
基于影响空间与YOLOv3的古建筑检测方法
2022-12-11 13:33:30胡立华王敏敏刘爱琴张素兰
计算机技术与发展 2022年12期
胡立华,王敏敏,2,刘爱琴,张素兰
(1.太原科技大学 计算机科学与技术学院,山西 太原 030024;2.佛山市科自智能系统技术有限公司,广东 佛山 528010)
0 引 言
物体检测[1]是计算机视觉中的经典问题,主要任务是在静态图像或动态视频流中快速、精确地识别及定位出其中感兴趣的目标。目前物体检测已广泛应用于行人检测[2]、流量检测[3]、智能手机[4]等领域。物体检测方法主要分为基于传统的检测方法和基于深度学习的检测方法。传统检测方法主要依赖于图像处理技术或人工设计特征,由于该方法提取的特征是人为设计的,因此具有相对简单,无需学习与训练,仅需计算与统计的优点,但同时存在工作量大、不具备普适性和稳定性差等缺点。而基于深度学习的方法有较强的特征表达能力,具有检测精度高、检测结果稳定等优点,因此,基于深度学习的物体检测方法成为计算机视觉中研究热点之一。YOLOv3[5]作为一种基于深度学习的物体检测方法,首先采用k-means方法获取先验框(anchor),然后将先验框运用于YOLOv3模型的训练过程,最后输出检测结果。YOLOv3具有检测精度高、小物体识别能力强的优点。
古建筑是人类宝贵的文化遗产,是人类精神文明的载体,是人类历史长河中的里程碑。随着网络的发展,网络上的图片数量急剧增加,基于图像的古建筑检测方法具有重要的研究意义和应用价值,可进一步应用于古建筑的图像标注和智慧旅游等方面。因此,古建筑图像的物体检测具有重要的意义。而中国古建筑具有结构复杂、纹理重复严重等特点,基于k-means方法的聚类结果受聚类初始点选择的影响较大,因此基于YOLOv3的古建筑检测结果受聚类结果的影响,检测结果存在偶然性、不稳定性、检测精度差和定位不准等问题。
针对上述问题,以中国古建筑图像为对象,结合影响空间的思想,提出了一种基于影响空间和YOLOv3的古建筑图像检测方法。该方法首先结合密度聚类思想,采用RNN-DBSCAN方法对已标注图像聚类,利用差异性函数作为聚类度量函数,从而有效地解决了k-means算法使用欧氏距离方法聚类得到不稳定聚类结果(古建筑图像宽高比例)的问题;其次从聚类结果中选取k个结果作为初始聚类中心;并采用k-means聚类方法获得聚类结果,作为YOLOv3网络的先验框,有效解决了基于k-means算法的初始类中心的选择问题;然后依据先验框信息,训练YOLOv3网络;最后采用voc[6](20类)和中国古建筑数据集为对象,进一步验证了算法的有效性。
该文创新点如下:
(1)针对k-means方法聚类结果不稳定的问题,结合基于密度的方法,采用了差异性函数,设计了一种RNN-DBSCAN+k-means聚类方法。
(2)以古建筑图像为对象,设计了一种基于影响空间与YOLOv3的古建筑检测方法。
1 相关工作
1.1 物体检测
物体检测是计算机视觉的基本任务之一,过程为对于给定任意一幅图像,图像中的目标能够被正确地识别出它的类标签,且能准确地被定位出来。目前,物体检测方法主要分为两类:一类是传统的物体检测方法,另一类是基于深度学习的物体检测方法。
传统的物体检测主要是基于图像处理或特征的算法[7],此类算法主要采用传统的人工设计特征+浅层分类器的框架。典型方法包括:2001年,Paul Viola和Michael Jones在ICCV上提出了VJ算法[8]。该方法主要采用了滑动窗口检测第一次实现实时检测。2008年,Felzenszwalb提出了基于组件的DPM算法[9],该方法采用改进后的HOG[10]特征、SVM[11]分类器和滑动窗口检测思想实现物体检测。此类方法具有算法简单、速度快和适应变形的优点;但由于特征是人为设计,存在工作量大、无普适性和稳定性差等缺点。
与传统方法相比,深度学习具有比较强的特征表达能力。基于深度学习的检测方法主要包括两类:无锚框的检测方法和基于锚框的检测方法。无锚框检测方法的基本思想为去掉锚框,运用关键点或铺设锚点来检测物体。无锚框检测方法可为两类:一类是基于关键点的检测方法;另一类是基于中心域的检测方法。基于关键点检测的典型方法有:2018年,Law H等人提出基于关键点为角点的无锚框检测算法CornerNet[12]。该算法运用一对角点表示目标,通过角点池化、嵌入量等方法提高检测精度[13]。2019年,Zhou等人提出了基于关键点为4个极值点+1个中心点的无锚框检测算法ExtremeNet[14]。与CornerNet相比,ExtremeNet关键点的标注成本更低,由于极值点在目标上,标注4个极值点相对比较容易,但是缺点为速度慢,在实时中无法使用。基于中心域深度学习检测的典型方法有:2019年,Tian等提出一种基于全卷积的单级物体检测器FCOS[15]。该方法采用点+点到框的四个距离来表示目标,凭借NMS[16]后处理提高了检测精度,缺点为召回率低和缺乏理论的可解释性。
基于锚框的检测方法的基本思想是从已标注数据集中获取锚框,并以锚框为起点,对锚框的类别和位置进行矫正。基于锚框的检测方法分为两类:二阶段法和单阶段法。二阶段法也称为基于候选区域的检测算法。该方法分两个步骤实现,首先使用带有候选区域的CNN[17]网络产生候选区域,再在候选区域上做分类与回归。常见的二阶段法:2007年,Lou X等人提出R-CNN[18]算法。该算法采用选择性搜索算法[19]生成类别独立的候选区域,并运用SVM[11]和边界框回归来做物体分类和定位。2015年,Ross Girshick在R-CNN上采用SPP-net[20],提出Fast R-CNN算法[21],解决了R-CNN训练步骤繁琐的问题,在检测速度和精度上都有很大提升。2016年,Ross B. Girshick在Fast R-CNN上采用区域建议网络提取候选区域,将特征抽取、候选区域提取、边界框回归和分类都整合在一个网络,提出了Faster R-CNN算法[22],解决了Fast R-CNN不能实现端到端物体检测的问题。但该算法的计算量大,无法达到实时检测目标的目的。单阶段法将物体检测问题看作对物体位置和类别的回归分析问题,主要通过一个网络直接输出检测结果。常见的单阶段法:2017年,Joseph Redmon和Ali Farhadi在YOLOv1算法[23]的基础上采用批量归一化[24]、Darknet-19[25]网络结构和锚框卷积[26]等方法进行改进,提出YOLOv2[27]和YOLO9000[28],解决了YOLOv1只能检测单个物体和位置检测不准确的问题。2018年,Redmon在YOLOv2算法上将Darknet-19网络结构改进为Darknet-53[29],并采用softmax[30]函数分类方法,提出YOLOv3算法。该算法实现了多尺度检测,在兼顾实时性的同时保证了物体检测的准确性。
上述检测方法中,YOLOv3中采用的先验框,使得未训练前就具备目标的部分特征,可以在后续训练中降低网络迭代次数,加快网络训练速度,达到更好的检测性能。因此该网络具有检测精度高、检测速度快、端到端等优势。
1.2 聚类方法
聚类作为一种无监督模式识别方法,在图像分析、遥感、生物信息学和文本分析[31]等多个领域有广泛应用。聚类方法可分为基于划分、基于层次[32]、基于密度[33]、基于网格[34]和基于模型[35]的方法。
划分聚类中最具有代表性的是k-means算法。该算法思想简单、容易实现、运算速度快、空间复杂度和时间复杂度低,但也存在聚类结果依赖聚类数目k值及初始聚类中心[36]等问题。
在基于密度的聚类中,具有代表性的是DBSCAN[37]算法和RNN-DBSCAN[31]算法。DBSCAN算法的核心思想是用一个点ε邻域内的相邻点数目来衡量该点所在空间的密度。该算法可以找出形状不规则的类,具有不需要预先制定聚类数目、距离和规则相似度容易定义、限制少的优点。但也存在计算复杂度高、奇异值影响大的问题。与DBSCAN相比,RNN-DBSCAN算法有两大优势。首先,降低问题复杂性。因为RNN-DBSCAN算法只需要使用单个参数k,而DBSCAN需要两个参数minpts(阈值)和eps(邻域半径)。其次,DBSCAN在一定条件下使用基于距离的eps,导致该算法无法区分密度变化较大的簇。此外,DBSCAN聚类结果具有随机性,为了确保结果的确定性,必须使用对称距离度量,而RNN-DBSCAN算法没有这样的限制。
中国古建筑具有的结构复杂、纹理重复严重等特点和k-means聚类选取初始类中心的随机性导致聚类的效果时好时坏,不具有稳定性,从而在古建筑物体检测过程中存在古建筑图像特征提取不准确、定位目标不准确等问题。基于k-means的YOLOv3网络的检测结果会因此受到影响,检测精度低,效果差。因此,该文采用RNN-DBSCAN+k-means方法选取聚类初始中心,有效解决k-means聚类结果不稳定的问题。
2 基本概念
设给定图像集I={I1,I2,…,In},n为图像数量。首先需对图像进行标注,在图像标注过程中会产生相应目标的真实框Xi=(Xup,Xdown),1≤i≤m。其中Xup、Xdown分别表示左上角的坐标和右下角的坐标,即Xup=(ai1,bi1),Xdown=(ai2,bi2)。a、b分别表示X的横坐标和纵坐标,此时:
Xi=(ai1,bi1,ai2,bi2),1≤i≤m。
设给定样本集X={X1,X2,…,Xm},m=|X|,∀Xi∈X:∃Xi=(ai1,bi1,ai2,bi2)。
定义1:欧氏距离d(Xi,Xj)。
∀Xi,Xj∈X:Xi=(ai1,bi1,ai2,bi2),Xj=(aj1,bj1,aj2,bj2)且i≠j,Xi和Xj的欧氏距离d(Xi,Xj)可定义为:
定义2:交并比(intersection over union,iou)iou(Xi,Xj)。
∀Xi,Xj∈X:Xi=(ai1,bi1,ai2,bi2),Xj=(aj1,bj1,aj2,bj2)且i≠j,Xi和Xj的交并比iou(Xi,Xj)可定义为:
wij=min(aj2-aj1,ai2-ai1)
hij=min(bj2-bj1,bi2-bi1)
in_sectionij=wij×hij
xi_area=(ai2-ai1)×(bi2-bi1)
xj_area=(aj2-aj1)×(bj2-bj1)
定义3:差异性函数diff(Xi,Xj)。
在X中,∀Xi,Xj∈X:Xi=(ai1,bi1,ai2,bi2),Xj=(aj1,bj1,aj2,bj2),且i≠j,已知iou(Xi,Xj),Xi和Xj的差异性函数diff(Xi,Xj)可定义为:
diff(Xi,Xj)=1-iou(Xi,Xj)
定义4:检出率avg_iou。
在X中,设e为聚类算法得出的k个先验框,iou(Xi,e)为第i个真实框和先验框的交并比,则X和e的检出率avg_iou可定义为:
定义5:X的k近邻。
∀Xi∈X,Xi的k近邻由函数Nk(Xi)=N定义,其中N满足以下条件:
(1)N⊆X/{Xi};
(2)|N|=k;
(3)∀Xi∈N,Xz∈X/(N+{Xi}):diff(Xi,Xj)≤diff(Xi,Xz)。
定义6:X的逆k近邻。
∀Xi∈X,Xi的逆k近邻由函数Rk(Xi)=R定义,其中R满足以下条件:
(1)R⊆X/{Xi};
(2)∀Xj∈R:Xi∈Nk(Xj)。
定义7:直接密度可达。
如果Xi和Xj满足下列两个条件时,Xi是Xj可以直接达到的密度:
(1)Xi∈Nk(Xj);
(2)|Rk(Xj)|≥k。
定义8:密度可达。
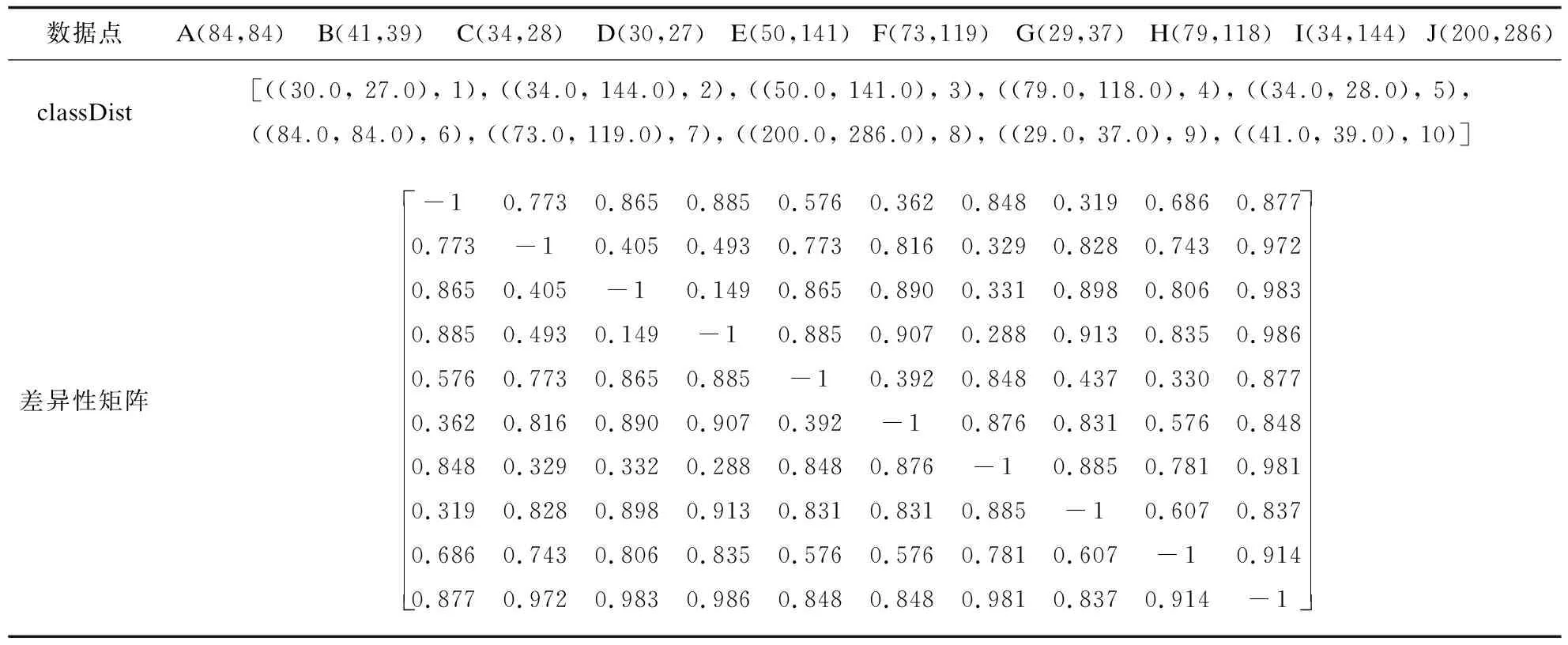
如果有一个链X1,X2,…,Xm,X1=y,Xm=x,且满足|Rk(x)|≥k。如果满足如下条件的话,则x是y的密度可达。
(1)∀1≤i≤m-1:当|Rk(x)| (2)∀1≤i≤m-2:观测点Xi+1从观测点Xi直接可达的,或者说,观测点Xi从观测点Xi+1直接可达的。 定义9:类。 一个类别C是X的一个非空子集(∅≠C⊆X),满足下列条件: (1)∀Xi,Xj∈X:如果Xi∈C且Xj是Xi的密度可达,则Xj∈C(极大性); (2)∀Xi,Xj∈C:Xi和Xj密度相连(连接性)。 定义10:类的密度。 给定类别C,设C的密度为C中核心观测之间的直接密度可达距离的最大值。类别C的密度由函数den(C)定义: 其中,y是x直接到达的密度。 基于YOLOv3的物体检测方法首先需对已标注古建筑图像真实框进行聚类,采用k-means聚类算法。然而针对古建筑图像,k-means算法聚类结果存在以下问题:(1)k-means算法的k个初始聚类中心是随机选取的,从不同初始聚类中心出发,得到的聚类结果也各不相同,因此聚类结果容易陷入局部最优解。(2)标注的古建筑图像真实框具有宽高差距大、宽高比例不一的特点,若k-means算法选取的k个初始聚类中心处于真实框的k个高密度分布的区域,则聚类效果极佳,用时短;若k-means算法选取的k个初始聚类中心处于真实框的k个低密度分布的区域,则聚类效果极差。因此,基于k-means算法的初始聚类中心的选择会对聚类结果产生很大的影响。而古建筑图像真实框具有宽高信息差距大、比例不一的特点,依据古建筑的这些特点容易形成高密度区域。所以,结合密度聚类方法可有效提高聚类结果。在所有的密度聚类方法中,RNN-DBSCAN具有参数少、可应用于各种形状的优点,具体聚类过程为:首先输入数据集和参数k,接下来计算它的k近邻和逆近邻,k近邻和逆近邻的并集组成了影响空间,然后以影响空间为聚类扩展条件,依赖密度可达等概念进行聚类拓展。影响空间的引入进一步确保RNN-DBSCAN的聚类中心来自于聚类高密度区域,从而得到最佳的聚类结果。 基于上述思想,该文设计了一种RNN-DBSCAN+k-means方法,该方法分两个步骤进行。首先运用RNN-DBSCAN算法对已标注古建筑图像的真实框聚类,得出多组迭代的聚类结果;再从这些聚类结果中选出检出率最高的一组;然后将RNN-DBSCAN算法得出的聚类结果作为k-means聚类算法的初始聚类中心,进行二次聚类;最后k-means聚类得出的结果则为最终结果,作为YOLOv3网络训练的先验框。 RNN-DBSCAN算法作为基于密度的聚类算法,具有能准确识别噪声点、处理任意形状和大小的簇的优点,因此,基于RNN-DBSCAN的聚类结果可有效确定聚类高密度区域,进而准确定位聚类中心,从而解决k-means方法聚类结果波动性大、不稳定的问题。然而,RNN-DBSCAN得到的聚类结果受输入k值的影响较大,而YOLOv3网络进行物体检测的过程中需要9个先验框。因此,要想确保最终的聚类中心为9个先验框,基于YOLOv3的物体检测方法需要将经过预处理的所有真实框进行RNN-DBSCAN聚类,从得到的多组结果中挑出9个先验框。 基于上述思想,初始聚类步骤如下: (1)数据预处理。 a.输入n幅已标注古建筑图像,构建古建筑数据集I={I1,I2,…,In},从I中提取已标注真实框左上角和右下角的坐标信息Xi=(ai1,bi1,ai2,bi2),1≤i≤m。由于一幅古建筑图片中可能包含多个古建筑真实框,因此m和n的关系为m≥n。 b.依据下式: 将Xi转化为真实框的宽高信息为Mi=(wi,hi),1≤i≤m; c.构建真实框的类别列表classList,如第i、j、k幅图像的真实框宽高信息分别为Mi=(wi,hi),Mj=(wj,hj),Mk=(wk,hk),若满足wi=wj≠wk,hi=hj≠hk,则Mi和Mj表示相同的真实框,相应地,Mi、Mj是一类,Mk是一类,因此,真实框类别列表classList=[1,1,2]; d.将M中宽高信息完全相同的真实框去掉,形成N,记N的长度为N',即所有真实框初始为N'类; e.依据classList构建数据词典classDict,如上述第i、j、k幅图像的真实框所形成的数据词典classList=[[[Mi,Mj],1],[[Mk],2]]。 (2)计算差异性矩阵。 a.依据数据预处理获得的X,确定真实框总个数m,建立初始值为-1的m×m矩阵W,W即为差异性矩阵; b.∀Xi,Xj∈X,依据定义2和定义3,计算差异性函数值diff(Xi,Xj)=1-iou(Xi,Xj); c.依据差异性函数值更新差异性矩阵W,计算方法为:Wij=Wji=diff(Xi,Xj)。 (3)聚类过程。 a.数据信息整合: ①依据k(选取真实框Xi周围差异性函数值最小的真实框的数目)、M、classList和W,根据定义5,在差异性矩阵W中寻找与真实框Mi的差异性函数值最小的k个真实框,若这k个真实框为M1,M2,…,Mk,并标记为kMatrix[i]=(1,2,…,k),依据上述过程c个类别可生成kMatrix[m,m]; ②创建矩阵rMatrix[m,m],依据定义6,在kMatrix中找到每一个对象的逆k近邻rMatrix[i]=(1,2,…,k); ③构建数据信息整合矩阵IM,其中IM[i]=[M[i],rMatrix[i],kMatrix[i],W[i],i,classList[i]],1≤i≤m。 b.聚类扩展: ①创建长度为m、初始值为-1的数组assign,assign即为类别矩阵,其中-1表示未分类; ②创建类别cluster并赋值为1; ③依据定义7和定义8,依次遍历数据整合矩阵IM中的每个真实框Mi。以Mj为例,Mj是以Mi为中心的簇中的一个真实框,若rMatrix[j]的长度小于k,则assign[j]=-2,此时Mj被认为是噪声;若rMatrix[j]的长度不小于k,则认为密度可达,此时assign[j]=assign[i],依据定义9,Mj和Mi属于同一类; ④依据定义10,计算类的密度den(C),输出类别矩阵assign。 以10个数据点为例,数据集构造及聚类过程如表1所示。 表1 数据集构造及聚类过程 续表1 (4)获得聚类中心。 a.当m<3 000时,k=1,且每次迭代k值加1; 在上述迭代过程中,若聚类结果小于9,则终止迭代。从聚类数目不小于9个的聚类结果中挑出聚类数目最接近9的一组结果,并计算其检出率,其中,最接近9的聚类数目范围为(9,22)。最后,选出检出率最高的一个组合作为RNN-DBSCAN聚类的最终结果。 图1 RNN-DBSCAN聚类过程 为了提高聚类稳定性,减少噪声对聚类结果的影响,该文在采用RNN-DBSCAN方法得到检出率最高的一组聚类中心后,将这组聚类中心作为k-means算法的初始聚类中心,并运用差异性函数作为聚类相似性度量方法,采用中位数法(将簇中所有真实框的中位数的宽高信息作为更新后的聚类中心点更新聚类中心)进行k-means聚类。获得的最终聚类结果即为YOLOv3模型所需的先验框。 以Windows7操作系统为平台,AMD A8-5550M APU with Radeon(TM) HD Graphics处理器,12 GB内存为开发环境,以及开放源码工具箱python3.6、Tensorflow1.14.0、Keras2.2.5和opencv4.5.5为工具,实现了基于RNN-DBSCAN+k-means,结合影响空间与YOLOv3的古建筑检测算法。该算法共包括两部分,分别为古建筑数据集构建及网络训练、测试结果。 古建筑数据集共有12 660幅图像,包括4类古建筑类型:五台山龙泉寺、九华山旃檀寺、普陀山法雨寺和峨眉金顶寺。依照3.1节方法构建古建筑数据集,以数据集中的一幅图像为例(如图2所示),它所提取的真实框信息如表2所示。 图2 已标记的图像825 表2 图像825生成的真实框信息 voc数据集共有9 963幅图像,包括20种类型,分别为飞机、自行车、鸟、船、公共汽车、小汽车、猫、椅子、牛、餐桌、狗、马、摩托车、人、盆栽植物、羊、沙发、火车和电视监视器。 好的聚类算法产生良好的先验框,使得先验框在未训练前就具备目标的部分特征。在后续的网络训练中能够降低网络迭代次数,加快网络训练速度,更快取得最佳训练效果。 古建筑数据集可划分为训练集和测试集,如表3所示。其中,训练集占80%,测试集占20%。 表3 训练集和测试集的划分 该文采用YOLOv3网络对古建筑进行训练和测试。模型训练分为预训练和全训练。设置epoches为100,其中3epoch为预训练,其余为全训练。训练过程中每三次迭代保存为一个权重文件,方便后续确定最佳训练效果的迭代范围。训练完成后,用训练得到的权重文件对测试集进行测试,输入待检测图片,得到测试结果。 评价指标为检出率和检测概率。其中,检出率应用于先验框中,在RNN-DBSCAN+k-means算法得出先验框后,采用检出率验证先验框的有效性,用百分比表示。检测概率应用于YOLOv3模型的测试中,用来检测古建筑图像中成功识别古建筑的概率,也用百分比来表示。 以古建筑数据集和voc数据集为对象,验证算法检测结果的有效性,分别采用k-means算法和RNN-DBSCAN+k-means算法进行聚类,计算其检出率,具体结果如表4所示。 从表4可以看出: 表4 k-means方法和RNN-DBSCAN+k-means方法在两种数据集上的检出率 % ·针对古建筑数据集,采用iou的k-means物体检测结果相较于基于欧氏距离的k-means物体检测结果,检出率有所提升。主要原因是:将差异性函数(1-iou)作为聚类相似性度量,能将所有真实框中宽高比例相同或相近的真实框聚为一类,进而提高检出率;若依据定义1的欧氏距离,聚类结果是将宽相同、高相差较大或高相同、宽相差较大的真实框聚成一类,检出率较低。 ·在voc数据集和古建筑数据集中,RNN-DBSCAN+k-means算法与采用iou的k-means算法相比,除voc数据集的类别9、11、12、16和20因目标形态各异和样本数不足,导致检出率略低于iou k-means的检出率外,其余类别的检出率提升范围为0.1%~0.9%,在古建筑数据集中平均提高了0.33%;在voc数据集单类检测中,检出率提升最高为voc数据集类别1,检出率为0.84%。原因为:与k-means算法随机选取初始聚类中心相比,RNN-DBSCAN算法的聚类结果已具备目标的部分特征,将其作为k-means算法的初始聚类中心,聚类结果更加稳定,从而提高了检出率。 在古建筑数据集中运用YOLOv3模型检测的结果如下:以训练集中图像1为例,检测结果如图3左所示,检测概率为98%。以测试集中图像2为例,检测结果如图3右所示,检测概率为77%。训练集和测试集均取得了很好的结果。 (a)图像1(左) (b)图像2(右) 针对基于YOLOv3的古建筑检测结果不稳定的问题,结合影响空间思想,提出了一种基于RNN-DBSCAN+k-means的古建筑检测算法。该算法主要采用RNN-DBSCAN获得初始聚类中心,并以上述聚类中心为初始值,结合差异性函数与k-means获得聚类结果,并进一步得到先验框。将先验框用于YOLOv3网络对古建筑的训练中,得到更稳定的权重。检测结果在古建筑数据集上取得了很好的效果。同时,在非古建筑数据集(voc)上,RNN-DBSCAN+k-means方法获取先验框的检出率也有所提高,验证了采用RNN-DBSCAN+k-means方法获取先验框的有效性。 但RNN-DBSCAN+k-means算法也存在弊端,由于该算法是两种算法的组合,所以时间复杂度略高于k-means,有待进一步改进。该算法从整体上来说,获取的先验框更加稳定,有利于YOLOv3模型的训练和测试,检测精度有所提高。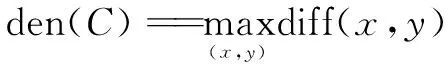
3 文中方法
3.1 初始聚类中心的确定

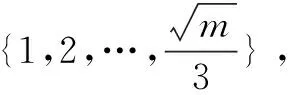



3.2 +k-means算法
4 实验结果
4.1 数据集及预处理



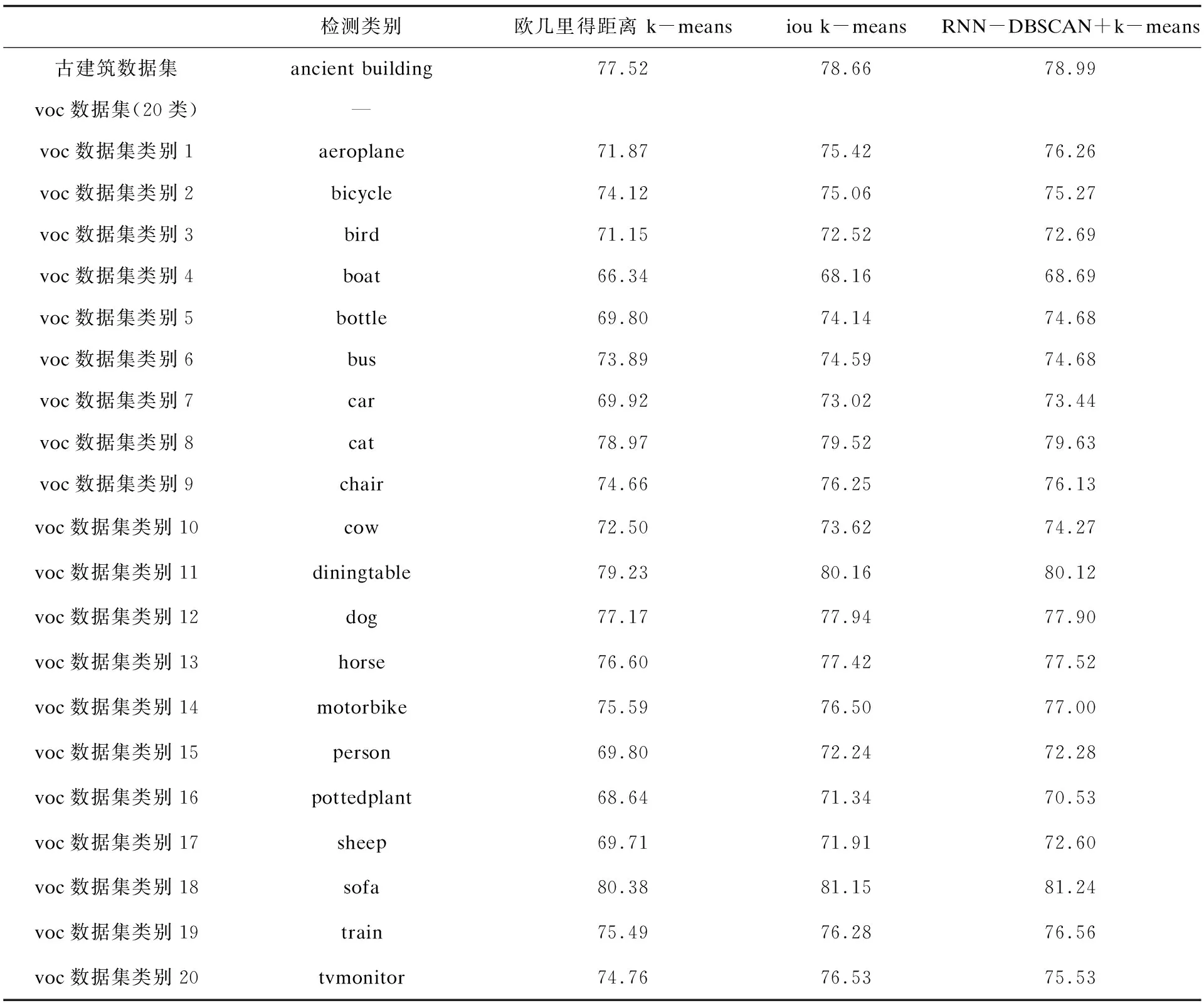
4.2 测试结果

5 结束语
猜你喜欢
学生天地(2020年31期)2020-06-01 02:32:16
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
视野(2018年18期)2018-09-26 02:47:52
自动化学报(2017年5期)2017-05-14 06:20:44
文物季刊(2017年1期)2017-02-10 13:51:01
探测与控制学报(2015年4期)2015-12-15 15:00:56
大众考古(2015年10期)2015-06-26 08:00:08
东南法学(2015年2期)2015-06-05 12:21:36
