
基于人工智能算法的数据中心机房气流组织温度预测研究
2023-01-25 11:50胡孝俊姚贵策中讯邮电咨询设计院有限公司郑州分公司河南郑州450007北京航空航天大学北京009中国联通上海分公司上海0008
邮电设计技术 2022年12期
许 俊,程 序,胡孝俊,姚贵策,祝 华,贺 晓(.中讯邮电咨询设计院有限公司郑州分公司,河南 郑州 450007;.北京航空航天大学,北京 009;.中国联通上海分公司,上海 0008)
1 概述
在过去的十几年中,数据中心在能源效率、可靠性和可持续运行方面做出了巨大的贡献。特别是随着信息技术(IT)产业的快速发展以及物联网(IoT)和人工智能(AI)技术的出现,计算和电力的需求呈爆发式持续增长[1]。促使数据中心必须在规模和稳定性方面做出回应并升级其设施。而随着数据中心规模的不断扩张,自身的能耗已不容忽视;2019 年全球数据中心的能耗为200 TWh,占全球总能耗的1%,合计占全球碳排放的0.3%[2]。目前,数据中心的能耗平均每4 年翻倍[3]。2020 年9 月,在75 届联合国大会一般性辩论上,我国明确要采取更加有利的政策和措施,力争二氧化碳排放2030 年前达到峰值,努力争取2060年前实现碳中和。为了促进峰值目标尽快实现,2020年12月,《新时代的中国能源发展白皮书》提出新时代的中国能源清洁低碳发展的导向,加快能源绿色低碳转型,贯彻“4个革命、1个合作”能源安全新战略;在国家双碳背景下,发展数据中心的节能低碳技术,降低其PUE(Power Usage Effectiveness)及CUE(carbon Us⁃age Effectiveness)势在必行。
典型的数据中心能耗结构中,气流冷却系统占据了其总能耗的50%,而服务器和存储则只占到26%[4]。因此,建立有效的数据中心节能措施的首要任务就是了解其冷却方式,并采取相应的措施。传统的数据中心冷却方式采用的是冷空气对流冷却:冷空气自底部冷却通道自下而上流经服务器并将之冷却,然后换热后的热空气从顶部回到空调控制中心形成冷却循环系统。由于数据中心布局复杂,气流组织分布也不均匀,因此机房各服务器的冷却效果也不尽相同。掌握数据中心机房温度分布,特别是机柜周围的温度热点有利于调整冷却空调功率、风速等参数,从而在最有效的做功范围内保证数据中心正常运转。
限于现有的实验测量手段,数据中心机房整体的温度分布难以捕捉;因此,对数据中心机房的温度调控主要依赖于有限的传感器温度和传感器的分布情况。一方面如果传感器测量的局部温度属于非关键局部热点,此时依赖传感器进行整体数据机房的调控,势必会导致其余各处冷却效能过剩;另一方面,如果传感器布局在温度相对较低的位置,此时传感器的测量温度过低,无法真实反映机柜运行的最高温度,从而无法保证数据中心性能。利用计算流体力学的方法(Computation Fluid Dynamics,CFD)可有效地表征特定条件下的数据中心机房气流组织流场、温度场的分布,从而可进一步对冷却效能进行分配[5−6]。事实上,数据中心运行过程中,其负载功率计算任务等时刻在变,传统的CFD 方法难以及时给出不同功率负荷下的温度全局分布情况。因此,亟需建立快速温度场的预测方法[7−10],从而可及时反映温度分布情况,并为后期建立智能调控数据中心提供数据支持。
基于此目的,本文采用机器学习卷积神经网络,配合传统CFD 数据,实现了一种可以快速预测数据中心机房温度分布的方法,即AI−CFD[11],希望可以为建造智能数据中心提供技术支持。
2 模型建立及描述
2.1 CFD数据获取
以图1 所示的简单数据中心机房为例,首先通过6SigmaDC 软件计算了该机房不同空调设定温度及服务器功率下数据中心的温度分布,取图1 中Y方向中心截面温度数据为后续快速预测模型的输入及输出数据提供依据。该机房大小4.8 × 4.2 m2,共设有6 个服务器,每台服务器功率设定可从4 kW 到12 kW 以2 kW 的功率间隔进行调整;空调设定温度可从12 ℃到20 ℃以2 ℃的温度间隔进行调整。通过每次改变一个参数变量,最终可获得91 组不同服务器功率、不同空调设定温度下机房的温度分布数据。由于后面讨论了数据库数量对快速预测模型精确度的影响,因此,从91 组数据中取变量在中间的39 组数据单独学习来探讨数据库尺寸的影响。
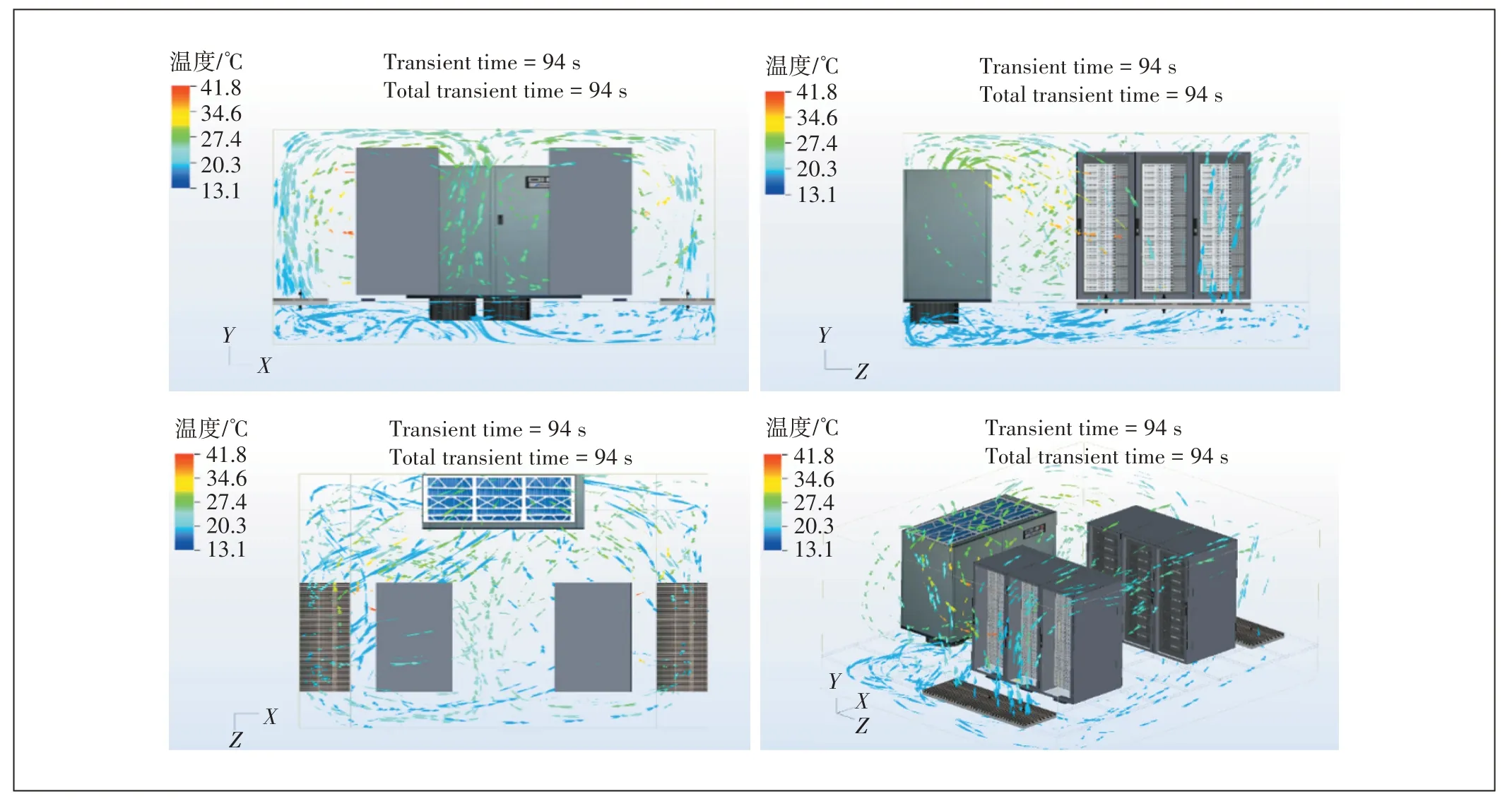
图1 采用的数据中心机房布局及CFD模拟数据
需要指出的是,由于6SigmaDC 中的CFD 模拟只输出网格节点上的温度数据。因此需要进一步处理,将这组离散的、非均匀的数据点转化为均匀的网格,形成有效的训练集。通过使用最近邻插值图中的数据点填充3 次插值图中的空白数据,最终得到了插值的温度场。
2.2 AI-CFD模型建立
图2所示为整个AI−CFD 预测模型的结构,它包含了3个模块:输入模块、学习模块以及输出模块。神经网络的输入由3 个部分组成。前2 个部分分别定义了区域的物理坐标和材料属性。通过对控制2个部分的数组进行赋值,可以有效地使预测模型判别流体区域和服务器及机房边界。除了这2 个部分外,空调设定温度和服务器功率也作为一个输入导入到快速预测模型中。学习模块采用卷积神经网络[12],对图像进行低维采样,并在上采样期间对其进行重构。下采样和上采样通过跳跃连接(Skip Connection)进行通信。将尺寸相同的3个输入阵列与输出温度场的阵列输入网络,将其简化为潜在几何表示(LGR),然后通过解码器中的转置卷积层得到最终温度场。
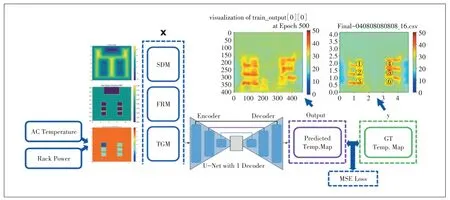
图2 快速预测模型网络架构
2.3 误差分析
对于卷积神经网络,通常使用均方误差(mean square error,MSE)的方式来计算预测温度场与真实温度值之间的偏差,其定义为:
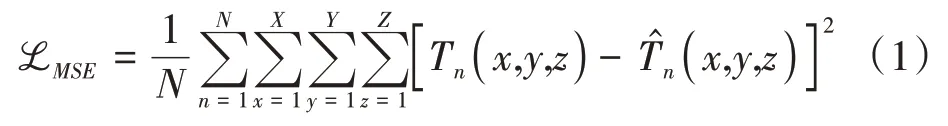
其中,Tn(x,y,z)为样本数为n点(x,y,z)的真实温度值,为对应的预测温度。N是样本的数量,可以是训练时的批次,也可以是测试时测试集中的样本数量。X、Y和Z分别表示x−、y−和z−方向的数据点总数。
3 数据分析及讨论
图3所示为数据中心机房二维温度场快速预测结果示例。从左至右依次是CFD 模拟真实温度值,AI−CFD 快速预测温度值以及误差分布图。从图3可以看出,快速预测的结果与真实值趋势相同且数值相近,由于插值原因,部分结果存在偏差。特别是在服务器位置,CFD 没有流固耦合数据,此部分数据误差主要由于插值引入,单纯考虑机房温度场分布误差会大大缩小。值得一提的是,相比于传统CFD 的设置,形成后的AI−CFD 模型,只需要输入空调设定温度和服务器运行功率即可获得数据中心机房气流组织的温度分布,计算时间也缩减到秒级。从时间和人力上都大大降低了计算成本。事实上,预测结果与学习率、数据集数量大小以及神经网络的架构等参数息息相关,在下面的章节中,着重探讨了在基于现有学习网络架构下,不同学习率和数据库尺寸对预测结果的影响。
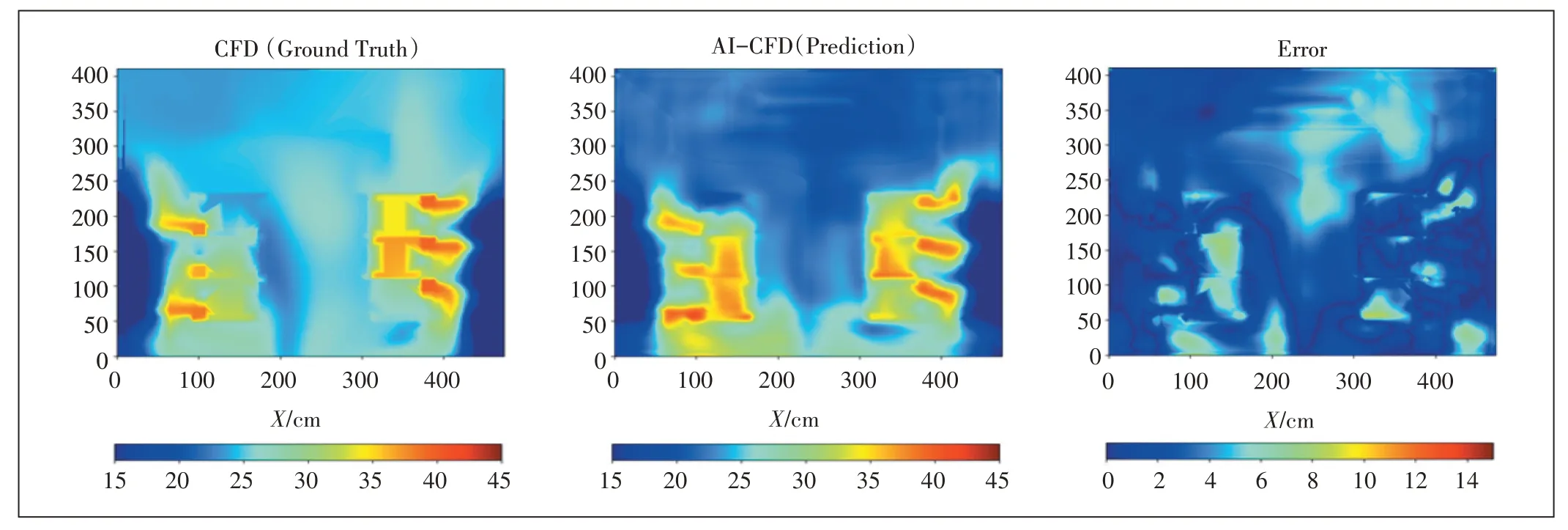
图3 数据中心机房二维温度场快速预测结果示例
3.1 学习率的影响
通过设置学习率为0.000 06、0.000 1、0.000 3 和0.000 5,研究了不同学习率对快速预测结果的影响,结果如表1 所示。从表1 可以看出不同学习率下AI−CFD 预测模型精度及与真实温度值的误差。图4 所示为不同学习次数下学习率对训练误差的影响。从图4可以看出,一味地增加或减小学习率并不能使预测结果更好。过度地增大学习率,会使学习的过程间隔太大,从而降低准确性。而过小的学习率会导致数据之间的鲁棒性降低,卷积网络难以准确追踪数据,从而导致预测失准;综合考虑训练过程的误差波动,选取0.000 1作为最优学习率。事实上,从表1中可以看出,预测精度仍然不尽人意,这主要是和数据量有关。针对学习率的研究是建立在39个数据集的基础上,数据的离散程度过高,不足以实现连续的精准预测。
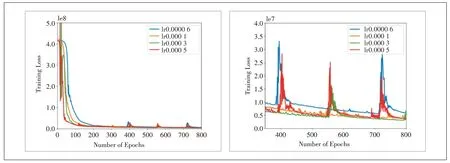
图4 不同学习率对训练误差的影响
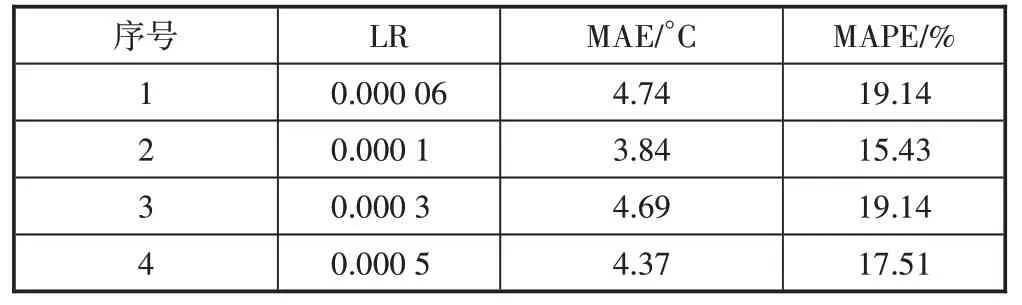
表1 不同学习率对预测结果的影响
3.2 数据库的影响
为了探究数据库尺寸对模型预测精度的影响,在给定学习率为0.000 3 的情况下,将数据集扩大到91组数据,结果如表2 和图5 所示。从表2 和图5 中可以看出,增大数据集可使神经网络预测更准确。这是因为数据集的扩充,弥补了数据离散情况下对未知点的近似值估算,使得预测精度更逼近真实值。在本研究中,仅考虑了2 组数据集的比较,如果继续增大数据集,缩小数据的间隔,一定程度上会继续提高预测精度。但值得指出的是,当数据集过于密集,数据相似度高时,会出现“过学习”的现象,反而会降低预测精度。因此,在实际应用过程中,应该以实际模型、数据为基准,确定最佳的数据集数量。

表2 不同数据集尺寸对预测精度的影响
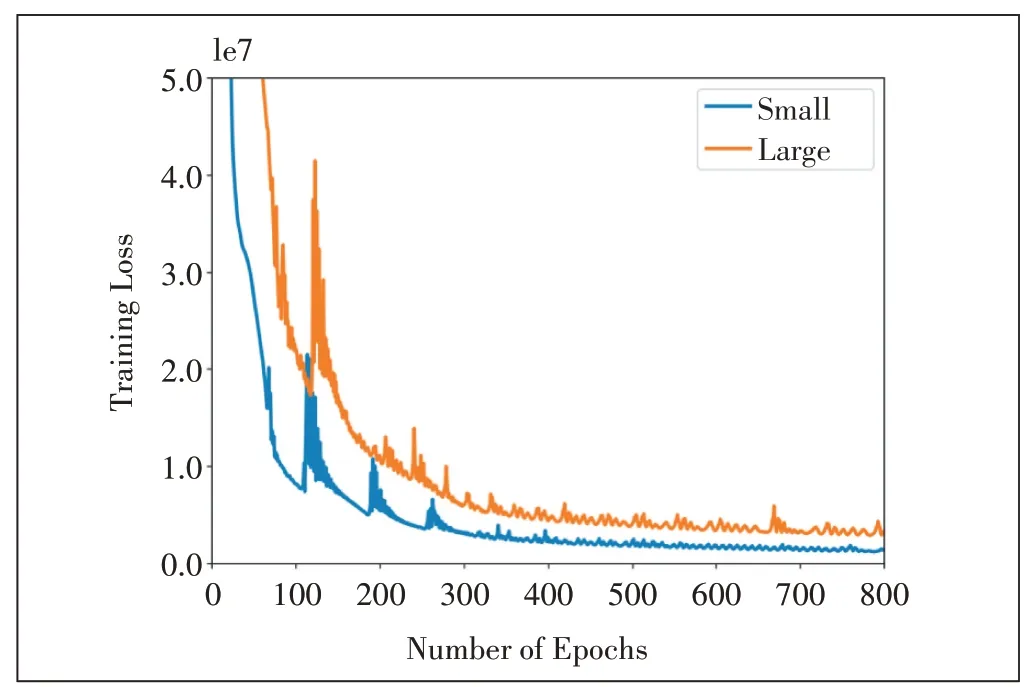
图5 数据集尺寸对训练误差的影响
4 结论
通过利用卷积神经网络,成功搭建了以空调设定温度和服务器功率为输入参数的AI−CFD 数据中心机房气流组织二维温度场的快速预测模型,无需再对服务器结构布局相同的机房进行重新划分网格、设置参数等长时间的计算。该模型研究了学习率、数据集等相关参数,其预测精确度需要根据实际模型需求选取最优参数。
根据现有测试集上所有模型的预测精度,实际的预测误差应该略低于这个值,因为服务器的真实温度值是通过插值生成的,这在CFD 计算中其实不存在。从图3 中可以看到,大多数预测误差较大的区域实际上都在服务器上,而服务器上的真实数据本身是有缺陷的。在某种程度上,甚至可以说服务器上的温度预测比用6SigmaDC 中分散的地面真实温度数据点插值得到的温度预测更合理。
此外,这一工作也是建立智能数据中心的一环,通过搭建智能决策网络与此快速预测网络结合,可以实现数据中心根据机房温度分布的智能调控和参数调优,也是今后数据中心节能低碳的重要发展方向。
猜你喜欢
现代仪器与医疗(2022年4期)2022-10-08
导航定位学报(2022年3期)2022-06-10
舰船科学技术(2021年12期)2021-03-29
电子制作(2019年19期)2019-11-23
电子制作(2019年16期)2019-09-27
制造技术与机床(2019年9期)2019-09-10
新生代(2018年16期)2018-10-21
中国交通信息化(2018年1期)2018-06-06
北京航空航天大学学报(2017年2期)2017-11-24
中国交通信息化(2017年12期)2017-06-06
