
适用于Android平台的SG-YOLO人脸检测算法研究
2023-01-30 04:08:14邹振超
计算机时代 2023年1期
邹振超,刘 瑜
(浙江理工大学机械与自动控制学院,浙江 杭州 310018)
0 引言
随着科技的日新月异,人脸识别技术被应用到生产、生活的各个领域,而人脸检测是人脸识别的一个重要环节,在进行人脸识别之前,需要检测出图像中是否含有人脸,并获得人脸在图像中的位置、姿态等信息。随着移动设备不断智能化,个人隐私问题不断突出,人们对移动设备信息安全提出了更高的要求,基于移动设备的人脸识别在普及过程中遇到了很多问题。比如移动设备的摄像头采集到的视频图像受到光照、背景、姿态以及表情等影响,使得移动设备的人脸识别无法达到较高的准确性和实时性。
传统的人脸检测算法有模板匹配方法、统计模型方法及知识规则方法等,在检测速度上具有实时检测的优势,但是在实际使用中,受到光照等环境因素的影响,鲁棒性差。近些年来,基于深度学习的检测算法已经越来越成为人脸检测的趋势,如Li 等提出的CascadeCNN 算法、Redmon 等在2015 年提出的YOLO算法以及R-CNN、Fast-R-CNN、Faster-R-CNN 等熟知的目标检测算法[1-3]。在配置有GPU 的PC 端,由于较强的计算和处理能力,这些深度网络模型可以快速地运行,能够达到对人脸的实时检测,但是对于一些移动设备来说,由于GPU 处理器性能的限制,检测速度只能达到1-2FPS的帧率,达不到实时检测。
为了提高在移动设备的运行速度,研究者们提出一些小型化的目标检测网络,如Redmon 提出YOLOTiny 模型[4],以达到实时检测的目的,但是检测精度也会随之下降。为了兼顾人脸检测的快速性和准确性,同时减少模型参数,本文基于YOLOv4 算法提出一种轻量级的人脸检测算法SG-YOLO(Shuffle Attention AndGhostNet-YOLO),在PC 端训练好后移植到RK3288 主板的Android 平台,提升检测的精度,验证其工程需求。
1 SG-YOLO算法结构
YOLO算法是基于深度学习的一种端到端的目标检测算法,本文主要在YOLOv4的算法基础上进行改进优化。YOLOv4的主干特征提取网络为CSPDarkNet53,包含Mish 激活函数和五个CSPNet,起到下采样和残差块堆叠的作用。第三个和第四个CSP 残差模块会经过卷积输入到PANet 结构中,第五个CSP 残差模块经过卷积后输入到SPP 结构中,SPP 和PANet 对特征层进行了特征的融合[5]。特征融合后,YOLOHead 利用获得的特征进行预测,会输出三种特征层,尺寸大小分别为输入尺寸的1/8、1/16、1/32。对于输入大小为416×416的图片相当于划分为52×52,26×26,13×13的三个不同大小的网格图,每个网格图生成三个不同的先验框进行预测,通过调整计算获得预测框,YOLOv4的结构如图1所示。

图1 YOLOv4结构图
此结构虽然在精度上有很大的提升,但是CSPDark 模块中的很多卷积层存在相互堆叠的情况,造成YOLOv4 的参数量和计算量偏大,无法满足在移动设备上实时检测的需求。
本文为了便于在低算力的Android 平台上完成部署,提出将人脸检测模型轻量化,首先将主干网络CSPDarknet替换成GhostNet网络[6-8],具体实现是运用更低计算量的操作生成含有冗余量的特征图,其中Ghost Module 是该网络的最小单元,通过线性运算生成特征图,Ghost Module通过卷积生成GhostBottleneck,最终构建出Ghost Net。Ghost Module 的功能是代替普通的3×3 卷积,首先对输入进来的特征图利用1×1 卷积进行通道的缩减,获得特征浓缩。完成通道缩减之后对每一个通道使用逐层卷积获得更多的特征图,获得特征图之后将1×1 卷积后的结果和上述特征图进行堆叠,获得输出特征层,其结构如图2所示。
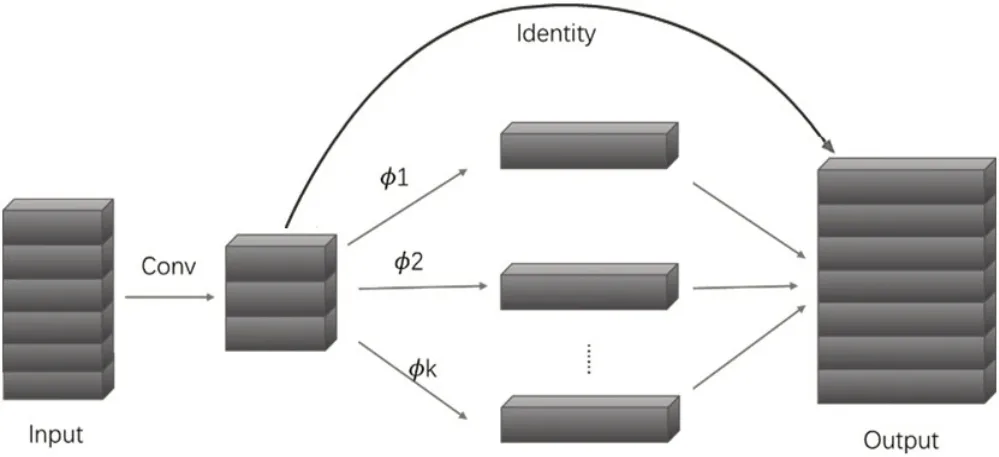
图2 Ghost Module结构图
接着使用Ghost Module 构建瓶颈结构,结构图如图3 所示,将两个Ghost Module 组成一个Ghost bottleneck,第一个Ghost Module作为扩展层来增加通道数,第二个Ghost Module 与shortcut 通道相匹配来减少通道数Ghost bottleneck 分为步长为1 和步长为2两类,步长为1 的Ghost bottleneck 不对输入进来的特征层进行宽和高的压缩,步长为2 的Ghost bottleneck对输入进来的特征层进行宽和高的压缩。
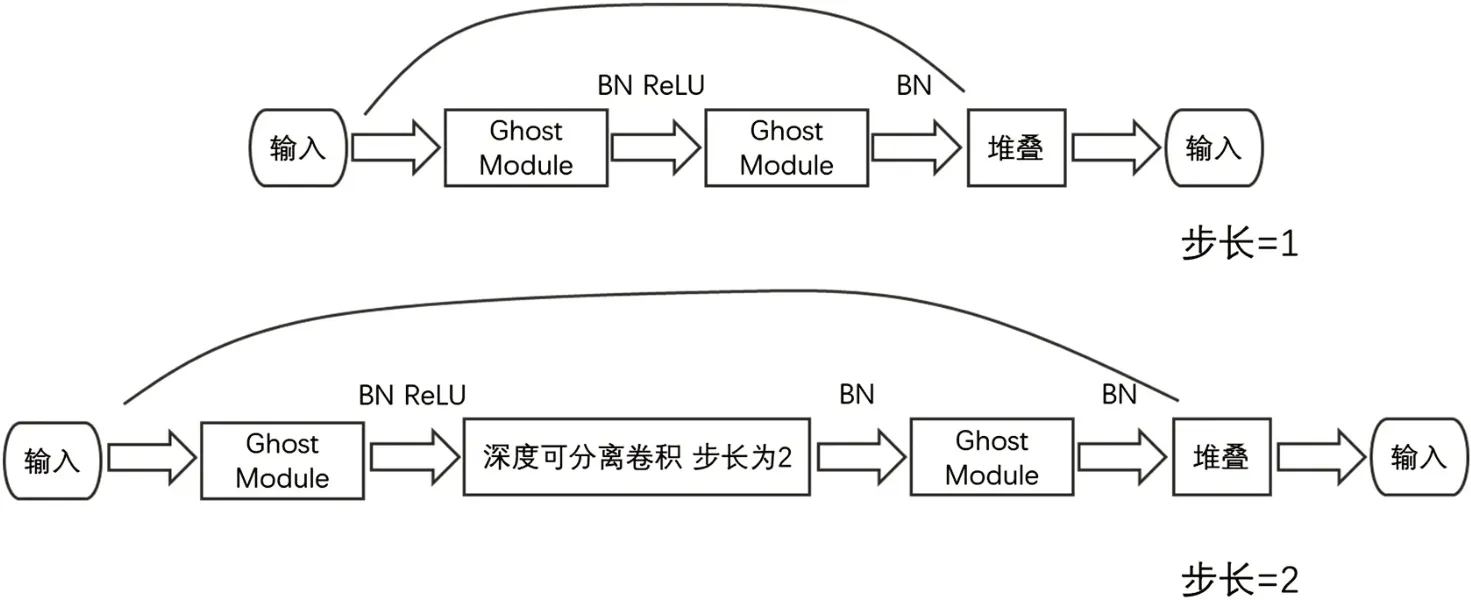
图3 Ghost bottleneck结构图
同时,为了提升替换主干网络后的模型准确度,引入注意力机制模块SA。这是一个融合了通道注意力机制和空间注意力机制的综合模块,全称为Shuffle Attention。SA 的算法流程如图4 所示,先在通道维度上将输入特征按照分组数G 进行分组,再将分组后的特征平均分为Xk1和Xk2,其中Xk1赋予通道注意力权重,Xk2赋予空间注意力权重。
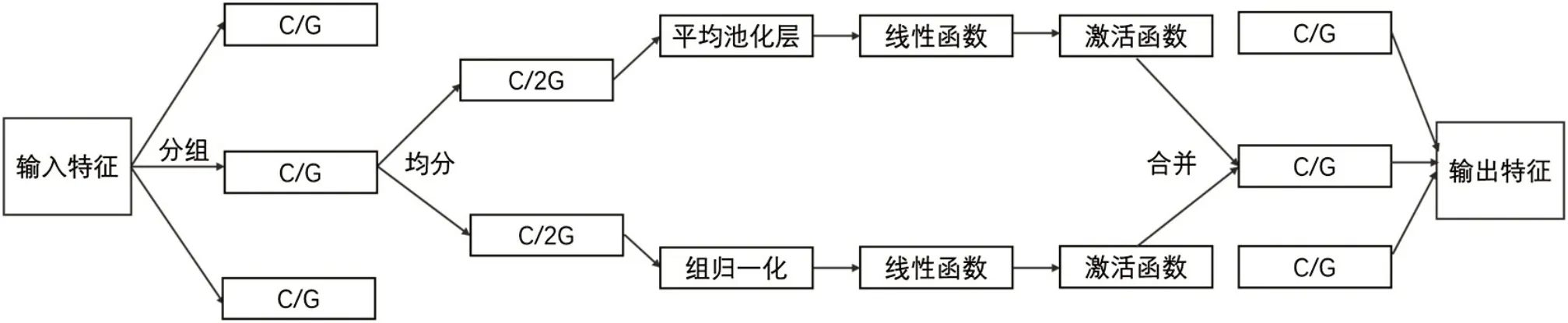
图4 Shuffle Attention注意力模块
Xk1经过通道注意力机制的处理。首先通过全局平均池化函数生成通道统计数据,然后利用Fuse 线性函数进行特征增强,最后经过sigmoid 函数激活后,与输入的特征值相乘嵌入到全局信息中,通过以上三个函数共同组成通道注意力机制。

其中,Fc1为线性函数,σ为激活函数,FA为全局平均池化函数,W1和b1为线性函数的参数,S1为平均池化后的特征。
Xk2经过空间注意力机制的处理。首先通过组归一化函数生成空间统计数据,然后利用Fuse 线性函数进行特征增强,最后经过sigmoid函数激活后与输入的特征值相乘嵌入到全局信息中,通过以上三个函数共同组成空间注意力机制。
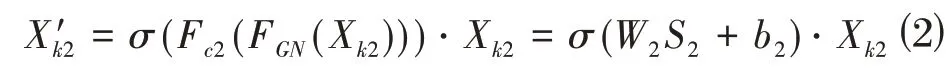
其中,Fc2为线性函数,σ为激活函数,FGN为组归一化函数,W2和b2为线性函数的参数,S2为归一化后的特征。
本文提出将SA 注意力机制融入到步长为1 的Ghost bottleneck 中,在降低运算量的同时保证了查准率和查全率。在对第一个GhostModule 采用ReLU 激活函数之后添加SA 注意力机制[9],由此对YOLOv4 完成了改进,SG模块的结构如图5所示。

图5 SG模块结构图
2 模型在安卓端的移植和配置
本文使用SG-YOLO 算法对人脸样本进行训练,将得到的模型部署于Android 平台上,以此来验证算法的工程实用性[10],但由于SG-YOLO 算法训练后得到的模型为.pth 格式,因此需要进行模型转换。首先在pytorch 环境下将.pth 文件转为.onnx 文件,然后借助腾讯推出的NCNN 框架启动onnx2ncnn 脚本生成.param 和.bi 两个文件,由此完成了模型转换并进行部署,Android平台具体配置见表1。

表1 Android平台配置
3 实验结果与分析
本文使用的数据集为WIDER FACE 人脸数据集,该数据集包括的背景复杂的小尺度人脸图像对人脸检测的评估有较大的权威性。选取16102 张图片,其中训练集13041 张,测试集3061 张,利用labelimg 对其中的人脸进行标注。操作系统为64位的windows10,处理器为NVIDIA GeForce RTX 3080,算法通过pytorch 框架来实现,训练过程中使用的参数如下:迭代次数为300 轮,每次输入图片张数的batch-size 为16,输入图片尺寸缩放到416×416。选择YOLOv4 原模型和小型化的YOLOv4-Tiny模型作为对比模型,在WIDER FACE数据集上对算法进行训练和测试,获得最终人脸检测模型权重。实验中由权重大小、准确率、检测速度三个参数作为评价指标。图6 为三种模型在测试集上对人脸检测的准确率(测试集中实际检测出的人脸数/测试集中预测出的所有人脸数),在不同的得分阈值(Score_Threhold)下的变化曲线。取Score_Threhold为0.5时的准确率作为评价值。

图6 三种不同模型的准确率
如图6 及表2 可知,与YOLOv4 和YOLOv4-Tiny算法相比,本文提出的网络模型SG-YOLO 的准确率分别提高了4.1%、1.2%,模型权重大小分别下降了82%、31%,速度分别提高了42%和35%。本文算法在检测的准确度差别不大的情况下,很大程度上减小了模型的权重大小,提高了检测速度。
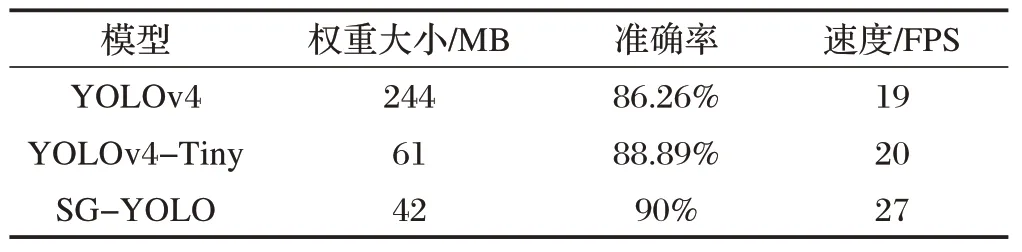
表2 不同模型在WIDERFACE数据集上的的测试结果
在训练完YOLO 模型之后,将该模型通过NCNN移植到Android 平台中进行APP 开发,本文使用的Android 设备是芯片型号为RK3288 的开发板,调用摄像头进行实时检测时可以达到平均12FPS 的速度,且检测效果与PC 端相同,满足人脸检测在低算力的Android 平台的部署需求,图7 是算法部署后进行实时检测的效果图。

图7 算法部署效果图
4 结束语
本文提出了一种满足Android 平台运行的轻量化人脸检测算法,对网络进行压缩和改进,提高检测速度的同时,保持了较高的准确率,在模型大小、检测速度和准确性上都优于YOLOv4-Tiny 和YOLOv4 算法,满足人脸检测的实时性需求,可为其他深度学习算法部署在低算力的嵌入式设备[11-15]上提供参考。下一步的工作是在其他不同的低算力平台上进行对比试验,来验证此算法的通用性,同时考虑更多的影响因素来改进此算法,做到以更高的帧率进行实时检测。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
动漫星空(2018年9期)2018-10-26 01:17:14
中国交通信息化(2018年5期)2018-08-21 03:37:40
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
发明与创新(2015年33期)2015-02-27 10:40:09
