
Change Point Detection for Process Data Analytics Applied to a Multiphase Flow Facility
2023-01-21 08:04RebeccaGeddaLarisaBeilinaandRuomuTan
Rebecca Gedda,Larisa Beilina and Ruomu Tan
1Department of Mathematical Sciences,Chalmers University of Technology,SE-42196,Gothenburg,Sweden and ABB Corporate Research Centre,Ladenburg,Germany
2Department of Mathematical Sciences,Chalmers University of Technology and University of Gothenburg,Gothenburg,Sweden
3ABB Corporate Research Center,Ladenburg,Germany
ABSTRACT Change point detection becomes increasingly important because it can support data analysis by providing labels to the data in an unsupervised manner.In the context of process data analytics,change points in the time series of process variables may have an important indication about the process operation.For example,in a batch process,the change points can correspond to the operations and phases defined by the batch recipe.Hence identifying change points can assist labelling the time series data.Various unsupervised algorithms have been developed for change point detection,including the optimisation approach which minimises a cost function with certain penalties to search for the change points.The Bayesian approach is another,which uses Bayesian statistics to calculate the posterior probability of a specific sample being a change point.The paper investigates how the two approaches for change point detection can be applied to process data analytics.In addition,a new type of cost function using Tikhonov regularisation is proposed for the optimisation approach to reduce irrelevant change points caused by randomness in the data.The novelty lies in using regularisation-based cost functions to handle ill-posed problems of noisy data.The results demonstrate that change point detection is useful for process data analytics because change points can produce data segments corresponding to different operating modes or varying conditions,which will be useful for other machine learning tasks.
KEYWORDS Change point detection;unsupervised machine learning;optimisation;Bayesian statistics;Tikhonov regularisation
1 Introduction
In process industries,the operating conditions of a process can change from time to time due to various reasons,such as the change of the scheduled production or the demand of the market.Nevertheless,many of the changes in the operating conditions are not explicitly recorded by the process historian;sometimes such information about the changes is indirectly stored by a combination of the alarm and event and the time trends of process variables.It may be possible for process experts to label the multiple modes or phases in the process manually;however the effort required will be enormous especially when the dataset is large.Therefore,an automated,unsupervised solution that can divide a large dataset into segments that correspond to different operating conditions is of interest and value to the industrial application.
The topic ofChange point detection(CPD) has become more and more relevant as time series datasets increase in size and often contain repeated patterns.In the context of process data analytics,change points in the time series of process variables may have important indications about the process operation.For example,in a batch process,the change points can correspond to the operations and phases defined by the batch recipe.Identifying change points can assist labelling of the time series data.To detect the change points,a number of algorithms have been developed based on various principles,with application areas such as sensor signals,financial data or traffic modelling.Reference[1–7]The principles differ in solution exactness due to computational complexity and in formulating a cost function which determines how the change points are defined.
The first work on change point detection was done by Page [5,6] where piecewise identically distributed datasets were studied.The objective was to identify various features in the independent and non-overlapping segments.The mathematical background of change point detection can be found in work by Basseville et al.[8].Examples of the features can be each data segment’s mean,variance,and distribution function.Detection of change points can either be done in real-time or in retrospect,and for a single signal or in multiple dimensions.The real time approach is generally known as online detection,while the retrospective approach is known as offline detection.This paper is based on offline detection,meaning all data is available for the entire time interval under investigation.Many CPD algorithms are generalised for usage on multi-dimensional data[7]whereas one-dimensional data can be seen as a special case.This paper focuses on one-dimensional time dependent data,where results are more intuitive and common in real world settings.Another important assumption in CPD algorithms is whether the total number of change points in a dataset is known beforehand.This work assumes that the number of change points is not known.
Recent research on change point detection is presented in[9,10].Various CPD methods have been applied to a vast spread of areas,stretching from sensor signals[2]to natural language processing[11].Some CPD methods have also been implemented for financial analysis [3] and network systems [4],where the algorithms are able to detect changes in the underlying setting.Change point detection has also been applied to chemical processes [1],where the change points in the mean of the data from chemical processes are considered to represent the changed quality of production.This illustrates the usability of change point detection and shows the need for domain expert knowledge to confirm that the algorithms make correct predictions.
The current work is based on numerical testing of two approaches for CPD: the optimisation approach,with and without regularisation,and the Bayesian approach.Both approaches are tested on real world data from a multi-phase flow facility.These approaches are developed and studied separately in previous studies[7,12].Performance comparison and the evaluation of both approaches’computational efficiency form this work’s foundation.In extension to the existing work,presented in [7],new cost functions based on regularisation can be implemented.Some examples where regularisation techniques are used in machine learning algorithms are presented in [13–15].For the Bayesian approach,the work by Fearnhead[12]describes the mathematics behind the algorithm.These two approaches have been studied separately and this work aims to compare the predictions made by the two approaches in a specific setting of a real world example.The methods presented by van Den Burg et al.[16]are used for numerical comparison,along with metrics specified by Truong et al.[7].
Using the same real world example,the paper also focuses on how regularised cost functions can improve change point detection compared to the performance of common change point detection algorithms.The contributions of the paper include the following:
1.Study of regularised cost functions for CPD that can handle the ill-posed problem in noisy datasets.
2.Application of various CPD algorithms to a dataset from a multi-phase process to demonstrate that CPD algorithms can identify the changes in the operating mode and label the data.
3.Numerical verification of improvement in the performance of CPD using regularised cost functions when applied to real-life,noisy data.
This work is structured as follows:first the appropriate notation and definitions are introduced.Then,the two approaches for unsupervised CPD are derived separately in Section 2 along with the metrics used for comparison.In this section,the background theory of the completeness for ill-posed problems along with the proposed regularised cost functions are also introduced.The real life dataset,the testing procedure and the results of the experiment are presented in Section 3.A discussion is held in Section 4 and a summary of findings and conclusions are given in Section 5.
2 Background
In this section we provide the background knowledge for the two unsupervised CPD approaches.The section first presents the notations and definitions used in the paper,followed by the introduction to the optimisation-based CPD approach.Several elements of the optimisation approach,such as the problem formulation,the cost function and the search method,are also presented and the common cost functions are defined.The need of regularisation for CPD is discussed along with the proposed regularised cost functions.Then the Bayesian CPD approach is derived from Bayes’formula using the same notations.It is demonstrated that,although the formulations of the two CPD approaches are different,the results obtained by both methods are similar,enabling the performance evaluation and comparison.Finally,the metrics used for evaluating the performance of change point detection are introduced.
2.1 Notation and Definition
Let us now introduce the notations used in the work.Fig.1 shows multiple change points(τ0,τ1,...,τK+1)and the segments(S1,S2,...,SK+1),defined by the change points,and is an example of a univariate time-series dataset.Since the CPD approaches are unsupervised and do not require prior knowledge about the true change points,the target is to identify the time stampsτ0toτK+1given the time series.

Figure 1:Illustration of used notation.In the figure,we see how K intermediate change points are present on a time interval t ∈[0,T],where we note that τ0 and τK+1 are synthetic change points
Throughout the work we are working in the time domain [0,T] ⊂N which is discretised withti∈[0,T],i=0,1,...,n.The signal value at timetiis given byyti:=y(ti).The time points are equidistant,meaningti+1=ti+dt,withdt=,∀i.A set ofKchange points is denoted byTand is a subset of time indices {1,2,...,n}.The individual change points are indicated asτj,withj∈{0,1,...,K,K+1},whereτ0=0 andτK+1=T.With this definition the first and the final time point being implicit change points,we haveKintermediate change points(|T|=|{τ1,...,τK}|=K).A segment of the signal fromatobis denoted asya:b,wherey0:Tmeans the entire signal.With the introduced notation for change points,the segmentSjbetween change pointsτj-1andτjis defined asSj:=[τj-1,τj],|Sj|=τj-τj-1.Sjis thej-th non-overlapping segment in the signal,j∈{1,...,K+1},see Fig.1.Note that the definition forSjdoes not hold forj=0,since this is the first change point.
As the goal is to identify whether a change has occurred in the signal,a proper definition of the term change point is needed along with clarification of change point detection.Change point detection is closely related to change point estimation(also known as change point mining,see[17,18]).According to Aminikhanghahi and Cook[19],change point estimation tries to model and interpret known changes in time series,while change point detection tries to identify whether a change has occurred[19].This illustrates that we will not focus on the change points’characteristics,but rather if a change point exists or not.
One challenge is identifying the number of change points in a given time series.A CPD algorithm is expected to detect enough change points whilst not over-fitting the data.If the number of change points is known beforehand the problem is merely the best fit problem.On the other hand,if the number of change points is not known,the problem can be seen as an optimisation problem with a penalty term for every added change point,or as enforcing a threshold when we are certain enough that a change point exists.It is evident that we need clear definitions of change points in order to detect them.The definitions for change point and change point detection are defined below and will be used throughout this work.
Definition 2.1(Change point).A change point represents a transition between different states in a signal or dataset.If two consecutive segmentsytl:tiandyti,tm,tl <ti <tm,l,i,m=0,...,nhave a distinct change in features or ifytiis a local extreme point (i.e.,minimum or maximum1If f(x*)≤f(x)or f(x*)≥f(x)for all x in X within distance ∈of x*,then x* is a local extreme point.),then,τj=ti,j=0,1,...,K,K+1 is a change point between the two segments.
We note that the meaning of adistinct changein this definition is different for different CPD methods,and it is discussed in detail in Section 3.In the context of process data analytics,some change points are of interest for domain experts but may not follow Definition 1,hence difficult to identify.These change points are referred to as domain specific change points and are defined below.
Definition 2.2(Change point,domain specific).For some process data,a change point is where a phase in the process starts or ends.These points can be indicated in the data,or be the points in the process of specific interest without a general change in data features.
Finally,we give one more definition of CPD for the case of available information about the probability distribution of a stochastic process.
Definition 2.3(Change point detection).Identification of timestamps when the probability distribution of a stochastic process or time series segment changes.This concerns detecting whether or not a change has occurred,or whether several changes might have occurred,and identifying the timestamps of any such changes.
2.2 Optimisation Approach
Solving the task of identifying change points in a time series can be done by formulating as an optimisation problem.A detailed presentation of the framework is given in the work by Truonga et al.[7],while only a brief description is presented here.The purpose is to identify all the change points,without detecting fallacious ones.Therefore,the problem is formulated as an optimisation problem,where we strive to minimise the cost of segments and penalty per added change point.We need this penalty since we do not know how many change points will be presented.Mathematically,the non-regularised optimisation problem is formulated as
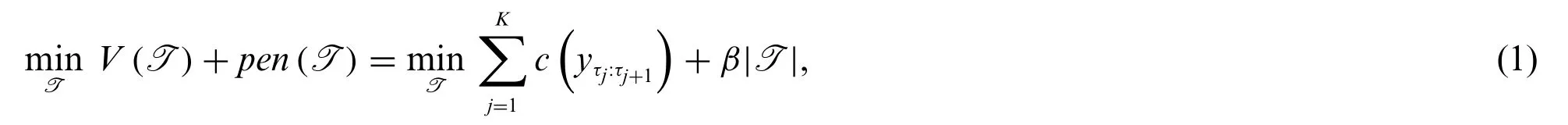
while the regularised analogy is
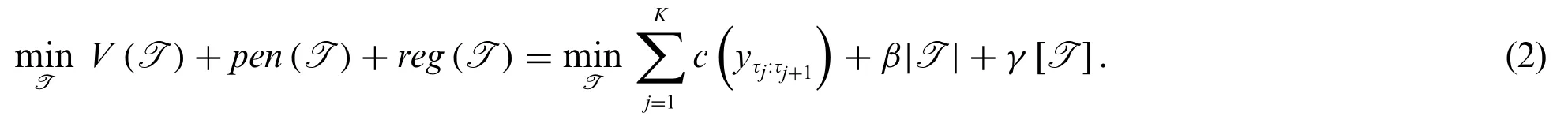
Here,V(T)represents a cost function,pen(T)is a linear penalty function with constantβandreg(T)is a regularisation term in the appropriate norm in the time space[0,T]with the regularisation parameterγ.
To solve the optimisation problem(1),we need to combine three components:the search method,the cost function and the penalty term.Fig.2 shows a schematic view of how the search method,cost function and penalty term create components of a CPD algorithm.Numerous combinations of components can be chosen for the problem(1).Fig.2 also illustrates which methods will be studied in this work.The two methods for search directions and cost functions are presented in separate sections,while the choice of penalty function is kept brief.A common choice of penalty function is a linear penalty,which means each added change pointτjcorresponds to a penalty ofβ.A summary of other combinations are presented in Table 2 in the work by Truonga et al.[7].
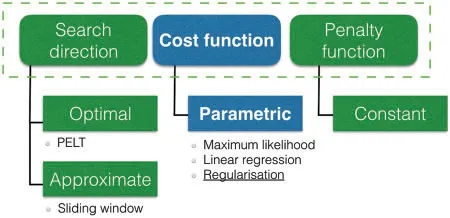
Figure 2:Illustration of the components used in the optimisation approach for change point detection.The focus of the paper is the cost function with regularisation
2.2.1 Search Direction
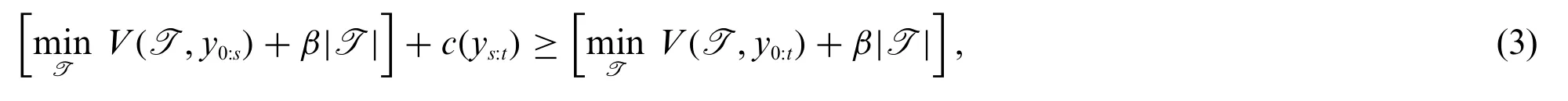
The search method poses a trade-off between accuracy and computational complexity.In CPD there are two main approaches used for this,optimal and approximate,see Fig.2.The problem formulated in Eq.(1)should be solved for an unknownK,where the penalty function can be chosen as a constant function,pen(·)=β.The search method used for this special case is known asPruned Exact Linear Time(abbreviated PELT)and implements a pruning rule.The pruning rule states that for two indicessandt,s <t <T,if the following condition holds thenscannot be the last change point.Intuitively,the algorithm compares if it is beneficial to add another change point betweensandt.If the cost of a segmentys:tis greater than the cost of two separated segmentsys:τ,yτ+1:tand the additional penaltyβ,then there is a change pointτpresent between indicessandt.The PELT-algorithm is presented in Algorithm 1 in [20],and has a time complexityO(T)[7].A drawback of this algorithm is that it can become computationally expensive for large datasets with many time stampst.
An alternative approach is to use an approximate search direction algorithm to reduce complexity.To reduce the number of performed calculations,an approximate search direction can be used,where partial detection is common.There are multiple options available to approximate the search direction;some are studied by Troung et al.[7].This paper focuses on one approach,thewindow based approximation.A frequently used technique is theWindow-slidingalgorithm(denoted as WINalgorithm),when the algorithm returns an estimated change point in each iteration.Similar to the concept used in the PELT-algorithm,the value of the cost function between segments is compared.This is known as the discrepancy between segments and is defined as

wherewis defined as half of the window width.Intuitively,this is merely the reduced cost of adding a change point attin the middle of the window.The discrepancy is calculated for allw≤t≤T-w.When all calculations are done,the peaks of the discrepancy values are selected as the most profitable change points.The algorithm is provided in Algorithm 2 in[20].There are other approximate search directions,which are not covered in this work,presented by Trounga et al.[7].For this work,the PELT-algorithm is used for the optimal approach and the WIN-algorithm is used for the approximate approach.
2.2.2 Common Cost Functions
The cost function can decide which feature changes are detected in the data.In other words,the cost function measures the homogeneity.There are two approaches for defining a cost function:parametric and non-parametric.The respective approaches assume either that there is an underlying distribution in the data,or that there is no distribution in the data.This work focuses on the parametric cost functions,for three sub-techniques illustrated in Fig.2.The three techniques,maximum likelihood estimation,linear regression and regularisation,are introduced in later sections with corresponding cost function definitions.
Maximum Likelihood Estimation(MLE) is a powerful tool with a wide application area in statistics.MLE finds the values of the model parameters that maximise the likelihood functionf(y|θ)over the parameter spaceΘsuch thatMLE(y)=maxθ∈Θ f(y|θ),whereyis observed data andθ∈Θis a vector of parameters.In the setting of change point detection,we assume the samples are independent random variables,linked to the distribution of a segment.This means that for allt∈[0,T],the sample

whereθjis a segment specific parameter for the distribution.The function 1(·)is the delta functionδ([τj,τj+1]),and is equal to one if sampleytbelongs to segmentj,otherwise zero.The functionf(·|θj)in(5)represents the likelihood function for the distribution with parameterθj.Then theMLE(yt)reads:

whereθjis segment specific parameter for the distribution.UsingMLE(yt)we can estimate the segment parametersθj,which are the features in the data that change at the change points.If the distribution family offis known and the sum of costs,Vin (1) or (2),is equal to the negative log-likelihood off,then MLE is equivalent to change point detection.Generally,the distributionfis not known,and therefore the cost function cannot be defined as the negative log-likelihood off.
In some datasets,we can assume the segments to follow a Gaussian distribution,with parameters mean and variance.More precisely,iffis a Gaussian distribution,the MLE for expected value(which is the distribution mean) is the sample mean.If we want to identify a shift in the mean between segments,but where the variance is constant,the cost function can be defined as the quadratic error between a sample and the MLE of the mean.For a sampleytand the segment meanthe cost function is defined as

where the norm‖·‖2is the usualL2-norm defined for any vectorv∈Rnas The cost function(7)can be simplified for uni-variate signals to


which is equal to the MLE variance times length of the segment.More explicitly,for the presumed Gaussian distributionfthe MLE of the segment varianceis calculated asusing the MLE of the segment mean,.This estimated variancetimes the number of samples in the segment is used as the cost function for a segmentya:b.This cost function is appropriate for piecewise constant signals,shown in Fig.1,where the sample meanis the main parameter that changes.We note that this formulation mainly focuses on changes in the mean,and the cost is given by the magnitude of the variance of the segment around this mean.A similar formulation can be given in theL1-norm,

where we find the least absolute deviation from the medianof the segment.Similar to the cost function in Eq.(7),the cost is calculated as the aggregated deviation from the median for all samples inya:b.This uses the MLE of the deviation in the segment,compared to the MLE estimation of the variance used in (7).Again,the function mainly identifies changes in the median,as long as the absolute deviation is smaller than the change in median between segments.
An extension of the cost function (7) can be made to account for changes in the variance.The empirical covariance matrixcan be calculated for a segment fromatob.The cost functions for multi-and uni-variate signals are defined by(11)and(12),correspondingly,as
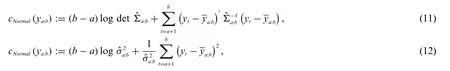

which clearly is an extension of Eq.(7).This cost function is appropriate for segments that follow Gaussian distributions,where both the mean and variance parameters change between segments.
If segments in the signal follow a linear trend,a linear regression model can be fitted to the different segments.At change points,the linear trends in the respective segment changes abruptly.In contrast to the assumption formulated in(5),the assumption for linear regression models is formulated as

with the interceptβj0and coefficientβjdependent on segmentj={0,...,K+1}.The noise for each sample is given byεt,which is assumed to be normally distributed with zero mean.Having only one covariatext,the model fitting is known as a simple linear regression model,which constitutes an intercept and a coefficient for the covariate.The interceptβj0and coefficientβjare unknown and each segment is presumed to have an underlying linear regression model.A simple minimisation problem for the cost function which uses the simple linear regression is defined as

where we use a single covariatext.The cost is given by the error between the simple linear regression and the samples,and is known as the model squared residual.
If we use previous samples[yt-1,yt-2,...,yt-p]as covariates,we have an autoregressive model.In this work,this is limited to four lags(p=4),meaning the covariate att=tiis defined as the vectorSimilar to Eq.(15),we can define a cost function as

2.2.3 Ill-Posedness of CPD with Noisy Data
In this section,we show that the solution of the CPD problem with noisy data is an ill-posed problem;thus,regularisation should be used to get an approximate solution to this problem.In order to understand ill-posed nature of CPD problem with noisy data,let us introduce definitions of classical and conditional well-posed problems,illustrated in Figs.3 and 4.The notion of the classical correctness is sometimes calledCorrectnessby Hadamard[21].
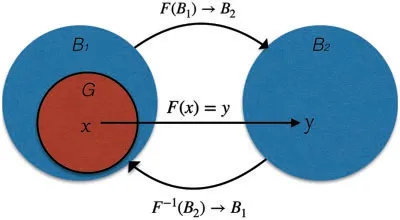
Figure 3:Illustration of classical correctness,see Definition 4
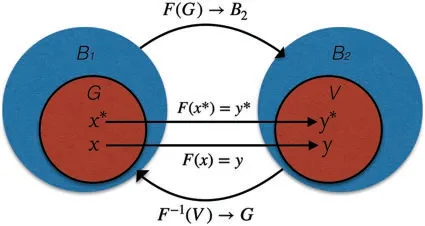
Figure 4:Illustration of conditional correctness,see Definition 5
Definition 2.4(Classical well-posed problem).LetB1andB2be two Banach spaces.LetG⊆B1be an open set andF:G→B2be an operator.Consider the equation

The symbolsxandyin this section represent two general variables and are different from the symbolsxandyelsewhere in paper.The problem of solution of Eq.(17) is calledwell-posedby Hadamard,or simplywell-posed,orclassically well-posedif the following three conditions are satisfied:
1.For anyy∈B2there exists a solutionx=x(y)of Eq.(17)(existence theorem).
2.This solution is unique(uniqueness theorem).
3.The solutionx(y)depends continuously ony.In other words,the inverse operatorF-1:B2→B1is continuous.
If Eq.(17) does not satisfy to at least one of these three conditions,then the problem (17) is calledill-posed.The problem setting studied in this paper does not satisfy all the above points.Fig.3 illustrates the definition of classical correctness.Let us now consider the problem(17)when the right hand side is a result of measurements and thus,is given with a noise of levelδ.We say that the right hand side of equation

is given with an error of the levelδ>0 (small) if ||y*-y||B2≤δ,wherey*is the exact value.The problem(18)can represent the non-regularised form of CPD as well if we associate withxthe change point and withythe noisy data corresponding to this change point.
Clearly,if we want to solve the problem(18)with noisy datay,the solution of this problem will be ill-posed in the sense of Hadamard,where our noisy data does not guarantee existence of the solution and makes the operatorF-1not continuous.In order to develop mathematical methods for solution of ill-posed problems Tikhonov has developed regularisation theory starting with the first work on this subject[22].First,he introduced the definition of a conditionally well-posed problem on the setG.
Definition 2.5(Conditionally well-posed on the set).LetB1andB2be two Banach spaces.LetG⊂B1be ana priorichosen set of the formG=,whereG1is an open set inB1.LetF:G→B2be a continuous operator.Suppose that||y*-yδ||B2≤δ.Herey*is the ideal noiseless data,yδis noisy data.The problem(18)is calledconditionally well-posed on the set G,orwell-posedby Tikhonov on the setGif the following three conditions are satisfied:
1.It isa prioriknown that there exists an ideal solutionx*=x*(y*)∈Gof this problem for the ideal noiseless datay*.
2.The operatorF:G→B2is one-to-one.
3.The inverse operatorF-1is continuous on the setF(G).
Fig.4 illustrates the definition of conditional correctness.Thus,the concept of Tikhonov’s consists of the following three conditions we should consider when we solve the ill-posed problem with noisy data:
1.A prioriassumption that there exists an ideal exact solutionx*of Eq.(18)for an ideal noiseless datay*.
2.A priori choice of the correctness setG.In other words,we shoulda priorichoose the set of admissible parameters for solutionx.
3.If we want to develop a stable numerical method for the solution of the problem (18),one should:
· Assume that there exists a family{yδ}of right hand sides of Eq.(18),whereδ>0 is the level of the error in the data with||y*-yδ||B2≤δ.
· One should construct a family of approximate solutions{xδ}of Eq.(18),wherexδcorresponds toyδ.
· The family{xδ}should be such that
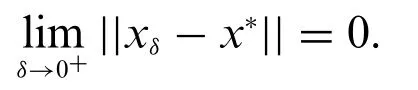
In order to satisfy this conception Tikhonov introduced the notion of a regularisation operator for the solution of Eq.(18).
Definition 2.6(Regularisation operator).LetRγ:Kδ0(y*)→Gbe a continuous operator depending on the regularisation parameterγ>0.The operatorRγis called theregularisation operatorfor

if there exists a functionγ (δ)defined forδ∈(0,δ0)such that
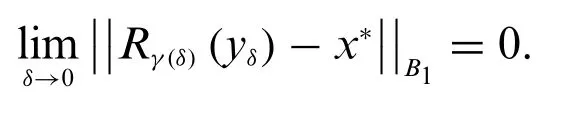
Thus,to find approximate solution of the problem (19) with noisy datay,Tikhonov proposed minimise the following regularisation functionalJγ(x),

whereγ=γ (δ)>0 is a small regularisation parameter and(x)is the regularisation term.
There can be a lot of different regularisation procedures for the solution of the same ill-posed problem[23–25],different methods for choosing the regularisation parameterγ[26–30]and a lot of different regularisation terms.Main popular regularisation terms are[26]

2.2.4 Regularised Cost Functions
As was discussed in the previous section,by adding a regularisation to Eq.(15)we transform illposed CPD with noisy data into conditionally well-posed problem.Thus,we can better handle the noisy data.The regularisation term is dependent on the model parametersβand a regularisation parameterγ,whereγcan be estimated or chosen as a constant (γ>0).Ifγ=0,we get the ordinary linear regression model,presented in Eq.(15).The use of regularisation has been studied widely,where the approach can provide a theoretical,numerical or iterative solution for ill-posed problems [25,27,30].Tikhonov’s regularisation has been used when solving inverse problems [21,24]and in machine learning for classification and pattern recognition,see details and analysis of different regularisation methods in[13–15,32].In this work we study Ridge and Lasso regularisation which are standard approaches of Tikhonov regularisation[33,34].
The first regularisation approach which is studied in this work is the Ridge regression,
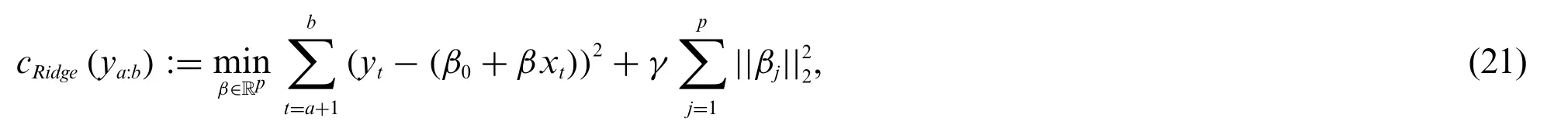
where the regularisation term is the aggregated squaredL2-norm of the model coefficients.If theL2-norm is exchanged for theL1-norm we get Lasso regularisation.The cost functions is defined
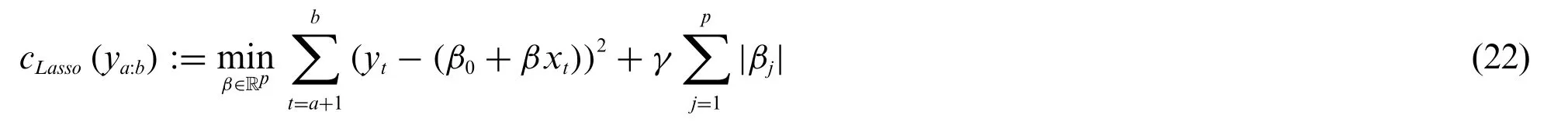
whereγis the previously described regularisation parameter.Note that this parameter can be the same as the parameter in the Ridge regression (21) but these are not necessarily equal.In all of our computations we empirically setγ=1.The study of how to choose the optimal value for gamma is the topic of future research.
2.3 Bayesian Approach
In contrast to the optimisation approach,the Bayesian approach is based on Bayes’probability theorem,where the maximum probabilities are identified.It is based on the Bayesian principle of calculating a posterior distribution of a time stamp being a change point,given a prior and a likelihood function.From this posterior distribution,we can identify the points which are most likely to be change points.The upcoming section will briefly go through the theory behind the Bayesian approach.For more details and proofs of the used Theorem,the reader is directed to the work by Fearnhead [12].The section is formulated as a derivation of the sought after posterior distribution for the change points.Using two probabilistic quantitiesPandQ,we can rewrite Bayes’formula to a problem specific formulation which gives the posterior probability of a change pointτ.Finally,we combine the individual posterior distribution to get a joint distribution for all possible change points.
In our case,we wish to predict the probability of a change pointτgiven the datay1:n.The principle behind the Bayesian approach lies in the probabilistic relationship formulated by Bayes in 1763[35]as

which can be reformulated in terms of CPD problem.A posterior probability distribution for a change pointτgiven the data can be expressed as
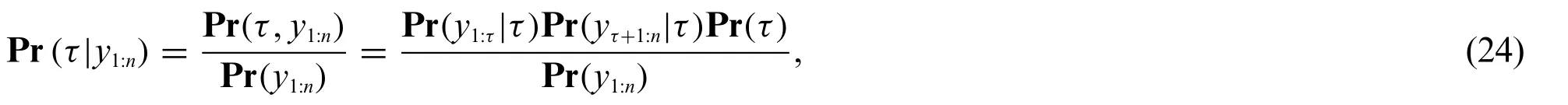
where Pr(y1:τ|τ)and Pr(yτ+1:n|τ)are the likelihood of segments before and after the given change pointτ,respectively.The prior distribution Pr(τ)indicates the probability of a potential change pointτexisting andy1:nrepresents the entirety of the signal.Using the(MAP)we identify the most probable timestamps of being change points.ExpressingMAP(y)in logarithmic terms,we get
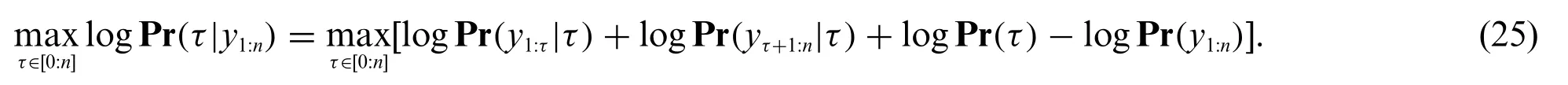
Similarly to Fearnhead[12],we will define two functionsPandQwhich are used for calculations in the Bayesian approach.First,we define the probability of a segmentP(t,s),given two entries belonging to the same segment
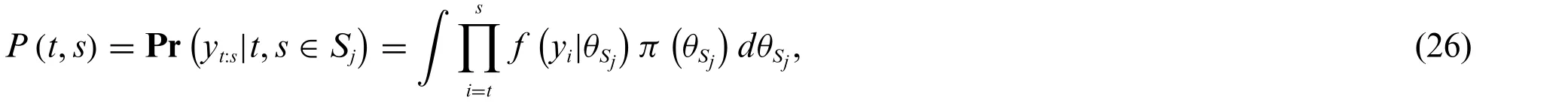
wherefis the probability density function of entryytbelonging to a segmentSjwith parameterθSj.We note that this function has similarities used in the optimisation approach,namely in Eq.(5),where we assume a distribution for each segment.In this work,this likelihood will be the Gaussian observation log-likelihood function,but other function choices can be made.Note thatπ(θSj)is the prior for the parameters of segmentSj.The discrete intervals[t,s],t≤smakePan upper triangular matrix which elements are probabilities for segmentsyt:s.Note that this probability is independent of the number of true change pointsK.
The second function,Q,indicates the probability of a final segmentyt:nstarting at timetigiven a change point at previous time step,ti-1.This probability is affected by the number of change pointsK,and also which of the change points that is located at timeti-1.Since we do not know the exact number of change pointsK,we use a generic variablek,and perform calculations for all possible values ofK.The recurrent function is defined as
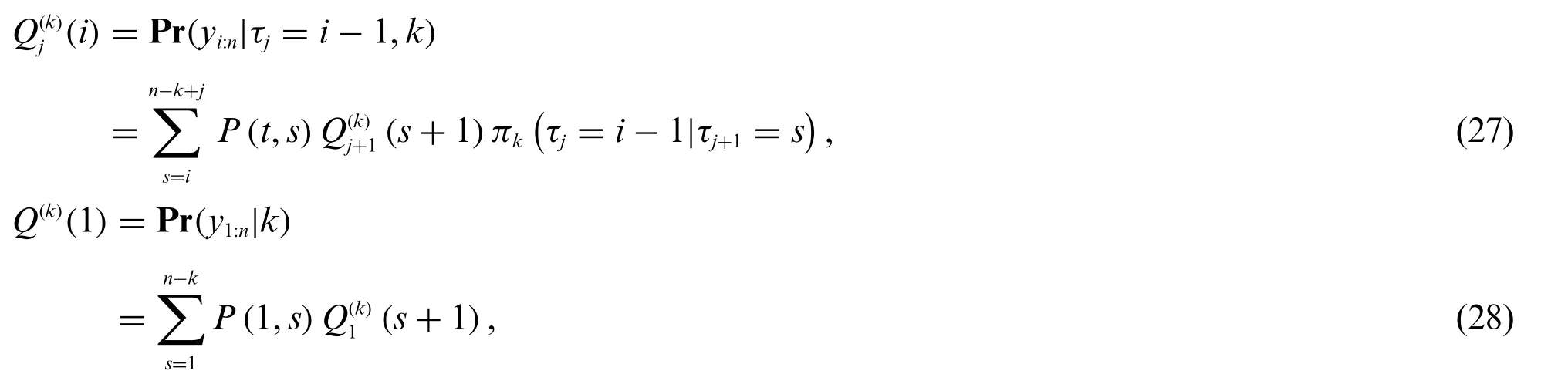
whereQ(k)(1)is the first time step and is a special case ofQ(k)j (i).The time index is indicated withi∈[2,...,n].The assumed number of change points is denotedk∈{1,...,n-1},wherej∈{1,...,k}indicates which of thekassumed change points we are currently at.The priorπkis based on the distance between change points,naturally dependent onk.This prior can be any point process,where the simplest example is the constant prior with probabilityp=1/n,wherenis the number of samples.Other examples include the negative binomial and Poisson distribution.Note that the prior should be a point process since we have discrete time steps.The first time step is defined as an altered function in(28).The result from this recursion is saved in an array of lengthn.A derivation and proof for this functionQare provided by Fearnhead in Theorem 1[12].When calculating the sums in Eqs.(27)–(28),the terms on the right hand side contribute to the function value.We use the same truncation rule as expressed in the work by Fearnhead[12],where∈=10-10is used as a truncation threshold.
Using functionsPandQ,the posterior distribution Pr(τj|τj-1,y1:n,k)for change pointτj,given the previous change pointτj-1,the datay1:nand number of change points,can be calculated.Using Eq.(24)along with the expressions forPandQ,we can formulate the posterior distribution for change pointτjas
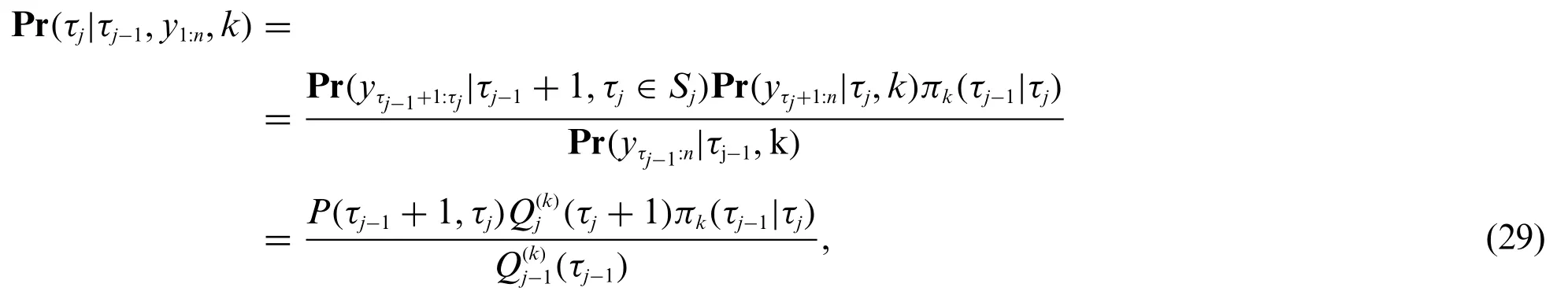
where

Here,πkis the probability ofτjbased on the distance toτj-1.This posterior distribution indicates the probability of change pointτjoccurring in each possible time stepti∈[1,n-1].The formulas in(29)and(30)can be applied for each possible number of change points,wherekcan range from 1 ton-1.Therefore,this posterior distribution is calculated for every available number of change pointsk.
The final step in the Bayesian approach is to combine the conditional probabilities for each individual change point(seen in Eq.(29))to get the joint distribution for all available change points.The joint probability is calculated as
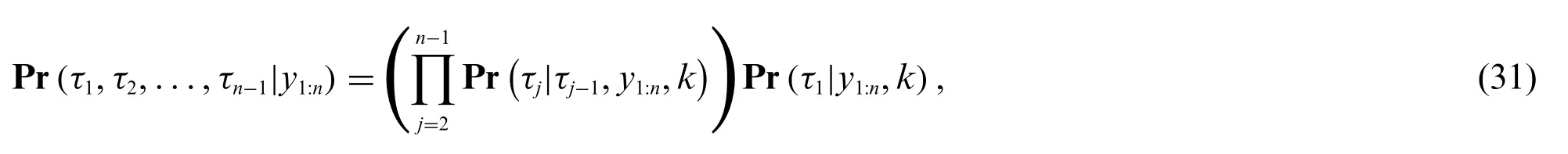
where the first change pointτ1has a different probability formulation due to not having any previous change point.This joint probability can be used to identify the most likely change points.Examples of calculated posterior distributions are found in Appendix A[20],where we see the varying probability of being a change point for each sample in the dataset.A sampling method can be used to draw samples from the joint posterior distribution,where we are interested in the points that are most likely to be change points.This means that we can identify the peaks in the posterior distribution,above a set confidence level.This is explained further in Section 3.2.In our computations,we use the python function find_peaks [36] to identify the posterior distribution’s extreme points (local maximums).These local maximums are taken as the change points.
2.4 Methods of Error Estimation
In this section,the used metrics for evaluating the performance of the CPD algorithms are presented.The metrics has previously been used to compare the performance of change point detection algorithms[7,19],where a selection of metrics has been chosen to cover the general performance.We first differentiate between the true change points and the estimated ones.The true change points are denoted byT*={τ*0,...,τ*K+1}whileindicate estimations.Similarly,the number of true change points is indicatedK*whilerepresents the number of predicted points.
The most straight forward measure is to compare the number of predictions with the true number of change points.This is know as theAnnotation error,and is defined as

Another similarity metric of interest is theRand Index(RI)[7].Compared to the previous distance metrics,the rand index gives the similarity between two segmentations as a percentage of agreement.This metric is commonly used to compare clustering algorithms.To calculate the index,we need to define two additional sets which indicate whether two samples are grouped together by a given segmentation or if they are not grouped together.These sets are defined by Truonga et al.[7]as
GR(T):={(s,t),1 ≤s <t≤T:s and t belong to the same segment in T},
NGR(T):={(s,t),1 ≤s <t≤T:s and t belong to different segments in T},
whereTis some segmentation for a time interval [1,T].Using these definitions,the rand index is calculated as
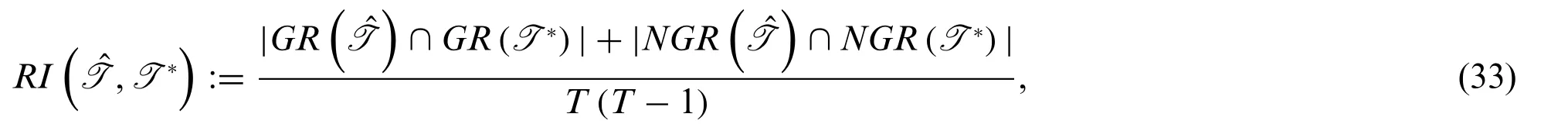
which gives the number of agreements divided by possible combinations.
To better understand how well the predictions match the actual change points,one can use the measure called themeantime errorwhich calculates the meantime between each prediction to the closest actual change point.The meantime should also be considered jointly with the dataset because the same magnitude of meantime error can indicate different things in different datasets.For real-life time series data,the meantime error should be recorded in units of time,such as seconds,in order to make the results intuitive for the user to interpret.The meantime is calculated as

A drawback of this measure is that it focuses on the predicted points.If there are fewer predictions than actual change points,the meantime might be lower if the predictions are in proximity of some of the actual change points but not all.Note that the meantime is calculated from the prediction and does not necessarily map the prediction to corresponding true change point,only the closest one.
Two of the most common metrics of accuracy in predictions areprecisionandrecall.These metrics give a percentage of how well the predictions reflect the true values.The precision metric is the fraction of correctly identified predictions over the total number of predictions,while the recall metric compares the number of identified true change points over the total number of true change points.These metrics can be expressed as
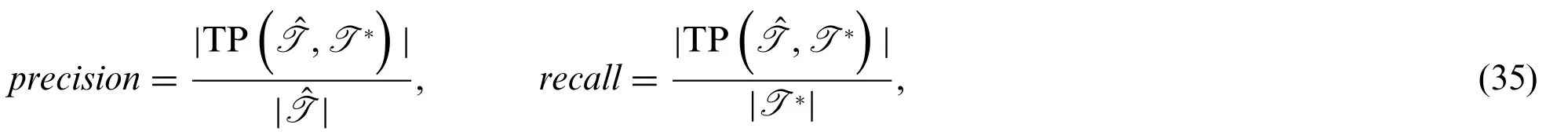
where TP represents the number of true positives between the estimationsand true change pointsT*.Mathematically,TP is defined as TPwhere∈is some chosen threshold.The threshold gives the radius of acceptance,meaning the acceptable number of time steps which can differ between prediction and true value.The two metrics(35)can be incorporated into a combined metric,known as theF-score.The metricF1-score uses the harmonic mean of the precision and recall and is applied in this work.As reviewed in this section,the metrics measure the similarity between the predicted change points and the actual change points from various perspectives.Hence this work adopt all of them to give a comprehensive evaluation of the performance of CPD algorithms.
3 Results
This section presents numerical examples illustrating the performance comparison of methods discussed in the paper.First,we describe the real-life dataset together with testing procedure.Next,several numerical examples demonstrate performance of CPD methods.
3.1 PRONTO Dataset
Multiphase flow processes are frequently seen in industries,when two or more substances,such as water,air and oil,are mixed or interact with each other.Different flow rates of the multiphase flows and different ratios between these flows will result in different flow regimes and the process is hence operated in different operating modes.An example is the PRONTO benchmark dataset,available via Zendo[37],and an illustration of the facility is seen in Fig.5.The dataset is collected from a multiphase flow rig.In the described process,air and water are pressurised respectively,where the pressurised mix travels upwards to a separator located at an altitude.A detailed description of the process can be found in[38].

Figure 5:Illustration of the multi-flow facility for generating the PRONTO dataset[38].The shaded areas indicate the air and water flows that are studied in this paper
Since the varying flow rates can result in varying flow regimes,we focus on the process variables of the flow rates.The signals are sampled with the same sampling rate and can be examined simultaneously,but will be treated individually in this work.The CPD approaches are applied to four process variables,including two flow rates of the inlet air denoted by Air In 1,Air In 2 and two flow rates of the inlet water represented as Water In 1 and Water In 2,visualised in Fig.6.The figure shows these four signals,where the different operating modes are marked with alternating grey shades in the background.
We take these changes in the operating mode as the true change points and they are used for evaluating the CPD algorithms.The operating modes were recorded during the experiment and always corresponded to the change in the water and air flow rates.However,due to human errors some change points were missing at the end of the experiment(after around the 13,000-th sample).
We observe a range of typical behaviours in the time series data,such as piecewise constant segments,exponential decay and change in variance.One can see that the changes in the flow rates will result in the changes in the operating mode.On the other hand,such changes in operating mode may not always be recorded during the process operation and then not always available for process data analysis.Therefore,the change points in the data will be a good indicator of changes in the operating mode if the CPD approaches can detect the change points accurately.
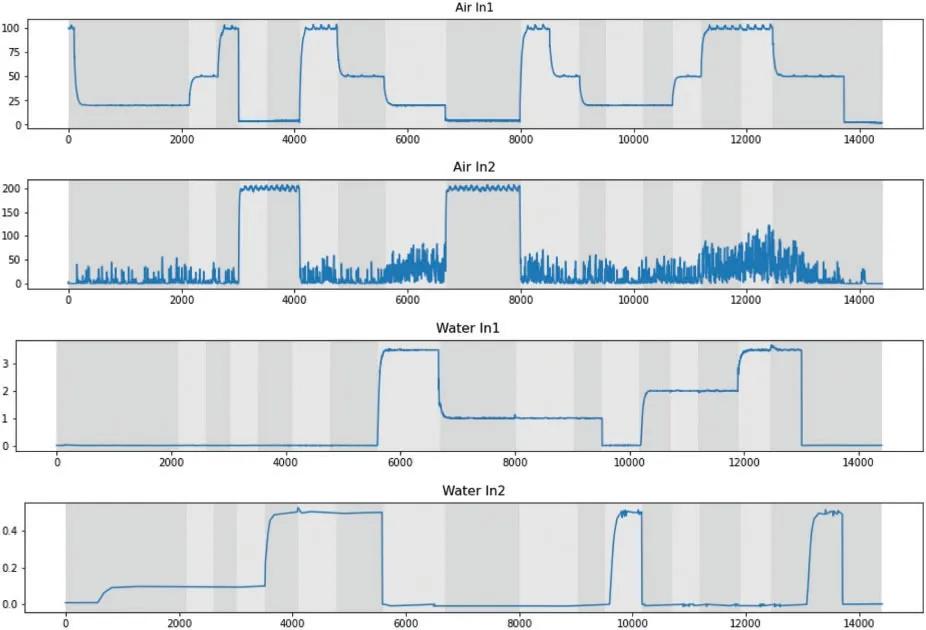
Figure 6:The process variables Air In 1,Air In 2,Water In 1 and Water In 2 described in [38].The segments of different operating modes are indicated with alternating grey regions,and sixteen change points are present on the boarder between segments
3.2 Testing Procedure
Both CPD approaches introduced in Section 2 are tested on the PRONTO dataset.To make predictions with the Python package RUPTURES[39],first one needs to specify the algorithm with search direction and cost function.In addition to this,the penalty level should also to be specified.The value of the perfect penaltyβin Eq.(1)is not known a priori,therefore,multiple predictions are done for various penalty valuesβ∈N ∪{0}.Ifβ=0 the algorithm receives no penalty when adding a change point,and the algorithm can add as many change points as necessary to minimise the cost functions.Predictions are made using all cost functions,where both PELT and WIN are used,and the time stamps of the detected change points are saved.
Using the concepts derived in Section 2.3 we can calculate posterior distribution with probabilities for each time step being a change point.Due to the algorithm being computationally heavy,the resolution of the data is reduced in the real dataset by PRONTO usingPiecewise Aggregate Approximation(PAA)[40].The function aggregates the values of a window to an average value.The used window size is 20 samples.Generally,to conclude a posterior distribution,sampling is used to create a collection of time stamps which in this case represents the change points.In essence,we want to create a sample of the most probable change points,without unnecessary duplicates.To draw this type of samples of change points from the posterior distribution,the function find_peaks in the Python package SciPy[36] is used.The function identifies the peaks in a dataset using two parameters: threshold which the peak value should exceed,and distance which indicates the minimum distance between peaks.The threshold is set to 0.2,where we require a certainty level of at least 20%.The distance is set to 10 time steps to prevent duplicate values.We note that this is not necessarily a proper sampling methodology,and other approaches can be used instead.An alternative sampling method is provided in Fearnhead[12].
All signals are normalised and handled individually such that CPD is applied to each variable for searching change points in univariate signals and the relation between the variables is neglected.The change points are then aggregated to get the combined change points on the entire dataset.The detected change points are compared against the real changes in the operating modes.The metrics provided in Section 2.4 are calculated and saved for each prediction.When enough tests have been performed in terms of penalty values,the results are saved to an external file.The values of the metrics are used to select the best prediction of change points.Our goal is to minimise the annotation error and meantime,and at the same time maximise theF1-score and the rand index.
3.3 Numerical Results
Given the different search directions and cost functions presented in Sections 2.2.1 and 2.2.2,respectively,we can presume that different setups will identify different features and hence differ in predicting of change points.We can also assume that the Bayesian approach,presented in Section 2.3,will not necessarily give the same predictions as the optimisation approach.We note that all algorithms predict the intermediate change pointsT={τ1,...,τK}along with one artificial change pointτK+1:=n.This artificial change point is based on definition and is used when the predictions are compared with respect to created segments,an example being RandIndex.This section presents the results of the two approaches on the real-world dataset.
The result of change point detection by CPD approaches is visualised in Fig.7.The figure also visualises the time series data from four process signals and the real operating modes.The cost functions are selected to represent the different types of cost functions;maximum likelihood,linear regression and the introduced regularised cost functions.Table 1 shows the predictions obtained using WIN.To calculate the precision and recall,the margin 1%of the number of samples are used,equivalent to 144 s in error is accepted as an accurate indication.The cost functionscNormalandcLassopredict 17 change points and have the lowest absolute error,where these algorithms also have the highest meantime.The smallest meantime is obtained bycL2andcL1,which predict fewer points.The cost functionscL2andcL1have the highestF1-scores of 59.3%and 64.1%respectively and rand index of 96.4%and 97.2%,respectively.The highest precision is obtained usingcL2while the recall is lower at 50%.In the top image of Fig.7 we see a comparison of the predictions made bycL1,cARandcRidge.We see similarities in the predictions made bycL1andcRidgeand other predictions made bycAR.We can also note that,due to the linear model structure chosen for the cost function,some algorithms detect two change points when an exponential trend appears;one change point is in the steep part and the other when the trend stabilises.An example can be seen around the 10k-th sample in Fig.6.
In the bottom image,we see predictions made bycL2,cARandcRidgewhen PELT is used.The predictions’evaluation metrics are given in Table 2.We can note the generally high rand indices andF1-scores,with the exception ofcNormal.Most cost functions predict 17 change points,and have a lower meantime compared to the values in Table 1.The smallest meantime of 95.8 time steps is obtained bycARand the largest meantime bycNormal.The highestF1-score of 66.7%and rand index of 95.4%is obtained bycRidge.In the bottom image of Fig.7 we see thatcL2,cLinRegandcRidgegive similar predictions and correspond to many of the true change points.
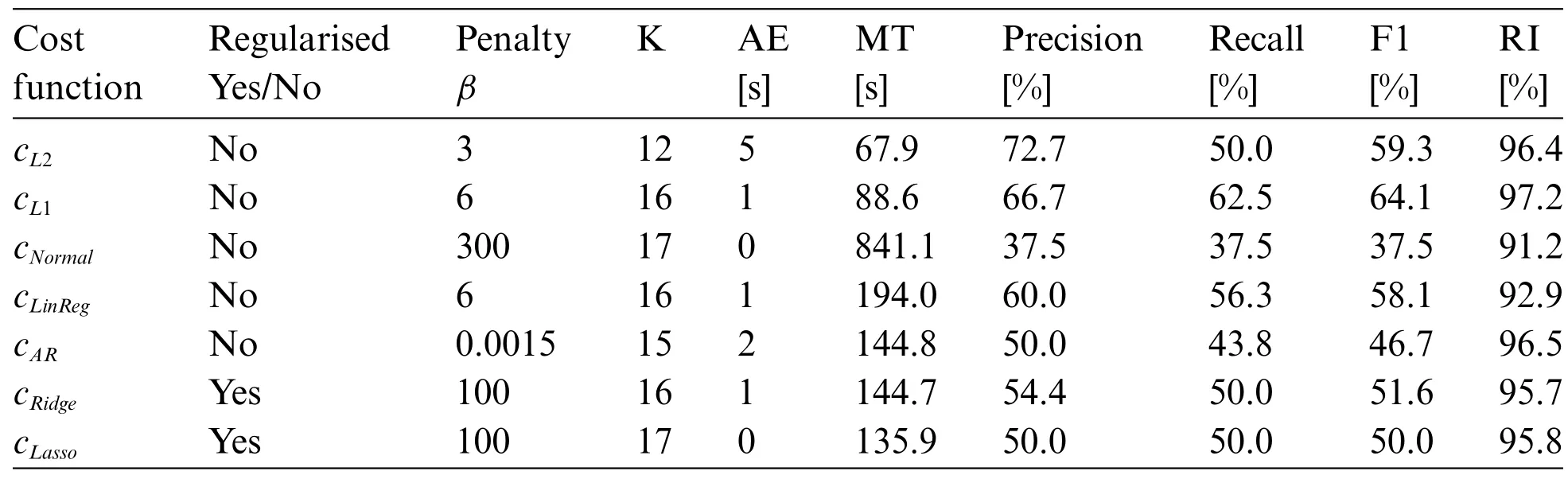
Table 1:Prediction results for PRONTO dataset[37]using the optimisation approach,where the search method WIN is used.Each cost function indicated the best possible penalty level β defined in(1),along with respective obtained scores
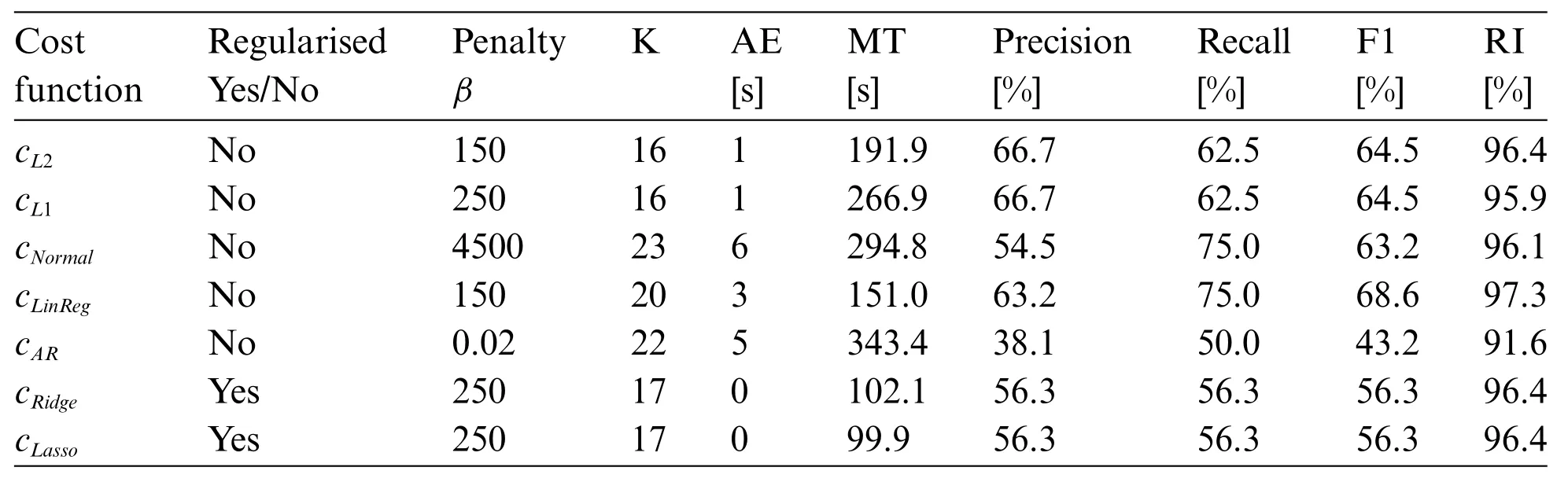
Table 2:Prediction results for PRONTO dataset[37]using the optimisation approach,where the search method PELT is used.Each cost function indicated the best possible penalty level β defined in (1),along with respective obtained scores
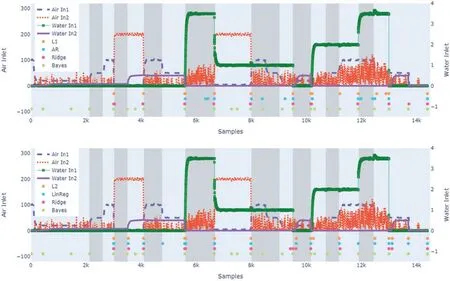
Figure 7:Results for the PRONTO dataset,using various cost functions.The different operating modes are visualised in the background as shaded intervals.Predicted change points are seen in coloured points,which are time points and do not have a value
Fig.7 also shows predictions obtained by the Bayesian method.The method predicts 21 change points,which gives an absolute errorAE=4.The meantime of the predictions is 448.9 s.The precision and recall are 65.0% and 81.3%,respectively,which gives anF1-score of 72.2%.The rand index is 96.0%.
4 Discussion and Future Work
In the previous sections,the two CPD approaches are reviewed and applied to the PRONTO benchmark dataset and the detected change points are compared against the real changes in the dataset.We have demonstrated that CPD can be executed on real life data to generate useful insights that may facilitate the analysis.In this section,the results and the implication are discussed and several potential directions are given towards further development and application of CPD for process data analytics.
A natural extension of the work is to conduct the study with other search methods for the optimisation approach and the study can be conducted with other search methods for the optimisation approach and other CPD algorithms to be used as benchmarks.For example,more results on numerically simulated datasets can be found in[20].When the change points have been identified,the corresponding timestamps can be used to create segments in the data.The segments can correspond to phases in the process,which in turn can be relevant to compare to detect variations in the process phases.Alternatively,change points can indicate anomalies in the process variable signals.This underlines the usability of change point detection in terms of data processing.
Datasets tend to increase in size,and a relevant topic is the suitability for large amounts of data.The two approaches studied in the present work are suitable for datasets with different sizes.The optimisation approach can employ various combinations of cost functions and search directions and the search direction is the major impact factor for the computational complexity.This paper studied two search directions,where the optimal search direction PELT generally gives more accurate predictions.The approximate search direction has a lower computational complexity and can handle larger datasets in a reasonable amount of time.The window size for the WIN algorithm is a tuning parameter that needs to be adjusted accordingly;hence it requires further investigation.On the other hand,the PELT algorithm is computationally heavy,and accurate concerning search direction.Therefore,additional steps,such as down sampling the data,may be necessary when applying PELT to large datasets.The Bayesian approach is also computationally heavy since the posterior distribution needs to be calculated for every time stamp.Nevertheless,the posterior distribution used for identifying the change points only needs to be calculated once and multiple samples of change points can be drawn from the distribution.To conclude,the two CPD approaches may perform differently on larger datasets while having their own merits.
Real data generally have noise,which can affect the predicted change points.For the optimisation approach,some of the common cost functions tend to be sensitive to noise,while the proposed regularised cost functions are less sensitive.It is also noted that the model based cost functions are more sensitive to changes in the shape of the signal than to changes in the values,making model based cost functions more generalisable and less sensitive to noise.Similarly,the Bayesian approach is not too sensitive to noise and can handle value changes in a similar way as the model based cost functions.This indicates that both approaches are compatible with real-world datasets and the optimisation approach demands a suitable cost function to make accurate predictions.Some segments in the PRONTO dataset follow an exponential decay,where some cost functions give indicate two change points in these segments,one at the start of the decay and one where the decay has subsided.In this dataset,we see a change point at the beginning of the exponential decay and not when it has subsided.It is important to select a cost function that handles these segments appropriately to give accurate predictions.
In industrial practice,process experts are often able to provide useful feedback and insights about the operating status of a process.Hence a future direction of applying CPD to process data analytics will be to incorporate the feedback of process experts.For example,it may be interesting to incorporate such information as the prior for the Bayesian approach.This paper has not studied the possibility of user interaction,but suggests it as a topic for future work.
5 Summary
This paper demonstrated how change point detection is relevant for analysing process data,particularly,when the operating condition in the process varies a lot and the corresponding labels are unavailable.Two unsupervised algorithms for change point detection,namely the optimisation approach and the Bayesian approach,are studied and applied to a real-life benchmark dataset.We also illustrated why the optimisation problem of CPD is an ill-posed problem when there is noise in the data and proposed a new type of cost function,using Tikhonov regularisation,for the optimisation approach.Based on the results of the real-life dataset,the paper investigated how the features influence the performance of CPD approaches in the data.The results of CPD on the dataset verified that CPD can detect change points that correspond to the changes in the process and these change points can be considered as labels for data segmentation for further analysis.The proposed regularised cost functions were compared against non-regularised cost functions.It has been shown that,when applied to the real-life dataset with noise,regularised cost functions can achieve better performance of CPD than non-regularised cost functions.
Acknowledgement: The authors acknowledge the financial support by the Federal Ministry for Economic Affairs and Climate Action of Germany(BMWK)within the Innovation Platform“KEENArtificial Intelligence Incubator Laboratory in the Process Industry”(Grant No.01MK20014T).The research of L.B.is supported by the Swedish Research Council Grant VR 2018–03661.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2023年3期
Computer Modeling In Engineering&Sciences2023年3期
- Computer Modeling In Engineering&Sciences的其它文章
- A Consistent Time Level Implementation Preserving Second-Order Time Accuracy via a Framework of Unified Time Integrators in the Discrete Element Approach
- A Thorough Investigation on Image Forgery Detection
- Application of Automated Guided Vehicles in Smart Automated Warehouse Systems:A Survey
- Intelligent Identification over Power Big Data:Opportunities,Solutions,and Challenges
- Broad Learning System for Tackling Emerging Challenges in Face Recognition
- Overview of 3D Human Pose Estimation