
急性髓系白血病流式细胞术全程自动化诊断技术研究
2022-12-05 06:22郭玉娟李智伟芮东升雷伟摆文丽陈鉴李敏农卫霞张向辉王奎
石河子大学学报(自然科学版) 2022年4期
郭玉娟,李智伟,芮东升,雷伟,摆文丽,陈鉴,李敏,农卫霞,张向辉,王奎*
(1 石河子大学医学院预防医学系,新疆 石河子 832000;2 新疆维吾尔自治区人民医院临床检测中心,新疆 乌鲁木齐 830001;3 石河子大学医学院第一附属医院血液风湿科,新疆 石河子 832000)
由于流式细胞术具有高通量、高灵敏度、高精确度定量和多参数检测的功能特点,越来越被广泛应用于临床医学研究中,尤其是医学检验方面[1]。在应用流式细胞术对急性髓系白血病(AML)进行诊断和免疫分型时,会产生多组合、高维度的流式数据,近年来不断有学者提出流式数据的分析需要自动化技术的帮助[2-3]。
目前多数的研究主要侧重于使用机器学习方法实现对细胞亚群聚类和疾病识别的自动化。在最新的综述中,Cheung等[2]列出了聚类分析中引用较多的方法,包括SPADE[4],FLAME[5],SWIFT[6-7],FlowSOM[8]和flowDensity[9]等算法。Pyne等[10]和Lee等[11]提出的JCM方法、Arvaniti[12]构建的CellCnn模型,以及Lhermitte等[13-14]建立的专家诊断系统,在疾病的诊断方面也展现出了良好的效果。
然而,Cheung[2]等人最新的调查显示,在实验室中,众多的流式细胞自动分析技术,除了降维可视化方法[15-18]和FlowSOM方法外,使用的并不多。Finak等[19]也指出大多数自动分析方法都是探索性的,与临床研究的要求还有差距。经探索发现现有的细胞亚群聚类分析和疾病诊断两部分方法的研究是断裂的,虽然两类方法在各自的领域表现良好,却不能实现流式实验室流式数据分析的全程自动化。
针对以上问题,本研究提出ArcDia(Automated Registration of Cell populations and Diagnosis and Immunophenotyping of AML)方法以实现AML流式诊断全程自动化分析。下面将围绕ArcDia的四个主要环节即数据预处理、细胞聚类分析、亚群的分类及标注、特征提取及诊断进行阐述,并使用两个实例验证其准确性和可用性。
1 资料与方法
1.1 数据来源
数据1来源于公共数据库flowrepository.org,包括316个正常人和43个AML病人,每人8管数据,其中第一管为同型对照,第八管使用7AAD检测细胞活性。
数据2来源于实验室2016、2017急性髓系白血病流式检测数据,包括50个正常人和28个AML病人标本(包括4个治疗后流式重测无异常标本),每人8管数据,前3管各使用6个荧光抗体,后5管各使用4个荧光抗体。本研究经当地政府伦理委员会批准,所有参与者均签署知情同意书。
数据1和数据2 分别来自不同的流式细胞测试平台,存在平台效应。数据1在采集阶段就对数据进行了清洗,不需做去粘连设门和活细胞设门,为基准数据;数据2是原始数据,未经过清洗,为真实数据,需要自动化完成去粘连设门和活细胞设门过程。
1.2 方法
1.2.1 数据的预处理
对流式细胞数据各抗体的荧光强度先做补偿再使用双指数转换提高数据的对称性,前向散射光FSC使用线性变换,侧向散射光SSC使用lg对数转换。由于数据1和数据2来自不同的流式细胞实验平台,其最大可测强度存在倍数关系。为统一数据的分析过程,在做转换前,对每个变量都进行了线性缩放处理,使得最大观测值和预定值(262144*4)保持一致,保证每个变量的范围小于15,以便进行统一的下游数据分析。
1.2.2 多元正态混合分布模型
假设N个m维观测值x1, x2, …, xN服从混合分布X,则变量X的概率密度函数可定义为:
(1)
式中,πi> 0,i=1, 2, …,g,称为混合分布的混合概率,满足条件:∑πi=1;fi(x)为某分布类型m维随机变量的概率密度函数。
在混合模型中,可以认为总体是由g个子总体{Ci,i=1, 2, …,g}构成,每个子总体服从一个概率密度函数为fi(x)的特定分布。从总体中随机选择一个观测值,它从特定的子总体Ci中被抽取的概率是πi。
特别的,当fi(x)是m维正态分布的概率密度函数,且其均值向量和协方差矩阵已知时,其概率密度函数可以表达为:
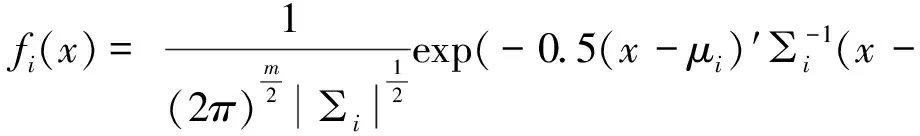
(2)
此时,公式(1)对应的分布称为g个成分正态混合分布,其参数用Θ={πi,μi,∑i}表示。当参数Θ={πi,μi,∑i}已知时,任意观测值xj属于Ci的后验概率
(3)
如果我们用多元t分布的概率密度函数代替公式(2),则混合分布公式(1)为t混合分布,相应的参数为Θ={πi,μi,∑i,νi},其中vi为自由度。其他混合分布的定义类似。当参数Θ未知时,可采用EM算法对其进行估计。为了更加清晰,本文使用正态混合模型。
如果数据集只有测量值,没有所属类型标签信息,得到模型参数后,可以按照(3)对每一个观测值计算g个后验概率,选取最大ωji对应的子总体Ck为该观测值所属的总体,可以把N个m维观测值分成g个互不相交的集合或者类。这种用某种算法将N个m维观测值分成g个互不相交的类的过程称为聚类分析。聚类分析属于无监督学习方法,在流式细胞术中,聚类分析对应于细胞亚群的识别,又称为自动设门。这里可根据实际需求和偏好选择不同的聚类方法,本文仅考察正态混合模型和FlowSOM两种聚类方法对AML病人的诊断效果。
如果部分数据集有所属类型标签信息,这时可以使用包含g种类型的元素作为训练集,训练正态混合分布模型,得到含有g个子总体的正态混合模型(1~2),然后利用公式(3)对测试集中类别未知的元素进行分类。这个数据分析过程叫做分类分析,属于有监督学习方法。
1.3 统计分析软件
模型构建及程序编写均采用R 4.1.2,聚类分析调用EMMIXskew[20]和FlowSOM[8]软件包。采用灵敏度、特异度、准确率和F-measure构成评价指标体系。
2 结果
2.1 粘连细胞的识别去除
数据2为原始数据集,需做去粘连细胞处理。首先选取FSC-H大于1.5且FSC-A小于7的细胞子集,计算其在全体细胞中的占比。当占比小于0.9时,使用子集变量FSC-A与FSC-H的百分位点P5和 P75两个对子为端点做线段,将连线垂直上移和下移0.95单位得到两条平行线,如图1A所示;当子集占比大于0.9时,则使用全集计算 FSC-A与FSC-H各自的四分位点P25和P75,然后以P25对子作为起点,P75对子为终点做连线,将连线垂直上移和下移0.95单位得到两条平行线。则两条平行线以内的点为正常细胞,平行线之外的点为粘连细胞,识别过程如图1B所示。对每一管数据做去粘连细胞处理,通过检查发现,粘连细胞的划分均合理有效。此过程对应于流式分析去粘连设门。
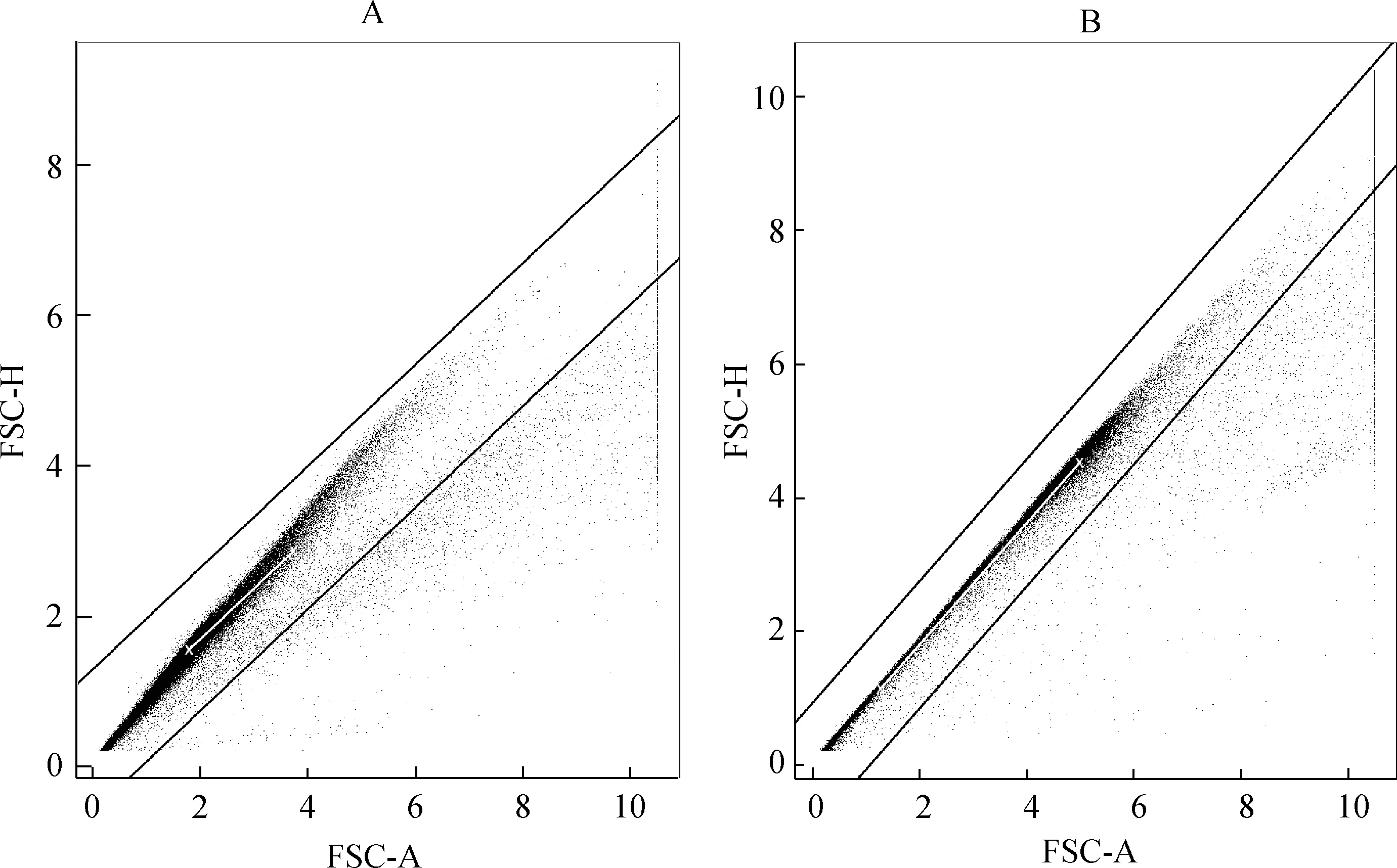
A:使用子集变量FSC-A与FSC-H的百分位点P5和P75两个对子为端点做基准线;B:使用全集变量FSC-A与FSC-H的百分位点P25和P75两个对子为端点做基准线。图1 粘连细胞识别过程
2.2 亚群识别与聚类分析
对去除粘连细胞后的数据使用两种不同聚类方法进行分析。对所有训练样本的细胞亚群中心点即宏细胞,做散点图,并与真实细胞的散点图比较,见图2。如图2所示,个体宏细胞的分布情况与真实细胞所构成的散点图相似,且两种聚类方法得到的宏细胞分布形态也是类似的,说明宏细胞体现了亚群的分布特征,因此在下游分析中对宏细胞进行统一的映射标注即可。

上行:采用正态混合模型得到的宏细胞;中行:采用FlowSOM方法得到的宏细胞;下行:真实细胞的散点图;前两列:正常人数据,后两列:AML患者数据图2 细胞亚群宏细胞的分布情况
2.3 亚群分类与映射标注
数据1使用flowCAP给定的前179个个体作为训练集,后180个个体作为测试集。舍去第一(同型对照)和第八管(细胞活性检测管),先对第2管的宏细胞进行20个类别的混合正态分布建模,以此模型参数做初值,然后使用第3管数据更新模型参数,重复此修正过程,直至第7管数据修正结束,得到训练好的有监督分类模型。数据2则从78个个体中随机选取40个个体,取全8管数据的宏细胞作为训练集,由于样本相对较小,为避免过拟合,使用五折交叉验证法训练分类模型。其余38个个体作为测试集。
为使细胞亚群分类更加精确,分类模型中亚群数目的设置通常高于常规使用的细胞类型数。为此,需将多个相似的细胞亚群标注为同一个细胞类别,这个过程成为亚群标注。标注其实是多对一的映射过程,如图3所示。图中训练集的20个宏细胞类被标注为10个细胞类型,从而得到一个多对一映射。10个细胞类型包括淋巴细胞,单核细胞,中性粒细胞,嗜酸粒细胞,幼稚细胞,有核红细胞,细胞碎片,凋亡细胞,小细胞,未知细胞等。其中未知细胞类为难以分辨的类,细胞碎片、小细胞和凋亡细胞对应于流式分析中活细胞门剔除的细胞。
利用训练好的分类模型把测试集的宏细胞分为20个类,然后把20个类标注为10个细胞类别,完成了测试集数据的分类和标注。
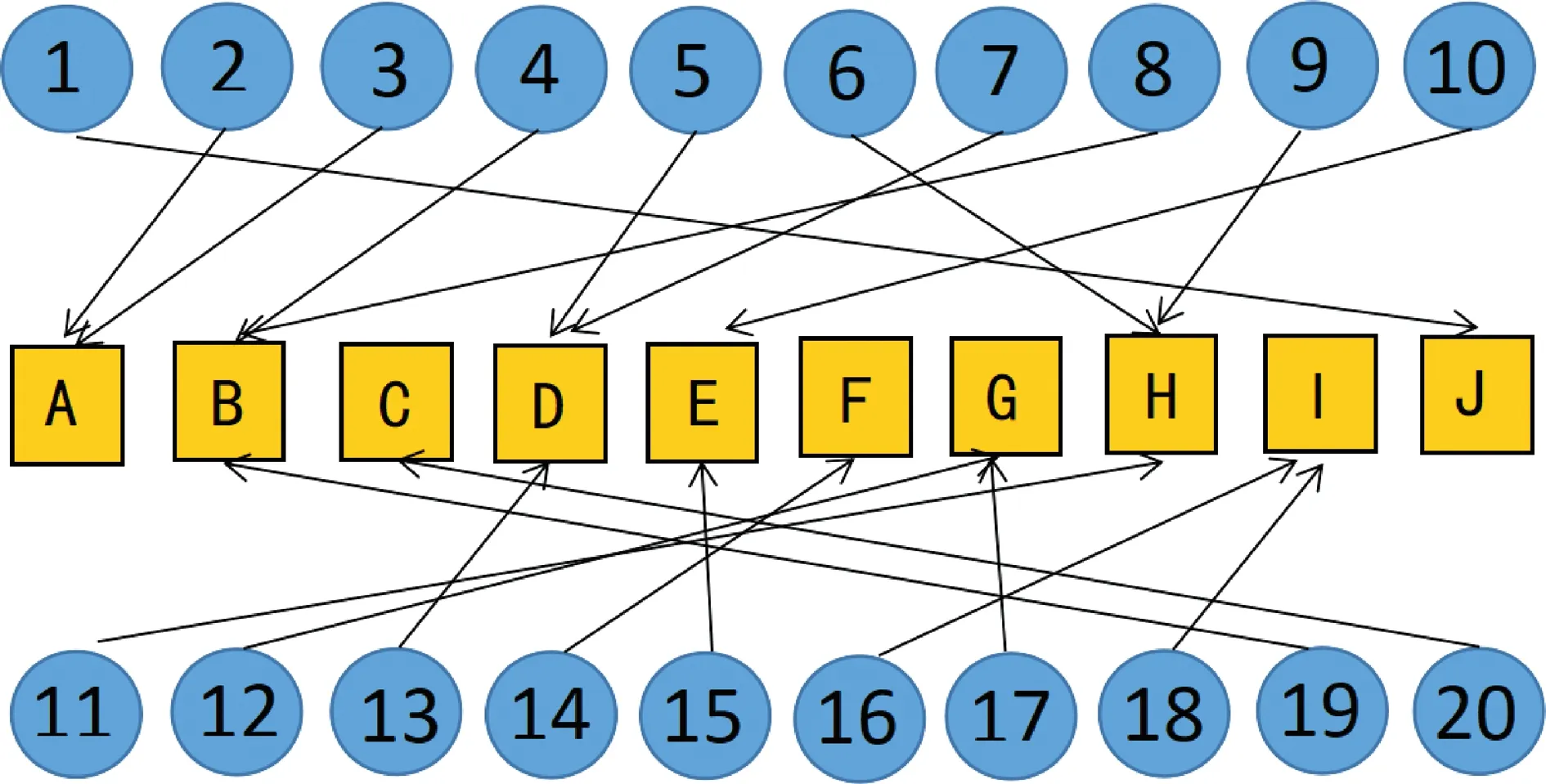
蓝色圆圈:20个宏细胞类;黄色方框:标注后的10个细胞类别。图3 亚群标注映射图
亚群分类和标注可以通过宏细胞的标注效果图或者单个病人的亚群标注图进行质控。图4给出了数据2中的495号病人细胞亚群的分类情况(A)和亚群标注前(A)、标注后(B)的对比。上行为病人某管宏细胞按照有监督分类模型给出的结果,不同颜色代表不同的细胞亚群。下行代表细胞亚群按照图3映射后得到的亚群标注后的结果。红色的幼稚细胞,天蓝色的有核红细胞,绿色的淋巴细胞,蓝色的单核细胞,紫色的中性粒细胞,清晰可见,均无异常。
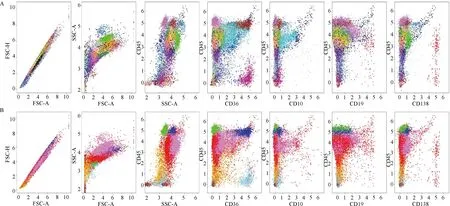
A:495号病人亚群标注前;B:495号病人亚群标注后。图4 细胞亚群标注前后的比较
2.4 特征提取与AML诊断
在亚群特征提取的基础上进行AML诊断。亚群特征提取的内容包括:绝对数:总细胞数N、淋巴细胞数R2、幼稚细胞数R3、中性粒细胞数R4、单核细胞数R5、有核红细胞数R6、嗜酸性粒细胞数R7;相对数:原始细胞在非红细胞中的占比R3/M、R4/M、R5/M,其中M为非红有核细胞数M=R3+R4+R5+R7,淋巴细胞在细胞中的占比R2/N;各类细胞不同抗原的阳性表达率。利用训练集对AML诊断所需的特征资料进行筛选,编制统一的判断准则用于对测试集进行诊断,判断一个人是否患有急性髓系细胞白血病(AML)。判断准则由3组子准则的逻辑或组成,满足一条即为AML。
2.5 AML诊断结果比较
数据1的自动诊断结果见表1。使用正态混合模型进行细胞聚类的ArcDia诊断结果,灵敏度为1,特异度为0.99,准确度是0.99,F-measure为0.99;使用FlowSOM作为聚类方法的ArcDia的诊断结果,灵敏度为1,特异度为0.98,准确度是0.98,F-measure为0.98。
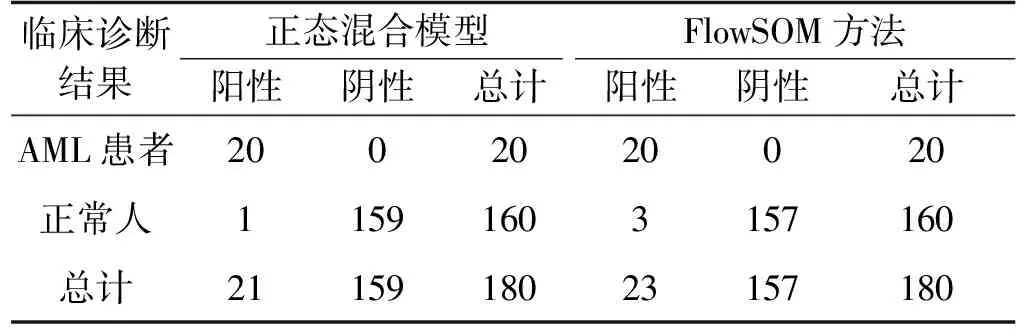
表1 数据1两种聚类方法的ArcDia自动诊断结果比较(测试集)
数据2的自动诊断结果见表2。基于正态混合分布的ArcDia诊断,灵敏度为1,特异度为0.96,准确度是0.97,F-measure 为0.97;基于FlowSOM的ArcDia诊断,灵敏度为0.92,特异度为0.92,准确度是0.92,F-measure为0.92。注意,表2是五折交叉验证第四折的结果。上述四个指标的五折交叉验证的平均值,使用FlowSOM方法时分别为:0.88,0.95,0.93,0.93;使用正态混合分布模型时分别为:0.91,0.95,0.94,0.94。
数据1和数据2的4个指标和五折交叉验证的平均值表明,ArcDia 使用的两种聚类方法得到的AML诊断结果相近。
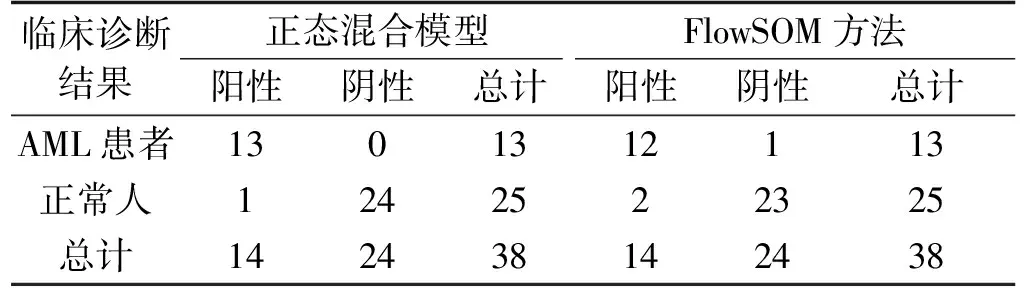
表2 数据2两种聚类方法的ArcDia自动诊断结果比较(测试集)
3 讨论与结论
本研究从临床应用的实际角度出发,结合2种AML流式数据,分析AML亚群识别和疾病诊断过程中出现的问题,结合《急性白血病系别判断的流式细胞免疫分型专家共识》[21],提出一种和AML人工诊断分析过程完全匹配的模块化全程自动分析方法(ArcDia),对流式实验室AML全程自动化分析技术的发展具有重要意义。
ArcDia有其显著的特点。首先,ArcDia是模块化的,无监督的聚类方法和有监督的分类方法都是可替换的。目前ArcDia所使用的聚类方法包括正态混合模型和FlowSOM,比如可以选择精准的SWIFT聚类方法,SWIFT采用加权抽样、亚群拆分、亚群合并等方法,可以确保最后的亚群都是单峰并且对应唯一亚群。正态混合模型只能保证得到的大部分细胞亚群是同类型细胞的集合,SWIFT方法更为精准,正态混合模型更为省时。由于版权等原因,我们并未包括SWIFT方法。其次,ArcDia对细胞亚群的视角与其他方法不同。大多数方法关注的重点在于人群的差异和分类,并不关注亚群的类型,也不提供诸如阳性率、各类细胞占比等资料,是实验室技术人员难以理解的。ArcDia则模拟实验室AML分析的全过程,通过对分析过程中生成的聚类分析结果文件,亚群标注文件,亚群标注效果图,特征提取文件,诊断结果文件等过程文件的质量控制,提高AML流式数据自动分析的准确性和可用性,实现实验室AML流式诊断的全程自动化。最后,ArcDia方法实现了细胞亚群跨面板、跨样本的统一标注。现有的亚群对齐方法只对特定抗体组合进行跨样本的亚群对齐,并不能进行不同面板间的亚群对齐。而本文中数据1和数据2均为8管多色流式数据,对两个数据的所有细胞亚群均做了统一标注。
本文也存在着一些不足,第一,使用正态混合模型进行聚类分析时,亚群个数的确定使用的是ICL最大准则,亚群个数选取区间预先规定在16~25之间,因此,亚群个数的选择还不是全局最优的。第二,本方法只是对白血病中较为简单的单系别急性髓系白血病诊断过程实现了自动化分析,虽然从流式数据预处理到特征提取的自动分析过程是通用的,但诊断部分自动化到其他类型白血病的推广应用还在尝试中。第三,数据1和数据2分别来自两大著名流式细胞仪器生产商BC和BD公司的流式细胞仪,流式数据存在平台效应,不能直接将两个平台数据直接进行统一的亚群分类和标注。目前,本方法只能对细胞亚群进行跨面板、跨样本的统一标注,但ArcDia是可扩展的,借助于SwiftReg提供的平台效应和批次效应的处理方法,建立跨面板、跨样本、跨批次、跨平台的AML自动诊断平台(ArcDia)是完全可能的。我们相信随着AML流式细胞检测数据资料的积累和多中心流式细胞数据的使用,ArcDia算法将得到进一步的完善和应用。
利益冲突声明:本研究不存在任何利益冲突
猜你喜欢
现代临床医学(2023年1期)2023-03-24
中国医药科学(2022年5期)2022-05-05
矿产勘查(2020年6期)2020-12-25
工程与建设(2019年5期)2020-01-19
统计与决策(2017年2期)2017-03-20
光学精密工程(2016年1期)2016-11-07
电测与仪表(2016年15期)2016-04-12
中国卫生标准管理(2015年3期)2016-01-14
湖北师范大学学报(自然科学版)(2015年1期)2016-01-10
西南石油大学学报(自然科学版)(2015年4期)2015-08-20
