
SpringBeanUtils和ApacheBeanUtils属性拷贝的对比和应用*
2023-01-30 04:08:20杨春发
计算机时代 2023年1期
杨春发,潘 鹤,李 鑫
(1.中国电建集团华东勘测设计研究院有限公司,浙江 杭州 311122;2.中电建华东勘测设计研究院(郑州)有限公司)
0 引言
“沣西新城”为区域内建设项目,对于其数据平台的建设,需要融入CIM(City Information Modeling)理念,即建立CIM 基础数据平台。该平台服务于城市规划、建设和治理等多个场景,为城市挖掘数据价值,有效避免重复投资与建设助力。
平台开发中,需要将不同二维数据对象的相同或相似属性进行赋值。传统的方法是通过手动编写Getter/Setter 为属性或字段赋值,当拷贝对象字段较多时,会导致大量代码堆积,可读性降低。为解决这一痛点,平台引入拷贝工具类,分别为Apache和Spring的BeanUtils,以优化两个任意多字段对象的属性拷贝,提高开发效率,为相似二维数据对象复制繁琐问题,提供解决方案。
1 相关定义
1.1 BeanUtils
JavaBeans 的静态便捷方法,对Bean 进行实例化、检查属性类型、复制属性等操作。应用比较广泛的一个是Apache Commons 的BeanUtils,另一个是Spring Framework的BeanUtils。
1.2 JavaBean
JavaBean 作为工具类的作用对象,本质上是一种命名规则,具体如下。
⑴对于一个名称为xxx的属性,通常要写两个方法:getXxx()和setXxx()。任何浏览这些方法的工具,都会把set 或get 后的第一个字母转为小写,以此产生属性名。get方法返回的类型需要与set方法里的参数相同,属性名称与get和set所依据的类型毫无关系。
⑵对于布尔类型属性,使用以上的get 和set 方式,可把get替换成is。
⑶ Bean 中的普通方法不必遵循以上的命名规则,不过其访问权限控制符必须是public的[1]。
2 实现原理
2.1 深拷贝与浅拷贝
工具类本质上是对象的拷贝,而对象拷贝又分为深拷贝和浅拷贝,BeanUtils 的拷贝方法就是浅拷贝,拷贝原理见图1,定义如下:

图1 拷贝原理图
⑴浅拷贝:对基本类型采用值传递(传递该变量的副本)。对引用类型进行引用传递即复制指向源对象的地址,不复制对象本身,修改新对象会影响原对象。
⑵深拷贝:对基本类型采用值传递,对引用类型来说,深拷贝会复制一个完全与源对象一样的对象,且不共享内存。
2.2 反射与自省
工具类的核心拷贝原理就是通过反射和自省实现的。
Java反射机制是在运行中,对任意一个类,能够获取得到这个类的所有属性和方法,对于任意一个对象,都能够调用类的任意一个方法,这种动态获取类信息以及动态调用类对象方法的功能叫做Java语言的反射机制[2]。利用反射机制编写与执行程序代码时,使程序代码能够接入装载到JVM中的类的内部信息[3]。
内省是操作Java 对象属性的API,内省依赖于反射,利用BeanInfo来获取属性描述器,就可获取某个属性对应的Getter和Setter方法,最后通过反射机制来调用Getter和Setter方法[4]。
2.3 小结
BeanUtils 本质是通过内省对JavaBean 的属性进行浅拷贝,通过Class 引用获取BeanInfo 信息,调用BeanInfo 的getPropertyDescriptors 方法,返回类型为PropertyDescriptor 的属性描述器数组。针对每一个PropertyDescriptor,调用getPropertyType 方法得到类型,getName 方法得到属性名,getReadMethod 方法得到读方法,getWriteMethod 方法得到写方法,后两个方法返回Method 对象,在对象上调用相应方法(invoke),进行属性的赋值。
3 实验与结果分析
3.1 实验场景
实验以平台的三维可视化系统返回单条场景及相关信息为例进行测试,使用Spring-Beans5.1.10 和Commons-BeanUtils1.9.3 作为实验版本,持久层方法对源对象属性赋值后,依次用两个工具类对源、目标对象的同名属性值进行拷贝,打印场景联合体对象的编号、名字、相关第一条图层编号、相关第一条标绘编号,核心调用方法如下:

3.2 结果分析及结论
3.2.1 链式编程的支持性
⑴实验结果及分析
图2 是工具类对启用链式编程的对象拷贝后的打印结果,使用Spring 的BeanUtils 能正常打印新闻信息,而使用Apache 的BeanUtils 拷贝为空,具体原因如下。

图2 启用链式编程打印结果
①Apache 中,使用默认的getWriteMethod()方法,通过查找set前缀的属性名方法并判断返回类型是否为void类型,如下:

②而SpringBean 中在获取BeanInfo 对象的过程中,提供候选方法,候选可写方法将返回类型不是void的类型纳入可写方法中,而链式编程的返回类型是本类,这就导致Apache的BeanUtils不支持链式编程。


③关闭链式编程后再次测试,两个工具类会打印同样的结果,如图3所示。

图3 关闭链式编程打印结果
⑵结论
Spring 的BeanUtils 支持链式编程,而Apache 的BeanUtils不支持。
3.2.2 安全性
⑴实验结果及分析
图4、图5 是Spring BeanUtils、Apache BeanUtils对于null的Long 写入long 类型的打印结果,前者提示非法参数异常,后者拷贝正常,原因如下:

图4 SpringBeanUtils打印结果
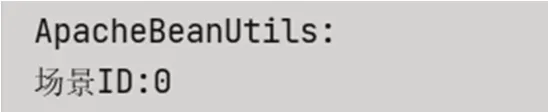
图5 ApacheBeanUtils打印结果
①Spring的BeanUtils的部分代码:

②Apache的BeanUtils的部分代码:


Apache 的工具类采用多种数据验证方式来保障安全性,包括类型的转换,甚至还会检验对象所属类的可访问性。
⑵结论Spring的BeanUtils校验更少,而Apache的BeanUtils会进行多种数据验证和类型转换,是更安全的。
3.2.3 性能
⑴实验结果及分析
针对两种拷贝工具类一次进行100,10000,100000,1000000 的对象数量多次拷贝,具体平均消耗时间如图6所示。

图6 BeanUtils性能对比图
在大数量对象拷贝时,SpringBeanUtils 的拷贝性能是ApacheBeanUtils 的近十倍,其主要原因在于Apache BeanUtils 对属性的各类条件判断,包括但不限于类型、可读性等。Apache BeanUtils 还对类加载器进行单例限制,获取实例时会加锁,造成资源持有,影响性能。
⑵结论
Spring 的BeanUtils 内部逻辑简单,效率比Apache的BeanUtils更高。
4 总结
针对平台二维数据的需求场景选择不同的拷贝工具类,实现数据的转换。将沣西新城CIM 基础平台构建为一个不仅是数据展示,更是数据管理的载体。对于平台性能要求较高的场景,可采用Spring 的BeanUtils,如有更多的格式验证、访问控制的需求,可采用Apache的BeanUtils。使用过程中应注意以下几点:
⑴涉及数值类型的封装类像Integer、Short、Long、Double的数据转换时,Spring BeanUtils需要手动初始化,否则提示数据转换异常。而Apache BeanUtils 内置转换器,无需担心初始化问题。
⑵两个拷贝工具类方法的传参顺序是相反的,SpringBeanUtils 的参数顺序是(source,dest),而ApacheBeanUtils顺序为(dest,source)。
⑶ Spring 的BeanUtils 可指定忽略字段,实现Bean的部分属性拷贝。
⑷涉及Date 对象的数据转换时,需注意Apache的BeanUtils 不支持until 包下的Date 类,应使用sql 下的Date类,避免数据异常。
此外,BeanUtils 并不是任何场景都适用的。BeanUtils 的不足之处在于其本质是浅拷贝,涉及对象只能是单一属性和或者几乎不改动的子对象。一但涉及深拷贝的场景,BeanUtils 是无法满足的。另外,虽然使用BeanUtils 进行属性拷贝十分方便,极大的减少了代码冗长,但由于各种验证、获取及调用方法、序列化等对象操作,BeanUtils 的消耗时间实际上比手动调用Getter/Setter的时间长,因此要合理使用。
猜你喜欢
商品与质量(2019年34期)2019-11-29 03:25:51
测控技术(2018年5期)2018-12-09 09:04:46
中国生殖健康(2018年1期)2018-11-06 07:14:38
黑龙江电力(2017年1期)2017-05-17 04:25:05
信息安全研究(2016年4期)2016-12-01 06:07:05
电测与仪表(2015年4期)2015-04-12 00:43:08
电测与仪表(2015年4期)2015-04-12 00:43:08
中国工程咨询(2015年10期)2015-02-14 05:57:18
中国信息化·学术版(2013年1期)2013-05-28 05:53:24
计算机应用文摘(2011年8期)2011-04-29 00:44:03
