
基于改进的Yolov5的端到端车牌识别算法
2022-12-16 09:22蔡先治鲁旭葆苗泽宇
计算机时代 2022年12期
蔡先治,王 栋,鲁旭葆,苗泽宇
(山东科技大学测绘与空间信息学院,山东 青岛 266590)
0 引言
车牌识别系统是智能交通和智慧停车不可或缺的重要一环,在万物互联的时代对于车辆信息的管理和车辆位置的规划都起着非常重要的作用。车牌识别算法按照流程可分为对图像中车牌边框进行定位,对定位的车牌进行字符识别两部分。
车牌定位算法,即通过车牌的某些特征来获取车牌的位置信息。传统定位的方法有利用颜色信息[1]、形态学特征[2]、边缘检测[3]等方法,对车牌进行定位。基于颜色信息的车牌定位,利用车牌和字符的颜色特征实现定位,该方法易受到光照和背景颜色的影响。基于边缘检测的定位,主要利用车牌的轮廓特征进行车牌定位,对于倾角较大的车牌图像定位效果不佳。传统的车牌定位方法,步骤繁琐、定位的精度低,需要利用新技术改进和提升。
近些年随着深度学习的发展,基于深度学习的车牌定位算法成为当下的主流。车牌定位算法可分为单阶段和双阶段两类。单阶段如Yolo系列,该类算法在获取候选框的时候同时得到位置信息和分类信息,该类算法具有速度快准确率高的特点。双阶段的算法,出现了像SSD[4]、Faster-Rcnn[5]这类算法,这类算法分两个步骤,先获取车牌的候选框,并不断对候选框的位置进行修正,再对物体分类,双阶段算法相比于单阶段算法准确率更高,可时间成本更大。
车牌识别算法可分为字符分割和无分割两种类型,传统的车牌识别方法多采用字符分割算法,再利用光学字符识别(Optical Character Recognition)对字符识别,常用算法有模模板匹配算法[6]、支持向量机[7]、ANN[8]等对字符进行识别,可这类方法步骤较多,容易逐步积累误差,造成识别准确率下降。随着循环神经网络(Recurrent Neural Network,RNN)的提出和发展,其对语音和文本的较好的识别能力,使得无分割车牌识别算法成为当前的主流算法,文献[9]利用BGRU 序列识别模型实现无分割的字符进行识别,文献[10]提出LPRNet 网络利用轻量化的卷积神经网络实现无分割车牌识别,识别准确率达到95%,可该算法中文数据集不均衡对中文识别能力较弱。
基于车牌识别在检测速度、模型的大小、可靠性等问题,本文以Yolov5 的端--端车牌识别方法为框架,通过在主干网络中加入EPSA 注意力模块、引入损失函数α-CIoU、增加检测尺度,再利用CRNN 字符识别模型实现端--端的车牌识别。同时采取车牌模拟的方法以应对中文数据集不足的特点,均衡各个省份车牌的数据集,达到数据增强的目的,提高中文字符识别能力。
1 Yolov5结构基本原理
Yolo 系列的算法,其特点是将目标检测算法转换成回归问题,可以快速的识别目标。目前已经推出了多个版本,如Yolov3、Yolov4。UitralyticsLLC 公司为了进一步这类算法提高检测精度和速度,推出了Yolov5 目标检测网络,相比于之前的算法无论是检测速度、精度、模型大小都有着不同程度提高。Yolov5按照网络结构的复杂度可分为Yolov5s、Yolov5m、Yolov5l 等版本,大小依次递增,本文考虑了模型的运行速度对程序的影响,以复杂度最小的Yolov5s 作为车牌定位的框架。
Yolov5s网络结构如图1,主要由BackBone、Neck、Head 等部分组成。Backbone 是特征提取网络,由Focus、csp 等结构组成。Focus 即为切片操作,通过扩大通道数量,再进行卷积实现下采样,在不提高模型计算量的前提下,保留更多图像信息。Yolov5s 将csp结构应用在Backbone 中,csp1 对信息进行提取,csp2负责信息的特征融合。Neck 结构是由FPN[11]特征金字塔和PAN 路径聚合结构所组成,FPN 是由上而下传递语义信息,PAN 是由下而上传递图像的位置信息,Neck 结构整合了上述两种结构,促进了主干网络中不同尺寸网络信息的融合。Head 即目标检测部分,主要用来检测不同尺寸图像,不同大小的Head头部负责检测大、中、小不同尺寸的物体。可由于Yolov5s 的设计主要是在中、大尺寸物体的检测,小尺寸物体由于分辨率低、图像信息不丰富,因此识别率较低,Yolov5 在这方面有着一定的改进空间。

图1 Yolov5结构图
2 基于Yolov5的车牌定位算法
2.1 引入注意力机制
Yolov5s 对于小尺寸物体的识别能力不能满足实际应用的需要,而在深度学习领域,通过加入注意力机制可以有效提高深度卷积网络的性能。考虑到EPSANet[12]结构可以有效的获取多尺度的图像信息,能够凸显小目标物体的权重信息,提高小尺寸物体的检测准确率,并且模型的参数小,轻量化。这里将在Yolov5s 主干网络中加入EPSANet 注意力模块,以提取更细粒度信息,提高多尺度信息的表达能力,抑制图像中无关信息的影响,强调车牌特征的表达,达到对车牌精确定位的目的。
EPSANet 模块具体可以分为以下几个流程,如图2所示,将输入的特征图送入到SPC模块中去,然后将其送入到SE[13]权重模块中,得到每个部分相应的权重,利用Softmax 对权重值进行归一化处理,使权重值映射到[0,1]区间。再将所得到的参数和分割的部分进行点乘运算,输出得到特征图再将各个特征图将其拼接起来。

图2 EPSA结构图
2.2 多尺度检测结构
Yolov5s 目标检测网络采用8×8、16×16、32×32倍下采样来检测不同大小的物体,对于以608×608大小的车牌为例,若车牌的宽度小于8 的像素点。网络很难学习到特征信息。另外小尺寸的物体分辨率低,信息量少,若对其进行复杂的卷积、下采样运算,容易造成信息的丢失,小尺寸目标更依赖浅层的图像信息。综合以上几点,本文将在原有的三个检测尺寸的基础上,将在浅层附近再增加一个检测尺寸,在主干网络浅层部分整合更多高分辨率的图像信息,以提高Yolov5s对小尺寸车牌的检测能力。
2.3 对IoU损失函数的改进
Yolov5s原本的检测框损失函数,使用的是GIoU[14],其公式为:

其中,IoU 为预测框(PB)与真实框(GT)的交并比,Ac为能够将预测框和真实框同时包含在内的最小的矩形,U 表示预测框和真实框的并集。GIoU 是从PB 和GT之间重合的面积来考虑,可以改善IoU 在PB 和GT 不相交时,梯度不能传递的情况。当PB 和GT 之间的相互包含的时候,由公式⑴、⑵可知GIoU 退化成IoU,会弱化实验结果。
本文在CIoU 的基础上结合结合α-IoU的特点,提出可调节边框检测损失函数α-CIoU。α-CIoU的定义如下:

其中b、bgt表示预测框和真实框的中心点,ρ 表示采用欧式距离计算两点之间距离。C表示同时包含预测框和真实框的最小矩形的对角线长,β 为权重参数,ν是用来衡量长宽比的相似性。α为该函数的调节参数,α可以取不同的值,实现不同的边框检测效果,该改进可以进一步挖掘原来目标检测框的能力,并且针对不同的数据集,找出其相对最优的α值,使其目标检测的效果达到最佳。
3 基于CRNN的字符识别算法
为了避免车牌分割造成字符被错分漏分,影响最后的识别结果,本文利用RNN 的改进方法CRNN[15]算法实现无分割车牌字符识别。
对于语音识别和文字识别,通常采用RNN,可RNN 在训练过程容易出现这梯度消失的问题,容易导致训练中断无法继续学习更深层等内容,只对相邻的序列有较好记忆功能,因此难以满足对于较长文本的序列识别。BLSTM[16,17](Bi-directional Long Shortterm memory)是RNN 的一种改进版本,能够学习到文本中较长的依赖信息,可以在一定程度上解决RNN梯度消失的问题,BLSTM主要通过门的结构选择性的让信息通过,过滤掉不重要的信息,实现信息的添加和移除,同时BLSTM 采用双向结构,即可同时利用序列的前向信息、后向信息能够更有助于序列的预测,得到更准确的结果。
其原理如图3 所示,首先利用车牌定位将车牌分割出来,再将分割的车牌送入到CRNN 网络中。具体流程图如下,利用卷积和池化层提取图像的特征图,将特征图按照宽度划分成26个小特征图,再利用双层BLSTM对这些小特征图的结果逐一预测,每一部分的特征图都对应图像的对应分割序列的感受野。再利用中文名CTC(Connectionist Temporal Classification)对BLSTM 的输出结果进行解码,得到每个车牌的字符,获取车牌的识别结果。
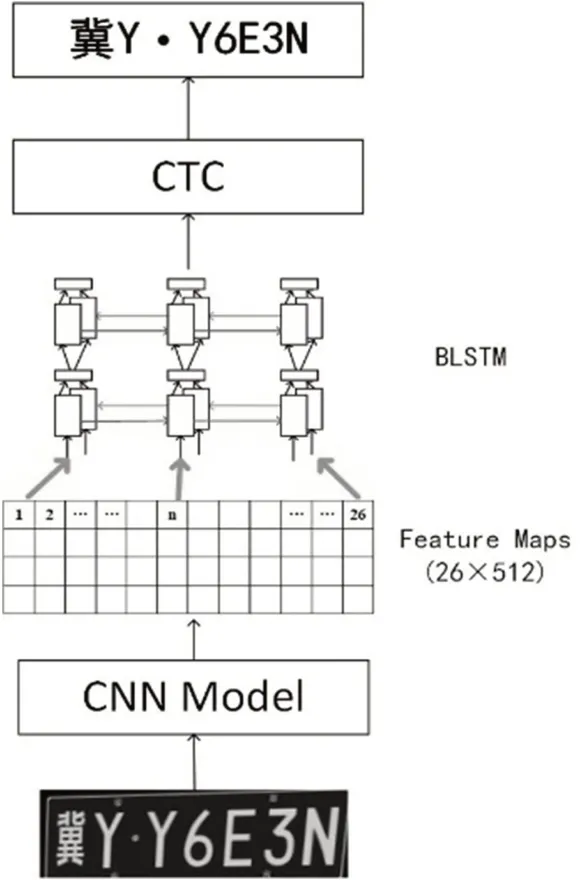
图3 车牌识别网络
4 实验与结果分析
4.1 实验数据
本文的数据集采用了网络上公开的CCPD 数据集,部分停车场数据集和自采车牌图片,共收集到10628 张车牌图像。在实际的识别过程中,车牌边框在图像中分布的位置、所占的整个图像的比例,影响着最后的识别结果。如图4(a)为目标框的中心点在图中的分布概率,图4(b)为样本边框与图片的长、宽比。由目标的空间、大小分布看,目标框由顶部至中间部分,依次增大,底部数据量较少,且小目标车牌的数据量较大。
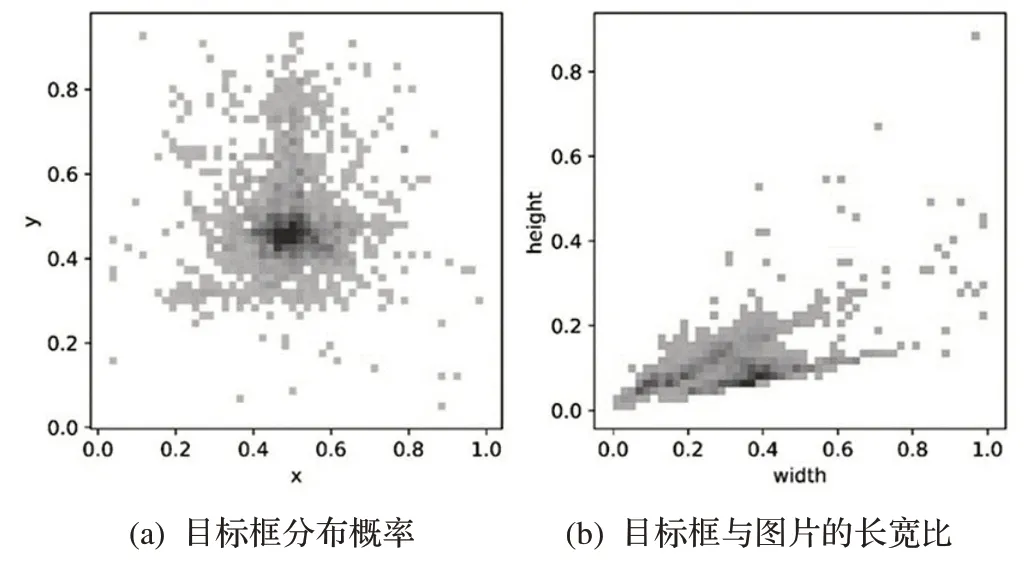
图4 车牌目标框的分布信息
训练车牌识别网络,若以一万张的车牌数据集为例子,由于字母和数字可以在一张车牌中重复出现,可在CRNN 网络中多次训练,而每张车牌只有一个中文字符,因此对于一万张样本的车牌数据集平均每个字符只有300 多个中文数据样本,这对于中文字符复杂的结构来说,较少数据量无法满足复杂的应用场景,这也造成了中文字符无法被有效的识别出来,无法满足实际训练的需要。另外,有些偏远的省份,车牌图像的收集难度较大,因此难以做到中文数据集均衡的状况。因此,本文将采用车牌图像仿真的方法,通过模拟在多雾、倾斜、灰度变化等情况下的车牌,达到数据集增强效果,其模拟的效果接近真实车牌,图5为部分仿真车牌图片。

图5 模拟车牌
4.2 改后的车牌定位算法验证
4.2.1 实验平台搭建及其准备
本文的所有实验环境是Window64 位操作系统系统下搭建的,电脑的16GB 运行内存,显卡采用NVIDIA GeForce RTX 3060 Laptop GPU,6GB,在pytorch torch 1.8.1+cuda11.1 平台下实现模型的搭建和训练工作。
训练信息如下,输入图像为640×640,对数据集按照9:1 的比例划分出训练集和测试集,学习率设置为0.001,批次大小设置为12,迭代次数设置为120次。
本文通过查看每个迭代下的平均检测精度(Average precision)的变化来比较模型的优劣,通过FPS(每一秒钟检测的图片的数量)来衡量模型的检测效率。
4.2.2 消融实验及对比
为了比较做出改进的每一部分对于车牌定位的具体影响,本文采用消融实验,分析每一部分对于车牌实际效果的贡献率,通过AP、FPS 的值,分析出模型的效果。通过对比的每一部分若使用该部分内容则用“✔”,若是未采用则用“✘”符号来表示。具体结构见表1。

表1 Yolov5消融实验
由表1的消融实验可知,EPSA 对检测结果的提升较为明显,AP值有着一定程度的提高,EPSA注意力机制可以有效地抑制背景加强目标信息的表达,使其对小目标特征提取能力得到提升,由于增加了网络的复杂度,相应的降低了识别速度;通过加入多尺度,能够有效提高网络的检测性能,相比之前的网络准确率提高了2.4%,使得之前在网络中被筛掉的小目标车牌,被检测出来。而改进的边框损失函数α-CIoU可以在一定程度上改善网络的性能,提高网络的定位精度,提高了0.6%的定位精度。由上述对比实验可知的结果可知,使用本文的改进后的方法可以有效的改善车牌的识别能力,抑制背景特征。
4.2.3 不同模型识别性能的对比
本文利用经典的网络模型如SSD、Faster-Rcnn、Yolov3、Yolov4、Yolov5做对比实验。
由表2的信息可知,本文方法的检测查准率、查全率都有着一定的提升,另外相比其他目标检测模型,本文的检测速度并不逊色。从权重模型的大小上看,本文的权重模型的大小是Yolov4 的1/3,是Faster-Rcnn 模型的1/22,权重模型占用内存空间较小,对移动端友好,降低了设备的运算量,提高了效率,可以方便的部署到移动端。改进后的方法与Yolov5相比,精度提高了4.6%,尽管检测速度却有所下降,可改进后的方法仍优于其他目标检测模型,能够满足实际应用的需要。

表2 主流检测网络性能对比
4.3 车牌识别模型验证
本文对车牌识别模型中共使用了18628 张车牌图片,其中采集的车牌10628 张,仿真的车牌8000 张,仿真的车牌主要是为了弥补数据集对于一些偏远省份数据量过小的影响。训练的批次大小设为12,设置为30 个训练周期,学习率设置为0.001,训练的框架为pytorch。本文从loss 和识别的准确率(accuracy)两个方面来衡量模型的效果。
由图6的训练的结果可知使用CRNN 模型的收敛速度较快,精度较高,识别准确率为96.5%,实际训练的模型的大小为7.1MB,对移动端友好。另外从图7的实际车牌检测效果看,本文的车牌识别算法对于车牌在遮挡、模糊、倾斜、灰暗条件下的车牌图像均有着较为好的识别效果,能够满足在各种天气、角度、昏暗条件的实际车牌识别需要。

图6 字符训练结果

图7 改进算法后的车牌识别结果
5 结束语
本文研究以Yolov5s 为框架端——端的车牌识别方法,通过加入EPSA 注意力机制,增加多尺度检测框可以有效的提高小尺寸车牌的检测能力,增强车牌在复杂背景的识别能力,另外引入的α-CIoU 检测框损失函数,提高其预测框结的精度。在车牌识别阶段,利用CRNN实现无分割的车牌识别也能达到较高的准确率,并通过车牌模拟的方法,实现中文数据增强,提高中文字符识别的准确率。实验表明本文的车牌定位准确率达到98.8%,识别准确率达到96.5%,且能够适应复杂条件下的车牌识别的要求。
猜你喜欢
医学食疗与健康(2021年27期)2021-05-13
电子制作(2019年12期)2019-07-16
中国交通信息化(2018年5期)2018-08-21
成都信息工程大学学报(2017年3期)2017-11-09
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
河南科技(2014年3期)2014-02-27
环球时报(2009-03-03)2009-03-03
