
基于改进YOLOv7 的小目标检测
2023-01-27 08:27戚玲珑高建瓴
计算机工程 2023年1期
戚玲珑,高建瓴
(贵州大学大数据与信息工程学院,贵阳 550025)
0 概述
目标检测作为计算机视觉领域中如目标追踪、目标分割等其他更高层次视觉任务的基础,其主要任务包括识别图片目标类别和定位目标所在位置两个部分[1]。传统目标检测算法主要依赖于手工构建特征,存在速度慢、精度低等问题,是早期目标检测常用的算法。随着卷积神经网络的提出,基于深度学习的目标检测算法因其结构简单、检测效果好等特点,成为目标检测方向的研究主流。
基于深度学习的目标检测模型[2]主要分为两类:两阶段(two-stage)模型和单阶段(one-stage)模型。其中:前者通过卷积神经网络得到一系列候选区域,进而完成分类和定位任务;后者利用回归思想将输入图片送入卷积神经网络中,经检测后直接输出得到结果。
与其他计算机视觉任务相比,小目标检测(Small Object Detection,SOD)的历史相对较 短。2014 年,通用数据集MSCOCO 将分辨率小于32×32像素的目标定义为小目标。2016 年,文献[3]提出了基于深度学习的小目标检测网络,通过引入小目标检测数据集以及数据集的评估指标,从相对大小出发将同类别目标中目标框面积占总面积0.05%~0.58%的部分定义为小目标,为探索小目标检测奠定了一定的基础。文献[4]提出一种基于上采样的技术,在小目标检测中取得了更好的效果。2018 年,文献[5]将反卷积RCNN 应用于遥感小目标检测。随后,在Faster RCNN[6]、SSD[7]以及YOLO 系列网络模型的基础上,研究人员提出了很多小目标检测网络模型。
ReDet[8]、Oriented Bounding Boxes[9]以及Box Boundary-Aware Vectors[10]通过旋转预测框和旋转检测器提升了小目标检测效果,但针对的只是遥感场景;TPH-YOLOv5[11]通过增加目标检测层,使用transformer 预测头集成CBAM 注意力模块[12],有效提升了网络对小目标的检测性能,但在不密集的情况下容易造成漏检;YOLO-Z[13]虽然通过将PAFPN替换为Bi-FPN,扩大Neck 层等一系列操作,使中浅层特征得到很好融合,但并不适用于目标尺寸变化大的场景。
为解决上述问题,本文提出一种改进的YOLOv7 目标检测模型。通过结合特征分离合并的思想,对MPConv 模块进行改进,以减少特征提取过程中的有效特征缺失及漏检情况。针对小目标检测中的误检,引入注意力机制,并结合卷积注意力机制和自注意力机制实现特征优化。最终通过改进损失函数,将两锚框中心点连线与水平方向形成的最小角纳入考虑,以提高网络对于目标尺寸的鲁棒性。
1 相关工作
1.1 YOLOv7 模型
YOLOv7[14]是YOLO 系列中的基本模型,在5~160 帧/s 范围内,其速度和精度都超过了多数已知的目标检测器,在GPU V100 已知的30 帧/s 以上的实时目标检测器中,YOLOv7 的准确率最高。根据代码运行环境的不同(边缘GPU、普通GPU 和云GPU),设置了3种基本模型,分别称为YOLOv7-tiny、YOLOv7 和YOLOv7-W6。相比于YOLO 系列其他网络模型,YOLOv7 的检测思路与YOLOv4[15]、YOLOv5[16]相似,其网络架构如图1 所示。

图1 YOLOv7 网络架构Fig.1 YOLOv7 network architecture
YOLOv7 网络模型主要包含了输入(Input)、骨干网络(Backbone)、颈部(Neck)、头部(Head)等4 部分。首先,图片经过输入部分数据增强等一系列操作进行预处理后,被送入主干网,主干网部分对处理后的图片提取特征;随后,提取到的特征经过Neck模块特征融合处理得到大、中、小3 种尺寸的特征;最终,融合后的特征被送入检测头,经过检测之后输出得到结果。
YOLOv7 网络模型的主干网部分主要由卷积、E-ELAN(Extended-ELAN)模块、MPConv 模块以及SPPCSPC 模块构成。E-ELAN 模块在原始ELAN 的基础上,在改变计算块的同时保持原ELAN 的过渡层结构,并利用expand、shuffle、merge cardinality 来实现在不破坏原有梯度路径的情况下增强网络学习的能力。SPPCSPC 模块在一串卷积中加入并行的多次MaxPool 操作,避免了由于图像处理操作所造成的图像失真等问题,同时解决了卷积神经网络提取到图片重复特征的难题。在MPConv 模块中,MaxPool 操作将当前特征层的感受野进行扩张再与正常卷积处理后的特征信息进行融合,提高了网络的泛化性。
在Neck模块,YOLOv7 与YOLOv5 网络相同,也采用了传统的PAFPN 结构。在检测头部分,本文的基线YOLOv7 选用了表示大、中、小3 种目标尺寸的IDetect 检测头,RepConv 模块在训练和推理时其结构具有一定的区别。
1.2 注意力机制
注意力机制[17]是机器学习中的一种数据处理方法,广泛应用在自然语言处理、图像处理及语音识别等各种不同类型的任务中。
由于注意力机制的引入,可使网络集中的目标区域获得更多细节性的信息。对于目标检测任务而言,网络中注意力模块的添加,可使网络模型的表征能力得到提升[17],有效减少无效目标的干扰,从而提升对关注目标的检测效果,达到提高网络模型整体检测效果的目的。机器学习中的注意力机制主要分为卷积注意力机制和自注意力机制两类。
本文对YOLOv7 的主干网络进行多次实验,发现在特征提取的过程中,许多对于小目标检测及其重要的中、浅层纹理和轮廓信息都没有被充分提取,对小目标检测产生了一定程度的影响,容易造成目标漏检。因此,本文从增强网络对小目标的注意力出发,兼顾输入与输入之间的关系及输入与输出之间的关系,减少漏检情况的发生。
1.3 IoU 损失函数
在目标检测网络中,目标定位依赖于一个边界框回归模块,而IoU 损失函数的作用就是使预测框靠近正确目标从而提升目标框的定位效果[18]。2019年,针对在两框不相交情况下IoU 很难衡量回归框好坏的问题,GIoU[19]通过引入能够包围预测框和真实框的最小框(类似于图像处理中的闭包区域)来获取预测框、真实框在闭包区域中的比重。次年,考虑到当预测框和真实框处于水平位置时GIoU 就会退化为IoU 的情况,DIoU[21]在IoU 的基础上,将预测框和真实框中心点之间的距离纳入考虑,从而提高了损失函数的收敛速度。之后,为了得到更加精准的预测框,CIoU[22]对DIoU 进行改进,将长宽比引入计算,提升了回归框的检测效果。
由于在遇到预测框和真实框长宽比相同的情况时,CIoU 损失函数长宽比的惩罚项恒为0,收敛过程波动相对较大。因此,本文对损失函数进行更细致的表示,以达到损失函数平稳收敛的目的,使目标框具有更好的定位精度。
2 YOLOv7 目标检测模型的改进
2.1 MPConv 改进模块
在YOLOv7 网络中,MPConv 模块上的分支在最大池化层后连接一个k=1、s=1 的卷积;下分支在k=1、s=1 的卷积后连接一个k=3、s=2 的卷积。其中,最大池化层和1×1 卷积进行级联,通过选取局部最大值对图像的边缘和纹理信息进行学习,而另一分支通过两个卷积级联,提取得到了图像的更多细节信息。两分支合并为网络带来了更好的信息融合效果。如图2 所示,当选择卷积核为3、步长为2 的卷积时,卷积过程会造成一些细粒度的丢失,从而使得网络产生低效率的特征表示学习。

图2 stride 为2 时的卷积过程Fig.2 Convolution process with stride of two
为避免这类由于步长为2 的卷积对小目标网络所造成的特征缺失,需进行分离合并操作,操作原理如图3 所示。对于一张含有S×S像素的图片,本文将其分离成4 个S/2×S/2 的子图,然后将4 个子图按照通道进行拼接。经过分离合并后的特征再通过1×1卷积就可以得到S/2×S/2×1 大小的特征。
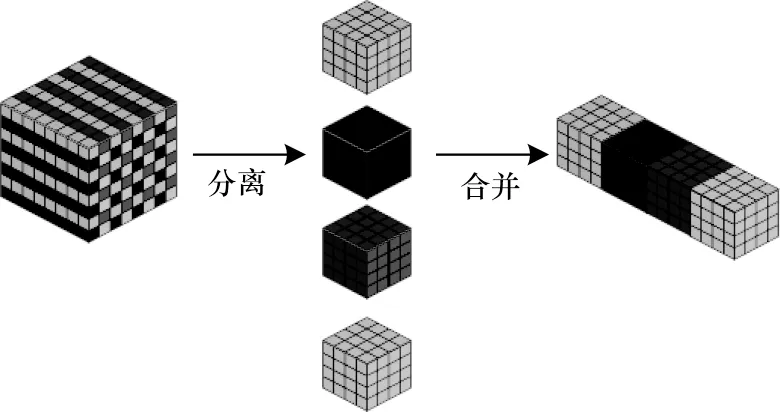
图3 分离合并操作示意图Fig.3 Schematic diagram of separation and merging operation
如图4 所示,改进后MPConv 模块的右分支与改进前相同,达到了特征图尺寸减半的目的,但操作过程中不会造成特征的缺失。

图4 MPConv 框架Fig.4 MPConv framework
为进一步探究改进后MPConv 模块放在网络哪个位置能够最大程度地提升检测效果,本文针对以下3 种情况进行了实验,实验结果如表1 所示。其中,mAP@0.5 和mAP@0.5∶0.95 分别表示IoU=0.5、0.5≤IoU≤0.95 时各个类别的平均AP 值。

表1 不同情况下的实验结果对比Table 1 Comparison of experimental results under different conditions
1)只将Backbone 结构中的MPConv 模块替换为改进后的MPConv 模块。
2)只将Neck 结构中的MPConv 模块替换为改进后的MPConv 模块。
3)将网络中所有MPConv 模块替换为改进后的MPConv 模块。
从表1 的实验结果可以看出,只将Neck 结构中的MPConv 模块替换为改进后的MPConv 模块时,网络表现最佳,相比于原网络,提取到了更多有效的特征信息。
2.2 ACmix 注意力模块
在注意力机制中,卷积注意力模块多注重输入与输出的关系,而自注意力模块则多注重输入与输入之间的关系。受CoAtNet[23]网络的启发,本文结合自注意力和卷积注意力两者的优点,引入ACmix注意力模块[24]以增强网络对于小目标的注意力。如图5 所示,ACmix 注意力模块由卷积注意力和自注意力两个模块并行组合而成。

图5 ACmix 原理图Fig.5 Principle diagram of the ACmix
ACmix 原理如下:将H×W×C的特征通过3 个1×1×C卷积进行投影后分成N片,得到3×N个尺寸为(H×W×C/N)的子特征。
对于上分支(内核为k的卷积路径),网络像传统卷积注意力一样从局部感受野收集信息,子特征通过3N×K2N的全连接层后,对生成的特征进行移位和聚合以及卷积处理,得到H×W×C的特征;对于下分支(自注意路径),网络像自注意力一样在考虑全局的同时并聚焦重点,3N个子特征对应的3 个H×W×C/N尺寸的特征图分别作为查询、键和值,并遵循传统的多头自注意力模型,通过移位、聚合、卷积处理得到H×W×C的特征。最终,对两条路径的输出进行Concat 操作,强度由两个可学习的标量控制,如式(1)所示:

其中:Fout表示路径的最终输出;Fatt表示自注意力分支的输出;Fconv表示卷积注意力分支的输出;参数α和β的值均为1。
两分支的输出结果经过合并后,兼顾了全局特征和局部特征,从而提升了网络对于小目标的检测效果。
2.3 损失函数
YOLOv7 网络模型中损失函数如式(2)所示:

其中:Lloc,Loss表示定位损失;Lconf,Loss表示置信度损失;Lclass,Loss表示分类 损失。
置信度损失和分类损失均采用BCEWithLogits Loss 函数进行计算,而坐标损失采用CIoU 进行计算,计算公式如下:

其中:b表示预测框;bgt表示真实框;c表示能够同时包含预测框和真实框的最小闭包区域的对角线距离;α为平衡参数;v用来衡量长宽比是否一致。从式(4)可以看出,当预测框与真实框的长宽比一样大时,v取0,此时长宽比的惩罚项并没有起到作用,CIoU 损失函数得不到稳定表达。
因此,使用SIoU[25]损失函数替换原网络中的CIoU,将角度成本纳入考虑,使用角度成本对距离重新进行描述,减少损失函数的总自由度,SIoU 损失函数所用到的参数如图6 所示。

图6 SIoU 损失函数的计算Fig.6 Calculation of SIoU loss function
2.3.1 角度成本
通过角度是否大于45°,判断使用最小化β还是α,角度成本的计算如式(6)所示:

2.3.2 距离成本
距离成本代表预测框与真实框两框的中心点距离。结合上述定义的角度成本,SIoU 对距离成本重新定义如式(10)所示:

当α趋向于0 时,距离成本的贡献大幅降低。相反,当α越接近π/4 时,距离成本的贡献越大。随着角度的增大,γ被赋予时间优先的距离值。
2.3.3 形状成本
形状成本Ω的定义如式(14)所示:

此处θ的值定义了形状损失的关注程度,本文设置为1,它将优化形状的长宽比,从而限制形状的自由移动。
综上,SIoU 损失函数的最终定义如式(17)所示:

由于角度成本的增加,损失函数在得到更充分表达的同时,减少了惩罚项为0 出现的概率,使得损失函数收敛更加平稳,提高了回归精度,从而降低了预测误差。
3 实验结果与分析
3.1 实验环境与参数设置
网络实验环境为Ubuntu18.04、Python2.7.17 和PyTorch1.12.1,相关硬件配置和模型参数如表2 所示,其中训练数据量为300。

表2 实验相关硬件配置和模型参数Table 2 Experiment related hardware configuration and model parameters
3.2 实验数据集
实验采用欧卡智舶发布的无人船视角下内河漂浮垃圾数据集,该数据集是全球第一个真实内河场景下无人船视角的漂浮垃圾检测数据集。在FloW-Img 子数据集中,超过1/2 的目标都是小目标(Area<32×32 像素),可以支持针对小目标检测的研究。数据集采集于不同的光照和波浪条件下,在不同方向和视角上对目标进行观测。数据集共包括2 000 张图片。为满足实验需求,本文以6∶2∶2 比例划分为训练集、验证集和测试集。数据集示例如图7所示。

图7 本文数据集示例Fig.7 Sample data sets for this paper
3.3 评价指标
通过对比同样实验环境下改进前后的网络模型对几种类型图像的检测差异来评估漏检、误检情况,主要选取准确率-召回率(P-R)曲线和平均准确率(Average Precision,AP)、平均精度均值(mean Average Precision,mAP)等3 个指标,计算公式如下:

其中:TTP表示正确预测;FFP表示错误预测,包括把不是瓶子的目标检测为瓶子和漏检两种情况;FFN表示误把瓶子目标检测为其他类别的情况;P为准确率;R为召回率。在P-R曲线中,P-R曲线与坐标轴围成的面积等于AP 值大小。对所有类别的AP 值取平均值就可以得到mAP,一般地,使用mAP 来对整个目标检测网络模型的检测性能进行评价。
3.4 损失函数收敛对比
在同一网络模型同种实验环境下,对YOLOv7损失函数的收敛性进行验证。两种Loss 函数随着迭代次数的变化曲线如图8 所示。其中,两条曲线分别表示边框损失使用CIoU 和SIoU 时平均边界框损失的情况。

图8 损失函数迭代对比Fig.8 Loss function iteration comparison
从图8 可以看出,随着迭代次数的增加,SIoU 和CIoU 最终都处于收敛状态。但是SIoU 相对于CIoU损失值更小,稳定性也得到了一定的提升。所以,使用SIoU 作为本文数据集的边界框损失函数,对网络模型的性能提升有着更重要的意义。
3.5 YOLOv7 网络模型与改进网络模型实验对比
改进前后网络模型对于水面漂浮小目标检测得出的P-R曲线对比如图9 所示。P-R曲线与坐标轴围成的面积大小描述了水瓶的AP 值。可以明显看出,改进后的YOLOv7 网络模型在小目标数据集的检测中取得了较好的性能,检测目标的AP 值明显高于改进前网络模型。

图9 改进前后网络模型P-R 曲线对比Fig.9 Comparison of network models P-R curves before and after improvement
针对实际情况中目标密集图像、小目标图像、超小目标图像等3 种类型的图片,基础YOLOv7 网络模型与改进YOLOv7 网络模型的检测效果如图10~图12 所示。图10 对于目标密集图片,原图共有11 个目标,原网络模型检测到9 个目标,漏检2 个,改进后网络模型全检测出;图11 针对小目标图片,改进前后网络模型均检测出2 个目标,但改进后网络模型的预测框置信度明显大于原网络模型;对于图12 超小目标(目标框大小为0.05×0.04)的图片,原网络模型漏检,而改进后的网络模型仍能检测出目标。

图10 目标密集图片检测结果对比Fig.10 Comparison of detection results of target dense pictures

图11 小目标图片检测结果对比Fig.11 Comparison of detection results of small target pictures

图12 超小目标图片检测结果对比Fig.12 Comparison of detection results of ultra-small target pictures
3.6 改进YOLOv7网络模型与其他网络模型的对比
在保证配置环境及初始训练参数一致的情况下,本文将改进的YOLOv7 网络模型与其他网络模型进行实验来验证改进网络模型的有效性,结果如表3 所示。可以看出,改进后的YOLOv7 网络模型在输入相同尺寸图片的情况下,mAP 值超过了其他经典网络模型,更适合小目标检测场景。

表3 不同网络模型实验结果对比Table 3 Comparison of experimental results of different network models
4 结束语
针对小目标检测困难的问题,本文提出一种改进的YOLOv7 检测模型。通过将分离合并思想与卷积相结合,对MPConv 模块进行改进,提取图片中的细节信息。同时,将传统卷积注意力机制与自注意力机制进行融合,并加入ACmix 注意力模块,在此基础上,对IoU 损失函数进行优化,引入SIoU 损失函数增强网络的定位能力,从而提高网络检测精度,减少检测过程中小目标误检、漏检情况。实验结果表明,改进后的YOLOv7 网络模型检测效果优于原网络模型和传统经典目标检测网络模型。下一步通过对数据集进行扩增,增加数据集中的检测类别,扩大检测范围,以提高模型在实际应用中的检测性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
共产党员(辽宁)(2015年2期)2015-12-06
