
基于双关主题模型的中药方君臣佐使配伍规律分析
2022-12-28 15:25:28马甲林王兆军郭海
中国中医药信息杂志 2022年12期
马甲林,王兆军,郭海
1.淮阴工学院计算机学院,江苏 淮安223003;2.淮安市吴鞠通中医学术研究会,江苏 淮安 223300;3.南京医科大学附属淮安第一医院,江苏 淮安 223000
中药配伍理论经过古今医家的发展和总结,形成较为完整理论体系的主要有药性配伍、七情配伍及君臣佐使等。其中,君臣佐使是中医方剂重要配伍理论原则之一,最早见于《黄帝内经》。《素问·至真要大论篇》有“主药之谓君,佐君之谓臣,应臣之谓使”,“君一臣二,制之小也。君二臣三佐五,制之中也”,“君一臣三佐九,制之大也”。元代李杲《脾胃论》将其表述为:“君药分量最多,臣药次之,使药又次之。不可令臣过于君,君臣有序,相与宣摄,则可以御邪除病矣。”《黄帝内经》对君臣佐使的定义得到众多医家认可[1-4]。
历代中医处方数据中蕴含着丰富的药方配伍原则的先验知识[5-6]。针对中医药配伍规律挖掘分析研究工作主要关注药物的组合关系,以药物作为复方的特征项,采用关联规则分析、频繁项分析、主成分分析、聚类分析等[7]。目前研究大多专注于抽取某种疾病的特殊规则,探索某种特定疾病或中医名家的用药规律。而针对君臣佐使配伍规律和分析集中在对有限数量的药方进行人工注解分析,以探索其概念的内涵和外延及临床原则,采用数据挖掘分析的研究极少[7-8]。本研究以中药方数据为分析挖掘对象,以主题模型理论为建模基础,提出一种用于分析君臣佐使隐性结构的双关主题模型(double correlated topic model,DCTM),建立主题在病证和药方2个语义空间的联系,分析标注出中药方的君臣佐使角色,为研究计算机自动组方、验证和完善中医君臣佐使配伍理论提供帮助。
1 药方数据关系分析
组方药物可按其在方中所起的作用和地位分为君药、臣药、佐药、使药[9]。君臣佐使依据药物功效,表明药物在整首方中的作用和重要程度[10-12]。君臣佐使配伍理论从多元用药角度,论述组方各味药物在方中的地位及配伍后的性效变化规律。它高度概括了中医配药组方的原则,是七情配伍理论的进一步发展[10]。根据《方剂学》[9]定义,君臣佐使具有以下核心含义:君药针对治疗主病或主证;臣药辅助君药加强治疗主病或主证,或治疗兼病或兼证;佐药有3种,佐助药辅助君臣药加强疗效,佐制药消除或缓解君臣药毒性与烈性,反佐药与君药性味相反而又能在治疗中起相成作用;使药包括引经药和调和药,起引经作用或调和作用。
根据君臣佐使概念,可总结中药方数据存在的主要特性。显性数据包括病证、药物。隐性数据包括以下4类:①主病证和兼病证;②君药、臣药、佐药、使药;③佐助药、佐制药、反佐药;④引经药和调和药的隐含角色。根据以上特性,可进一步从中抽象出以下主要关系:①君药对应主病证;②臣药辅助君药,或对应兼证;③佐药与君药有关;④使药相对较为独立。根据以上抽象关系需要建立一种多关系主题模型,不仅需要分析处方的君臣佐使的配伍结构,而且能够描述君药与臣药、君药与主病证、臣药与兼病证的隐性关系。
2 双关主题模型构建
主题模型是一种概率图生成模型,能够从文本数据中学习潜在的主题信息和语义结构,广泛用于文本数据挖掘。目前研究在经典主题模型PLSA[13]、LDA[14]基础上,弱化主题模型的各种假设、与元数据结合,结合领域理论及数据特点进行拓展建模[15-16]。针对多类型数据,GM-Mixture模型采用潜在变量连接图像及其文字标题2种不同类型的数据,用于图像数据自动组织、自动注释及检索等任务[16]。在此基础上,提出GM-LDA和Corr-LDA模型[17-19]。此外,针对社会媒体中的文档和标签数据,提出Tag-LDA模型用于实时标签推荐[20]。
主题模型对多种数据类型同时建模,根据实际任务选择不同的分布描述变量之间的相关关系,已用于中医临床诊疗[12]。相关主题模型(correlated topic model,CTM)[21]为表达主题之间的相关性,引入正态分布ηd~N{μ,Σ}替代LDA中Dirichlet分布,但CTM模型为单语义空间模型。中药方内容分为病证和药方两部分,二者处于不同的特征空间,病证的特征词由病、证候和症状组成,药方的特征词为中药。本研究对处方的君臣佐使配伍结构,及君药与臣药、君药与主病证、臣药与兼病证关系同时建模,提出无监督的DCTM,用于挖掘中药方数据表现为病-证、证-药及药-药配伍等多重复杂隐性关系。
2.1 建模思想
中药方数据集可看作D个独立的文档生成过程,单个药方被看作一篇文档d,该文档同时存在2个语义空间的特征(包含2种类型的词):病证被看作组成文档的第一类语义空间,中药被看作第二类语义空间。DCTM为一个双类型词袋模型。在DCTM中,文档d由两部分分步生成:第一部分是病证生成,由K个主题按比例组成,主题是建立在病证语义空间上的词分布;第二部分是中药,同样由K个主题按比例组成,主题是建立在中药语义空间上的词分布。2个语义空间共享主题分布,实现主题的双关联,并引入正态分布作为先验,建立主题之间跨2个语义空间的两两相关关系。DCTM的图模型表示见图1,符号含义见表1。

表1 DCTM图模型表示符号含义

图1 DCTM图模型表示
图1所示DCTM中采用一个K维隐变量ηd,服从正态分布N(μ,Σ),μ(为K维向量)和Σ(为K*K协方差矩阵)为该分布的参数先验。由K个主题的协方差矩阵Σ表达主题两两之间的相关性。因为ηd~N(μ,Σ),所以类似CTM,DCTM中exp(ηd)服从对数正态分布,可用来表达中药复方中主题之间的比例;但为了满足各个主题比例之和为1,因此将ηd转化为参数θd,满足θd1+θd2…+θdK=1,且0≤θdi≤1,具 体 为:θd=f(ηd)=exp(ηd)/Σkexp(ηk)。
DCTM建模在2个语义空间上,包含病证描述部分的词和药方部分的中药;一篇中药复方文档d同时共享主题分布f(ηd)且服从多项分布;通过共享主题分布,建立病证主题和中药主题的两两相关关系。φs为多项式分布,表示主题上的病证分布;同理,φh为多项式分布,表示主题上的中药分布;一篇中医复方文档d的病证和中药的联合生成概率可表达为公式(1)。
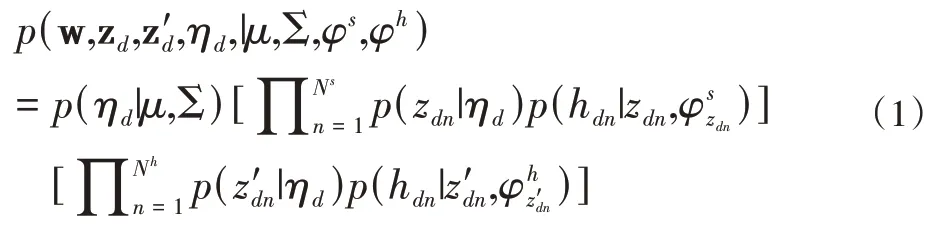
DCTM模型中,一个中药复方语料库的生成过程为:
步骤1抽取一个文本-主题(document-topics)分布:ηd|{μ,Σ}~N(μ,Σ)
步骤2 For eachsdnind:
步骤2-1随机抽取一个主题编号:zdn|ηd~multinomial(f(ηd))
步骤2-2从病证词袋中为主题zdn抽取词:sdn|zdn,φs~multinomial(φzdn)
步骤3 For eachhdnind:
步骤3-1随机抽取一个主题编号:z'dn|ηd~
multinomial(f(ηd))
步骤3-2从中药词袋中为主题z'dn抽取词:hdn|z'dn,φh~multinomial(φz'dn)
2.2 模型参数推断
本研究DCTM中引入了正态分布来建模主题之间的相关关系。正态分布不是多项分布的共轭分布,所以依靠共轭分布来推断后验分布的Gibbs Sample不再适用于DCTM模型参数推理,因而采用变分推断EM算法进行参数求解[15-16]。根据DCTM生成过程可见,模型的目标是推断隐变量在显性变量条件下的后验估计,见公式(2)。

2.3 配伍规律分析
DCTM可通过变分EM算法推断关键模型参数φs、φh及{μ,Σ},并可通过参数ηd间接转化得到文档d的主题比例参数θd,θd=f(ηd)=exp(ηd)/Σkexp(ηk)。
2.3.1 由参数θd分析君药及主病证
通过中药复方d中第一部分的病证描述部分,可知主病证必然反映为较高的主题比例概率值;君药针对主病证,第二部分的药方部分必然反映为较高的主题比例。因此,选取主题比例最高的主题对应药物为君药(φhd,k),对应病证为主病证(φsd,k),其中k=argmax({θd,1,θd,2,…θd,K})。进一步可知,在d中除去φsd,k,均为兼证。
2.3.2 由参数Σ分析臣药及兼证
在前述关系中,臣药辅助君药,或对应兼证,可知臣药与君药相关度较高,或与兼证相关。因此,可通过分析各主题之间相关性得到臣药。参数Σ反映各主题之间两两相关度,可得到两两主题间相关系数ρi,j矩阵。所以臣药可取与主题i相关度高的(ρi,j>ε,ε为相关度阈值参数,在实验中根据实际情况观察确定)主题{j}的前topn个词:φd,{j}(j∈{1,2…K})。
2.3.3 佐药和使药确定
使药的作用主要是引经和调和,常用使药相对比较固定,因此,使药可选用自固定集合。依据中医六经和十二归经理论,相应药物大约几十种,可在DCTM模型分析中直接根据固定集合标注。佐药作用相对比较复杂,也反映出佐药的多关系特性。因此,在分析方法中,可在其他结果得出后将剩余药物全部划归佐药。
2.3.4 基于DCTM的君臣佐使分析算法步骤
输入:中药方数据集、中药信息库
输出:中药方中各味药的君臣佐使角色标记
步骤1输入中药方数据集、并利用中药信息库对数据集进行中药识别及同名中药归一化等预处理;
步骤2训练DCTM模型;
步骤3根据DCTM模型训练结果进行药方君臣佐使角色标记;
步骤3-1根据“2.3.1”项下方法标记君药;
步骤3-2根据“2.3.2”项下方法标记臣药;
步骤3-3根据“2.3.3”项下方法标记佐使;
步骤4结果输出保存。
3 模型应用
3.1 数据来源及预处理
数据来源于国家人口健康科学数据中心(http://dbcenter.cintcm.com/)中国方剂数据库共84 464首方剂及中国中药数据库共8 173种中药。84 464首方剂数据包含的方剂信息项有:名称、别名、组成、出处、功效、主治、附注、用法、加减、制备方法、用药禁忌、各家论述。根据分析目的选取数据集中处方的中药组成和主治描述部分进行分析。经统计分析,该数据集涉及中药6 213种,病证5 436种。8 173种中药信息共有别名21 890个,每种中药平均2.7个别名。对上述方剂数据进行预处理:①由8 173种中药构建专用词表,对方剂药物构成部分进行分词;②对方剂中的所有中药同名药物进行统一替换;③为保证模型中的多项分布,去除中药构成少于3种的方剂。
3.2 参数设置
DCTM及LDA为无监督学习模型,主题参数K对实验结果影响较大,由于方剂功效与病证及组方有直接关系,因此,分析中借助数据集自带的功效项,统计出数据集共有479种功效,作为依据来确定实验各模型参数K=479。另外,参照文献[15,21],EM算法的迭代次数为500,似然边际不小于10-5;变分推断的下界不小于10-6。
3.3 分析结果
金代成无已《伤寒明理药方论》首次以君臣佐使组方原理完整解析了《伤寒论》的20首常用经方,开创了后世君臣佐使方论的先河。为进一步评估本研究建立的DCTM模型对中药方君臣佐使组方规律挖掘结果,分别计算20首经方的DCTM分析结果,并与《伤寒明理药方论》的君臣佐使注解[22]进行对比。
20首经方中,小青龙汤包含药物最多,有8味药,其他多为4~7味药,为方便比较,本研究中君药和臣药各取1味。20首经方DCTM分析结果与《伤寒明理药方论》注解对比见表2。表中,k=argmax(θd,k)=i,表示在DCTM模型分析结果中选取方剂d的主题概率最大的主题编号i,θd,i为该概率值;Top(φsd,i)n表示取方剂d中,主题i概率最高的前n个病证;Top(φhd,i)n表示取方剂d中,主题i概率最高的前n个中药;argmax(ρi,j)表示取与主题i相关度最高的主题j。

表2 20首经方DCTM分析结果与《伤寒明理药方论》注解对比
DCTM模型能够正确分析大部分君药,20首经方中有15首与《伤寒明理药方论》注解一致,其他5首经方中有2首君臣药角色篡位;臣药共有8首与文献一致,臣药不全的有2首,其中桂枝汤由于臣佐药角色兼职导致DCTM模型不能正确识别;此外,栀子汤模型给出的臣药黄连不在该经方内是由于DCTM模型以主题相关性进行关联主题所得臣药,黄连在该关联主题中出现概率过高导致分析结果有误。结果偏差较大的是大陷胸汤,臣药标注为君药,将君药标注为佐药。综合其他几个差错较大的方剂如栀子汤、大陷胸汤、茵陈蒿汤和建中汤方可见,经方包含药物较少,一般少于4味药的容易标注错误;另外,一味药兼多个角色的经方如桂枝汤也易出错。
采用准确率、召回率、F1-得分对20首经方的DCTM分析结果进行评价。君药的准确率、召回率、F1-得分分别为0.75、0.75、0.75,臣药的准确率、召回率、F1-得分分别为0.50、0.45、0.47,佐药的准确率、召回率、F1-得分分别为0.71、0.85、0.77,使药的准确率、召回率、F1-得分分别为0.81、0.43、0.56。
由评价结果可以看出,部分指标较低,尤其是臣药和使药,分析其原因主要为统计的中药方数量较少。另外,DCTM分析结果中差错较大的是臣药和使药,臣药容易与君药或佐药混淆,使药主要起引经和调和作用,因此很多使药的应用具有很大的灵活性,本研究中对使药的识别采用固定的集合匹配方式,存在不足之处。尽管如此,20首经方DCTM分析结果中,有8首方的臣药标注结果与《伤寒明理药方论》注解一致。

续表2
4 讨论
为探究中医方剂君臣佐使配伍原则和规律,本研究提出一个涉及病证及中药,反映君臣佐使隐性结构的DCTM。本模型以病证和中药2种显性变量为线索,挖掘分析君臣佐使隐性结构。但是,自《黄帝内经》和《神农本草经》有记载以来,君臣佐使理论一直存在争议,且很多经典经方中君臣佐使的药物对应争议较大,君臣佐使理论尚未统一,权威标注君臣佐使文献严重欠缺,采用专家人工评判又存在争议性。为进一步评估DCTM对君臣佐使组方规律挖掘结果,本研究以《伤寒明理药方论》解析的20首经方君臣佐使注解为参照进行检验,结果表明,DCTM对君药识别较为准确,能够对大部分经方的佐使正确识别,对臣药的识别结果一般。由于缺乏已标注的数据集,模型还需进一步寻求其他验证方法,有待今后提高和改进。
猜你喜欢
世界科学技术-中医药现代化(2021年8期)2021-12-21 07:03:54
中国民间疗法(2021年19期)2021-11-20 06:23:00
中国民间疗法(2021年9期)2021-07-22 08:05:08
世界科学技术-中医药现代化(2021年12期)2021-04-19 12:32:48
中国中医急症(2019年10期)2019-05-21 07:20:28
医学信息(2018年6期)2018-06-17 05:15:36
中药与临床(2017年4期)2017-01-14 12:23:23
转化医学电子杂志(2015年4期)2015-12-27 12:17:00
中医研究(2014年12期)2014-03-11 20:29:58
中国中医药现代远程教育(2014年14期)2014-03-01 04:27:17
