
基于BERT的嵌入式文本主题模型研究
2023-01-13 11:58王宇晗李艳玲赵佳鹏
计算机工程与应用 2023年1期
王宇晗,林 民,李艳玲,赵佳鹏
1.内蒙古师范大学 计算机科学技术学院,呼和浩特 010022
2.中国科学院大学 网络空间安全学院,北京 100089
3.中国科学院 信息工程研究所,北京 100089
LDA(latent Dirichlet allocation)主题模型[1]是一种有效的统计语言模型,能够对海量文本数据进行建模并反馈规定主题数的词语聚类,在文本分类[2]、话题演化[3]、文本自动摘要[4]等任务中有着广泛的应用。但LDA及其扩展模型采用词袋文本模型抽取主题词,无法建模词语之间的语义和序列关系,并且忽略了停用词与长尾词,极大限制了生成主题词的可解释性[5]。为了有效解决词袋模型存在的问题,文献[6]通过使用词嵌入(word embedding)模型Word2Vec构造了一种嵌入式主题模型(embedded topic model,ETM)[7],能够考虑到词与词之间的关系,并能拟合出更具可解释性的主题。但Word2Vec只考虑单词的固定大小的上下文窗口,在获取文档全局语义信息方面存在困难,并且将处于不同语境的同一词汇综合表示成一个向量。这种上下文不敏感的静态表示方法不能获取文本中多义词在不同语境下的语义差异,难以检测到领域主题之间存在的细粒度的区别。针对以上问题,本文提出将BERT(bidirectional encoder representations from transformers)模型[8]有效融入ETM。BERT模型解决了Word2Vec等模型的聚义问题,该模型能够通过大规模语料的训练生成对上下文语境敏感的词向量,多义词在不同语境中动态地生成词的语义表示,一词多义问题得以有效解决。本文提出构建一种基于BERT的嵌入式主题模型,称为BERT-ETM模型。BERT-ETM既能获取到充分结合上下文特征的词嵌入,解决一词多义问题,又能挖掘出高质量、细粒度的文档主题词表示,对大规模文本十分有效。
本文首先介绍了模型的构建方法,然后为了验证本方法的有效性,比较了BERT-ETM和ETM的主题一致性和多样性,发现BERT-ETM的主题一致性、多样性乘积明显提升;为验证BERT-ETM能够解决一词多义问题,计算了不同语境下多义词向量之间的夹角余弦值,发现多义词能够结合上下文信息学习到动态的词嵌入;为验证结合中文分词的BERT模型能够获取更细粒度的主题词,本文将以词为单位的WoBERT-ETM与传统BERT-ETM获取到的主题词进行对比,在实验部分对这些方法做了详细描述。
1 相关工作
1.1 BERT词嵌入模型
自文献[9]提出神经概率语言模型(CBOW和Skipgram)以来,词嵌入成为词汇的分布式表示学习中最具代表性的方法。文献[6]提出的Word2Vec是比较常用的一种词嵌入模型,通过将词汇编码为一个语言特征空间中的低维度稠密向量,将文本语料中的词语训练为分布式向量表示,能够捕获隐藏在单词上下文中的语法、语义信息。很多学者将Word2vec应用于中文信息处理任务,例如,文献[10]提出使用Word2vec训练微博短文本词向量,并引入TF-IDF模型对词向量加权,将加权词向量应用于短文本分类任务;文献[11]提出一种将Word2vec和双向长短时记忆循环神经网络(long shortterm memory,LSTM)结合的情感分类模型,并取得了不错的效果。但以上方法将处于不同语境的词汇综合表示成一个静态的词向量,生成的词嵌入与词是一一对应的,仅学习到了词的表层特征,不能获取文档全局语义信息,不能表达一词多义。
为了有效学习词向量的多种含义,解决一词多义问题,文献[8]提出了BERT模型。BERT使用能捕捉语句中的双向关系的Transformer编码器[12]作为算法的主要框架,利用注意力机制对句子进行建模,使用掩蔽语言模型(masked language model,MLM)和预测下一句(next sentence prediction,NSP)的多任务训练目标进行预训练,并通过细调的方法将模型应用到其他特定任务,得到语义更丰富的词向量表示。目前很多学者也对BERT模型进行了改进,例如,文献[13]提出的Roberta使用字节进行编码以解决未登录词的问题。文献[14]提出了BERT-wwm模型,即对整个词都通过Mask标签进行掩码,而不仅仅是对子词进行掩码。文献[15]提出SpanBERT模型,将预训练方法改进到分词级别,不再对单个词项进行掩码,而是随机对邻接分词添加掩码。但以上都是基于英文词特性进行改进的,即以英文的每一个字单元进行训练。而中文和英文特性不同,中文中最小的Token是字,词由一个或多个字组成,每个词之间没有明显的分隔,并且包含更多信息。为进一步改进BERT模型在中文NLP任务上的训练效果,文献[16]预训练并开源了以词为单位的中文BERT模型,称为WoBERT,基于词的WoBERT能够明显提升训练速度,在融合词信息的同时也提升了拟合效果。因此本文构建了BERT-ETM和WoBERT-ETM两个模型,并对比二者获取的词嵌入效果以及拟合的主题词效果。
1.2 主题表示及主题词抽取方法
最早研究从词向量空间采样的主题模型始于2015年文献[17]提出的GLDA模型,GLDA将词向量代替离散的词汇作为观测变量,使用多元高斯分布采样主题-词分布,相较于LDA模型提高了主题词的语义一致性。随后,词向量增强的思想也被应用于主题词的抽取,LFTM[18]、GPU-DMM[19]、GPU-LDA[20]等模型在文本生成过程中将语义相似的词以更大概率分配到同一主题下,大幅度提升了模型性能。但这种方法并没有从主题层面上对模型进行优化。许多学者因此提出了结合主题模型与语言模型的联合训练模型,如文献[21]提出的主题词向量模型TWE,将LDA与词向量模型相结合,从同一语料中同时训练出词和主题的向量表示,并以两者的拼接作为主题词的向量表示,但它直接使用LDA生成主题词,忽略了词序列之间的依赖关系,获得的主题词的语义一致性效果一般。国内也在主题词的生成方面进行了多种探索,例如,文献[22]提出使用Word2Vec训练词向量并使用LDA训练短文本向量,通过向量拼接构建词向量与LDA相融合的短文本表示模型用于短文本分类,解决了特征稀疏问题;文献[23]则提出先利用LDA抽取主题词,再用Word2Vec训练词向量,通过词向量相似度传播构建关键词网络,利用网络结构分析方法对主题词进行二次提取,能够获取更多低词频高主题相关的词。但目前这些使用词向量建模的主题模型并没有在拟合主题时对主题进行嵌入表示,而且不擅长捕获稀有词的分布和语言数据的长尾,不能对停用词建模,在处理大型文本集合时,通常需要删除稀有词和停用词,才能拟合出预测性和解释性良好的主题模型。而稀有词中存在某些重要词汇,对于区分话题非常有帮助,停用词也含有使句子具有可读性的句法信息,这种删减可能会删除文本重要的词而限制模型的应用范围。针对这一问题,Dieng等人[7]提出将Word2Vec和LDA相结合的嵌入式主题模型ETM,通过神经网络的训练可以考虑到长尾词的含义,也可以通过加入预训练好的词嵌入从而不受语料中停用词的影响,构建出更具有可解释性的主题[24-25],并且也能够在训练主题词过程中拟合出主题嵌入。如图1展示了ETM的主题-词可视化分布图,数字表示主题序号,语义相近的词环绕在对应主题的Topic四周,形成一个簇。可以看出,Topic33是关于学生信息的一个主题。

图1 ETM主题-词可视化分布图Fig.1 Chart of ETM topic-word visual distribution
但ETM使用Word2Vec这种上下文不敏感向量表示方法,获取到的静态词向量不能表达文本中同一单词在不同语境下的语义差异,难以检测到主题之间存在的细粒度的区别。通过对相关工作进行分析,本文提出将BERT模型融入到ETM的训练过程中,获得充分结合词汇上下文特征的动态词向量从而提取更全面的特征,解决一词多义问题。
2 BERT-ETM模型的构建及主题词生成方法
基于BERT的嵌入式主题模型流程框架图如图2所示。本模型关键步骤如下:首先,对数据集进行预处理,进行分句、分词等操作;其次,统计每篇文档中的词频,同时,使用BERT模型训练文本,获取BERT模型结合领域文本生成细调后的词嵌入表示;然后将文档词袋表示和词嵌入输入给BERT-ETM,其中文档词袋表示在推断网络进行训练,词嵌入在生成网络进行训练;最后,通过BERT-ETM变分自编码器的训练,得到文档的主题词表示。

图2 BERT-ETM流程框架图Fig.2 Flow framework chart of BERT-ETM
2.1 文档词袋表示及词嵌入生成方法
得到预处理的数据后,将文本按行输入给BERT模型进行词向量的训练。BERT在训练时的单元为token,即为字,输入编码向量是字向量、句向量和位置向量三个嵌入特征的融合。以输入文本句子“软件还可以分为通用软件和定制软件”为例,BERT的输入表示如图3所示。其中,其中特殊符号[CLS]表示该特征用于分类模型,对于非分类模型,该符号可以省略;[SEP]表示分句符号,用于断开输入语料中的两个句子。

图3 BERT-ETM模型输入表示Fig.3 Input representation of BERT-ETM model
传统BERT以字为单位,在中文日常使用中却习惯以包含更多语义信息的词为基本单位。为探究以词为单位和以字为单位训练BERT词向量的差异,本文将BERT的一个变体——WoBERT模型也用于生成词嵌入。WoBERT以中文词为单位,将处理输入文本时的Tokenizer进行修改,加入了一个“预分词(Pre_tokenizer)”操作,避免Tokenizer强行把中文字符用空格隔开。输入文本数据后,首先使用jieba进行自动分词,然后对分词的文本进行Pre_tokenizer,得到符合实验需要的中文词,将每个词用BERT自带的Tokenizer切分为字,然后用字向量的平均作为词向量的初始化。以同样的句子为例,WoBERT的输入表示如图4所示。
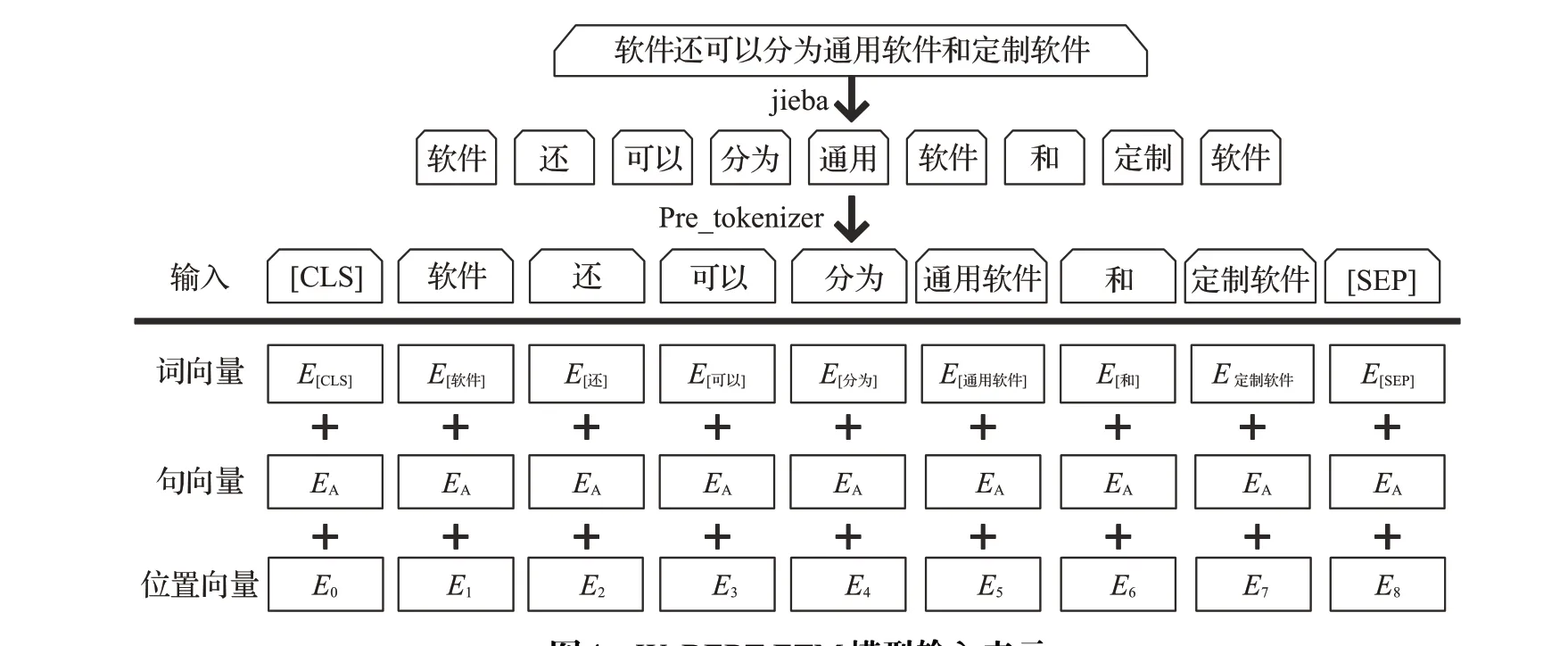
图4 WoBERT-ETM模型输入表示Fig.4 Input representation of WoBERT-ETM model
获取BERT模型结合领域文本生成细调后的词嵌入表示过程如算法1所示。将文本输入给BERT预训练模型,获取到文本词向量表示后,为了使词向量能结合领域文本学习到更多的语义信息,将词向量进一步细调,同时通过比较词向量之间的相似度来进一步区分多义词与其他词。以多义词“苹果”为例,在语句“苹果公司发布了官方的人机界面指南”中,苹果的语义为美国的一家科技公司,而在语句“常见的水果有苹果、香蕉等”中,苹果的语义为水果,两个“苹果”在BERT模型下的词向量相似度为0.70,在WOBERT模型下的词向量相似度为0.69,因此将相似度阈值设置为0.75,用于判断多义词。比较词wi当前生成的词向量wti和前一次生成的词向量wt-1i的相似度,以0.75作为阈值,如果相似度大于0.75,将两个词向量取平均,用以生成结合更多语义信息的词向量;如果相似度小于等于0.75,则说明当前词是一个一词多义词,将当前的词向量wti另存为wti -1#,表示为词的另一个含义,并将对应在语料句子中的该词也同步添加#,方便后续主题词的生成与区分。
获取到文档的词嵌入表示后,将每个文档的词袋表示和词嵌入一起作为模型的输入,用于生成文档的主题词。
算法1 BERT细调词嵌入生成算法
输入:BERT预训练模型获取到的文本词向量表示。
输出:结合领域文本细调的BERT词嵌入表示。
Begin
for BERT文本词向量中的每一行
得到每个词的向量表示wi;
计算当前词向量wti和该词上一次出现的词向量wt-1i的相似度cosine_similarity;
if cosine_similarity>0.75
将当前词的词向量赋值为的词向量平均值avg;
else
将wti存储为wti -1#;
整合结合领域文本细调的BERT词向量
End
2.2 文档主题结构及主题词生成过程
BERT-ETM的文档主题结构如图5所示,假设语料库D中有d个文档,共有V个词表示第d个文档中的第n个词。ρ是L×V的词嵌入矩阵,列ρv是wv的词向量表示,通过BERT模型获得,ρv∈RL。K是主题个数,α是L×K的主题矩阵,列αk是第k个主题的向量,αk∈RL,θ是文档-主题分布的参数,β是主题-词分布的参数,z是主题。主题词的生成过程如下:

图5 BERT-ETM文档主题结构图Fig.5 Topic structure chart of BERT-ETM document
(1)生成文档-主题分布θ
为了便于使用变分推断求解文档-主题分布,θ不再像传统LDA模型一样服从Dirichlet分布,而是服从logistic-normal分布,如式(1)和(2)所示,它是一个归一化后的标准高斯分布。
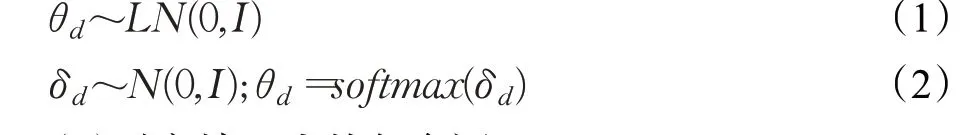
(2)对文档d中的每个词
①模型为每个观察到的单词抽样分配第d个文档中第n个词的主题zdn,得到第n个词的主题,如式(3)所示:

②模型通过BERT获取词嵌入,得到词向量矩阵ρ。
③模型在词向量矩阵ρ的同一语义空间中得到主题向量矩阵α。得到主题zdn后,将词向量矩阵ρ与主题向量矩阵α相乘,将矩阵乘积当作主题-词分布,再进行词汇抽取,得到第n个词,如式(4)所示:

2.3 主题模型的训练过程
BERT-ETM的网络结构图如图6所示,设计了一个基于神经网络的变分自编码器用于获取文档词分布。输入词袋和词嵌入后,词袋表示进入推断网络用于获取文档-主题分布θd,为了适应不同长度的文档,将文档词袋表示规范化并进行线性降维,随机丢弃后分别经过两个不同的线性层,得到高斯分布的均值μd和方差Σd,归一化的标准高斯分布得到文档-主题分布θd。为了获取文档词分布,还需要获取主题-词分布用于共同拟合。为了获取主题词分布β,将得到的词嵌入ρ经过一个线性层得到主题嵌入αk,对词和主题都使用嵌入表示形式,使用神经网络对原文档-主题矩阵和新加入的词嵌入矩阵进行训练,使得模型可以处理语料库中未出现过词,通过计算未现词与已知词的距离,就可以将它归入更可能的主题中,从而将语义相似的词汇分配到更相似的主题中。将词嵌入ρ和主题嵌入αk的乘积作为主题词分布βk。文档-主题分布θd对应着不同的主题-分布β,最后,θd和不同β的乘积可以得到文档词分布。损失函数分为两个部分:推断网络获取的文档-主 题 分 布 的KL散 度(Kullback-Leibler divergence)kld_θ和生成网络获取主题-词分布的交叉熵recon_loss共同构成整个训练过程的损失。
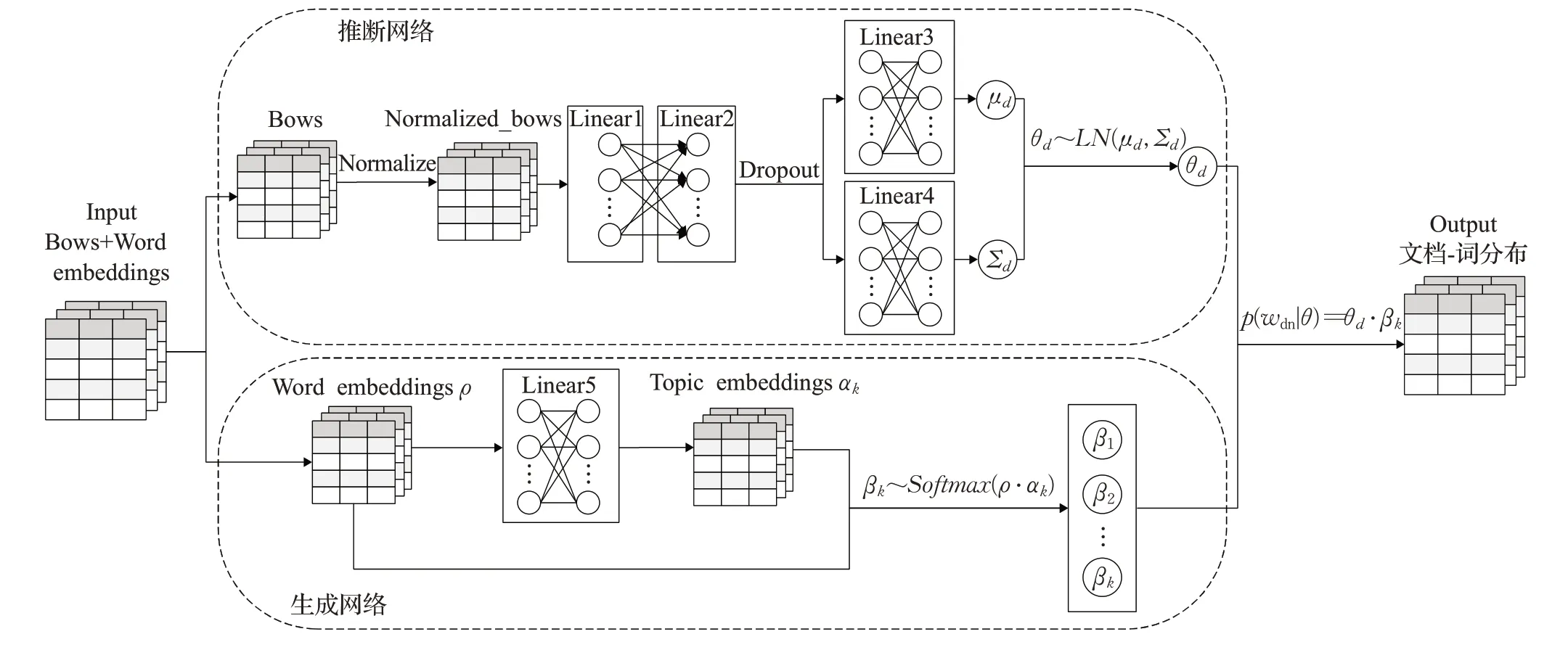
图6 BERT-ETM网络结构图Fig.6 Network structure chart of BERT-ETM
在拟合BERT-ETM时,需要最大化文档集[w1,w2,…,wD]的边际似然,其中,wd是Nd个单词的集合。模型的参数是词嵌入ρ和主题嵌入α。数据集中所有文档的边际似然函数如式(5)所示:

由于文档边际似然计算困难,用公式(2)中未变换ρ的文档主题分布参数δd的积分来表示:
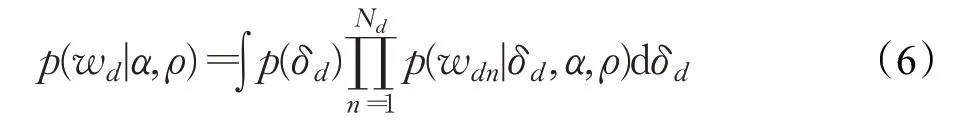
生成每个单词的条件分布使主题分配索引zdn被边际化:
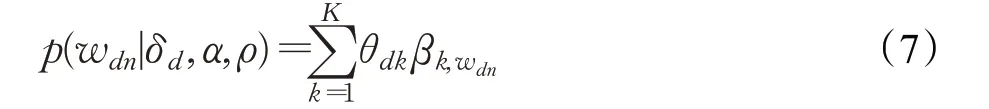
其中,θdk表示公式(2)中变换后的文档主题分布参数,βkv表示主题k对应词v的分布参数,可由词嵌入ρ和主题k的嵌入αk推断得到:

由于可观测数据的边缘分布求解十分困难,其计算复杂度非常高,所以使用变分推断构造了一个后验分布的近似分布来拟合后验分布,用以最大化生成每个文档的对数边际似然边界的总和。假设一个未变换的文档主题比例分布簇q(δd;wd,v),该高斯分布的均值和方差来自于变分自编码器的推断网络。使用此变分分布簇来约束对数边际似然。对数边际似然的证据下界(ELBO)如式(9)所示:
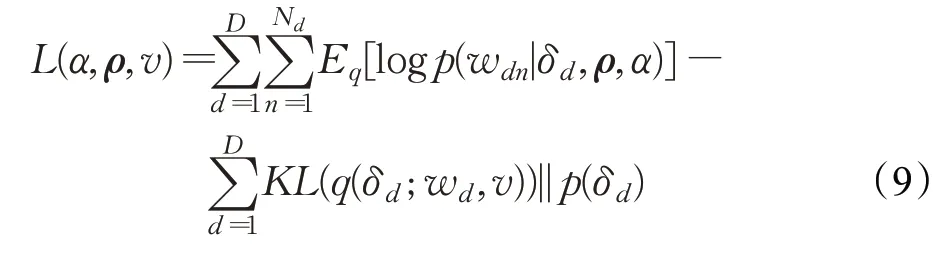
3 实验与分析
3.1 实验数据集介绍
本文首先使用英文通用数据集20Newsgroups语料库和中文通用数据集微博语料库来验证BERT-ETM的实验效果。20Newsgroups数据集收集了约20 000个左右的新闻组文档,均匀分为20个不同主题的新闻组集合,是自然语言处理领域的标准数据集之一。微博数据集则采集了2014年1月至8月用户在新浪微博发布的具有各种主题的贴文,在主题分析等领域有着广泛的应用[26]。通过筛选停用词、文档分词来预处理语料库;另外,本文也将《软件工程》专业领域教材文本作为数据集用于模型的进一步分析,版本为《软件工程——理论与实践》(第2版)。将《软件工程》专业教材作为主题分析研究的对象,希望分析和展示教材中主题间的关联关系,发现学科重点难点,帮助教师和学生理解课程内容。初始数据集中包含12章内容,共260 220个文字,通过人工方式将文字录入电子版数据集,并手工标注领域词典,词典共计2 405个领域词汇。首先对初始数据集进行预处理,将文本按句分隔开来,且保证分开后的句子长度不超过BERT的最大输入长度512。然后通过jieba分词工具进行句子的分词,将分词后的词与领域词典进行整合,整理后的数据输入到BERT进行训练。模型使用85%的文档进行训练,10%的文档用于测试,5%的文档用于验证。
3.2 实验设置
3.2.1 实验模型的参数设置
模型训练的batch_size为100,并使用Adam优化器[27]设置学习率为2×10-3,为防止过拟合,添加了dropout层,dropout率为0.5,主题数目K为50。
其中,主题数K设为50是由困惑度(perplexity)计算出来的。主题的最优数目可以通过选取困惑度最小的模型来确定[28]。较小的困惑度意味着模型对文本有较好的预测作用,所以困惑度一般随着潜在主题数量的增加呈现递减的规律。困惑度的计算如式(10)所示:
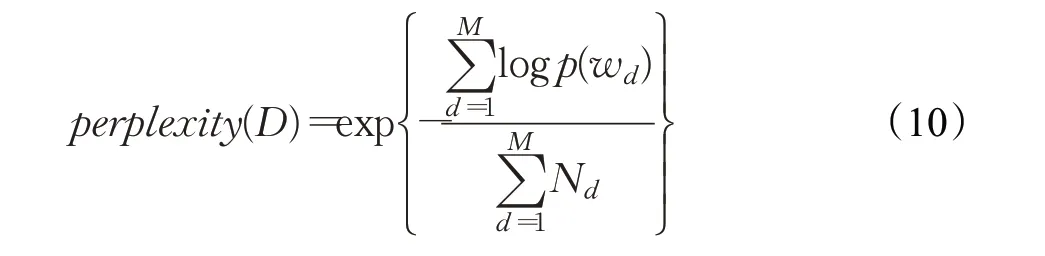
其中,D表示语料库中的测试集,共M篇文档,Nd表示每篇文档d中的单词数,wd表示文档d中的词,p(wd)为文档中词wd产生的概率。
设置主题数目K的取值范围为[5,60],取步长为5进行主题抽取,计算每个主题下困惑度的取值,主题-困惑度变化折线如图7所示。从图中可以观察到当K=50时,困惑度最小,对文本有较好的预测作用,故主题数K的取值为50。

图7 主题-困惑度变化折线图Fig.7 Line chart of topic-perplexity change
3.2.2 环境设置
本文的实验环境是基于深度学习的框架pytorch,采用的编程语言为python,操作系统处理器为Intel®Core™i7-5500U CPU@2.40 GHz。基于BERT的嵌入式主题模型以ETM模型为基准进行实验对比,构建的基于中文分词的WoBERT-ETM模型目前开源的是Base版本。
3.2.3 评价指标
本文通过融合主题一致性和主题多样性两个指标来衡量主题质量,将模型主题质量的总体度量定义为其主题多样性和主题一致性的乘积。在以前的研究中,主题模型的效果通常采用困惑度进行评估,但是一些研究[29-31]也发现困惑度与人们对主题的理解结果并不一致。为更好地对主题进行评估,文献[32]提出了使用主题一致性评价主题可解释性。主题一致性如公式(11)所示,使用一个主题包含的任意两词间的平均点互信息(average pointwise mutual information,APMI)来 度量。APMI可以量化不同词在表示主题中共现的可能性,如果一个主题中词共现概率越大,说明该主题的一致性更强,主题也更具可解释性。


其中,p(wi,wj)是词wi和wj在文档中共现的概率,p(wi)是词wi的边际概率。
主题多样性定义为在所有K个主题的排名前N个单词中出现不同单词的百分比,接近0的多样性表示冗余的主题,接近1的多样性表示多样的主题。主题多样性的计算如式(13)所示:
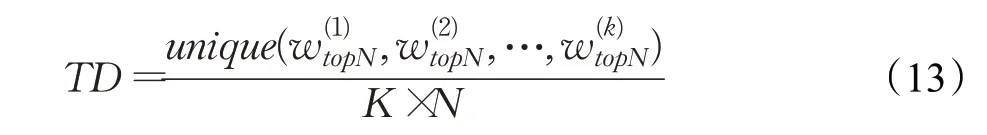
3.3 实验结果与分析
3.3.1 三种词嵌入模型词向量效果对比实验
在获取词嵌入阶段,为了验证BERT用来训练词嵌入的有效性,在《软件工程》专业领域教材文本数据集中随机抽取50个词分别观察BERT模型、WoBERT模型、Word2Vec模型生成词嵌入的效果。使用PCA算法对三种模型生成的词嵌入进行降维,得到词嵌入的向量空间可视化图,三种词嵌入的对比展示结果如图8所示。

图8 三种模型获取的词向量可视化分布图Fig.8 Visual distribution chart of word vector obtained by three models
词的嵌入式表示将文本语义信息编码为空间中的连续矢量,语义相似的单词往往在向量空间中距离相近,从以上三个图进行分析可以看出,BERT模型和WoBERT模型获取到的词向量的分布更能体现词与词之间的关联关系,分布效果明显优于Word2Vec模型。基于Word2Vec获取到的词向量在空间中的分布较为均匀,没有将语义相近的词聚集在一簇,而BERT和WoBERT获取到的词向量分布有明显的词簇,语义相近的词都聚集在了一起。比如BERT词嵌入中表示性能的词“依赖性”“抽象性”聚成了一个簇,表达计算机软件的词“计算机系统”“软件文档”“软件工程”等也聚在了一起,簇与簇之间有明显的界线。同样地,WoBERT获取到的词向量在空间中也有明显词簇,并且与BERT词向量得到的词簇类似。因此,BERT模型获取的词向量更能学习到词的语义,生成的词嵌入的效果更优。
3.3.2 主题模型评价指标对比实验
为验证本文提出的BERT-ETM在获取主题-词分布时的有效性,首先在英文通用数据集20Newsgroups上对比W2V-ETM和BERT-ETM的评价指标——主题一致性和主题多样性的结果,并在使用中文微博通用数据集对比W2V-ETM和BERT-ETM实验结果的同时,增加针对中文词向量的WOBERT-ETM的评价指标结果,实验结果如表1所示。
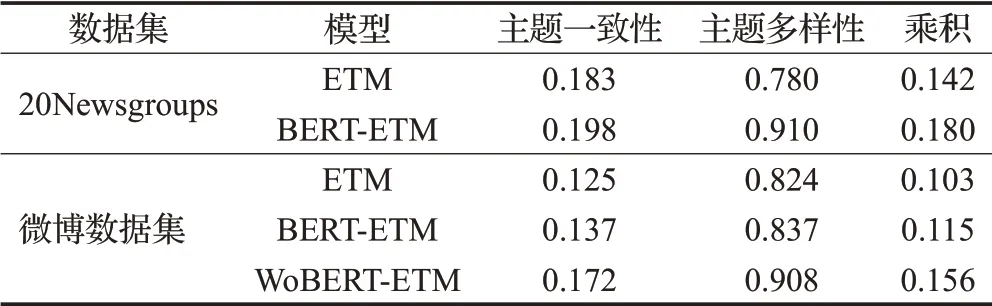
表1 通用数据集评价指标对比Table 1 Evaluation indicator comparison of general datasets
分析实验结果,可以发现BERT-ETM在中英文通用数据集上获取到的融合主题一致性和主题多样性的乘积明显高于W2V-ETM,而基于中文分词的WOBERTETM在中文微博通用数据集上获取主题词的效果则相较于BERT-ETM更优。为了进一步验证实验结果,将《软件工程》专业领域教材文本数据集按照比例分为5%、15%、30%、50%,并分别观察W2V-ETM、BERT-ETM、WOBERT-ETM在不同比例的数据上得到的评价指标——主题一致性和主题多样性的结果,得到表2所示。
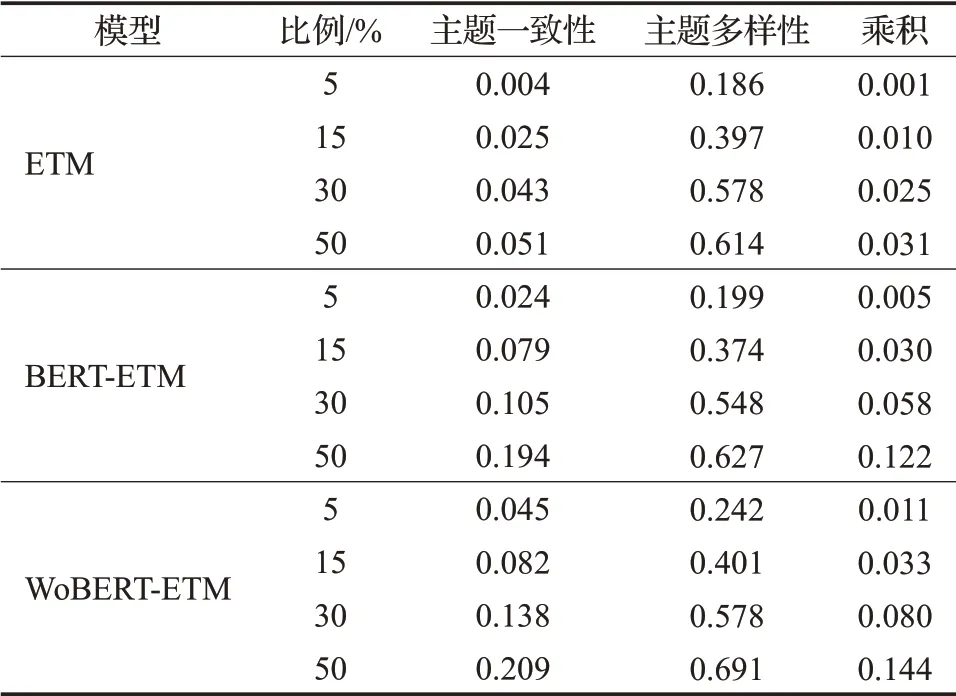
表2 《软件工程》数据集评价指标对比Table 2 Evaluation indicator comparison of Software Engineering datasets
将实验结果进行整理,将三种模型的主题一致性和主题多样性的乘积进行对比,对比图如图9所示。

图9 评价指标对比图Fig.9 Comparison chart of evaluation indicator
从实验结果可以看出,基于Word2Vec的ETM获取主题词的效果明显劣势于BERT的BERT-ETM和WOBERT-ETM。在同样规模的语料下,BERT-ETM和WOBERT-ETM的主题一致性和主题多样性都比ETM有了显著的提高,说明基于BERT的嵌入式主题模型可以获得更具可解释性的主题词。由于BERT模型能够结合上下文信息更好地捕捉文本语义,BERT-ETM中的词嵌入可以充分学习到词的语义表示,特别是基于中文词的WoBERT,由于结合了中文词特性,在获取词嵌入时以词为单位,降低了词义的不确定性,效果更是优于其他模型。
3.3.3 两种主题模型生成的主题词质量对比实验
由于BERT-ETM和WOBERT-ETM的性能都优于ETM,为了进一步比较二者获取主题词分布的效果,选取两种模型拟合出的十组最常用的主题-词分布,展示结果如表3和表4所示。
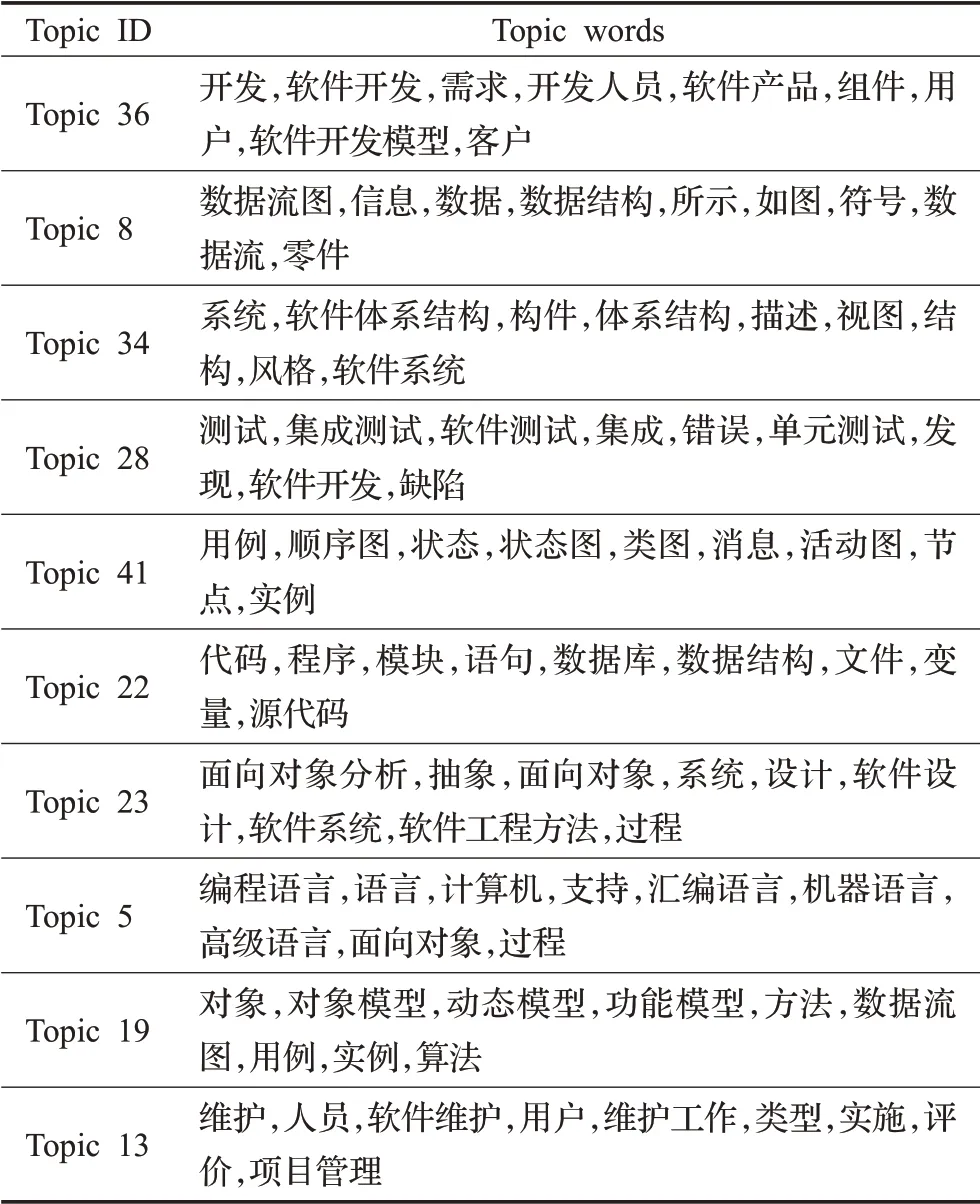
表3 BERT-ETM十组主题-词分布Table 3 Ten groups of BERT-ETM topic-word distribution
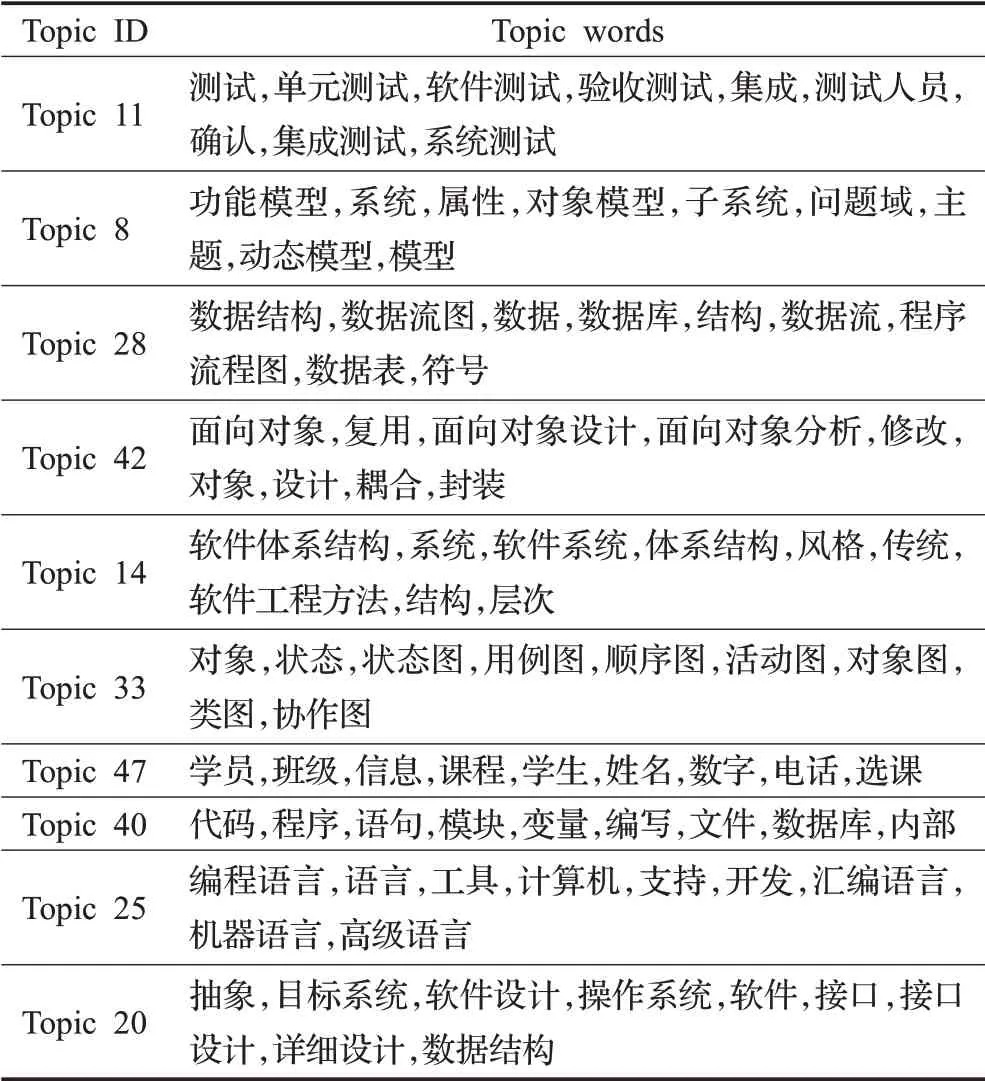
表4 WoBERT-ETM十组主题-词分布Table 4 Ten groups of WoBERT-ETM topic-word distribution
通过主题代表词,可以理解该主题所表示的语义信息,并将主题词应用于课程教学中。由于本文使用《软件工程》专业教材作为文本语料,获得的主题词可以方便教师和学生在教学过程中的使用,解决教师和学生因没有时间整理、分析大量教材文本中的重点内容和关联关系的问题,避免人工整理过程中因各种失误而导致的错误。为了进一步对比BERT-ETM和WoBERT-ETM获取主题词的效果,在两个模型结果中选取三组代表同一主题的分布进行对比,分别选取代表测试主题的主题词分 布:BERT-ETM中的Topic28和WoBERT-ETM中的Topic11;代表数据主题的主题词分布:BERT-ETM中的Topic8和WoBERT-ETM中Topic28;代表图主题的主题词分 布:BERT-ETM中的Topic41和WoBERT-ETM中Topic33。将这几组主题-词分布结果在向量空间中进行可视化,如图10、图11、图12所示。

图10 测试主题的主题词分布Fig.10 Topic-word distribution of test topic

图11 数据主题的主题词分布Fig.11 Topic-word distribution of data topic
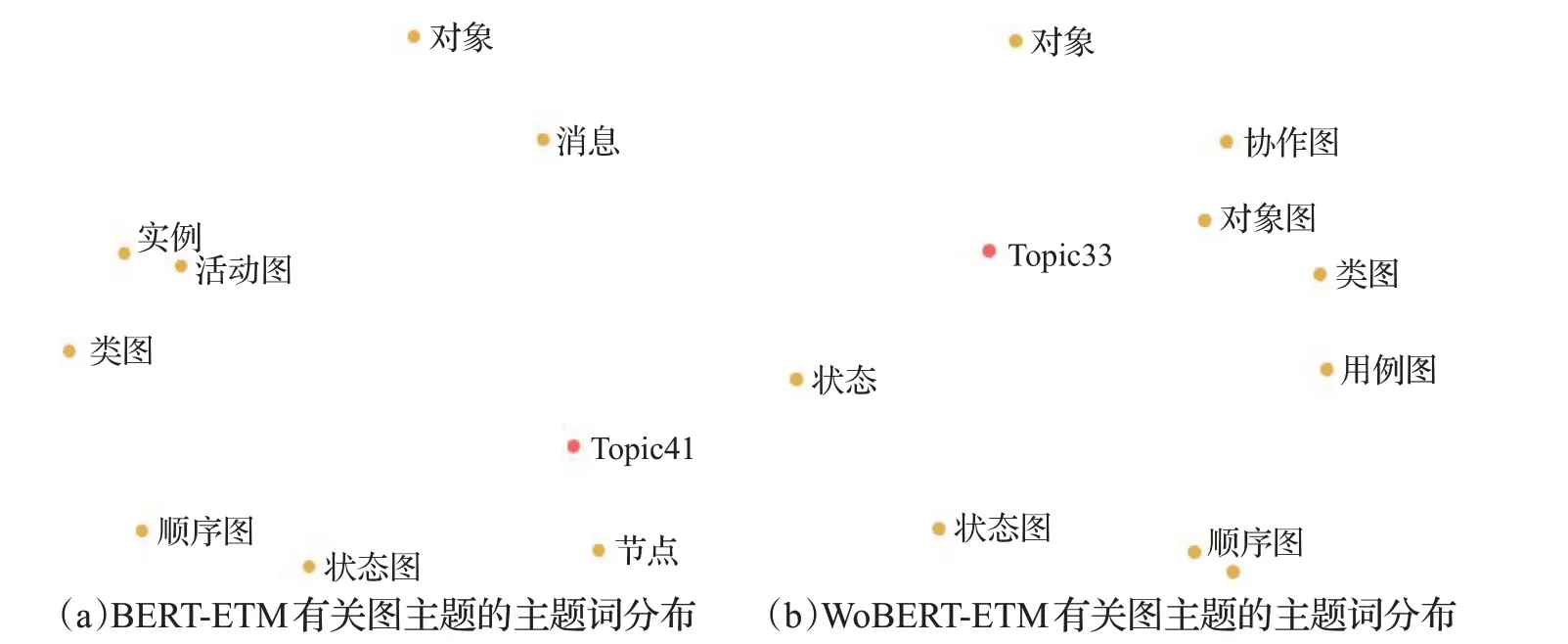
图12 图主题的主题词分布Fig.12 Topic-word distribution of chart topic
根据图10可以观察到,WoBERT-ETM相对于BERT-ETM能够拟合出更多有关软件测试主题的词,除了二者都拟合出来的“测试”“软件测试”“单元测试”“集成测试”以外,WoBERT-ETM还能够拟合出“测试人员”“系统测试”“验收测试”;根据图11可以观察到,WoBERTETM相较于BERT-ETM同样能够拟合出更多有关数据主题的词,除了二者都拟合出来的“数据”“数据结构”“数据流”“数据流图”以外,WoBERT-ETM还能够拟合出“数据库”“数据表”,而且在语义空间中WoBERTETM拟合出的主题更靠近有关数据的分布词,可以看出,WoBERT-ETM拟合出的主题能够学习出更多关于数据的语义表示;根据图12可以观察到,WoBERT-ETM相较于BERT-ETM仍然能够拟合出更多有关图主题的词,除了二者都拟合出来的“类图”“顺序图”“状态图”以外,WoBERT-ETM还能够拟合出“协作图”“对象图”“用例图”,并且主题更靠近与图相关的词。
综合分析,结合中文词特性的WoBERT-ETM能够拟合出更细粒度的主题词,学习到文档隐含的主题信息和知识点,获取到的主题更加具有可解释性。
3.3.4 多义词相似度对比实验
BERT-ETM的另一个优点是可以解决一词多义问题。在面对不同语义下的相同词时,Word2Vec将在两个句子中为该词生成相同的词嵌入,获取到的词嵌入是静态的;而在BERT下,不管该词上下文语境如何,BERT都会从其周围的词动态来生成词嵌入,获取到的词嵌入是动态的,所以该词在每个句子中的词嵌入都是不同的。利用词向量夹角余弦值度量多义词的语义相似度,词向量夹角余弦计算公式如式(14)所示:

其中c,s表示要比较的两个词向量,计算结果表示两者之间语义关系相似程度。由余弦定理可知,cosine值的范围为[0,1],越趋近于1时两个向量的夹角越小,也代表两个文本越相似。
在此将BERT-ETM和WoBERT-ETM获取到的不同语境下的相同词的相似度值进行对比,使用“苹果”一词进行实验测试,实验样例如表5所示,在两种模型上分别计算“苹果”的词向量,并计算不同样例中“苹果”词嵌入的相似度,得到的结果如表6所示。

表5 一词多义实验样例Table 5 Example of polysemy experiment

表6 “苹果”一词多义结果对比Table 6 Result of polysemy of word“apple”compared单位:%
由表6分析可知,两种BERT模型下“苹果”的词嵌入在每个句子中的嵌入表示并不相同,可以证明BERT在面对一词多义问题时能够充分结合词的上下文信息来生成结合语义的动态词向量,从而得以保证特征提取的全面性。
4 总结与展望
本文将BERT模型和嵌入式主题模型相结合构建一种BERT-ETM主题模型,经过Word2Vec和BERT的词向量可视化对比实验,证明了BERT作为嵌入层学习到的文本词嵌入可以充分结合语境上下文信息,捕捉文本在不同语义下的差异;经过ETM和BERT-ETM的主题一致性和主题多样性的对比,证明了BERT-ETM获取主题词的有效性;通过计算词向量相似度,证明BERTETM能够解决一词多义问题;通过对比以字为单位的BERT-ETM和以中文词为单位的WoBERT-ETM,证明结合中文词特性的WoBERT-ETM在处理中文文本时能够获得高质量、细粒度的文档隐含主题信息从而改善主题建模的效果。本文在将教材文本向量化表示的基础上,继续研究文本的主题提取和分析过程,对于提高课程知识的共享和传播、发现学科重难点及关联关系、推进课堂信息技术的进步和发展均有着重要的现实意义。在下阶段的工作中将继续研究文本的词嵌入表示,并考虑到目前的主题模型大多将主题归纳为单层结构,无法将主题组织成层次体系的问题,着力研究基于词嵌入的多层次主题模型,并将多层次主题模型提前到的主题词进一步应用于智慧教育领域中,以提升教师教学、学生学习的效果和性能。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
实用医药杂志(2021年4期)2021-01-11
开放教育研究(2020年2期)2020-03-31
中国医学计算机成像杂志(2020年6期)2020-03-14
电脑爱好者(2017年7期)2017-05-06
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
中国骨与关节杂志(2016年12期)2016-01-23
