
A Thorough Investigation on Image Forgery Detection
2023-01-21 08:04AnjaniKumarRaiandSubodhSrivastava
Anjani Kumar Raiand Subodh Srivastava
Department of Electronics&Communication Engineering,NIT,Patna,India
ABSTRACT Image forging is the alteration of a digital image to conceal some of the necessary or helpful information.It cannot be easy to distinguish the modified region from the original image in some circumstances.The demand for authenticity and the integrity of the image drive the detection of a fabricated image.There have been cases of ownership infringements or fraudulent actions by counterfeiting multimedia files,including re-sampling or copy-moving.This work presents a high-level view of the forensics of digital images and their possible detection approaches.This work presents a thorough analysis of digital image forgery detection techniques with their steps and effectiveness.These methods have identified forgery and its type and compared it with state of the art.This work will help us to find the best forgery detection technique based on the different environments.It also shows the current issues in other methods,which can help researchers find future scope for further research in this field.
KEYWORDS Forgery detection;digital forgery;image forgery localization;image segmentation;image forensics;multimedia security
1 Introduction
Millions of digital documents are created and circulated daily through newspapers,magazines,websites,and television.Images are an excellent tool for communication in any of these information channels.These images,along with video and audio,can be easily collected using various devices or software.DIs serve as evidence or proof against crimes.Unfortunately,manipulating images with computer graphics and image processing tools is not difficult.The way we deal with photo modification raises many legal and ethical issues that need to be addressed [1].However,before considering what action to take in response to a problematic image,one must first determine it has been altered.There are various ways to modify the content of an image,such as compression,splicing,copy-move,and retouching techniques [2–4].One of the most typical picture alteration processes is image composition (or splicing) and retouching.Various applications can perform manipulations in images that humans cannot detect by just looking at them once.Therefore,there is a need for automated digital image forgery detection(DIFDs)techniques to perform these tasks very fast and effective.Image forgery detection has developed as a fantastic study in various DIPs applications(digital image processing),image forensics,criminal investigation,biomedical technology,computer vision[5–7].There are various digital image forgery detection techniques used to detect the different kinds of forgery.DIFDs can be broadly classified passively or actively [8],as depicted in Fig.1.An active forgery detection technique requires pre-extracted or pre-embedded information.
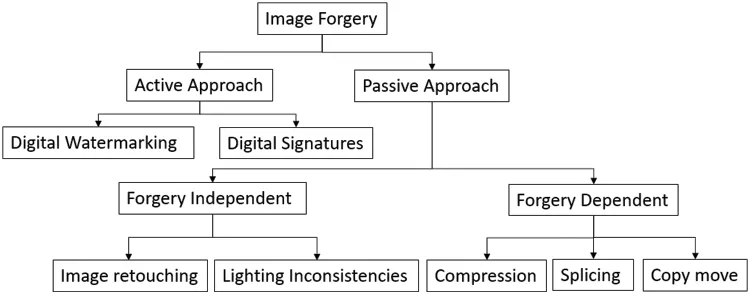
Figure 1:Categorization of image forgery detection techniques
1.1 Categorization of DIFDs
Active DIFDs necessitate the preparation of digital images,including watermarking,embedding and signature creations,limiting their practicality in applications.Passive DIFDs,unlike watermarks[9]and signatures[10],do not generate digital signatures or embedding from watermarks.DIFDs can be classified into five groups[11],as shown in Fig.2.A few select DIFDs are presented for detecting passive image forgeries[12].

Figure 2:Digital image forgery detection techniques
Pixel-based DIFDs:Pixel-based approaches process DI pixels to statistically identify abnormalities that arise in image pixels due to tampering.The approaches also consider spatial or altered domain correlations between pixels that happen in the tampering of images.Copy-move,re-samples,retouches,and image splicing are some of the approaches under this category.These are the most frequently used methods in DIFDs[13].
Format-based DIFDs:Forged images can also be detected based on their formats.They are used mainly in JPEG formats.Identifying fraud in compressed images is a complex task.However,structure-based approaches detect forgery even in compressed images.A modified,fabricated image that has been compressed (JPEG) makes forgery detections extremely difficult.Forensics investigations,however,use many characteristics of JPEG compression to discover manipulations.Format based DIFDs can be found on one of JPEG quantization [14],double JPEG compressions [15,16],multiple JPEG compressions[2,17],and JPEG blocks.
Camera-based DIFDs:A digital camera transfers acquired images from sensors to memory.They are quantized,color correlated,gamma-corrected,white balanced,filtered,and JPEG compressed.These processes are based on the different camera models and artefacts.Image captures undergo multiple stages of processing.Light enters the camera’s lens,followed by the sensors’traversals through CFAs(Color Filter Arrays).The sensor’s Photodetectors capture this incidental light and convert it to a voltage form,converted into digital data using A/D(Analog-to-Digital)conversions.Most current cameras use CMOS(Complementary Metal-Oxide Semiconductors),while a few use CCDs(Charged Coupled Devices).CFAs acquire color images from these sensors,which capture one color.At the same time,balance colors are computed using interpolations correlations that could be used to identify manipulations.Image Enhancement techniques are used to improve image qualities before storage.Artefacts generated at various phases of image generations can also be used to identify manipulations.These artefacts are generally estimated using chromatic aberrations,source camera identifications,CFAs,interpolations,and sensor noise errors where discrepancies indicate manipulations.
Physical environment-based DIFDs:Assuming fakes of two Hollywood stars rumored to be romantically connected through their beach images.Two individual photos can be superimposed to create a combined image but fail in mimicking the lighting effects of original images captured separately.Differences in illuminations throughout an image are proof of manipulations.These approaches are based on the lighting conditions of the captured original idea,as lighting is crucial to photography.They can be categorized into three groups.Discrepancies in light sources between certain items in the images assist in detecting manipulations in physics-based methods[18].This approach was first developed by Kee et al.[18]and used three-dimensional surface geometries.
Geometry-based DIFDs:Geometry-based approaches measure object locations in the environment of the camera.Geometries can be faked using two sub-divided intrinsic camera parameters-based techniques,including multi-view geometries,focal lengths,primary points,aspect ratios,skews,and metrics.The main points or optical axis intersections and planes lie in genuine image centres.When tiny portions of images are moved or translated,copy-moves or images are merged,called spliced.It is not easy to retain main image points from the same perspectives[19].
DIP approaches have traditionally focused on altering image pixels.Hence,pixel-based DIFDs have been extensively utilized as the most basic and widely used forgery techniques.These approaches analyse inter-pixel correlations caused by direct/indirect image tampering.Copy-moves,Image splices,re-samples,and retouches are the most prevalent pixel-based DIFDs,as indicated explained in the introductory part of this work.In copy-moves,image parts are duplicated and/or within images,resulting in significant correlations in these areas,which can be utilized as evidence for DIFDs.However,developing effective characteristics or matching algorithms for DIFDs is a big issue.
2 Literature Review
DIFDs generally include pre-processing,feature extraction,and classification/detection techniques.These DIFD processes are examined by others researchers in previous works.The review consists of three sub-sections.Where the first section discusses processing methods.While subsequently,reviews of feature extraction approaches have been done.The third section review of classification and deep learning methods with its descriptions.
2.1 Preprocessing Methods
Forensic research mainly focuses on strong algorithmic creations to identify where altered image elements are present.Hence,image noise eliminations are the first step for clearly identifying forgeries.A multitude of approaches exist in pre-processing,like color conversions,image smoothing,CEs(Contrast Enhancements),HEs (Histogram Equalizations),and MFs (Median Filters).In image forensics,it is critical to look at these processing processes,which are detailed below.Pre-processing step typically begins with color to grey scale conversions before the subsequent stage of feature extractions.
DIFDs for detecting copy-moves were proposed by Panzade et al.[20].The scheme called CMFDs (Copy-Move Forgery Detections) converted RGB (Red Green Blue) images into HSVs(Hue Saturation Values) in their representations from faked photos.The study used SIFTs (Scale Invariant Feature Transforms) to extract key points and match them where they were clustered for final detection.Their comprehensive experimental findings demonstrate detection of cloned areas successfully.Their scheme also gave good results to geometrically transformed or multi-cloned images.
Many pre-processing methods were combined by Lonnie et al.[21] in their proposed scheme.Their pre-processing included HEs and filters (median,Gaussian and sharpening),processed using SIFTs.The study decreased false matches in identifying forged areas.SIFT key points such as identified counts,count of matches,and inaccurate match counts were displayed in the survey.Their scheme coupled SIFTs with pre-processing methods to reduce false matches in 30 tampered photos divided into three categories.Their optimum pre-processing strategy produced minimal false matches when tested on image databases.
A unique pre-processing method was proposed by Kuznetsov et al.[22].Their work used hashing for the detection of copy-moves and could work on duplicated images.The work used initial image transformations to integrate modifications.In the second step,Image intensity range reductions,gradient computations,orthonormal expansions,Alces(adaptive linear contrast enhancements)and LBPs(local binary patterns)were compared during their tests on their ability to detect DIFDs.
CEs in DIPs can improve the dynamic range of image pixel values,as Chakraverti et al.[23]showed in their study for detecting copy-moves.Their ORB(Oriented FAST and Rotated BRIEF)approach was combined with modified Local CLAHEs(Contrast Limited Adaptive Histogram Equalizations),an alternative to SIFTs.Their experimental results revealed the success and betterment of their proposal when compared with other techniques in terms of FPRs (False Positive Rates) and TPRs(True Positive Rates).
Cao et al.[24]proposed two new methods using CEs for digital images that were modified.Their scheme concentrated on detecting global CEs,which were applied to JPEGs.Theoretically,histogram peak/gap artefacts caused by JPEG compressions or translation of pixels were examined,and zeroheight gap fingerprints were identified for differentiation.It was followed by a novel method that detected composite images generated by enforcing contrast adjustments on source image regions.For detecting applied CEs in source areas,they were identified using block-wise peak/gap groupings.Image forgeries were detected by evaluating composition borders and the consistency of regional artefacts.Their extensive tests showed the efficacy of the proposed approaches.However,when CEs was the final post-processing step and failed on image compressions after executing CEs,it worked efficiently.
Yuan [25] proposed grey level cumulative distributions of image HEs.The distributions were represented as discrete identity functions on inherent fingerprints created by global HEs.The study has observed cumulative distributions matched well with their model.Their classifications recognized usage of global HEs.Compared to prior approaches,their proposed method differentiated global HEs from other types of CEs accurately.The proposal’s effectiveness was exhaustively evaluated in identifying image HEs and resistance against attacks.
Powerful MFs were presented by Kang et al.[26]in their study where residuals of MFs(differences between original and filtered image versions) were examined statistically.The study fitted their MF residuals into an AR(Autoregressive)model for capturing statistical characteristics.Their model used AR coefficients as characteristics for detecting MFs,followed by a series of tests that evaluated the efficiency of their proposed MF based detections.Their results demonstrated that their proposed forensic methodology outperformed previous techniques,shallow FPRs and limiting characteristic counts.
MFs for DIFDs were also proposed by Gao et al.[27] using CFDIs (combined differences image characteristics).Their CFDIs were a combination of first-order JCPDFs (Joint Conditional Probability Density Functions)and Second-Order Difference Images.Dimensionality reductions were executed using PCAs(Principal Component Analyses)for obtaining final features for given threshold values.The study’s experiments on single/compound databases showed that their proposed scheme outperformed other approaches on uncompressed/compressed image datasets,mainly on solid JPEG compressions and low-resolution images.
A different approach for detecting global CEs and copy-paste forgeries was proposed by Charpe et al.[28].The study used contrast computations for detecting CEs in images.The proposed method was resistant to post-processing JPEG compressions,and features from the pictures in copypaste duplicates were extracted using DCTs(Discrete Cosine Transforms).The scheme could detect tiny or medium,or large areas of fabrications in forged images with ease.
Sensor’s pattern noise was used for DIFDs by Chierchia et al.[29] in their study.Their scheme recast forgery issue as a Bayesian estimation issue,used appropriate MRFs (Markov Random Fields) to describe the source’s spatial solid dependencies,and judged each image pixel collectively.Subsequently,convex optimizations were used to produce globally optimum solutions,and non-local denoising enhanced PRNUs (Photo-Response Non-Uniformities) for estimations.Their simulation of genuine forgeries indicated that their proposed approach improved existing approaches successfully in a wide range of practical instances.
CNNs(Convolution Neural Networks)were used by Chen et al.[30],where the study presented convolution filters with an isotropic design.The scheme is minimized the number of CNN parameters and their proposed filter,rotation-invariant features using equal weights for image forensics.Their experiments demonstrated that their new rotation-invariant CNNs achieved significantly higher performances and fewer parameters,improving 13% in Gamma corrective forensics DIFDs.When compared to the popular BayarNet,it also produced considerably better generalization results on diverse databases,in addition to its resilience against JPEG compressions.
It may be noted that CLAHEs responsible for RGBs-HSVs conversions play a critical role in DIFDs pre-processing stages.
Picture enhancement entails methods that increase image quality,allowing for more accurate visuals for analyses.It is extensively utilized in various applications because it can overcome some image capture systems’constraints [31].Image improvement processes include deburring,noise reduction,and contrast enhancement.CLAHEs[32,33]are standard approaches for enhancing local CEs that have proven practical and helpful in various applications[34–36].CLAHE is a technique for increasing the visibility of a hazy picture or video.
CLAHE is an AHE variation that minimizes noise amplification.CLAHE has also been proven to be unsuitable for digital images with fine details.They combined global histogram modification with CLAHE in Histogram Modified(HM-CLAHE)[35].Along with the usual CLAHE,local CEs emphasized the small features buried in images and an enhancement parameter to adjust the amount of enhancement.As a result,combining Local Contrast Modification (LCM) with CLAHE yields optimum contrast enhancement with all local information of pictures that standard CLAHE may not fail.
The authors propose the LCM-CLAHE algorithm,which contains various steps:First,take the input image.LCM is provided with the original picture and the enhancement parameter as input.We alter the photo in LCM to generate the more delicate features concealed in the mammography image and then send that output image to CLAHE,enhancing image quality[37].
The initial step for image enhancements is an application of CEs to images where both global and local information are considered for image improvements.Local knowledge of images is captured by a window defined to the network’s pixel widths.An equation can be used to express the transformation function Eqs.(1)–(2).

E-parameter for enhancement,M–input image’s global mean,g-enhanced image,f-input image,m-input image’s local mean,σlocal SD(standard deviation),E–constant in the interval[0,1].Eqs.(3)–(4)are used to calculate m andσfor a user-defined window width,

Averages of windows are computed from the obtained standard deviation and local mean values utilized in Eqs.(1)and(2).The more delicate features of mammography pictures will be highlighted with this approach.This approach produces an improved image that is sent into CLAHE.
A picture received in RGB space is transformed into a color space with a brightness(Y)and two chrominance components(Cb,Cr)as shown in Eq.(5),
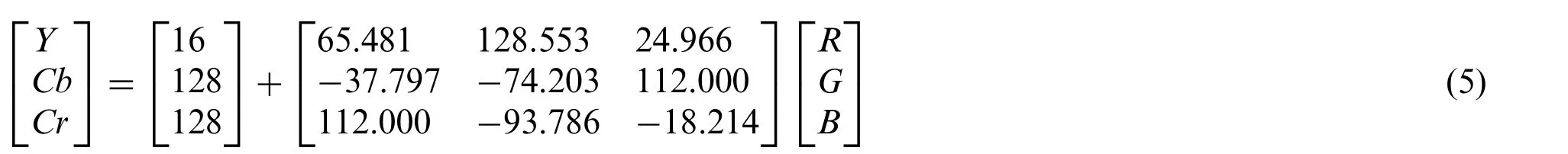
The two chrominance channels are separated,and the number of rectangular contextual tiles into which the image is split is determined for each chrominance channel.The best value for this is determined via experimentation.The contrast transform function is built based on a uniform distribution.

Assumingic_minis minimum allowed intensity,ic_maxstands for maximum allowed intensity and optimal clipping limit is fixed and ifFk(ic_in)represents cumulative distribution function for inputsic_in.,then Eq.(6)mathematically depicts modified chrominance with uniform distributions.Inferences of pre-processing methods for forgery detection are discussed in Table 1.

Table 1:Inferences of preprocessing methods
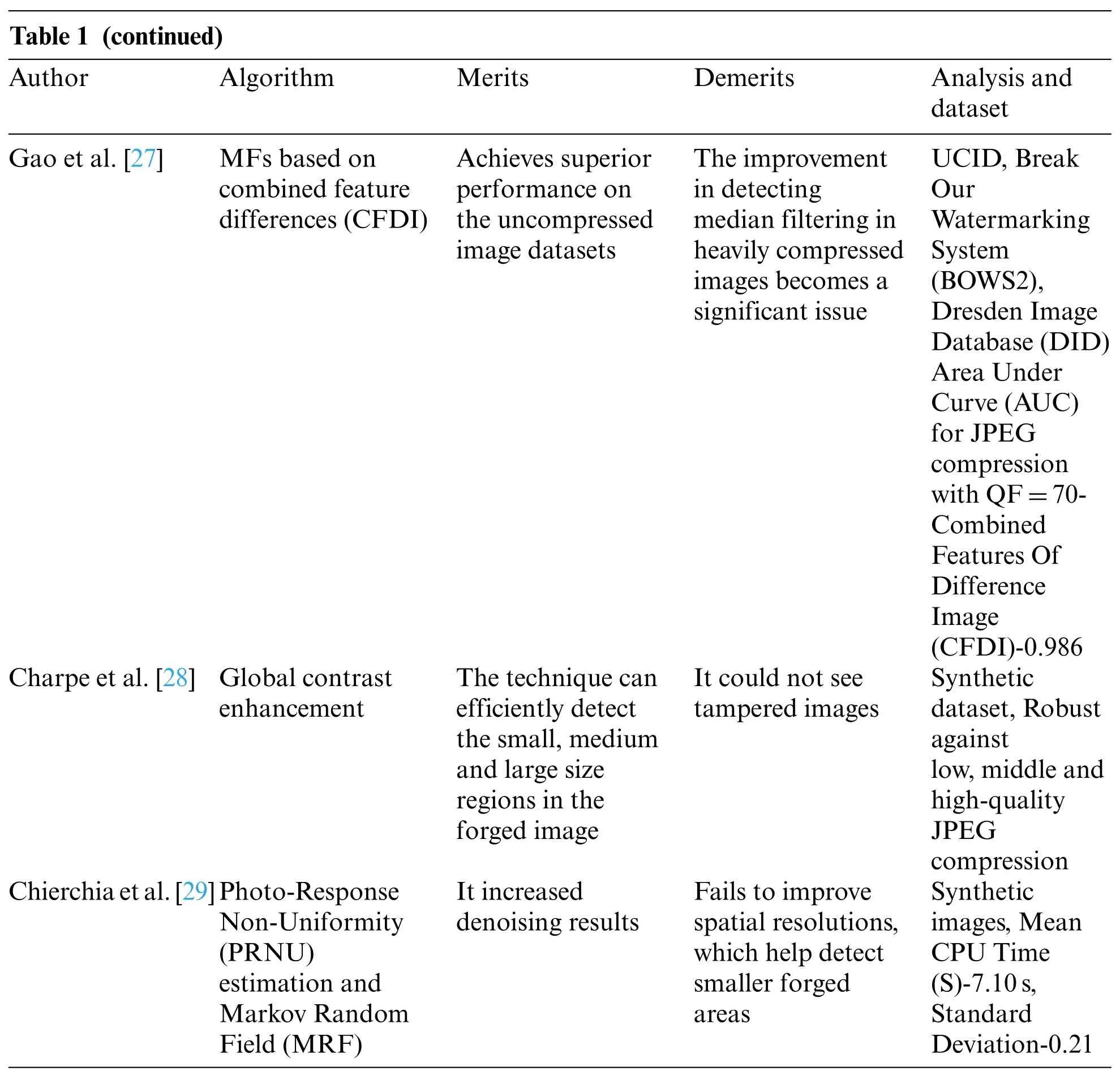
Note: The introduced method uses local CEs for highlighting minute image details and a parameter for controlling enhancements along with CLAHEs.This usage of LCMs(Local Contrast Modifications)with CLAHEs produced optimal CEs as more local image information was visible compared to normal CLAHEs.
As a result of the preceding,a variety of techniques to improve detection performance have been developed.The only difference between the following works is the characteristics utilized in the forgery detection method.Here,three main categories are introduced to categories these algorithms:Techniques based on space,transforms,and hybrid techniques[13](see Fig.3).
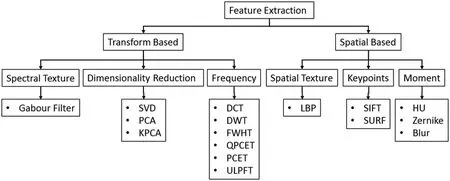
Figure 3:Classifications of feature extraction methods for copy-move forgery detection techniques
2.1.1 Spatial Domain Methods
The pixel location directly describes the content of a picture in a spatial feature space,where the energy is distributed evenly,and nearby pixels are highly associated.As a result,the matching procedure is highly computationally intensive.In spatial feature spaces,copy-moves can be based on moments or intensities or key points or textures.
Moment-based methods: Copy-move DIFDs can be assessed using Hue,blur invariance and Zernike moments.Liu et al.[38]detected duplicate locations in forged images by rotating the photos using circle block and Hu moments in their scheme.Their proposed method worked well against notions with noises,blurs,JPEG compressions and rotations.
Ryu et al.[39]proposed copy-move DIFDs detections using Zernike moments to locate duplicated areas.The presented approach detected forged areas amidst rotations as Zernike moment amplitudes show invariance in rotations.The proposed method is also resistant to deliberate distortions,including blurs,JPEG compressions,and the addition of white Gaussian noises.Their experiments showed that their technique was effective in identifying the faked region in copy-rotate-move forging.
Ryu et al.[40]suggested a forensic approach using Zernike moments of tiny picture blocks to locate duplicated image areas.To dependably reveal repeated measurements following arbitrary rotations,use rotation invariance characteristics.The block matching process is based on locality-sensitive hashing.It reduces false positives by looking at the phase of the moments,by using signal properties and differentiating between“textured”and“smooth”duplicated areas.The proposed approach beats prior art,especially when the repeated measurements are smooth.Experiments show that the system is resistant to JPEG compressions,blurs,additive white Gaussian noises,and modest scaling.
Singh et al.[41] proposed the No-Reference Image Quality Assessment (NR-IQA) technique,which employs simple spatial filtering operations and is computationally efficient.Laws’filters,which are effective in texture analysis,are used to calculate the features.A primary Generalized Regression Neural Network is used to predict the picture quality score(GRNN).Because of its low computational complexity,the proposed technique could be used in real-time applications.The proposed method produced good results amidst distortions with reduced computational cost when compared to most existing methods.
Intensity-based methods:Images were divided into distinct sub-blocks for computing their energies using various intensity-based copy-move DIFDs [42].These techniques support both color and grayscale pictures.However,all of these methods anticipated that the duplicated areas would not be subjected to post-processing,including scaling or rotations or JPEG compressions.The features mentioned above’rotation invariant characteristic has also been proved in a recent study[42].Bravo-Solorio et al.[5,43] suggested methods for detecting reflections and rotation invariance in copymoves.Pixel’s Log polar transforms from overlapping picture blocks were used to determine the characteristics.
Key point-based methods: These techniques use high entropy areas to focus the entire picture.Das et al.[44]proposed a fast and robust detection method for this type of picture fraud.The image is first turned to grayscale.The grayscale picture is then divided into four parts using two-level SWTs(Stationary Wavelet Transforms).The key points were extracted by approximating components of a decomposed image using SIFTs.The matching pairs of key-points are then discovered.Then,using a variety of linking techniques,matching pairs of key-points are grouped.
SIFTs and reduced LBPs based histograms were used in Park et al.[45]method.The 256-level LBP values collected from local windows centered on key-points were then minimized.A 138-dimensional is created for each key point to detect copy-move fraud.While comparing the detection accuracy of the proposed algorithm with current techniques on many image datasets,findings showed that their proposed method outperformed other copy-move DIFDs in evaluations.Their scheme also exhibited uniform detections on a multitude of test datasets.
For feature extractions,Amerini et al.[46] proposed SIFTs that determined whether a copymove attack has happened and retrieved the geometric transformation utilized for cloning.Extensive experimental data shows that the approach can accurately identify the changed region and estimate the geometric transformation parameters with high accuracy.This approach also handles multiple cloning.
Texture-based methods:The human visual system primarily interprets images through texture,divided into spatial texture and spectral texture properties.The pixel statistics are used to derive texture characteristics in the spatial domain.They may be computed from any data and are usually noise sensitive.
Li et al.[47]exploited textural characteristics using LBPs to manage geometrical changes.Images were low-pass filtered and subsequently divided into overlapped circular blocks,and finally,uniform rotation invariance LBPs were employed for extracting features in the pre-processing stage.The study was resistant to rotations,flips,noises,JPEG compressions,and blurs.
By collecting LBPs based Histogram Fourier Features of blocks,Soni et al.[48] detected copymoves by proposing block-based blind DIFDs.The proposed approach is evaluated using the CoMoFoD dataset as a benchmark.Experiments indicate that the proposed technique decreases the time complexity of tamper detections and shows resistance to post-processing assaults such as blurs,brightness alterations,and contrast adjustments.
Kalsi et al.[49]proposed the Approximation Image Local Binary Pattern(AILBP)technique for feature extraction.A typical solitary picture is used to start the number of trials.The experiments show that the proposed system can provide exemplary performance in terms of speed and accuracy.Darmet et al.[50]proposed a method to disentangle source and target areas in copy-move based on local statistical model of image patches.Zhang et al.[51]proposed an end-to-end deep learning model for robust smooth filtering to identify multiple filtering operations simultaneously.
Yang et al.[52]proposed LBPs for rotation invariance in their DIFDs for detecting copy-moves.The study initially filtered and divided images into constant sized chunks that overlapped.LBPs then extracted image characteristics from blocks and stored them as sorted feature vectors.Euclidean distance computations between blocks found block pairs.The study’s shift-vector counter C identified tampered areas,thus demonstrating their DIFDs even on multiple copy-moves while resisting JPEG compressions,noises,blur rotations,and flips.
Adding an LBP histogram-based descriptor to the CMFD technique improves it[45].LBPs for pixels centered on in 16×16 window key points were computed.The histogram of the 256 LBP levels is utilized as a new descriptor,and the histogram is decreased to 10 levels.A reduced LBPs histogram was used as additional descriptors to enhance key point pair matches.
LBPs are generic ways to extract textures from images.Their computations are simple with a higher level of discrimination.LBPs for pixels located at(p,q)can be computed using Eq.(7),

where L(p,q)-centre pixel’s LBP with(p,q)as its location and Inis the intensity of neighboring pixel and I(p,q)represents the intensity of pixel located at(p,q),and N represents neighboring pixel count within a defined radius.Eight-bit LBPs are obtained by using a local window centred at (p,q)) and defined as s(x)in s(x)(8),

AssumingΩ(xi,yi)represents pixels within (16×16) local window centred withkias t6he key point located at(xi,yi).LBPs are computed for all pixels at(p,q)∈Ω(xi,yi),LBP.
Features obtained using SIFTs carry information suitable for CMF detections.Hence,using complete LBPs may not be required.LBPs with a maximum of two transitions in 0→1 or 1→0 are categorized as uniform patterns(characterized by consecutive 1’s)where 00110000 is an example.01010100 six transitions or is a non-uniform pattern.Amongst 256 LBPs,only 58 were found to be uniform.Assuming Lc(p,q) (c=0,1,2,...,8) are LBPs with c consecutive 1’s,then L0(p,q)=00000000,and L8(p,q)=11111111.For c=1,2,...,7,Lc(p,q)can have 8 binary patterns or view as rotational shifts of the single pattern.Lnon(p,q)are patterns without consecutive 1’s except for L0(p,q).256 level LBPs can be divided into 10 groups where Lc(p,q)total nine and Lnon(p,q).
This work usesLc(p,q),Lnon(p,q)probabilities as CMFD descriptors.Further,the descriptor’s rotation invariance is maintained by checkingLc(p,q)the occurrences.Values fromLnon(p,q)might reflect variations occurring due to noises or modified backgrounds or errors in quantization within small windows.Non-uniform patterns are checked for reducing these effects of variations.A descriptorriwith its corresponding keypointkiis depicted in Eq.(9),

whereRc(xi,yi)andRnon(xi,yi)are the normalized number of occurrences ofLc(p,q)andLnon(p,q),respectively,inΩ(xi,yi).Rc(xi,yi)is calculated by Eq.(10),
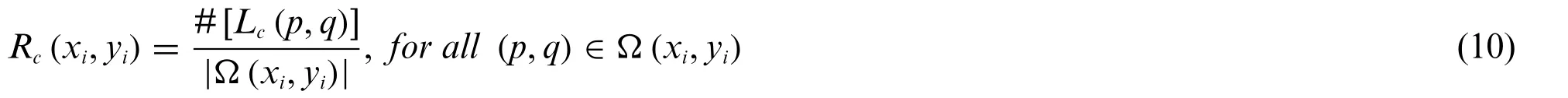
where #[Lc(p,q)] representsLc(p,q)pattern counts or cardinality inΩ(xi,yi)and Rnon(xi,yi) can also be found similarly.riis a ten-dimensional feature vector encompassingLc(p,q)andLnon(p,q)Histograms.
Eq.(11)is used to get the SIFT based key point descriptor and to obtain a histogram of reduced LBPs,

wheregirepresents CMFD’s descriptor with 138-dimensional features asriin contrast tofiis computed from larger areas and can robustly handle minute pixel changes and errors in quantization caused by compressions.
2.1.2 Transformation Based Approaches
Coefficients have lower correlations when transformed,and only a few coefficients have most of the energy.Hence,only these coefficients are used as features for overlapping blocks.Transformations can be in three forms,namely Frequencies,textures and reduced dimensions.
Frequency-based transformations:DIs were validated based on pixels by Parveen et al.[53] in their proposed DIFDs for copy–moves.Their study used five significant steps:(1)color images were converted to grey-scale images,(2)the converted images were then split into 8×8 overlapping blocks,(3)DCTs were used for extracting features based on feature sets,(4)the blocks were clustered by Kmeans clustering(5)features were matched using radix sorts.Their experimental evaluations showed that the scheme accurately detected forged areas in DIs.
Alahmadi et al.[54] suggested passive DIFDs based on LBPs and DCTs.First,discriminative localized features are extracted from the chrominance component of the input picture using 2D-DCTs.Detections were then carried out using a support vector machine.Experiments on three picture forgery benchmark datasets showed that their approach outperformed recently developed methods with better detection accuracies.
Hayat et al.[55]proposed DIFDs based on feature reductions using the DWTs and DCTs.After splitting the DWT images into separate blocks,the DCT is applied.The correlation coefficients are then used to compare the blocks.A mask-based tampering mechanism is also created as part of the studies to verify the detection approach.When compared to two other systems in the literature,the method yields intriguing findings.
Jwaid et al.[56] used DWTs and PCAs to do productive calculations in light of LBPs.Preprocess the image to convert it from RGBs to YCbCrs(Yellow,Green,and Blue).Second,the picture is compressed using the Discrete Wavelet Transform.The guess sub-picture comprises areas with low recurrence and the most severe data.Covering squares divide the LLs(Low Levels)sub-images.LBPs and PCAs matched chunks as part of the feature matching process.The final stage used SVMs(Support Vector Machines)to classify fakes.
Thajeel et al.[57]created novel stage-wise CMFDs based on QPCETs(Quaternion Polar Complex Exponential Transforms).The suspicious image is split into blocks that overlap.Second,QPCET is used to extract invariant characteristics for each block.Finally,k-dimensional tree (kd-tree) block matching is used to find duplicated picture blocks.Finally,a novel approach is proposed to decrease false matches caused by flat regions.Experimental results demonstrated the proposed approach’s exact and efficient recognition capability of copy-moves on rotated,scaled,noises added,blurred,brightened,colors reduced,and JPEG compressed images.Furthermore,the proposed technique solves false matches and outperforms other methods in terms of accuracy and false-positive rate.The technique shown here might be used to conduct accurate digital image forensic investigations.
PCETs(Polar Complex Exponential Transforms)were suggested by Wo et al.[58]to detect copymoves.The study extracted rotationally invariant and multi-scale features with PCETs which used multi-radii with graphic processing unit accelerations.For achieving coarse matches,lexicographical order matches optimized with minimum heap were used.The radius ratio and location information were applied to detect changes accurately.The proposed PCETs noticed forged sections created by rotations or scaling while resisting smoothing,JPEG compressions,and noise degradations.
Soni et al.[59] proposed an efficient block-based copy-move DIFDs based on FWHTs (Fast Walsh Hadamard Transforms)to reduce processing time in finding duplicated portions in a picture.Lexicographical sorting and an effective shift-vector technique are used to detect forged areas.
Park et al.[60]proposed a ULPFTs(Up sampled Log-Polar Fourier Transforms)based descriptors resistant to rotation,scaling,sheering,and reflection,among other geometric changes.The theoretical foundations of the ULPFT representation are first presented.Then,from the ULPF representation,a feature extraction technique is shown that can extract scale-invariant features and rotations.Analyzed common CMFDs (Copy-Move Forgery Detections) processing pipeline and modified a section to handle various forms of tampering assaults more effectively.Simulation findings show that the introduced feature descriptor outperforms other descriptors with established performance guarantees.Another benefit of ULPFT is that it has low computational complexity.
A new approach for CMFD of duplicated items was given by Hosny et al.[61].The bounding rectangle is designed around the identified item to create a sub-image.The morphological operator is used to get rid of the tiny things that are not needed.For the identified objects,exact PECT moments were employed as characteristics and items were compared using Euclidian distances and correlations between feature vectors.
Emam et al.[62]used PCETs to extract block’s invariant characteristics,resulting in PCETs based kernels representing blocks.Second,probable comparable blocks were discovered using LSH(Locality Sensitive Hashing)and Approximate Nearest Neighbor searches.Morphological techniques are used to eliminate the incorrectly similar blocks,making the method more resilient.The presented approach is resilient to geometric changes with minimal computing complexity,according to experimental data.
Zhu et al.[63] proposed using Gaussian scales and extracting key-points quickly using ORB features in scales.Subsequently,the input image coordinates of FAST key points were reverted,and hamming distances matched obtained ORB features between key-points pairs.In its final part,the scheme eliminated falsely matched key points using RANSACs(Random Sample Consensus).Their experimentations showed that their approach was effective in detecting geometric transformations,including rotations and scaling.Further,their system was robust to see forgeries even in Gaussian blurred,or Gaussian white noised or JPEG recompressed images with high accuracy.
Dimensionality reduction-based methods: Chihaoui et al.[64] suggested automatically detecting duplicated areas in the same picture where SIFTs identified local properties of the photographs(sites of interest),and SVDs matched identical features.The findings demonstrate that the proposed hybrid approach is resistant to geometrical changes and can detect duplicated areas accurately.
SWTs(Stationary Wavelet Transforms)was proposed by Dixit et al.[65]to detect copy-moves due to shifting invariance of SWTs,which assist in similarity detections(matches)and dissimilar detections(noises) due to blurs in image blocks.The study used SVDs (Singular Value Decompositions) for deriving image features represented in image blocks.Additionally,the color-based segmentation technique employed in this study aids in achieving blur invariance.Their experimental findings showed the suggested technique’s effectiveness in detecting copy-moves of images using intelligent edge blurring while outperforming most other methods in the accuracy of detections.
To describe and detect duplicated blocks in a picture,Hilal et al.[66] proposed an approach that used PCAs and DCTs.The algorithm is optimized and tested on a database of forged images.The algorithm’s flexibility and performance are demonstrated by comparing the obtained results to a reference technique.
Sunil et al.[67] also proposed using DCTs and PCAs to compress overlapping block feature vectors.The down-sampling of low-frequency DCT coefficients creates features that are invariant to local changes in intensity.
Images are initially split into overlapping square blocks by Mahmood et al.[68],then DCT components were for block representations.Gaussian RBF kernel PCAs reduced the dimensionality of the feature vectors,thus improving feature matching efficiency.Extensive tests were carried out to compare the proposed approach with other approaches.Experimental findings show that the proposed method accurately estimated CMFDs even when pictures were polluted using blurs or noises or compressions and could identify numerous CMFDs.As a result,the proposed methodology was computationally efficient and reliable for copy-move DIFDs and enhanced the trust of evidencebased applications.However,compared to linear PCAs,both KPCAs and SVDs were computationally inefficient.In contrast,methods described above effectively expressed 2nd order data,forgeries based on altering high-order statistics,complex to detect.
Several authors have used PCETs,and as a result,PHTs (Polar harmonic transforms) are a type of complex exponential transforms [6–71].It is a signal representation technique that uses a superposition.Harmonics to represent a signal[72–74].PCETs are beneficial tools for characterizing images.
In polar co-ordinates (r,θ),the function Hnm(r,θ),includes radial basis function Rn(r) and angular function exp(jmθ)by Eq.(12),

whereRn(r)=exp(j2nπr2),n,m=-∞,···,0,···,+∞,0 ≤r ≤1,0 ≤θ≤2π.Rn(r)is orthogonal in a unit circle,as in Eq.(13),

whereδnn′is the Kronecker delta andR*n′(r)is the conjugate ofRn′(r).The function set Hnm(r,θ)is orthogonal in the unit circle as in Eq.(14),

whereπis the normalization factor;δnm,δn′m′are Kronecker deltas;andH*n′m′(r,θ) denotes the conjugate ofHn′m′(r,θ).n order PCETs with repetition m are as per Eq.(15),
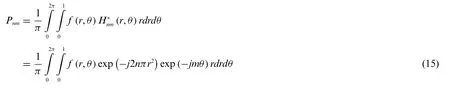
Based on the theory of complete orthogonal function sets,images can be reconstructed by PCET coefficient’s infinite orders(|n|≤nmax,|m|≤mmax).
2.1.3 Hybrid Methods
Many new approaches based on merged methods have recently been introduced to improve the performances of copy-moves in images.Yang et al.[75] proposed KAZE,a robust interest point detector that may be used in conjunction with SIFTs to extract additional feature points where enhanced matches are employed to deal with numerous duplications,and n-best matches in features can be discovered.Then,to eliminate false conflicts,a practical filtering step based on picture segmentation is performed.Furthermore,an iterative approach for estimating transformation matrices and determining the presence of forgeries is devised.The duplicated areas may be found at pix using these matrices.According to experimental results,the presented approach accurately detected duplicate areas even after distortions,including rotations,JPEG compressions,noise additions,and scaling.
Lin et al.[76] proposed a hybrid feature and evaluation clustering-based region duplication detection technique.The proposed system is broken down into two stages:rough matching and precise matching.Rough matching begins with the extraction of hybrid key points from the input picture,then is characterized by unified descriptors.Second,the Neural Network(NN)approach matches those key points.Third,the introduced clustering based on evaluation groups those matching key points.Fourth,affine transformations between these groups are approximated,and Bag of Word(BoW)is utilized to filter inaccurate affine transformations to enhance pixel-level results.When no affine transformation can be found,each suspicious region is addressed independently in precise matching.Under various situations,their suggested approach outperformed most other methods.
CMFDs were proposed by Tinnathi et al.[77] based on both block and key point techniques.Adaptive watershed segmentation is utilized to split the forged picture into non-overlapping segments,and adaptive H-minima transform retrieves the markers.In addition,a AGSOs (Adaptive Galactic Swarm Optimizations) to find the best gap value when picking the tags can improve segmentation performance by eliminating unwanted regional minima.After that,using HWHTs (Hybrid Wavelet Hadamard Transforms),the features from each segment are retrieved.Adaptive thresholding was then used to accomplish feature matches.RANSAC’s(Random Sample Consensus)eliminated false matches or outliers.Finally,the FREA (Forgery Region Extraction Algorithm) was used to detect the duplicated region from the host picture.The presented technique successfully detects the picture forgery region,according to the results of the experiments.
Sunitha et al.[78]proposed CMFDs using key-points,combined feature extractions,and hierarchical clustering to identify forgeries.According to their experimental results,their suggested DIFDs achieved considerably higher performances when compared to other methods,according to their experimental results.
A machine learning classification approach was presented by Jaiswal et al.[3].Spliced and nonspliced pictures were divided into two categories using logistic regression.For this,a feature vector was created using a mixture of four handmade features taken from photos.Then,using a logistic regression classification model,these feature vectors are trained.The outcome was evaluated using a ten-fold cross-validation test assessment technique.Finally,the study’s comparisons of their suggested approach with other methods on three publicly available datasets discovered that the acquired findings outperformed other techniques.
FMTs(Fourier-Mellin Transforms)along with SIFTs were used by Meena et al.[4]in their hybrid approach for DIFDs.The study separated smooth and rough parts of images followed by key point’s extractions from image textures using SIFTs.FMTs were applied on softer image parts for extracting their features which were then compared for detecting forgeries.Their scheme outperformed CMFD algorithms when tested with post-processing procedures and geometric transformations within an acceptable amount of time.In Table 2,the inferences of feature extraction approaches for forgery detection are well described.
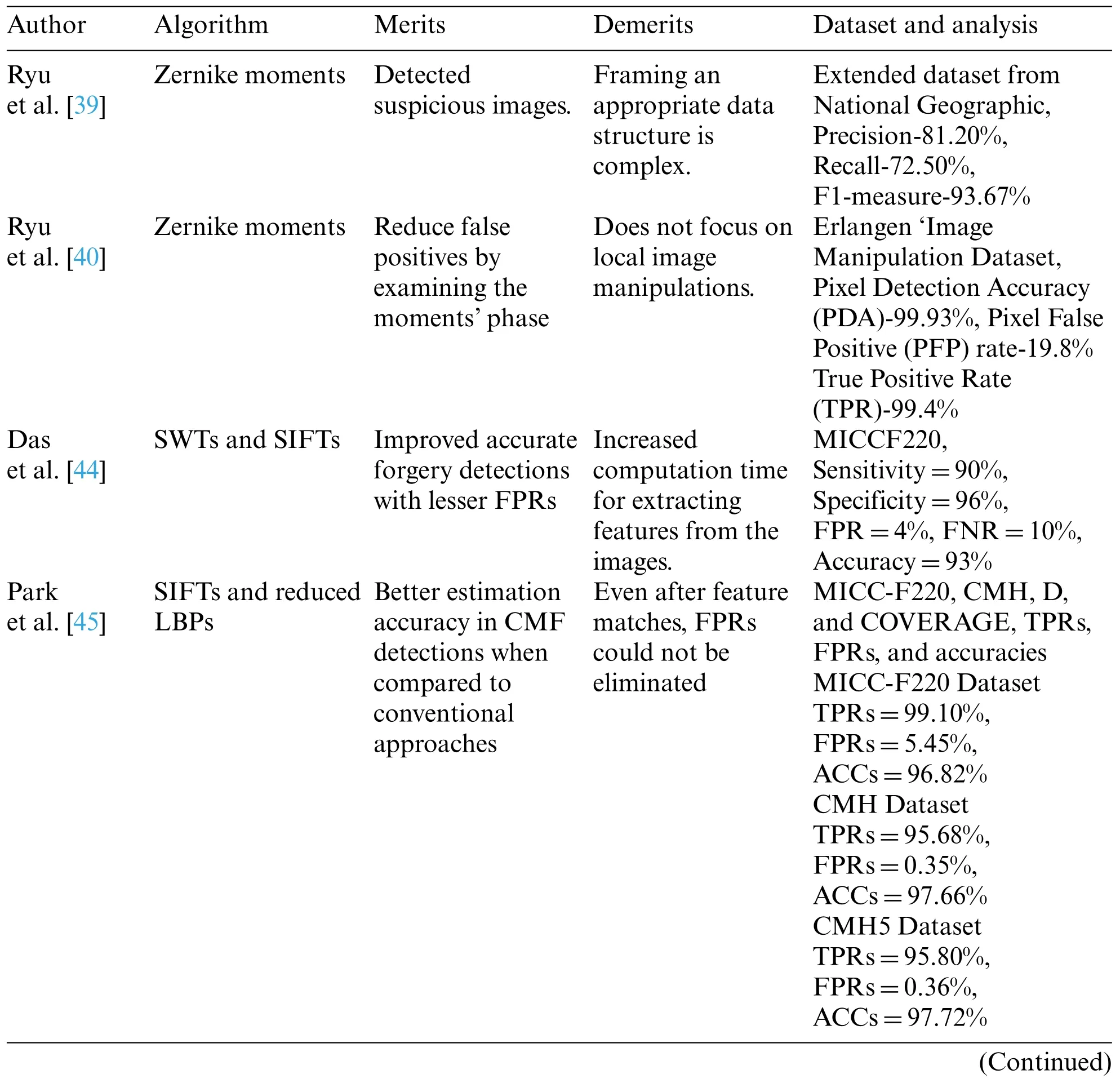
Table 2:Inferences of feature extraction methods
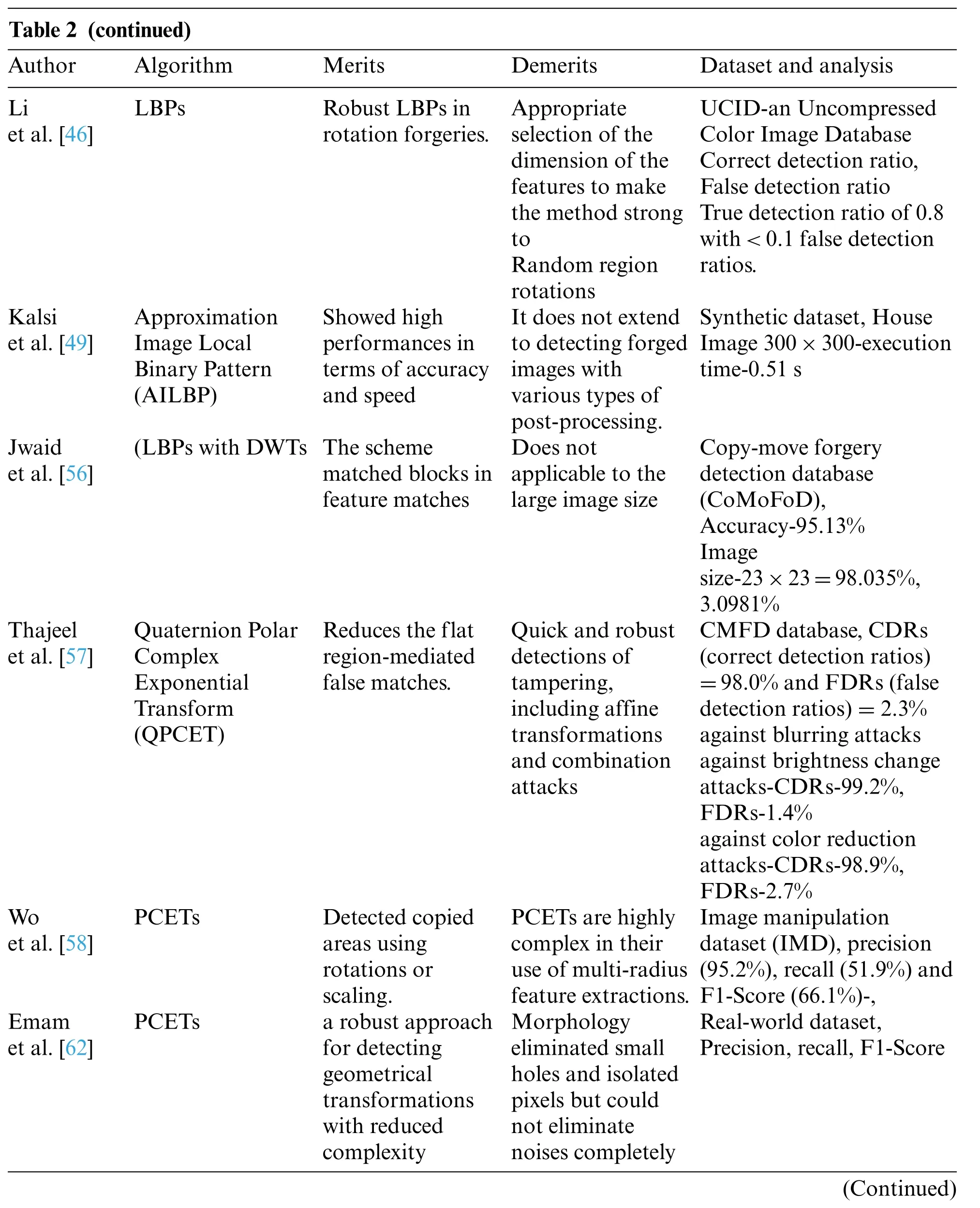
Table 2 (continued)Author Algorithm Merits Demerits Dataset and analysis Li et al.[46]UCID-an Uncompressed Color Image Database Correct detection ratio,False detection ratio True detection ratio of 0.8 with <0.1 false detection ratios.Kalsi et al.[49]LBPs Robust LBPs in rotation forgeries.Approximation Image Local Binary Pattern(AILBP)Showed high performances in terms of accuracy and speed Appropriate selection of the dimension of the features to make the method strong to Random region rotations It does not extend to detecting forged images with various types of post-processing.Synthetic dataset,House Image 300×300-execution time-0.51 s Copy-move forgery detection database(CoMoFoD),Accuracy-95.13%Image size-23×23=98.035%,3.0981%Thajeel et al.[57]Jwaid et al.[56](LBPs with DWTs The scheme matched blocks in feature matches Does not applicable to the large image size CMFD database,CDRs(correct detection ratios)=98.0%and FDRs(false detection ratios)=2.3%against blurring attacks against brightness change attacks-CDRs-99.2%,FDRs-1.4%against color reduction attacks-CDRs-98.9%,FDRs-2.7%Wo et al.[58]Quaternion Polar Complex Exponential Transform(QPCET)Reduces the flat region-mediated false matches.Quick and robust detections of tampering,including affine transformations and combination attacks Image manipulation dataset(IMD),precision(95.2%),recall(51.9%)and F1-Score(66.1%)-,Emam et al.[62]PCETs Detected copied areas using rotations or scaling.PCETs a robust approach for detecting geometrical transformations with reduced complexity PCETs are highly complex in their use of multi-radius feature extractions.Morphology eliminated small holes and isolated pixels but could not eliminate noises completely Real-world dataset,Precision,recall,F1-Score(Continued)

Table 2 (continued)Author Algorithm Merits Demerits Dataset and analysis Tinnathi et al.[77]MICC-F600 dataset,and Bench mark dataset It illustrates AGSOs ability to identify forged images with Precision=95.31%;Recall=96.89%and F1=95.28%on MICC-F600 Precision=99.08%;Recall=98.42%and F1=98.33%on Bench mark dataset under plain copy move at image level Sunitha et al.[78]Hybrid Wavelet Hadamard Transform(HWHT)Copied areas are detected in images and minimize computational complexities Hybrid feature extractions using SURFs-detections and SIFTs-descriptors.Efficient key-point based CMFD(EKP-CMFD)Image forged regions were affected by attacks&geometrical transformations Efficient mismatch elimination and image transformation Meena et al.[4]FMTs and key point-based techniques using SIFTs Forged regions were indicated using lines without explicit demarcations of boundaries MICC-F220 dataset EKPCMFD-Recall-92.50%,FPR-8.90%,F1-Score-91.70%Detect the duplicated regions of the image Feature extraction with more computation time Image Manipulation Dataset(IMD),GRIP dataset,Precision,Recall,F-measure Rotation attack Precision=93.88%,recall=95.83%and F-measure=94.85%Scaling attack Precision=94.00%,recall=97.92%and F-measure=95.92%JPEG compression Precision=94.12%,recall=100%and F-measure=96.97%Additive noise Precision=91.67%,recall=68.75%and F-measure=78.57%
2.2 Review of Classification and Deep Learning Methods
The job of detecting picture fraud among legitimate and counterfeit photos is a binary classification example[79–83].This part will go through the specifics of detecting forgeries using conventional matching and deep learning approaches.
Cozzolino et al.[84] suggested CMFDs and localization based on dense nearest-neighbor field computations in a short amount of time.The study’s Patch Match was a recursive randomized method for nearest-neighbor search that uses image regularities to converge to a near-optimal and smooth field swiftly is utilized to do.Modify the fundamental algorithm to make it more resistant to rotations while maintaining its computational efficiency.Experiments demonstrate that the presented approach outperforms all evaluated reference procedures in terms of accuracy and speed nearly equally.
Copy–moves were detected in DIs by Bi et al.[85] with their proposed MLDDs (Multi-Level Dense Descriptors)based on Hierarchical Feature Matches.The study’s descriptors(Color Textures and Invariant Moments) were extracted at several levels with MLDDs.Their Hierarchical Feature Matched identified forged areas in DIs after computing MLDDs for pixels.The pixels with comparable color textures were sorted into different neighbor pixel groups and geometric invariant moments of pixels identified a pixel’s corresponding neighbors.Subsequently,Adaptive Distances and Orientations are used for Filtering superfluous pixels based on generated/matched pixel pairs.The study used morphology for their final outputs,where forged areas were identified.Their experiments demonstrated the scheme’s sturdiness even under demanding conditions,including geometric transformations,JPEG compressions,noise additions,and down sampling compared to other CMFDs.
Key points identified forged smooth areas in DIs by Wang et al.[86] in their scheme based on CMFDs.Their scheme divided tampered DIs into non-overlapping/irregular super pixels before categorizing super pixels from smoothened,normal textured and strongly textured backgrounds based on local information entropies.Subsequently,adaptive feature point detectors extracted DIs key points from super pixels belonging to different textures and generated local visual characteristics (moment magnitudes)for these super pixel key points.A reversed generalized dual Nearest Neighbor Algorithm discovered key point’s matches quickly.In the final stage,erroneous key-points were eliminated by random sample consensus and forged areas were normalized using zero-mean normalized crosscorrelations.The scheme showed its superiority compared to other CMFDs in detecting copy-moves in DIs generated with geometric transformations,JPEG compressions,and additive white Gaussian noises.
Bi et al.[87] segmented host images into irregular but non-overlapping patches using multiple scales.The study used SIFTs to extract multi-scale feature points from these patches.Subsequently,APMs(Adaptive Patch Matches)identified suspicious/forged areas for the used scales.Matched Key points were merged,and suspect regions of multiple scales were combined in the final stage to identify forgeries.Their experimental evaluations outperformed other CMFDs in DIFDs on images forged with geometric transformations,JPEG compressions,and specific noise additions,including multiple copies and down sampling.
Li et al.[88] developed a quick and efficient CMFD method using hierarchical feature point matches.First,prove that reducing contrast thresholds and image rescales required key-points even in tiny or smoothened areas.Then,to handle more key point counts in matches,a unique hierarchical matching technique was devised.Unique iterative localizations decreased false alarm rates and precisely located tampered regions with the assistance of key-points’resilient features,including leading orientations,size information,and color information.Extensive experimental data are presented to illustrate the suggested scheme’s improved performance in terms of efficiency and accuracy.
Wang et al.[89] proposed color invariance as the base for their DIFDs where SIFER (Scale-Invariant Feature Detector with Error Resilience)and FQRHFMs(Fast Quaternion Radial Harmonic Fourier Moments) were used for detecting copy-moves.Their scheme derived adaptively stable key points from super pixels by integrating block contents with SIFER color invariance after segmenting DIs into non-overlapping uniform super pixel blocks.The extracted key-points and local image features were used to build Delaunay triangles using FQRHFMs and gradient entropies.The proposal matched Delaunay triangles using CSHs (Coherency Sensitive Hashing) followed by DLFs (Dense Linear Fittings).Errors in Delaunay triangle matches were eliminated by localizing forged areas using ZNCCs(Zero Mean Normalized Cross-Correlations).The study’s extensive tests assessed the scheme’s efficacy in copy-move forgeries with positive finds.
Copy-moves were also detected by Yang et al.[90] in their study using multi granular super pixel matches.Their approach combined key point and block-based features for their DIFDs.The scheme extracted stable key-points in DIs from coarse granular super pixels after dividing DIs into non-overlapping/irregular coarse granular super pixel-based blocks.Each of these extracted super pixel’s features was considered quaternion exponent moment magnitudes and used for rough granular super pixel matches where E2LSHs(Exact Euclidean Locality Sensitive Hashing algorithms)quickly identified forged areas.In the final step,finely granulated super pixels were separated and replaced by their key point matches followed by morphological operations on delicate granular super pixel neighboring areas,which were then combined to yield the identified forgery areas.When tested on publicly available online datasets,extensive experimental findings showed that the presented method performs well under a range of demanding situations compared to other techniques.
Liu et al.[91]proposed a new Key point and Patch Match-based CMFDs.To obtain trustworthy key-points,LIOPs(Local Intensity Order Patterned),robust key point descriptors was coupled with SIFTs.After matching the collected key points using g2NN,the redundancy matched key point pairs were eliminated using matched key point pair descriptions and filters based on density grids.Finally,an improved method for matching patches was used to evaluate key-point pair matches to detect forgeries properly.According to their experimental results,their presented technique accurately saw copy-moves in images better than existing methods and performed well even on deformed images processed by rotations,JPEG compressions,and noise additions and scaling.
Elhaminia et al.[92] proposed treating CMFDs as MRFs in labelling.Pre-processing included over segmentations to create super pixels which were treated markov network nodes for balancing precision and speed.The maximal a posteriori labelling can accurately map the forged areas while selecting unary and binary potentials intelligently.According to qualitative and quantitative comparisons with other methods utilizing public benchmarks,the presented technique can enhance accuracy while keeping processing demands low.
Cozzolino et al.[93] detected copy-moves accurately using rotational invariance,where these characteristics were computed based on localizations.The study’s Patch Match was a dense-field approach that showed better performances when compared to key point approaches but took longer execution time in feature matches.The study computed dense fields in DIs and handled invariant characteristics more effectively,increasing resilience against rotation or scaling.Furthermore,based on the output field’s smoothness,a dependable and straightforward post-processing technique was devised.According to their experimental research on available online datasets,their approach was accurate with greater resilience and quicker than most dense field references.
Ouyang et al.[94] proposed CNN based CMFDs.The proposed technique takes an already trained model from an extensive database,such as ImageNet,and tweaks the net structure significantly with tiny training examples.Experiments demonstrate that the proposed approach produced good counterfeit images automatically using simple image copy-moves using computers.
Liu et al.[95]proposed that CMFD be performed using CKNs(Convolution Kernel Networks).CKNs are deep convolution architectures based on data-driven local descriptors.Because of its high discriminative capabilities,it can produce competitive results.Three essential modifications are made to better adapt to the situation of CMFD:First and foremost,CKN has been rebuilt for use with a Graphical Processing Unit (GPU).The GPU-based reconstruction achieves excellent efficiency and allows hundreds of patch matching in CMFD to be applied.Second,to create homogenously dispersed key points,a segmentation-based key point distribution technique is presented.Finally,an adaptive over-segmentation approach is employed.Experiments on publically available datasets are carried out to verify the proposed method’s other performance.
Thakur et al.[96]concentrated on efficient splicing detection and CMFD pipeline design,which focuses on identifying the traces left by different Splicing and copy-move forgeries post-processing activities like JPEG compressions or noises or blurs or contrast adjustments.Their use of LFRs(Laplacian Filter Residuals)and SDMFRs(Second Difference of Median Filters)on images as one of the residuals were introduced jointly to suppress image content and focus solely on the traces of tampering activities.
Agarwal et al.[97] developed a deep learning-based approach for identifying the CMFD.The newly developed method uses the altered picture as the system’s first input for detecting the tampered region.Segmentation,feature extraction,dense depth reconstruction,and ultimately seeing the tampered areas are all part of this method.The newly developed deep learning-based method may reduce computing time and improve the accuracy of duplicated region detection.
BRISKs(Binary Robust Invariant Scalable Key points)were used as Yang et al.[98]descriptors in their study.Their approach used adaptive uniform threshold value distributions to extract key-points of local features from DIs.The study then used the embedded random ferns approach for formulating needed matches,thus achieving discriminative classifications.Their local descriptors based on BRISKs matched image key-points.The study also used RANSAC’s to eliminate erroneous key point pairs Normalized Intensity Correlations to detect tampers in DIs.Their experiments with other CMFDs showed their scheme’s enhanced detection and localization accuracies even under adverse image conditions.
DCNNs(Deep Convolution Neural Networks)were exploited by Kao et al.[99]for offline hand signature verifications.The study used novel local feature extractions using SigComp on ICDAR(Document Analysis and Recognitions)2011 dataset.Their training on the authenticity of signatures was used for testing unsaved fresh author’s signatures.
Feng et al.[100]proposed a CNN based picture forgery detection method to achieve image preprocessing for the Columbia University picture mosaic detection dataset.SRM and high-pass filtering are introduced initially instead of the standard feature of extracting related features based on image content.The CNN then completed the training and verification processing.On the classification findings,the impacts of pre-processing and the number of convolution layers are thoroughly compared.Experiments indicate that the CNN approach described in this paper is successful and resilient in classifying picture forgeries.
Agarwal et al.[101] compared different deep learning-based forgery detection approaches with strategies that do not utilize NN architecture for feature extraction.To identify these photos as factual or fabricated,developing an effective image forgery detection system is necessary.
Zhong et al.[102] proposed a Dense-Inception Net-based image CMFD method.Dense-InceptionNet,which are multi-dimensional DNNs (Deep Neural Networks) with dense feature connections.Their DNNs learnt feature correlations in training and used their learning to match forgeries.The use of PFEs (Pyramid Feature Extractors),FCMs (Feature Correlation Matches)and HPP (Hierarchical Post-Processing) modules were a part of their Dense-Inception Nets.PFEs extracted dense multi-dimensional/scale features where each layer was linked directly to previous layers.FCMs learnt strong correlations amongst features for producing candidate matches as maps.HPP in the final stage used these maps to generate cross entropies using training’s back propagations.Their experimental results showed that their Dense-Inception Net approach produced efficient DIFDs while proving to guard against most known assaults.
For Copy-Move Forgery Detection,Pun et al.[103] proposed a two-stage localization method CMFDs.SLIC(Simple Linear Iterative Clustering)divided images into meaningful patches in the first step,preliminary localization.The WLDs(Weber Local Descriptors)computed and extracted feature from each super pixel is then presented.The super pixel matches are then obtained using a matching threshold based on an experimental study.In the final step,weak super pixel’s Euclidean distances were used to generate suspect approximations.The study’s DAFMTs (Discrete Analytic Fourier–Mellin Transformations)extracted image characteristics at a blocking lever while localizations were given by sliding varying radii circular blocks in suspect areas.The study’s generated candidate circular blocks were matched by LSHs (Locality-Sensitive Hastings).Poor matches were filtered and eliminated in identified areas to obtain final identified regions,and geometric morphological techniques were used.The extensive experimental findings show that the proposed approach outperformed other CMFD methods on available benchmark databases.
Silva et al.[104] proposed a new method to CMFD based on a digital image’s multi-scale analysis and voting procedures.Extract interest points from a suspicious image resilient to scaling and rotation,then look for probable correspondences between them.Based on geometric restrictions,corresponding group points into regions.Following that,a multi-scale picture representation is built for each scale.The produced groups are examined using a highly resilient descriptor to rotation,scaling,and somewhat robust to compression,reducing the search space of duplicated regions yielding a detection map.The ultimate choice is made once all detection maps have been voted.Validate the approach using a variety of datasets that include both original and realistic picture cloning.Compare and contrast the proposed method with 15 others found in the literature and present promising findings.
Pun et al.[105] proposed an adaptive over-segmentation and feature point matching CMFD method.The proposed technique combined forgery detection methods based on blocks and keypoints.The study’s over segmentations adaptively divided DIs into non-overlapping/irregular blocks to extract feature points from blocks that were matched to identify labelled feature points,thus indicating forged areas in DIs.They replaced feature points in forged areas with tiny super pixels and combined neighboring blocks similar to feature blocks’local color characteristics,thus creating a merged region.As the last step,morphological operations identified forged regions from the merged regions.Their proposed scheme identified developed regions as very effective when compared to other DIFDs for copy-move detections.Their experimental results also showed that their copy-move forgery detection system produced considerably superior detection results under various demanding situations.
Li et al.[106]proposed a method for CMFD in images based on the extraction of key points.The study’s approach differed from prior approaches in dividing DIs as semantically independent blocks before key point extractions.Subsequently,these extracted patches were matched for identifying copymoves.The study’s matches used two steps where initially suspicious patch pairs included forged areas in the first step to estimate approximate affine transform matrices.EMs(Expectation-Maximizations)was used subsequently to refine the estimated matrices and establish their existence.Comparing the presented method to other strategies on public datasets,experimental findings showed that it performed well.
Bi et al.[107] proposed a new and fast reflecting offset-guided CMFD image searching technique.The features are retrieved,and feature correspondences are randomly allocated during the initialization step to get initial mapping offsets,while reflective offsets were computed in searches to obtain mapping offsets as copy-move forgery mapping offsets.Then copy-move forgery mapping offsets were disseminated to enhance mapping and reflective offsets based on priority feature matches.Finally,only a few iterations can completely detect the forgeries areas from the mapping offsets.According to experimental data,the presented approach for image copy-move DIFDs decreased computational complexities while providing higher detection results than other CMFD algorithms,even under challenging situations.
Bi et al.[108] proposed a method for detecting CMFDs for accuracy and resilience.To build feature correspondences in images,the study used an enhanced coherency sensitive hashing algorithm.A local bidirectional coherency error factor was used in iterations for improved accuracy and advanced feature correspondences.The iterative procedure ended when the local bidirectional coherency error fluctuations were less than a predefined threshold,suggesting that feature correspondences were stable.This error of each feature was used to recognize copy-moves from regular feature correspondences.Their experimental findings demonstrated that their proposed detection technique was successful in real-time/near real-time data and produced excellent detection results compared to other copy-move DIFDs even under challenging situations.
CNNs were used by Rao et al.[109]in their study for their CMFDs,where CNNs learnt RGB color image’s hierarchical representations from DIs.Their CNNs spliced images for detecting copy-moves.Instead of randomizing weights,the study network’s first layer was initialized by high-pass filter sets and residual maps computed for SRM(Spatial Rich Models).The model regularized DIs efficiently to suppress image effects and capture artefacts introduced in image tampers.The study’s pre-trained CNNs extracted dense features of DIs,followed by feature fusions to explore discriminative features for classifying using SVMs.The scheme’s experimental results on multiple datasets showed that their CNNs outperformed most other methods.
Fig.4 depicts the suggested CNNs’architecture,including 8 convolutions,2 pooling,and 1 fullyconnected layer with a bi-way softmax classifier.Patches of 128×128×3 (128×128 patch,3 color channels)make up the CNN’s input volume.The first and second convolution layers contain 30 kernels with a receptive field of 55,whereas the subsequent layers all have 16 kernels with a receptive field of 33.ReLUs(Rectified Linear Units)were applied to neurons for the activation function to preferentially react to relevant signals in the input using a size 22 filter,which resizes the input spatially and discards 75% of the activations.This is because the max-pooling process aids in the retention of additional texture data and improves convergence performance.Local response normalization is also used to the feature maps before the pooling layer to increase generalization,where the surrounding pixel values normalize the center value in each neighborhood.Finally,through“dropout,”which sets the neurons in the fully-connected layer to zero with a probability of 0.5,the recovered 400-D features (5516)are transferred to the fully-connected layer with a bi-way softmax classifier.This usage of the fullyconnected layer at the end was different from other traditional CNNs using 2 or more fully connected layers,leading to overfitting,especially in small training sets.

Figure 4:The architecture of the proposed 10-layer CNN
Wu et al.[110]also proposed end-to-end DNNs in DIFDs.The study’s CNNs extracted block features from DIs and computed self-correlations between blocks with extracted feature points matched to rebuild forged/masked areas using de-convolutions.In contrast to traditional approaches,which needed multiple training and parameter tuning steps followed by post-process spans,the proposed method eliminated multiple training/parameter adjustments.The study’s scheme was trainable as it combined forged mask reconstructions with loss optimizations.Their experimental results showed that their proposed scheme beat other traditional DIFDs based on their matching schemes and effectively against assaults,including affine transforms,JPEG compressions,and blurs.
Wu et al.[111]proposed BusterNet,a new DNNs for CMFD images.BusterNet is an accurate,end-to-end trainable DNNs system,unlike prior efforts.It has a two-branch design with a fusion module in the middle.The two branches,respectively,locate possible manipulation locations (by checking for visual artefacts) and copy-move regions (by evaluating visual similarities).This is the first CMFD algorithm that can identify source/target areas with discernibility to the best of our knowledge.Simple techniques for generating large-scale CMFD samples from out-of-domain datasets are shown,as well as stage-wise BusterNet training procedures.According to extensive tests,Buster-Net considerably beats other copy-move detection algorithms on the two publicly accessible datasets,CASIA and CoMo-FoD,and is resistant against other known assaults.However,it is preferable to take these features into account directly.Thus BusterNet is recommended as a two-branch DNN architecture.
Dashed blocks are only activated during branch training.Output mask of the main task,i.e.,MXcis colour coded to represent pixel classes,namely pristine(blue),source copy(green),and target copy(red).Output masks of auxiliary tasks,i.e.,MXmandare binary where white pixels indicate manipulated/similar pixels of interests,respectively.In dual branch DNN based CMFDs,dashed blocks are active only in training.The main outputs(MXc)are color codes representing pixel classes:pristine (blue),source copy (green),and target copy (red) where output’s masks of auxiliary tasks(MXmand MXs)are white pixels in binary representing manipulated/similar pixels.An input image X’s features are extracted using CNNs,and feature maps are scaled to original image sizes using Binary Classifier(Mask Decoder)to create manipulation masks.CNN Feature Extractor may be used with any CNN.Because of their simplicity,the first four blocks of the VGG16 design are employed here.The resultant CNN feature has a resolution of 1,616,512,significantly lower than that required by the modification mask.
Bunk et al.[112] detected altered imaging with two approaches based on a combination of deep learning and re-samples.The study’s Radon initially transformed re-sampled images computed from overlapped image patches converted to heat-map using deep learning classifiers and Gaussian conditional random field models.The approach used Random Walker segmentations to identify tampered areas in images.LSTMs(Long Short-Term Memories)used these overlapped images as inputs for localizations and classifications.Their experiment results demonstrated that both approaches successfully identified and localized forgeries in DIs in terms of detection/localization capabilities.
Qiao et al.[113] used a linear parametric model to examine the problem of picture resampling detection.First,reveal the one-dimensional 1-D resampled signal’s rare artefact.The detector is built based on the likelihood of residual noise recovered from the resampled signal using a linear parametric model after dealing with the nuisance parameters and Bayes’rule.After that,focus on the characteristics of a resampled image.Meanwhile,it calculates the likelihood of pixel noise and creates a realistic LRT(Likelihood Ratio Tests).Numerical studies indicate the significance of the presented technique in recognizing uncompressed/compressed resampled pictures compared to another testing.
Amerini et al.[114] proposed a novel CMFD and localization schema based on the J-Linkage method,achieving robust clustering in the geometric transformation space.Experiments on several datasets demonstrate that the proposed method surpasses other comparable strategies for CMFD reliability and accuracy in the modified patch localization.
Bayar et al.[19] proposed a new CNN-based technique for camera model identification that is resampling and recompression resistant.A new low-level feature extraction method is presented that employs both a restricted convolution layer and a nonlinear residual feature extractor in tandem.These layers’feature maps are then concatenated and sent on to subsequent convolution layers for feature extraction.The presented technique improves camera model recognition performance in resampled and recompressed pictures according to experimental data.When CNN is employed without ACFM in experiments,we utilize the architecture which refers to as Non ACFM-based CNN.It’s worth noting that the ACFM method may be extended and used to various types of nonlinear features to add variety to current features and improve CNN’s resilience in real-world settings.
Non ACFM-based CNN [19] is for Convolution Feature Maps Augmentation;BN stands for Batch-Normalization Layer;TanH stands for Hyperbolic Tangent Layer;ET stands for Extremely Randomized Trees.
CNNs for use in forensics was proposed by Bayar et al.[115] in their study.CNNs learning for classifying features tend to be on the current state of images contents.The study defined a new CNN layer called the restricted convolution layer,which concealed image contents during learning and manipulations were detected adaptively to overcome this issue.The study showed that their restricted CNNs could learn about manipulations directly in a series of tests where experimental results outperformed current other general-purpose manipulation detectors in DIFDs.Moreover,in cases of source camera model mismatched between training and testing data,their restricted CNN could still identify picture alterations correctly.The proposed method is made up of four separate conceptual blocks that may be used to: (i) use a block of 11 convolution filters to jointly suppress an image’s content and learn prediction error features while training,(ii) extract higher-level representations of previously learned image manipulation features,and (iii) learn new connections between feature mappings in a deeper layer.These filters learn a linear combination of features in the exact location but from a different feature map across channels.The classification block,which has three completely linked layers,receives the output of the latter block.The input layer of our CNN in this study is a grayscale picture patch with 256×256 pixels.
Bondi et al.[116] proposed a method for detecting and localizing image manipulation based on different camera types’distinctive imprints on pictures.The algorithm’s logic is that all pixels in immaculate photos should be recognized as being captured by a single device.In contrast,evidence of several devices can be identified when a picture is created by image composition.The proposed technique uses a CNN to extract typical camera model characteristics from picture patches.These characteristics are then examined using iterative clustering algorithms to determine if a picture is fabricated and pinpoint the foreign location.
In low-resolution pictures,Zhang et al.[117]proposed a Shallow Convolution Neural Network(SCNN)capable of identifying the borders of fabricated areas from original edges.SCNN was created to make use of Chroma and saturation data.Two methods based on SCNN have been developed to identify and localize picture forgery areas: Sliding Windows Detection (SWD) and Fast SCNN.The CASIA 2.0 dataset is used to test this model.The results demonstrate that Fast SCNN operates effectively on low-resolution pictures and outperforms the other significantly.Several works[7,118–120]utilized this CNN.A CNN[6,121,122]is a multilayered neural network with a unique design to detect complicated data characteristics.Pixels are the building blocks of images.A number between 0 and 255[123]is assigned to each pixel.A neural network based analysis[124–126]for image forensics based on localization of features.
Introduce a Fast SCNN method that is quicker and more efficient than SWD,inspired by the Fast RCNN.The suggested Fast SCNN computes all of the image’s CNN characteristics.After that,the features are sent to SCNN’s fully linked layers.Table 3 clearly explains classification inferences and deep learning approaches for forgery detection.
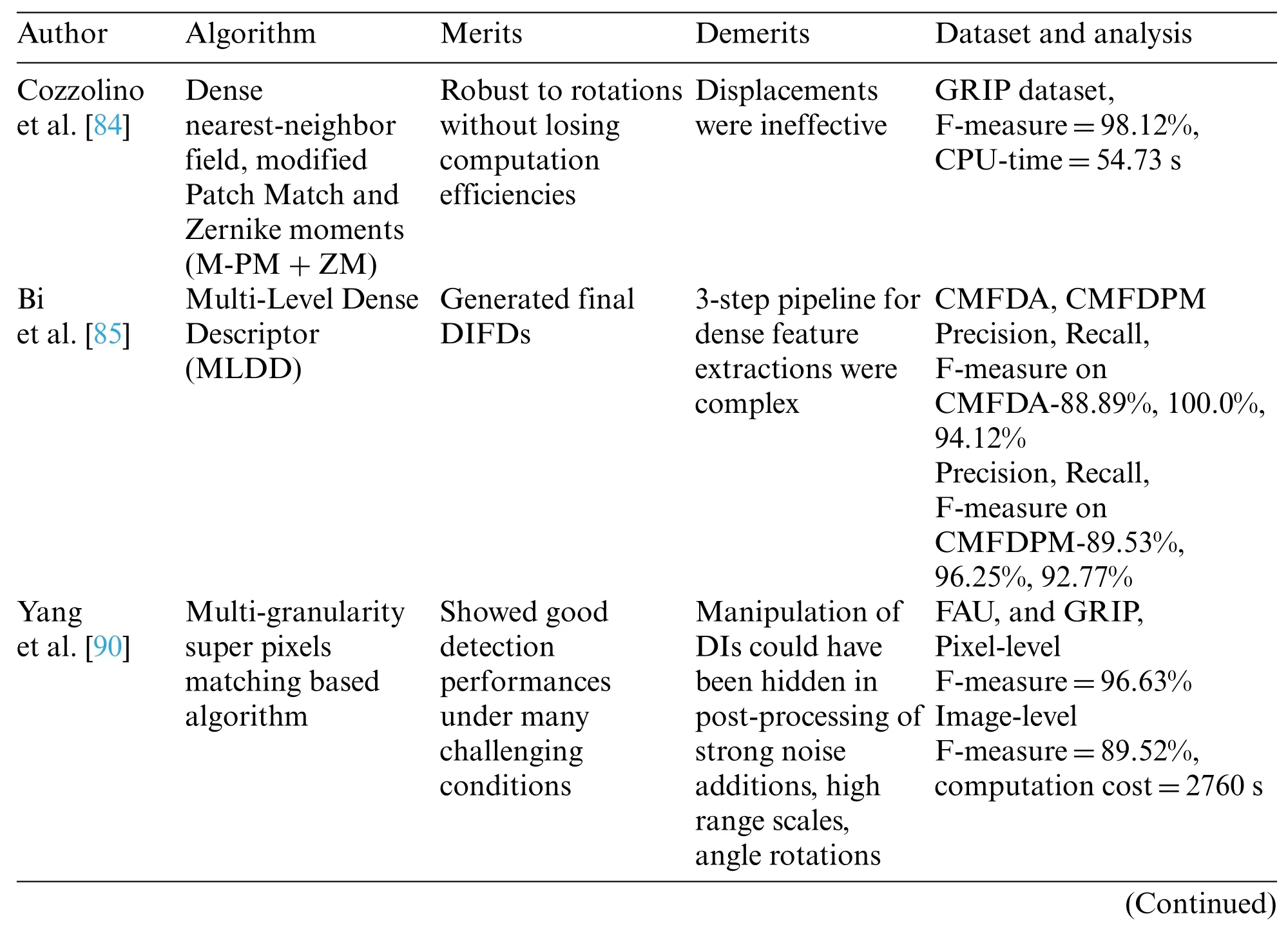
Table 3:Inferences of classification and deep learning methods

Table 3 (continued)Author Algorithm Merits Demerits Dataset and analysis Ouyang et al.[94]UCID,OXFORD,CMFD image database Error=2.32%,2.43%,4.2%for UCID,OXFORD,CMFD image database,respectively Liu et al.[95]CNN classifier Achieve better performance in various datasets The method could not detect real-world copy-moves in DIs MICC-F220,precision,recall and F1-measure=59.27%,82.20%,63.18%CoMoFoD dataset=55.99%,78.25%59.97%Kao et al.[99]Convolution Kernel Network(CKN)The GPU version was robust to varying conditions with good discriminations Research had gaps between copy-moves and CNN features ICDAR 2011 SigComp dataset VGG-19=Training accuracy=99.93%,Validation accuracy=100%,Testing accuracy=99.96%Test FRR=0%,Test FAR=0.22%Inception V3 Training accuracy=100%,Validation accuracy=99.98%,Testing accuracy=90.85%Test FRR=2.83%,Test FAR=16.31%Guorui et al.[100]Deep Convolution Neural Network(DCNN)Higher sample counts could increase accuracy rates CNN classifier Effective and robust for image forgery classification Unfavorable conditions of small sample size MLTs based feature extractions had the same disadvantages as block-based methods Columbia University image mosaic detection dataset,Accuracy No pre-processing layer=65.22%General filtering=83.94%Combination of SRM filtering and general filtering=91.80%(Continued)

Table 3 (continued)Author Algorithm Merits Demerits Dataset and analysis Zhong et al.[102]FAU,CASIA CMFD,and Comofodnew Dataset Precision,Recall,F1-Score=70.85%,58.85%,64.29%for CASIA CMFD Precision,Recall,F1-Score=46.10%,42.20%,44.41%for FAU Rao et al.[109]Dense-Inception Net Achieved performances were good against attacks and could increase the efficiency of detections Falsely identified foreground in real-time DIs CASIA v1.0,CASIA v2.0 and Columbia grey DVMM Spatial Rich Model(SRM)-CNN,Xavier-CNN=98.04%,88.24%for CASIA v1.0 SRM-CNN,Xavier-CNN=97.83%,97.30%for CASIA v2.0 SRM-CNN,Xavier-CNN=96.38%,74.67%for DVMM Wu et al.[111]CNN classifier The advantage of modelling residuals was original image pixels were suppressed while generating residual images Fully connected layers with more parameters might lead to overfitting in small training sets CASIA and CoMo-FoD Image Level Evaluation Protocol=Precision,Recall,F-Score=78.22%,73.89%,75.98%,Processing Speed=0.62 s for CASIA Dataset Precision,Recall,F-score=83.52%,78.75%,80.09%for CoMo-FoD dataset Bunk et al.[112]BusterNet Discernibility to localize source/target regions LSTMs Effective in detecting and localizing digital image forgeries Shows robustness to attacks No visual changes in manipulations in authentic images fail to perform well in segmenting manipulated regions NIST Nimble 2016 Dataset,Accuracy=94.86%,and AUC=91.38%(Continued)
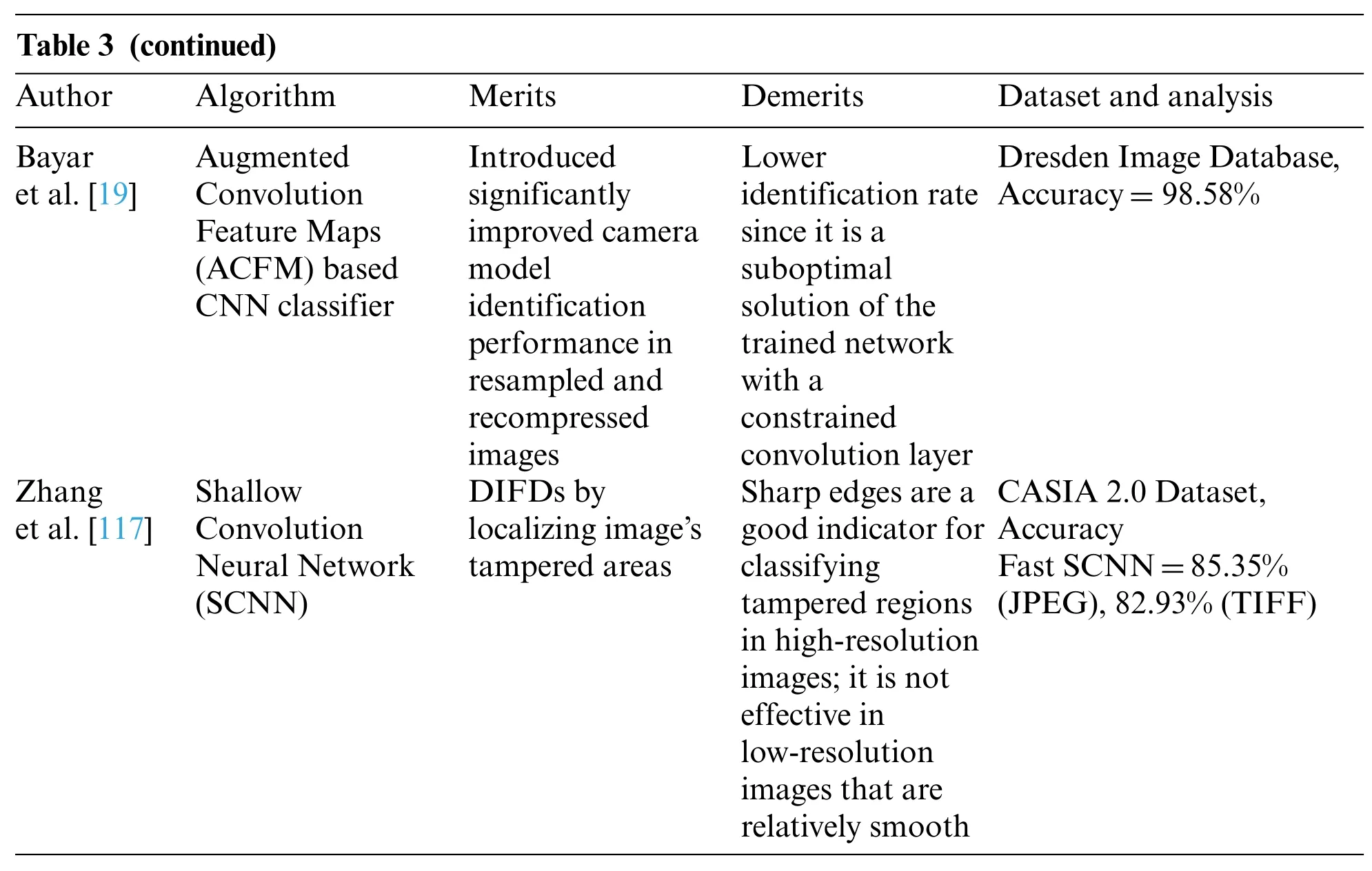
Table 3 (continued)Author Algorithm Merits Demerits Dataset and analysis Bayar et al.[19]Augmented Convolution Feature Maps(ACFM)based CNN classifier Introduced significantly improved camera model identification performance in resampled and recompressed images Zhang et al.[117]Shallow Convolution Neural Network(SCNN)Lower identification rate since it is a suboptimal solution of the trained network with a constrained convolution layer Dresden Image Database,Accuracy=98.58%DIFDs by localizing image’s tampered areas Sharp edges are a good indicator for classifying tampered regions in high-resolution images;it is not effective in low-resolution images that are relatively smooth CASIA 2.0 Dataset,Accuracy Fast SCNN=85.35%(JPEG),82.93%(TIFF)
There is also a deep fake based technology which is emerging and hottest branch of image forgery.In this GAN’s network is used to learn the probability distribution based on examples and generate the images which are very similar to original images.Li et al.[127] proposed a method to detecting forgery in face images generated by unseen face manipulation.In this method author used face x-ray based on blending step.Li et al.[128]proposed a novel frequency-aware discriminative feature learning framework based on single-center loss.Haliassos et al.[129]proposed Lip Forensics technique which targets high-level semantic irregularities in mouth movements.
Shang et al.[130] proposed pixel-region relation network which exploit pixel wise and regionwise relations for face forgery detection.It is very helpful to detect deep fake face forgery detection.Hu et al.[131] proposed dynamic Inconsistency-aware Network which uses CRM to capture global and local inter-frame inconsistencies to detect deep fake forged video.
Image inpainting forgery is task to reconstructing some regions in the image.It is the used in applications like object removal,image manipulations.This type of forgery has been focused in Elharrouss et al.[132].Where various method has been discussed based on this problem.Currently,various work has been done to improve image inpainting.To tackle this type of forgery [133]proposed method like impainting quality assessment tool using local features.Zhu et al.[134]proposed a encoder-decoder network to detect patch-based inpainting operation as shown in Fig.5.Zhang et al.[135]proposed a feature pyramid network for diffusion-based image inpainting.
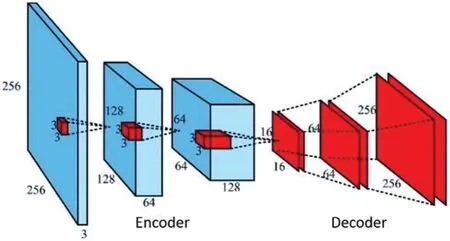
Figure 5:The layout,architecture and parameter settings of the CNN based on Encoder and Decoder network for inpainting forensics
Zhang et al.[135]proposed a Federated Learning to face forgery video detection,which is trained with decentralized data.Inconsistency-Capture module(ICM)[136]to capture the dynamic inconsistencies between adjacent frames of face forgery videos.Qian et al.[137]proposed a novel Frequency in Face Forgery Network taking advantages of frequency-aware decomposed image components,and 2) local frequency.Li et al.[138] proposed a novel feature learning framework for single-center loss which compresses mere intra-class variations of natural faces.
There are some other model which exploits the deep learning based approach such as DLFMCMDFC[139],deep learning by recompression[140],copy-move image forgery[141],CNN by using the architecture of ResNet50v2[142].
1)Convolution
A convolution is a two-function integration that demonstrates how one influences the other.The input picture,the feature detector,and the feature map are key components in this process as in Eq.(16),

For input images,the feature detector (Kernel) could be a 3×3 or 7×7 matrix.The kernel multiplies matrix representations of the image elements to generate feature maps(convolved features or activation maps)to reduce image sizes and hasten to process.Though specific image characteristics might be lost,essential factors necessary for DIFDs are retained.
2)ReLu(Rectified Linear Unit)
This function boosts non-linearity in CNNs,and items that are not linear to each other are used to generate images.The primary use of ReLu is to handle image classification as a non-linear issue.
3)Pooling
The idea of spatial invariance states that the position of an object in an image has no bearing on the neural network’s capacity to recognize its unique characteristics.CNNs Pooling(maximum/minimum)identifies image characteristics irrespective of illumination/camera angle differences s.A 2×2 matrix is placed on feature maps,and the most significant value in the box is selected while pooling.This 2×2 matrix is passed over the entire feature map from left to right,choosing the maximum value in each pass.These data are then combined to create a new matrix known as a pooled feature map.Max pooling helps to keep the image’s key characteristics while shrinking its size.This helps avoid overfitting,which occurs when the CNN is given too much data,especially if the information is irrelevant to categorizing the picture.
4)Flattening
After acquiring the pooled featured maps,they need to be flattened.The whole pooled feature map matrix is flattened into a single column,then given to the neural network for processing.
5)Full connection
The flattened feature map is then sent through a neural network after flattening.The input layer,the fully linked layer,and the output layer make up this stage.In ANNs,the completely connected layer is identical to the hidden layer,except it is fully linked in this case.The projected classes are the output layer.The data is sent via the network,and the prediction error is computed.The mistake is then sent back into the algorithm to enhance the prediction.
In most cases,the neural network’s final values do not add up to one.However,it is critical to reducing these figures to integers between zero and one,which indicates each class’s likelihood.By Eq.(17),the Softmax function plays this job,
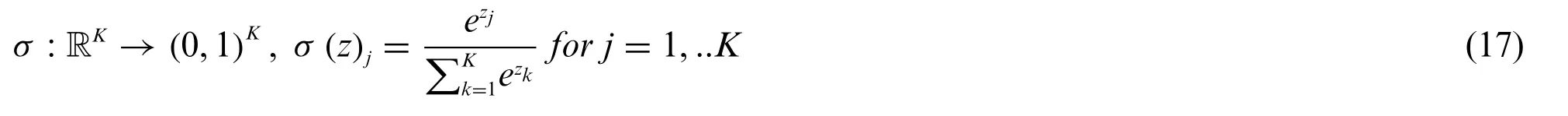
3 Challenges and Issues
The techniques above nevertheless have many drawbacks.First,rather than leveraging correlated information across patches.Most existing pixel-wise tampering detectors employ a patch-based approach.As a result,statistical information required for feature extraction is insufficient,particularly at the boundary of a forged region.Alternatively,to make assessing the validity of an inquiry patch simpler,the features of neighboring patches should be underlined.
Furthermore,the absence of statistical characteristics across flat sites(clear sky,Blue Ocean,etc.)generates estimation uncertainty,resulting in poor detection performance.In this case,the texture of the image content becomes an essential factor in enhancing detection accuracy.Furthermore,as imageediting software has advanced rapidly,the leftovers of alteration operations now behave similarly to the original(i.e.,tampering traces are hard to detect).As a result,lowering the likelihood of detection mismatches and increasing localization resolutions (determined by the smallest unit of detection)remains an ongoing challenge.
Machine learning approaches that rely on block feature extraction,on the other hand,suffer from the same flaws as block-based methods.Furthermore,to counter forgeries,these algorithms only learn characteristics of a single recognized picture.Due to the lack of past information to handle forgeries in other images,the techniques must re-initialize the model and repeat many times.These approaches are significantly less efficient than deep learning methods.
4 Conclusion and Future Work
In terms of simulation,this article has examined the numerous processes involved in forgery detection approaches.It is clear from this paper that there would be two primary categories accessible in forgery detection.Several authors rely heavily on the passive voice.The passive-based forgery detection approaches are also discussed in this review paper,along with image processing processes such as preprocessing,feature extraction,and classification.Many writers have proposed numerous methods for picture preparation,but only a handful have solely concentrated on this phase.Several scholars have worked on spatial domain approaches in feature extraction,but only a few have focused on transform and hybrid methods.Because of its high detection accuracy and quick calculation,Deep Learning-based feature extraction has made significant progress in forgery detection applications.Furthermore,the authors are attempting to enhance the accuracy of forgery detection,either by building a solo feature extractor or by inventing additional feature extraction.Finally,several detecting matching techniques are examined.
Funding Statement:The authors received no specific funding for this study.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2023年3期
Computer Modeling In Engineering&Sciences2023年3期
- Computer Modeling In Engineering&Sciences的其它文章
- A Consistent Time Level Implementation Preserving Second-Order Time Accuracy via a Framework of Unified Time Integrators in the Discrete Element Approach
- Application of Automated Guided Vehicles in Smart Automated Warehouse Systems:A Survey
- Intelligent Identification over Power Big Data:Opportunities,Solutions,and Challenges
- Broad Learning System for Tackling Emerging Challenges in Face Recognition
- Overview of 3D Human Pose Estimation
- Continuous Sign Language Recognition Based on Spatial-Temporal Graph Attention Network