
核相关神经网络点云自动配准算法
2022-12-01 07:32:14黄硕文
同济大学学报(自然科学版) 2022年11期
李 健,黄硕文,冯 凯,朱 琦,崔 昊
(1.郑州大学地球科学与技术学院,河南 郑州 450001;2.郑州大学水利科学与工程学院,河南 郑州 450001;3.河南省测绘工程院,河南 郑州 450003)
随着三维激光扫描技术的发展,点云数据被广泛应用于三维重建、自动驾驶、智能机器人等领域。然而由于被测物体几何形状、位置、结构及角度的限制,传感器难以一次获取完整的点云数据,因此需要将得到的多站具有不同坐标系的点云统一到同一参考坐标系下,这个过程称为点云配准[1-2]。点云配准是完成点云后续处理的前提和关键步骤,配准的精度将直接影响三维建模成果的好坏。
目前传统的点云自动配准算法大致可以分为三类:(1)迭代最近邻点算法(iterative closest point,ICP)[3]及其变种。经典的ICP算法以最近欧式距离建立点对间的对应关系,并通过迭代方式优化目标函数来获得最终的配准结果。经典ICP虽然简单实用,但需要配准的两组点云之间具有良好的初始位姿,否则容易陷入到局部最优解。为了解决该方法的局限性,国内外学者提出了众多改进方法,主要集中在匹配点对选择[4]、配准初值的计算[5]、目标函数的设计与优化[6]等方面。(2)基于同名特征的方法。此类方法首先从扫描点云中提取关键点[7]、线[8]、面[9]等要素,对这些关键要素设计特征描述子进行特征描述,然后基于特征相似性匹配建立同名对应关系,进而优化目标函数求解出位姿变换参数。此类方法无需提供初始值,但在两个点云分布不一致的情况下容易配准失败。(3)基于数学统计的方法。如正态分布变换算法(normal distribution transform,NDT)[10]、高斯混合模型算法(gaussian mixture models,GMM)[11]等,通过对点云建立概率模型来描述其分布特性,使得配准后的两个点云之间的似然函数达到最大,从而解出对应的变换矩阵。基于统计的配准方法对于点云的噪声以及缺失值具有较强的鲁棒性,但对复杂点云进行精确的数学描述计算量过大,算法效率较低。
近年来,随着计算机的硬件性能提升,深度学习技术在三维点云数据处理领域中得到了快速发展[12]。在点云配准应用中,Zeng等[13]将三维点云划分为体素栅格,使用三维卷积神经网络来训练点云的特征描述子,基于特征完成同名点匹配以及配准参数求解;Gojcjc等[14]把点云用体素化平均密度值表示,通过全卷积层学习具有旋转不变性的三维点云描述子;Choy等[15]采用稀疏卷积代替传统卷积,然后使用类似UNet结构的网络对输入点云中每个点的特征描述进行训练。这些方法虽然在配准任务中取得了不俗的表现,但基于特征匹配搜索同名点的方式较为耗时,且网络训练出来的特征描述子通常只适用于特定场景点云配准。为提升配准的效率,一些学者通过神经网络直接端到端地输出点云配准结果,如舒程珣等[16]提出了一种基于卷积神经网络的点云配准方法,将源点云以及目标点云从多个视角投影为深度图,使用卷积层来提取深度图中的高维特征,然后通过全连接层进行配准参数的回归;Aoki等[17]使用多层感知机网络将原始点云维度映射到高维空间,在特征域中引入光流估计法对点云变换位姿进行迭代求解;Sarode等[18]通过多层感知机和最大池化层获取点云的全局特征,把源点云和目标点云全局特征向量进行拼接后输入全连接网络对点云配准参数进行回归,然后以迭代的方式优化配准结果。
总的来说,目前工程中常用的基于标靶布设的点云配准方法耗时耗力,而传统的点云自动配准方法则效率较低,基于深度学习的端到端点云配准虽然在效率上有所提升,但使用多层感知机的特征编码方式未考虑到点云的局部邻域信息,且缺乏对同名对应点关系的显示构建,因而鲁棒性性较差。针对以上问题,本文提出一种基于核相关神经网络的点云自动配准算法(kernel correlation registration,KCR),首先通过构建点云核计算核相关度来获取点的局部邻域信息,然后使用多层感知机对源点云以及目标点云进行特征编码。为提升配准效率,通过对应关系估计层建立两个点云间的同名点对应关系,使用奇异值分解法(singular value decomposition,SVD)求解点云变换参数,最后以迭代的方式来减小配准误差直至符合精度要求。
1 算法原理
1.1 算法整体架构
KCR算法的网络结构主要包含特征提取层、对应关系估计层、SVD位姿求解层三个关键模块,具体步骤如下:
步骤1:输入待配准的源点云以及目标点云。
步骤2:使用八叉树算法对无序点云数据进行空间拓扑划分,对每个目标点建立K邻域索引。
步骤3:建立不同形状的点云核,计算源点云以及目标点云中每个点与所建立点云核之间的相关性,再通过多层感知机(multi-layer perception,MLP)将点云中每个点的特征维度映射到高维空间对点云进行特征编码。
步骤4:基于两个点云的特征编码使用多层感知机来估计源点云在目标点云中的对应点,然后根据点对间对应关系使用SVD法求解变换矩阵。
步骤5:计算本次迭代所求得的Ti与Ti-1之差,若小于阈值或达到最大迭代次数n,则输出变换矩阵否则将变换后的点云输入网络得到下一次迭代的变换矩阵。
如图1所示,对于输入的源点云和目标点云,网络首先通过特征提取层对点云进行特征提取,然后基于两个点云提取的特征通过对应关系估计层得到源点云在目标点云中的对应点,最后使用SVD位姿求解层求解配准结果并以迭代方式优化,实现从源点云到目标点云的自动配准。下面对网络所使用的各个关键模块进行介绍。图中,N为输入点云数目,MLP为多层感知机网络,R和t分别为对应的旋转以及平移矩阵。
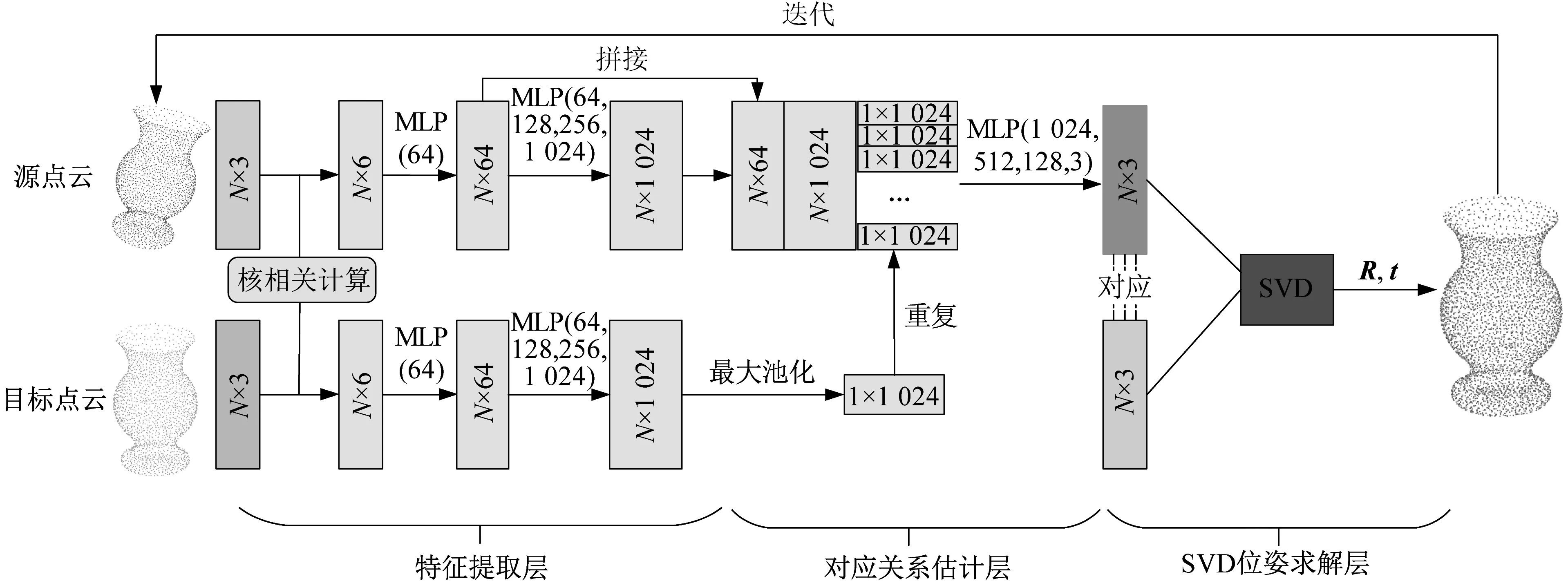
图1 KCR算法的网络结构图Fig.1 Network structure of KCR algorithm
1.2 特征提取层
在点云特征编码中,考虑每个点的邻域信息有助于提升后续任务的精度。类似于2D图像中卷积神经网络使用卷积核提取图像的邻域信息,本文首先使用核相关[19-20]的方式对点云的局部几何信息进行编码,通过构建多个点云核并计算点云中每个点与所构建点云核之间的相关度,以此来获取点云的局部邻域结构信息。点云核的函数表达形式如下:
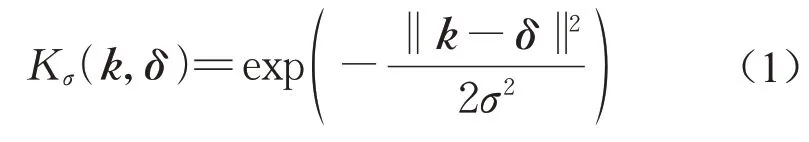
式中:Kσ(·)为高斯函数;δ为均值;σ为方差,函数的值随两点之间距离的增加呈指数衰减。
原始输入的点云是散乱无序的,为查询每个点的邻域点,首先使用八叉树算法对待配准的点云数据建立邻接拓扑关系,然后通过式(2)计算待配准点云中的点与所建立点云卷积核之间的相关性:
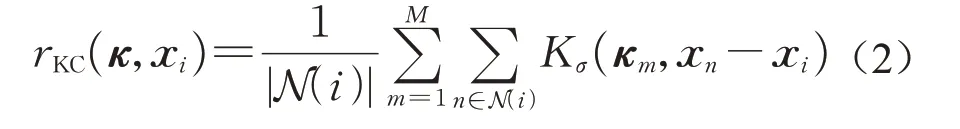
式中:κ为点云核;xi为待配准点云中一点;xn为其邻域中一点;κm为点云核中的第m个点;|N(i)|为待配准点云中第i个点的KNN邻域;Kσ(·)为核函数;rKC为点与点云核之间相关度,可对两个点云之间的几何相似性进行描述,值越大代表点云之间的相关性越强。
在对输入点云中每个点进行核相关性计算后,为使神经网络学习到点云的高维度特征,使用多个多层感知机网络将点的特征维度映射到1 024维的高维空间,完成对原始点云的特征编码。
1.3 对应关系估计层
在点云配准任务中,基于特征相似性匹配进行同名对应点搜索的方式较为耗时。因而本文通过神经网络直接估计源点云在目标点云中的对应点云,以提升匹配的效率。首先对编码后的目标点云进行最大池化提取到全局特征,将其扩展至与源点云点数量相同的维度,然后与源点云的64维特征以及1 024维特征进行拼接,最后通过多个多层感知机输出对应点云,如式(3)所示:
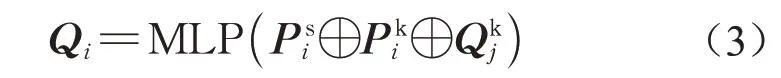
式中;Qi为源点云中点在目标点云中的对应点;Pis和Pik分别为源点云的64维特征和1 024维特征;Qkj为目标点云经最大池化后的全局特征;MLP为多层感知机网络。
1.4 SVD位姿求解层
对于给定的两个待配准点云P和Q,其中P为源点云,Q为源点云经过变换后的目标点云,三维点云配准任务为寻找合适的变换参数即旋转矩阵R和平移向量t,使得配准后的点云在同一坐标系下对齐。在确定点云之间的对应关系后,变换参数可以通过优化以下目标函数来求得:
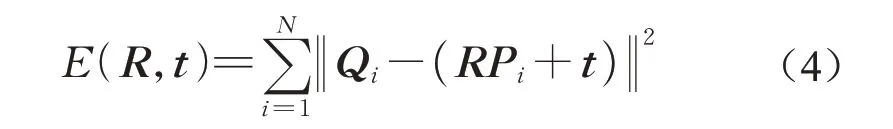
式中;N为点云中点的数量;Pi和Qi为估计的同名点。
SVD是求解式(4)的经典方法,由最小二乘推导而来,速度快且稳定性高。使用SVD求解配准变换参数的计算步骤如下:
首先通过式(5)和(6)分别计算源点云和目标点云的质心,即求取点云中点的均值:
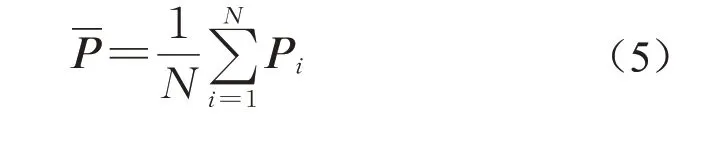

解算出初始变换矩阵后,将其应用于源点云得到初始配准结果。由于点云位姿变换的复杂性,神经网络难以一次性地对配准参数进行精确的估计,因此通过一个迭代过程将变换后的源点云与目标点云重新输入网络计算,使得配准误差不断减小,直到达到最大迭代次数或两次产生的矩阵之差小于阈值,完成点云精细配准过程。其中最大迭代次数和矩阵差阈值本文分别设置为10和0.2,在保证效率的前提下能达到较好配准效果,具体数值设置可根据应用进行微调。
1.5 损失函数设计
通常神经网络需要根据不同的任务设计损失函数进行反向传播以达到优化网络参数的目的。对于点云配准任务,所设计的损失函数目标为使预测配准参数与真实配准参数之间误差最小,定义如(11)所示:
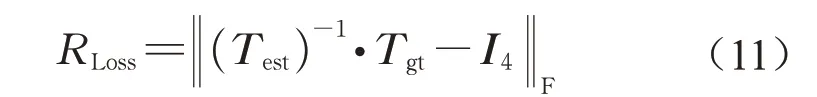
式中;Test为网络估计的变换矩阵;Tgt为真实变换矩阵,当两者相等时乘积为单位阵I4。
2 实验结果及分析
2.1 实验设置
实验采用ModelNet40[21]作为神经网络的训练数据集,数据集中总共包含12 311个点云样本,分为40个类别,每个点云中包含4 096个点。训练过程中以ModelNet40中的原始点云作为源点云,对其进行随机旋转以及平移产生目标点云,记录其变换矩阵作为真值标签。网络训练使用Adam损失函数优化器,学习率为0.001,共训练300个epoch。训练完成后,在斯坦福大学3d扫描模型库中的Bunny、Dragon、Happy、Elephant、Horse模型进行仿真测试。将本文算法与ICP[4]、相干点漂移算法(coherent point drift,CPD)[22]、GMM[17]、支持向量机算法(support vector registration,SVR)[23]进行精度以及效率对比,其中ICP算法以最近欧式距离建立点对间的对应关系,并通过迭代方式优化目标函数来获得最终的配准结果;CPD算法将两个待配准点集分别视为高斯混合模型的质心和数据,利用EM(expectation maximization)算法进行最大似然估计,从而得到质心点集到数据点集的变换关系;GMM算法将源点云和目标点云视为两个高斯模型分布,通过最小化两个分布间的欧式距离求解变换参数;SVR算法通过训练支持向量机模型来最小化两个点云模型之间的距离实现配准。文中使用均方根误差(root mean square error,RMSE)来定量评价各算法配准精度,其定义如下:
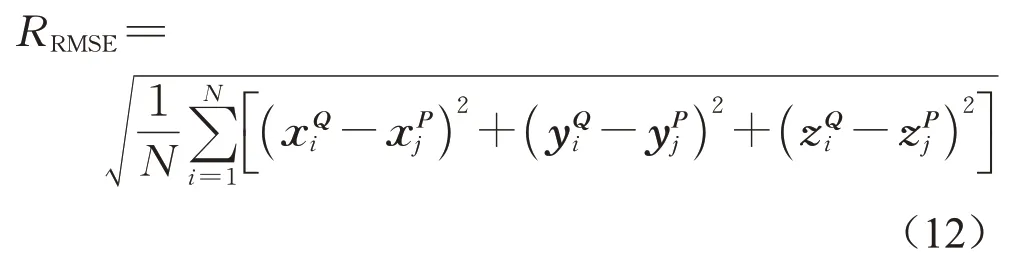
式中;RRMSE表示均方根误差;N为点云个数;Q和P分别代表源点云和目标点云。
所有实验在一台配置Intel Xeon W-2145@3.70GHz处理器,64G内存和NVIDIA TITAN X显卡的工作站上进行,系统为Ubuntun16.04,使用的编程语言为Python。
2.2 各算法配准精度及效率对比
实 验 中 用 于 测 试 的Bunny、Dragon、Happy、Elephant、Horse点云的初始位姿如图2所示。
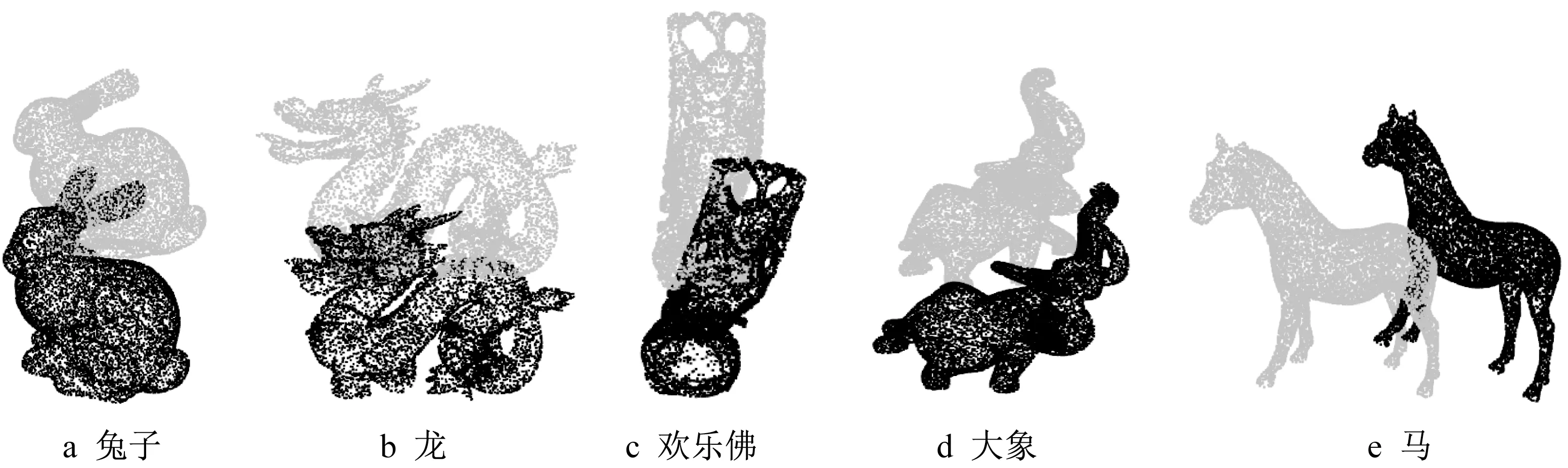
图2 点云初始状态Fig.2 Initial state of point cloud
各算法在测试点云上的配准效果如由图3所示。
由图3可以看出,CPD、SVR以及本文提出的KCR算法均可以实现不同物体点云的配准,其中ICP算法在Bunny、Dragon、Happy点云上有较好的配准效果,而在Elephant和Horse点云上配准效果较差;GMM算法在各个点云上的配准结果均不理想,容易陷入到局部最优解,受初始位置影响较大;CPD算法配准后的点云形态发生了改变,有轻微失真现象;经SVR算法配准后Bunny源点云与目标点云仍有偏差,仍需进一步的精细配准;PCRNet在Dragon和Happy点云上配准效果良好,但在其他点云模型配准中误差较大;KCR算法在各个模型上均取得了不错的配准效果,经变换后的源点云基本与目标点云重合。

图3 各算法配准效果Fig.3 Registration effect of each algorithm
在配准误差的定量对比上,由表1可以得知KCR算法在各个物体上的配准精度优于所对比算法,PCRNet算法配准精度受输入点云形态的影响较大,SVR与CPD算法的配准精度相当,ICP次之,GMM算法的配准精度最差。由表2得知,在配准时间上,PCRNet算法用时最短,KCR算法略次之,CPD算法用时最长,SVR算法耗时略优于ICP算法。相比传统算法,基于深度神经网络的配准方法可直接根据输入的两个待配准点云端到端地输出变换矩阵,在效率上有良好表现,KCR算法由于引入了核相关度计算和对应关系估计层等模块以提升配准参数求解的精度和鲁棒性,因此在运行效率上略低于直接通过全连接层输出配准结果的PCRNet算法。

表1 各算法配准误差Tab.1 Registration error of each algorithm
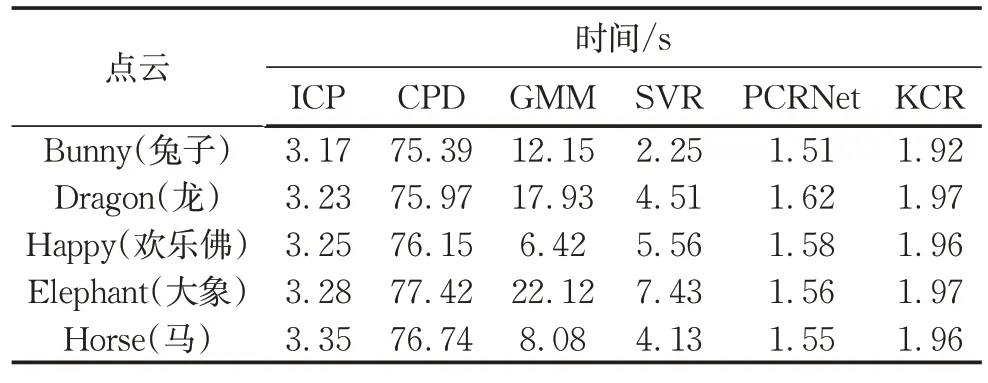
表2 各算法配准时间Tab.2 Registration time of each algorithm
2.3 噪声点云配准
由于扫描过程中点云传感器、环境以及人为因素的影响,所获取的点云不可避免地会出现噪声影响。为验证各个算法的抗噪能力,在Elephant点云上施加均值为0,方差为0.05的高斯分布噪声,对比各个算法在噪声环境下的配准精度与效率。
由图4和表3可知,除ICP和PCRNet算法外,其余算法均对噪声具有良好的鲁棒性。由于ICP算法基于最邻近搜索来建立同名点对应关系,而噪声的存在会造成大量错误的对应关系,不利于后续配准参数求解的过程;CPD、GMM算法均通过建立概率分布模型来实现点云间的配准,因而有良好的抗噪能力;PCRNet通过全局特征向量进行配准参数回归求解,而噪声的存在干扰了全局特征向量对于点云的表达能力,从而影响配准结果;KCR考虑了核相关信息对点云特征进行编码,在大样本数据集训练下对于噪声并不敏感。精度对比上,KCR算法略优于其他算法,对比无噪声情况下的点云配准精度有所下降。时间效率上,高斯噪声对于所测试算法用时影响较小。
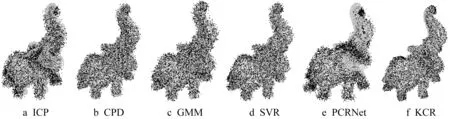
图4 各算法在噪声点云下的配准效果Fig.4 Registration effect of each algorithm in noisy point cloud

表3 各算法在噪声点云下的配准配准误差和时间Tab.3 Registration error and time of each algorithm in noisy point cloud
2.4 不同密度点云配准
由设备获取的点云数据会出现远处点云密度高而近处密度低的情况,且在实际点云拼接中两个点云的密度通常也不一样,因此进行不同密度下的点云配准实验。对待配准的Elephant点云进行50 %的数据随机丢失,目标点云保持不变,进行算法精度以及效率评价。
各个算法的配准效果与精度如图5和表4所示,可知在对不同密度点云的配准实验中,ICP、GMM、SVR和PCRNet算法均配准失败,CPD以及KCR算法能实现良好的配准效果。由于两组点的密度不一样,ICP算法缺乏足够的对应点对来用于求解变换参数,而KCR算法通过训练神经网络来估计对应同名点,其间考虑了目标点云的局部和全局特征信息,因此即便待配准的两组点云密度不同,依然能够根据估计的现有点对关系来计算出点云位姿。

图5 各算法在不同密度点云下的配准效果Fig.5 Registration effect of each algorithm at different densities of point cloud

表4 各算法在不同密度点云下的配准误差和时间Tab.4 Registration error and time of each algorithm at different densities of point cloud
总结以上实验,可以发现ICP算法完成点云配准对点云的初始位置要求较高,且对点噪声以及缺失较为敏感;CPD和GMM算法均是基于概率模型的点云配准算法,此类算法的鲁棒性较好,但计算量大,效率较低;SVR算法将机器学习中经典的支持向量机算法与高斯混合模型相结合,在不同点云配准任务上表现良好,但在密度不同的点云上配准结果较差;PCRNet算法虽然效率较高,但配准精度受输入点云的位姿和形态影响,且基于全局特征向量求解配准参数的方式鲁棒性较差;KCR算法通过构建直接作用于点云上的迭代神经网络来完成点云配准任务,能够实现在不同场景下点云的精确配准。
3 结论
本文提出了一种基于核相关神经网络的点云自动配准算法,对输入的两组点云使用深度神经网络进行编码,通过对应关系估计层来匹配同名点并进行变换参数求解,最后以迭代方式对配准结果进行优化。通过实验表明,本文算法能够在各个物体点云上实现端到端的精确配准,效率较传统点云配准算法有明显提升,且在点云数据存在噪声和密度不一致的情况下仍具有良好的稳定性和精度,基本解决了现有点云配准算法效率低、鲁棒性差的问题。
但由于网络容量的限制,本文算法仅在小场景点云配准任务上进行实验,对于大场景的点云配准任务仍需对网络结构进行进一步的优化。
作者贡献声明:
李健:提出想法,论文撰写。
黄硕文:论文撰写,神经网络设计。
冯凯:神经网络算法程序设计。
朱琦:点云配准数据收集。
崔昊:点云配准实验分析。
猜你喜欢
阿来研究(2021年2期)2022-01-18 05:36:12
数学年刊A辑(中文版)(2020年3期)2020-10-27 02:44:16
阿来研究(2020年2期)2020-02-01 07:12:36
当代陕西(2019年11期)2019-06-24 03:40:46
读友·少年文学(清雅版)(2018年8期)2018-12-06 08:41:24
中学生数理化·八年级物理人教版(2017年9期)2017-12-20 08:11:30
外语学刊(2017年3期)2017-12-07 01:45:38
陕西理工大学学报(社会科学版)(2017年1期)2017-03-02 10:50:35
陕西理工大学学报(社会科学版)(2017年1期)2017-03-02 10:50:35
中国科技博览(2016年27期)2017-01-23 04:18:13
