
基于深度学习的单视图三维重建方法的研究进展
2022-12-30 15:54:24刘国柱
青岛科技大学学报(自然科学版) 2022年6期
刘国柱,于 新
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
基于图像的三维重建是从输入的一张或多张二维图像中恢复出物体的三维几何形状的过程,是计算机视觉领域中非常重要的研究内容之一。三维重建有着巨大的应用价值,广泛应用在医学诊断、城市建设、文物修复、商品展示和无人驾驶等多个领域。依据输入图像数量的不同,三维重建可以划分为多幅图片三维重建和单张图片的三维重建。从单张图像预测物体的不可见部分一直是三维重建的一大挑战,本工作着重介绍单幅图像物体的三维重建方法。
基于单幅图像的三维重建的传统方法分为基于模型的重建方法和基于几何形状复原的重建方法两类[1]。其中基于模型的重建方法针对特定类别的物体获得的重建结果比较好,但该传统方法很难拓展到不同类别和不同形状的物体上;对于基于几何形状复原的重建方法虽具备良好的泛化性,但该方法对图中的光照和灰度要求更高,使得很难重建出的较好质量的效果。自2015年YANN等[2]推动深度学习技术的发展以来,不停地涌现出各种各样的基于深度学习的单幅图像的三维重建方法,并取得了巨大的进展,三维重建迎来了新的机遇。
为了将二维卷积神经网络更好地应用于三维领域,人们探索了多种三维模型的表示形式。在计算机图形学领域,传统的形状表示方法包含体素、点云和网格这些显式[3]表示方法,因此本工作根据三维模型不同的表示方式,从体素、点云、网格三种类别分别介绍深度学习在单视图三维重建中的研究现状。本工作第一节将分别讨论这三类表示方法的实现技术的特点和优势,第二节归纳总结三维重建研究中常用的数据集以及评价标准,并对一些经典的三维重建方法从不同指标对比分析。第三节对该领域依然存在的问题及发展趋势进行总结与展望。因此,本工作依据不同的三维模型表示,总体分类如图1所示。图2用时间轴的方式总结了本工作中综述的从2016年至今的基于深度学习的单视图三维重建的一些里程碑方法,其中按照方法出现的年份分段标注出了方法名及作者。

图1 总体分类组织结构图Fig.1 Overall classification structure diagram
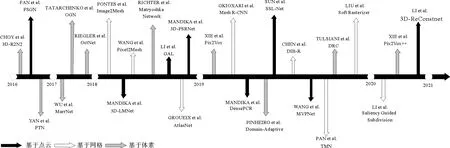
图2 单视图三维重建中基于点云、网格和体素的时间顺序概述Fig.2 An overview of the time sequence based on point clouds,grids,and voxels in single-view 3D reconstruction
1 基于深度学习的单视图三维重建法
近年来,基于深度学习的三维重建技术的研究逐步成熟起来,EIGEN等[4]和LIU等[5]分别在2014年和2015年提出用卷积神经网络(convolutional neural networks,CNN)学习图像到它的深度图像信息之间的映射,使用深度图来解释重构原始输入图片的信息,虽然深度图像可以用来理解重建物体的三维信息,但是不够直观,因此出现了使用体素、点云和网格等形式来表示三维模型信息的大量研究。
1.1 基于体素表示的三维重建
体素类似于像素,是二维像素的自然延伸,它与卷积神经网络具有兼容性,实现起来具有简单性。体素表示是基于学习的三维重建的最早的表现方式之一。随着大量三维数据集的出现以及深度学习的发展,在基于深度学习的单张图片的三维重建中取得了很大进展。3D ShapeNets[6]于2015年提出,成为了最早将深度神经网络应用在体素表示的方法之一。综合基于体素表示的三维重建的相关文献内容,可以将体素模型的生成方法分为两类:基于特征学习的方法和基于协同学习的方法。
1.1.1 基于特征学习的方法
大多数基于特征学习的单视图重建方法都是使用编码器将输入的图像编码到一个潜在的空间,然后解码器再将潜在层的向量映射到一个三维体素化模型上。实现过程如图3基于特征学习的三维体素模型生成过程所示。

图3 基于特征学习的三维体素模型生成过程Fig.3 Process of generating 3D voxelized model based on feature learning
在大多数的单视图三维物体重建方法中,都是将输入的图像直接编码到一个较低维的离散的潜在空间[7-11]。CHOY等[7]提出了一种基于标准长短时记忆(long short-term memory,LSTM)的拓展网络架构3D-R2N2,该网络可以建立二维图像特征到其对应的三维体素模型的映射关系,首先利用卷积神经网络对原始输入图像编码为低维特征,然后运用一个反卷积网络解码,中间使用LSTM模块过渡连接,完成从任意角度接收单个或者多个对象实例的图像生成三维体素模型。不久,GIRDHAR等[9]设计了TL-embedding network网络,利用三维自编码网络和简单的特征提取网络(5个卷积层)分别提取三维体素化模型和图像的特征,也是将输入的图像直接编码到一个较低维的离散的潜在空间,同时是第一个提出将学习可生成和预测的三维模型特征作为目标的网络。
还有一些研究使用间接的方式生成三维模型,首先利用编码器-解码器结构生成输入二维图像的中间表示,然后将中间表示编码为一个离散的潜在空间。例如,WU等[12]提出Marr Net,将三维重建问题按照先估计2.5D的草图再预测3D形状方式进行,该方法在训练时通过多个阶段微调的方式取得了效果不错的三维模型。该方法利用ResNet-18编码输入图像,得到多个特征图,通过解码器输出对应的中间表示,例如深度图、轮廓图等形式,然后将中间表示编码为向量,最后将向量解码为体素网格。类似思路的研究还有文献[13-14]提出的方法。
1.1.2 基于协同学习的方法
体素化模型可以有效的预测全局形状结构,但在拓展到高分辨率输出时,会导致内存和计算量成本太大,针对这一问题,一些研究开始将重点放在如何生成高分辨率三维体素化模型和使用八叉树进行有效的空间划分[15-18]上,使用八叉树的独特的数学体征结构协同体素构建任务完成目标的三维重建。RIEGLER等[16]提出一种卷积网络Oct Net,利用输入数据的稀疏性,使用一系列不平衡的八叉树来分割三维空间,由此可以更合理的使用内存以及降低计算量。
受文献[16]的启发,HÄNE等[17]提出利用八叉树的结构表示体素,将体素分为边界、占用以及未占用三类,使用八叉树叶节点存储CNN提取的图像特征,从而节省了计算量。TATARCHENKO等[18]提出一种深度卷积解码器结构,使用八叉树表示法,该方法可以在有限内存下得到更高分辨率的体素模型输出。表1整理了近几年一些基于体素表示的单视图三维重建方法。
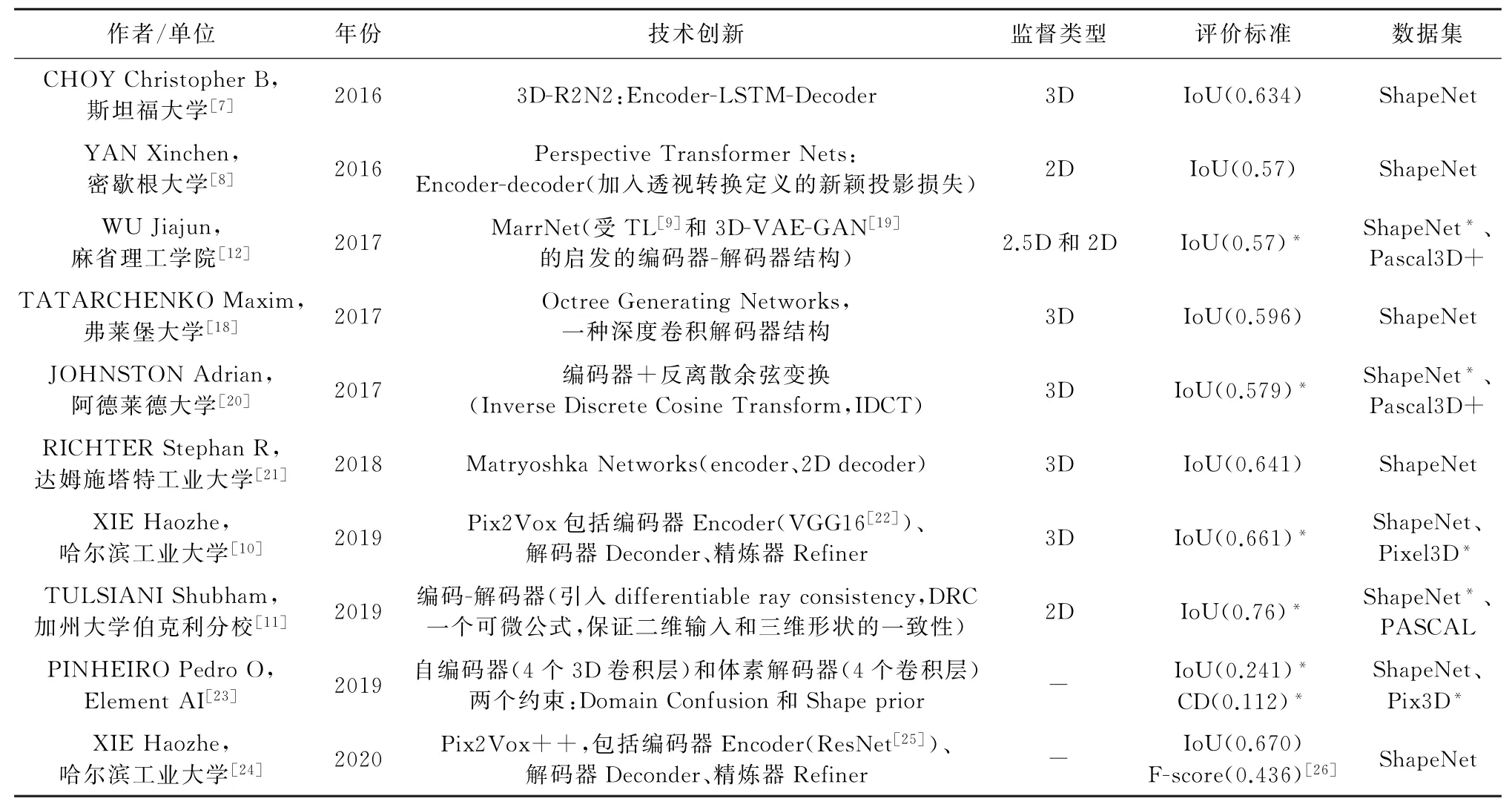
表1 基于体素表示的三维重建方法整理Table 1 3D reconstruction methods based on voxel representation
1.2 基于点云表示的三维重建
点云表示是以3D空间中点的集合的形式来表现物体的三维模型,3D点云作为一种基于表面的几何形式,具有均匀、连接性强、富有表现力的优势。随着点云形式在物体识别方面相关研究的出现以及深度网络发展的推动,最近出现了大量基于点云的三维重建方法。根据监督的类型,本节将从2D监督和3D点云监督两类分别综述三维重建方法。归纳基于点云表示的重建方法,可以发现大多数方法是采用编码器-解码器结构进行重建,大致处理过程见图4。
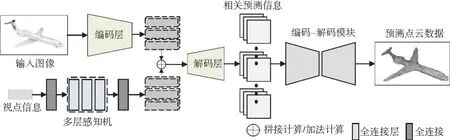
图4 基于点云的三维重建模型预测过程Fig.4 Prediction process of the 3D reconstruction model based on the point cloud
1.2.1 基于3D点云监督的三维重建
早期出现的基于点云表示的方法大多数都是利用3D点云监督来完成重建任务的[27-31]。FAN等[27]提出了点集生成网络(point set generation network,PSG-Net),这是最早用深度学习研究点云表示点集生成问题,通过3D点云监督完成了单幅图像的三维重建任务。MANDIKAL等[28]扩展了PSG-Net,同时受方法[32]中分类结构的启发,提出了3D-PSRNet联合训练分割和重建两个任务,引入位置感知分割损失训练网络得到了更真实的重建结果。SUN等[33]使用部分点云数据作为监督,在生成3D模型的同时渲染图像数据,并与输入图像进行比较完成自监督学习下的三维重建。DALAL等[34]在方法[35]的基础上设计KRO Loss使用3D点云实现自监督的三维重建网络训练。
1.2.2 基于2D监督的三维重建
上文提到的利用3D点云监督的方式重建在训练时需要大量的三维数据,数据不易于获取并且昂贵,因此,研究人员尝试利用二维监督的方式[36-39]进行重建。LIN等[36]用一个可微的模块即伪编码器近似真实的渲染操作,不断优化合成的新的深度图来学习密集的三维形状,利用2D监督实现重建任务。NAVANEET等[37-38]在分别开发了DIFFER和CAP-Net可微投影模块,通过对点及其特征投影到二维图像,不断训练网络。其中方法一[37]可以直接从单幅图像中预测3D形状和颜色等属性,方法二[38]中利用多个前景掩膜作为监督数据,完成单幅图像的三维重建任务。文献[35,40]使用2D标签数据完成自监督的网络训练,并且可以实现较好的重建精度和分辨率表示。表2整理了近几年一些基于点云表示的单视图三维重建方法。
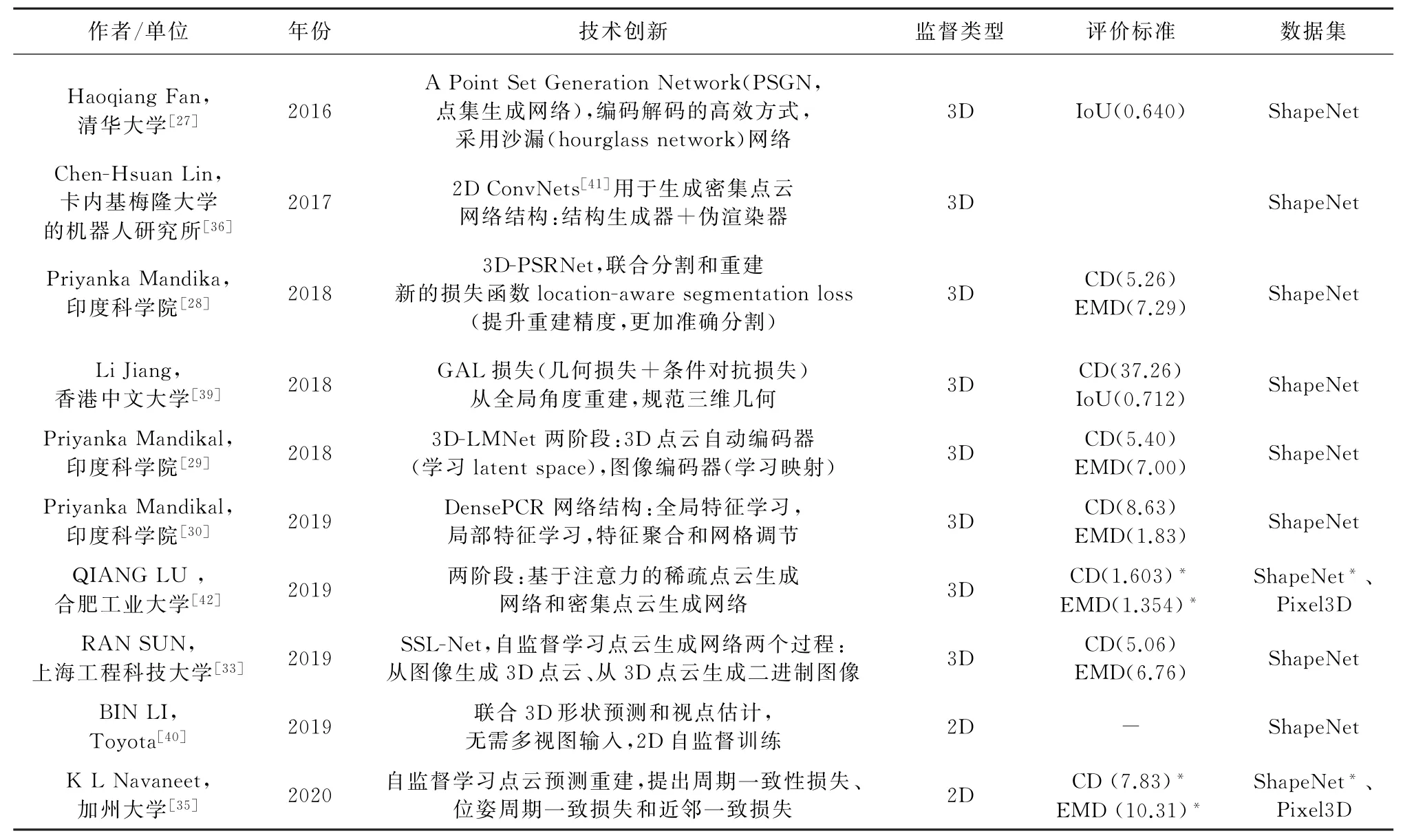
表2 基于点云表示的三维重建方法整理Table 2 3D reconstruction method based on point cloud representation
1.3 基于网格表示的三维重建
网格表示是一种基于点、边、面的三维模型表示方法,它是计算机图形学和计算机辅助设计中的标准形式,在三维重建的研究中变得越来越受欢迎。大多基于网格表示的重建方法利用变形模板网格的形式进行重建,还有一些自由形式生成三维模型的方法,下面将从这两类分别介绍一些经典的重建方法。
1.3.1 基于模板网格的变形
基于模板网格的变形的三维重建方法,实现思路是通过从输入图像中提取的感知特征来变形模板网格以得到三维网格模型[31,43-48]。在文献[43-44]中方法的启发下,WANG等[45]提出一种端到端的深度学习框架Pixel2Mesh,该网络结合提取的输入图像的相关特征,借助图卷积网络解码器,实现输入单张RGB图像预测物体的三维网格模型,逐渐将椭球网格变形为三维网格模型。PAN等[46]在基于网格变形的学习方法[31]的基础上,通过面修剪这种动态方式不断地更新可变形网格的拓扑结构,使用单个球体模板网络更好地捕捉了重建细节。以拓扑修改网络为例,图5展示了大多数基于模板网格变形来进行三维重建的处理过程。

图5 拓扑修改网络的三维重建实现过程Fig.5 3D reconstruction process of topology modification network
1.3.2 基于自由形式的生成
在利用模板网格变形的方法重建时,当目标对象拥有不同的拓扑结构时,会导致较大的重建的错误。与变形初始网格不同,最近提出了一种与二维感知相结合的三维重建方法。GKIOXARI等[49]在Mask R-CNN基础上扩展提出了Mesh R-CNN[50],不仅可以检测图像中的物体,并且可以预测得到目标对象的三维网格模型。该方法使用Mask RCNN从单张图像中估计图像中物体的边界框、类别标签和分割掩码,随后预测一个粗体素模型,然后转换为网格表示,解决了任意拓扑的网格重建。还有一些新的基于网格表示的三维重建方法相继出现[51-54],表3整理了近几年一些基于网格表示的单视图三维重建方法。
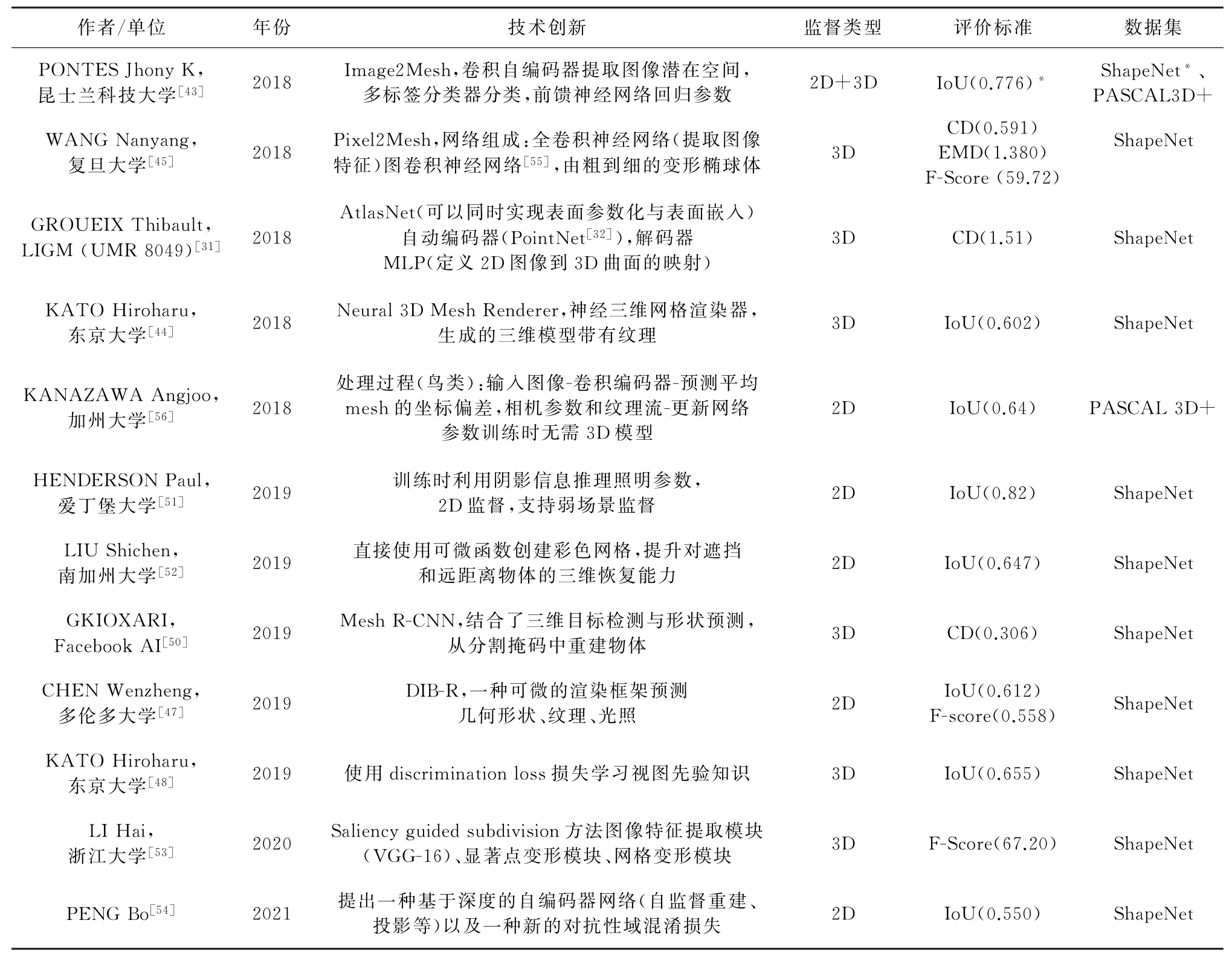
表3 基于网格表示的先进的三维重建方法的整理Table 3 3D reconstruction method based on grid representation
2 数据集与评价指标
2.1 数据集介绍
为了更好的研究三维重建技术,离不开大量三维模型数据集的支持。深度学习依附于大量的数据集,以实现算法研究、对比分析和结果评估。随着三维重建研究的不断推进,对三维模型数据集的需求也越来越大,目前已经推出了多个三维模型的公开数据集,表4列出了一些常见的用于三维重建的数据集及其属性。
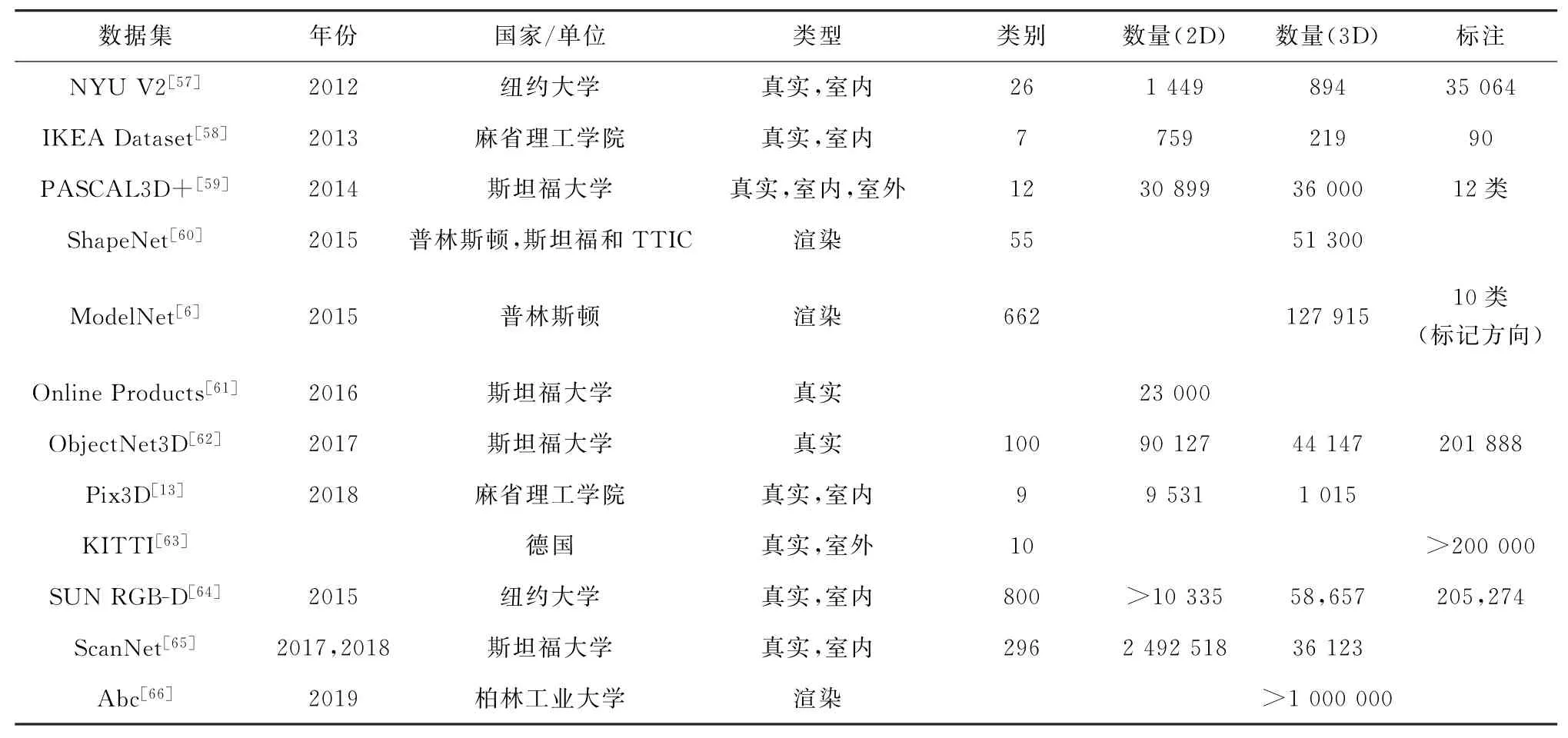
表4 用于三维重建的常见数据集及介绍Table 4 Common datasets and introduction for 3D reconstruction
2.2 评价标准
1)交并比(Io U):在三维重建的背景下,Io U指的是重建预测出的三维形状体积和地面真实体积的交集与两个体积的并集的比率,Io U值越大代表着重建结果的质量越高。
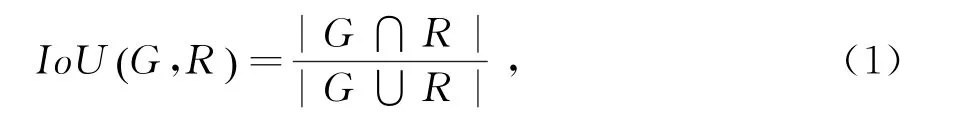
其中,G,R表示二分类的占用图。
2)倒角距离(CD):定义真实形状G与重构形状R(均表示为点云)之间的倒角距离,即计算生成G与原始R之间平均的最短距离。在三维重建中,CD的值越小越好。
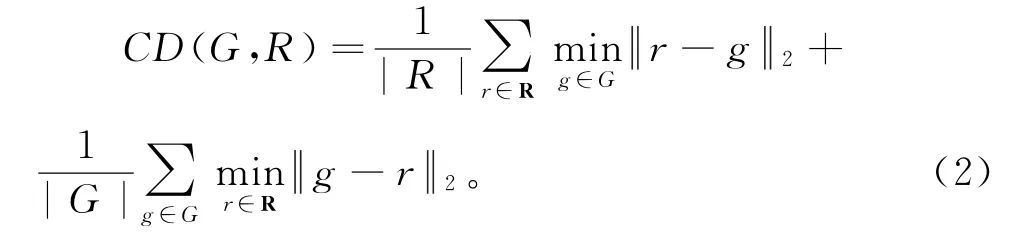
3)Earth Mover’s Distance(EMD):用来表示两个分布S1和S2之间的近似程度。在三维重建中,EMD的值越小,代表重建效果越好。

4)F-Score:是指重建准确率和召回率的调和平均。
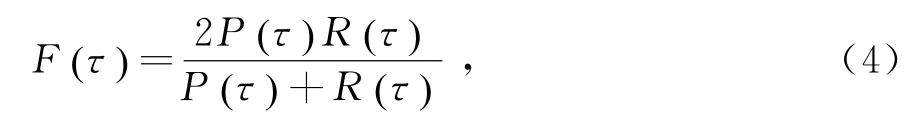
其中,P(τ)表示准确率,R(τ)表示召回率,τ表示给定的阈值。
2.3 IoU&CD指标对比分析
图6展示了过去4年三维重建精度的提高。其中,图6(A)展示了使用体素表示的相关方法在Io U评价指标下的对比结果,图6(B)展示了使用点云表示的相关方法在CD评价指标下的对比结果,图6(C)展示了使用网格表示的相关方法在Io U评价指标下的对比结果。可以看出,基于体素表示的单视图重建方法的重建结果相较于基于网络表示的方法Io U值偏低,这表明使用网格表示的重建效果上得到了明显的提升,也验证了网格的表示形式可以更好地捕捉输入图像的细节。基于点云表示的CD值逐年呈现出下降的趋势,重建效果越来越好。于此同时,通过文献方法对比可以看出使用3D监督的方法和使用2D监督的方法两者之间的差距正在逐渐缩小,这主要是因为2D到3D之间的映射通过使用视点估计[40]的方法进行弥补。

图6 一些关键方法在ShapeNet数据集上的表现Fig.6 Performance of some key methods on the ShapeNet dataset
3 思考与展望
随着深度学习的不断发展,基于深度学习的单视图三维重建方法越来越多,加之大规模三维数据集的涌现以及三维重建广阔的发展前景,三维重建一直是一个值得研究的课题,相比传统的三维重建方法,近年来提出的基于深度学习的重建方法在重建效果上得到了明显的提升,但是仍然存在如下问题。
1)重建结果的精度问题。三维模型相较于二维图像多了一维的信息,使得三维模型的生成问题在计算量和内存的需求上要求的越来越高,尤其是在高分辨率图像输入时。重建物体的分辨率通常是32×32×32,输入这种分辨率图片生成的三维模型结果是十分粗糙的,远远达不到理想的重建精度。即使针对这一问题,已经有很多新的重建方法被提出,但是在重建效果上仍然不够精细。接下来应该着重改变重建网络的结构以提高重建分辨率,最大程度利用计算机内存资源和显存资源,提升重建结果的分辨率,得到更多细化的重建结果。
2)输入图片信息的不足。基于单幅图像的三维重建,本身在输入图像时就会存在着不同的问题,同一类型的物体在材料、光照[67]等不同条件下,表现出不同的效果,不同类型的物体,在外形上存在着更大的差异,对于图片中物体存在的遮挡、变形等现象,对于单幅图像的三维重建无疑是巨大的挑战,这对三维重建算法提出更高的要求。未来要继续研究如何利用有限的假设和先验知识去重构出更高质量的三维重建模型。
3)公共数据集较少。在三维重建任务中对数据集的需求量越来越大,数据集是网络计算的基础,增加数据集的种类和数量能够提高网络的泛化性。与已有的二维图像数据集相比,三维的公开数据集种类少,数量少,这对三维重建技术的研究来说是一劣势。未来随着深度学习的不断发展,对于三维数据集的开发一定会越来越多。
4)三维模型的表示及评价。随着深度学习技术的发展,涌现出越来越多的三维模型的表示方法,除去常见的基于体素、点云、网格的表示形式,基于隐式表示[68]和高斯表示[69]等方法都相继出现,对于哪一种表示方法是最好用的,现在仍然在持续探索。对单幅图像的三维重建的评价指标问题上,哪种指标可以更好地反映出模型的重建效果,在未来仍然需要继续研究。
在基于深度学习的单幅图像的三维重建的研究中,是一个有价值并且值得研究的方向。本研究首先综述了基于体素、点云、网格这三种表示形式的三维重建方法,然后对三维重建中的常用数据集及评价指标进行了简要介绍,并对一些经典方法的重建结果进行对比分析,最后对三维重建方法存在的问题及未来的发展趋势进行了思考和展望。总之,深度学习为单视图的三维重建方法带来了新思路,取得了不错的研究成果,但现有方法仍存在着各种各样的问题,该问题仍然是一个有待解决的研究方向。
猜你喜欢
计算机集成制造系统(2022年11期)2022-12-05 11:40:44
计算机集成制造系统(2020年4期)2020-05-08 02:41:16
软件(2020年3期)2020-04-20 00:56:34
中国惯性技术学报(2019年1期)2019-05-21 00:58:46
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
光学精密工程(2016年6期)2016-11-07 09:07:56
腹腔镜外科杂志(2016年12期)2016-06-01 12:10:09
