
通信音视频编解码技术的研究与应用
2022-12-06 09:05:20李胜辉王文敏
微型电脑应用 2022年11期
李胜辉,王文敏
(中移在线服务有限公司,河南,郑州 450000)
0 引言
随着无线通信技术的迅速发展,可视化数字媒体丰富了人们日常生活,智能手机等信息采集设备逐渐普及,图像、视频音频的采集更加便利。视频数据库、可视电话、视频会议已经进入实用阶段,音频视频信息内容丰富,数据量占有巨大空间。对音频视频的传输使用时间过长,数据的传输和存储的实现成本非常大,对资源产生极大的消耗。
针对上述存在的问题,文献[1]中基于TMS320DM642的通用音视频解码器,数据集并行和线程级并行增强了对音视频信息的处理能力,但核心处理器的散热性能较差,输出图像码率不稳定。文献[2]基于DSP软硬件结合方法实现了音视频编解码,使用特殊的DSP数字信号处理芯片,数据传输采用HPI方式,但系统中没有设计网络接口,通信中视频图像的编解码时延较大。
针对上述研究中存在的不足,本研究对通信音视频编解码进行了详细的分析,并构建了通信音视频编解码系统,将编解码过程分为音视频编码子系统和音视频解码子系统,并对视频编码算法进行了优化。
1 通信音视频编解码系统
1.1 系统整体设计
在多媒体通信过程中所传输的视频图像和音频数据都含有大量的冗余信息,增加了通信传输的时间。如果音视频的分辨率更高,传输的数据量迅速增加,使用的传输时间增加,无法保证通信的实时性。通信中视频图像信息中数字帧内有空域冗余,图像的前后帧之间存在时域冗余[3]。为降低传输时间,保证通信的实时性,对音视频信号进行编码,消除通信信号中的冗余信息,降低相关性[4]。采用帧间编码技术,将视频数据的每一个帧分为若干区块,每个区块中像素的位移向量相同,视频图像中帧的相对变化称为运动矢量[5]。根据视频图像的变化,每帧的画面存在不同的运动矢量,通过熵编码进一步对音视频信号进行压缩,能够依照图像中前一帧的像素预测下一帧的图像,减少视频信号中的冗余信息[6]。图1为本研究通信音视频编解码系统总体结构框图。
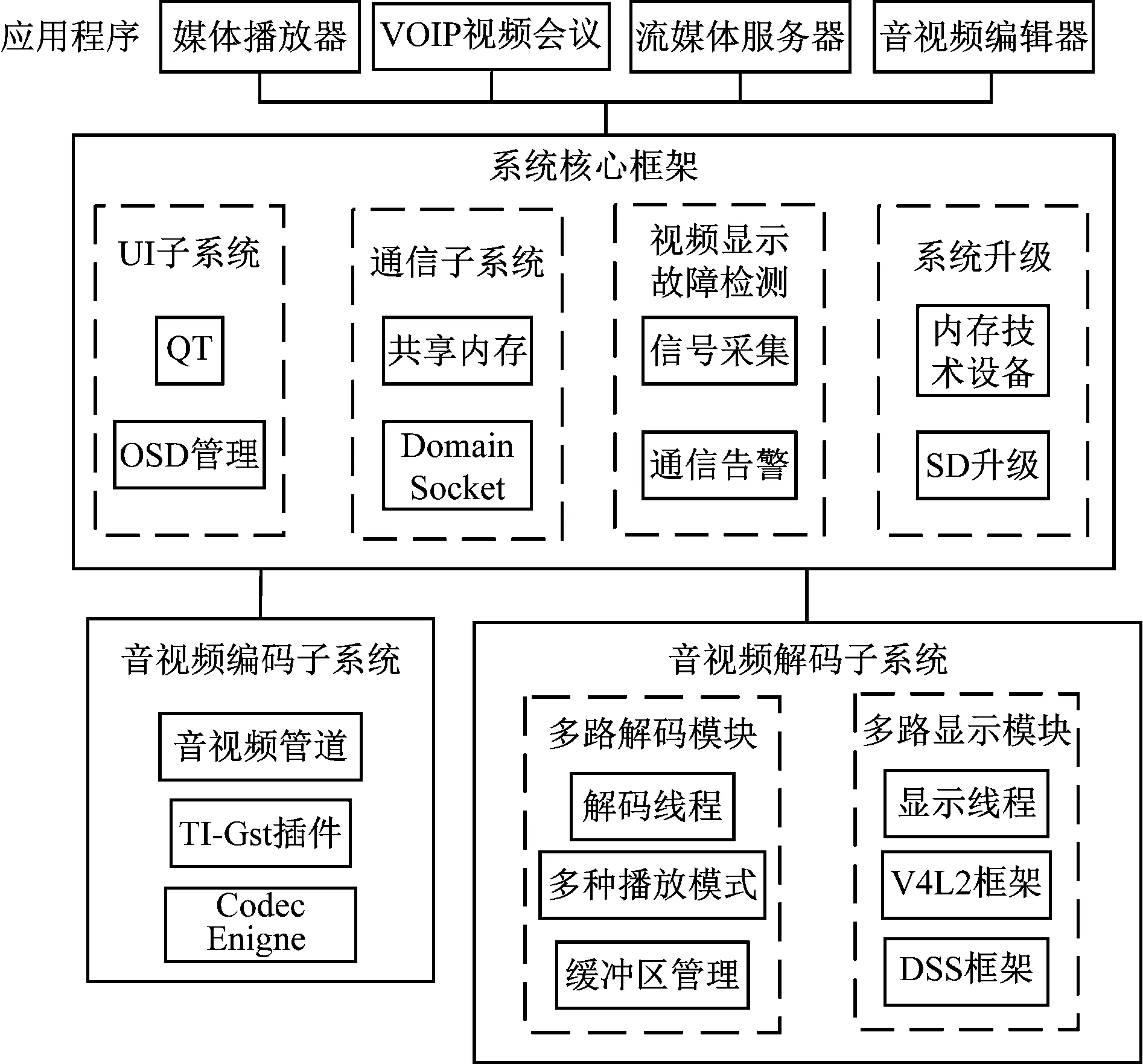
图1 系统总体结构框图
本研究通信音视频编解码系统分为系统核心部分、音视频编码子系统和音视频解码子系统。根据用户对通信音视频编码需求,系统构建于Linux系统的开源框架之上,利用GSteamer插件加速视频的处理,能够提高通信图像质量,减少音视频信号中的噪声[7]。音视频解码子系统能够支持高达8路视频的并行解码和显示,实现实时解码、视频图像满帧率显示、不会出现卡顿的情况。当进程开始时根据设定参数开始解码和显示线程。系统核心部分采用共享内存完成各子系统之间的通信,并实现自动检测视频和显示故障,通过无线通信通知用户。系统升级模块实现对整个系统的升级和维护,降低了成本,提高了升级速度[8]。表1为各模块接口的具体指标。

表1 各模块接口指标
在实际编码工程中,视频图像的参考帧在经过编码解码和滤波后的通信视频帧中选择,这种方式可以提高预测精度和视频图像的压缩编码效率[9]。将预测值与视频图像进行处理,对音视频信号变换量化后得到相应的变换系数[10]。根据变换系数对通信中的信号进行熵编码,压缩后的信号包含解码的图信息,通过网络打包后进行传输。
1.2 音视频编解码硬件设计
音视频编解码模块连接外部电源后,将外部电能转换为系统所需的各类电源,提供标准工作电压给各芯片使用,同时时钟芯片输出多种时钟信号传输到各芯片中,使各芯片发挥正常功能。复位芯片发生复位信号使各芯片功能复位,经过AD模数转换,然后传输到新视频编解码专用的输入通道,按照指定的码率和帧率对通信中传输信号进行编码。视频编码芯片处理器的内部原理框如图2所示。
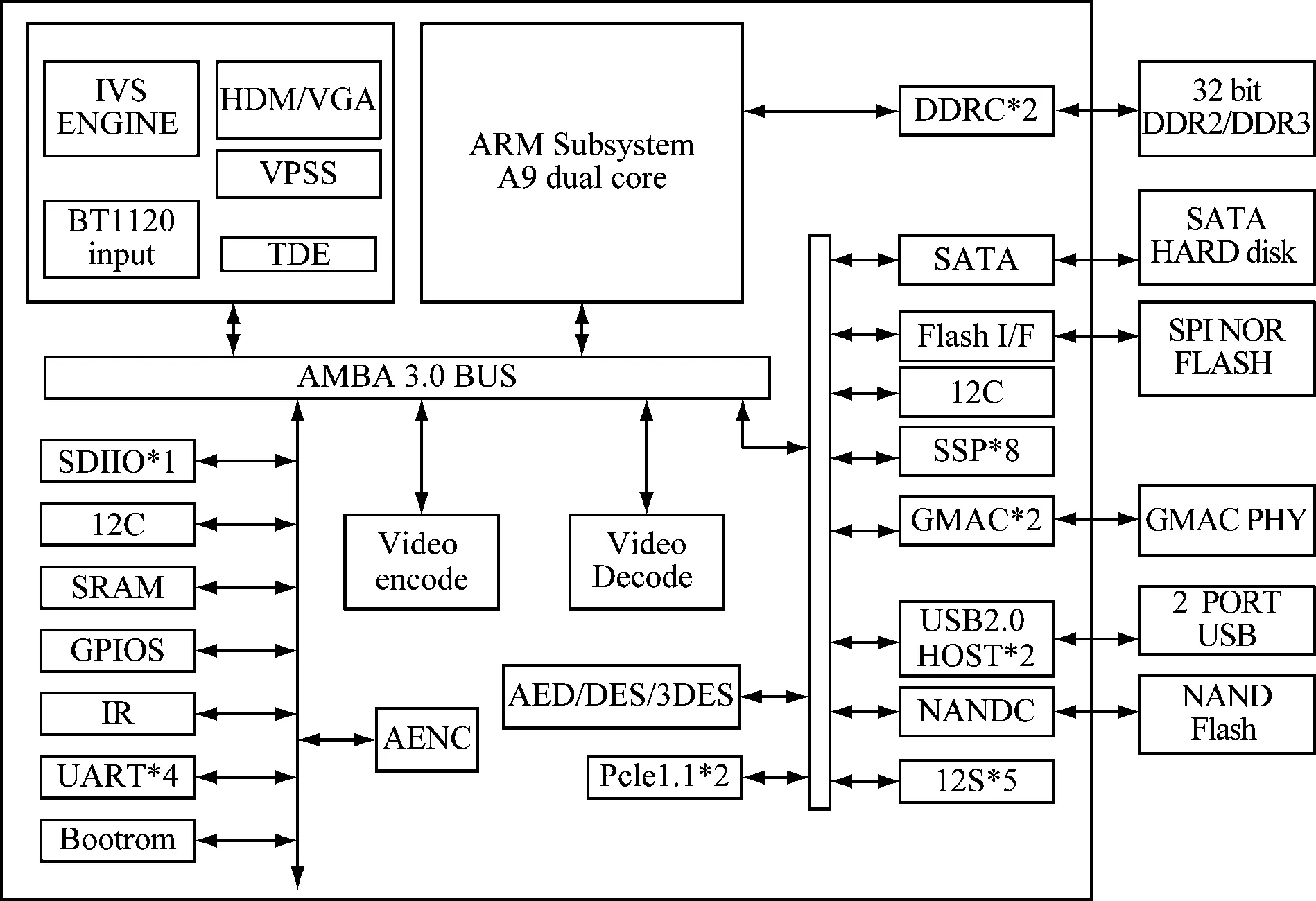
图2 处理器内部原理框图
本文应用Hi3531处理器,具有双核处理器,能够同时对多路视频进行编解码,安装有特定的网络加速模块,同时具有高度集成和多个外围接口,能够满足多种差异的产品功能和图像质量要求。处理器最高主频可支持390 MHz,提供独立的32 kB L1I缓存、32 kB L1D缓存和共享265 kB L2缓存。支持多协议视频解码,包括H.264/AVC Baseline、Main和High三个档次以及MJPEG/JPEG Baseline、MPEG-4、MPEG-2、AVS基准档次等,自适应比特率的码率在16~40 Mbit/s范围内,编码帧率最高为60 fps。还能够对图像信息去隔行,对通信中视频图像进行边缘增强,增强图像的对比度,减小图像的冗余信息。
视频AD转换芯片的性能直接关系到视频信息解码速度和图像质量,本研究选用AD9886A作为视频输入芯片,如图3所示。
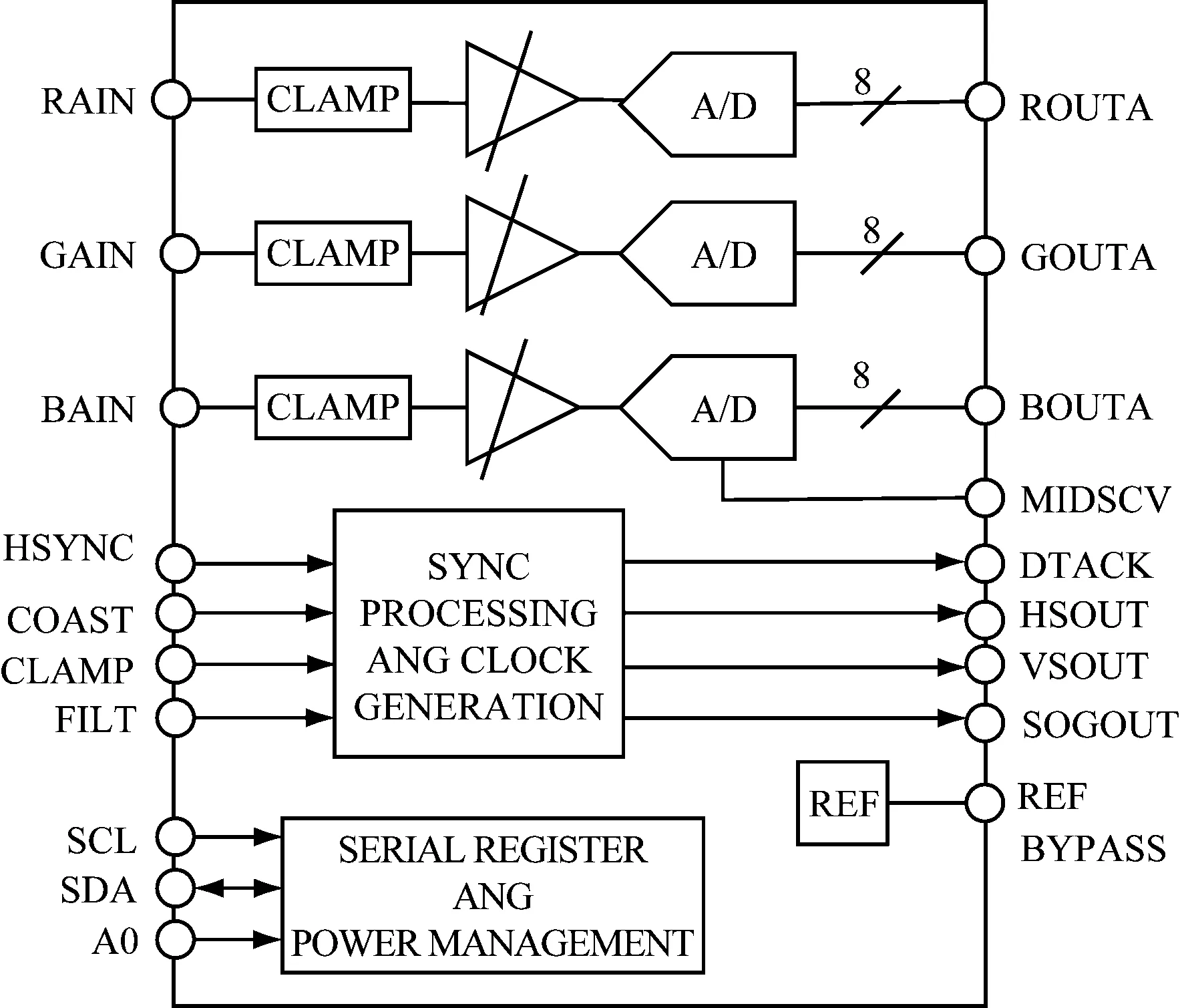
图3 AD9886A芯片图
编码器的视频输入芯片支持VGA格式的视频信号,视频经过A/D,输出数字RGB/YUV格式的视频。同具有110 MSPS转换速率,4∶2∶2输出模式,140 MHz模拟带宽,最大功耗为500 MW。
本研究选用TW2984芯片用来采集音频信号,支持4路音频同步输入,内置4个完整的音频ADC和1个音频DAC转换器,支持多通道的输入,采样频率为8/16/32/44.1/48 kHz。该芯片的内部结构如图4所示。
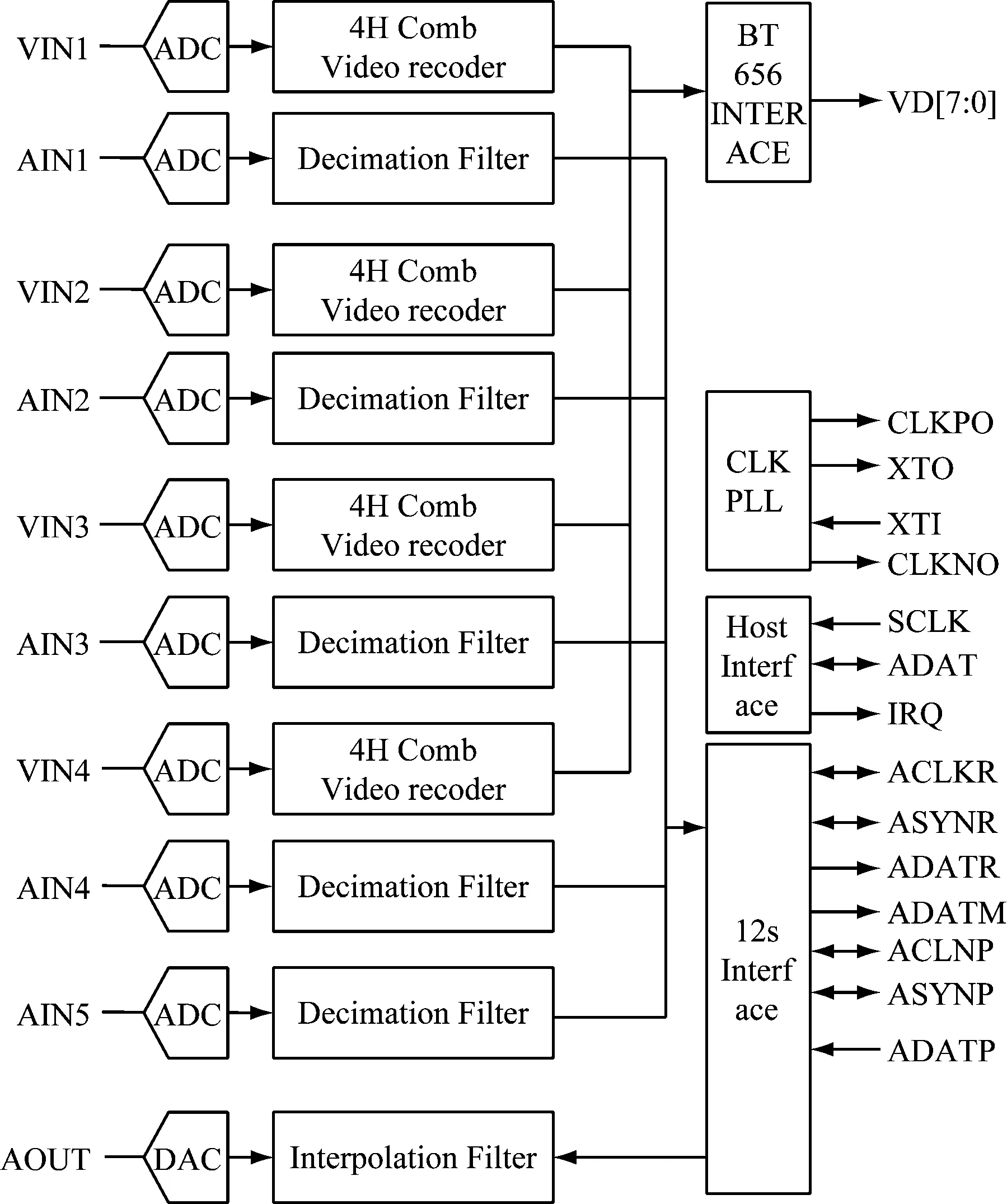
图4 TW2984芯片图
音视频编码模块通过AD转换芯片转换为数字RGB视频信号和音频信号,进行编码压缩后通过连接的线路输出。
1.3 视频编解码算法
采集到音视频信号后,音视频编码子系统开始对原始数据进行图像帧编码。使用图像中的帧间像素进行预测,进一步对误差变化和量化处理。通常使用的变换方式有离散余弦变换和小波变换等,视频图像经过特定变换后能够达到更好的视觉效果。
由于DCT整数变换,对通信中的音视频信号量化压缩前,引入H.264标准将时域信号转换为频域信号。通过离散余弦变换,避免了采用泛用性较强的DCT变换引起逆变换中错配的问题。在对数据量化过程中,H.264根据视频图像的像素值变化范围使用非静态方法确定量化参数,能够最大程度地保留图像的细节,不损失视频信息完整性的同时去除了不必要的码流。H.264编码方式如图5所示。
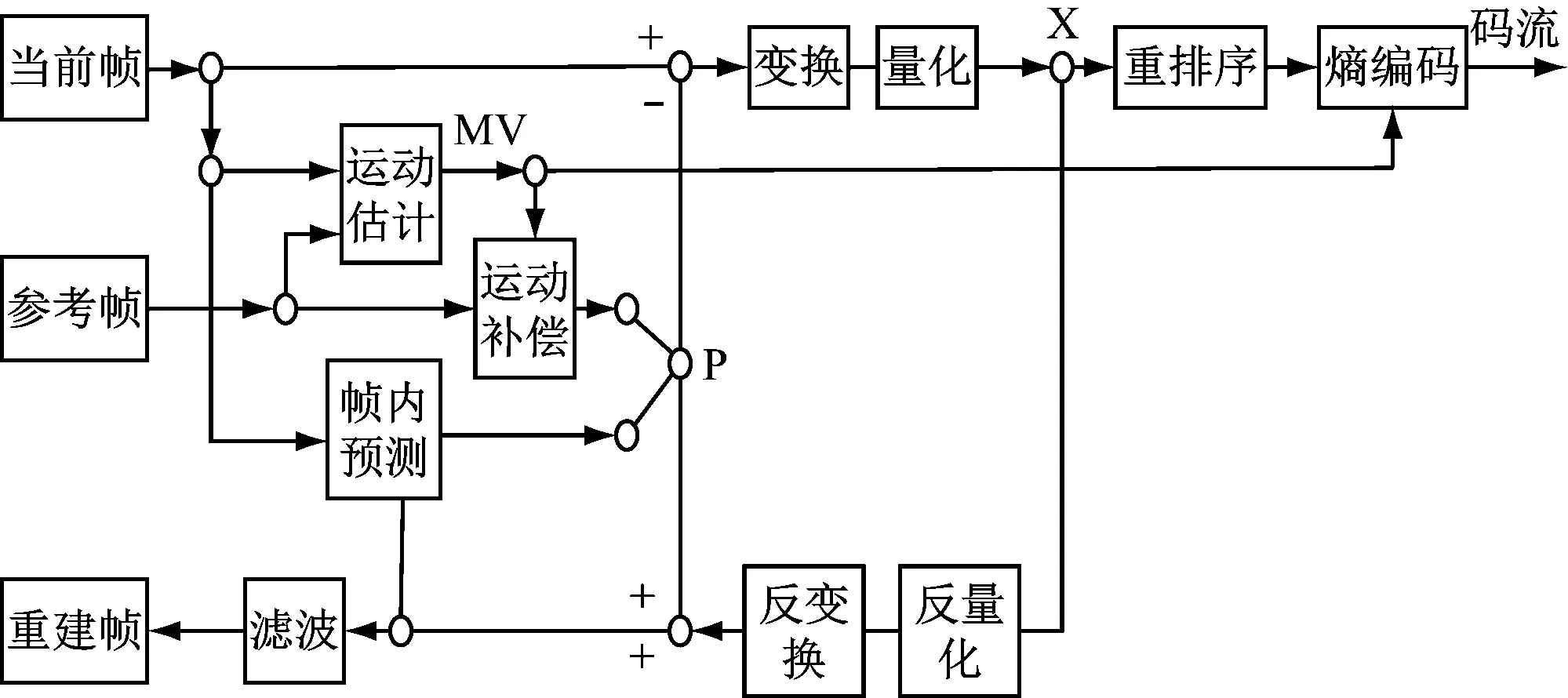
图5 H.264混合编码
在对音视频数据中比例因子进行编码时,除第一个比例因子外,剩余的比例因子都应该利用特殊的霍夫曼码进行差分编码,使用了频域去除数据中的冗余信息,均匀量化可表示为
(1)
其中,Sn表示输出的反量化音视频数据,Sm表示输入的量化点数,b表示每个音视频数据自带的位数。
而MP3使用非均匀量化可以进一步压缩对音视频数据编码的码率,进一步减小量化误差,可表示为
(2)
其中,X(j)表示量化后的数值,ri(j)表示第i个频带的频域值,Ci表示综合因子。与之对应的反量化公式为
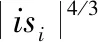
(3)
其中,xri为反量化结果,A为综合指数。量化不同的步长解析不同的频谱系数采用非均匀量化,公式为
X(j)=int[(|ri(j)|×21/4s-cs)3/4+M]
(4)
其中,s表示比例因子,cs表示全局比例因子,M表示调整偏差。与之对应反量化可表示为
(5)
关于时域混叠消除法的改进离散余弦变换是一种与傅里叶变换有关的变换,处理对于数据量级较大的音视频信息时的效果更好。在视频图像数据信号中,出现前一块数据与之后的数据重叠的情况,使用离散余弦变换能够避免音视频数据区块边界出现冗余。AVS音视频压缩标准可表示为
(6)
其中,Xk表示混叠重建后输入的音视频信号,xn表示经过变换后的输入值。对音视频信号量化后使用熵编码进行压缩,同时不会产生任何编码损耗。音视频信号构成为A={ai|i=1,2,…,m},其中每个信号出现的可能性表示为P(ai),音视频信号的信息容量为I(ai)=-log2P(ai),其中某一音视频信号在信源端与其他信号不关联,信号源的熵可定义为
(7)
其中,H(X)表示通信中某一音视频信号的平均信息量。音视频信号出现的可能性完全一致时,信号的熵达到最大,在实际通信音视频信号编码过程中出现信号的冗余,时信号编码的复杂程度增加。H.264中采用CAVLVC算法可表示为
(8)
其中,Xij为通信信息中视频图像块第i行第j列的值,Xmn表示变换矩阵中的系数值。量化公式为
(9)
其中,F表示输出的音视频信号量化值,Qstep表示量化步长。利用通信中用音视频信号完成编码的信息块消除音视频信号将出现概率上的联系,减少了对音视频编码使用的资源,在一定程度上提高了编码效率。
2 应用测试
为验证本文研究通信音视频编解码技术的性能,分别使用文献[1]编解码方式、文献[2]编解码方式和本研究音视频编解码技术对视频实验样本进行处理,比较分析输出码率水平和端到端时延。表2为本研究软件实验环境。表3为实验数据样本。

表2 实验环境

表3 数据样本
本研究实验设定目标帧率为30 fps,与视频图像的输入帧率相同,设定为恒定码率控制,I帧和P帧初始参数为28,编码过程根据码率对量化参数进行调整。对标准测试图像样本进行测试输出的码率如图6所示。对图像数据样本的时延分析如图7所示。
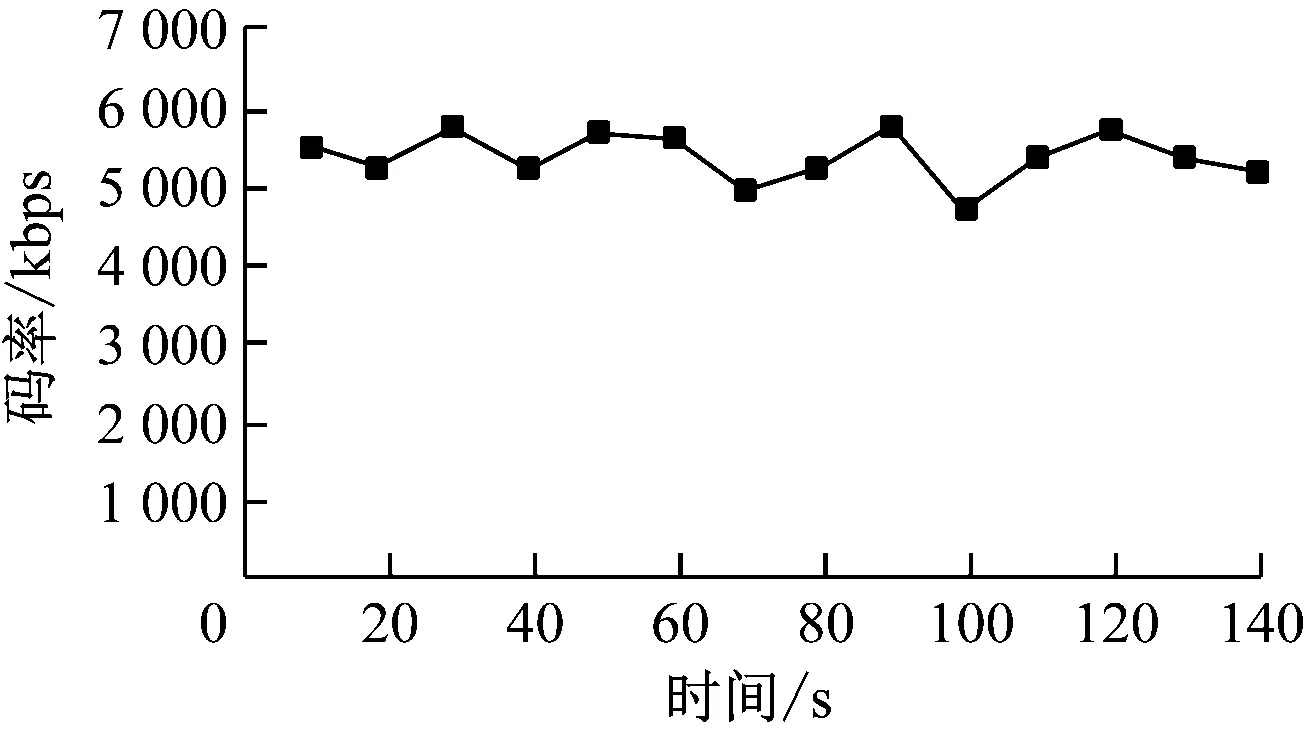
图6 图像序列输出码率
由图6可知,本研究图像序列输出码率范围在5~6 Mbps,输出码率比较稳定,有利于音视频码流的平稳传输。
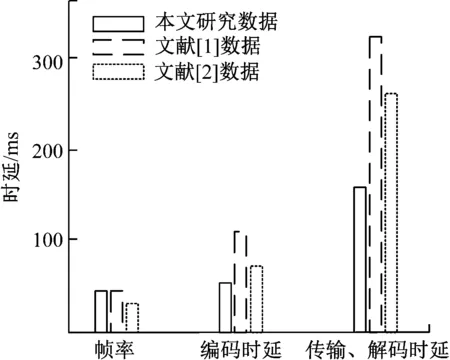
图7 编解码时延分析
观察实验结果可知,本研究对音视频数据的编解码技术的时延最低,编解码效率最高。本研究编解码的帧频为30 fps,编码时延为65 ms,传输、解码时延为168 ms,说明本研究编解码技术具有更好的实时性,减少了音视频信号中的冗余信息。
文献[1]编解码方式的帧率同样为30 fps,编码时延为125 ms,传输、解码时延高达318 ms。文献[2]编解码方式的帧率为25 fps,编码时延为86 ms,传输、解码时延为272 ms。文献[1]和文献[2]的编解码方式对视频图像样本编解码时延过高,算法过于复杂,运算量较大,所使用的时间过长,效率不高,压缩增益效果较差。
3 总结
本研究对通信音视频编解码系统的设计和实现进行了详细的分析,能够最大程度地满足用户通信需求。采用Linux系统的开源框架实现了通信中编解码功能,提高了应用程序的适用性。详细说明了新视频编解码模块的功能和设计,使用H.264视频编码和G.711音频编码,并分析了子系统的实现过程。
本文研究还存在一些不足之处有待改进,对于视频信息中内容复杂、运动较为强烈的情况,运动估计算法的精度有待提高。信号中变换和量化使用的时间过长,对熵编码还需进一步优化。
猜你喜欢
空间科学学报(2020年4期)2020-04-22 01:17:38
家庭影院技术(2019年7期)2019-08-27 02:42:20
民用飞机设计与研究(2019年2期)2019-08-05 01:33:26
电子测试(2018年18期)2018-11-14 02:30:54
计算机应用(2018年7期)2018-08-27 10:42:40
电子制作(2018年12期)2018-08-01 00:48:06
中国交通信息化(2017年2期)2017-06-06 05:49:47
江西理工大学学报(2015年3期)2015-12-22 05:26:24
计算机工程(2015年8期)2015-07-03 12:19:56
宇航学报(2014年2期)2014-12-15 02:49:06
