
基于CNN-BiLSTM特征融合的异常检测算法
2023-01-31 08:56王晨辉王恩东高晓锋
计算机应用与软件 2022年12期
王晨辉 王恩东 高晓锋
1(郑州大学信息工程学院 河南 郑州 450001) 2(浪潮电子信息产业股份有限公司 山东 济南 250101)
0 引 言
云计算的发展带来数据中心规模化、集中化的趋势,为保障用户所需业务的稳定运行,在云数据中心需要对监控指标进行异常检测,但由于监控指标多、数据量大的特点,完全依赖人力来判定异常已经不切实际。同时数据中心和人们的生产生活都密切相关,一旦异常不能够及时进行处理,就会带来严重的损失。2018年8月,腾讯云服务因操作失误造成大量数据丢失,造成了难以估量的损失。因此,亟需一种高效且稳定的运维方式来解决这一问题。Gartner于2016年提出智能运维(Artificial Intelligence for IT Operations,AIops)的概念,基于数据中心的运维数据,通过统计机器学习的方法来处理手动运维无法解决的问题[1],进而大大提高了运维效率。
1 相关工作
针对智能运维中异常检测方法的研究,国内外的研究人员将异常检测方法主要分为两种。一种是基于统计模型的方法[2],例如:Yahoo团队于2015年提出一种时间序列异常检测框架EGADS[3],将目前流行的回归模型和差分移动平均模型等统一放到上述框架中,在所提供的数据集中得到了可靠性较高的检测结果;James等[4]提出了一种可以自动检测数据中的异常点的统计模型方法,通过传统的能量统计方法来监测数据中的异常点出现的概率。另一种是基于机器学习或者神经网络的检测方法。Liu等[5]与百度公司合作并提出了一种关键性能指标(Key Performance Indicator,KPI)自动异常检测系统Opprentice,通过特征提取的方法将数据放到一个训练好的随机森林模型中去,通过分类判定数据的异常。Liu等[6]提出的孤立森林(Isolation Forest)算法属于一种无监督算法,递归地随机分割数据集,将异常定位于分布稀疏且离密度高的集群较远的点。
以上异常检测方法大都是基于传统的统计模型和机器学习算法,同时也有研究人员尝试将多种深度学习方法应用于异常检测,深度学习模型在图像、语音识别等领域应用比较广泛,其中最具代表性深度学习方法包括卷积神经网络(CNN)[7]和循环神经网络(RNN)[8],CNN和RNN可以分别提取空间和时间上的特征,研究人员[9]根据数据的时态特征尝试结合这两种方法可以在时间序列上更好地进行预测和分类。Kim等[10]首先应用了C-LSTM[11]时间序列异常检测模型,C-LSTM模型由CNN、LSTM和深度神经网络(DNN)组成。首先,应用滑动窗口将时间序列分为几个固定长度的序列,并建立新的序列数据集;然后高层的时空特征由CNN和LSTM从窗口数据中提取;最后将提取的特征输入到一个全连接的DNN网络实现分类。文献[10]中的模型基于线性结构,依次将数据从一维卷积神经网络输出到LSTM,然后输出结果到全连接层进行分类,能够较好地提取时间和空间特征,但缺少对融合特征的处理。基于文献[10]中的研究方法,本文提出改进的网络架构,以更好地应用于异常检测,在获取数据集后,使用滑动窗口用于生成时间相关的子序列,分别输入到一维卷积神经网络和BiLSTM中去,得到数据的空间和时间特征,然后将提取到的特征使用Attention进行加权,得到融合特征,再将其输入到一个全连接层得到预测结果,最后通过Softmax函数进行分类。
2 CNN-BiLSTM-Attention模型结构
2.1 卷积神经网络
卷积神经网络(CNN)是一种前馈神经网络,其最初是由Lecun等[7]提出,CNN的本质就是构建能够提取数据特征的滤波器,因此在深度学习领域中多被用作特征提取网络,一个完整的CNN网络包括输入层、输出层和隐藏层,隐藏层又可以分为卷积层、池化层和全连接层,本文主要用到其中的卷积层和池化层,其大致结构如图1所示。
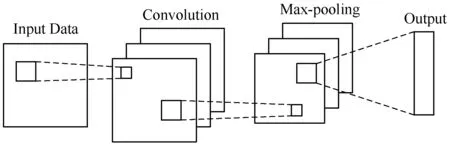
图1 CNN结构示意图
图1中的卷积层和池化层主要用于提取输入序列的空间特征[12],其中卷积层利用滤波器来处理输入的序列,从而依次获得空间上的特征,卷积层后接一个激活函数,本文使用tanh双曲正切激活函数,从而能够提取更加复杂的特征。
Pooling层主要是用于减少CNN网络的参数,从而能够减轻计算压力,池化的方法有均值池化和最大池化,本文取用Max Pooling,其实质上就是在n×n的样本中取最大值,作为采样后的样本值。
2.2 长短时记忆网络
LSTM是一种由循环神经网络衍生而来的时序神经网络,它使用存储单元来代替RNN中的循环单元来存储时间序列的特征,能够比较好地解决循环神经网络中的长时间依赖问题[13]。
LSTM内部结构如图2所示,其中:xt代表第t个输入序列元素值;c表示记忆单元,其控制着序列的传递;i指代输入门决定当前xt保留多少信息给ct;f代表遗忘门,其决定保存多少前一时刻的细胞状态ct-1传递至当前状态的ct;o指代输出门,其决定ct传递多少至当前状态的输出ht;ht-1指代在t-1时刻的隐层状态[14]。
上述过程对应公式如下:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(4)
ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=ot∘ tanh(ct)
(6)
式中:Wf代表遗忘门的权重矩阵;[ht-1,xt]表示上一时刻与当前时刻组成的新的输入向量;Wi代表输入门的权重矩阵;Wc代表记忆单元的权重矩阵;Wo代表输出门权重矩阵;bf代表遗忘门的偏置量;bi代表输入门的偏置量;bc指代记忆单元的偏置量;bo代表输出门的偏置量;σ指代Sigmoid激活函数;∘ 表示向量元素乘。
LSTM更适合进行时间扩展,并且较好地解决了长时依赖问题,具有长期记忆功能,能够很好地处理时间序列上的特征[15],上面的CNN通过卷积和池化操作提取空间特征,LSTM可以在提取空间特征的基础上进一步提取时间维度上的特征,从而能够提升数据特征的表达能力。
2.3 注意力机制
Attention机制是基于人类观察事物的过程而演进过来的一种方法,人们在观察事物时并不会将整个事物完全地看一遍,而是根据自己的偏好有选择性地进行欣赏。基于此,将Attention用到对空间和时间特征的处理上,可以获得包含原数据更多信息的融合特征[16]。本文中的Attention主要是对前面CNN和LSTM提取的特征进行加权处理,从而捕捉到原序列空间和时间上的融合特征,然后放到模型中进行预测,其大致结构如图3所示。
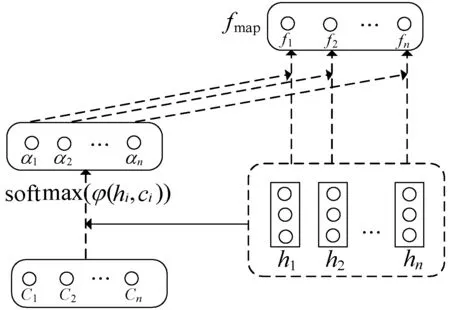
图3 Attention结构
φ(hi,C)=tanh(hi·Wα·CT+bα)
(7)
(8)
(9)
式中:Wα是一个m×n的权值矩阵;bα为偏置项;C为CNN网络得到的特征向量;hi为第i个时刻LSTM得到的特征向量。式(7)是将CNN和LSTM提取到的特征进行加权,并通过激活函数得到融合后的权值;式(8)是将权值通过Softmax函数;最后通过式(9)将LSTM的输出值与权值相乘得到最终的特征,然后将其通过一个全连接层的网络输出预测结果[17],最后通过Softmax函数将数据分类为0(正常)或1(异常)。
2.4 模型结构和参数设置
本文所提出的CNN-BiLSTM-Attention完整结构如图4所示。
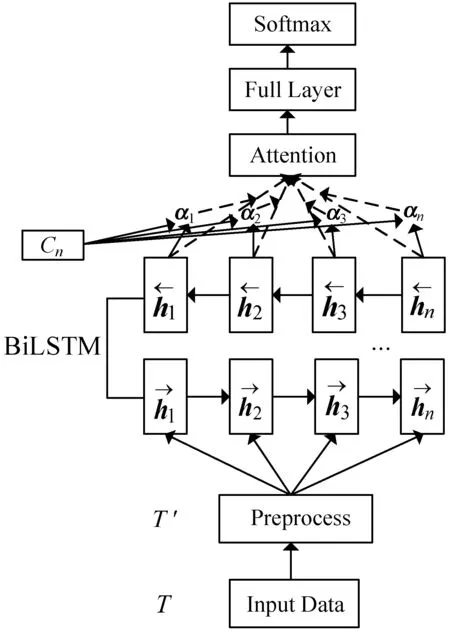
图4 CNN-BiLSTM-Attention模型结构
图4中,首先对输入数据进行预处理,然后将处理过的数据分别输入到CNN和BiLSTM网络中去得到相应的空间和时间上的特征,然后将这二维特征使用Attention进行加权,然后将权值与LSTM网络输出进行相乘,得到融合特征,然后将其通过全连接层和分类器进行分类。
CNN-BiLSTM-Attention算法流程如算法1所示。
算法1异常检测算法
输入:
1.原始时间序列X=[x1,x2,…,xt];
2.滑动窗口的窗长b,步长s;
3.训练好的CNN-BiLSTM-Attention模型;
输出:
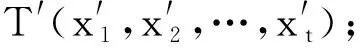
2. 通过CNN网络从输入数据中提取高维度空间特征;
3. 通过BiLSTM网络提取高维度时间特征;
4. 使用Attention机制对空间特征和时间特征进行加权得到融合特征;
5. 将融合特征输入到全连接层网络和Softmax函数进行分类,得到分类结果0或1;
Endfor
本文所提出模型中包含许多的参数,其中CNN滤波器个数为64,卷积核大小为5,步长设置为1,LSTM中隐层单元个数为64,Adam优化器用来优化深度学习模型,epoch设置为100,batch size设置为64,学习率设置为10-3,使用tanh作为激活函数,交叉熵作为损失函数来评估模型的优劣。
3 实验与结果分析
3.1 实验配置
本文实验的设备为个人电脑,核心处理器为Intel(R) Core(TM)i7- 9750H CPU @ 2.50 GHz,RAM 16 GB,图形处理器为NVIDIA GeForce RTX 2060,Windows 10操作系统,开发环境是Python3.6.5,Keras- 2.2.4,TensorFlow- 1.14.0。
3.2 实验数据及预处理
本文实验数据集选用雅虎[18]和亚马逊[19]这两大云平台所监控采集的KPI时序数据集。这些数据集来源于真实的业务环境,涵盖了云环境中大部分KPI时序数据可能出现的形态特征和异常类别,具有较好的代表性。
本文使用了Yahoo Webscope S5异常基准数据集中的A1类,包含67个文件,用于验证提出的异常检测算法结构,其收集到的数据来自实际Web服务的流量监测值,采集频率为5分钟一次,并且手动标记异常值。亚马逊的数据集来自于云监控CloudWatch所采集的服务器基础资源指标数据,包含多种服务器运维指标,并分别以这些指标进行命名。这两个数据集均是由时间戳、值和标签组成,KPI中的值是某个KPI指标在对应的时间戳的值,对应上面所说的Web流量监测数据和服务器基础资源指标数据,是企业经过脱敏处理后的监测数据,标签是运维人员对于异常与否进行的标注。这里分别选取Yahoo数据集中类别为A1的真实数据集和亚马逊数据集中编号为cpu_utilization_asg_misconfiguration的监控CPU利用率的数据集进行模型训练,分别记为数据集①和数据集②。图5(这里是A1类中的其中一个数据集)、图6是两组数据集的时序曲线(为截取的其中一部分数据曲线)。
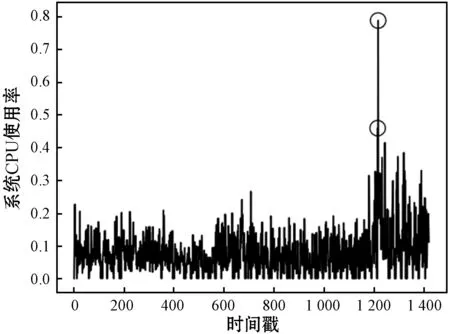
图5 数据集①时序曲线
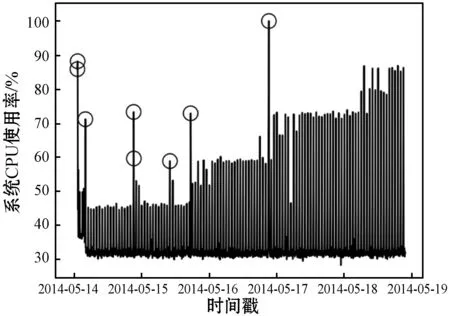
图6 数据集②时序曲线
由图5和图6中的时序曲线可以看出,数据集①中曲线变化趋势相对明显,图5中标注的部分即为离群异常点,真实网络流量的突增突降意味着网络的异常占用,对正常用户使用造成影响。数据集②中,标注的部分表现为数据激增,正常系统中任务到来时CPU利用率会增长继而表现平稳,并不会突然地增加下降,如图6中未标注的部分。表1是两个数据集的数据情况对比。
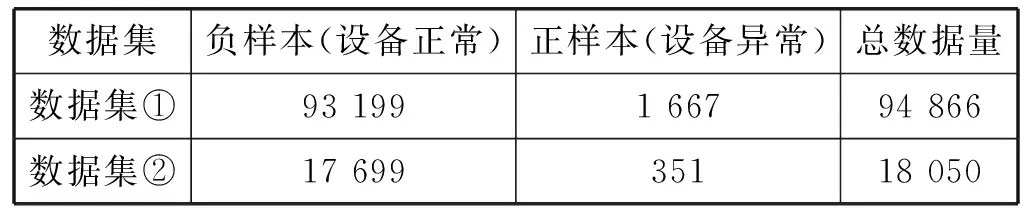
表1 实验数据集对比
可以看出,数据集中的负样本数量占比较大,因为系统在大多数情况下都处于正常工作状态,因而正负样本比例严重不平衡,这样会使得模型训练效果大打折扣。因此本文采用过采样联合欠采样的方法来解决数据不平衡问题[20],对大样本进行欠采样,对小样本进行过采样,从而使得正负样本比例接近对等,保证模型的训练效果。过采样包含简单随机过采样和启发式过采样,前者仅仅是对小样本进行简单的复制使得其在数量上大大增加,并没有增加小样本所携带的特征信息,对于模型训练效果并没有很好地提升;后者是利用当前小样本来合成新的样本,比较典型的是SMOTE(Synthetic Minority Oversampling Technique)算法,其是在邻近小样本之间进行插值,得到新样本,然后依次进行插值,最终增加小样本的数量,这样得到的小样本就携带有新的特征信息,使得模型训练的效果得以提升。这里主要是用SMOTE算法进行小样本过采样和简单随机欠采样,使得数据样本得以均衡。
在对数据进行均衡之后,需要对数据进一步处理,得到适合模型输入的数据格式,因为原始数据为一维时间序列,需要将数据处理成多维的向量格式,这里使用滑动窗口的方法,具体流程如图7所示。
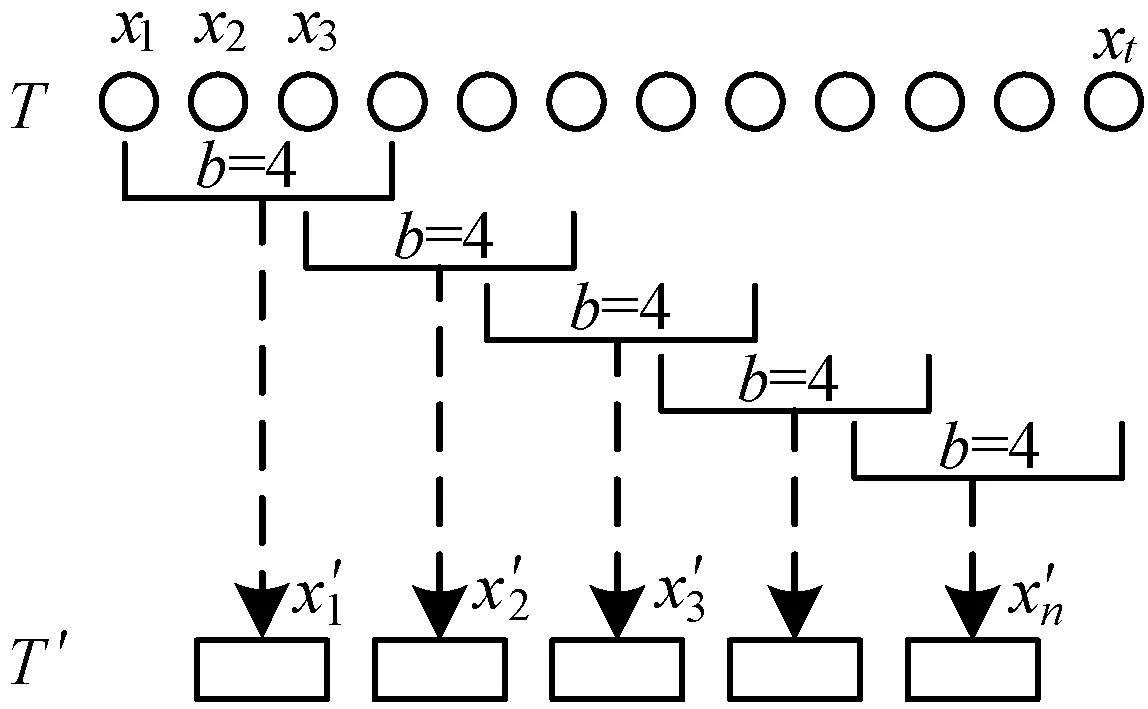
图7 滑动窗口流程
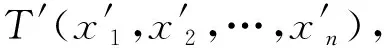
(10)
(11)
在对数据进行加窗时,还要注意窗口长度和步长的设置,设置过大会使特征淡化,使得数据间的特征偏离原数据特征,因此这里以窗长和步长为变量,对模型进行训练,得到如图8和图9所示的随训练周期变化的损失函数曲线。
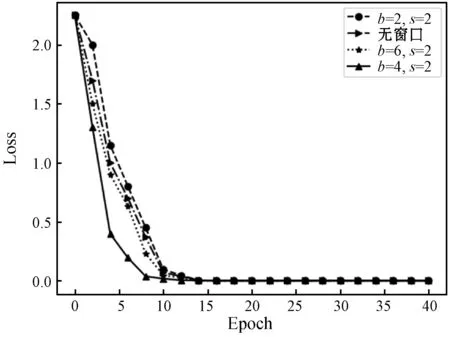
图8 数据集①损失函数曲线
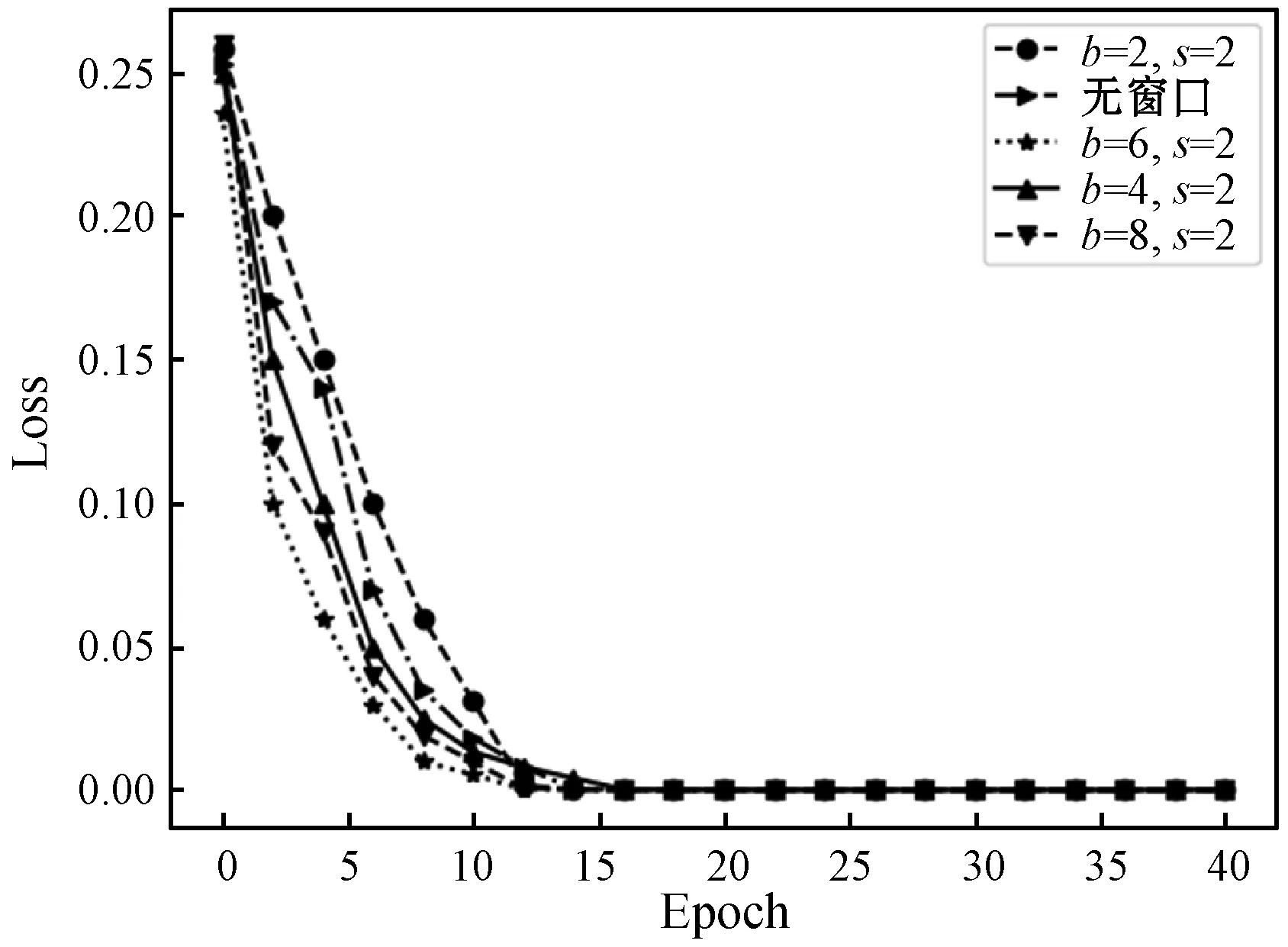
图9 数据集②损失函数曲线
从图8和图9的损失函数来看,在进行加窗处理过后,损失值也相应降低,曲线下降趋势也比未加窗的要快,但是当窗口长度设置较高时,效果反而不佳,因为设置的窗口长度过长时,其提取的特征也会相应偏离原数据特征。因此,针对相应的数据,应设置合适的窗口长度以得到最佳的特征提取效果,由图8、图9的下降趋势来看,这里对数据集①选取窗长b=4,步长s=2,数据集②选取窗长b=6,步长s=2。
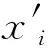
(12)
式中:xmin表示数据中的最小值;xmax表示数据中的最大值。
3.3 评价标准
分类算法的评价指标较多,这里选取以下几个标准对模型进行评估,准确率代表所有分类正确的样本个数与总体样本的比例,其数值越高,代表模型预测正确的数目越多,如式(13)所示。精确率代表模型预测结果是正类数的数据中原本为真的数据的比例,数值越高,查准率也就越高,如式(14)所示。召回率代表模型预测为正类数的数据与原本属于正类数据总数之间的比率,数值越高,查全率就越高,如式(15)所示。F1-score值是由精确率和召回率计算得到的,由式(16)可以看出,当精确率和召回率接近时,其值最大,值的大小往往反映着模型的综合指标。
(13)
(14)
(15)
(16)
式中:TP为将正类预测为正类的个数;FN为将正类预测为负类的个数;FP为将负类预测为正类的个数;TN为将负类预测为负类的个数。
3.4 实验结果
将预处理过后的数据放到模型中进行训练,得到图10和表2、表3中的实验结果。
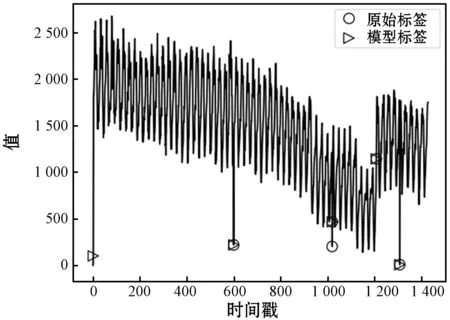
图10 检测效果对比
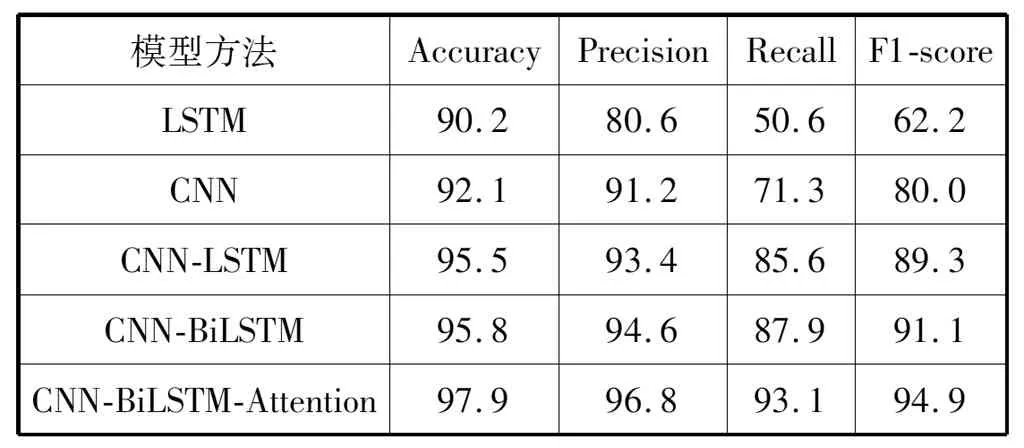
表2 各个模型效果对比(数据集①)(%)
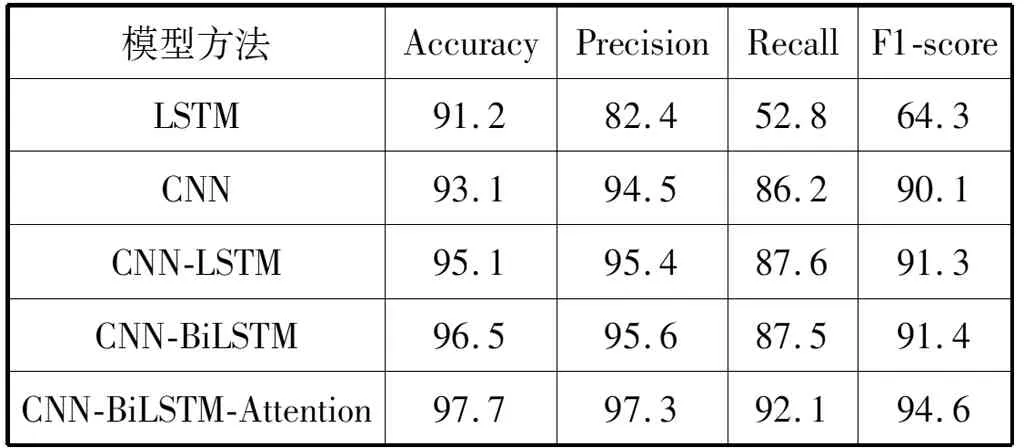
表3 各个模型效果对比(数据集②)(%)
图10为测试集中原有的标记与模型标记对比图,模型标记为三角,可以看出模型可以比较准确地标记出异常点位置。由于对数据进行了加窗处理,相邻的异常点就会标注为一处,比如在横坐标为1 020位置。而在起始位置数据表现为突增,这里模型进行了异常标注,原数据应表现为机器开始运作有大量的网络流量涌入,因而出现了误报的情况。由表2和表3中的数据可以看出,混合模型的训练效果相比单个模型有着很大的提升,在数据集①中,单个模型的F1-score值均比较低,数据集②中单一LSTM模型的F1-score值也相对较低,通过提取单一的特征可以得到数据间的简单特征,但当面对数据量较大时,就难免捕捉不到数据间的复杂特征,当使用混合模型时,对数据特征的捕捉能力提升,同时加入双向LSTM编码可以对上下文之间的特征获取更加全面。最后使用Attention可以对特征进行合理加权,得到更好的检测效果,最终准确率均能保持在97%以上,F1-score值可以达到94%以上,证实了本文模型的有效性。
4 结 语
针对运维系统复杂性和运维数据多样性的特点,本文提出一种基于CNN-BiLSTM的混合模型,并引入了Attention机制,用于提取融合特征来实现可靠性更高的云数据中心异常检测,实验表明该模型表现良好,准确率、精确率及召回率均能达到92%以上,证实了算法的有效性。然而,运维数据的异常检测通常要关注一个大型系统中的成百上千个参数,在以后的工作中,将转向如何更加有效地提取多维数据的复杂特征,因为系统的异常往往伴随着各个指标的偏差,多维监控指标的异常分析对于运维人员监测系统运行状态更有帮助,其包含有更多的异常判决因素,进而更加有效地提高检测效率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
中国交通信息化(2019年5期)2019-08-30
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
能源(2018年8期)2018-09-21
北京航空航天大学学报(2018年1期)2018-04-20
能源(2017年11期)2017-12-13
山东工业技术(2016年15期)2016-12-01
