
基于随机森林的气体传感器检测分类方法
2022-12-19 10:26靳春博刘新蕾
黑龙江科技大学学报 2022年6期
沈 斌, 靳春博, 刘新蕾
(黑龙江科技大学 安全工程学院, 哈尔滨 150022)
0 引 言
气敏感应器具有制造成本低、灵敏度高、稳定性好等优势,可用于无线传感网和电子鼻系统等领域[1]。由于气敏传感器本身的交叉敏感性和气体漂移现象的产生,以及受到工作环境中的外界因素影响,导致在各种气体环境中工作的单个传感器往往难以实现对目标气体的精确测量[2],因而数据传输时如何对监测数据实现精准的分析分类是当下的难题。
提升传感器数据分类精度主要有两种途径:一是提高传感器本身的性能,以减小因传感器本身问题对检测数据偏于理想情况的偏差;二是优化模式识别算法,以提升数据分类算法的分类能力[3]。陈寅生等[4]在提高识别二元结构有机物质成分准确性的实践中,发现了KPCA和MRVM可以组合鉴别,实验结果提高了识别精确度,但需要选择适合模型的核函数及设定参数ξ,使训练效率降低。秦轲等[5]利用主成分分析对BP神经网络进行优化,虽减少了主成分分析算法的信息冗余度,但BP神经网络结构依旧复杂。笔者采用兼顾随机和复杂度低的随机森林模型,减少算法运行的时间成本,同时又保持了较高的识别准确度,且训练过程中无需人工调节参数。
1 随机森林算法模型
1.1 算法原理
随机森林算法实质是由若干个决策树所构成的模型,而随机森林算法则是取模型内的各个决策树对决定结论加以票选,最高得票的为分类的基础结论[6]。由于随机森林模型以决策树特征为基础,所以对决策树数学原理也加以描述,而决策树计算则按照选择最优预测特征属性的不同,主要包括ID3决策树算法、C4.5决策树算法和CART决策树算法。
选择数据样本信息的数据增益划分最优属性的类别为ID3决策树算法。信息熵是反映统计样本集合纯度的指数,而信息增益ED出自信息熵,表达式为
(1)
式中:D——数据样本集;
Pk——第k类样本所占总样本的百分比。
由式(1)可知,ED的比值越小说明了数据样本集D的纯度就越高。用某一特征或属性的a划分集合D时会产生V个分支节点,记作第V个分支节点为Dv,得到属性a划分数据样本集合的信息增益为
(2)
ID3决策树算法的缺点是处理连续性变量属性的能力较差,存在利用偏向于分类较多的属性进行分类的情况[7]。
确定了样本中信息增益率的最优属性的类别为C4.5决策树算法,利用信息增益率的分析可以减少对ID3决策树算法的不良影响。表达式为
(3)
(4)
CART决策树算法是利用数据集合的基尼指数划分最优属性的,属性a的基尼指数为
(5)
基尼值Gi(D)用来表示数据样本集合D的纯度,即在数据样本集合中用随机抽取的方式类别不相同的发生概率,概率越小表示数据样本集合的纯度越高,基尼值的表达式为
(6)
随机森林首先使用自助采样法随机有放回的方法选择样本,每颗决策树将选择大约为总样品集合63.2%的数量作为初始训练集,剩余36.8%的数据用作测试集也可用于随机森林模型的改进优化。其次则是特征属性选择时的随机抽样,是为了在生成决策树时随机选取样本特征属性,然后将决策树进行组合构成随机森林模型[8]。随机森林模型的运算过程就是采用自助采样法对训练集进行训练,再通过训练结果产生若干个决策树,利用产生的决策树对样本决策分类最后取投票最多的为随机森林模型的分类结果。
1.2 性能指标
随机森林模型分类时会产生预测的数据集,该数据集与实际测试集存在偏差,预测正例与真实正例相同的称之为真正例,不相同的则称之为假正例,同样,预测反例与真实反例相同的称之为真反例,不相同的则称之为假反例。统计以上几种分类结果的情况可以得到二元混淆矩阵[9],见表1。

表1 分类结果混淆矩阵
由学习器预测的结果得到衡量算法模型优劣的评价指标:准确率A、查全率Se、查准率P、特异度Sp和F1值的表达式为
(7)
(8)
(9)
(10)
(11)
统计准确率为所分类样本分类正确的数量与样本总树的百分比,而查准率则表示将模型准确的度量,查全率即代表模型分析的真正例数,特异度即代表模型分析的真负例数,F1值为调和平均,是机器学习算法中比较常见的一个评价方法。
2 算法实现流程
随机森林模型本质是将多个决策树结合起来,每个树都是独立的且分布形式相同,而每个树的分类错误程度与各个树的相关性有关。在特征选取中,随机的对每个节点进行分割,并对不同情形下的错误进行比较。所探测到的内在估计误差、分类能力和关联度确定了所选取的特性数量。尽管每个树的划分工作能力相对较低,但经过随机地生成了大规模的决策树以后,能够根据各样本的划分结论加以计算,并从中选出最有可能性的类型[10]。随机森林的具体实现过程分为5个步骤。
步骤1给定的训练集合S,检测集合T,以及特征维度F。确定系数:决策树的数量t,每棵树的大小d,每节点所用到的特征量f,以及终止条件,节点s,节点上最少的信息增益m对于第i棵树,i=1∶t。
步骤2在S中有放回的抽取尺寸与S相同的训练集S(i),可以当作根节点的练习样本,从根节点中进行练习。
步骤3假设在当前节点上满足了终止要求,那么设定当前节点作叶子节点,该树叶节点的估计输出就是当前节点样本集中数量最多的那一个c(j),概率p为c(j)占当前样本集的百分比;假设当前节点不能满足终止要求,可在所有F维特征中随机选择f维特征(f≪F)。使用这f维特征,可以找出分类效率较好的一维特性k及阈值th,当前节点上所有样品第k维特性低于th的样品被分配到左节点,而剩下的则被分配到右节点。继续训练其他节点。
步骤4复制步骤2、3直到每个结点都被训练完了,或是被记录为叶子节点。
步骤5重复步骤2~4直至所有决策树都被训练过。
3 实 验
3.1 检测系统
文中所采用的实验系统见图1。其中,包括催化燃烧型气体传感器、数据采集系统、气源和计算机。
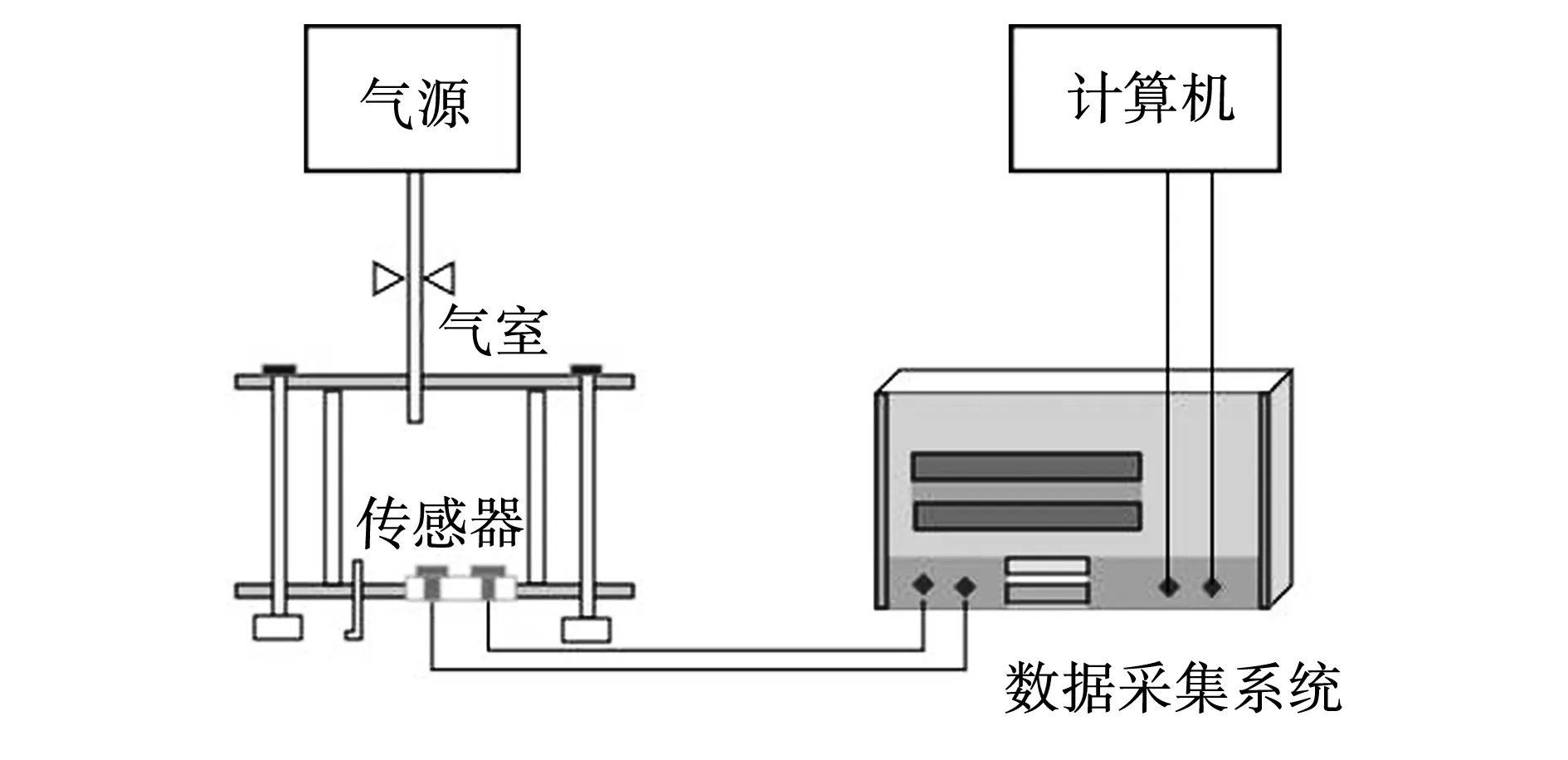
图1 实验系统示意Fig. 1 Schematic of experimental system
3.2 系统检测信号
选取二氧化碳传感器分别检测0.3%、0.5%、2%、10%和40%体积分数的二氧化碳进行系统检测实验,经过实验得到传感器的检测数据如图2所示。
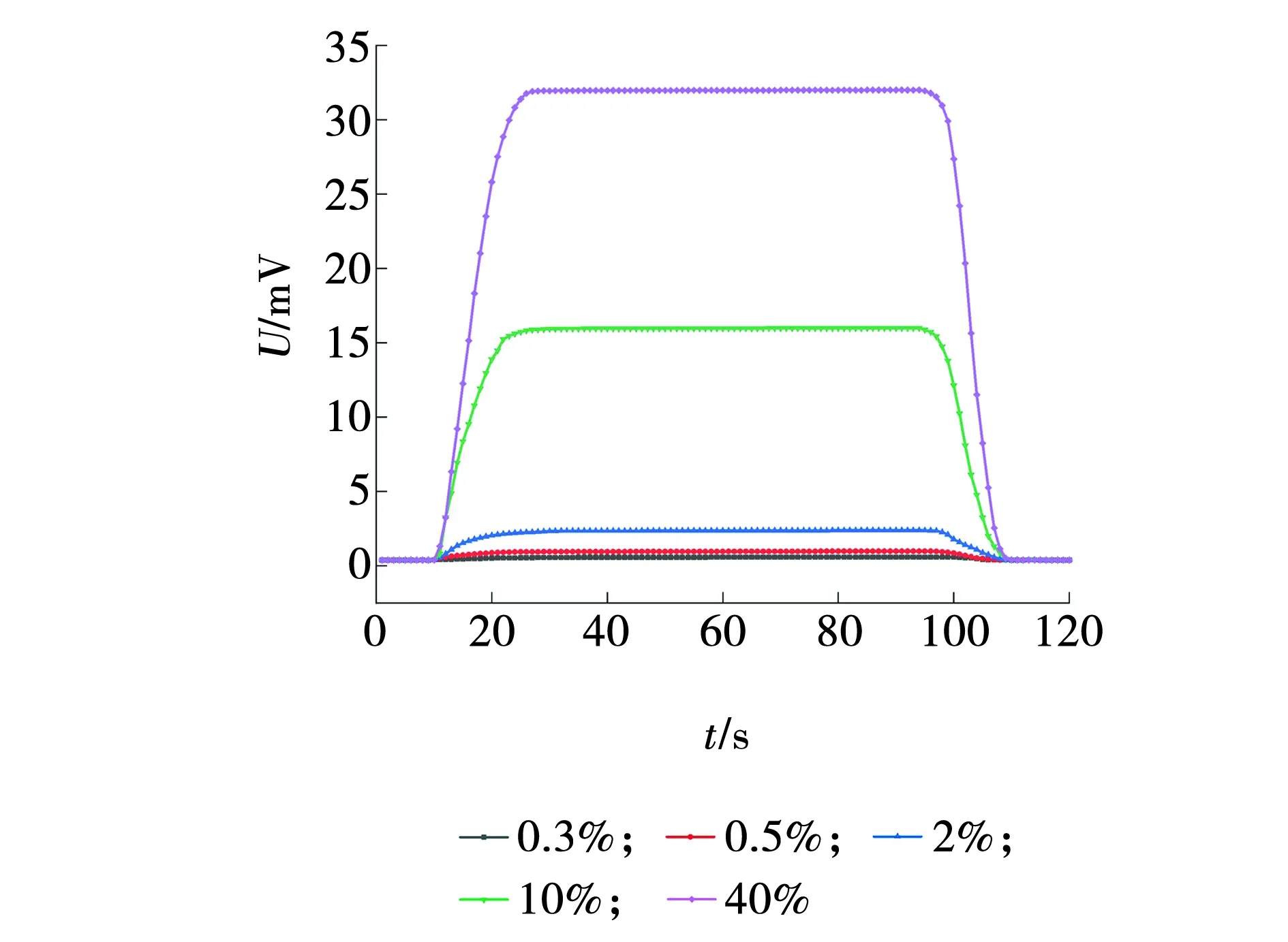
图2 检测信号及特征选取Fig. 2 Detection signal and feature selection
由系统输出信号可以观察出,不同时刻系统对不同体积分数二氧化碳的响应信号是不同的,从图2可以看出,在等待10 s后传感器开始响应二氧化碳气体,检测的输出电压逐渐提升,0.3%、0.5%、2%、10%和40%体积分数的响应输出电压在25 s处逐步趋于稳定在0.6、1、2.4、16和32 mV处,在98 s处阻断二氧化碳气体通入传感器时响应输出电压迅速回复到初始状态。从系统检测信号分析,系统对不同浓度气体的响应信号具有差异,因此,可以根据检测信号的特征信息实现检测气体浓度的区分。文中选取传感器响应曲线的输出电压值及其对应的响应时间点构成特征值向量用于后续的算法识别。
3.3 算法决策树棵树优化
决策树棵树一定程度上影响随机森林模型分类的准确性,因而确保准确度的同时需要尽量减少决策树的棵树,以提高模型的运行效率。设置的决策树棵树m在0~1 000棵范围内并以50棵递增,以不同棵树的决策树训练并取得精确度的均值,得到决策树的棵树和模型准确率间的关联,见图3。由图3可以看出,在训练决策树的每棵树总量较少时,精确度就比较少,而伴随训练决策树的增加,随机森林模型的精确度也在上升。而产生这个趋势的主要因素,是由于训练样本和节点变量都是随机选择的结果,当训练决策树总量较少时,会由于随机性而造成RF模式的精确度较低;当决策树的总量在逐步增加时,这种随机性就在不断减少,因为所有变数都可以更全面地对分类结果产生影响,从而训练模型的准确度也就在逐步提高;当训练决策树增长到一定规模时,随机数列对训练RF建模准确度所产生的影响就已经很小,所以即使是在不断提高训练决策树的规模,准确度也就没有增加。当模型内决策树棵数超过150棵时,建模精确度就不再提高,因此选取总决策树150棵为最优数量。
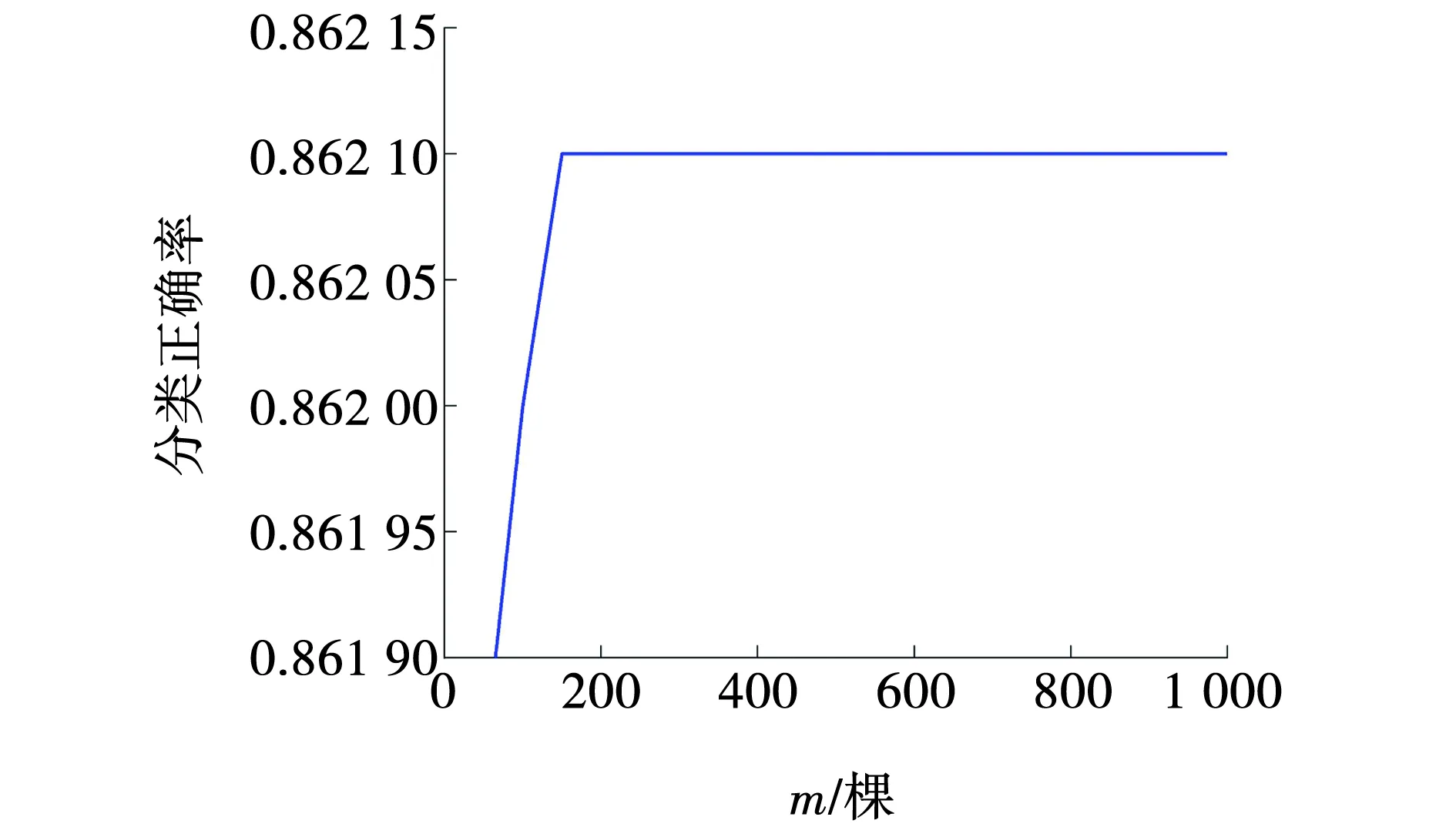
图3 RF模型准确率与决策树棵树关系Fig. 3 RF model accuracy and decision tree
3.4 模型分类结果
利用Matlab平台,建立了含有150棵决策树的随机森林算法模型,待模型构建完毕后选择实验系统响应5组不同体积分数的输出信号与特征向量数据各120个,共600组实验数据。并将实验数据以7∶3比例随机地分为训练集与实验集[11],数据划分的情况见表2。其中,η为训练集和测试集占总数据的比例。
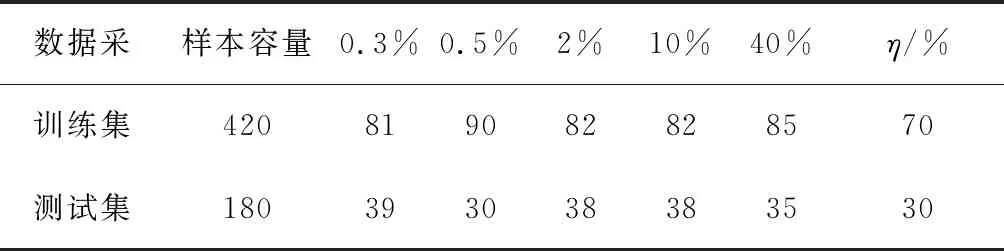
表2 数据样本划分详情
将处理好的数据导入到随机森林模型中进行训练,多次实验并统计分类结果取得模型的各个评价指标的平均值如图4所示。其中,百分比为w。
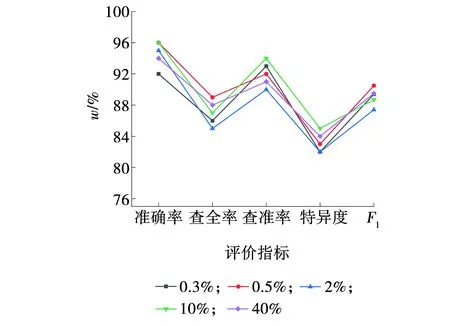
图4 RF模型性能指标Fig. 4 RF model performance index
从图4可以看出,RF模型对三种不同浓度气体分类准确率的均值分别为0.92、0.96、0.95、0.96和0.94也就是说,在理想条件下,随机森林模型对于不同气体的平均分类精度可以达到0.946,大大超过常规方法的精度;同时,该模型查准率的均值为0.920,查全率的均值为0.864,特异度的均值为0.824,F1的均值为0.891,表明了该模型在气体分类中的应用是可行的。利用机器学习技术对气体进行分类,可以显著减少人工费用,缩短分类时间,提高不同浓度气体的分类效率是未来气体传感器数据分类方法的趋势。
4 结 论
利用Matlab数学软件构建了随机森分类林算法模型,对实验所得CO2气体传感器数据进行分类实验。
(1)在传统传感器数据分类方法的基础上,提出了随机森林机器学习算法,将输出电压和对应时间以向量的方式进行结合,作为检测数据的特征向量,验证了随机森林算法的有效性。分析了决策树颗树对模型性能的影响,设置决策树的数量为150棵时模型分类正确率最高达到86.21%,使模型达到最佳分类性能。
(2)将数据导入到模型中训练,最终模型分类准确度为94.6%,实验结果证实,所提出的随机森林分类模型能够更高效地实现对传感器数据的分类。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
成都信息工程大学学报(2019年3期)2019-09-25
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年16期)2018-09-26
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
