
坐标注意力特征金字塔的显著性目标检测算法
2023-01-17 09:31王剑哲
计算机与生活 2023年1期
王剑哲,吴 秦,2+
1.江南大学人工智能与计算机学院,江苏无锡214122
2.江南大学江苏省模式识别与计算智能工程实验室,江苏无锡214122
显著性目标检测旨在模拟人的视觉特征分割出图像中感兴趣的目标或区域。作为计算机视觉领域中一项重要的预处理操作,显著性目标检测已被广泛应用于图像分类[1]、语义分割[2]、目标检测[3]以及目标跟踪[4]等任务中。但由于目标所在场景复杂,显著性目标检测任务依然存在诸多挑战。
传统的显著性目标检测主要使用手工提取特征或启发式先验方法来检测图像中的显著性目标[5]。这些方法往往是根据颜色或轮廓等低级特征来寻找目标,在单一场景下效果显著,而在包含丰富背景信息的复杂场景下则极易产生误判,无法生成高质量的预测图。近年来,卷积神经网络在特征提取上展现出巨大的优势,随着全卷积网络(fully convolutional network,FCN)[6]在图像分割领域取得的成功,现有的显著性目标检测方法大多基于FCN且采用金字塔结构来对特征进行编解码以增强感兴趣目标的表征能力。
尽管特征金字塔的结构能够有效提取不同层次的特征,但其依然存在一些问题:首先,复杂场景中存在容易被误判的背景噪声,如图1(1)至(3)中的标志牌、影子等,由于其具有与显著目标相似的特征,在特征提取过程中极易发生误判,对检测精度和预测图都会产生较大影响。其次,如图1(4)至(6)所示,被检测的显著性目标往往拥有复杂的形状和轮廓,导致网络难以精确地界定其边界,而目标边界的检测效果同样影响最终的显著图质量。

图1 显著性目标检测问题的图像示例Fig.1 Examples of problem in salient object detection
为有效减少背景误判且同时关注对显著目标边界的预测,本文提出一种特征金字塔结构下的坐标注意力显著性目标检测网络。金字塔结构下的网络将首先自底向上地提取不同层次的特征,并使用坐标注意力模块(coordinate attention module,CAM)调整蕴含着高级语义信息的最深层网络下的特征图权重,进一步锁定显著性目标,在突出关键特征的同时有效抑制了背景噪声对显著图生成的干扰。在自顶向下的解码过程中,加入特征细化模块(feature refinement module,FRM)以融合不同层次下的不同尺度形态的特征,以防止逐层特征提取过程中丢失关键信息。此外,还提出边界感知损失函数来使网络提升对目标边界预测情况的关注度,进一步修正显著目标的边缘检测情况,结合多层次监督使得网络能更好地界定目标范围,同时生成更高质量的显著图。本文的主要贡献如下:
(1)提出坐标注意力特征金字塔的显著性目标检测网络,结合特征金字塔提取多层次特征的优势与坐标注意力对深层次特征的挖掘能力,有效解决显著目标背景误判问题。
(2)提出特征细化模块,保留特征的细节信息,实现不同层次特征的高效融合。
(3)提出边界感知损失,帮助网络捕获显著目标边界信息,解决边界模糊问题。
(4)大量的实验数据表明了所提方法对提高显著性目标检测精度的有效性,可视化的实验结果论证了所提模块确实能有效解决背景误判与边界复杂问题。
1 相关工作
显著性目标检测于1998 年被提出,主要分为基于手工提取特征的传统方法和当前基于卷积神经网络(convolutional neural network,CNN)的方法。传统显著性目标检测方法主要依赖于对低级特征的利用,例如颜色对比、背景先验以及探索相似特征等。基于卷积神经网络的显著性目标检测方法则通过多个神经元对图像进行学习,提取了不同层次和形态的目标特征,并探索了具有更深层含义的高级语义信息,取得了比传统方法更准确的检测精度。自2015 年Long 等人[6]提出FCN 后,像素级的图像分割任务得到进一步发展。其中,Ronneberger 等人[7]与Badrinarayanan 等人[8]均采用编解码结构网络,并应用于不同的分割领域。Zhang 等人[9]则将特征金字塔结构应用于显著性目标检测中,进一步整合了低级特征与高级语义信息,有效提高了检测性能。现有的工作通过特征融合、注意力机制以及边界感知等方法有效提高了显著性目标检测的精度,本章将对这些方法依次介绍。
1.1 特征融合
为了充分利用不同阶段的特征形态又演变出诸多特征融合的方法,张守东等人[10]融合深度-手工特征与深层网络特征,避免了模型过拟合问题,提高网络性能。Liu 等人[11]则设计了金字塔池化模块和全局指导模块,并将其用于特征融合,以锐化显著物体细节,提高检测精度。然而,这些方法采用的像素点相加的融合方式将导致不同层次下细节信息丢失。针对这一问题,本文提出的特征细化模块将在融合不同层次特征时,通过像素级相乘过滤背景噪声,并采用像素级相加保留更多细节信息。
1.2 注意力机制
检测方法中往往使用注意力机制帮助网络进一步聚焦关键特征,削弱无关信息权重,以提高网络区分前背景的能力,这一模式也被广泛应用于分割领域。Hu等人[12]曾提出通道注意力模块SENet(squeezeand-excitation networks)为不同通道的特征分配不同权重,以探寻通道之间的关系,有效放大关键信息。Woo等人[13]在通道注意力的基础上加入空间注意力,设计了卷积块注意力模块(convolutional block attention module,CBAM)帮助网络自适应地在空间和通道维度上调节特征权重。Zhao 等人[14]则将CBAM 应用于显著性目标检测中,提升了预测精度。然而,这些注意力机制均仅能捕获局部信息,缺少对全局信息的把控能力。本文将使用坐标注意力(coordinate attention,CA)[15],分别从水平和垂直两个空间方向聚集特征,在捕获一个空间方向上长期依赖关系的同时,保留另一空间方向上精确的位置信息,使网络对目标整体的结构信息有一个更好的把握。同时,坐标注意力模块将方向感知与位置敏感的注意力图互补地应用于显著图像,有效增强了显著性区域特征的表征。
1.3 边界感知
为有效改善边界预测,Zhou 等人[16]设计了边界模块用于学习目标的边界信息。Su 等人[17]同样设计了针对边界学习的分支,将生成的边界与显著图结合以获得最终的结果。这些模块和分支均在一定程度上改善了目标在边界上的预测,但是都将增加网络的参数量和计算量,降低了网络的效率。本文则针对复杂边界设计了边界感知损失函数,通过引入边界感知系数来赋予边界像素点不同的权重,使网络更适应复杂边界的同时,提升网络对边界预测的关注度,以进一步提高检测精度和最终显著图的质量。
尽管特征融合、注意力机制、边界感知等方法对提高显著性目标检测性能起到了一定的作用。然而现有方法中依然存在特征融合的细节丢失、高性能注意力机制的应用、边界感知网络的低效等问题。针对这些问题,本文的坐标注意力特征金字塔模型,加入特征细化模块、坐标注意力模块以及边界感知损失,在对这些方法改进的同时,提高了显著性目标检测的性能。
2 坐标注意力特征金字塔模型
本文提出的坐标注意力特征金字塔显著性目标检测模型结构如图2 所示。整体为端到端的编解码框架,其中编码器使用特征金字塔提取不同深度层次特征,以辨识场景中多尺度显著目标;坐标注意力应用于深层次特征,起到聚焦显著目标区域,抑制背景噪声的作用,以生成高质量的显著图;解码器用于融合不同层次特征,以充分结合空间信息和通道信息。网络具体的参数配置如表1 所示。

表1 网络参数Table 1 Network parameters
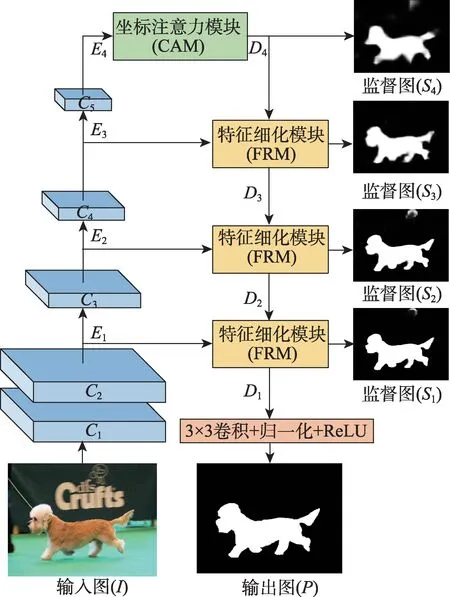
图2 坐标注意力特征金字塔网络结构Fig.2 Architecture of coordinate attention feature pyramid network
给定的输入图I首先通过由ResNet-50[18]前48 层组成的编码器,生成不同层次的编码图Ei(i=1,2,3,4)。深层次编码图E4则通过坐标注意力模块CAM,以生成解码图D4。解码器采用3 个特征细化模块自顶向下地融合不同层的编码图Ei和解码图Di+1,输出结合后的解码图Di与监督图Si(i=1,2,3,4)。其中监督图Si用于多层次监督,网络最终的预测结果P则由编码图D1经过卷积、归一化、ReLU 生成。
后续将依次对组成网络的关键模块进行详细介绍,包括组成解码器的特征细化模块FRM,编解码器中间的坐标注意力模块CAM 以及训练过程中所使用的边界感知损失函数。
2.1 特征细化模块
解码器旨在逐层融合来自编码器中不同层次的特征,达到空间信息与通道信息的有效结合。FCN方法采用像素相加的方式实现相邻层次特征的融合。由于不同层次特征间差异,此举往往造成融合中细节信息的丢失。考虑到残差结构能有效保留原特征图中信息,本文设计了特征细化模块以应对特征融合中存在的细节丢失问题,其具体结构如图3所示。
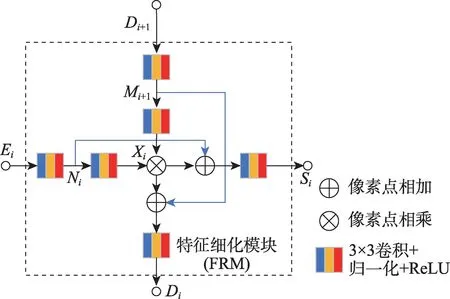
图3 特征细化模块结构Fig.3 Architecture of feature refinement module
特征细化模块的输入为特征图Ei和上一层特征融合后所得的特征图Di+1。其中Ei为编码阶段所得,其虽蕴含丰富的低级特征却同时存在大量背景噪声。而Di+1则包含的是更高层次的语义特征,其有效过滤背景噪声,却缺失目标的全局信息。
特征细化模块旨在有效融合不同层次的特征图Ei和Di+1。其首先使用像素级相乘的方式将经过卷积学习后的特征图Ei和Di+1结合得到特征图Xi,不仅充分融合显著性目标的低级特征和高级特征,而且有效过滤背景噪声。再将中间特征图Ni和Mi+1以像素级相加的方式与Xi结合,以防止有效信息丢失。特征细化模块最终将输出整合后的特征图Di用于与下层低级特征进一步进行融合,同时输出特征图Si用于后续多层次监督。
2.2 坐标注意力模块
基于特征金字塔的编解码结构通过融合不同层次特征实现显著目标的高效检测。然而,对于图像中易被误判为显著目标的背景噪声这一问题,特征金字塔并不能有效解决。而注意力机制则通过增加显著区域赋予高的权重,帮助网络更加关注显著区域。相比仅采用全局池化捕获局部信息而忽略了特征在平面上不同方向的呈现形式的卷积块注意力模块CBAM,坐标注意力在捕获通道信息的同时,保留了对捕捉物体结构和产生空间选择性注意力图至关重要的方向信息,同时还捕获到长范围依赖信息,有利于更好地定位和识别显著性区域[16]。结合了坐标注意力的特征金字塔结构能够有效解决背景误判问题,生成高质量的显著图。
坐标注意力模块具体结构如图4 所示,其输入为最深层的拥有最大感受野的特征编码图E4,在结合通道及方向信息调整E4中不同区域特征权重维度后输出特征图D4,以进行进一步解码。整个过程中特征图均保持宽高为8,通道数为2 048。对特征图在不同方向和通道上的注意力图的学习主要分为坐标信息嵌入和坐标注意力生成两个步骤。
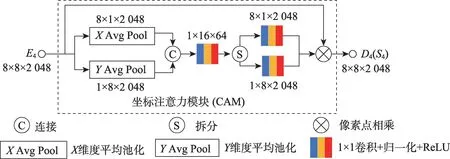
图4 坐标注意力模块结构Fig.4 Architecture of coordinate attention module
坐标信息嵌入操作具体体现为采用尺寸为8×1和1×8 的全局池化操作,将特征图分解为垂直与水平维度的特征编码。其从垂直与水平方向编码显著图,以保留特征空间结构信息。其具体计算过程如式(1)和式(2)所示。

其中,W和H为特征图的宽和高。E4(i,j)为特征图E4在(i,j)位置的值。得到的zh与zw为垂直与水平方向上所得的单向坐标感知注意力图,坐标注意力生成操作则旨在编码显著图的通道信息并重新调整显著区域的权重。在显著图通道信息编码过程中,首先将单向编码特征图zh和zw进行级联并通过1×1的卷积探寻通道间关系以对其进行调整,其过程如式(3)。

其中,F1×1为1×1 卷积,cat为级联操作。f为所得的尺寸为1×16×64 的同时具备空间和通道维度重要特征探索能力的双向通道注意力图。随后对特征图f进行切分并转置成8×1×64 的fh和1×8×64的fw,结合1×1 卷积,最终生成一对方向感知和位置敏感的注意力图gh和gw,其具体操作如式(4)和式(5)所示。

在显著区域权重分配中,gh和gw可以通过像素点相乘互补地应用于特征图E4,得到模块输出的坐标注意力图D4,以增强对显著目标的表征,计算过程如式(6)。

2.3 边界感知损失
显著性目标检测中常用交叉熵损失来监督网络,其计算方式如式(7)所示。
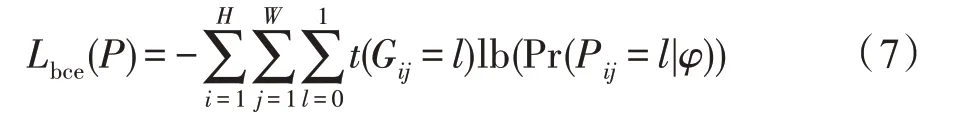
其中,Gij和Pij为真值图G和预测图P在位置(i,j)的值。Pr(Pij=l|φ)指的是给定所有参数φ的条件下,Pij=l的预测概率。函数t(Gij=l)如式(8)。

然而,交叉熵计算单个像素点的损失值,给每个像素点赋予同样的权重,未区分边界点和其他点对于显著目标检测的重要程度差异。为帮助网络感知边界,提升边界预测能力,本文使用wij提高边界像素点的损失值,具体如式(9)。

其中,Aij指的是以(i,j)为中心、大小为31×31的区域。wij取值范围为[0,1],wij取值越大,就意味着像素点(i,j)越接近边界。通过将wij与交叉熵损失函数结合,得到能够感知边界像素的损失函数Lwbce,如式(10)。
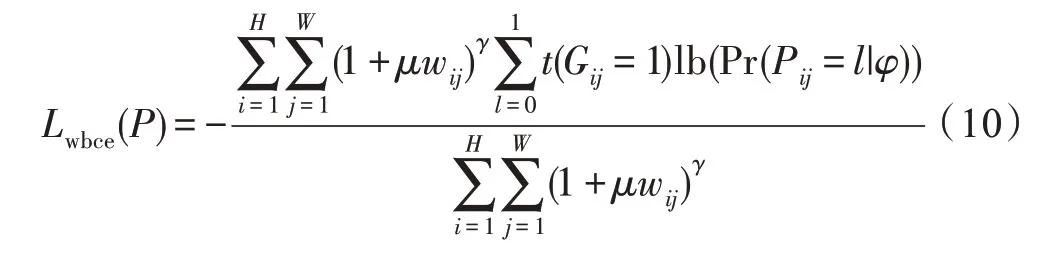
其中,μ和γ为用于调整边界权重的超参数。Lwbce具有以下优点:(1)通过引入边界感知因子wij,Lwbce获得感知边界像素点的能力。(2)通过引入边界权重μ和γ,提升了网络对于显著目标边界预测的关注度,使得模型对不同复杂度的边界信息拥有了更好的适应和调整能力。
此外,由于Lwbce计算的是单像素点的损失,其缺少对显著图像整体的感知能力,为了使网络学习到显著图像的整体信息,使用式(11)定义的IoU 损失来监督实例级的分割情况。

基于以上讨论,使用由式(12)定义的损失函数来指导监督图P的生成。

此外,为了提升模型的学习能力,本文还将多层次监督的特征图Si纳入损失函数中。其中,S1和S2为千层网络输出的特征图,其中多为繁杂的低级特征,使用边界像素损失Lwbce较为合理;S3和S4为高层网络生成的、蕴含着语义信息的高级特征,适合使用整体性损失LIoU。因此,最终的损失函数为定义在式(13)中的多层监督损失,其中的P和Si为图2 中模型的预测图和监督图。

3 实验和分析
本章首先介绍使用的数据集与实验环境,然后介绍评估模型使用的评价指标,接着对网络的参数设置和实现细节进行说明,最后通过定性与定量的方式与当前主流的显著性目标检测方法进行对比与分析。
3.1 数据集
为了验证模型的有效性,使用五个在显著性目标检测领域常用的数据集来评估模型性能,分别为ECSSD[19]、PASCAL-S[20]、HKU-IS[21]、DUTS[22]和DUTOMRON[23]。ECSSD 包含1 000 张来自网络的复杂场景的显著图像,且均有像素级标注。PASCAL-S包含850 张不同的自然图像,这些图像来自PASCAL VOC2010[24]分割比赛。HKU-IS 包含4 447 张高质量像素级显著图像,每张图像中有多个显著目标区域。DUTS 是目前最大的显著性目标检测数据集,来自ImageNetDET[25]和SUN[26]数据集,共包含15 572 张图像,其中10 553 张作为训练集DUTS-TR,剩下的5 019 张作为测试集DUTS-TE。DUT-OMRON 包含5 168 张显著图像,这些图像选自140 000 张自然图像,每张都包含多个显著目标与复杂的背景信息。相比其他数据集,DUT-OMRON 更具有挑战性,在显著性目标检测领域有着更大的研究空间。
3.2 评价指标
5 个评估指标用于度量模型的性能,包括平均绝对误差(mean absolute error,MAE)、准确率-召回率(precision-recall,PR)曲线、F 值、结构相似性度量(Smeasure)和E 值。
MAE 用于评估预测图和真值图之间像素级平均误差,其值越小,则说明误差越小。其实现如式(14)。

其中,P和G分别为预测图和真值图。
PR 曲线用于刻画准确率与召回率之间的关系,通过一组0 到255 的阈值,计算预测图与真值图之间的准确率和召回率,计算方式如式(15)。
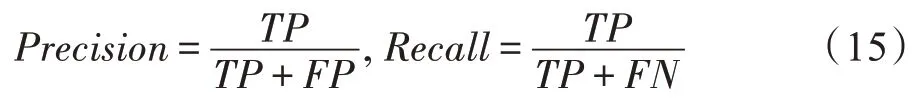
其中,Precision为准确率,Recall为召回率。TP、FP、FN分别表示显著区域预测为显著区域、背景预测为显著区域、显著区域预测为背景的像素点数量。
F 值为准确率和召回率的加权调和平均,用于统合评估模型性能。其计算公式如式(16)。

其中,β根据文献[27]设置为0.3。
S 值用于计算预测图和真值图间的结构相似性,计算方法如式(17)。

其中,Sr为基于区域的结构相似性,So为基于目标的结构相似性。α根据经验被设置为0.5。文献[28]展示该指标的具体细节。
E 值同样作为评估预测图与真值图的整体性指标,计算方法参考文献[29]。
3.3 实现细节
模型使用DUTS 中具有10 553 张图像的DUTSTR 作为训练集,DUTS-TE 和其他的数据集作为测试集用于评估模型性能。在数据增强阶段,加入水平翻转和随机裁剪。ResNet-50 使用ImageNet 预训练模型。ResNet-50 初始学习率设置为0.005,其他部分设置为0.05。模型采用SGD 优化器,最小学习率为0.000 5。Batchsize设置为32,训练轮数为64。
3.4 实验结果对比分析
将本文提出的坐标注意力的特征金字塔网络同当前流行的其他基于深度学习的先进方法进行对比。对比的方法包括RAS[30]、R3Net[31]、TDBU[32]、AFNet[33]、PoolNet[11]、BANet[17]、CPR-R[34]、GCPA[35]、GateNet[36]、ITSD[16]、MINet[37]。为保证公平性,参与对比的方法使用相同的评估代码。
3.4.1 定量分析
表2 和表3 展示本文方法与其他11 种方法在数据集ECSSD、PASCAL-S、DUTS、HKU-IS 和DUTOMRON 上不同评价指标的对比结果。如表2 和表3所示,得益于特征金字塔对各层次特征的有效融合与坐标注意力模块对显著区域的权重分配,本文的模型在整体上取得较好的成绩。在数据集DUTS 和HKU-IS 上,本文方法在各项指标上均超过其他方法。在数据集PASCAL-S 上,除了S 指标比最好的方法GCPA[35]低0.003 外,其他指标上均取得一定程度的领先。对于最具挑战的数据集DUT-OMROM,模型在MAE 与F 指标上同样取得最好的结果,而在其他指标上也与其他先进的方法保持一致。图5 展示本文方法和其他4 种方法的PR 曲线图,本文方法同样表现出更好的性能。
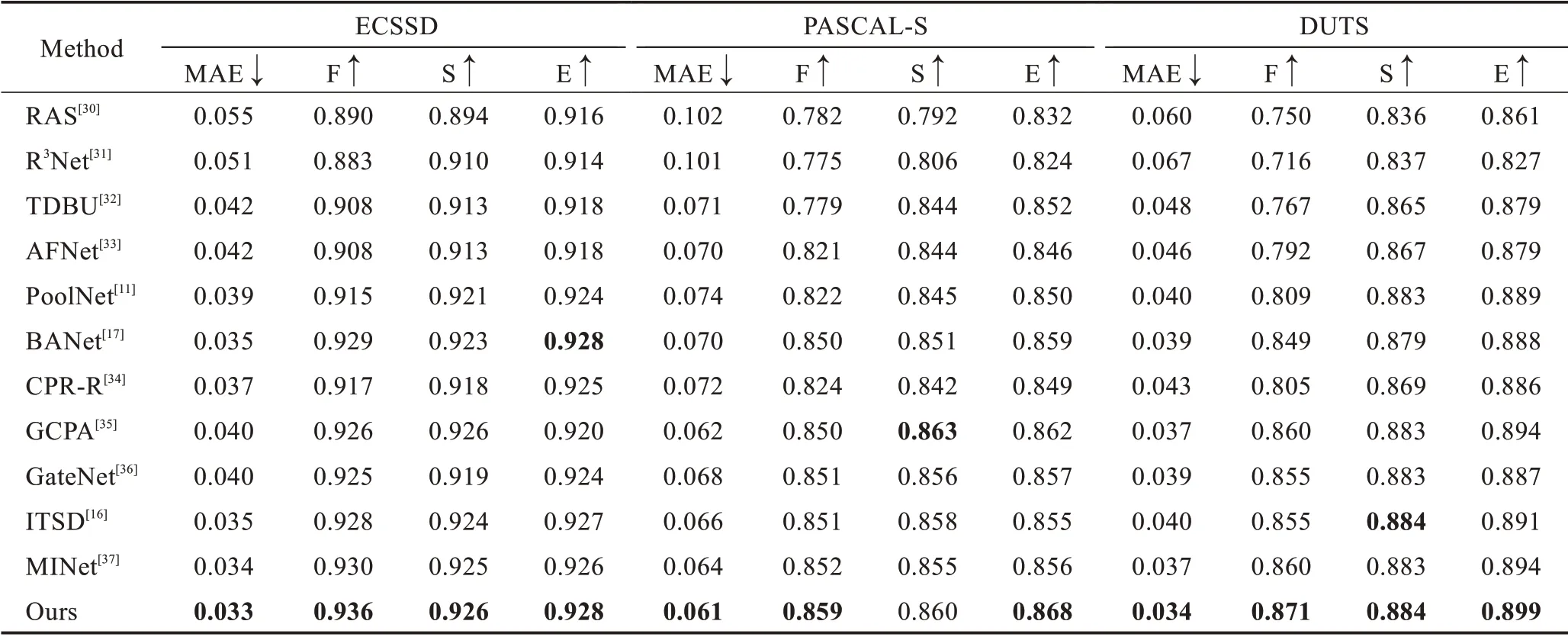
表2 数据集ECSSD、PASCAL-S 和DUTS 上的定量对比Table 2 Quantitative comparison on datasets ECSSD,PASCAL-S and DUTS

图5 本文模型与其他先进方法的PR 曲线Fig.5 PR curves of proposed model and other state-of-the-art methods
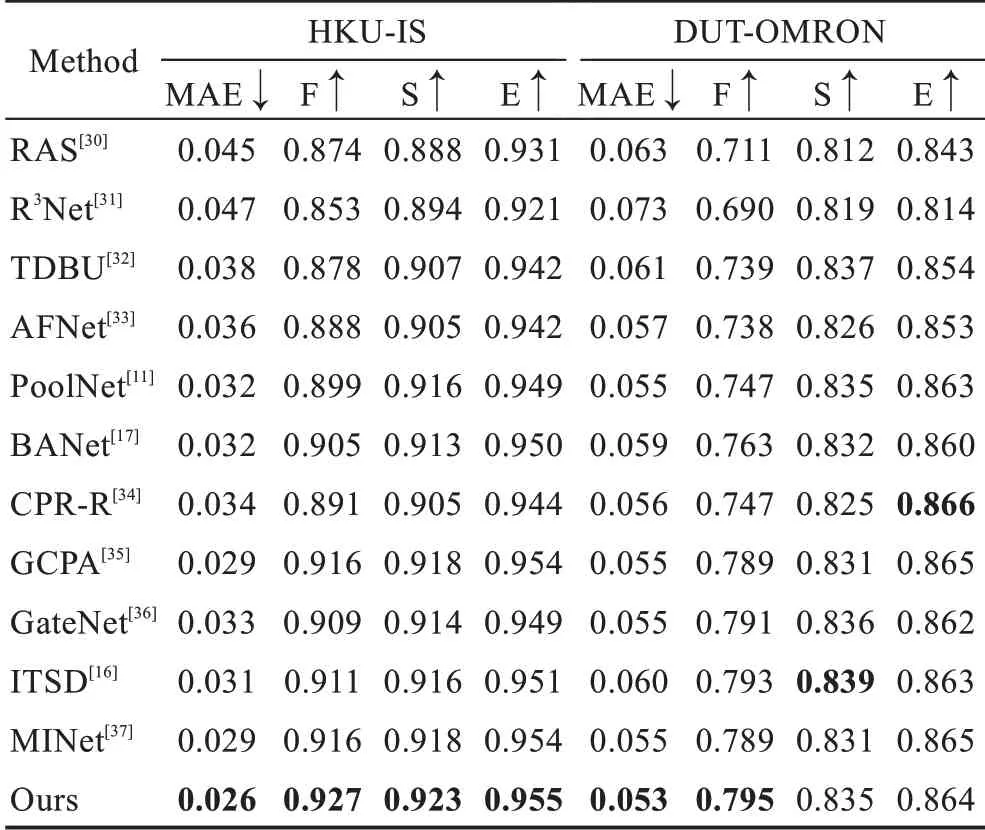
表3 数据集HKU-IS 和DUT-OMRON 上的定量对比Table 3 Quantitative comparison on datasets HKU-IS and DUT-OMRON
3.4.2 定性分析
为了进一步验证本文方法的性能,图6 展示本文方法与其他方法的可视化对比结果。加入了特征细化模块的特征金字塔网络结构,能够有效检测不同尺度的显著目标。由图6(1)至(3)可以看出,对复杂场景下不同大小的显著目标,本文方法均能够生成高质量显著图。坐标注意力模块的加入,有助于网络对显著区域与背景噪声的有效判断。由图6(4)至(6)可以看出,与昆虫相邻的花朵以及动物的影子,都属于背景中易被误判的噪声,而本文模型均能够将它们区别出来。得益于边界感知损失帮助网络对边缘信息的学习,网络能够更准确地预测边界像素点。由图6(7)至(8)看出,相比其他缺少边界感知的方法,本文模型生成的显著图具有更加清晰的边界。

图6 本文方法与其他先进方法的可视化对比Fig.6 Visual comparison of proposed model and other state-of-the-art methods
3.5 消融实验
3.5.1 所提内容有效性验证
为验证各个模块的有效性,在数据集DUTS 和DUT-OMRON 上进行相关的消融实验。基础网络结构包括ResNet-50 编码器和3 个VGGBlock 组成的解码器。之后用特征细化模块FRM 代替VGGBlock,再依次加入多层特征监督(multi-level supervision,MLS)和坐标注意力模块CAM。实验结果如表4 所示,可以看出,在使用特征细化模块FRM 后,得益于细节保留能力,检测性能有了显著提升。DUTS 数据集中MAE 由0.040 降至0.036,DUT-OMRON 数据集MAE 也由0.062 降至0.055,其他指标也有较为显著的提升。随后加入多层特征监督MLS 以优化训练过程,检测精度F 值和结构相似性指标S 值有所提升。DUTS 数据集中F 值提高0.005,E 值提高0.004。DUT-OMRON 数据集中F 值提高0.008。在融入坐标注意力模块CAM 后,模型有效解决背景误判问题,模型检测效果进一步提升。DUTS 数据集的MAE 降低0.002,F 值提高0.004。DUT-OMRON 数据集的MAE由0.055降低至0.053,F值由0.791提升至0.795。

表4 不同模块的消融实验Table 4 Ablation study for different modules
为进一步探索各个模块的有效性,本小节进行了可视化对比的消融实验。特征细化模块在解码过程中保留更多的细节信息,有助于生成更加清晰的显著图,而多层次监督能够在这一过程中起到优化作用。图7 展示了特征细化模块FRM 和多层次监督MLS 的可视化对比。可以看出,在加入FRM 与MLS后,预测图的显著区域更加准确,也没有模糊区域。监督图S1至监督图S4的显著区域不断精细的过程也反映了MLS 的有效性。

图7 特征细化模块与多层次监督的可视化对比Fig.7 Visual comparison of feature refinement module and multi-level supervision
坐标注意力模块捕获深层次的通道信息与长范围空间信息,为显著区域与非显著区域分配不同权重,增强前景,抑制背景。图8 展示了坐标注意力模块的可视化对比。在不加入坐标注意力的情况下,网络依然不能准确区分易被误判的背景噪声,而加入坐标注意力模块后,模型则能够对这些噪声有效判断,解决背景误判问题。

图8 坐标注意力模块的可视化对比Fig.8 Visual comparison of coordinate attention module
3.5.2 损失函数对比
为使网络具有更好的性能,本小节对损失函数进行消融实验。首先对式(10)中Lwbce中超参数γ和μ进行调参。如表5 和表6 所示,当γ和μ分别取2和5 时,模型取得最好的性能。

表5 超参数γ 消融实验Table 5 Ablation study for hyper-parameter γ
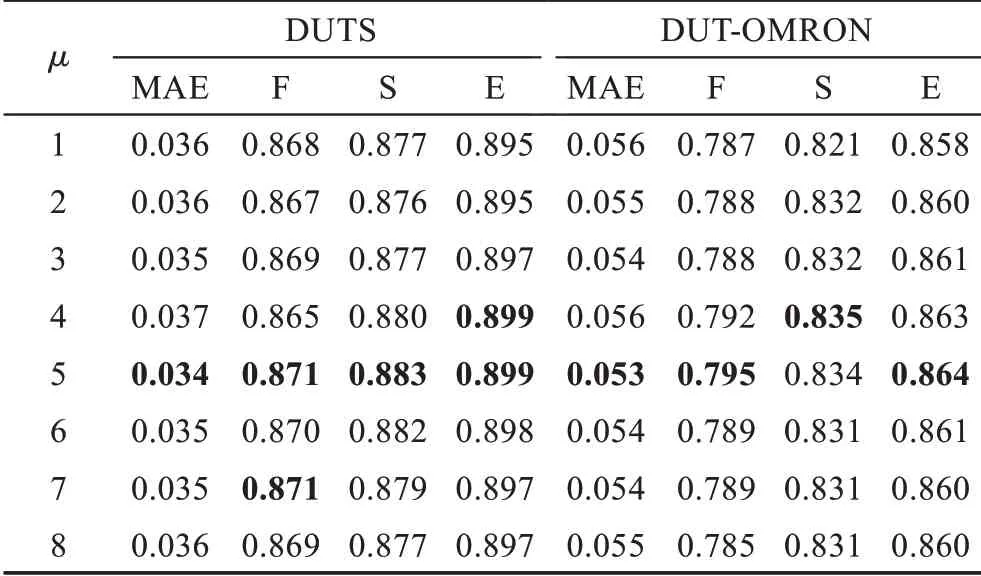
表6 超参数μ 消融实验Table 6 Ablation study for hyper-parameter μ
本小节将提出的边界感知损失与式(7)中的交叉熵损失、式(11)中的IoU 损失以及两者相加所得到的结果进行对比。得益于边界感知损失对边界信息赋予更多的权重,网络对边界像素点的预测更加准确。如表7 所示,相比使用Lbce+LIoU,边界损失感知在各项评估指标上有了更好的表现,这也论证了边界感知损失的有效性。图9 展示了损失函数的可视化对比结果,在未使用边界感知损失的情况下,模型会因为目标边界复杂而产生模糊的边界,甚至将部分边界像素点预测为背景。使用边界损失后,这些像素点得到有效的预测,显著图边界也更加清晰准确。这也论证了边界感知损失的加入,更有助于网络对边界像素点的准确判断。

表7 不同损失函数的消融实验Table 7 Ablation study for different loss functions

图9 损失函数的可视化对比Fig.9 Visual comparison of loss functions
4 结束语
本文提出了一种坐标注意力的特征金字塔模型以解决显著性目标检测中背景误判和边界复杂问题。设计特征细化模块,使不同层特征的融合更加高效。通过坐标注意力模块,减少背景中易误判的噪声。为使网络能够更加关注边界信息,生成具有清晰边界的显著图像,本文设计边界感知损失。在与其他先进方法的实验对比中,所提出的模型具有更强的竞争力。未来的工作中,将考虑通过逐层收缩的方式,提高对相邻特征节点的关注度,以便动态更新不同层次特征权重。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
儿童时代·幸福宝宝(2021年11期)2021-12-21
小学科学(学生版)(2021年4期)2021-07-23
数学小灵通·3-4年级(2021年5期)2021-07-16
现代装饰(2020年4期)2020-05-20
今日农业(2019年15期)2019-01-03
证券法律评论(2018年0期)2018-08-31
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
共产党员(辽宁)(2015年2期)2015-12-06
