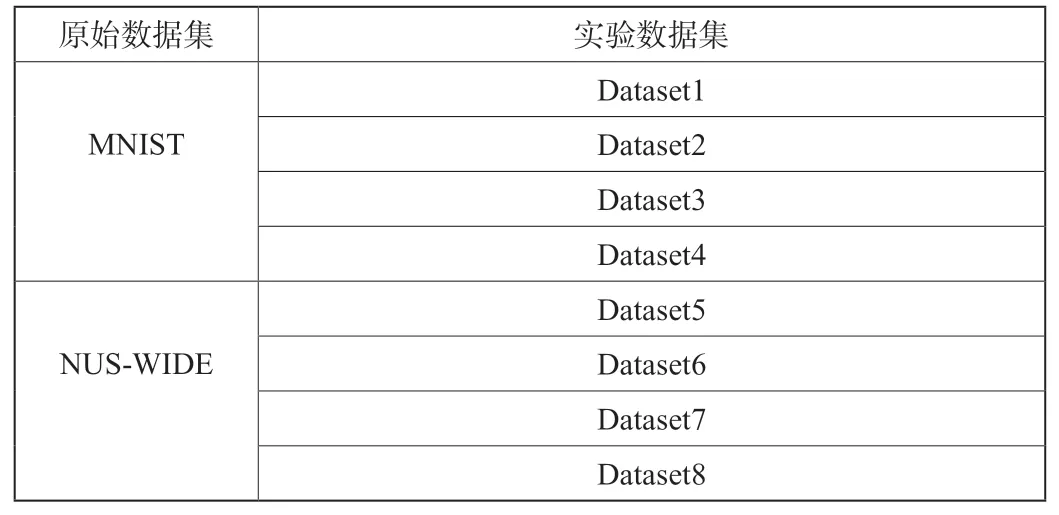
表1 数据集设置
MNIST数据集是一个巨大的手写数字图像库,一共有65000个实例,包含了数字‘0’-‘9’的各类手写图片。在实验中,将数字图片‘2’,‘4’设置为正类,其他数字图像自然默认设置为负类。同时,从HOG描述符获取的信息当作辅助信息。
NUS-WIDE是一个由网页图片和对应标记组成的数据集,一共有2万多实例图片,实验中选取其中的3个子集进行试验。我们将机场,熊,海滩设置为正类,其他的部分默认设置为负类。同时,我们从每一个图像文本里面提取一个多维的词频特征作为特权信息。
针对本方法的方法对照,选取了多任务学习和特权学习相关的学习方法进行性能比较,以此来说明本方法的有效性。选取的方法中,PSVM-2V、L2-SVM[9-10]是特权信息的学习方法,具有良好的泛化能力,误差范围很小。OMTRSL[11]和LSSMTC[12]是多任务聚类的学习方法,能够挖掘数据之间不易发现的结构,找到数据分组的依据。
在实验中,核函数采用高斯核,并且对相关参数进行设定。在L2-SVM方法中,设定函数中的下降指数,建立梯度下降函数,更改对偶形式,转变为更简单的优化问题。在LSSMTC方法中,设定任务数为T,设置惩罚因子为u,并且从数据集合中选择对应的取值范围。对于其他的方法,在每个最佳参数设置下重复20次,对照每一个任务的标准值进行参数调整,使得u值能够在一个允许的范围内变化。实验结果表2。
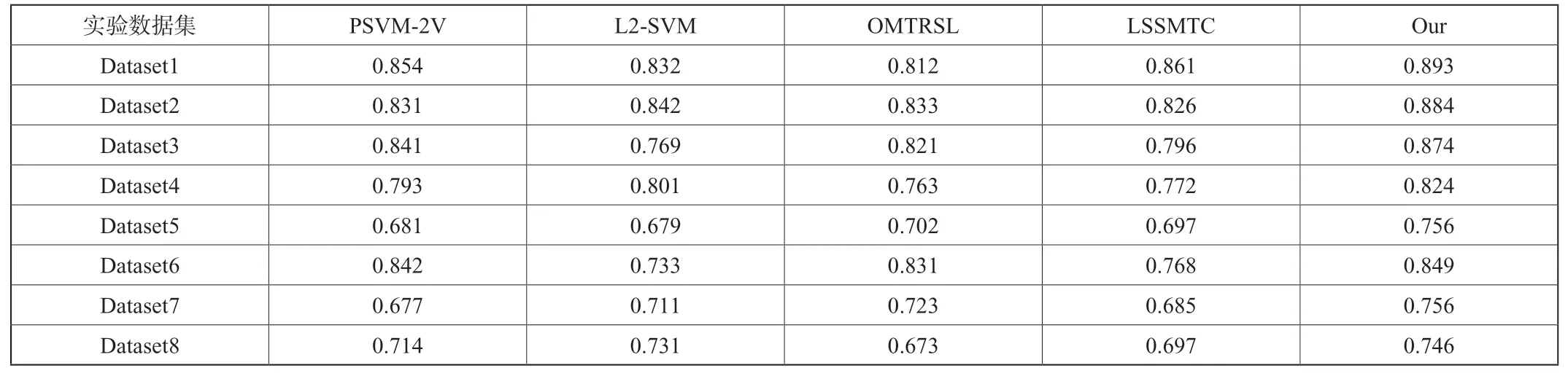
表2 实验结果
由实验结果可知,本文提出的方法有更好的分类性能。相对于PSVM-2V和L2-SVM,多任务协同学习的不仅能共享同一参数的数据,还能参考不同任务之间的个性参数,能够切实提升分类器的性能。相对于OMTRSL和LSSMTC,在不同任务之间加入特权信息,能够辅助模型更好的提升分类器的性能。总之,实验中的结果说明,在基于多任务学习的模型框架下,加入特权信息,能够提升分类器的精度,并且优于其他的分类方法。
同时,对本文提出的方法进行了收敛性的分析。从表1中,选取从MNIST数据集生成的Dataset2,Dataset4,从NUSWIDE数据集中选取Dataset5,Dataset8,作为收敛性分析的数据组。由实验结果可得知,在迭代次数为50次以下时,误差数值在急速下降。当迭代次数的范围在50~65之间时,误差数值趋于稳定,最终在65次左右达到收敛。由此可以得出,基于上述的数据集中,本文提出的方法是收敛的,并且是有良好的分类性能。
4 结束语
本文研究了多任务学习的基本思想和方法,同时充分考虑到特权信息和半监督学习,由此提出了基于半监督学习和特权信息的多任务学习算法模型。该模型能够自动学习不同任务之间的参数,构造相似矩阵来学习任务之间的相关性。同时,选取不同的数据集,进行恰当的分组实验和对照实验,并且证明了模型的收敛性。这表明,本文提出的算法是优于大多数现有的算法,体现出更好的分类性能。对于未来的展望,希望针对辅助信息的多维度进行探究,为提升分类精度而考虑更多方法。
猜你喜欢
好日子(2022年3期)2022-06-01 15:58:27
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
自动化学报(2016年3期)2016-08-23 12:02:56
电测与仪表(2016年5期)2016-04-22 01:13:46
广州大学学报(社会科学版)(2015年1期)2015-02-27 12:40:14
电测与仪表(2014年15期)2014-04-04 12:05:20
浙江人大(2014年6期)2014-03-20 16:20:42
