
基于生成对抗网络的煤矿工人脸图像超分辨方法
2022-12-19 10:19高志军冯娇娇
黑龙江科技大学学报 2022年6期
高志军, 冯娇娇
(黑龙江科技大学 计算机与信息工程学院, 哈尔滨 150022)
0 引 言
煤矿工人脸图像是实现智能矿业的重要信息载体,由于工作环境的特殊性,高质量的煤矿工人脸图像难以获得[1],因此,通过有效地利用计算机和图像处理技术处理低分辨率(Low resolution, LR)图像,生成具有清晰边缘、清晰纹理和完整保色的高质量、高分辨率(High resolution, HR)图像是国内外学者关注的焦点[2]。
图像超分辨率重建技术一般被分为基于插值[3]、重建[4]和深度学习三类[5]。基于插值的算法即通过邻近像素点的灰度值估算待插像素点的灰度值。传统的双三次插值方法[6]操作简单迅速,但易丢失图像细节。基于重建的算法分为频域方法[7]和空域方法[8],频域方法通过消除频谱混叠重建图像的信息。空域方法包括迭代反投影法(IBP)[9]、凸集投影(POCS)[10]、最大后验概率法(MAP)和正则化。该类算法在重建效果上有一定的提升,但计算繁琐,复杂度高。
基于深度学习的超分辨率重建技术的萌芽,受到国内外学者广泛关注。Dong等[11]将卷积神经网络(CNN)方法应用于超分辨率领域,用三层卷积的方法(SRCNN)完成LR图像到HR图像的重建。Dong等[12]进一步改进SRCNN得到一种快速超分辨率重建卷积神经网络(FSRCNN)。Shi等[13]提出了一种基于亚像素卷积层的超分辨率重建方法(ESPCN)。Goodfellow等[14]提出的生成对抗网络(GAN)为超分辨率领域提供了另一种可能性。Ledig等[15]将GAN的网络框架应用于图像超分辨率,建立了SRGAN模型。Wang等[16]实现了更高倍数的超分辨率重建,取得较好的效果。
在煤矿工人脸超分辨率的领域,需要解决在面目存在大量粉尘的情况下,得到清晰的、较多细节信息的煤矿工人脸图像。文中通过进一步改进SRGAN网络模型[15],在生成器网络中,采用去除批量归一化层的残差密集块进行深层特征的提取,同时,增加残差密集块的个数,实现生成对抗网络的加深,有效避免重建图像出现伪影的现象。运用亚像素卷积层,逐步实现图像的上采样重建,摒弃原网络结构中的反卷积层,在重建图像时能保留图像更多的细节信息,利用感知损失、对抗损失以及L1损失的混和损失函数,使网络模型快速收敛到最优。
1 原 理
1.1 模型结构
Ledig等[15]在4倍放大因子下,提出了一种生成对抗网络的超分辨率算法,网络结构如图1所示。该模型以结合跳跃连接的深度残差网络(SRResNet)作为生成器的主要结构,将残差块数量定义为16个,采用3×3小内核的卷积层和64个特征映射,通过残差块加强信息跨层之间的流动,以及防止网络深度的加深导致梯度消失的问题。在鉴别器上,采用传统的标准鉴别器,整个鉴别网络是一个没有池化层的VGG网络,包含8个卷积层。
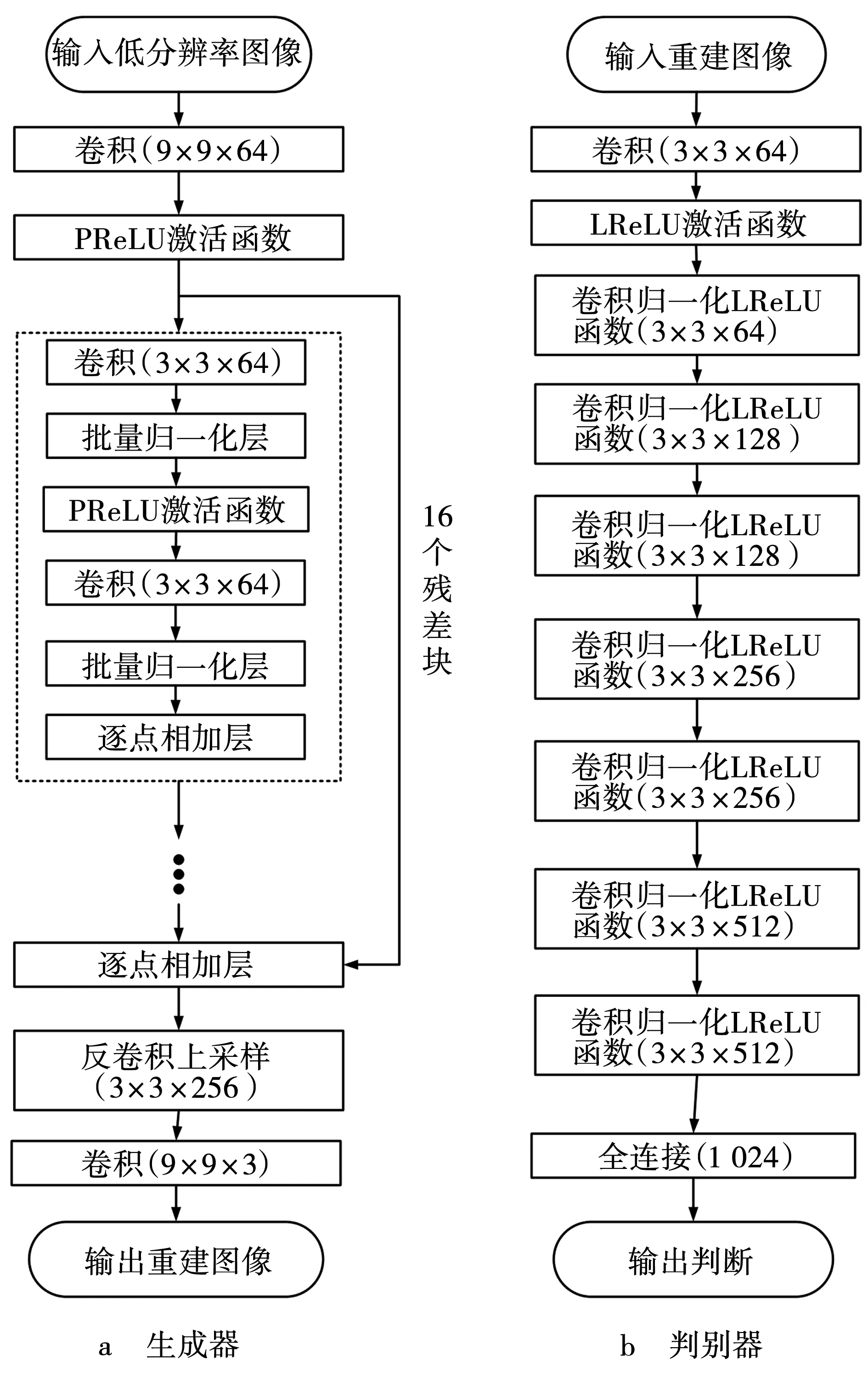
图1 SRGAN网络结构Fig. 1 SRGAN network structure
1.2 文中方法
鉴于煤矿工人图像的特别之处,脸部图像由于分辨率不足导致在某些环境下无法识别,因此,采用基于生成对抗网络进行煤矿工人脸部图像的超分辨率重建,生成器网络为主要部分并进行改进,总共分为三部分:浅层特征提取网络(SFENet)、深层特征提取网络(DFENet),以及重建网络(ReNet),整体的生成器网络结构如图2所示。
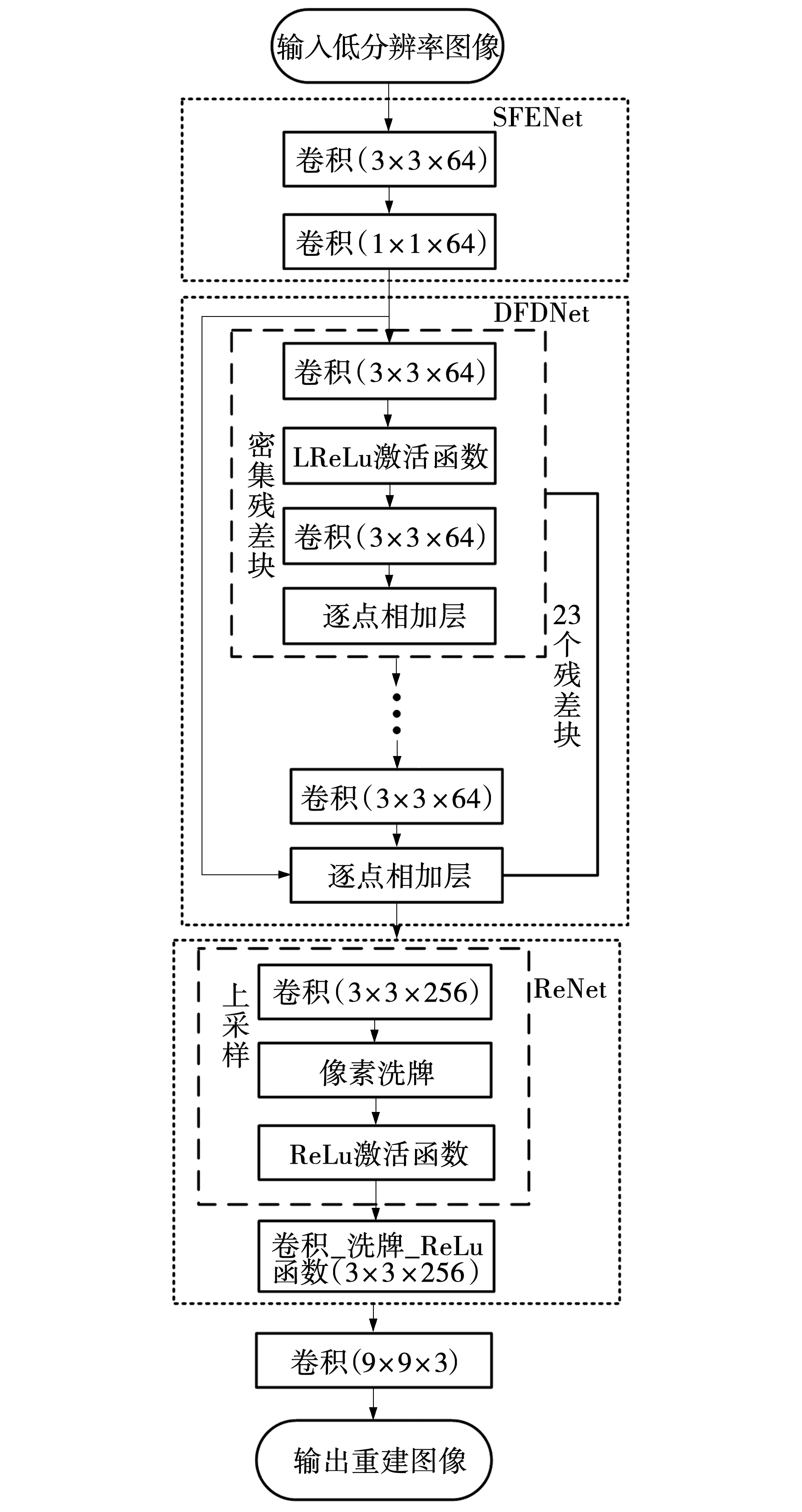
图2 文中生成模型结构Fig. 2 Structure of model generated in this paper
1.2.1 浅层特征提取网络
SFENet主要适用于提取图像中煤矿工人脸部的浅层特征,由两层卷积组成,第一层是卷积核为3×3的卷积层C3,用于提取第i幅低分辨率矿工人脸图像ki的边缘信息,完成矿工图像从空间维度到特征维度的映射;第二层为卷积核1×1的卷积层C1进行特征降维,网络表示为
F-1=C3(ki),
F0=C1(F-1)。
最终获得的F0表示为浅层特征提取网络的图像中矿工人脸的浅层特征[17]。
1.2.2 深度特征提取网络
DFENet采用残差密集网络结构,以SRResNet的残差模块为主干部分并进行了一定的改进。在SRResNet的残差模块中,存在批量归一化层(Batch normalization,BN),而BN层可能会引入伪影,同时可能会造成训练速度的缓慢。因此,移除BN层,对相加后的数据不再经过ReLU激活层处理,展示了残差结构的改进结构如图3所示。
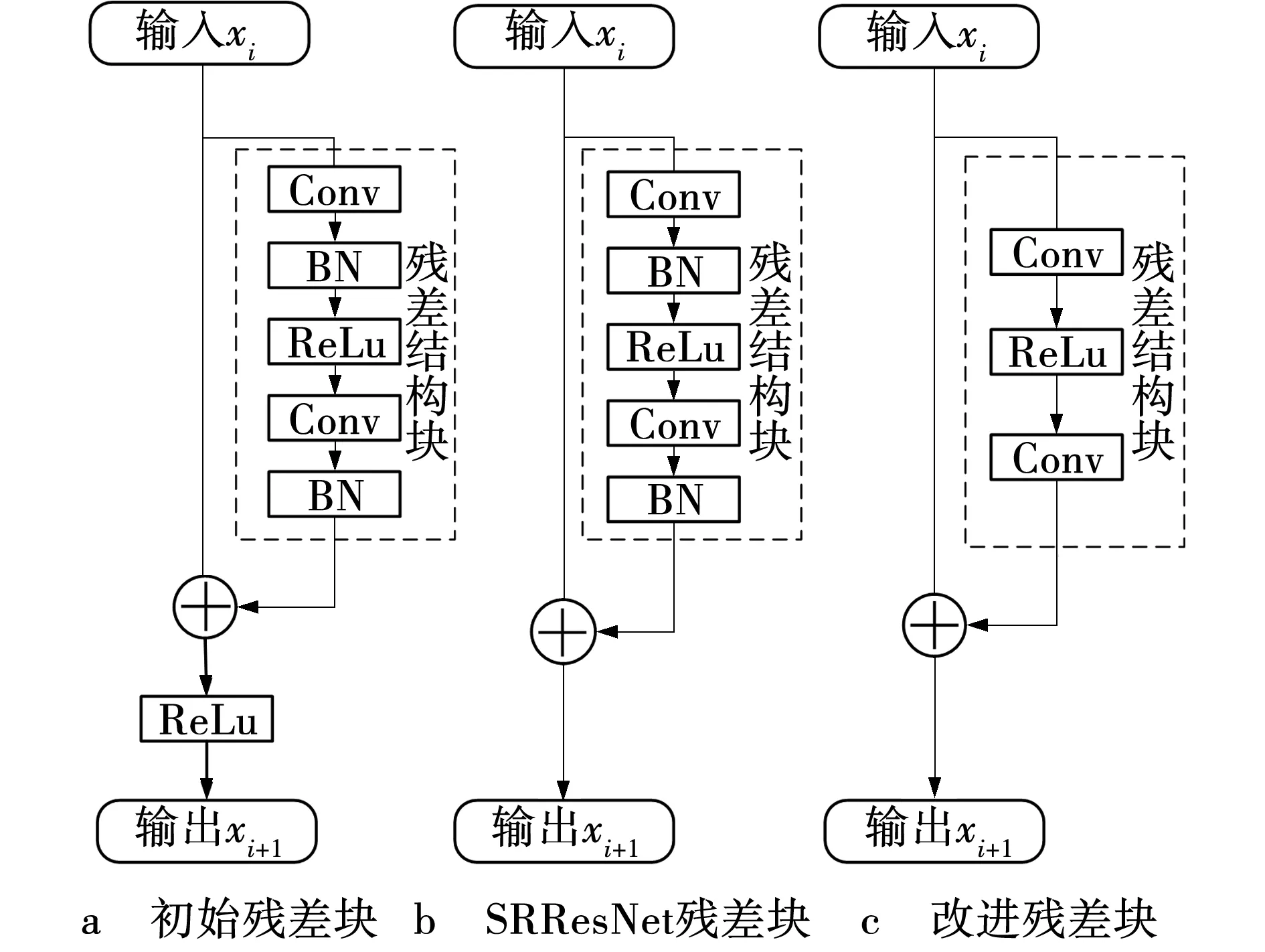
图3 残差块结构变化Fig. 3 Residual block structure change
DFENet整体采用两层残差结构,由多个残差密集块(Residual in residual dense block, RRDB)链接组成,能很好地将全局特征和局部特征融合形成一个连续的记忆机制。DFENet的主体部分RRDB由多个密集块(Dense block, DB)构成,比例为1∶3,每一个DB块都包含5个卷积核为7×7的卷积层和4个激活函数,卷积层步幅设置为1,如图4所示。通过密集连接卷积层提取丰富的局部特征,利用残差密集块的局部特征融合自适应地从先前和当前的局部特征中学习更有效的特征,使训练更加稳定。激活函数选用Leaky-ReLu,避免了丢失小于0的数据。
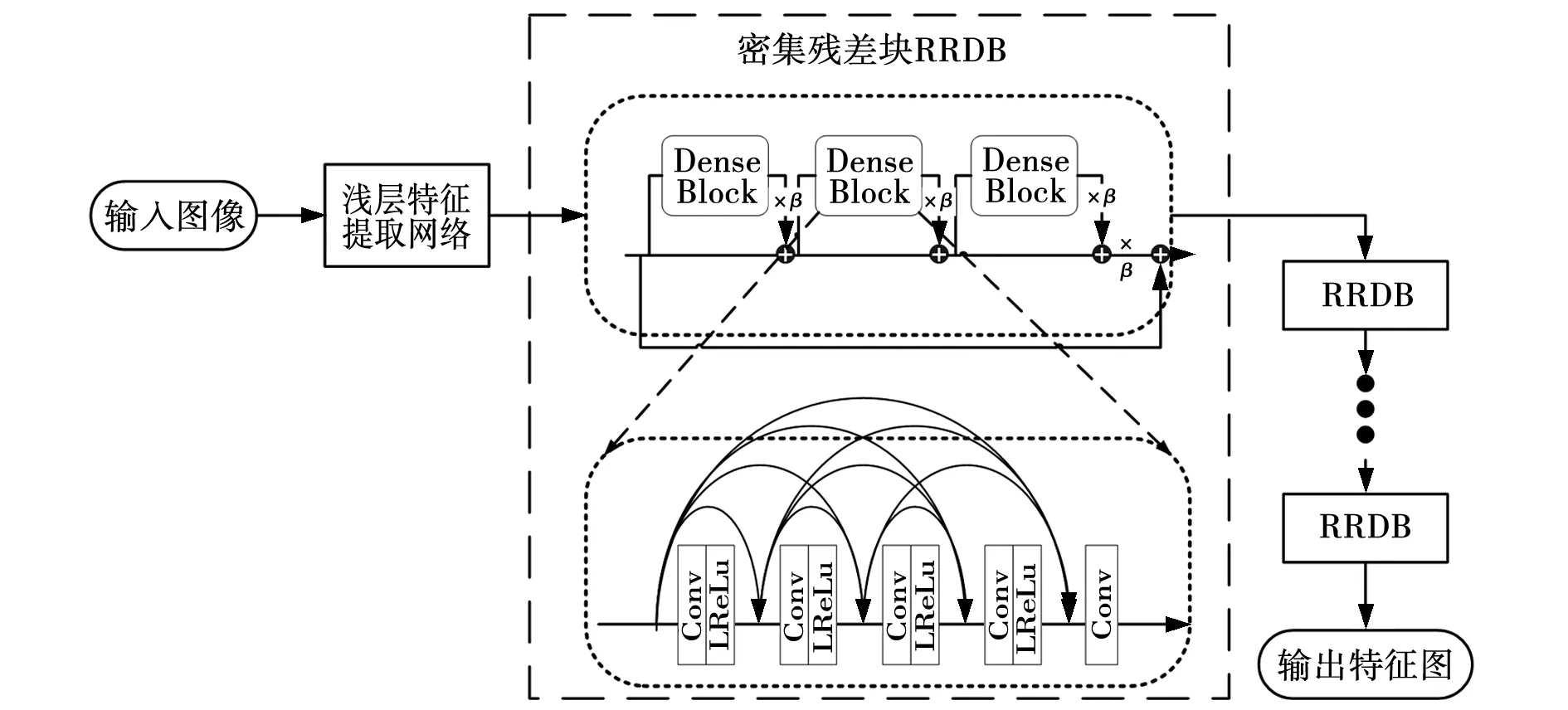
图4 残差密集块结构Fig. 4 Structure of RRDB block
同时,相较于原有的网络结构,残差密集块数量由16个增加为23个,通过残差密集块的数量加深网络,达到更高复杂度映射,提高了模型性能。
1.2.3 重建网络
原网络的上采样采用步长为0.5的两个反卷积层构成,反卷积层的方式易出现重建后的高分辨率图像的颜色有不均匀重叠的现象,因此,文中采用亚像素卷积层与逐步上采样的方式实现,该方法在超分辨率算法中,可以为图像重建提供更多的上下文信息。根据亚像素卷积层的原理,要完成4倍超分辨率重建,除了卷积层的引入还采用了像素洗牌重新排列组合的操作。4倍的放大效果分成两步完成,每一步完成2倍放大效果,使用两个3×3×256的卷积层,且每一层都经过像素洗牌操作,最终经过卷积层9×9×3输出重建图像。
1.2.4 鉴别器网络结构
在鉴别器上,传统标准鉴别器最终输出的概率是其来自真实样本的概率,仅能单纯地判别图像的真假,因此,文中采用相对鉴别器输出的是相对概率,即真实图像和生成器的生成图像之间的相对真实概率。
标准鉴别器定义为
D(x)=σ(C(x)),
式中:σ——sigmoid函数;
C(x)——非变换鉴别器输出。
相对鉴别器定义为
D=σ(C(xr))-E[C(xf)],
式中:xr——原始真实图像;
xf——网络生成图像,xf=G(xi);
xi——输入的低分辨率图像;
E[·]——mini-batch中所有假数据的均值操作。
1.2.5 损失函数
SRGAN[15]网络中,作者提出了一种基于感知内容损失的损失函数,该损失定义为重建图像与输入图像特征之间的欧几里得距离,可以更好地注重矿工人脸图像得细节特征,公式为
式中:IH——高分辨率图像;
IL——低分辨率图像;
Wi,j——VGG网络中特征映射宽度尺寸;
Hi,j——VGG网络中特征映射高度尺寸;
Φi,j——图像经过预训练VGG19网络中第i个卷积层之前的第j个卷积层的特征图,通过Relu函数激活得到的特征映射;
G——生成器网络。
因此,基于感知内容损失函数,文中网络模型采用一种混合损失函数,公式为
LG=Lp+λLG+ηL1,
式中:λ、η——平衡不同损失项的系数;
Lp——感知内容损失。
Φi,j(G(IL)x,y)2。
原模型内容损失函数的计算采用激活后特征,文中采用VGG19网络中第二次最大池化操作之前的第二个卷积层激活前特征,即为lVGG(2,2),在矿工人脸图像的超分辨率重建任务中,能对重建后的图像能更好保存色彩和亮度的信息。
LG为生成器的对抗损失,根据鉴别器可知,鉴别器的损失公式为
LD=-Exr[log2D(xr,xf))]-Exf[log2(1-D(xf,xr))],
则,生成器的对抗损失定义为
LG=-Exr[log2(1-D(xr,xf)]-Exf[log2(D(xf,xr))],
L1损失函数定义为
L1=Exi||G(xr)-y||1。
2 实验与结果分析
2.1 数据集与评价指标
数据集为采集到的煤矿工人脸图像,共有图像270张,进一步扩增数据集,扩增方法有图像左右上下翻转、图像分别沿x、y轴平移20个像素单位长度、图像旋转10°、图像对比度增强0.2或减弱0.2、图像亮度增强0.2或减弱0.2,经过5倍扩充后,数据集共有1 350张,其中,训练集占80%,测试集占20%如图5所示。通过 Matlab的双三次核函数对高分辨率图像进行下采样,比例因子r=4,得到对应的低分辨率图像。为了方便训练,高分辨率图像裁剪为512×512,则低分辨率图像为128×128。
超分辨率算法常用的评价指标包括:峰值信噪比(PSNR)和结构相似性(SSIM)。
PSNR经常作为图像质量的衡量指标。两个m×n单色图像I和P,均方误差定义为
式中:I——无噪声的原始图像;
P——I的噪声近似。
峰值信噪比定义为
式中,I——未压缩的原图像。

图5 数据集的扩增展示Fig. 5 Expansion of data set
SSIM是衡量两幅图像相似度的重要指标,取值范围为[0,1],SSIM的值越接近数值1,表示图像失真程度越小。
SSIM的公式为
式中:μx——图像x像素灰度的均值;
μy——图像y像素灰度的均值;
σx——图像x像素方差;
σy——图像y像素方差;
σxy——图像x和图像y的协方差;
c1、c2——常数。
2.2 实验
2.2.1 训练细节
文中的算法训练实验中,数据集的低分辨率图像与高分辨率图像之间以4倍的比例因子,最小批量大小(batch size)设定为16, HR的裁剪块大小(patch_size)设定为128×128。
模型训练中,学习率设置为1×10-4,并且在5×104、1×105、2×105和3×105迭代轮次时减半。损失函数L1的系数η为1×10-2,对抗损失函数LG的系数λ为5×10-3。
网络模型的训练过程使用Adam优化器,初始学习率为1×10-4,β1=0.9,β2=0.999,交替更新生成器和鉴别器网络,直至模型收敛。模型搭建通过PyTorch框架,操作系统为Linux,GPU为NVDIA GeForce RTX 3090。
2.2.2 实验结果
文中方法与双三次插值法(Bicubic)[17]、SRCNN[11]、FSRCNN[12]、ESPCN[13]、SRGAN[15]以及ESRGAN[16]方法进行对比实验,完成测试集的4倍重建, 峰值信噪比P与结构相似性S的对比结果如表1所示。
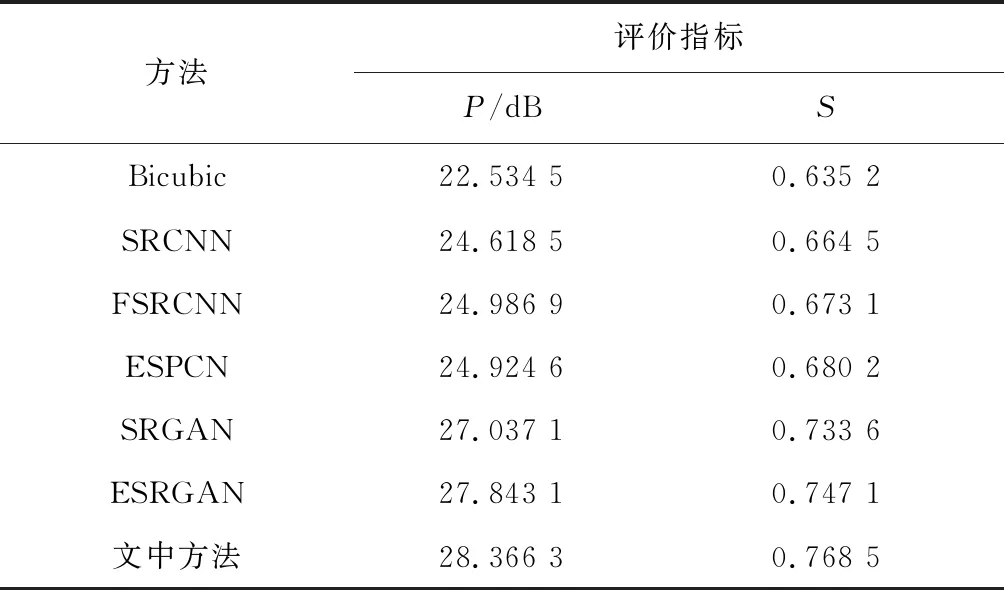
表1 不同算法的PSRN与SSIM对比结果
文中算法相较于Bicubic算法有较大的提升。相较于传统的卷积神经网络算法如SRCNN算法,PSNR提升了3.748 dB,SSIM提升了0.104;相较于FSRCNN算法,PSNR值提升了3.379 dB,SSIM提升了0.095;相较于ESPCN算法PSNR值提升了3.442 dB,SSIM提升了0.088。相较于SRGAN和ESGAN,PSNR值分别提高了1.329和0.523 dB,SSIM值分别提高了0.035和0.021。
将训练过程中每种算法的PSNR值随迭代变化的关系如图6所示。
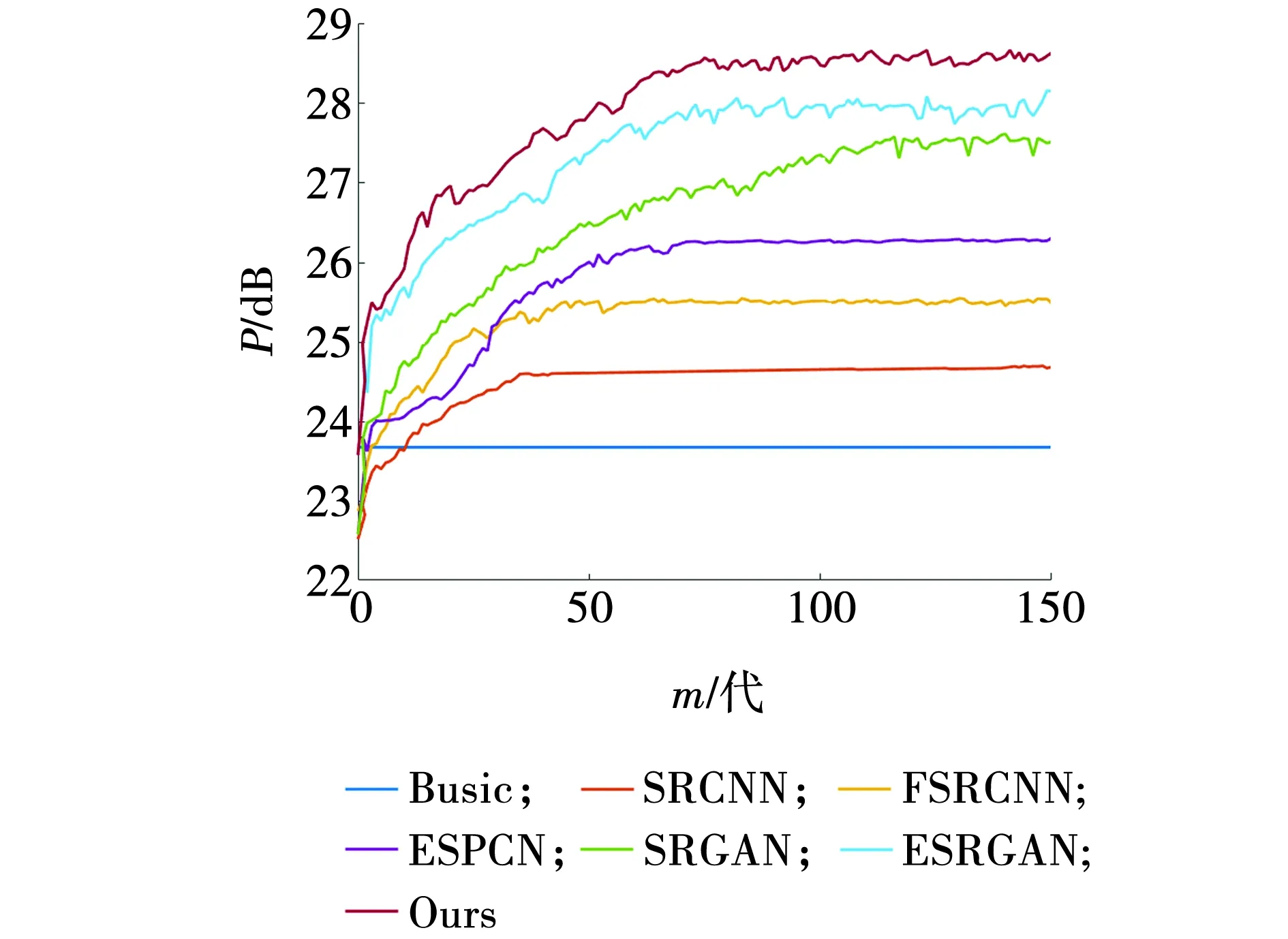
图6 不同算法的PSNR迭代对比Fig. 6 Comparison of PSNR iterations of different algorithms
由图6可知,训练100代后,文中方法模型在训练过程中PSNR值为最高,达到28.5 dB,并且文中方法的收敛性相对较好。
为了更加直观展示不同算法对矿工图像的4倍超分辨率重建效果,选取了正常光照下的矿工人脸图像如图7所示。

图7 正常光照下不同算法的矿工人脸对比Fig. 7 Comparison of miners′ faces with different algorithms under normal light
由图7可见,文中算法更好展示眼皮褶皱等细节信息,能更清晰的看到胡须、皱纹的纹理状况,整体色彩保存较完整,在视觉上更贴近真实图像。进一步选取了低光照射下的矿工人脸图像可视化图展示,如图8所示。

图8 低光下不同算法的矿工人脸对比Fig. 8 Comparison of miners′ faces with different algorithms in low light
由图8可见,在低光状态下,文中算法下图像能展示出眉毛的毛发状态,眼睛边缘的褶皱等细节信息,人脸的每个器官的轮廓相对更锐利,嘴巴的边缘、色彩等信息都保存较好。
2.2.3 消融实验
超分辨率领域,网络的深度,以及训练集中高分辨率图像的裁剪块(patch_size)大小对实验结果有较大的影响。因此,在文中算法中HR的裁剪块设为128×128、64×64,并分别在16个和23个残差块上进行4倍重建的实验,结果如图9所示。
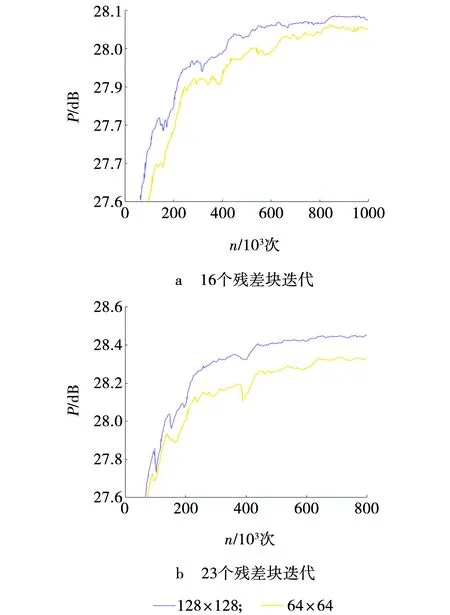
图9 不同残差块下裁剪块的迭代变化Fig. 9 Iterative changes of patch_size under different residual blocks
由图9可见,迭代6×105后,23个残差块的PSNR值约在28.3~28.5 dB,16个残差块的PSNR值在28.0~28.1 dB。在相同的残差块下,裁剪块为128×128比64×64的PSNR值高0.1~0.2 dB,因此,文中选用23个残差块,裁剪块大小设为128×128。
批尺寸(batch_size)设置的大小不同也会带来不同的训练效果。因此,在4倍放大因子下,将批尺寸分别设定为16、32、64进行实验,结果如图10所示。
由图10可见,迭代6×105后,三种批尺寸在训练集上的PSNR差值为0.117~0.126 dB,批尺寸设为16时PSNR值最高,因此,文中的批尺寸大小设定为16。
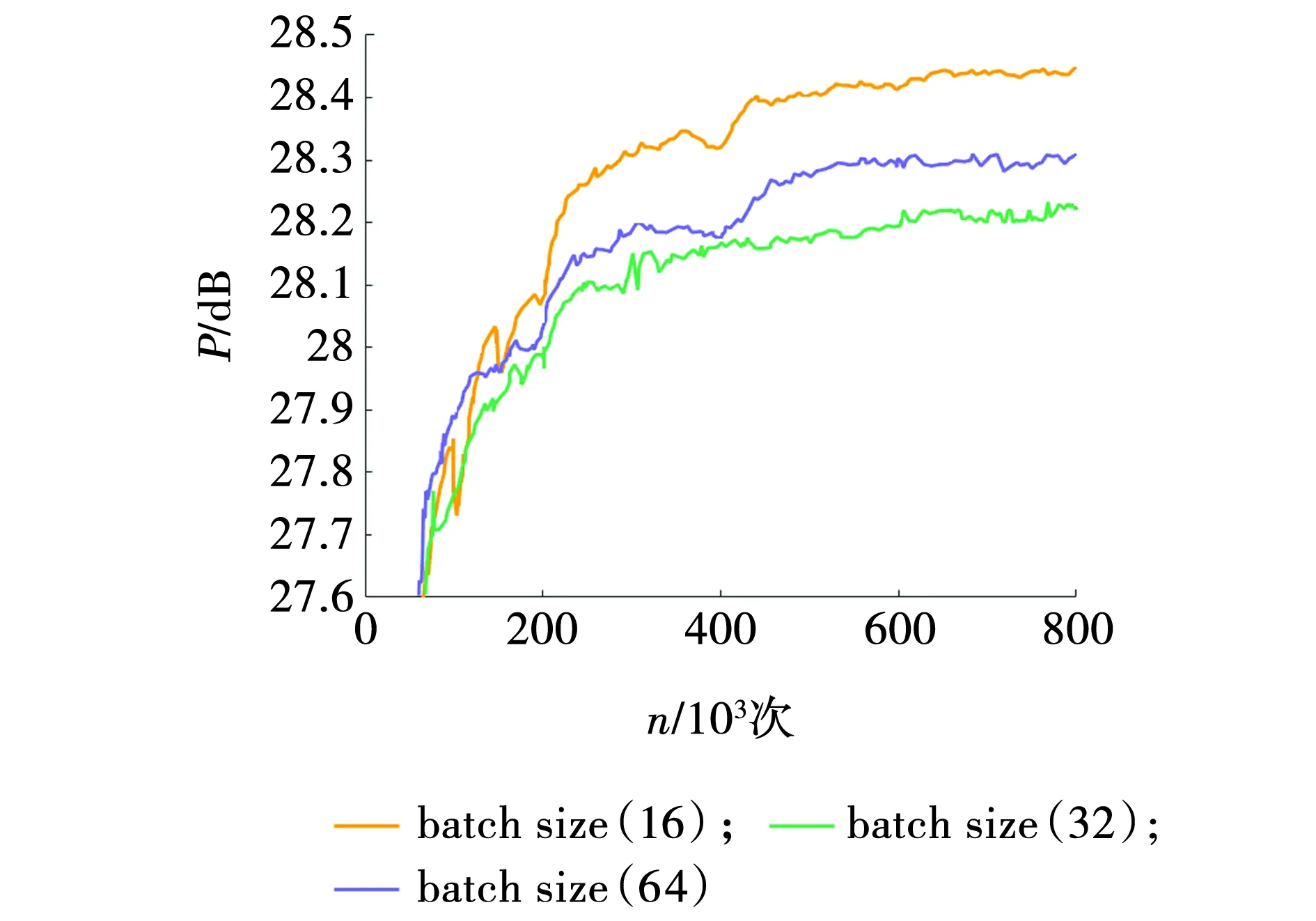
图10 不同批尺寸的迭代变化关系Fig. 10 Iterative change of different batch_size
在4倍放大因子下,设置四种情况,第一种情况,即为原网络结构,引用BN层,残差块为16个,上采样利用反卷积层;第二种情况引用BN层,残差块为23个,上采样利用亚像素卷积层;第三种情况引用BN层,残差块为16个,上采样利用亚像素卷积层;第四种情况不使用BN层,残差块为23个,上采样利用亚像素卷积层,四种情况的结果如表2所示。
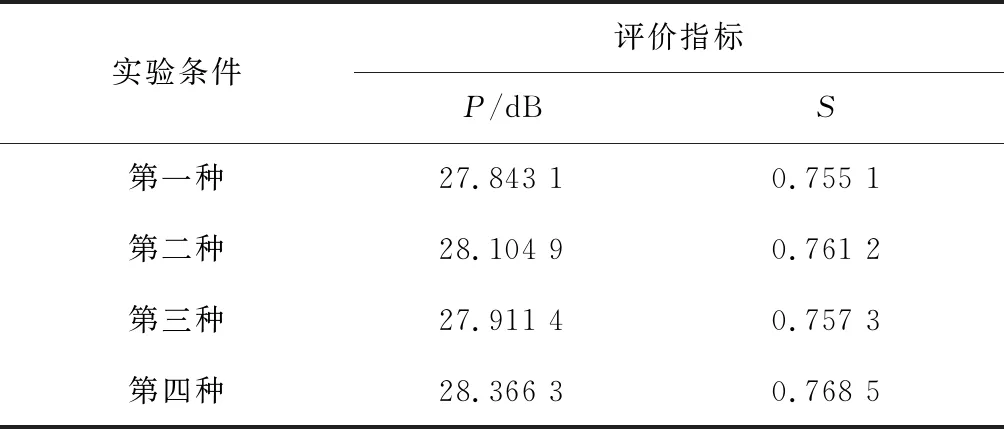
表2 不同实验条件下测试集的PSNR/SSIM结果
由表2可见,第一种情况为原网络,采用亚像素卷层后,第三种情况相较于第一种情况的PSNR和SSIM值分别提高了0.068 dB和0.002,在此基础上再提高网络深度,第二种情况相较于第三种情况的PSNR和SSIM值分别提高了0.194 dB和0.004,进一步删除BN层,文中方法即第四种情况比第二种情况的PSNR和SSIM值分别提高了0.261 dB和0.007,因此,文中方法即第四种情况的PSNR和SSIM值最高。
为了进一步展示不同实验条件对矿工人脸图像重建的影响,给出不同情况下的可视化结果,如图11所示。从视觉效果以及PSNR/SSIM的数值可知,删除BN层对于伪影的消除有一定的帮助,加深网络深度、采用亚像素卷积层能更好地保存矿工图像的色彩、图像边缘和细节信息。

图11 不同实验条件的可视化结果Fig. 11 Visualization results of different experimental conditions
3 结 论
(1)在原有超分辨率生成对抗网络模型的基础上,改进生成器,删除残差密集块的批量归一化层,将残差密集块的个数增加至23个,加深网络深度,可以更好提取图像的特征信息。同时使用亚像素卷积层,采用逐步上采样的方式,更好地保存了重建图像的边缘信息。
(2)文中使用了基于感知内容损失、对抗损失以及L1范数的混合损失函数,使生成器在重建矿工人脸时注意到图像的深层特征,在1 350张矿工人脸图像上进行训练、测试,实验结果表明,文中方法取得了较好的图像超分辨率重建效果。
(3)文中仅研究了4倍矿工人脸的超分辨率重建,下一步需要增加矿工人脸图像的2倍、3倍、8倍的图像重建,重建高倍数的矿工人脸图像,对模型的要求更高,仍需要进一步的学习和改进。
猜你喜欢
通信学报(2022年10期)2023-01-09
北京工业大学学报(2022年9期)2022-09-15
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
小哥白尼(趣味科学)(2021年4期)2021-07-28
中国盐业(2018年16期)2018-12-23
动漫星空(2018年9期)2018-10-26
作文通讯·高中版(2017年12期)2017-02-06
系统工程与电子技术(2016年5期)2016-11-02
奇闻怪事(2014年5期)2014-05-13
