
A Multi Moving Target Recognition Algorithm Based on Remote Sensing Video
2023-01-22 09:01HuanhuanZhengYuxiuBaiandYurunTian
Huanhuan Zheng,Yuxiu Bai and Yurun Tian
1School of Information Engineering,Yulin University,Yulin,China
2ZTE Communication Co.,Ltd.,Xi’an,China
ABSTRACT The Earth observation remote sensing images can display ground activities and status intuitively,which plays an important role in civil and military fields.However, the information obtained from the research only from the perspective of images is limited,so in this paper we conduct research from the perspective of video.At present,the main problems faced when using a computer to identify remote sensing images are:They are difficult to build a fixed regular model of the target due to their weak moving regularity.Additionally,the number of pixels occupied by the target is not enough for accurate detection.However,the number of moving targets is large at the same time.In this case,the main targets cannot be recognized completely.This paper studies from the perspective of Gestalt vision,transforms the problem of moving target detection into the problem of salient region probability,and forms a Saliency map algorithm to extract moving targets.On this basis, a convolutional neural network with global information is constructed to identify and label the target.And the experimental results show that the algorithm can extract moving targets and realize moving target recognition under many complex conditions such as target’s long-term stay and small-amplitude movement.
KEYWORDS Deep learning;remote sensing images;moving target;recognition;salient
1 Introduction
Remote sensing images can intuitively display wide view scene information,and are widely applied in the fields.It can be applied to multi-target recognition and tracking scenes such as battlefield reconnaissance,border patrol,post-disaster rescue,public transportation and more[1].However,it is difficult to obtain spaceborne remote sensing images,which limits the in-depth research[2].In recent years, with the development and popularization of UAV technology, UAV technology presents the characteristics of high efficiency,flexibility and low cost,and the imaging equipment carried tends to be mature.It has been widely used in battlefield reconnaissance, border patrol, post disaster rescue,public transportation,etc.[3,4],which makes the aerial photography data present a blowout situation.In the face of so many aerial remote sensing data,how we can obtain useful information from aerial video is an important direction in the field of computer vision[5].
Target detection is the basis of tracking,recognition and image interpretation[6].There are multiple moving targets in the video,just because the video field angle captured by UAV monitoring system is large.Thus,it is difficult to detect moving targets quickly and accurately.Xiao et al.[7]proposed a low frame rate aerial video vehicle detection and tracking method based on joint probability relation graph according to probability relation.Andriluka et al.[8] applied UAV technology to rescue and search.Cheng et al.[9]established a dynamic Bayesian network from the perspective of pixels to realize vehicle detection.Gaszczak et al.[10] established a model from the perspective of thermal imaging to detect pedestrians and vehicles in aerial images.Lin et al.[11] improved the traditional Hough transform to realize road detection.Rodríguez-Canosa et al.[12] established a model to solve the problem of aerial image jitter to a certain extent.Zheng et al.[13]established GIS vector map to realize vehicle detection.Liang et al.[14] guided target detection according to background information.Prokaj et al.[15]built a dual tracker to realize the construction of background and prospect.Teutsch et al.[16]established a model under the condition of low contrast to realize vehicle detection in aerial monitoring images.Chen et al.[17]optimized the tracking window to realize multi-target detection.Jiang et al.[18] introduced the prediction module to realize target tracking in order to enhance the stability of tracking.Poostchi et al.[19] established semantic depth map fusion for moving vehicle detection.Tang et al.[20]established single revolutionary neural networks to predict vehicle direction.Aguilar et al.[21] used cascade classifiers with mean shift to realize pedestrian detection.Xu et al.[22]established a prediction and feature point selection model to find moving targets in multi-scale on infrared aerial images.Hamsa et al.[23]established a cascaded support vector machine and Gaussian mixture model to realize vehicle detection (SVM + GMM).Ma et al.[24] established the rotation invariant cascaded forest(RICF)to meet the target detection in complex background.Mandal et al.[25] established simple short and shallow network to realize rapid target detection.Song et al.[26]built a model according to the time and space relationship of the target,and then built the regulated AdaBoost recognition model to realize target recognition.Qiu et al.[27]built a deep learning network to track moving targets.Feng et al.[28]used mean shift algorithm to track high-speed targets.Wan et al.[29]used Keystone Transform and Modified Second-Order Keystone Transform to achieve moving target tracking.Lin et al.[30]used multiple drones to achieve multi-target tracking.
The above algorithms have achieved certain results in target detection, but there are still deficiencies:The model considers the limited interference of noise, tree disturbance and other factors,which leads to the inaccurate extraction of moving targets.Insufficient mining target attributes lead to inaccurate recognition.The innovation of our algorithm shown as following aspects:firstly,from the perspective of Gestalt vision,we propose a target motion extraction algorithm based on the saliency graph theory; secondly, in order to achieve fast and accurate target recognition, we constructed the convolutional neural network structure with global information, especially take global information into consideration.
2 Algorithm
Gestalt visual school believes that the reason why things are perceived is the result of the public action of eyes and brain.Firstly, the image is obtained through the eyes, and then the objects are combined according to some rules to form an easy to understand unity.If it cannot be combined,it will appear in a disordered state,resulting in incorrect cognition.Based on this principle,a multi-target recognition process in accordance with the Gestalt vision principle is established,as shown in Fig.1.Firstly,the salient graph mechanism is established to extract moving targets,and then the convolution neural network structure based on global information is used to realize target recognition.

Figure 1:Algorithm pipeline
2.1 Moving Target Extraction Based on Salient Gragh
In the video scene, a large amount of short-term motion information is included between consecutive image frames,and ignores the information that does not move temporarily.A video with long time contains a lot of long-time motion information, so the conditional motion salient graph includes the motion saliency of the target and the motion saliency of the background.In addition,the interference of noise makes it difficult to distinguish the significance.
A time series group containing short-term motion information and long-term motion information is constructed on the time scale.By calculating the motion significance probability,the significance of the moving target is highlighted and the background significance is suppressed,as shown in Fig.2.

Figure 2:Pipeline of moving target extraction algorithm based on salient graph
Temporal Fourier transform (TFT) is a motion saliency detection algorithm based on time information which uses pixels at the same position in consecutive frames to integrate in time to form a time series.The waveform is reconstructed by Fourier transform and inverse Fourier transform,and the maximum point is marked on the salient graph.The significant values indicate the probability that the target belongs to the foreground.Let the time series be

Its corresponding Fourier transform is obtained as

whereFrepresents Fourier transform andrepresents the phase spectrum of.

whereF-1represents inverse Fourier transform,andg(t)is Gaussian filter.The larger the amplitude ofchange, the larger the time scale change.Thus, the motion significance of the time series is constructed as

whereφix,yrepresents the significant value of the pixel (x,y) in thei-th viewing angle sequence,||is F2 norm.
Conditional motion saliency probability refers to the probability that pixels belong to the foreground in the time series.To unify the scale,is normalized as

The motion saliency probability represents the probability that the pixel belongs to the foreground by the motion saliency of the pixel.Under the guidance of the full probability formula, it can be calculated as follows:

The motion saliency probability graph uses the long-term and short-term motion information to enhance the saliency of the moving target in the current frame and suppress the motion saliency of the background and historical frame.Due to the background interference,there is false detection in the detection results,which makes the local significance high and difficult to remove by traditional methods.We use the correlation between adjacent pixels to construct a histogram algorithm to segment the saliency graph,then model the spatial information,and use the spatial information modeling to calculate the displacement probability,which has achieved the purpose of eliminating interference.
The histogram based threshold method is used to segment the motion saliency probability graph to obtain the candidate pixels,

whereTis obtained by the traditional Ostu algorithm.WhenS=1,it indicates foreground candidate pixels.WhenS=0,it indicates background candidate pixels.When the background,i.e.,trees,moves,there is a risk of detection as the target.However, its inter frame motion amplitude is limited.We construct the function:


For the connected component of the real target,the probability of the component displacement from the background is very small,and the thresholdthis set to distinguish:

whereSc(x,y)=1 represents the foreground andSc(x,y)=0 represents the background.
2.2 Convolution Neural Network Based on Global Information
Convolutional neural network (CNN) is a kind of feedforward neural network, whose neurons carry out corresponding control on the units within the coverage.It has excellent performance in the field of large-scale image processing.Therefore, we process remote sensing images based on traditional CNN.
The basic structure of CNN includes feature extraction layer and feature mapping layer.Feature extraction layer:The input of each neuron is connected to the local acceptance domain of the previous layer,and the local features are extracted.When the local feature is extracted,the position relationship between it and other features is also determined.Feature mapping layer:Each computing layer of the network is composed of multiple feature maps.Each feature mapping can be regarded as a plane,and the weights of all neurons on the plane are equal.Because the feature detection layer of CNN learns from the training data,it avoids explicit feature extraction and implicitly learns from the training data.Because the weights of neurons on the same feature mapping surface are the same,the network can learn in parallel.Subsequent scholars have carried out a lot of research on the basis of CNN:Bayar et al.[31] constrained the convolution layer to meet the image target detection.Li et al.[32]used a double-layer CNN structure to detect targets.The above algorithms have improved CNN from different aspects and achieved certain results.
According to the particularity of remote sensing video, traditional CNN cannot be directly applied to multi-target tracking based on remote sensing video,which is not enough to capture global information.Therefore,a new convolution neural network framework based on global information is proposed by effectively combining global average pool and Atrous convolution,as shown in Fig.3.
The image sequence is convoluted and pooled to reduce the size of the image and increase the receiving domain.The merged image is restored by up sampling to the original size prediction of the image.The information in the original image is lost while zooming out and adjusting.To solve this problem, Atrous Convolution is applied, as shown in Fig.4.Atrus revolution is a convolution idea proposed to solve the problem of image semantic segmentation in which down sampling will reduce image resolution and lose information.The advantages are:on the condition of loss information without pooling and the same calculation conditions, the receptive field is increased so that each convolution output contains a large range.
Global information plays a key role in image classification or target detection.In order to obtain more global context information,the global average pool is combined with the atrus revolution.Fig.5 shows the main structure of the network.
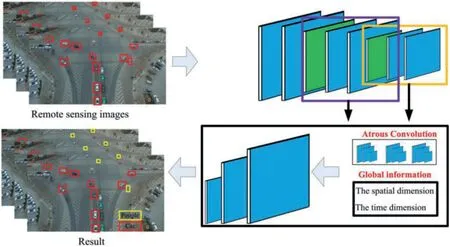
Figure 3:Convolutional neural network graph based on global information
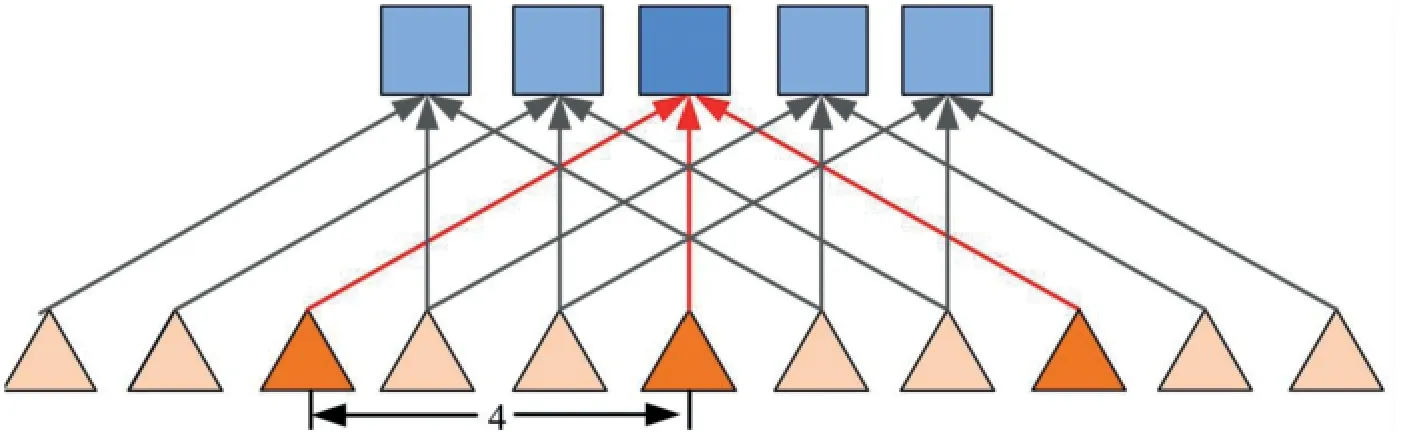
Figure 4:Atrous convolution
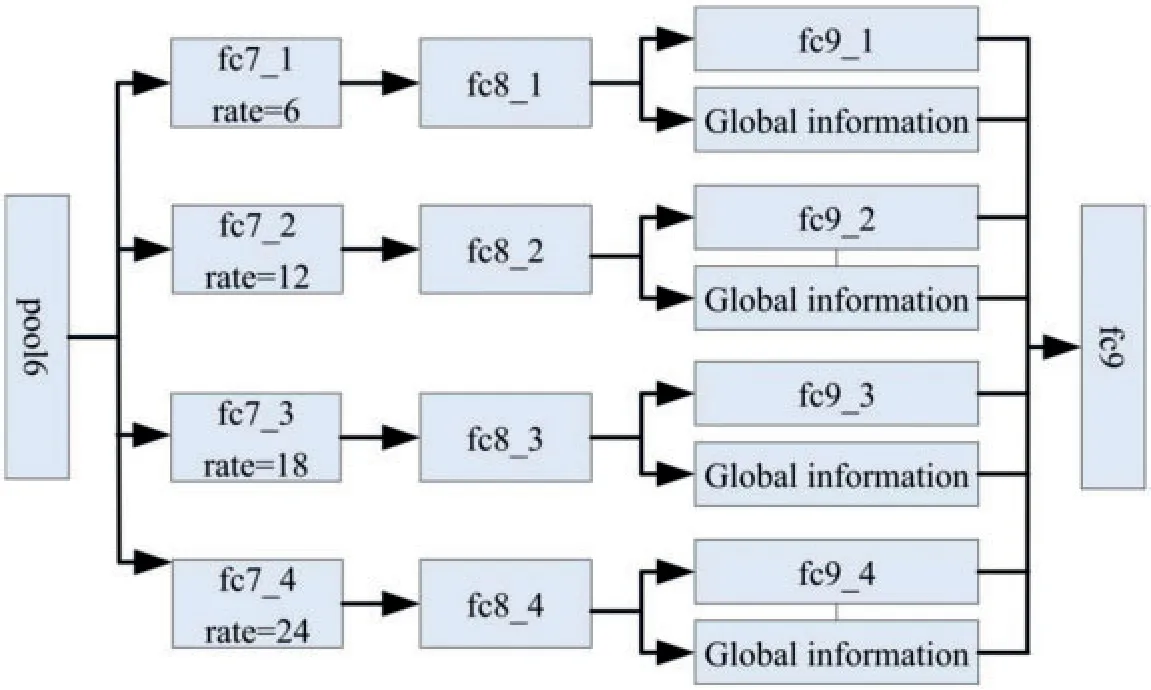
Figure 5:The network structure
When extracting global features for feature fusion,due to different data scales at different levels,it is necessary to regularize the feature data.

We use L2-normalize to normalize the input feature x,where y represents the normalized output vector.||·|is L2 norm.
Because the value distribution of the eigenvector is uneven,the scale parameter is introduced as

In the training process,L2 norm propagation is used to calculate the scale parameters through the chain method:

wherelis the objective function.L2 norm normalizes the extracted features and the added global features.
The median frequency balance strategy is used,and the cross entropy loss function is

as the objective function in the network training process.It is to determine the distance between the actual output P and the desired output p*,where c is the class of the tag.
Because the number of pixels in each category in the training data varies greatly,different weights are required according to the actual category.In order to obtain better results,the median frequency balance is proposed,and Eq.(4)is rewritten as follows:

wherewcis the adjustment weight,f(c)is the proportion of pixel value c to the total number of pixels.Through the different loss weights of real classes in the data to balance the categories,we can achieve better classification results.
In the process of deep neural network training, dropout is used in the full connection layer of convolutional network to prevent network over fitting[33].However,in FCN,dropout layer cannot improve the network generalization ability.To solve this problem,dropblock is introduced

whereγis used to control the number of channels removed from each convolution result.bsis used to control the block size to 0.kpis the dropout parameter.fsis the dimension of the characteristic diagram.dropblock makes the training network learn more robust features and greatly improves the generalization ability of the network.
3 Experiment and Result Analysis
The algorithm proposed in this paper is programmed and applied in the window system,VS2010 platform.Window 7, Intel®Core i5-6500 CPU, 3.20 GHZ, 16.0 GB and uses the deep network to extract features.We normalized the image to 512×512.At present, the average processing time of a single frame image is 1.2 s, which temporarily cannot meet the needs of real-time computing, and further research will be conducted in the future.
3.1 Database
3 datasets:The UA-DETRAC [34] dataset is a 10 h video shot by Canon EOS 550D camera at 24 different locations with a frame frequency of 25 fps and a resolution of 960×540 pixels.The UAV-DATA[35]dataset contains scenes such as trees and highways,including the characteristics of large-scale and multiple moving targets.The total video is 4.89 GB,and the minimum and maximum image resolution are 1920×1080 and 3840×2160,respectively.The minimum and maximum frame rate is 4 fps and 25 fps,respectively.The campus environment database is the shooting data over the playground,which contains a large number of small targets,as shown in Fig.6.

Figure 6:Data display
3.2 Detection Accuracy
To measure the effectiveness of the algorithm,AOM and ROC curves are introduced

whereγrepresents the result of manual annotation andνrepresents the detection result of the algorithm.
Based on the dataset described above,we have divided the data intoData 1:The first frame is a pure background image,and the target is moving all the time.Data 2:Small moving targets.Data 3:It remains stationary for a long time after the target moves.
As shown in Table 1 and Fig.7,with the complexity of the environment,the performance of the algorithm shows a downward trend.SVM+GMM algorithm uses GMM model to extract motion region,and SVM is used to judge whether the region is foreground.RICF detects the target according to the rotation invariance of the target.Time space[26]extracts the moving region according to the relationship between time and space, and establishes AdaBoost model to realize multi-scale target recognition.Under the guidance of gestalt vision,the proposed algorithm establishes a saliency graph mechanism to extract moving targets, and then realizes target recognition based on the convolution neural network structure of global information.Although the operation speed is slightly lower than SVM+GMM,AOM is the highest.

Figure 7:Region of interest curves

Table 1:AOM and operation time
3.3 Effect of Target Extraction
In order to intuitively show the effect of our algorithm, some detection results are selected, as shown in Fig.8.The proposed algorithm can effectively detect the target, and has good detection effect in the face of complex background,unstable target motion and small targets.

Figure 8:Detection results images
4 Conclusion
Remote sensing images can obtain ground and target’s information intuitively so as to provide accurate basis for decision-making.To solve the problem that it is difficult to accurately extract moving objects under complex conditions such as long-term stay and small-amplitude motion of moving objects in remote sensing videos,so we proposed a multi-moving object recognition algorithm based on remote sensing videos.Firstly,the problem of moving target detection is transformed into the problem of salient region probability,and the saliency map is constructed to extract moving targets.Secondly,by analyzing the global and local information of multiple targets, a convolutional neural network with global information is constructed to identify the target.Experiments show that the research results have a better effect on multi-target extraction in complex environments, and provide a new method for multi-target tracking in remote sensing images.So, on this basis, follow-up research on ground feature analysis can be carried out accordingly.
Funding Statement:This work is supported by Yulin Science and Technology Association Youth Talent Promotion Program(Grant No.20200212).
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2023年1期
Computer Modeling In Engineering&Sciences2023年1期
- Computer Modeling In Engineering&Sciences的其它文章
- A Fixed-Point Iterative Method for Discrete Tomography Reconstruction Based on Intelligent Optimization
- A Novel SE-CNN Attention Architecture for sEMG-Based Hand Gesture Recognition
- Analytical Models of Concrete Fatigue:A State-of-the-Art Review
- A Review of the Current Task Offloading Algorithms,Strategies and Approach in Edge Computing Systems
- Machine Learning Techniques for Intrusion Detection Systems in SDN-Recent Advances,Challenges and Future Directions
- Cooperative Angles-Only Relative Navigation Algorithm for Multi-Spacecraft Formation in Close-Range