
面向物联网的自适应可靠路由机制研究
2022-12-03 02:01郎登何
计算机应用与软件 2022年11期
郎 登 何
(重庆电子工程职业学院人工智能与大数据学院 重庆 401331)
Bidirectional processing
0 引 言
物联网(Internet of Things,IoT)是一种新兴的信息通信技术范式,支持分布式计算和集中式计算两种计算方式[1]。同时,IoT也是一种无边界智能网络,其中海量传感器、执行器和各种通信设备相互连接,并且可以采用复杂协同方式执行各种应用任务。随着IoT的不断发展,其网络架构呈现一种复杂分布式异构网络特征[2]。同时,IoT已经得到研究者和研究机构的密切关注,如智能家居、智能电网、智能交通和智能健康等领域[3]。
近年来,IoT路由方面的研究内容主要集中在服务路由选择、路由节点能耗和安全路由机制等方面。考虑网络中新相遇节点分组机制导致路由选择精度低的问题,文献[4]提出了一种物联网高效服务模型,该方法通过分组交换增量计算出传输概率,同时采用Epidemic机制产生节点约束概率,从而组建相遇节点的数据分组机制。对于IoT感知节点路由选择来说,能量受限是制约IoT节点传输效率的一个瓶颈之一,因此,陶亚男等[5]提出一种基于改进猫群算法的路由优化策略。该方法引入备份思想,在综合考虑节点剩余能量方差、节点负载和节点距离等条件下,保证数据传输实时性。与此同时,开放IoT环境下,IoT的路由机制容易受到恶意丢包攻击,张光华等[6]基于RPL协议提出一种具有信任机制的安全路由方法,该方法解决了网络中非法入侵因素导致的恶意节点误判断问题。但是,这些IoT路由方面研究均以无线传感器网络为数据传输背景,其网络的节点和路由节点通常采用电池供电方式,具有能量受限和资源受限等特点。当前IoT发展阶段,无线传感器网络已经不是IoT组网的主要组网方式,在部分智能家居和智能健康领域,传感器主要通过手机或者智能网关将数据传输到云端或者其他计算单元中[2],而这些智能网关多是固定电源供电。在这些条件下,网关设备不存在感知节点路由选择[4]、节点能量受限[5]和节点的路由安全问题[6]。因此,IoT智能网关路由策略性能成为制约新形势下IoT数据转发效率的一大瓶颈。
IoT智能网关路由策略通常采用自适应负载均衡技术[7]和多维通信技术[8],以解决异构IoT网络数据传输问题,同时保证海量高采样率IoT传感器设备流数据的高效转发和低延迟特性。文献[7]提出了一种面向IoT的自适应负载均衡路由技术,解决了并行机会路由场景中数据从源网关到互联网的延迟问题。而对于异构IoT来说,文献[8]提出一种三维异构IoT路由决策,降低了异构IoT的能耗和端到端延迟。此外,为了解决节点动态流量变化对网关造成的路由性能不佳问题,王玉珏等[9]提出一种最大化网关流量的IoT路由策略。虽然以上文献已经对路由传输延迟、能耗和流量控制等方面问题进行了研究,但是这些IoT网关路由策略只具备单项处理能力,无法根据数据特性实现双向路由处理,这对于IoT应用来说至关重要,许多场景需要双向数据传输,也就是一方面需要传输数据到云端,另外一方面IoT节点需要等待云端反馈控制信息。因此,急须开发一种自适应的双向处理路由策略。
因此,本文提出一种自适应双向处理路由策略,用于双向处理条件下的IoT物联网路由网关。该策略将路由信息转发表的更新操作交由节点本身处理,且只存储对于节点处理消息有用的信息数据。这些有用信息通常包括消息源节点和目的节点、输入和输出链路、当前消息切换值(Handover Number,HN)及路由表[8,10]。除此之外,对收集到的消息进行观察和分析,同时结合反向学习和强化学习模式来估计数据包到达目的节点所需要的时间。
1 相关工作
物联网作为一种新型的网络范式,涉及范围涵盖端、边和云,包括终端传感设备对数据的产生和监测、边缘交换转发设备对数据的转发、云端控制器对数据的处理过程。智能网关路由策略是端、边和云数据交互的重要传输机制。
文献[7]表示,使用传统的路由技术将数以百万计的物联网设备连接到互联网,会导致网关拥挤和过载,导致物联网网络吞吐量下降。为了提高吞吐量,提出了将多种无线技术用于并行数据传输,即并行机会主义路由(Parallel opportunistic Routing,PoR)。然而,在PoR中,从源网关到Internet的数据始终遵循相同的路径。这会导致某些网关出现拥塞,进而影响吞吐量。因此,文献[10]提出了一种自适应和负载均衡路由技术,称为自适应路由技术,利用多技术和负载均衡器,通过在整个网络上分配负载来最大化物联网网络的吞吐量。
文献[8]针对路由机制存在数据传输效率低、能耗高、物联网端到端延迟差等问题,建立了三维和通信模型的基础,并提出了基于蜂窝地址(Cellular Address,CA)的三维异构物联网路由决策机制。首先,CA建立了基于元胞自动机和节点平均接收信号强度的网络节点数据转发准则;其次,CA通过IPv6地址实现路由优化和控制;最后,通过蜂窝地址解决路由决策机制。仿真结果表明CA的包传送率在82%到95%之间,路由消耗率在20%到35%之间,平均端到端延迟为20毫秒,不仅保证了物联网通信性能指标,而且提高了网络的可靠性。
文献[10]为了更好地利用物联网基础设施,考虑在物联网网络中动态发现和组合物联网相关的功能,以执行新的或动态出现的任务。为了实现这一目标,开发了一个基于语义的物联网服务发现路由协议。在路由协议中,为了减少路由所需的空间,每个节点都维护一个带有“伸缩视图”的路由表,即关于直接邻居能力的更精确的信息,以及对更远的邻居能力的摘要。定义了一个能力本体,设计了一个基于本体的能力汇总算法,实现了伸缩视图的概念。同时还设计了一个本体编码方案,以进一步减少路由的内存需求,同时实现功能总结。解决方案能够减小路由表的大小,适用于内存有限的物联网设备。此外,实验结果表明,与现有的基于语义的路由算法相比,文献[8]方法可以显著降低网络流量和IoT功能查找的延迟。
文献[11]发现在物联网网络中,需要一个领导者节点,例如找到能量最小的节点或位于网络的最左侧。对于这类应用程序,算法必须具有鲁棒性和容错性,因为如果节点发生故障,很难甚至不可能进行干预。如果这个节点是领导者,这种情况可能是灾难性的。于是提出了一种基于树路由协议的新算法。它从根节点开始,通过洪泛的过程,以确定一棵生成树。在此过程中进行路由操作。如果两个生成树相遇,那么路由效果最佳的树将继续其进程,而其他树将停止。从而得出路由主宰树,它的根则作为领导者。该算法可以在任何节点可能发生故障和网络断开的情况下工作,能耗降低率可达85%以上。
尽管存在大量的IoT路由研究工作,但这些工作只具备单向处理能力,无法针对网络的变化进行有效反馈和灵活应对,特别是传感器流数据的双向自适应处理,因此也无法适应物联网中大量设备和数据的动态变化。
2 自适应可靠路由机制
本文提出的机制主要包括三部分:首先通过反向学习建立初始化的路由自适应模型;其次通过强化学习对初始化模型进行修正,使其支持可靠性;最后结合这两种学习模式实现分布式路由的自适应与可靠性传输。
2.1 反向学习初始化
给定任意一条链路LI,经过它的数据包所携带的HN数值能够被用于估计从源节点S到当前节点X所需的最短时间。于是,反向学习机制利用这个情况,同样也可以利用数据包所携带的HN数值来估计从当前节点X到源S的最短时间。
以LI作为输出链路,最短时间可以表示为T(S,LI)。随着网络时间的推移,节点X对于到达S的最短时间的预估已经不再准确,使用T(S,LI)old表示,那么基于反向学习技术,更新的过程可以表示如下:
T(S,LI)new=T(S,LI)old+k[HN-T(S,LI)old]
(1)
可以看出,影响数据包到达目的节点的最短时间的因素为参数k。通常,0≤k≤1。考虑到实际情况,需要对式(1)进行修正。于是引入两种类型的k参数k1和k2,其中:k1表示模型的“学习因子”,用于降低T(S,LI);k2则表示“遗忘因子”,用于提高T(S,LI)。在这里其实存在着更为复杂的统计预估方法,但这些方法通常需要每个路由表条目上的额外信息,从而对系统造成额外的开销。
然而,由反向学习所建立的模型通常需要使用间接信息,但是这种间接信息通常是不足的,这种情况往往可能会导致出现“乒乓效应”。以节点A和B为例,数据包目的节点为C,存在这样一种情况,A以为B距离C最近,而B同样以为A距离C最近,最终,数据包会在A和B之间来回传递,直到达到最大的切换次数Δtmax,从而终止。接下来对这种模型进行进一步的修正。
2.2 负增强学习修正
“乒乓效应”是反向学习技术的主要缺陷之一,它可以通过观察数据包处理过程中所采用的信息结构来进行判断。通常,当LI=LO成立的时候,就会发生这种“乒乓效应”。这种判断条件可以通过周期性的节点输入输出链路监测来保证。在此基础上,再采用负增强学习技术来对其进行修正和增强。
具体而言,负增强学习通过设置相应的惩罚机制来对反向学习进行修正。当任意节点X上存在LI=LO的情况时,进行以下修正操作:
T(D,LO)new=T(D,LO)old+2ΔTL
(2)
其中:T(D,LO)new和T(D,LO)old分别表示反向从目的到源所需的最短时间。那么根据式(2)对节点X上的路由信息表条目中的属性进行修改。将信息块中的特殊信号位(通常为0)设置为utility,并将信息返回给LO。如果LO上存在一个为utility的信号位,那么首先将其重置为0,然后对路由表进行如下修改:
T(D,X)new=T(D,X)old+2ΔTL
(3)
式中,ΔTL表示数据包通过当前链路所需要的时间长度。尽管对路由模型进行了修正,负增强学习在非对称惩罚的情况下的路由效率较低。
2.3 双向自适应机制
鉴于反向学习初始化模型和负增强学习修正技术彼此之间的优缺点,本文将二者进行融合,在保留它们有效特性的同时,抵消它们的缺陷。
根据式(1)的定义,显然在将“遗忘因子”k2设置为0的情况下,可以得出比较好的效果,原因在于k2的值和路由表条目数量成正比。这种融合情况下的技术,本文将其称之为双向自适应机制。一方面,通过使用减少路由表条目的反向学习方法来纠正负增强技术所导致的过度补偿,从而支持对新链路或者修复链路的自动化适应过程;另一方面,通过使用负增强技术增加路由表条目,从而提供对受损链路或者节点的直接适应规则,最后消除反向学习的错误信息问题。具体而言,如果来自于源节点S的消息数据包沿着链路LI到达节点X所花费的时间比从节点X到达S的预估时间T(S,LI)要小,那么,需要按照以下规则更新T(S,LI):
T(S,LI)new=min[HN,T(S,LI)old]
(4)
另外,如果路由算法为任意数据包所选择的输出链路LO和输入链路LI相同,则调用负增强规则,如式(2)和式(3)所示。双向自适应机制的实现同样还需要在每个消息块中设置一个额外的标志位。一旦发生“乒乓效应”,该标志位就会被设置为unity。此时,假设节点Y需要处理一个目的节点为D的数据包,使得LI=LO=X,那么,T(D,X)递增2个单位。在将标志位设为unity后,还需要将反馈消息发送回节点X。至此,重新检测标志位状态并将其重置为0,那么T(D,Y)同样递增2个单位。
2.4 时间复杂度分析
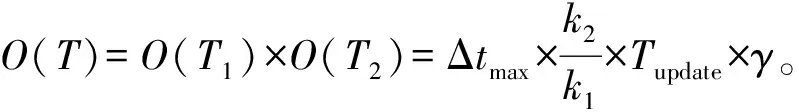
3 仿真实验与分析
3.1 实验参数设置
仿真实验拓扑基于NREN网络(如图1所示),具有1 157个节点和2 930条边,符合物联网规模的特性。1 157个节点分为两种类型,其中300个节点作为目的节点,857个节点作为源节点。源节点作为IoT数据传感输入端,接收传感器采集的数据流,目的节点作为数据流的终点,并每接收1分钟数据,向源节点反馈数值信息平均值。
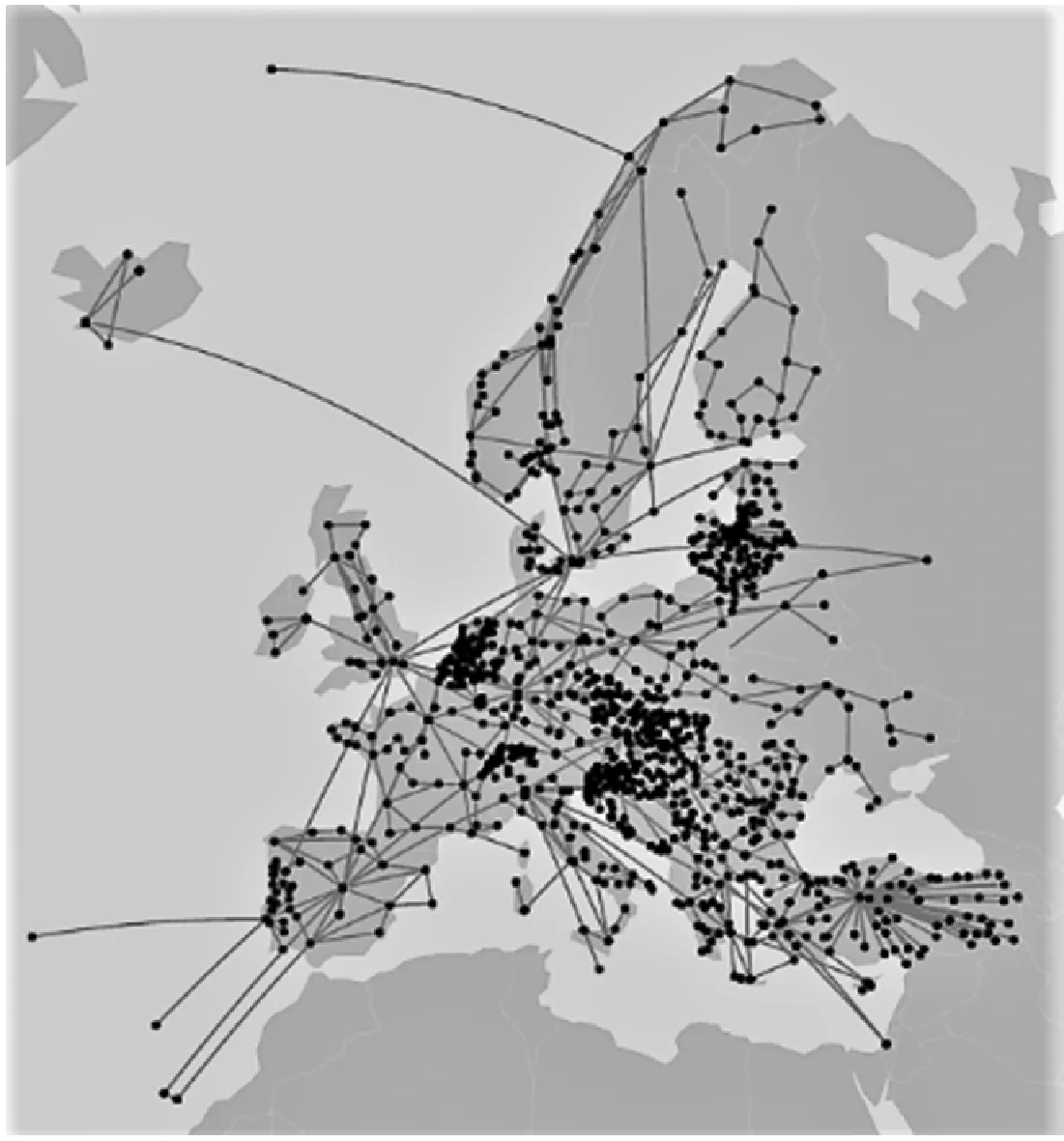
图1 NREN拓扑
为了使测试更接近实际的IoT路由环境,使用公开数据集MIMIC-III Waveform Database中的传感器数据作为本文的IoT流数据源。该数据库包括22 317条波形记录和22 247数值记录,其中波形记录包含一条或者多条心电信号、连续动脉压信号、呼吸信号和光电容积脉搏波信号等;数值记录包含心率、呼吸率、血氧和动脉平均压等数值数据。其中,每个节点配置为单核处理器,队列初始化为空,数据流的到达服从泊松分布。不同节点的处理速率不同,均服从均匀分布。
对于所有的实验情况,将“学习因子”k1设置为0.75,而“遗忘因子”k2则设置为0.25,从而模拟实际情况下的网络和模型的学习情况。
3.2 评价指标与对比机制
为了对本文提出算法进行评估,本文实现了三种先进的IoT路由策略进行对比分析,这三种先进的IoT路由策略分别为基于语义的IoT路由协议(算法1)[10]、最佳拟合路由策略(算法2)[12]和最大化网关流量的路由策略(算法3)[9]。此外,采用路由表条目数量和信息交付率等两个评价指标作为本文对比方法的评价指标,并在讨论非故障链路条件下和故障链路条件下的信息交付率。
3.3 实验结果与分析
3.3.1路由表条目数量对比
路由表条目数量是衡量路由算法效率的重要依据之一[10]。首先,在同等实验条件下,本文实现了四种不同方法(包括本文提出的方法和三种对比方法)。图2所示为四种方法的平均路由表条目数量对比。其中,本文假设在没有流量的时候路由表条目为空,即对于流量数为0时,对应的平均路由表条目数也为0。通过观察路由表条目数量的变化,可以得出一种路由算法是否能够适应当前网络状态的变化。图2表明四种算法在网络流量增加的条件下,对应的路由表条目也随着增加。其原因在于流量与负载是呈现正相关趋势,流量增加路由条目也会随之增加,以适应更多的流量种类。
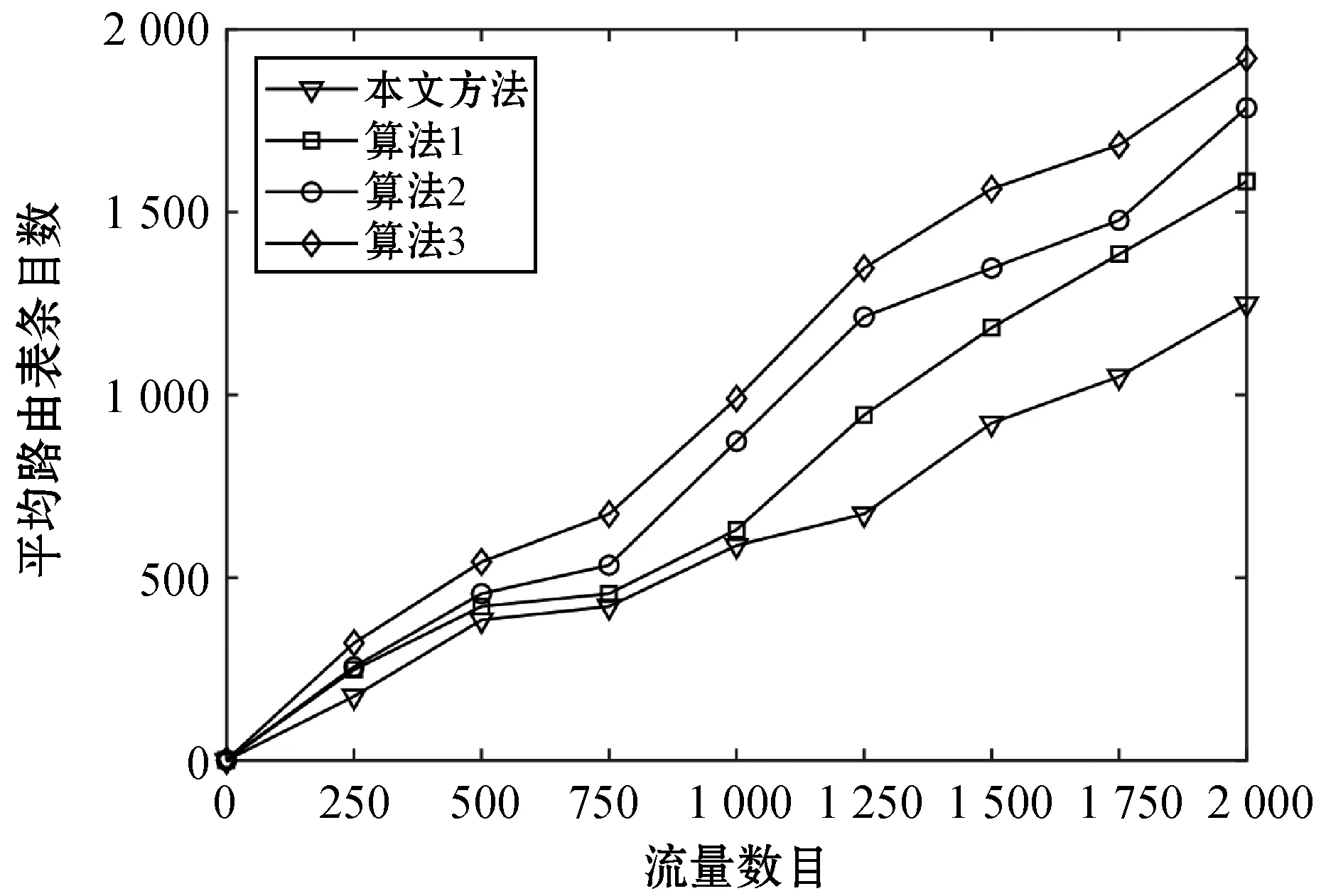
图2 路由表条目数量
如图2所示,相比其他三种算法来说,本文算法所需的路由条目数量最少,而算法3的路由表条目最多。一方面,这是由于本文采用了双向自适应机制,可以根据网络状态来动态获取当前网络中最佳的路由表条目数量;另一方面,本文采用了双向适应和负强化学习策略动态修正最短时间估计,从而保证了本文方法对各种网络场景的适应能力。与此同时,算法1为了保证低延迟特性,牺牲了部分路由表效率性能,增加了除了直系邻居以外的所有路由表条目数量[10]。而算法2是基于最优拟合遍历的路由策略[12],需要提高路由表条目数量来保证路由精度。对于算法3而言,它采用大流量节点构建路由表,但是本文的泊松分布输入条件下,某些一类节点会有较大流量出现,从而导致这些节点路由表数目庞大[9]。综上,在相同网络规模和实验条件下,本文方法具有最低的路由表数量,说明本文提出的路由策略对网络的自适应能力更佳。
3.3.2无链路故障条件下信息交付率对比
为了验证本文算法的可靠性,本文采用信息交付率作为验证路由性能的指标,它也是路由信息交付准确率的一种重要指标[10]。本文中用小数表示,范围为(0,1]。在无链路故障条件下,测试了四种算法的信息交付能力。
如图3所示,本文算法在流量负载增加的情况下,信息交付率可以保持稳定,并未出现断崖式降低或者持续下降的问题。在流量负载从250增加到2 000的情况下,本文算法仍然能保持稳定的信息交付率,平均信息交付率约为0.91。对于其他三种算法而言,在小流量负载情况下(250到500),算法1与本文算法信息交付率相差不多(平均信息交付率分别为0.96和0.94),而算法2和算法3信息交付率相对较低(平均信息交付率分别为0.91和0.88),特别是在负载为500的条件下。对于大于750的流量负载条件来说,虽然所有算法的信息交付率均逐渐降低,但是本文算法均保持在0.86以上,平均信息交付率为0.90,而算法1、算法2和算法3的平均信息交付率仅为0.79,0.74和0.62。以上情况的主要原因在于本文算法信息交付率可以通过负强化学习不断修正相关参数,从而达到自适应的策略,保持信息交付率的稳定性和可靠性。同时,其他三种算法无反馈机制参与路由决策,无法根据网络负载情况动态调整路由策略。相比较而言,算法1可以在小流量范围内提供高信息交付能力,但是对于大流量负载来说,无法提供可靠的路由传输,这是因为该方法以直接邻域为优先策略,较远节点出现大流量负载无法及时动态调整。综上所述,本文算法可以保持可靠的信息交付能力,提供高信息交付率的路由策略。
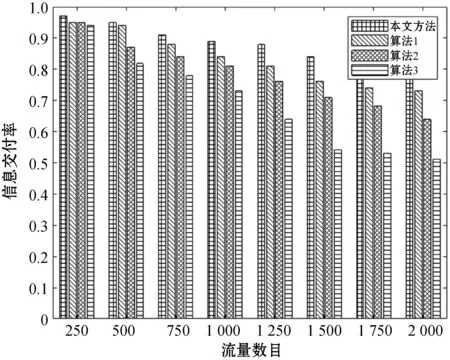
图3 信息交付率
3.3.3链路故障条件下信息交付率对比
为了进一步验证本文算法的可靠性,本文采用随机破坏网络的方式对算法进行进一步验证。虽然本文的实验环境有2 930条链路,但是超过一半以上故障属于网络瘫痪情况,所以随机生成故障链路范围被设置为1到1 000。为了与无故障链路条件实验次数统一,所以随机生成8个故障链路数目,用于检验算法对突发事件和故障事件的鲁棒性。
图4所示为链路故障条件下四种算法的信息交付率比较,故障链路数量从左到右分别为142、420、484、786、798、910、951和970。总体上讲,随着故障链路数量的增加,所有算法的信息交付率呈递减趋势。但是,本文算法的平均信息交付率为0.81,而其他三种算法的信息交付率仅为0.54、0.51和0.41。特别是当故障链路数量超过484以后,其他三种算法出现了断崖式的突然下降。这是因为算法1受到随机破坏影响,直系邻域节点范围减少,一些节点的路由交付效率降低;算法2则无法获得全局最优解[14],导致性能下降;而对于算法3来说,无法适应随机故障,局部路由流量过大,导致信息冲突增加,信息交付率降低。进一步,对于本文算法,由于采用了反向学习机制,算法可以根据当前网络环境做出预判,并负增强学习进行修正,从而达到对路由表中最短时间的自适应更新,保证了信息交付的稳定性。因此,本文算法在链路故障条件下仍然可以保证较可靠的路由交付功能。

图4 链路故障下的消息交付率
为了进一步验证提出机制的可靠性,在相同的流量条件下,分别针对网络链路无故障和有故障的情况,测试了提出机制所取得的交付能力。通过观察表1,可以得出:(1) 提出的机制在无故障情况下取得的交付能力要高于有故障的情况,符合实际情况;(2) 提出的机制在有故障和无故障两种情况下的交付能力都较高;(3) 提出的机制在网络有故障和无故障两种情况下,所取得的交付能力差别不大,大概在0.9%~6.83%之间。

表1 提出机制在有故障和无故障情况下的交付率
综合第2和第3种现象,可以看出提出的机制能够有效地应对网络无故障和有故障的情况,也能够保证在网络发生故障时,网络性能下降不大。因此,这在一定限度上反映了提出算法具有较高的可靠性。
4 结 语
本文针对物联网环境下的路由问题,提出了一种动态的、可反馈和修正的自适应路由算法。该方法通过负增强学习方法建立路由的修正模型,并提供反馈信息;采用双向自适应机制,实现路由表的自适应估计。实验结果表明,提出的算法有较好的网络适应特性,能够在不同的网络状态下保证相应的路由性能。未来的研究工作包括对进一步思考边缘计算在物联网中所起到的作用。
猜你喜欢
移动通信(2021年5期)2021-10-25
空间科学学报(2020年3期)2020-07-24
湖北第二师范学院学报(2020年2期)2020-06-05
铁道通信信号(2020年9期)2020-02-06
魅力中国(2019年37期)2019-10-21
太原学院学报(自然科学版)(2019年3期)2019-09-23
太原科技大学学报(2019年3期)2019-08-05
网络安全和信息化(2018年3期)2018-11-07
中国交通信息化(2014年3期)2014-06-05
自动化与仪表(2014年10期)2014-02-26
