
高级语义修复策略的跨模态融合RGB-D 显著性检测
2023-01-17 09:31石玉诚龙慧云
计算机与生活 2023年1期
石玉诚,吴 云,龙慧云
贵州大学计算机科学与技术学院,贵阳550025
显著性目标检测旨在模拟人类视觉系统检测出吸引人类注意力的物体或区域,显著性目标检测在许多计算机视觉任务中有着广泛的应用。例如,图像分类[1]、语义分割[2]、行人检测[3]、图像检索[4]、图像压缩[5]、视觉跟踪[6]等。随着深度传感器设备的普及,深度图的采集变得更加便利,推动了RGB-D 显著性目标检测的研究。针对该研究,主要存在以下问题,显著性检测是将图像中显著的区域检测出来,如何有效定位边缘清晰的显著区域是本文待解决的关键问题。此外,与RGB 图像相比,RGB-D 图像包含有颜色信息和深度信息,深度图作为RGB 的互补信息,包含丰富的空间结构以及形状信息,为显著性目标检测提供了更加丰富的信息,利用该信息有助于理解复杂的场景。但是,RGB和Depth属于不同模态,如何有效融合RGB和Depth信息是本文待解决的关键问题。
针对上述问题,早期的一些方法采用早期融合策略,Qu 等人[7]将手工RGB 和Depth 特征串联输入到网络中。Fan 等人[8]和Liu 等人[9]将深度图作为第四通道,与RGB 一起输入到网络模型中,采用单流网络模型架构进行学习。由于二者模态上存在差异,这种融合方式往往达不到好的效果。研究者们开始采用结果融合的方式[10-11]。采用双流网络模型架构,每个网络分别生成显著图,最后通过相乘、相加或者卷积运算生成最终的显著图。Wang 等人[12]采用结果融合策略,学习交换映射,自适应融合RGB 和Depth。由于两种数据在不同网络中进行特征提取,交互有限,这样的融合策略很难达到好的效果。因此,很多基于中间融合策略的方法被提出。例如,Chen等人[13]提出了一种多尺度多路径融合网络,改进了传统的单融合路径。Li 等人[14]提出深度特征加权组合模块(cross-modal depth-weighted combination,CDC),在每个层次上通过深度特征来增强RGB 特征,并提出一个信息转换模块,以交互式和自适应的方式融合高层的RGB 和Depth 特征。该方法虽然通过CDC 模块对RGB 和Depth 特征进行了一定的交互,但是模态交互有限,无法挖掘到更加复杂多模态交互特征,这样会导致后期融合得到的高层RGB 和Depth 特征有限。Fan等人[15]提出二分支主干策略网络(bifurcated backbone strategy network,BBSNet),两个网络分别对两种信息进行提取,使用相加对RGB 和Depth 特征进行融合。然后,采用二分支主干策略,把多尺度特征分为教师特征和学生特征,利用教师特征对学生特征进行指导学习。但是该网络前期模态融合简单,这样会导致提取得到的教师特征和学生特征不丰富,影响最终的检测效果。
针对上述存在的问题,本文提出一个跨模态特征融合模块,采用双流网络结构,将特征提取网络分为六部分,每部分采用跨模态特征模块对RGB 和Depth 特征进行充分融合,以获得更具共性和互补性的模态融合特征。该模块借鉴CDC 模块的Depth 特征对RGB 特征进行加权的思想,以突出显著区域与非显著区域的对比度。之后,将Depth 特征和增强的RGB 特征进行相乘、相加以及级联卷积运算,以完成二者之间的模态交互,创新性地引入注意力机制,使得网络关注有用的模态融合特征,提高融合稳定性。最后,加上一个残差连接分支,将原始RGB 特征与模态融合特征进行融合,有效避免低质量的深度图对模态融合特征造成的影响。
针对定位显著区域以及显著区域边缘模糊问题,受到Fan 等人[15]二分支主干策略的启发,高级语义特征具有丰富的语义特征有助于定位显著区域,底层特征具有丰富的细节信息,有助于改善显著区域边缘模糊问题。因此,提出一种高级语义修复策略,用于解决显著区域定位以及边缘模糊问题。
本文的工作不同于二分支主干策略,该策略将网络的后三层特征用于提取教师特征,将网络的前三层用于提取学生特征,利用教师特征对学生特征进行指导学习。本文将上述跨模态特征融合模块提取的模态融合特征的后三层用于提取高级语义信息,同样经过全局上下文模块(global contextual module,GCM)[15]对后三层特征进行进一步提取,本文采用拼接融合运算,具有更小的参数量和计算量,而二分支主干策略对提取后的特征进行不同层次的模态交互运算,增加了参数量和计算量。此外,本文的修复策略与二分支主干策略不同,本文采用U-Net[16]的网络结构,从网络的顶层向下融合,每一层经过上采样之后与下一层进行通道维度上的拼接融合。最后,前三层底层特征在融合前后采用高级语义特征修复,这样能充分利用高级语义特征对底层特征进行指导。本文的贡献如下:
(1)为了充分挖掘RGB 与Depth 的跨模态特征,本文提出一个跨模态特征融合模块,自适应地融合多模态特征,能够提取深度图中有效的信息,突出融合特征的共性和互补性,并降低融合的模糊度。
(2)为了提高显著区域的完整性以及边缘模糊问题,提出一种高级语义修复的策略,有助于准确检测出显著区域并提高边缘清晰度。
(3)实验结果表明,本文方法在五个公开的数据集上均达到了优秀的效果,达到了较为先进的性能。
1 相关工作
基于RGB-D 显著性目标检测,主要分为深度学习和传统方法。传统的方法主要利用对比的知识,通过计算颜色、边缘、纹理的对比得到图像中的显著区域。由于手工特征的局限性,效果往往不好。随着深度学习的不断发展,人们开始使用深度学习的方法进行显著性检测任务。Chen 等人[13]提出了一种多尺度多路径融合网络,改进了传统的单融合路径。Wang 等人[12]提出一个显著性融合模块,通过学习一个开关映射来自适应融合RGB 显著性预测。Li等人[17]提出一种交叉模态加权策略,以鼓励RGB 和深度通道之间的互动,提出三种深度交互模块,分别用来处理低、中、高层的跨模态融合特征。Li 等人[14]提出深度特征加权组合模块,在每个层次上通过深度特征来增强RGB 特征,并提出一个信息转换模块,以交互式和自适应的方式融合高层的RGB 和Depth特征。Fan 等人[15]提出一种二分支主干策略,使用相加对RGB 和Depth 特征进行融合。然后,把多尺度特征分为教师特征和学生特征,利用教师特征对学生特征进行指导学习。Li 等人[18]提出了一种注意力引导的融合网络,通过注意力引导机制逐步融合RGB 图像和深度图像中的跨模态、跨层次的互补性,对RGB-D 图像中的互补特征进行联合提取,并以密集交织的方式进行层次化融合。Fu 等人[19]采用一个共享网络同时对RGB 和Depth 进行特征提取,并提出联合学习和密集合作融合模块,进行显著性检测。Chen 等人[20]针对编码阶段的预融合和解码阶段的深度融合,提出了编码器和解码器的渐进融合策略,有效利用了两种模式的相互作用,提高了检测精度。Li等人[21]提出分层交互模块,该模块利用RGB 特征过滤掉Depth 特征中的干扰信息,然后使用过滤后的Depth 特征依次对RGB 特征进行增强,RGB 与Depth的交互分层进行。Jin 等人[22]提出一种新的互补深度网络来更好地利用显著的Depth 特征。
本文方法与上述方法不同,首先提出一个跨模态特征融合模块用来逐层提取丰富的跨模态融合特征。之后,基于该模块提取的融合特征,提出一种高级语义修复策略,将后三层融合特征用于提取高级语义信息,以U-Net[16]的网络结构,逐步向下融合,之后利用高级语义特征对前三层低层特征进行修复,从而检测出边缘清晰定位准确的显著图。
2 本文方法
针对跨模态融合问题、显著区域不完整以及边缘模糊问题,本文提出的解决方法,将在本章进行介绍。首先介绍网络的整体架构,接着阐述跨模态特征融合模块以及高级语义修复策略的主要思路以及具体实施过程。最后,介绍优化网络模型所使用的损失函数。
2.1 网络架构
本文提出的基于高级语义修复策略的跨模态融合RGB-D 显著性目标检测网络的架构如图1 所示,将该网络命名为SRMFNet(advanced semantic repair strategy for cross-modal fusion salient detection network)。
该网络架构以EfficientNet-b0[23]为主干网络,构建双流网络结构,分别用来提取RGB 和Depth 特征。Conv1~Conv6 表示EfficientNet-b0[23]的不同层,作为侧输出。每个侧输出经过跨模态特征融合模块进行特征融合,最终得到不同层次的模态融合特征。模态融合特征Slid4~Slid6 用于提取高级语义特征,并生成图1 所示的显著图Salient map 1。之后采用U-Net[16]网络结构,从网络的顶层向下融合,每一层经过上采样之后与下一层进行通道维度上的拼接融合,Slid1~Slid3 在融合前后采用高级语义特征修复,最终生成图1 所示的显著图Salient map 2。
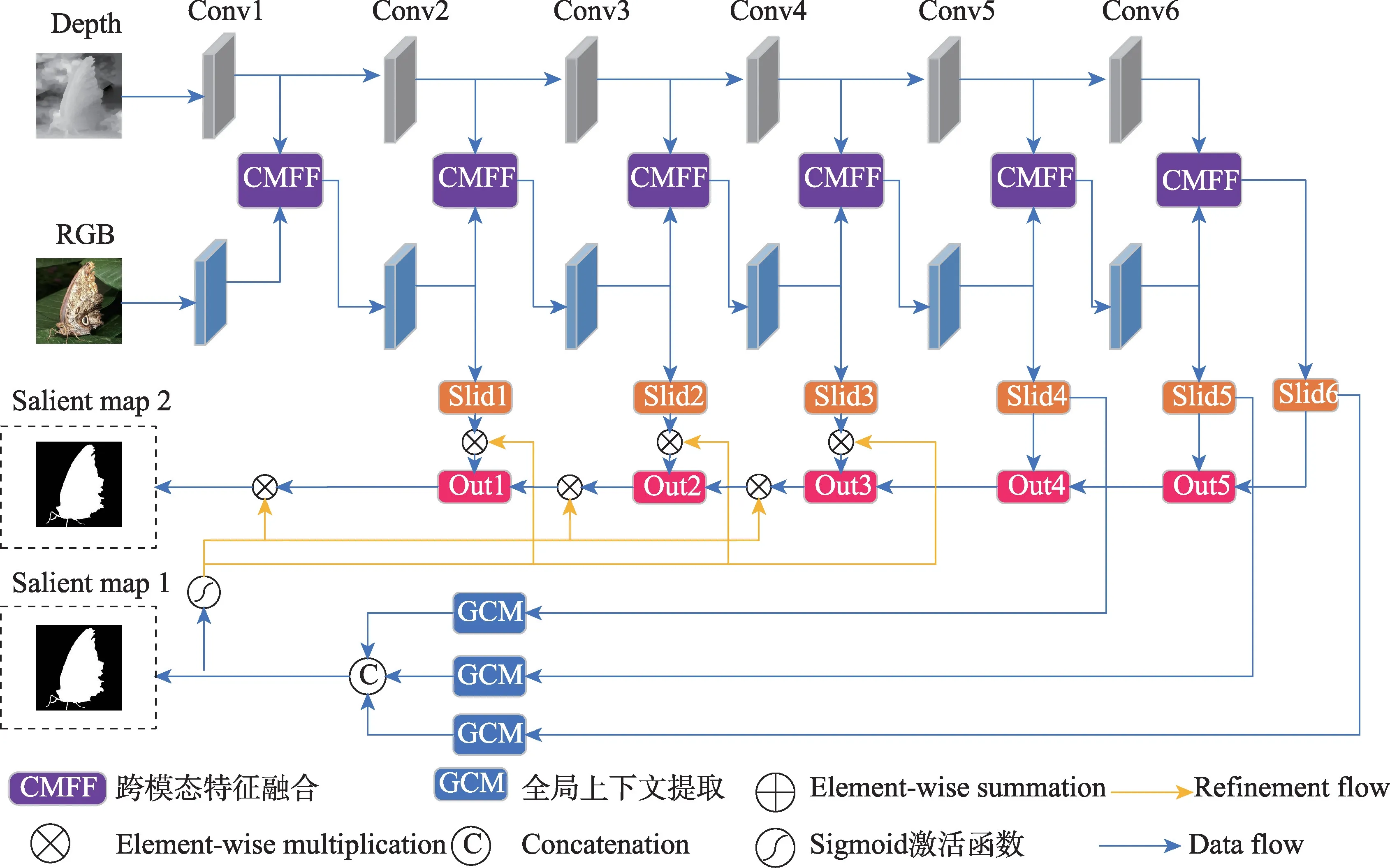
图1 高级语义修复策略的跨模态融合网络结构Fig.1 Cross-modal fusion network architecture for advanced semantic repair strategies
2.2 跨模态特征融合模块
由于RGB 和Depth 特征模态之间存在差异,深度图主要关注物体间空间距离,而RGB 主要负责捕获颜色和纹理信息,简单的融合操作,无法提取到复杂的多模态交互特征。受到信息转换网络(information conversion network,ICNet)[14]的CDC 模块的启发,深度特征可作为注意图对RGB 特征进行加权。本文借鉴该思想,首先利用深度特征计算得到深度注意图,然后利用深度注意图对RGB 特征进行加权,以获得增强的RGB 特征,以增强显著区域与非显著区域的对比度,避免显著目标丢失。将增强后的RGB 特征与Depth 特征进行相乘、相加以及级联卷积运算,充分挖掘模态交互特征,突显它们之间的共性和互补性。之后将三个融合操作结果进行通道维度上的拼接,得到跨模态融合特征输出。考虑到不是所有的模态融合特征都是有效的,因此,引入通道和空间注意力机制[24],使得网络能更加关注有用的模态融合特征,进而提高模态融合的稳定性。最后,考虑到低质量的深度特征对融合特征的影响,因此,加入一个残差边,将原始的RGB 特征与模态融合特征进行相加。即使深度图的质量不好,也能利用RGB 信息进行后续的特征提取,能有效避免了低质量的深度图对融合特征造成的影响。
本文的跨模态特征融合模块如图2 所示,主要有两个分支,一个模态融合分支,一个残差连接分支。假设,Srgb、Sd分别表示RGB 和Depth 特征提取网络的侧输出,具体操作如下所示:

图2 跨模态特征融合模块Fig.2 Cross-modal feature fusion module
(1)Depth 特征经过1×1 卷积运算,把通道数降为1,使用Sigmoid 激活函数生成Depth 特征注意图,对RGB 特征进行加权,得到增强后的RGB 特征,具体过程可表示为:

其中,Re表示增强后的RGB 特征;S(·)表示Sigmoid激活函数;Conv1-1(·)表示卷积核大小为1×1,通道数为1 的卷积;⊙表示逐像素相乘。
(2)将增强后的RGB 特征与Depth 特征进行相乘、相加以及级联卷积运算。然后将三个支路的结果进行通道维度上的拼接,具体过程可表示为:
^

(3)为了保证跨模态融合的稳定性,在融合之后引入一个串联的通道和空间注意力[24]。具体操作如下:


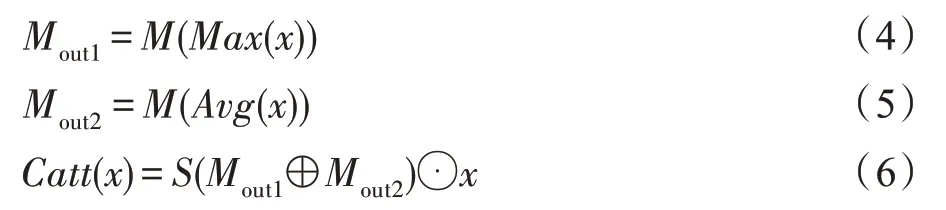
其中,x代表输入的特征图;Mout1、Mout2表示经过感知器特征提取的输出;S(·)表示Sigmoid 激活函数;M(·) 表示三层感知机;Max(·) 表示全局最大池化;Avg(·)表示全局平均池化;⊙表示逐像素相乘操作。空间注意力的具体操作为:
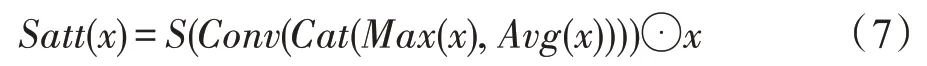
其中,x代表输入的特征图;S(·)表示Sigmoid 激活函数;Conv(·)表示卷积运算;Cat(·)表示通道维度上的拼接;Max(·)表示全局最大池化;Avg(·)表示全局平均池化;⊙表示逐像素相乘;⊕表示逐像素相加。
(4)为了避免低质量的深度图对融合特征的影响,加入一个残差边,与模态融合后的特征进行相加融合。具体操作如下所示:

其中,Fout表示跨模态特征融合输出;Fcat表示跨模态融合分支输出;Srgb表示原始的RGB 特征。
2.3 高级语义修复策略
基于上述跨模态特征提取模块提取到的多层次模态融合特征,本文提出一种高级语义修复策略,提高显著区域定位准确度以及边缘清晰度。受到二分支主干策略网络[15]的启发,高层特征具有较丰富的语义特征,能够有效定位显著区域,低层特征包含着丰富的细节信息,能够有效改善显著区域边缘模糊问题。利用高级语义信息定位显著区域,底层特征用于修复显著区域边缘,从而使得网络能检测出显著区域完整且边缘清晰的显著图。
本文的高级语义修复策略,首先利用模态融合特征Slid4~Slid6 提取高级语义信息。为了进一步提取全局信息,引入BBSNet[15]的GCM 模块,如图3 所示,该模块由四个并行分支组成,每个分支都采用一个1×1 卷积,将输入特征通道降低到32,对于k∈{2,3,4}分支,采用卷积核为2k-1 的卷积操作,紧接着进行卷积核为3、膨胀率为2k-1 的卷积运算。然后将四个分支的输出进行通道上的拼接,最后与最初的输入进行残差连接。
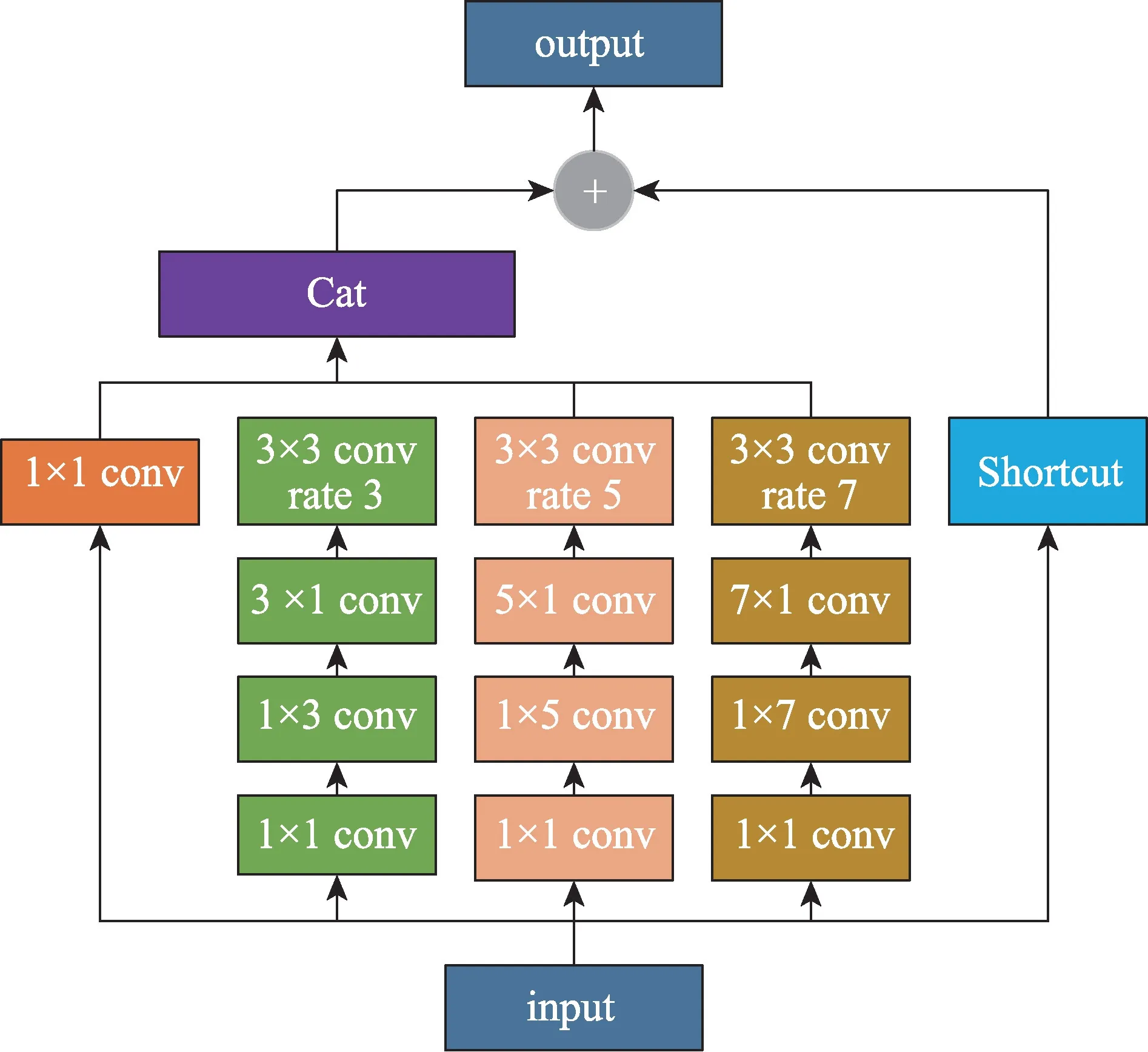
图3 全局上下文提取模块Fig.3 Global context extraction module
与BBSNet[15]提取教师特征不同,本文将GCM 模块提取到的三个分支特征,直接进行通道维度上的拼接融合,没有进行不同层次的模态交互运算,大大减小了计算量和参数量。具体操作如下所示:

其中,Conv(·)表示卷积运算;Cat(·)表示通道维度上的拼接;GCM(·)表示全局上下文提取操作;Fhs表示高级语义特征输出。
本文的修复策略如图1 所示,采用U-Net[16]的网络结构,自顶向下融合的过程中,需要将每一层的特征图分辨率上采样到下一层特征图的分辨率大小,然后进行通道上的拼接。当融合到Slid1、Slid2、Slid3时,融合之前使用具有高级语义信息的注意图,对Slid1、Slid2、Slid3 进行相乘操作。融合之后再进行同样的修复操作,具体操作如下所示:


其中,Fouti_j表示不同层的融合输出,i∈{5,4,3,2},j∈{6,5,4,3};Slidk表示不同层次的跨模态融合特征,k∈{1,2,3,4,5,6};Fhs表示具有高级语义的特征输出;⊙表示逐像素相乘;S(·)表示Sigmoid 激活函数;Up(·)表示两倍上采样;Cat(·) 表示通道维度上的拼接;Conv(·)表示卷积运算。
2.4 损失函数
假设W、H为输入图片的宽和高,则对应的网络输出的初始显著图S1∈[0,1]W×H×1,最终的显著图S2∈[0,1]W×H×1,其对应的标签G∈[0,1]W×H×1。总损失计算公式如下所示:

Lce表示二值交叉熵损失函数,具体计算公式如下:

其中,S表示预测的显著图,G表示对比标签。
3 实验
3.1 实验设置
本文模型基于PyTorch[25]框架实现,在一块2080Ti GPU 上进行训练。使用ImageNet[26]上的预训练权重来初始化本文的主干网络EfficientNet-b0[23]的参数。两个特征提取网络之间不共享权重。使用Adam 优化器[27]进行端到端的训练。初始学习率设为1E-4 并且每隔40 轮调整至原来的10%。使用二值交叉熵损失函数作为监督。所有训练和测试的图像尺寸大小统一设置为352×352。为了避免过拟合,提高模型的鲁棒性,在训练阶段采用随机翻转、旋转和裁剪等数据增强策略对训练数据进行增强。训练批次大小设置为10,训练模型120 轮大约需要4 h,得到最终的模型。
3.2 数据集
为了评估本文的网络性能,本文在7 个数据集上进行了实验。
NJU2K[28]总共有1 985 张图片,立体图像来自互联网和3D 电影,照片使用Fuji W3 照相机拍摄,其中训练集1 400 张,验证集100 张,测试集485 张。
NLPR[29]总共有1 000 张图片,由Kinect 在11 个场景下拍摄得到,其中训练集650 张,验证集50 张,测试集300 张。
STERE[30]共有1 000张立体图片,从互联网下载得到。
SIP[8]共有1 000张图片,由一部智能手机拍摄得到。
DES[31]总共135 张室外图像,由Microsoft Kinect拍摄得到。
LFSD[32]总共100 张图片,由Lytro 相机拍摄得到。
SSD[33]总共80 张图片,从三部立体电影中挑选得到。参照文献[34-35] 的训练策略,使用1 485 张NJU2K 的图像和700 张NLPR 的图像用于训练,其余样本用于测试,为了公平比较,本文将在该数据集训练的模型应用于其他测试数据上。
3.3 评价指标
为了评估本文方法,使用5 个广泛使用的评价指标:MAE、S-measure、E-measure、F-measure、P-R曲线。
(1)平均绝对误差(MAE),显著图与真值图逐像素之间绝对误差的均值,计算公式如下所示:

其中,m和n分别表示图像的宽和高;pij表示显著性概率结果;yij表示真值。MAE值越小表示模型性能越好。
(2)S-measure比较结构相似信息,其中so为物体结构相似性,sr为区域结构相似性,α为平衡参数,取值为0.5。计算公式如下所示:

(3)E-measure 增强匹配指标,基于认知视觉的研究来获取图像层次的统计信息及其局部像素匹配信息。
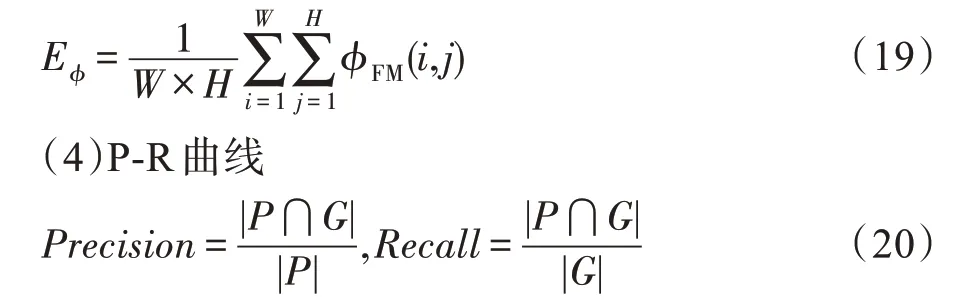
其中,P为二值化的显著预测图,G为Ground Truth。
通过设置阈值得到二值化的显著预测图P,通过上式计算得到一对Precision、Recall。阈值取值为0~255,不同的阈值,对应不同的P-R 对,总共有256个P-R对。以P为纵坐标,R为横坐标,构成P-R曲线。
(5)F-measure
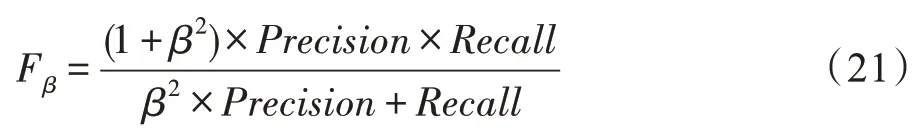
β2一般取值为0.3,每一对P-R,都可计算出一个Fβ,本文选取最大值作为评价指标。评价代码采用的是http://dpfan.net/d3netbenchmark/中提供的matlab 版本。
3.4 结果分析与比较
3.4.1 实验过程分析
图4 所示为模型在训练阶段的Loss 变化曲线和验证阶段的MAE 变化曲线。由曲线的趋势可以看出,模型在20 个Epoch 迭代以内训练损失以及验证集上的MAE 指标迅速下降,模型快速收敛,且在训练过程中未出现大幅度的抖动,比较平缓。随着迭代次数的增加,损失和MAE 指标不断降低,表明了本文提出的模型训练更加稳健。

图4 训练的Loss变化曲线和验证的MAE 变化曲线Fig.4 Loss change curve of training and MAE change curve of verification
3.4.2 结果对比
表1 展示了本文在7 个数据集上4 个评价指标MAE (M)、max S-measure (Sα)、max E-measure (Eξ)和max F-measure(Fβ)上的对比结果。表2 详细地列出了不同方法的模型大小,在这些先进的方法中,本文方法模型最小,比第二小的模型节省了24.6%的参数量。图5 和图6 展示了P-R 曲线和F-measure 曲线,本文方法用红线表示。这些方法所有的显著图都是由论文作者提供,或者根据他们提供的代码计算得到。

表1 不同方法的评测结果Table 1 Evaluation results of different methods

表2 不同方法的模型大小Table 2 Model size of different methods
如表1 所示,↑(↓)表示越高(低)越好。每行最好的结果用加粗表示,次优的结果用下划线表示,每个方法的下标表示出版年份。本文方法在四个评价指标、五个数据集上都取得了最好的结果。在SSD、LFSD 数据集上本文方法在Sα、Fβ、Eξ指标上处于次优,MAE 指标排在第三。
如图5 和图6 所示,展示了不同算法的P-R 曲线和F-measure 曲线。可以看到,在NJU2K、NLPR、STERE、DES、SIP 五个数据集上,本文方法的曲线明显高于其他方法。在LFSD 这个数据集上,本文曲线与先进算法基本持平。在SSD 数据集上,略低于先进算法。通过详细的定量比较可以看出,本文方法在精度和模型大小上都有明显的优势。
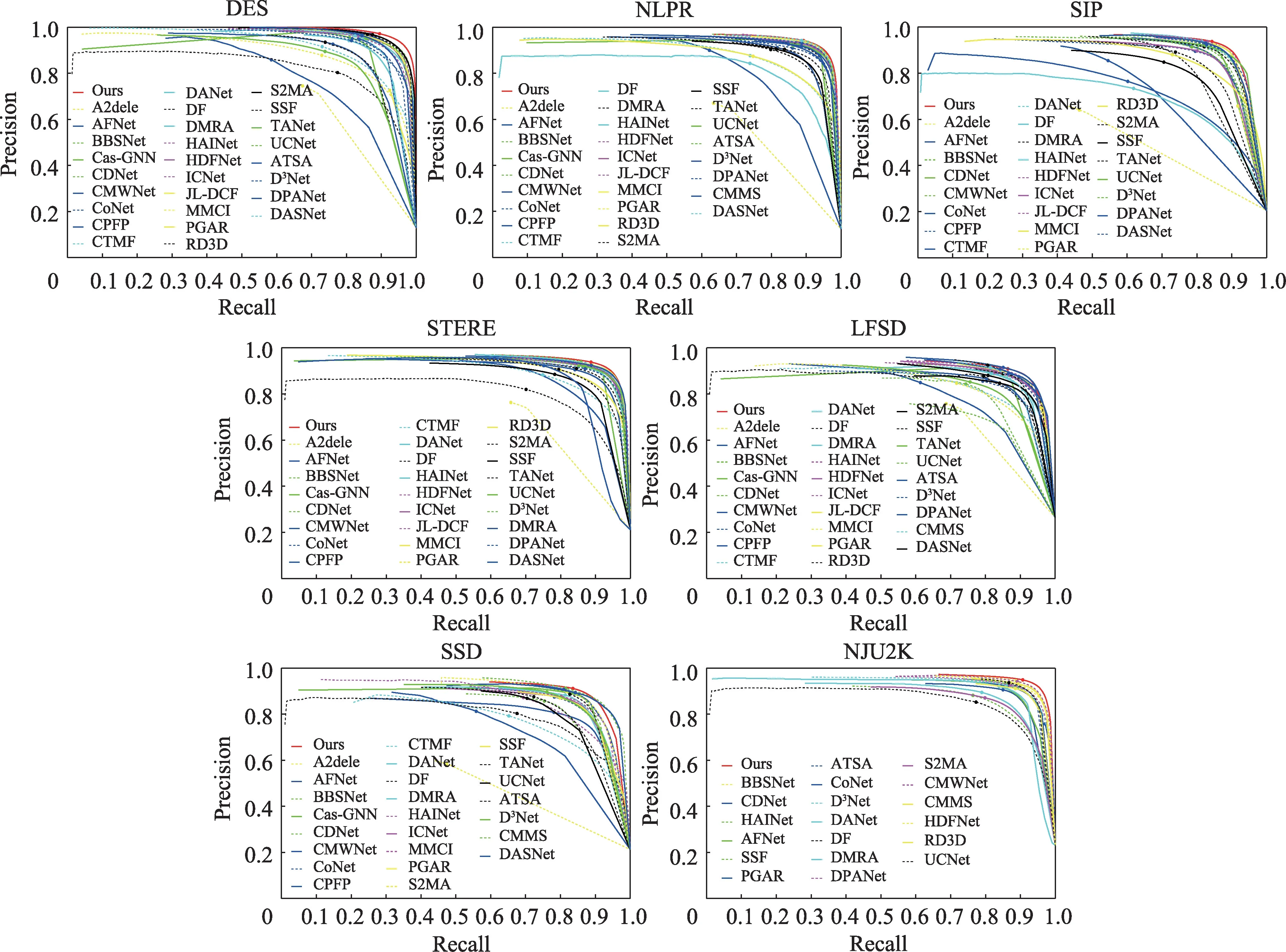
图5 不同算法在7 个数据集上的P-R 曲线Fig.5 P-R curves of different algorithms on 7 datasets

图6 不同算法在7 个数据集上的F-measure曲线Fig.6 F-measures of different algorithms on 7 datasets
3.4.3 视觉对比
图7 展示了本文方法和一些先进方法生成的显著图的视觉对比。将这些图像主要分为(a)简单场景、(b)小物体、(c)多物体、(d)复杂背景和(e)低对比度场景。

图7 本文方法和一些先进方法的视觉对比Fig.7 Visual comparison between method presented in this paper and some advanced methods
(a)图展示两个简单场景的图像。很多算法不能将椅子完整地检测出来,本文提出的高级语义修复策略能有效提高检测的准确度,完整地将椅子检测出来。
(b)图展示了三个小物体图像。如第一行的人,很多算法能把人作为显著性对象检测出来,但是都不能把人双腿之间的间隔检测出来,然而本文方法仍然能够准确地检测出来,第二行的小猫、第三行的蝴蝶图像,本文方法依然能将蝴蝶的脚这样的细节部分检测出来。
(c)图展示两个包含多个物体的图像。本文方法能够检测出所有的显著目标,并且能够很好地把它们分割出来。可以看出(c)图中第一行的深度图像没有清晰的信息,本文方法也能够将所有显著物体检测出来。
(d)图展示的是两张具有复杂背景的图像。尽管(d)图中第一行的深度图质量很差,但是本文方法受益于跨模态特征融合模块,不受低质量深度图的影响,能够自适应地融合Depth 特征中有效信息。很多方法受到复杂背景的影响,把背景作为显著物体的一部分,不能准确检测出来,本文采用了高级语义修复策略,准确地将显著物体检测出来。
(e)图展示了两张低对比度的图像,本文方法能够抑制背景的干扰并从深度图中提取有用的信息,尤其是最后一行,深度图提供的信息,蘑菇的下面部分的深度信息质量差,前景信息与背景信息分离很不明显。很多算法不能将蘑菇的下面部分检测出来,本文算法不被质量较差的深度特征影响,提取有用的深度特征,有效融合RGB 和Depth 特征,能够精准地将显著物体检测出来。
3.5 消融实验
本文以EfficientNet-b0[23]为主干网络,将RGB 和Depth 相加融合的网络作为基线,分析各个模块的贡献。所有模型都是用相同的超参数和训练集进行训练。为了证明它们的泛化能力,本文在7 个数据集上展示实验结果。
(1)高级语义修复策略的有效性
本文在基线网络的基础上加上高级语义修复策略,从表3 中数据显示以及图8 展示,使用Baseline 网络生成的显著图不能将显著物体完整检测出来,而使用高级语义修复策略能有效定位显著区域并提高边缘清晰度,该方法有效提升了网络的性能。

表3 高级语义修复策略消融结果对比Table 3 Comparison of ablation results of advanced semantic repair strategies
(2)跨模态特征融合的有效性
本文在上个消融实验的基础上加上跨模态特征融合模块,通过表4 中数据显示以及图8 展示,由于本文使用跨模态融合模块,能有效利用深度图所提供的细节信息,抑制干扰信息,共同检测出图像中的显著区域。从表格中的结果对比可以看出,本文所提出的跨模态特征融合模块能有效提高网络的性能。

图8 模块消融视觉对比Fig.8 Visual contrast of module ablation

表4 跨模态特征融合模块消融结果对比Table 4 Comparison of ablation results of cross-modal feature fusion modules
(3)本文跨模态特征融合模块与深度特征加权组合模块消融对比
从表5 的数据显示,本文提出的跨模态特征融合模块能有效融合RGB 和Depth 特征,模态交互分支能提取到更具共性和互补性的融合特征,引入的注意力机制能更加关注有用的融合特征,加入的残差连接分支,能避免低质量的深度图对融合特征的影响,提高网络的性能。从表中数据可以看出,本文提出的模块具有更大的优势。
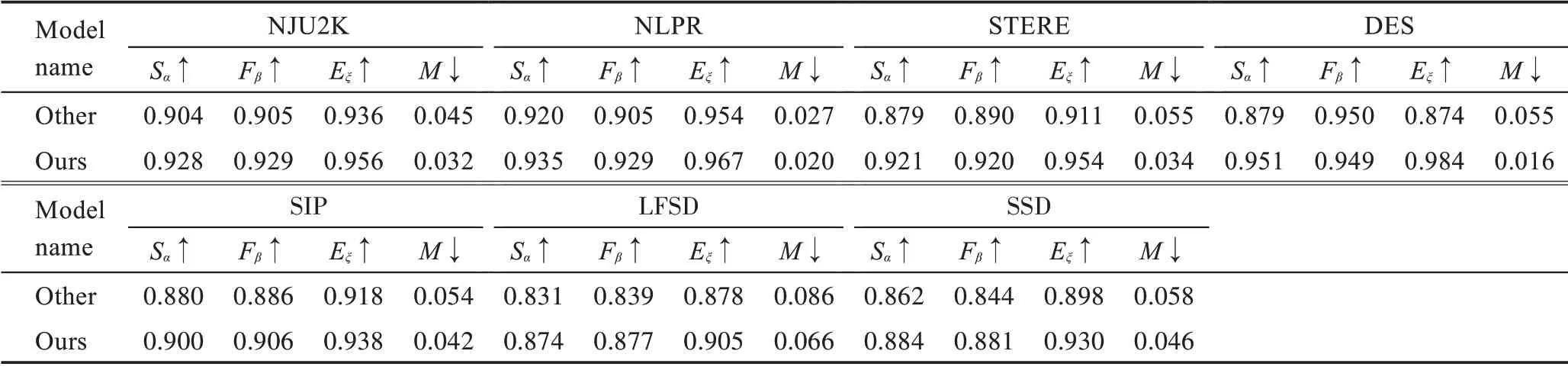
表5 跨模态特征融合模块与CDC 模块结果对比Table 5 Comparison of results between cross-modal feature fusion module and CDC module
(4)本文高级语义特征提取与BBSNet 教师特征提取消融对比
从表6 的数据中显示,本文提取高级语义特征的方法得到的结果更好。相较于BBSNet[15]提取教师特征的方法,本文方法需要更少的参数量和计算量,具有更大的优势。
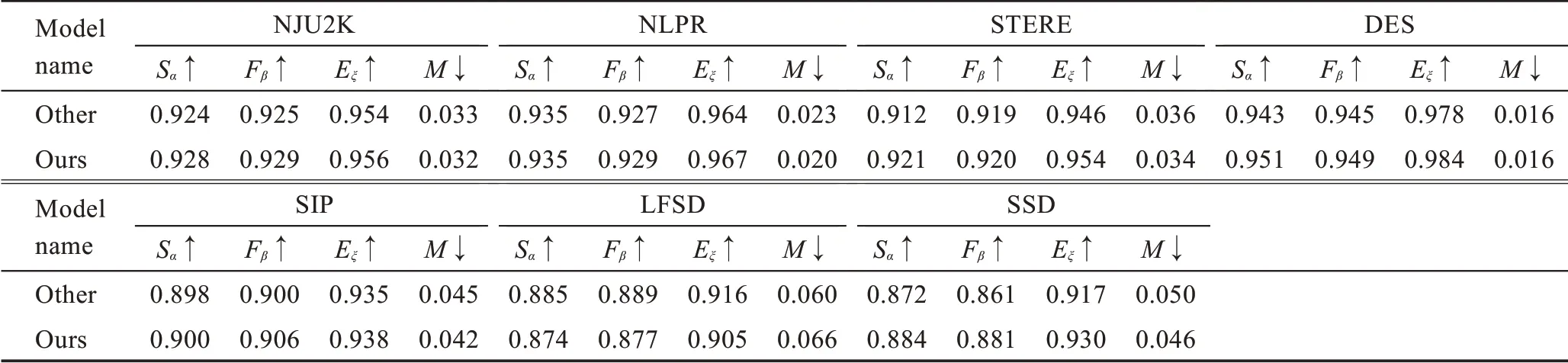
表6 高级语义特征提取与BBSNet教师特征提取对比Table 6 Comparison of advanced semantic feature extraction and BBSNet teacher feature extraction
(5)不同主干网络的性能测试
不同主干网络结果对比如表7所示。现有的RGBD 显著目标检测模型主要采用VGG(visual geometry group)[38]、ResNet(residual network)[39]系列网络作为主干网络,本文采用EfficientNet-b0[23]作为主干网络,主要考虑为了节省参数量,构建轻量级的RGB-D 显著性目标检测模型。为了证明本文方法的扩展性,表7展示了不同主干网络在4 个评价指标、7 个数据集上的max S-measure、max F-measure、max E-measure 以及MAE 上的对比结果。结果显示,尽管本文方法使用其他主干网络,仍然能超过很多先进算法。表8 展示不同主干网络的模型大小。数据显示,尽管本文使用了不同的主干网络,本文方法在模型大小上还是较小的。

表7 不同主干网络结果对比Table 7 Comparison of results from different backbone networks

表8 不同主干网络模型大小对比Table 8 Comparison of model sizes of different backbone networks
4 结束语
本文提出基于高级语义修复策略的跨模态特征融合的RGB-D 显著目标检测方法,该方法受益于跨模态特征融合模块、高级语义修复策略的网络框架。跨模态特征融合模块有效地将RGB 和Depth 特征进行自适应的融合,不会受到低质量深度图的影响,能有效地从深度图中提取到深度信息,进而辅助RGB 特征进行显著性特征提取。利用高级语义特征能够有效定位显著区域,低层特征具有丰富细节信息,联合底层特征,从而检测出边缘清晰、显著区域完整的显著图。本文方法在五个数据集上均达到了较为先进的性能。此外,本文方法同样也可适用于目标检测、语义分割、图像分类等方面的研究。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
上海师范大学学报·自然科学版(2021年4期)2021-09-23
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
开放教育研究(2020年2期)2020-03-31
计算机应用(2019年3期)2019-07-31
软件导刊(2016年9期)2016-11-07
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
科技视界(2016年2期)2016-03-30
