
一种基于图分析的不良网络应用快速发现算法
2022-12-03 01:57李雪妮马永征
计算机应用与软件 2022年11期
刘 冰 杨 学 杨 琪 李雪妮 马永征
(中国互联网络信息中心 北京 100190)
0 引 言
随着大数据、互联网的不断发展,域名(Domain Name)、IP与自治系统号码(ASN)等互联网基础资源的规模和监管难度不断增大。伴随网站承载形式的日趋多元化和互联网技术的蓬勃发展,各类网络攻击方法[1]层出不穷,网络空间治理的难度日益增加。不良网络应用是各种网络攻击的关键组成部分,如钓鱼网站和僵尸网络等[2],同时也是各类涉赌、涉黄、涉暴网站的主要载体,威胁着网络空间的安全。因此,及时发现和鉴别这些不良网络应用,并阻止利用其进行网络攻击的各类技术手段对维护网络空间的安全与稳定是至关重要的。近年来,不良网络应用的检测与发现越来越受到人们的关注。
目前,针对不良网络应用检测与发现的方法不尽相同,主要是通过特征提取的方式,获取网站文本数据特征或其他多维度的特征,一般涉及的特征大致分为两种:(1) 通过爬取网站数据,根据内容进行文本分析,提取文本特征[3];(2) 从网站域名注册和运维的角度分析域名系统(Domain Name System,DNS)相关数据并提取相关特征[4-7]。这种基于特征的检测途径都需要进行基于机器学习算法的分类识别与检测,通过将这些特征标记成训练数据集并构建分类器来区分不良域名和正常域名。这类方法的主要问题是许多局部特征(比如域名本地属性特征和记录类型特征等)通常并不健壮,攻击者可以很容易地改变这些特征来逃避检测,从而并不会对攻击能力造成影响。例如,如果将域名的缓存时间(Time To Live,TTL)设定为检测目标,那么攻击者可以简单地通过更改DNS查询缓存的时间来干扰检测结果从而达到攻击目的,其根本原因在于现有工作中提取的许多特征是基于单个域名或主机的局部特征。因此,攻击者通过合理化地更改这些特征,很容易使不良网络应用不符合分类器中指定的特征模式,从而影响分类检测算法的效果。
针对此现象,Khalil等[8]提出了一种基于图数据分析的不良网络应用快速发现算法。该算法可作为机器学习分类方法的补充算法,利用域名与IP、IP与ASN、域名与域名之间的全局关系解决域名局部特征不健壮问题,提升算法稳健性,并通过一种简单的度量方法来反映攻击者控制的资源之间的内在关联,达到利用少量已知不良域名快速关联和发现大量潜在不良网络应用的目的,降低种子数据成本,提高不良网络应用发现的可扩展性。但是,该算法在计算恶意得分时仅考虑遍历域名关系图谱中的所有连通图,忽略了排除在连通图之外的那些与种子域名有密切关联的域名,因此该算法更适用于连通图涵盖域名较多的情况,对于连通图整体规模较小且有较多节点散落在连通图外的情况表现不佳。因此,本文针对该算法进行了改进和优化,补充对非连通图内域名节点恶意得分的计算方法,扩大了种子域名的作用范围,对不在连通图中但与种子域名同样有密切关联的域名进行了恶意得分的补充计算,同时在种子获取方式和基于图路径的算法性能方面做了优化处理。为了评估本文算法的有效性,我们进行了大量的实验,通过主动采集的.CN域名DNS解析数据和从公开来源获取的有效数据,仔细权衡不同参数配置对真阳率和假阳率的影响来评估本文算法的实用性和有效性。实验结果表明,本文算法在保持较低假阳率(小于0.5%)的同时,可以获得较高的真阳率(大于99%)。此外,即使使用少量已知不良种子域名(数百个),本文算法也可以发现大量潜在不良网络应用所使用的域名(上万个),因而具有较好的大规模工程化实际应用的前景。
1 数据采集与预处理
1.1 数据采集
本文的实验数据主要来源于国家互联网基础资源大数据(服务)平台[9]以及来源于MaxMind开源数据库GeoLite2[10]的ASN数据。
国家互联网基础资源大数据(服务)平台[9]在互联网基础资源数据的采集和清洗方面具备面向全球互联网范围的主动式数据采集和探测能力,可批量采集结构化业务数据,批量导入半结构化文件数据,实时爬取非结构化网络数据,还可以实时采集被动式DNS数据(解析日志),形成了大数据平台的一体化数据采集及清洗能力。其主动式数据采集系统已具备覆盖2亿域名、超过100万台DNS服务器的深度采集和探测能力,能高效地采集并结构化域名DNS解析数据(以反映域名与IP对应关系的A记录为主,另有CNAME记录、MX记录等其他DNS解析数据),本文中应用的是此域名A记录解析数据库。
1.2 数据清洗
本文使用了国家互联网基础资源大数据(服务)平台2019年7月采集的域名A记录解析数据,域名A记录总数为3.76亿条,其中异常数据主要包括四种情况:查询返回服务器异常SERVFAIL、查询超时、域名不存在和域名无A记录。对异常数据进行清洗过滤后,剩余A记录总数为2.97亿条(含所有.CN和部分.COM等顶级域数据)。本文只选取了.CN域名的A记录解析数据,过滤了其他顶级域的数据,共计1 591万个.CN域名节点、219万个IP节点,以及1 683万条域名解析A记录(域名-IP边)。另外,本文采用GeoLite2开源数据库的ASN数据(选用2019年3月26日的数据)进行IP与ASN的关联处理,并应用开源图数据库HugeGraph[11]进行图数据存储。可视化局部图结构如图1所示,其中已在域名节点处标注上对应域名信息,未标注的节点是与域名关联的IP节点,由图1可知,域名与IP存在着多对多的关联关系。
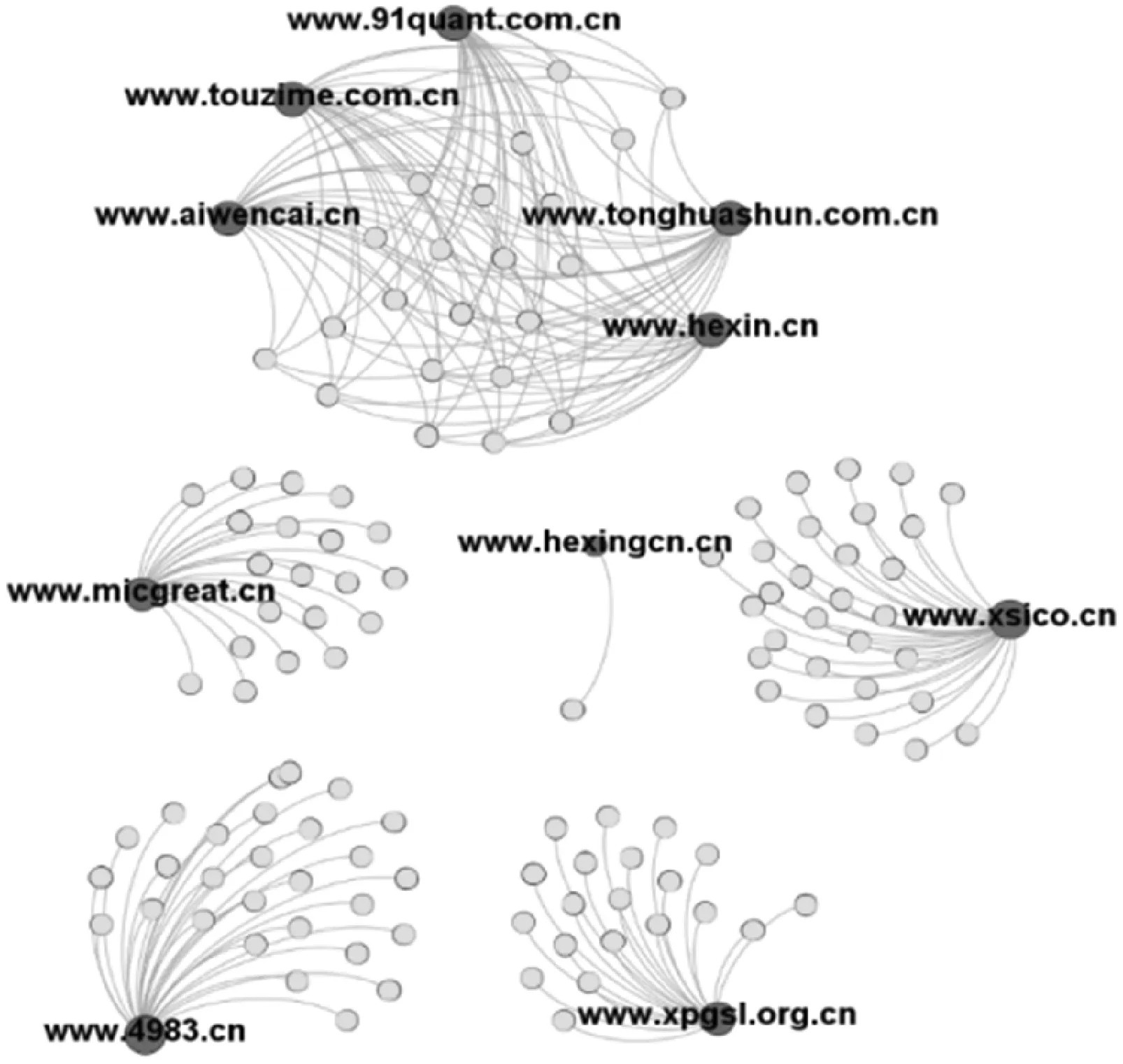
图1 域名解析图(局部)
2 算 法
Khalil等[8]提出的算法中,核心是发现和分析域名之间的全局关联关系而不是局限于对域名局部特征的分析。我们通过主动采集的DNS解析数据和ASN数据构建出域名、IP和ASN之间的全局关联关系,当然也可以通过被动DNS数据或集成其他数据源(如DNS日志和WHOIS记录等)来增强此关联关系的可信度。虽然DNS记录的很多特征可以通过不同方式更改,但是攻击者想要达到攻击目的就必须要把不良网络应用映射到他们可以控制或可以访问的IP上[12]。一般情况下,攻击者会通过频繁注册新域名来规避检测,不良网络应用之间也因此建立起了关联。例如,在针对反病毒威胁生态系统的纵向分析[13]中显示,这些恶意行为中使用的不良网络应用随着时间的推移在整个互联网空间中大规模移动,它们之间共享着许多不同的特征。因此,多个不良网络应用很有可能最终被映射在相同的IP上,同样,多个不同IP也很可能关联着相同的不良网络应用。为了解除它们之间的这种关系,攻击者只能尽可能地减少每个不良网络应用指向的IP数量以及每个IP主机关联不良网络应用的数量,但是这会大大限制攻击者对资源的利用,同时大幅提升了管理成本,很大程度地折损了攻击者的利益。因此,我们认为基于域名和IP之间的关联关系可以提供一种可靠的方法来研究攻击者是如何组织和部署恶意资源的,并进一步帮助我们利用有限的已知不良网络应用去大规模地检测和发现潜在的不良网络应用。
由于与已知恶意域名有强烈关联的域名很可能也是恶意的,因此,给定一组已知的不良域名列表作为种子域名,我们可以根据其与待测域名的关联强度来判断这些域名是否为潜在不良网络应用所使用,但核心问题是如何定义域名之间的这种关联强度。Khalil等[8]提出通过一种简单直接的度量方法来反映不良域名之间的内在关联,如果两个域名都指向相同的IP,则将它们建立连接,构建无向加权图。但其实很多完全没有任何关联的域名也可以使用相同的IP(比如在虚拟主机场景中)。因此,可以先将IP节点按度排序,将度值最高的少量节点作为共享IP池排除,然后再基于上述关联构建反映域名之间全局相关性的加权图,从而不局限于只针对主机或域名本地局部特征所做的分析。当然,在互联网资源的合法管理下,有些域名与不良种子域名之间也会存在着一定的关联,但并不能证明这些域名是恶意的。为了更准确发现不良网络应用,该算法提出了一种基于路径的机制,根据每个域名与已知不良种子域名的拓扑连接来获得其恶意得分,并设定一个恶意得分阈值,若超过该阈值,则认为是潜在不良网络应用所使用的域名。
本文在Khalil等[8]提出的算法基础上进行了以下几个方面的优化:1) 优化种子域名的获取方式。在原有利用VirusTotal API[14]遍历域名关系图中所有域名并将命中黑名单的域名作为种子域名的基础上通过分析种子域名度分布特征,将域名解析图中的域名节点按度值排序,然后取少量TopN的域名节点作为种子域名的补充。2) 优化计算两个域名间关联强度corr的算法。原有算法在计算corr时,针对所有与种子集合有交集的连通图中每个域名,需要分别计算其与各个种子域名之间所有路径中最短路径上经过的所有边的权值的乘积,再取其中的最大值作为corr的值。而优化后算法复杂度只是一个Dijkstra算法的复杂度即O(|E|+|D|log|D|),结合NetworkX和Spark GraphFrame工具,该优化算法在本文数据集上(域名总数千万级)的计算时间由1天缩短至10分钟左右,时间缩短了99%以上,大幅提升了算法性能。3)补充对非连通图内域名节点恶意得分的计算方法,扩大了种子域名的作用范围,对不在连通图中但与种子域名同样有密切关联的域名进行了恶意得分的补充计算,大幅提升了真阳率。
2.1 建立域名关联
2.1.1排除公共IP
Khalil等[8]提出如果两个域名解析到许多相同的IP上,那么这两个域名之间极有可能存在很强的关联。这种关联很有可能表明它们为同一组织所控制。例如,攻击者可能将钓鱼网站部署到其所控制的一组僵尸程序中,用一种或多种传播手段,将大量主机感染僵尸程序,从而在控制者和被感染主机之间形成一对多控制的僵尸网络[15],而这些钓鱼网站将被关联到攻击者所控制的主机资源中,关联到许多相同的IP上。
当然,很多不同的域名也可以合理共享一组IP。例如,为了负载均衡,一个组织可以在一组服务器中同时托管该组织下的几个不同域名。但这不影响我们的结论,因为这些域名仍然还是由同一组织所控制的。如果其中一个域名是恶意的,那么托管在同一服务器上的其他域名也可能是恶意的,因此这种情况下我们的结论依然成立。但在云服务、Web托管和内容分发网络(Content Delivery Network,CDN)中,毫无关联的域名会解析到相同的公共IP池中。这种情况下,共享IP的两个不同域名中当一个域名为不良网络应用所使用时,并不能说明另一个域名也很可能是恶意的。考虑到互联网上有大量的服务提供商,列出所有的公共IP池是不切实际的。因此,针对此场景的干扰,可以通过一个排除公共IP池地址的方案,简单直接地过滤掉大部分公共IP地址,减轻其对算法的影响。
针对我们获取到的域名解析A记录数据,结构化“域名-IP”关联数据,利用Spark GraphFrame图处理库建立反映域名与IP解析关系的图谱(Domain Name Resolution Graph),下文简称RG原始图。如果一个IP关联了大量的域名,那么它很可能是一个公共IP地址,因此我们排除公共IP时对RG原始图中所有IP节点计算度分布情况(如图2所示),分析图数据确定度阈值,将度值大于该阈值(可配置)的IP认为是公共IP地址进行过滤,并从RG原始图中删除,得到新的域名解析关系图(下文简称RG图)。
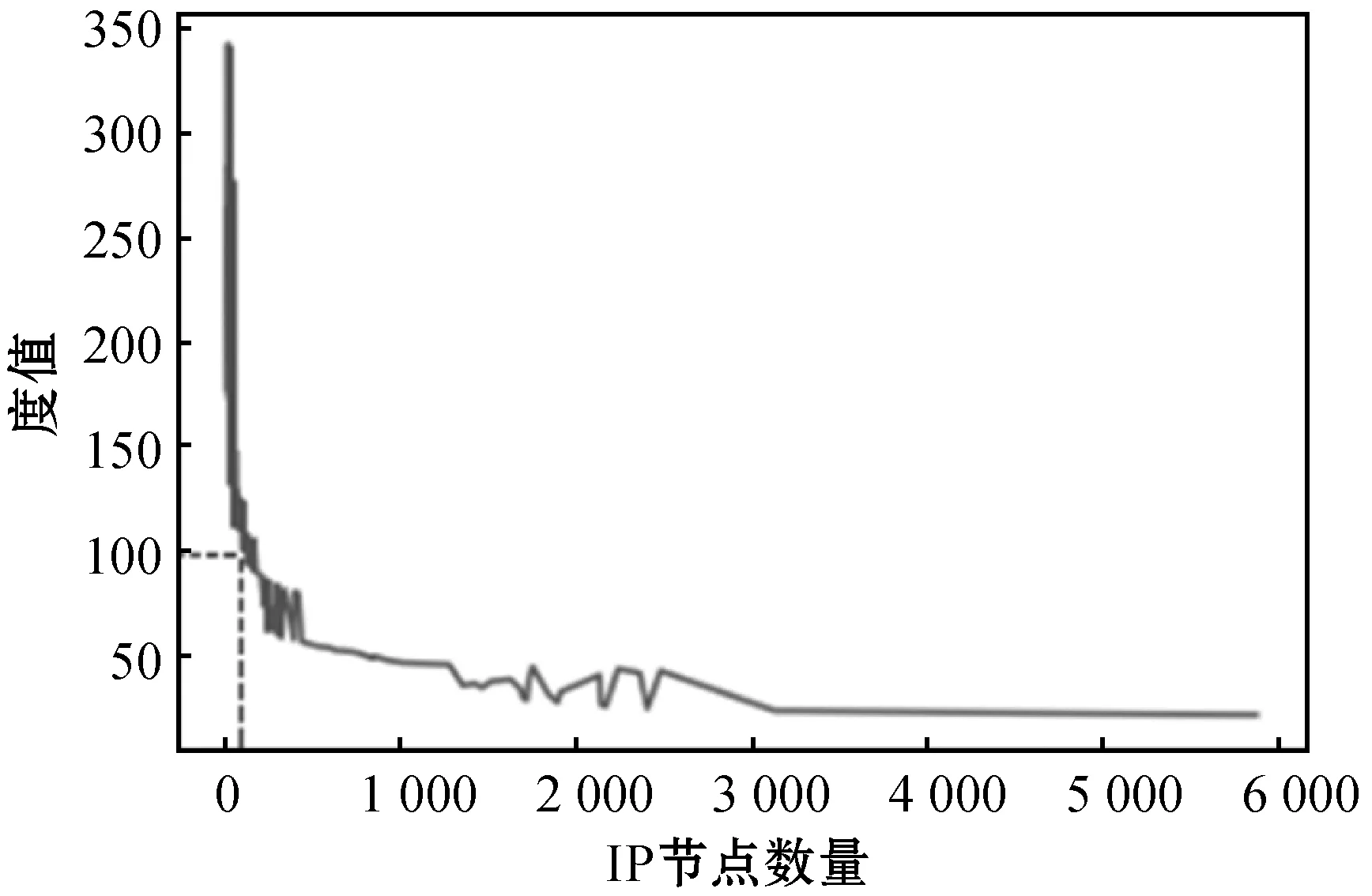
图2 IP节点度分布情况
本文中阈值选择100,即在RG原始图中过滤掉IP节点度大于100的点(累计9 103个IP节点),认为其为公共IP池中的IP。排除后,RG图中剩余1 591万个域名节点、218万个IP节点及883万条边,可以看出本文的数据集节点之间关联关系总数少于节点数,节点之间具有一定的关联关系但并不紧密,经实验验证,Khalil等[8]提出的算法在本数据集上表现效果不佳,经过本文算法改进后得到了较好的效果。
2.1.2构建域名关系图
Khalil等[8]提出,在构建域名关系图时,关键在于如何定义域名与域名之间的关联强度,以及如何确定与已知不良网络应用没有直接关联关系的域名的恶意程度。一般来说,如果两个域名解析到同一个IP上,那么它们就存在一定的关联。显然,如果两个域名共享的IP越多,或者两个IP关联的相同域名越多,那么它们之间存在的关联关系就可能越强。
由于两个域名解析的相同IP越多,它们的关联越强,权重越大。当两个域名解析的相同IP数量足够多时,关联足够强,此时添加额外的相同IP对关联程度不会产生太大的影响,而当IP数量较少时,增加额外的相同IP对关联强度的影响较大,因此对关联程度的影响也较大。针对域名之间的关联关系定义如下:2.1.1章节得到的RG图是域名与IP之间的无向关系图,对该图中任意两个有相同IP交集的域名d1和d2求权重,定义如式(1)所示。
对任意不相同的两个域名,计算其IP交集的个数|ip(d1)∩ip(d2)|,设置阈值t,过滤掉IP交集个数小于t的域名。将所有满足条件的域名d1和d2以及它们之间的边(权重ω)加入域名关系图(Domain Name Graph),下文简称DG图,构建得到该无向加权图。当两个域名d1和d2不共享任何IP时,根据式(1)可知ω(d1,d2)=0。因此,当d1≠d2时,ω(d1,d2)取值范围在0至1之间。
2.1.3关联ASN信息
为了进一步增强域名关联关系的有效性,降低公共IP池地址对算法的影响,Khalil等[8]提出在构建域名关系DG图计算边权值时,考虑到共享IP的多样性,可进行ASN信息的关联,而不仅仅是计算两个域名共享IP的数量。虽然一个服务提供商可以将两个不相关的域名同时映射到公共IP池中,但它们同时映射到两个或多个服务提供商公共IP池中的可能性很小。因此,本文利用IP所属的ASN信息来近似地识别来自不同服务提供商的IP。当然,服务提供商有可能拥有来自于多个ASN的IP,但即使两个不相关的域名仅属于单个服务提供商,它们也仍然可能是有关联的。但依据实验结果显示,这种情况是罕见的,对本文算法有效性的影响有限。除了关联ASN外,还可以使用WHOIS的IP记录来识别属于同一提供商的IP。但众所周知,WHOIS记录因为缺乏标准格式和异构的信息源往往存在噪声,并且信息相互冲突。综上所述,本文选择在构建域名关系图时引入ASN信息,对式(1)进行改进以更有效地映射域名与域名之间的关联强度。
具体来说,给定一个IP集合I,用asn(I)表示I中的所有IP所属的ASN集合,定义了对域名关系图中任意两个不同域名d1和d2之间权值ω(d1,d2)的计算公式,其中,ip(d)表示域名d解析到的所有IP的集合,以此更新DG图如式(2)所示。
(2)
利用域名、IP和ASN之间的关联关系,通过式(2)计算域名之间边的权值,并构建DG图,示例如图3所示,(a)为反映域名、IP和ASN之间关联关系的域名解析图,(b)为经过式(2)处理后建立起的反映域名与域名之间关联关系的无向加权图。
(a) 域名解析图(RG图)
2.2 获取种子数据
2.2.1获取已知不良网络应用所使用的域名
本文一个重要思路是用尽可能少的种子域名发现尽可能多的不良网络应用,而所谓“种子”就是已经确定为不良网络应用所使用的域名。通过考察多个不同渠道获取的不良黑名单(包括VirusTotal API、Bambenek Consulting、Xsec-ip开源库、360 netlab DGA数据库、Badips等),考虑到黑名单涵盖范围、更新频率、数据获取方式及稳定性等方面的因素,本文选择利用VirusTotal API查询DG图中所有域名,若域名命中任意一个黑名单,则认为其为不良种子域名。将获取到的已知不良域名列表定义为S集合,取较小比例(5%~30%)作为种子域名供快速发现不良网络应用,剩余大部分不良网络应用供算法评估(计算假阳率)使用。
2.2.2补充种子域名数据
由于VirusTotal域名检测网站核查的恶意范围有限,且数据集中域名关联程度有限,为加大种子域名在检测不良网络应用时发挥的作用,本文对已获取到的恶意种子域名在域名解析图(RG图)中的度分布情况进行了分析。如图4所示,RG图中度值较高的域名数量较少,度值较低的域名数量较多,符合幂律分布现象,且已知不良网络应用所使用的域名的度值分布集中在虚线框区域,即已知不良域名具有度值较高的特点。因此,本文提出种子域名提取的补充算法,将RG图中的域名节点按度值排序取TOPN(N值可配置)作为补充种子域名合并到种子数据列表中,以增加算法的普适性,提升算法在发现潜在不良网络应用时的命中率。

图4 种子域名(已知不良)度分布情况
2.3 计算恶意得分
利用基于图路径的算法,通过计算与种子域名密切关联的各域名恶意得分的方式来评估和发现潜在不良网络应用。Khalil等[8]认为DG图是由多个连通图组成,在计算可疑域名的恶意得分时,首先遍历DG图得到所有连通图的集合,再筛选出与种子集合S有交集的连通子图,对该连通子图中的所有域名d计算其恶意得分mal(d,S),若恶意得分超过阈值m,则将该域名d加入不良集合。但这样忽略了连通图之外的域名与种子域名同样存在有密切关联的可能,因此,本文在此基础上提出对连通图外域名节点的恶意得分的计算方法。
具体算法如下:
1) 遍历DG图中所有连通图,若与种子域名集合S有交集,则遍历该连通图中的任一域名d:

(2) 利用基于图路径的机制定义反映域名d与种子域名Si之间关联强度corr(d,Si)的计算方法:通过Dijkstra算法计算加权图中域名d与所有种子域名Si之间所有路径中最短路径的权值ω(d,Si),即两个节点之间关联最强的一条路径上的权值之和,对该数据取倒数并进行离差标准化处理,归一化至[0,1],即corr(d,Si)值越大表示关联强度越大,且该值取值范围在0至1之间。
(3) 将域名d到S集合中所有种子Si的关联强度corr(d,Si)列表进行倒序排序,用S1表示与域名d关联强度最大的种子,则corr(d,S1)表示该种子与域名d之间的关联强度,用mal(d,S)表示域名d的恶意得分,则计算公式如下(其中n表示种子数):
mal(d,S)=corr(s1,d)+
2) 本文提出对于连通图之外的域名节点,从DG图中分析获取所有与种子数据有直接关联的边,按域名分组,将其与该域名有关联的所有种子边的权值倒序排序作为corr的值,并按式(3)计算其恶意得分,并补充到结果中。
3 实验与评价
通过三大评价指标(真阳率、假阳率和发现数量)对算法效果进行评估,具体指标含义定义如下:
真阳率(True Positive Rate,TPR):实际为不良域名并被预测为不良域名的比例。将2.2节获取的种子域名随机取一定比例作为算法中使用的种子集合A,剩余大比例种子集合B作为真阳率的验证数据集,定义真阳率P计算方法如下:
假阳率(False Positive Rate,FPR):实际为正常域名但被预测为不良域名的比例。在计算假阳率时需要预先得到一个已知良性域名的白名单,本文获取白名单的方式是从Alexa和Domcop网站取域名排名TOP 2万的域名作为白名单。定义假阳率F的计算方法如下:
(5)
发现数量:通过少量已知种子域名快速发现的疑似不良网络应用所使用的域名的数量。
3.1 参数对结果的影响
如前文所述,本文实验数据集中的域名通过白名单筛选出已知良性域名,并通过黑名单方式标注出已知不良网络应用所使用的域名,具体分布情况如表1所示。
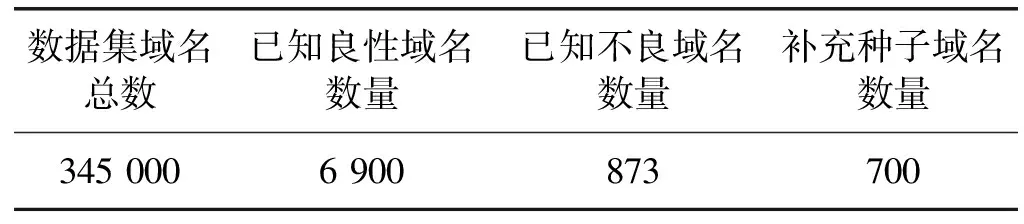
表1 数据集域名属性分布情况
3.1.1种子数量取值的影响
由于本文算法的核心是通过尽可能少的种子域名快速发现尽可能多的不良网络应用所使用的域名,实验中将已知不良域名数据按一定比例分为两部分,一部分作为种子域名数据用于发现大量疑似不良域名;另一部分作为验证数据集,用于计算真阳率。为进一步分析种子数量对真阳率和假阳率以及对不良域名发现数量的影响,本文将种子域名数量分别设置为已知不良域名总数的5%~50%,在种子域名数量的不同取值情况下分别预测得到的疑似不良域名,并统计其真阳率、假阳率和发现数量三个指标,如图5和图6所示。
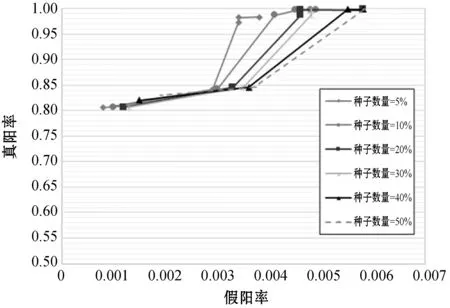
图5 种子数量对真阳率和假阳率的影响
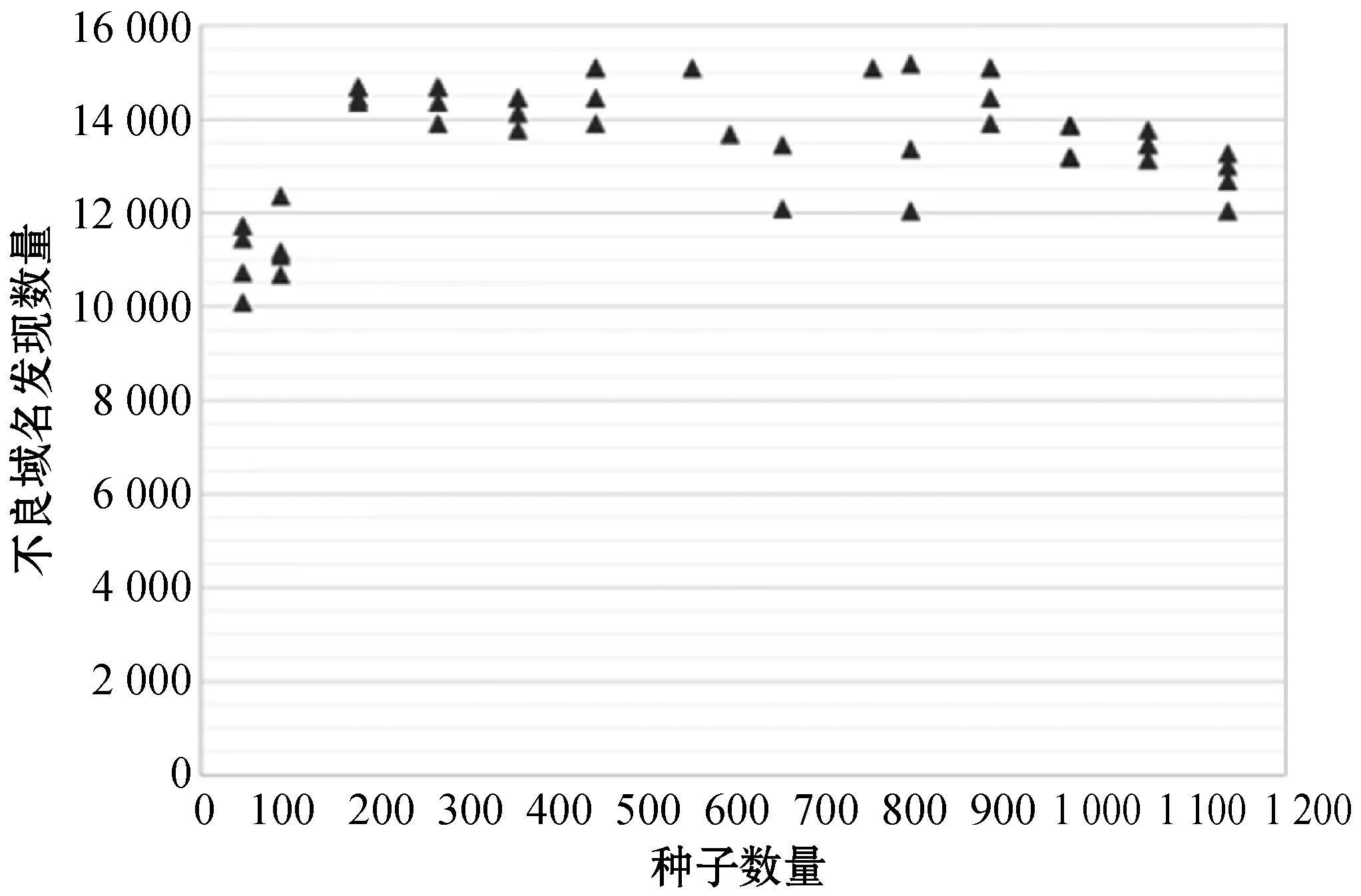
图6 种子数量对发现数量的影响
由实验结果整体来看,由图5可知,不同种子域名数量的取值对真阳率和假阳率的影响不大,当恶意得分阈值相同时,种子域名数量越大得到的真阳率越大但假阳率也越大,综合来看当种子域名数量取已知不良域名总数的10%~30%时,均可得到较大的真阳率(大于99%)和较小的假阳率(小于0.5%)。同时,由图6可知,种子域名数量对不良网络应用发现数量有一定的影响且符合幂律分布,当种子数量取值为种子总数的10%~50%之间时对算法影响差别不大,均可以获得较高的发现数量(1.5万左右)。因此,我们可以得出结论,即使使用数百个已知恶意种子域名,本文算法也可以发现上万个大量的潜在不良网络应用。
3.1.2恶意得分阈值的影响
本文在种子数量相同(取已知不良域名总数的10%)的情况下,分别设置恶意得分阈值在[0.50,0.75]之间取值(取值间隔为0.05,共6组取值),计算每组实验下的真阳率和假阳率,考察恶意得分阈值的取值对算法效果的影响。由于种子域名是随机选取的,固定种子数量的情况下,选取的种子依然不同,为保证实验的可靠性,我们在每组恶意得分阈值的设置下都随机进行6次实验(即每条折线上有6个数值结果)。如图7所示,当恶意得分阈值大于0.7时,可以获得极小的假阳率(小于0.4%)但真阳率相对较小(小于85%);而当恶意得分阈值的取值在[0.50,0.65]之间时,可以在得到极大的真阳率(大于99%)的同时获得较小的假阳率(小于0.5%),且在此区间内时恶意得分的影响不大。
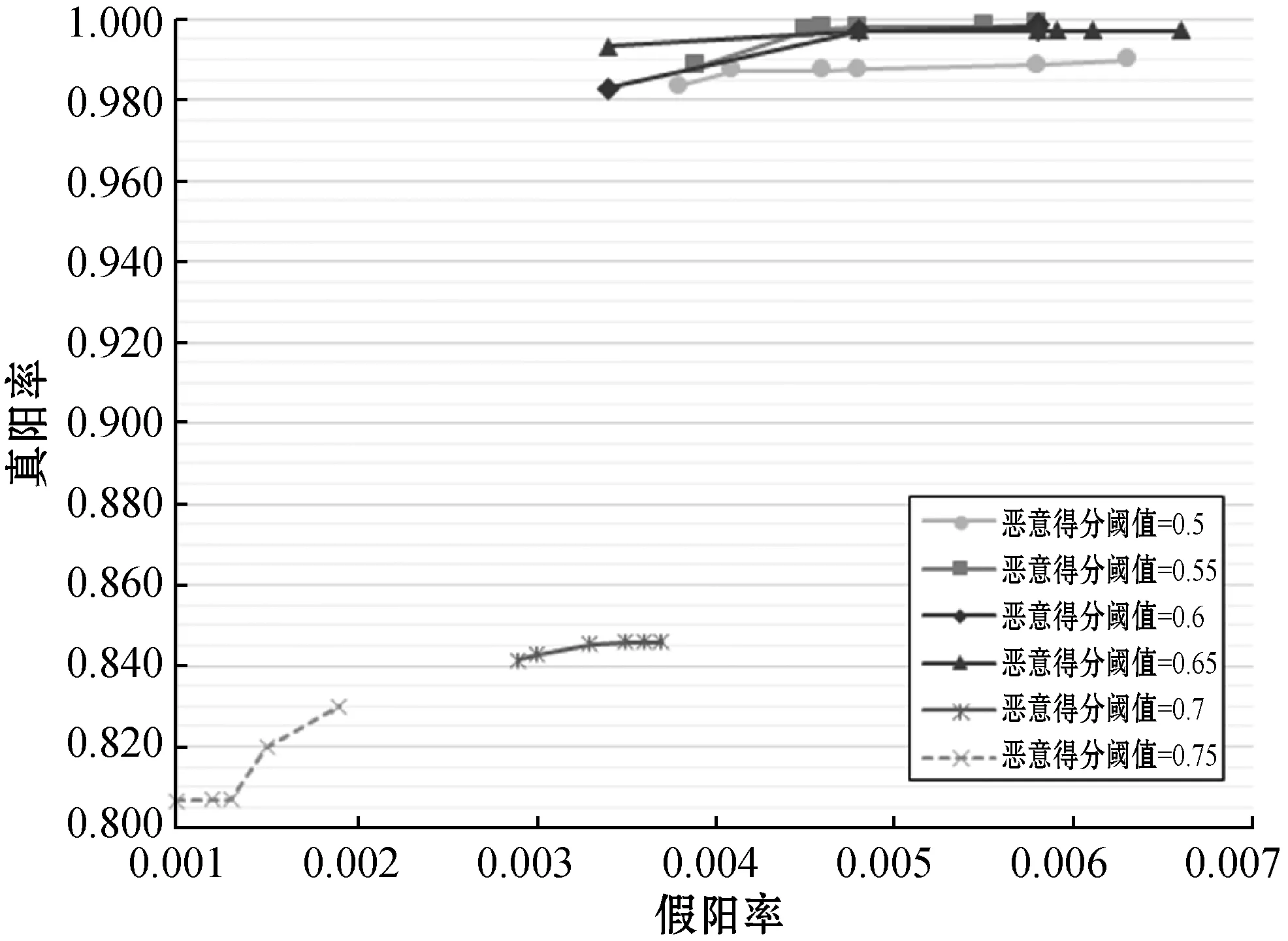
图7 不良得分对算法效果的影响
综合上述的实验结论可知,随着种子数量的增加,真阳率越来越大但假阳率也随之增大,同时,随着恶意得分阈值的增大,假阳率越来越小但真阳率也随之明显减小。为取得最佳算法结果即获取最大真阳率和最小假阳率,当恶意得分阈值取值在[0.55,0.65]之间且种子数量在种子总数的[10%,30%]之间时,可以获得算法的最佳效果。
3.2 算法优化前后效果对比
如第2节所述,本文对Khalil等[8]提出的算法进行了优化,经实验验证,算法效果明显提升。本文在固定恶意得分取值为0.5且种子数量为已知不良域名总数的10%的情况下,分别对优化前和优化后的算法进行6组实验(每组随机取固定数量的种子域名),计算其真阳率、假阳率和发现不良域名数量,得到图8。图8中两条折线分别代表了本文算法与Khalil等[8]提出的算法对比的真阳率和假阳率的变化情况,显然本文算法的真阳率得到明显提升的同时,假阳率也保持在小于0.7%的较小范围内,且受随机种子的选择影响波动极小,而优化前算法在本数据集中效果不佳且受随机种子的选择影响波动较大。图8中的柱状图显示本文算法在不同随机种子的6组实验中发现疑似不良网络应用的数量与原算法的对比情况,可以明显看出算法优化前只能快速发现小于1 000个左右域名,而算法优化后可以检测到1.5万个左右疑似不良网络应用所使用的域名。
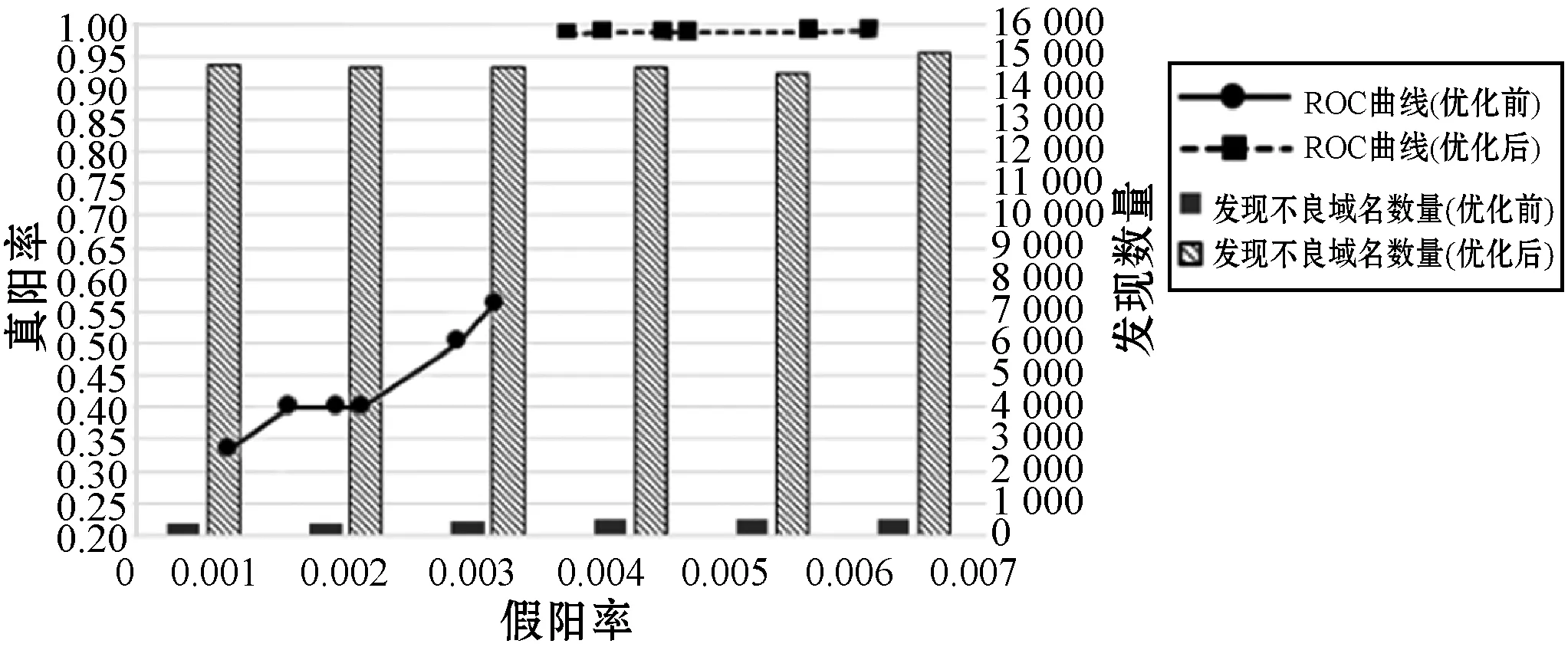
图8 算法优化前后效果对比
4 结 语
本文提出一种基于图数据分析的不良网络应用快速发现的优化算法,一方面能更加高效地快速发现疑似潜在不良网络应用,另一方面能在获得较低假阳率的同时确保得到极高的真阳率。算法具有普适性和较高的可扩展性,可以根据种子类型的不同(如赌博类、涉黄类、钓鱼类、僵尸类等)而挖掘发现不同种类的疑似不良网络应用,在不良网络应用快速检测和发现方面具有较好的实用价值和大规模工程化应用意义。尽管在本文中我们关注于利用域名、IP和ASN的全局关联来发现潜在的不良网络应用,但我们并不主张放弃现有工作中提出的局部特征,我们的目标是提供另一个维度来检测和快速发现不良网络应用,本文提出的方案可以与基于局部特征的算法集成起来进一步提高不良网络应用发现算法的效果。例如,可以将每个域名根据过去研究工作中识别出的一些本地特征进行初始评分,然后再应用本文算法通过已知不良网络应用作为种子快速发现潜在的大量未知不良网络应用,为后续发现算法研究提供一个非常稳健而准确的方案。同时,本文算法还可以与基于分类器的算法相结合,将分类器的输出作为获取种子域名的初始途径,有效提高算法整体的准确率,为未来的深入研究工作提供理论和实践基础。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中国-东盟博览(政经版)(2020年7期)2020-07-30
当代陕西(2019年15期)2019-09-02
中国交通信息化(2019年3期)2019-06-18
中国教育网络(2018年12期)2019-01-18
计算机与网络(2018年10期)2018-02-15
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
声屏世界(2015年5期)2015-02-28
互联网天地(2012年6期)2012-03-24
