
基于深度学习的网络入侵检测研究综述
2022-12-10 12:51黄屿璁王鑫元丁辰龙
信息安全研究 2022年12期
黄屿璁 张 潮 吕 鑫,3 曾 涛 王鑫元 丁辰龙
1(河海大学计算机与信息学院 南京 211100)2(水利部信息中心 北京 100053)3(河海大学水利部水利大数据技术重点实验室 南京 211100)(huangyc89757@163.com)
互联网在政治、金融、文化、通信等领域起着至关重要的作用,是我国关键信息基础设施之一.随着智能终端设备的普及与互联网技术的发展,网络逐渐成为人们工作与日常生活不可缺失的一种工具.然而,在当前日益复杂的网络环境下,网络攻击事件出现的频率逐年增加.根据相关报告显示,仅2021年1月我国境内感染木马或僵尸网络恶意程序的终端就有119万余个,遭到篡改、植入后门、仿冒的网站数量在22 000个以上.国家信息安全漏洞共享平台(CNVD)收集整理的信息系统安全漏洞高达1 660个,其中570个为高危漏洞.我国网络安全形势日益严峻,如何采取有效措施来应对层出不穷的网络攻击是我国互联网发展过程中必须解决的问题.
入侵检测系统(intrusion detection system, IDS)最早于1980年提出,是一种网络安全防护技术,主要通过实时监视系统在网络传输过程中识别入侵者的异常行为与企图,并采取相应安全措施进行防护.根据信息来源不同可分为基于主机的与基于网络的入侵检测系统,后者为本文主要研究对象.
传统入侵检测系统通常将数学统计方法与机器学习相结合来检测异常数据.机器学习能够从大量数据集中自动获取有用信息,与入侵检测系统结合能大大提升检测效率,因此在机器学习快速发展时期大量研究将该技术用于入侵检测[1],如k近邻、支持向量机、朴素贝叶斯等有监督机器学习方法以及k-means、DBSCAN、主成分分析等无监督机器学习方法.这些方法有效降低了入侵检测系统的异常数据误报率,提升了检测精度.
随着网络数据量的急剧增加与攻击手段的不断升级,在应对零日漏洞、加密攻击、内部威胁等新型攻击行为时单靠机器学习技术并不能达到理想效果.机器学习中数据仅需通过1个隐藏层进行训练,因此机器学习模型也被称为浅层模型[2].浅层模型的搭建相对比较简单,在处理大量无标签数据时往往出现精度低甚至无法正常检测的情况.为了解决这些问题,研究人员开始将研究重心转移至深度学习,使用含有多个隐藏层的深度模型对入侵检测系统进行优化.
深度学习是机器学习领域的一个分支.与传统机器学习技术相比,深度学习的主要目标是学习样本数据的内在规律,在模型构建与特征提取方面效率更高,在处理大规模数据时有更高的准确率.近年来,随着深度学习技术的成熟与火热,越来越多的学者将深度学习应用在网络异常流量检测中,开发出各种与CNN,RNN,AE,DBN等深度学习模型相结合的网络入侵检测系统,在检测海量异常数据与新型网络攻击等方面给出了不俗的表现[3].
本文首先介绍网络入侵检测系统中常用的几种深度学习模型,然后对深度学习模型中使用的数据预处理技术、数据集及评价指标进行介绍,接着从实际应用的角度介绍深度学习模型在网络入侵检测系统中的具体应用,再讨论当前所面临的问题及未来发展,最后总结全文.
1 深度学习模型
本节对当前网络入侵检测系统中常用的几种深度学习模型进行详细阐述,表1列举了各深度学习模型的特点及常用领域.

表1 深度学习模型特点及常用领域
1.1 卷积神经网络
卷积神经网络(convolutional neural network, CNN)由多层感知机变化而来,是一种包含卷积计算的深度前馈神经网络.结构灵感来自人类大脑中的神经元,主要包括卷积层、池化层、全连接层等,其中卷积层与池化层为核心模块.卷积层的作用是通过卷积操作提取输入数据中更高层次的特征,池化层的作用则是对卷积层输出的图数据进行特征选择与信息过滤,从而减少数据处理量.不同结构的CNN通过卷积层与池化层的差异来区分.CNN结构如图1所示:

图1 CNN结构示例
CNN具有参数共享、稀疏交互与等效表示等优点.与传统神经网络不同的是,CNN在网络中使用的是局部连接,且相邻神经元之间进行权重共享.这一特点使得CNN的结构比全连接神经网络简单很多,整个计算过程所产生的参数也大大减少,从而大幅降低计算复杂度与训练时间.此外, CNN有着很强的泛用性,能够用于多种分类任务,特别在自然语言处理[4]、模式识别、目标检测等方面具有良好的效果.利用CNN建立模式分类器能够对灰度图像进行识别与分类.在入侵检测过程中需要先将流量数据转换为灰度图的形式,再使用CNN提取图片数据的空间特征.
1.2 循环神经网络
循环神经网络(recurrent neural network, RNN)是一种递归式的神经网络,其输入值为序列数据.RNN在每条序列的演进方向上进行递归操作,且所有节点均以链式结构进行连接,如图2所示.与传统神经网络相比,RNN在隐藏层的神经元中添加了自连接的权重值,从而将每次训练输出值的状态信息发送至下一次训练,实现了保存前一序列信息的功能,有效解决了序列数据预测等一般神经网络无法处理的问题[5].
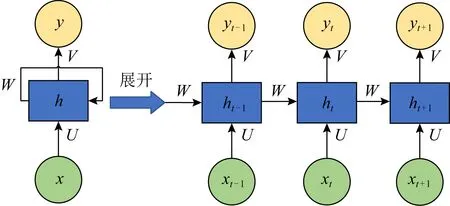
图2 RNN结构示例
由于RNN具有在隐藏层的节点间进行信息传递的特性,因此在自然语言处理、语音处理、上下文感知等需要处理序列信息的领域有着广泛的应用.网络流量数据中也包含许多与时间序列相关的特征,因此也有大量研究将RNN与入侵检测系统相结合.
然而,RNN在解决一些长时间依赖问题时往往会遇到梯度消失、梯度爆炸等情况,为避免这些情况,有学者提出了长短期记忆网络(long short-term memory network, LSTM).LSTM是一种基于RNN的人工神经网络,具有更深层次的隐藏神经元结构,并通过设计“门”结构实现信息的保留和选择功能,且能够在任意时间间隔内对先前的输入进行保留.因此,LSTM对时间序列中间隔和延迟长的事件有较强的处理能力.LSTM主要用于文本生成、机器翻译、语音识别等领域.
1.3 自动编码器
自动编码器(auto-encoder, AE)是一类用于学习与重构输入数据的无监督神经网络模型,由编码器与解码器组成,包含输入层、编码层与解码层.编码器以非线性方式将输入数据映射到隐藏空间,学习输入数据的隐含特征;解码器将编码数据映射回原始输入空间,用学习到的新特征重构出原始输入数据.AE通过编码与解码过程,使得高维度的输入层神经元能够被较低维度的神经元所替代,从而达到特征降维与提取的目的.
AE具有高效的数据编码与解码能力,通常用于数据降维、压缩、融合等工作,在生物信息学与网络安全领域应用较多.但随着隐藏层的增加,AE会出现梯度消失问题.后续提出的稀疏自编码器(sparse auto-encoder, SAE),变分自编码器(variational auto-encoder, VAE)[6]等高级AE模型对这一问题进行了改善.此外,AE没有分类功能,通常需要与其他分类模型(如CNN)结合使用.
在当今网络环境中,每日产生的数据量飞速增长,对大规模流量数据的处理成为网络入侵检测系统面临的挑战之一.在基于深度学习的入侵检测领域中,由于AE能够从输入数据中提取出紧凑且区分度较高的低维表示,因此AE被广泛用于入侵检测数据预处理过程中的降维任务.
1.4 受限玻尔兹曼机
受限玻尔兹曼机(restricted Boltzmann machine, RBM)是一类具有2层结构(分别为可视层与隐藏层)的随机生成神经网络模型.可视层和隐藏层采用对称的全连接,层内的神经元之间没有连接.RBM能够在无监督条件下从原始数据中学习到特征更深层次、更复杂的信息,主要用于特征提取与去噪.深度玻尔兹曼机(deep Boltzmann machine, DBM)是一种由多个RBM串联堆叠而成的深度神经网络,与单个RBM相比能够从大量无标签数据中学习出高阶特征,且鲁棒性也得到增强.
RBM具有很强的无监督学习能力,主要应用领域为数据编码、新闻聚类、图像分割等[7],在入侵检测中通常出现在深度信念网络中.
1.5 深度信念网络
深度信念网络(deep belief network, DBN)也是一种由多层RBM组成的深度神经网络,包含1个可见层与1个隐藏层,可以从复杂的高维数据中学习特征.与DBM不同的是,DBN是一种有向图结构,在通过叠加RBM进行逐层预训练时,某层的分布只由其上一层决定.DBM是一种无向图结构,某层的分布由其上下2层共同决定.2种模型的结构对比如图3所示:
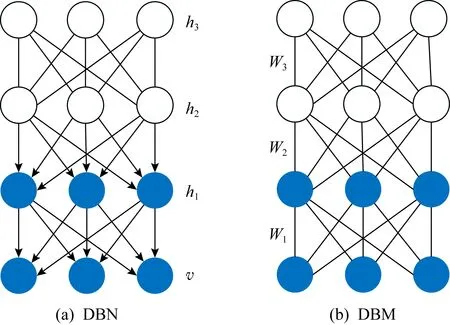
图3 DBN与DBM结构对比
DBN使用逐层贪婪学习算法优化网络各层的连接权重,具有快速学习的优点,并利用RBM对深层网络作逐层无监督训练,能有效避免陷入局部最优[8].此外,DBN既可以作为一个分类模型用于监督学习,又可以作为一个生成模型用于无监督学习,灵活的特点使其具有很强的可扩展性,能与各种深度模型及算法进行结合.DBN主要用在语音识别、自然语言处理、网络安全等领域.
1.6 生成对抗网络
与上述几种深度学习模型不同,生成对抗网络(generative adversarial network, GAN)作为一种混合式深度学习模型,兼顾了数据的生成与判别功能.GAN借鉴了博弈论中的二人零和博弈思想,结构上包含生成器与判别器2个神经网络.生成器不断生成接近真实结果的样本用以欺骗判别器,判别器判断样本是真实样本还是由生成器伪造的假样本.二者在对抗过程中不断优化,最终达到均衡生成最优结果.GAN的模型结构如图4所示:
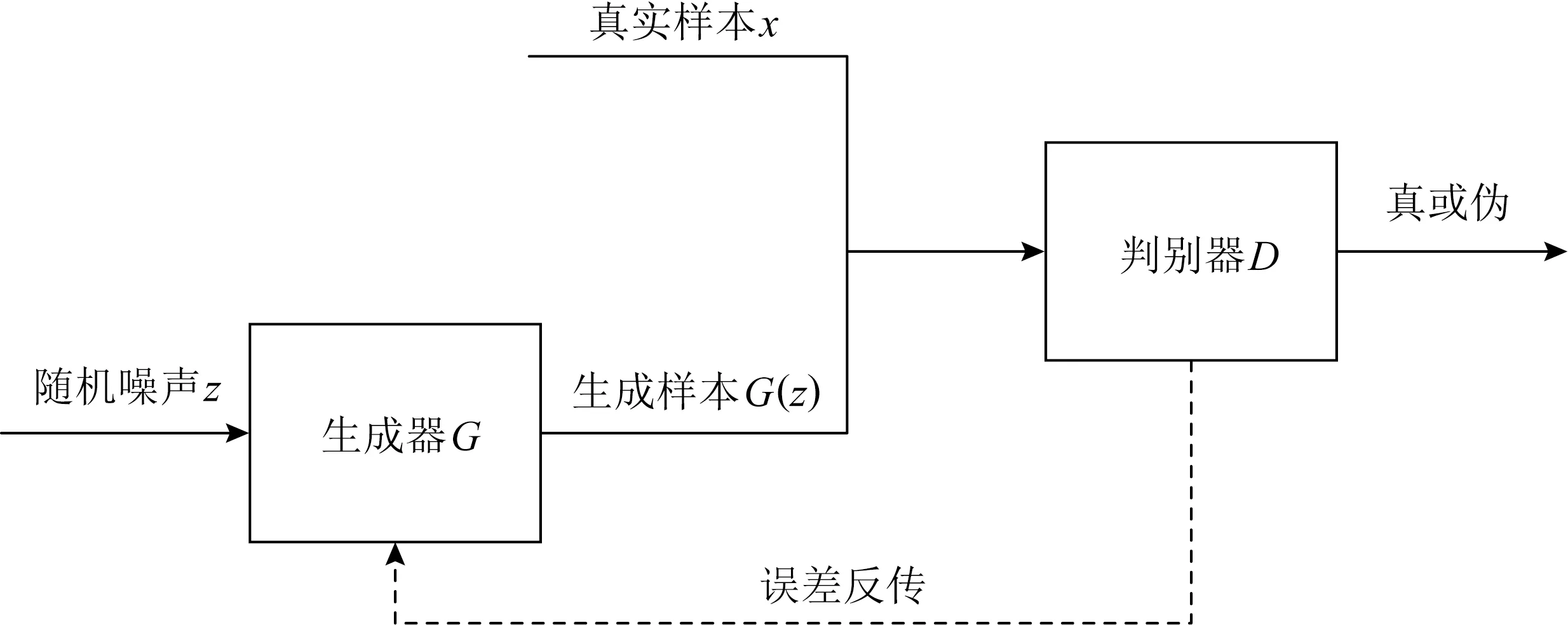
图4 GAN结构示例
GAN相较于其他深度学习生成模型结构要简单很多,且具有强大的预测能力,可对数据进行直接采样和推断,不需要对数据预设分布.此外,GAN通过生成器与判别器的对抗训练方法以及误差反传算法等机制大大提升训练效率.然而,由于GAN未对数据进行预设分布,很容易产生训练过程不稳定、模型崩溃等问题.后续提出的条件对抗生成网络(conditional GAN, CGAN),深度卷积对抗生成网络(deep convolutional GAN, DCGAN)等基于GAN的模型有效改善了这些问题[9].
GAN主要应用领域为图像处理,具体任务包括超分辨率图像重建、图像生成、图像翻译等.由于GAN能解决数据集中带标签样本数量较少的问题,不少学者将此模型用在入侵检测任务中.
2 数据预处理技术
用于入侵检测的流量数据通常包含基本特征、内容特征和流量特征,不同特征的数据类型不一定相同,数量级也可能相差较大.因此数据预处理是网络入侵检测系统使用深度学习技术对数据进行检测之前必不可少的一项工作.本节从数据收集、特征转化、数据降维3个角度介绍网络入侵检测系统中常用的数据预处理技术.
2.1 数据收集
网络入侵检测系统中的数据通常以网络流量形式进行传输.在对数据进行处理前需要使用有效手段从网络流量包与使用TCP/IP通信堆栈的应用程序中收集网络流量数据,收集方式包括完整数据包捕获(full packet CAPture, PCAP)与NetFlow协议2种[10]:
1) PCAP.PCAP允许收集完整的网络流量数据,包括数据包大小、协议类型、源IP与目标IP、源端口号与目标端口号等信息.其中一些信息可能涉及个人信息、浏览记录、消息会话等隐私而被删除或匿名化处理,从而对系统检测造成一定影响.PCAP包括数据捕获和预处理2个阶段,捕获阶段通常使用winPCAP,libPCAP,SNORT等应用程序,预处理阶段则使用Wireshark,tcpdump,scapy等程序.
2) NetFlow协议.Netflow协议是Cisco公司开发的一套协议,主要用来对流量数据进行采样与分析.Netflow协议主要收集数据相关的摘要信息或某些预定义属性,包括源地址、目的地址、源端口、目的端口、数据流大小、数据流经过的接口等.与PCAP相比,Netflow协议更加节省内存,适用于大规模数据的收集,但由于收集到的内容简略很多,无法像PCAP那样获取用户搜索关键字之类的详细信息.
2.2 特征转化
网络流量数据通常由多个数值型与非数值型特征组成,在训练之前对不同类型的特征数据进行转化可有效提高模型训练的效率与精度.针对数值型数据采用的是归一化或标准化,针对非数值型数据则采用Ont-Hot编码.
2.2.1 归一化与标准化
针对数值型特征通过线性变换的方式消除由于特征量纲不同所带来的影响,可在一定程度上提高深度学习模型的精度,也能在梯度下降过程中提高模型收敛的速度.主要有Min-Max归一化与Z-score标准化2种方法.
Min-Max归一化基于数据集合中的最大值与最小值,通过线性变换把原始数据映射到区间[0,1]内,计算公式如下:
(1)
其中,x是原始数据,y是变换后的数据,xmin是所有数据中的最小值,xmax是所有数据中的最大值.
Z-score标准化是使用所有数据的均值与标准差对原始数据进行转换,计算公式如下:
(2)
其中,x是原始数据,y是变换后的数据,μ为所有数据的均值,σ为所有数据的标准差.
2.2.2 One-Hot编码
对于非数值型特征,如会话状态、IP地址、设备名称等,通常采用One-Hot编码的方式进行处理[11].One-Hot编码也称为“1位有效编码”,原理是通过长度为N的状态寄存器对N个状态进行编码,每个状态都由1个数字表示在对应的寄存器位上,通常使用0或1来表示.在任意时刻仅有1位有效,即寄存器中该位的值为1,其余为0.
以流量数据中的“会话状态”为例.假设会话状态共有3种,One-Hot编码首先将3种状态映射为整数值1,2,3,再用3位的二进制向量来存储每种状态,因此3种状态可分别表示为001,010,100.One-Hot编码解决了模型处理非数值型数据的问题,在一定程度上也起到了扩充特征的作用.
2.3 数据降维
入侵检测数据集中存在大量冗余、噪声数据以及不相关的数据, 因此在使用深度学习模型进行检测之前需要对数据进行降维,从而减小计算开销, 提升模型分类器的检测性能与效率[12].数据降维方法主要分为特征选择与特征提取[13].
1) 特征选择.特征选择是指在指定的特征集合中挑选出适用于模型训练的特征构成特征子集.在入侵检测领域,特征选择通常包括3种方案:过滤法、包裹法与嵌入法.过滤法是按照发散性或相关性对各个特征进行评分,并与设定的阈值进行比较以完成特征选择,常用的过滤法有方差法、互信息法等;包裹法就是选定某种算法,根据算法效果来选择特征集合,常用的包裹法有遗传算法等;嵌入法是利用正则化的思想,将部分特征属性的权重调整到0,常用的嵌入法有LASSO回归等.
2) 特征提取.与直接从所有特征中选出子集不同,特征提取主要通过属性间的关系对不同属性进行组合得到新的属性.入侵检测领域常用的特征提取方法为主成分分析(principal component analysis, PCA)[14].PCA使用一种线性投影的方式,将维度较高的数据映射到低维空间,在降低数据维度的同时尽可能地保留较多原始数据的特征.此外还有线性鉴别分析(LDA)方法与独立成分分析(ICA)方法等也可用来对流量数据进行特征提取.
3 数据集与评价指标
入侵检测系统需要通过网络流量数据集与特定评价指标对系统性能进行评估.本节对基于深度学习的网络入侵检测系统中常用的数据集与评价指标进行介绍.
3.1 数据集
随着入侵检测技术的不断发展,越来越多的相关数据集出现供研究人员使用,常用的主要有KDD99,NSL-KDD,CIC-IDS-2017,UNSW-NB15等,大多数基于深度学习的网络入侵检测系统使用上述数据集进行测试.
KDD99主要包括4类网络攻击,分别为拒绝服务(DoS)攻击、远程到本地(R2L)攻击、端口扫描(Probe)攻击和用户提权(U2R)攻击.KDD99是最早用于入侵检测模型训练与测试的公共数据集之一,也是目前入侵检测领域使用最广泛的数据集之一.然而该数据集存在许多缺陷,如部分记录重复等,因此KDD99不能完全反映出当前网络攻击的特征.
NSL-KDD包含39种攻击类型.该数据集在KDD99的基础上进行研发,通过删除KDD99中重复出现的记录与部分较难分类的数据来解决KDD99存在的问题.虽然NSL-KDD有很多方面的改进,可帮助研究人员更好地测试入侵检测模型的性能,但该数据集仍然具有一定的局限性,无法反映当前真实网络环境中的流量数据.
为了解决KDD99与NSL-KDD不能反映真实网络流量数据和攻击的问题,有学者设计了UNSW-NB15.该数据集由基于数据包格式的网络流量组成,包括超过250万条记录与49个特征,涉及模糊攻击、后门攻击、拒绝服务攻击、蠕虫攻击等9种攻击类型,适合用于训练和测试.
CIC-IDS-2017包含81个网络流特征与7种网络攻击,分别为DoS攻击、SSH暴力攻击、僵尸网络攻击、DDoS攻击、Web攻击、心血漏洞及渗透攻击.该数据集中的数据采集自模拟正常流量的小型网络环境,与真实网络数据较为接近.
3.2 评价指标
基于深度学习的网络入侵检测系统主要采用以下指标评价系统性能:
1)TPR(真阳性率).被正确判断为恶意样本的数据与所有实际恶意样本数据的比率,值越高表明系统性能越好.
2)FPR(假阳性率).被错误判断为恶意样本的数据与所有实际良性样本数据的比率,值越高表明系统性能越差.
3)Recall(召回率).被正确预测为良性样本的数据与所有良性样本数据的比率,值越高表明系统性能越好.
4)Accuracy(准确率).被正确预测为恶意样本的数据与所有样本数据的比率, 值越高表明系统性能越好.
5)Precision(精确率).被正确预测为恶意样本的数据与所有预测为恶意样本数据的比率, 值越高表明系统性能越好.
6)F-measure(F1值).又称F1分数,Precision与Recall的加权调和平均,值越高表明系统性能越好.
4 入侵检测应用
本节从恶意软件识别、网络流量检测、攻击行为分类等角度,介绍不同深度学习模型在入侵检测系统中的实际应用情况,并分析各模型所达到的实验效果与存在的问题.
4.1 恶意软件识别
恶意软件是信息安全中常见的攻击方式.随着互联网技术的不断发展,越来越多的恶意软件被制作出来,并使用加密、伪装、匿名等方式混在正常数据中,通过网络传输的形式侵入用户主机,若不采取有效措施进行识别,很难在软件造成危害前将其找出.深度学习为恶意软件识别提供了极大便利,特别是面对一些新出现的恶意软件时依然能保持较高的识别率.
Shibahara等人[15]提出一种根据软件的网络行为判断恶意软件的方法.该方法的判断关键集中在恶意软件通信的2个特征上:通信目的的变化和常见的潜在功能.该方法应用递归张量神经网络,通过使用张量计算输入特征的高阶成分来提高RNN的分类能力.在对29 562个恶意软件样本的评估中,该方法精确度为97.6%,召回率为96.2%,F1分数为96.9%.然而当恶意软件在分析过程中进入长时间的休眠状态时,该方法将不再适用,且该方法还受到样本标记的限制,存在一定的局限性.
David等人[16]使用在未标记数据上训练的DBN生成恶意软件特征码,然后使用DBN和去噪自动编码器(DAE)对恶意软件进行识别与分类.使用传统方法生成恶意软件特征码是利用恶意软件的特定内容,很容易因为恶意软件代码的修改而检测失败.文献[16]通过沙箱获取日志,使用n-gram模型对日志进行处理,获取仅出现在恶意软件中的最常见的2万个一元语言模型(unigram),并创建1个2万维特征向量来识别是否出现了给定的一元语言模型.然后,利用这些识别后的一元语言模型对1个带有DAE的8层DBN进行预训练.最终的恶意软件特征码是1个由30个数字组成的向量.实验表明所训练的模型准确率为98.6%.
基于API调用序列可以构建基于语义感知和机器学习的恶意软件分类器,用于恶意软件检测或分类.然而目前基于API调用序列的相关工作涉及太多特征工程,无法提供可解释性.针对这一问题,Wang等人[17]使用RNN与AE将API调用序列转换为低维特征向量,通过分类层确定恶意软件家族类型,实现了99.1%的分类准确率.该方法解决了传统分类模型无法对新出现的恶意软件进行分类以及标签解释性差的问题,但只使用了API调用序列进行学习,没有将一些附加信息,如API调用的参数、可执行文件结构等,与模型进行结合.此外该方法还缺乏监督数据,在解码器的训练上存在一定的局限性.类似地,Yousefi-Azar等人[18]使用API调用序列构建了一个基于AE的多任务恶意软件分类模型,并测试了各种分类工具,发现最好的是SVM分类器,达到96.3%的精确率.该模型与其他基于API调用序列方法中的模型相比使用了特殊的训练方式与拓扑结构,不需要通过预处理来选择特征,且能通过更少的特征数量达到相同的检测精度,使得模型的计算效率显著提高.此外该模型还可用于网络异常流量的检测,能使用较少的特征数量达到较好的检测效果.
域生成算法(domain generation algorithm, DGA)是一种常见的恶意软件工具,可以为僵尸网络生成大量与C&C(command and control)服务器进行通信的域名,这类域名可以逃避域名黑名单的检测.DGA常用于垃圾邮件、数据窃取、分布式拒绝服务(DDoS)等网络攻击.Anderson等人[19]使用GAN生成当前DGA软件分类器难以识别的域名,并利用生成器创建合成数据.文献[19]对训练模型进行改进,使用LSTM层作为自动编码器,重新调整其用途,将编码器作为鉴别器(将语言转换为数字格式),解码器作为生成器(接收数据并输出域名);正则化层被添加为生成器的第1层,逻辑回归层被添加到鉴别器的最后一层.实验结果显示,该检测模型的TPR从68%提高到70%.相较于文献中用来对比的其他方法,文献[19]提出的方法能有效检测DGA的变体,且检测更加简单与灵活,但在GAN模型的训练策略上还存在改进空间,且FPR值容易受到数据实际分布的影响.
Woodbridge等人[20]开发了一种利用LSTM网络识别DGA所生成的恶意域名的方法.DGA检测方面的很多工作都无法用于实时检测和预防,其中大部分还使用上下文信息,甚至通过人工创建特征,耗费了大量的时间与成本.Woodbridge等人仅使用RNN中的域名和GRU(gate recurrent unit)节点对域名进行分类,将域名中的每个字符视为特征,并将其依次输入嵌入层、GRU层、分类层.该模型适用性极强,可部署在几乎任何环境中,检测率高达90%,FPR仅为0.1%,是文献中用来对比的次优方法的1/20.但与文献中列举的其他方法一样,该方法对类不平衡的情况非常敏感,使得其在检测一些冷门域名时存在限制.与Woodbridge等人提出的方法类似,Zeng等人[21]试图仅使用域名来检测和识别DGA生成的域名,通过基于ImageNet数据的多个预先训练的CNN对DGA与非DGA进行识别与分类.该方法在嵌入层之后对数据进行重塑,并将图像分类器的输出视为要输入决策树分类器的特征.与文献中列举的其他方法相比能处理大规模数据,且计算速度更快,实现了99.86%的TPR和1.13%的FPR.Mac等人[22]采用了和文献[21]类似的方法,但使用了结合递归SVM的LSTM(LSTM-SVM)和双向LSTM,在相关数据集上分别实现了0.996 9和0.996 4的AUC,均优于原始LSTM.除了LSTM-SVM和双向LSTM,Mac等人还将CNN层置于LSTM层之前,并在类似数据集上实现了0.995 9的AUC.但这些改进的LSTM计算成本要高于原始LSTM,计算时间更慢,双向LSTM甚至达到原始模型的3倍.
4.2 网络流量检测
网络流量检测是网络入侵检测系统的关键应用,也是网络入侵检测领域的研究重点.网络流量检测重点在于对大量通过网络传输到主机的流量数据进行实时检测,及时发现网络攻击行为并采取相应措施进行防御.
Nasr等人[23]提出一种基于CNN的入侵检测系统DeepCorr.与传统入侵检测系统相比,该系统将通用的统计相关算法转换成深度学习算法,能捕捉到噪声动态变化的复杂性质,实现更高的检测准确率.DeepCorr由2层卷积层与3层全连接神经网络组成.实验表明,DeepCorr在学习率为0.000 1的条件下可实现0.8的TPR,相较于文献中用来对比的其他系统有很大的改进.此外,DeepCorr对于长度较短的流量数据有很强的检测能力,实验中仅使用了900个数据包就达到96%的准确率,远远高于文献中用来对比的其他系统,但计算复杂度相应也有所增高,检测所需时间是其他对比系统的2倍以上.Jiang等人[24]提出一种基于特征级深度神经网络的在线检测方法,用来检测恶意URL与DNS.该方法首先将URL与DNS字符串映射为向量形式,然后通过CNN提取出恶意特征并对分类模型进行训练,是一种针对短文本检测的通用检测方法,适用于多种场合,具有很强的可扩展性.此外,该方法可对模型定期进行更新,用以检测新出现的恶意URL或DNS.目前该方法仅在虚拟环境中进行测试,未来还需部署到现实场景中进一步评估与微调.Khan等人[25]将CNN与softmax算法相结合,通过改变CNN中卷积层内核的数量增强模型学习特征的能力,有效提高了检测准确率.该方法选取KDD99的10%的数据进行实验,改进后的CNN的准确率高达99.23%.然而该方法的实验对比对象只有原始的SVM与DBN模型,没有与其他改进后的模型进行对比,并且只在准确率方面比另外2种模型高1%左右,其他方面的指标没有进行对照.Andresini等人[26]基于CNN提出一种入侵检测模型,解决了传统机器学习方法不能有效检测不可预见攻击的问题.该模型首先使用自编码器提取数据特征,然后对提取特征执行最近邻搜索与聚类算法导出适用于CNN的灰度图像,再利用该图像对CNN进行训练.文献[26]提出的数据映射方法能很好地帮助构建图像数据,从而发现相邻流量数据中产生的潜在数据模式.实验证明,该模型在KDD99,USW-NB15和CICIDS2017等上均有较高的准确率.未来可探索将RGB映射与相邻搜索结合以增强网络流量的成像表示,并研究在数据集不平衡的情况下聚类算法的参数设置.Shibahara等人[27]提出一种从代理日志中检测恶意URL的系统,并提出一种改进的CNN——事件去噪卷积神经网络(EDCNN).EDCNN对原始的CNN结构进行了扩展,主要功能是减少良性URL所受到的负面影响.文献[27]将2种现有方法与EDCNN进行了比较,并使用2种类型的特征提高EDCNN的检测性能.实验结果显示,在特定情况下EDCNN相较CNN降低了47%的错误警报,从而降低了恶意软件感染的检测成本(从27.6%降低至14.8%).但是EDCNN在进行分类时没有考虑URL对应的内容,如果网站中的恶意内容被人删除,EDCNN依然会将该URL识别为恶意网站,从而必须通过手动检查的方式才能避免这类误报情况.
Suda等人[28]针对车载网络提出一种入侵检测方法,该方法利用RNN可对数据包的时间序列特征进行提取.该方法能够检测各种类型的攻击,如ID修改攻击、数据字段修改攻击以及洪水攻击等.此外,与传统基于阈值的方法相比,该方法可在不需要阈值的情况下检测各种网络攻击,且能获得更高的检测精度.未来可考虑更多不同的攻击模式和硬件配置进行性能评估,并可对RNN模型本身结构进行优化.燕昺昊等人[29]为了解决传统入侵检测模型只检测网络入侵行为的静态特征、无法有效检测低频攻击样本的问题,提出一种深度循环神经网络(DRNN)和区域自适应合成过采样算法(RA-SMOTE)相结合的入侵检测模型DRRS.文献[29]首先利用RA-SMOTE算法优化了数据集中数据分布不平衡的状况,再利用DRNN完成对新样本集的学习与检测,除了提升低频攻击的检测率外,还依靠RNN的结构特性充分挖掘并利用了样本之间的时序相关性,提升了模型的检测性能与数据刻画能力.在NSL-KDD上,DRRS的各项指标均优于已有的入侵检测模型.Hou等人[30]构建了一种基于分层LSTM的入侵检测系统HLSTM,能够跨越多个时间层次在复杂网络流量序列上进行学习.在KDDTest+与KDDTest-21上,HLSTM的检测准确率分别为83.85%与69.73%,均高于用来比对的其他方法.此外,HLSTM对于低频率的网络攻击具有较高的分类精度与较低的误报率.然而HLSTM在检测R2L与U2R攻击时表现不是很好,使用的数据集中这2类攻击的样本数量也较少.针对物联网中的网络攻击,Roy等人[31]提出一种使用双向长短时记忆递归神经网络(BLSTM RNN)的入侵检测方法,主要研究了该方法在物联网正常模式与攻击模式二分类问题中的性能.该方法能够在训练阶段从数据集中学习详细的特征,从而达到较高的攻击流量检测准确率.实验使用UNSW-NB15的简化版本进行训练,检测准确率超过95%,精确率甚至达到100%,并且召回率、F1分数与FAR等评价指标均表现良好.该方法在检测参数方面还存在改进空间,需要更多的大型数据集来帮助进行模型参数调整,以平衡检测精度与参数之间的关系.Alkadi等人[32]将入侵检测系统与区块链技术相结合,提出一种深度区块链框架DBF,旨在提供物联网网络中基于安全的分布式入侵检测和基于隐私的智能合约区块链,在保护数据隐私的同时对恶意攻击进行识别.该框架也使用双向LSTM方法对网络数据进行检测,并通过UNSW-NB15与BoT-IoT对模型性能进行评估.结果表明,使用双向LSTM的DBF在准确性和安全性上优于文献中用来对比的其他框架,并且在该框架中的数据交换变得简单、透明,能显著降低日常开支.然而深度学习与区块链技术的结合可能会受到通信复杂度、流量开销等因素的限制,一定程度上导致传输过程中存在丢包问题,对结果精度造成影响.未来还需要在更多数据集上进行测试,以评估框架的可扩展性与实用性.Mahdavisharif等人[33]采用大数据感知的深度学习方法设计高效的入侵检测系统,以检测大规模的网络流量数据.该系统使用一种特定的LSTM结构,能够检测传入流量数据包之间的复杂关系与长期依赖关系,从而减少误报数量,提高入侵检测系统的检测准确性.此外,该系统还使用了大数据技术中的并行与分布式计算方法,有效提高了系统运行速度.实验在NSL-KDD上进行测试,结果表明该系统在检测率、准确率和训练时间等评价指标上均优于实验中用来对比的其他方法.为了进一步降低计算复杂度,Mahdavisharif等人打算使用GRU算法代替LSTM,并收集真实的网络流量数据进行训练,使得实验结果更加准确与可靠.
在深度学习模型中,AE非常适合从高维数据中提取特征,因此在入侵检测系统中有着广泛的应用.Farahnakian等人[34]将4个AE进行连接,将当前层AE的输出作为下一层AE的输入,并在输入前对当前层的AE进行训练,以此建立了一个深度AE的入侵检测模型.为了避免过度拟合和局部最优的情况,文献[34]使用贪婪的无监督分层方式对模型进行训练.实验结果表明,该模型在10%的KDD99上实现了94.71%的检测准确率.未来可在该方法的基础上进一步探讨如何对AE添加稀疏约束,以及如何设计稀疏AE来进一步提高入侵检测的有效性.为了解决传统入侵检测技术中存在的缺乏标记数据集、开销大及准确率低等问题,Li等人[35]提出一种基于随机森林算法的AE入侵检测系统.该系统通过特征选择和特征分组构造训练集,使用浅层AE神经网络进行攻击检测,降低了计算复杂度,并且借助AE特性解决了传统方法中存在的样本不均衡问题,有效提高了检测精度.实验结果表明,该系统能在较短时间内准确检测出大部分攻击.随着网络攻击的隐蔽性越来越强,恶意流量加密为入侵检测带来不少困难.该系统存在的问题是提取的特征数量不足,在面对加密后的恶意攻击时无法保证相同精度.Zavrak等人[36]提出一种使用变分编码器(VAE)的入侵检测模型,用来处理小规模的流量数据与识别未知攻击.该模型采用半监督的学习策略,对比模型有原始的AE以及OCSVM.实验证明该模型检测率在大多数情况下比AE和OCSVM高,但误报率较高,需要有监督学习方法的支撑.为了提高检测率,可以考虑在特定时间间隔对流量数据进行收集,从而更好地模拟出某些攻击特征.Yu等人[37]开发了一种网络入侵检测方法,从大量未标记的原始网络流量数据中自动有效地学习有用特征.该方法使用空洞卷积自动编码器(DCAE)识别正常和恶意流量,首先使用数据预处理模块将原始网络流量数据转换为二维数字向量,然后使用未标记的数据训练DCAE.在分类任务实验中,文献[37]所提出的方法在二分类任务中表现最好,准确率高达99.59%,在六分类任务中也高于文献中列举的其他基于深度学习的方法.实验还表明,添加多个隐藏层并不能显著提高性能,在1个卷积层、1个全连接层(带有ReLU)以及1个分类层的情况下,模型性能最好,这可能是因为第1个卷积层的隐藏单元数足以学习全部有用特征.模型的局限性在于训练过程需要较长时间,这可通过深度学习领域广泛使用的GPU并行化技术来解决.
Gao等人[38]首次将DBN用于入侵检测,提出一种基于DBN的入侵检测模型.为了证明DBN在网络攻击检测中的适用性,实验选用KDD99,对比模型有基于机器学习的人工神经网络(ANN)与SVM.实验表明,DBN在不同隐藏层的情况下检测率均高于SVM与ANN,且具有4个隐藏层的DBN表现最好,准确率为93.49%,TPR为92.33%.由于文章发表时间较早,实验仅仅对比了基于机器学习的经典模型.Alrawashdeh等人[39]也对1个四隐藏层DBN进行了类似实验,并使用softmax逻辑回归模型对深度网络进行微调,在10%的KDD99上实现了97.9%的准确率,无论是检测速度还是检测精度都优于文献中用来对比的几种基于深度学习的方法.通过对训练过程进行改进,该模型的FN值降到2.47%.然而该模型的训练与测试时间较长,计算过程相对复杂,且实验用的数据集较小,所包含的攻击类别有限.Chawla[40]专门针对物联网中存在的安全问题提出一种入侵检测系统.该系统使用含有3个隐藏层的DBN作为入侵检测模型,降低了物联网网络的异质性与动态性所导致的安全风险,大大减少了所需的计算资源.该系统在1次实验中收集了所有需要用到的数据,包含来自IPv6报头的信息以及有关数据包的元数据,其中恶意数据由12种不同的攻击类型表示.实验结果表明,该系统检测模型的TPR为95.4%,准确率为95.03%.
深度学习分类模型的训练需要大量标记数据,收集这些数据通常需要耗费大量时间与金钱.针对该问题,Singla等人[41]基于GAN提出一种使用对抗域自适应方法进行训练的入侵检测模型.该模型通过将域自适应学习和GAN相结合,降低了模型训练所需的数据量,使得模型可以通过少量样本数据训练达到较高精度,同时减少了训练时间.无论原数据集与目标数据集特征相似与否,使用文献[41]所提出的方法训练的模型均优于文献中列举的结合其他方法的模型.通过实验可以看出,在目标数据集与原数据集特征相似的情况下,该方法的准确率分别比文献中用来对比的2种方法高7.66%和6.73%,在特征不相似的情况下则分别高17.9%和5.78%.未来还需要对该方法在多类别分类及隐私保护等问题上的适用性作进一步研究.Liu等人[42]针对入侵检测数据集的不平衡性和高维性特点提出了一种基于GAN和特征选择的过采样技术,用来对数据集进行处理:一方面采用基于梯度惩罚的Wasserstein-GAN对高维攻击分别进行建模,以生成额外的样本数据;另一方面使用方差分析法选择代表整个数据集的特征子集,从而得到低维且平衡的数据集,放入模型进行训练.实验分别在NSL-KDD,UNSW-NB15,CICIDS-2017上进行,验证了该技术能够使入侵检测模型的检测性能显著提升,但文献[42]没有对不同特征所分配的权重进行研究,没有反映出每个特征在分类中的重要性.
4.3 攻击行为分类
在网络流量检测的基础上,对各种攻击行为进行分类能有效提升入侵检测系统的检测精度与效率.常见的网络攻击包括拒绝服务(DoS)、分布式拒绝服务(DDoS)、用户提权(U2R)、远程用户(R2L)、注入(injection)及探针(probe)攻击等[43].使用深度学习模型能够在对现有网络攻击精准分类的同时发现新的攻击类型,与其他攻击行为进行细致区分.
机器学习方法在处理海量、不具备独立同分布的流量数据时开销大、精度低.为了解决这些问题,张小莉等人[44]将PCA算法与改进的深度卷积神经网络分类模型(LCNN)相结合,提出一种流量分类模型.其中,PCA算法用来对数据进行降维分析,发现关键特征;LCNN则采用自主特征学习方式提升分类精度.实验使用3种带标签的数据集对模型进行测试,检测精度最高可达96.58%,比实验中列举的其他模型提升了5%~8%.此外,该模型还具有很强的泛化能力,可与其他算法结合进一步提升模型性能.该模型存在的主要问题是特征属性较少,在处理一些复杂数据时不太适用.Yin等人[45]将RNN与入侵检测系统相结合,提出RNN-IDS模型,并通过多个数据集进行实验.RNN-IDS模型不仅具有很强的入侵检测建模能力,而且在多类别分类中也具有较高的准确性,特别是在NSL-KDD的多分类任务中具有较低的FPR与较高的检测率.该模型与传统机器学习模型相比能实现更高的精度,但训练时间更长,且由于RNN存在梯度爆炸与梯度消失的问题,可以考虑使用GPU加速来减少训练时间.为了充分提取用户行为的特征信息,Xiao等人[46]提出一种基于AE与CNN的网络入侵检测模型.该模型通过AE对处理后的数据集进行降维,将降维后的数据转换为灰度图像输入CNN,通过CNN提取和分析数据特征进行分类.实验结果表明,模型的准确率、检测率与FAR分别可达94.0%,93.0%及0.5%,比大部分机器学习模型以及DNN,RNN等基础深度学习模型性能更好.但该模型在处理少数攻击类别(如U2L,R2L)时检测率较低,且特征学习较为困难,未来使用GAN生成新的样本数据能有效帮助识别更多攻击类别的特征.Kannari等人[47]针对网络流量数据维度高和数据不均衡的问题,提出一种基于swish-PReLU激活函数的稀疏AE,对NSL-KDD,CIC-IDS2017和AWID中的正常流量和攻击流量进行分类,其中在NSL-KDD中的准确率可达99.95%,检测率可达99.82%.在与文献[47]中列举的几个改进模型的对比实验中,该模型在分类精度与检测率等方面也有不错的表现.然而该模型并没有解决AE中过度拟合与数据稀疏的问题.
Aldwairi等人[48]考虑到建立一种能够学习和适应新型网络攻击的入侵检测系统的重要性,尝试使用RBM来区分正常和异常网络流量数据.实验使用训练算法CD与PCD对RBM性能进行评估,准确率分别为88.6%与89.0%,TPR分别为88.4%与84.2%.实验结果表明,RBM经过训练后能够正确区分正常和异常网络流量数据,并且可以识别新的攻击行为,但计算复杂度较高,准确率还有待提高,且文中只探讨了双层RBM,没有进行更深入的研究.Elsaeidy等人[49]对RBM的改进模型DRBM进行研究,提出一种基于DRBM的智能城市入侵检测框架.该框架使用经过训练的DRBM模型从网络流量中提取高层特征,结合前馈神经网络、随机森林等模型利用提取到的特征检测不同类型的DDoS攻击.实验结果表明,该框架中的DRBM具有高精度的跟踪检测能力,性能优于传统前馈神经网络、随机森林、SVM等模型.DRBM存在的问题是检测结果会受到RBM层数以及集群数量的影响,当RBM层数与集群数量增加时,模型的攻击检测性能会降低.Thamilarasu等人[50]开发了一种适合物联网环境的智能入侵检测系统,提出用DBN构建用于网络攻击检测与分类的前馈深度神经网络,并对虫洞攻击、黑洞攻击、DDoS攻击等攻击类型进行测试,其中DDoS攻击的检测准确率高达96%、召回率高达98.7%.此外,所有攻击场景的F1分数都较高,表明系统具有较好的整体检测性能.但是该实验的对比方法只有1个,不能很好地体现该方法的优势,并且也没有针对物联网中一些特有的攻击类型进行检测.
Lin等人[51]认为现有入侵检测系统的鲁棒性不强,提出一种基于Wasserstein-GAN的入侵检测系统.该系统中生成器的作用是将恶意样本转换为对抗性恶意样本,判别器对所有流量样本进行分类.为了保证入侵的有效性,实验只对样本的部分非功能性特征进行了更改.在NSL-KDD上,该系统能对多种类型攻击进行检测与分类,检测率高于对比的系统.此外,通过改变未修改特征的数量,验证了该系统具有很强的鲁棒性.未来可对系统进行改进,加入更多新类型的攻击数据,进一步提高系统鲁棒性.Liao等人[52]针对现有入侵检测方法缺少用于训练的标记数据以及检测精度低的问题,提出一种基于GAN的网络入侵检测方法,分别选用LSTM网络和ANN作为生成器和判别器,将GAN标准模型进一步转化为监督学习模型.在相同的测试集样本下,采用该方法的分类模型相较文献中的对比方法有更好的网络入侵检测性能,精确度达到82.3%.但由于对比方法的分类模型基本都来自于机器学习,该方法在部分评价指标上的值要低于对比方法.
5 问题与展望
近年来,基于深度学习的网络入侵检测系统研究取得了不少成果,从实验结果来看,相较传统机器学习方法有更好的性能表现.然而深度学习技术目前仍处于实验阶段,没有广泛应用于商用入侵检测系统.本节着眼于当前基于深度学习的网络入侵检测系统所存在的缺陷,介绍网络入侵检测系统需要解决的若干主要问题,并对未来发展趋势进行展望.
5.1 数据不平衡问题
深度学习中数据集的好坏会直接影响模型的训练过程与检测结果.在对模型进行训练时,往往需要足够多的样本来调整神经网络的各个参数.当前用于入侵检测的训练集中通常包含大量正常流量样本,恶意流量样本数量则较少.训练数据不平衡会导致训练后的模型存在严重的偏向性,即模型会将注意力过多地集中于正常流量数据上,使得异常流量数据的识别率大大下降.目前有关入侵检测数据不平衡问题的研究工作还较少,未来可以考虑将AE,CNN等多种深度学习模型相结合,利用模型各自的优势弥补数据不平衡所带来的影响.
5.2 实时检测问题
目前大部分入侵检测系统都是使用已有的公开数据集,在离线状态下进行研究,没有在真实的网络环境中进行实际应用[53].然而网络流量数据的行为特征会随着时间和空间的改变而发生改变,特别是在网络安全形势日益严峻的今天,各种新的网络攻击行为不断出现,恶意网络流量检测变得尤为重要.如何将训练的模型应用于实时检测以应对各种新型网络攻击是入侵检测系统未来研究的重点,如何对各深度模型结构进行优化和改进以适应日新月异的网络环境是未来发展的关键.
5.3 训练时间问题
在处理海量高维数据时深度学习能实现较高的准确率,但目前大多数深度学习模型涉及深层次的结构,训练所需的参数较多,从而导致训练时间过长,严重影响模型的检测效率.当前大多数研究都将重心放在系统检测的准确性上,很少将训练时间作为考虑因素及评价指标,导致很多模型仅存在于理论中,无法付诸实践.如何在有限的训练时间内保证较高的准确率,是基于深度学习的网络入侵检测系统模型优化的重要方向之一,也是网络入侵检测系统能否用于实际的关键.
5.4 深度学习框架安全问题
目前较为主流的深度学习框架有PaddlePaddle,TensorFlow,Keras,Caffe,PyTorch,CNTK等,这些深度学习框架为用户提供了大量可重复使用的算法与模块,有效提高了开发效率,但也存在一些安全漏洞,容易遭受网络攻击[54].例如,TensorFlow所依赖的1个用于科学计算的python库Numpy出现DoS攻击漏洞,攻击者可利用这个漏洞对系统进行干扰.深度学习框架以及它所依赖的组件中的任何安全问题都会威胁框架之上的应用系统,进行基于深度学习的网络入侵检测系统研究时需要格外注意这一问题.
6 结束语
深度学习技术有效提高了网络入侵检测系统的性能,在处理大规模流量数据时能实现较高的准确率.本文从深度学习模型、数据预处理技术、数据集与评价指标、入侵检测应用以及问题与展望等方面描述了基于深度学习的网络入侵检测系统的研究现状,希望能为相关领域的研究提供借鉴和思路.
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
舰船科学技术(2022年10期)2022-06-17
快乐学习报·教育周刊(2022年16期)2022-05-01
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
微型电脑应用(2019年8期)2019-08-22
当代陕西(2019年10期)2019-06-03
福建基础教育研究(2019年6期)2019-05-28
北京航空航天大学学报(2017年7期)2017-11-24
