
基于变分模态分解和神经网络的风速组合预测
2022-11-30 01:08郅伦海
合肥工业大学学报(自然科学版) 2022年11期
郅伦海, 訾 勇, 徐 凯
(合肥工业大学 土木与水利工程学院,安徽 合肥 230009)
0 引 言
近年来,可再生能源在全球能源供应中起着至关重要的作用,其中风能是一种新兴的可再生能源,作为过去几十年中化学燃料可行性的代替品,风能的开发利用引起了世界各国的关注和重视[1]。风能发电的安全性、稳定性及经济性与风速预测的准确程度有着紧密的联系,高精度的风速预测结果可为风能的有效利用提供坚强保障。目前风速预测的方法主要包括人工神经网络[2-3]、支持向量机(support vector machine,SVM)[4]以及各种组合方法[5-6]等。文献[7]利用自回归滑动平均模型预测纳瓦拉的短期风速,但时间序列模型多用于线性风速预测,存在着一定的局限性;文献[8]提出基于经验模态分解(empirical mode decomposition,EMD)风速序列分解的神经网络组合预测模型,证明了对于不同分量运用不同预测方法的可行性,采用EMD分解法将风速序列分解,降低了序列的不稳定性,但在处理过程中依旧存在虚假模态等问题。
本文提出一种基于变分模态分解(variational mode decomposition,VMD)和神经网络组合的预测模型。该模型通过VMD将原始风速序列分解,用样本熵(sample entropy,SE)计算子序列的复杂程度,将其分为复杂程度较高和复杂程度较低两类,对复杂程度较高的子序列采用组合预测,其他分量选择SVM模型直接预测,最后运用BP神经网络将预测结果拟合为最终预测值。
1 基本方法原理
1.1 VMD的基本原理
VMD是一种自适应的信号处理方法。其核心思想是变分问题,VMD将信号分解为K个带宽有限的固定模式函数(intrinsic mode function,IMF),并提取出对应IMF的中心频率,使得各个分量准确分离[9-11]。
计算步骤如下:
(1) 对每个模态函数uk(t)采用Hilbert变换得到相应的解析信号,获得单侧频谱。
(2) 加入指数项e-jωkt调整各自的中心频率,将频谱调制到相应基带上。
(3) 对已解调的信号计算其梯度的平方范数L2,应用高斯平滑估算相应的带宽。变分模型构造如下:
(1)
其中:{uk}={u1,…,uk}为分解后得到的k个模态分量;{ωk}={ω1,…,ωk}为各模态分量的中心频率;δ(t)为狄拉克函数;*为卷积符号。
通过引入二次惩罚因子α和拉格朗日乘法算子λ(t),将有约束的变分问题转化为无约束的变分问题,可以得到扩展的拉格朗日表达式如下:
L({uk},{ωk},λ)=
(2)
(3)
(4)
VMD实现过程如下:
(2) 根据(3)式、(4)式更新uk、ωk。
(3) 更新λ。计算公式为:
(5)
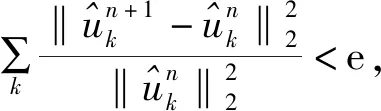
1.2 SE的计算步骤
SE[12]是一种度量时间序列复杂度的方法。SE值越高,说明序列的复杂性越大,反之亦然。SE值的具体算法步骤如下:
(1) 对于给定长度为N的时间序列数据x(i),按顺序构建m维向量,即
Xi=[x(i)x(i+1) …x(i+m-1)],
i=1,2,…,N-m+1
(6)
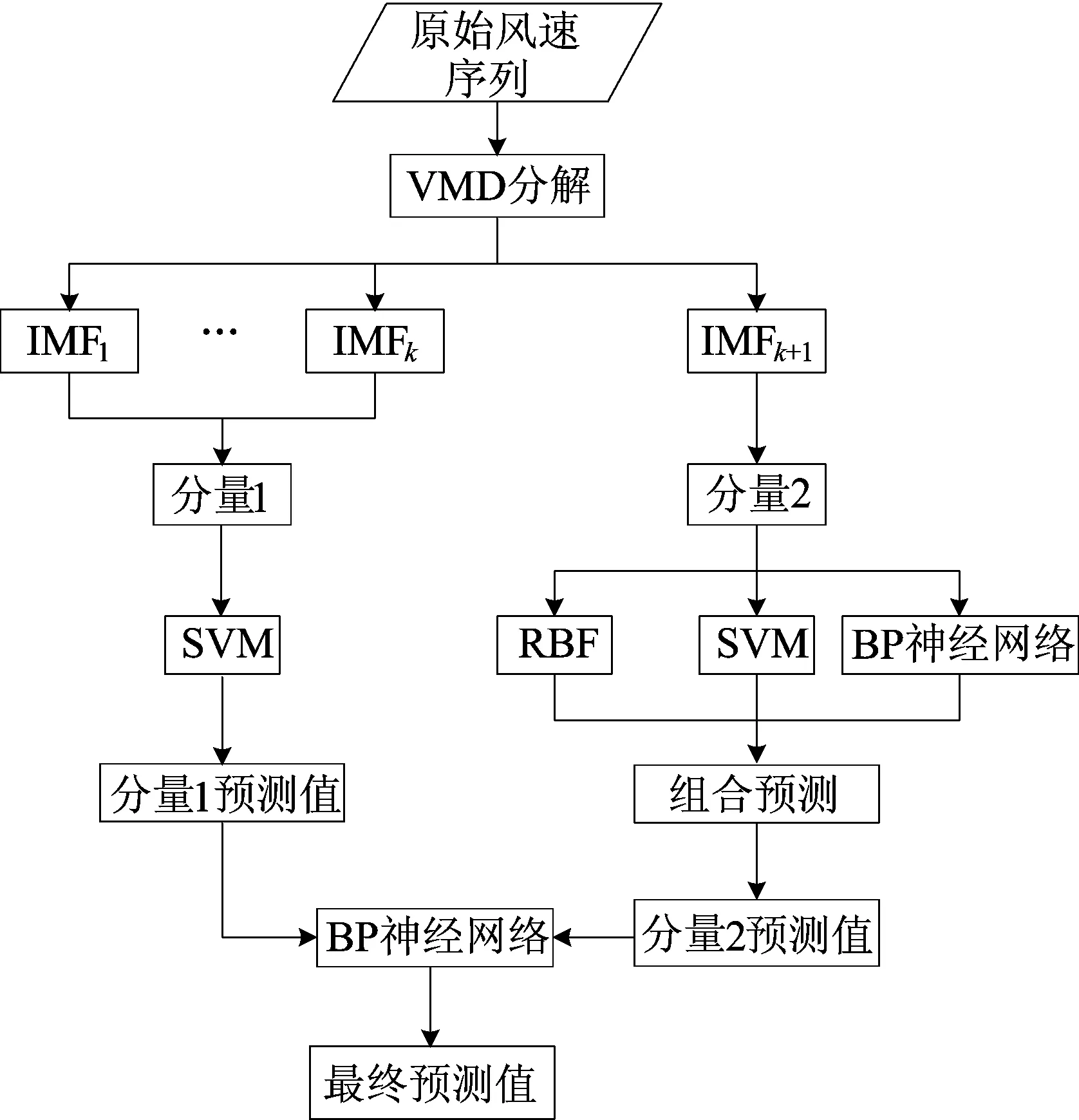
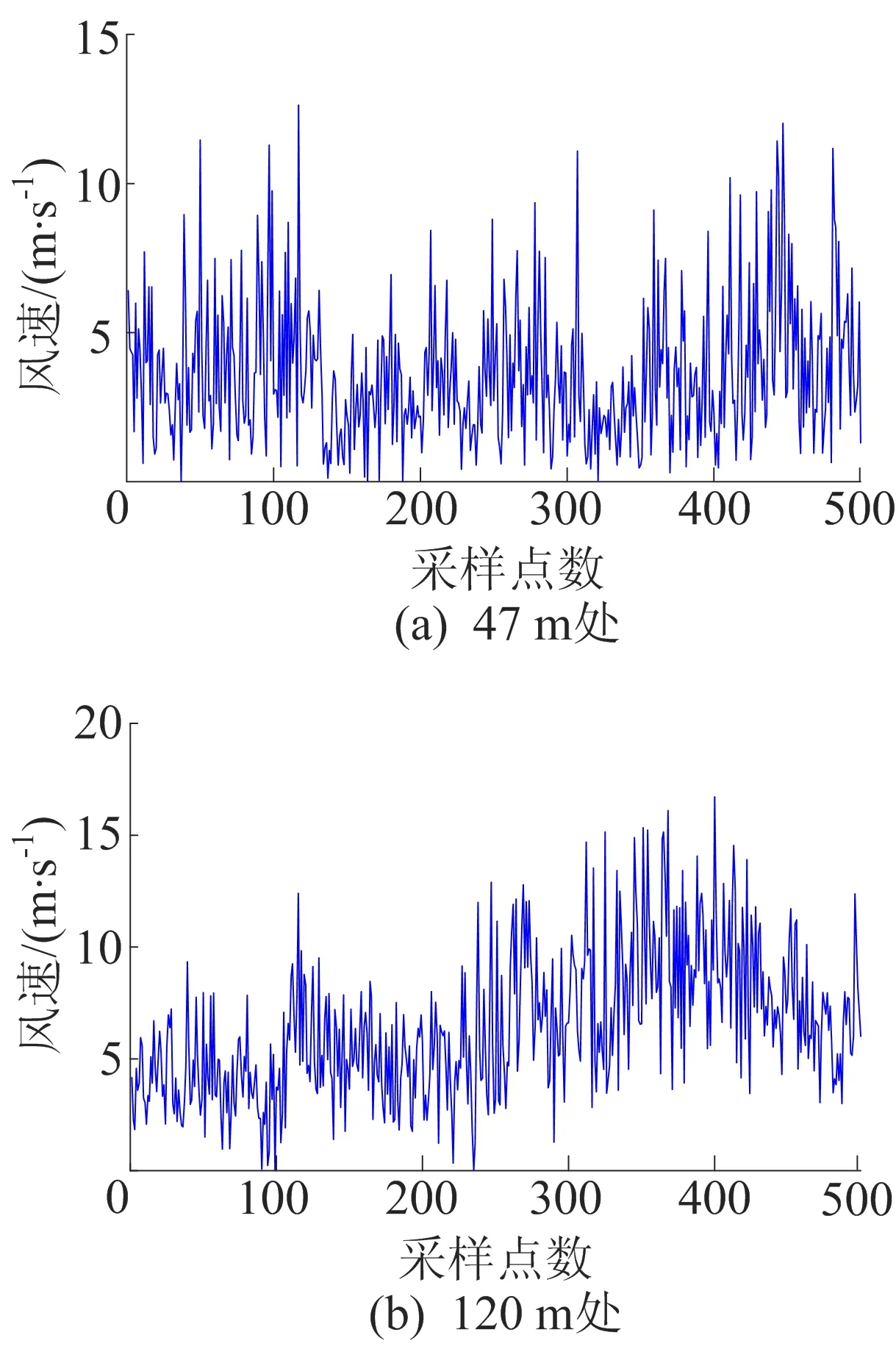
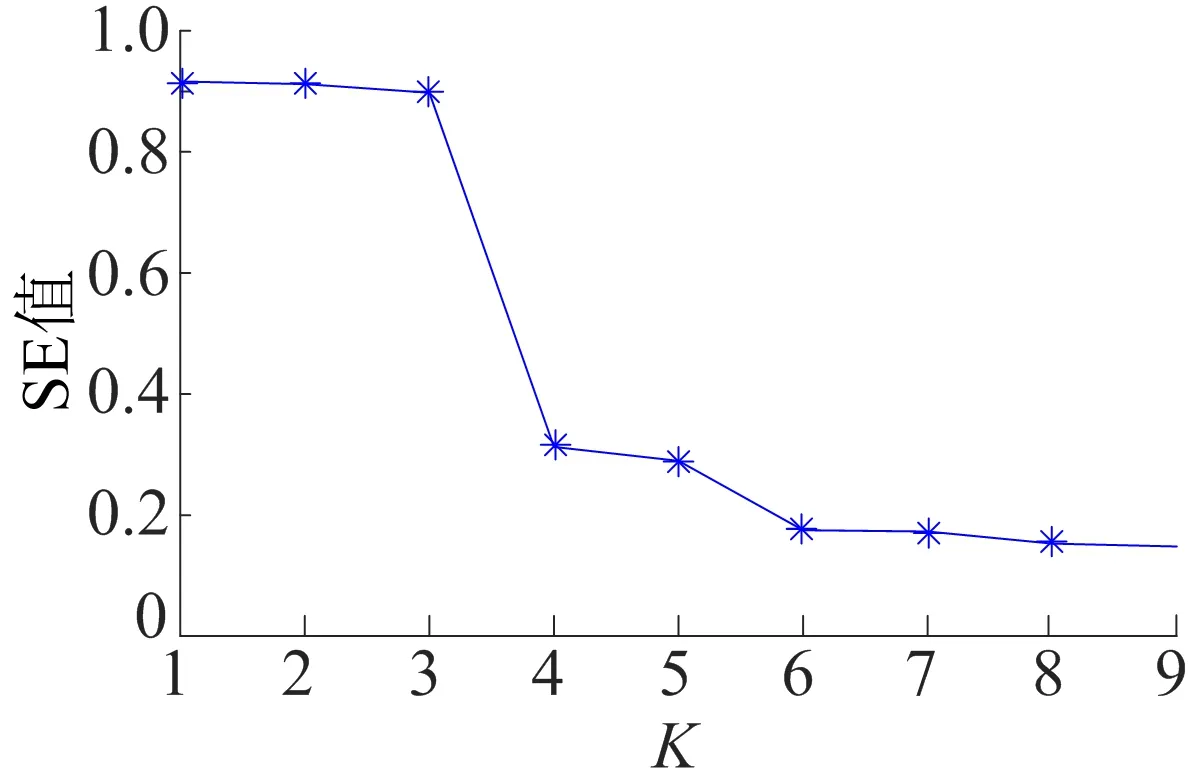
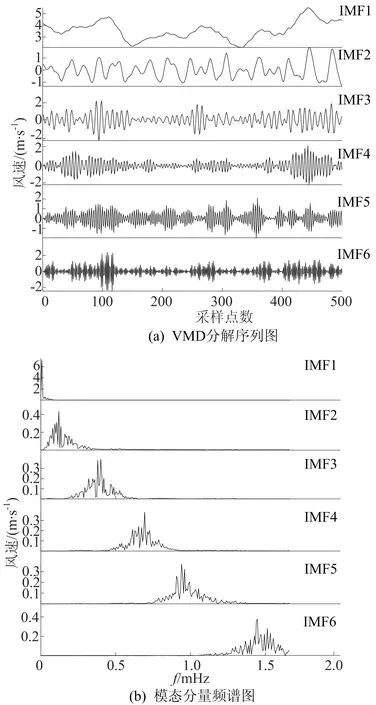
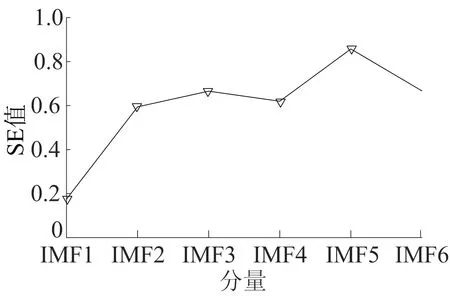
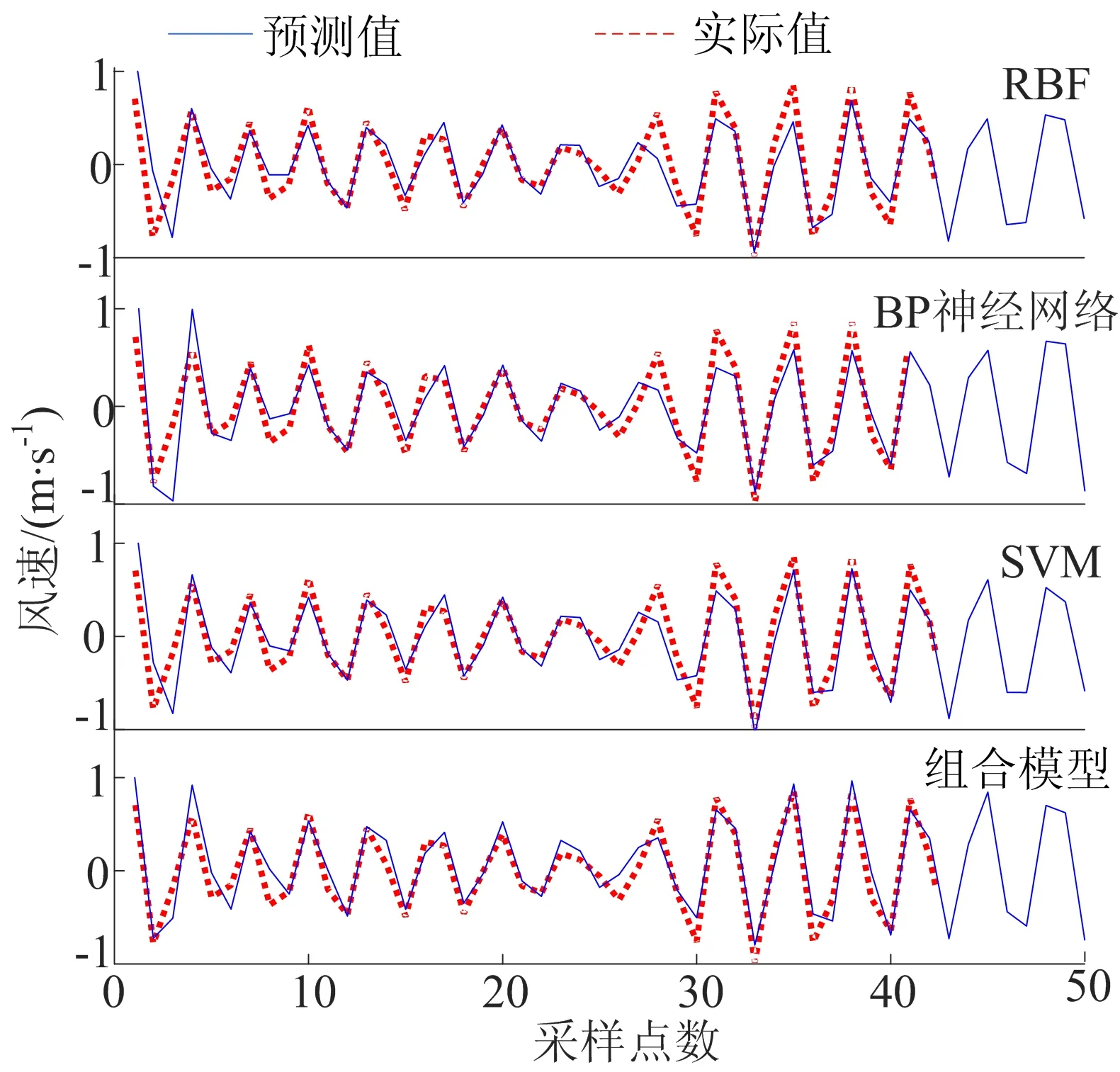
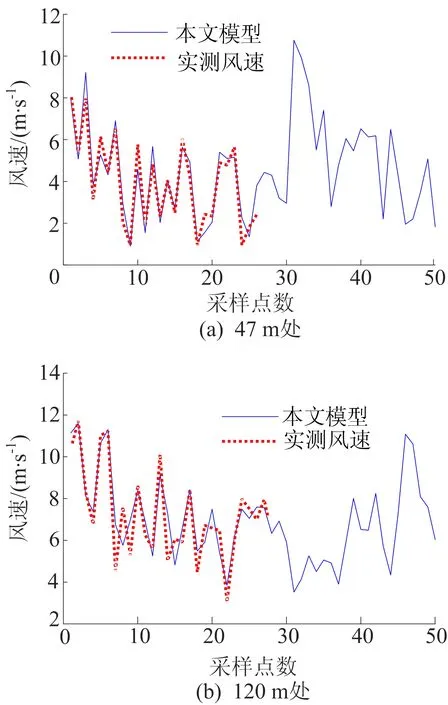
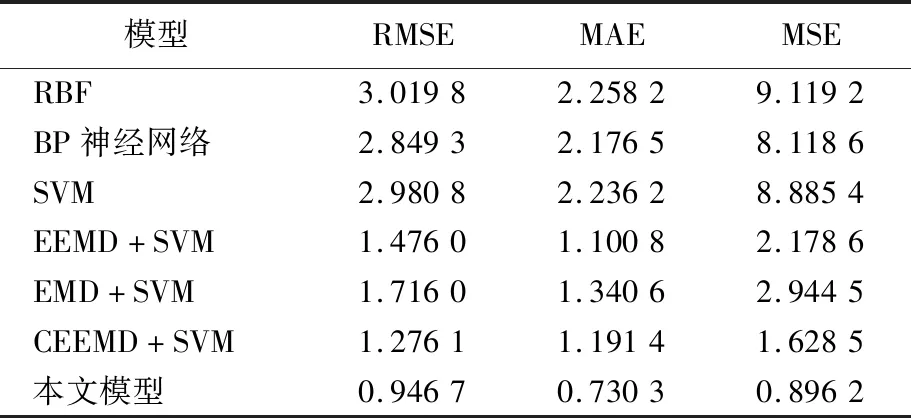
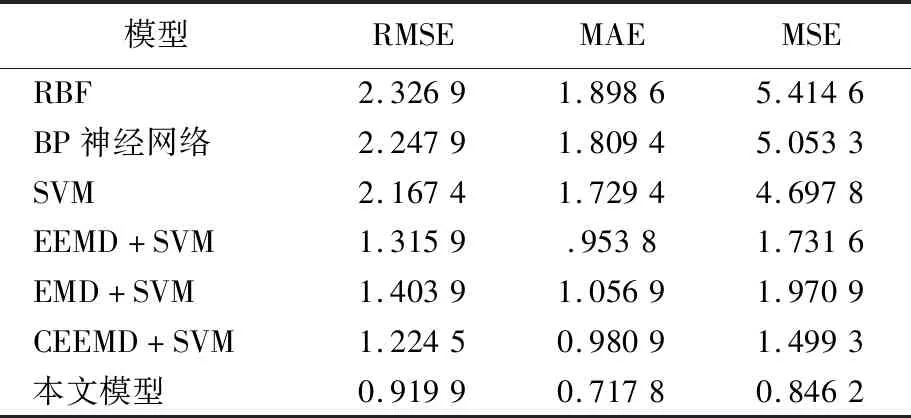
0 (7) (8) (9) (5) 更新维数,令m=m+1,并重复上述步骤,即可得到Cm+1(r)。 (6) 理论上,此时样本熵的值SE为: (10) 当N为有限数时,(10)式可表示为: lnCm(r)-lnCm+1(r) (11) 参数m、r的设定会对SE产生一定影响,一般令m为2,r取原始数据标准差的0.10~0.25倍,本文取0.20倍。 径向基函数网络(radial basis function network,RBF)[13]从结构上看是一个3层前馈网络,包含输入层、隐含层、输出层。该神经网络使用径向基函数作为隐含层节点的激活函数。RBF神经网络具有局部映射的特性,学习速度和逼近能力方面较好。 BP神经网络[14]是目前应用最广泛的神经网络模型之一。将训练输出和期望输出所形成的误差通过隐含层逐层反向传播到输入层,在反向传播的过程中,对每一层的权重系数进行修改,使全局误差实现最小化。 支持向量机[15-16]用于时间序列预测的基本思想是当训练数据在低维特征空间不可分时,通过核函数将输入空间映射到多维特征空间,将低维非线性形式的问题转化为多维线性化形式的问题。近年来SVM在函数逼近、时间序列分析等领域得到广泛的运用,被认为是替代神经网络较好的选择。 组合预测能够综合各独立模型的优点,取长补短,避免了单一模型的局限性[17-18]。组合预测是把不同的权重系数赋值于各单一模型,最后相加得到预测值。关键问题是确定权重系数,但实际预测中,若权重系数一直不变,则精度会随着时间延长而变差。本文引入信息熵[19]来描述权重的不确定性,通过引入熵值法建立一种变权重组合预测模型。 (12) 因为风速是连续变化的,所以当前时刻的风速与其之前的历史风速相关性较大。滚动提取t时刻之前最近的k个样本历史值来计算权重系数,用m个指标去评价n种预测模型,得出评价矩阵E=(eij)n×m,eij为第i种预测模型第j个评价指标,再对评价矩阵E按列归一化,整理后得到归一化矩阵P=(pij)n×m,其中 (13) 则第i种预测模型的信息熵为: (14) 若某种单一预测模型的信息熵越小,说明指标的变异程度越大,所能提供的信息就越大,则在最终的综合评价中作用越大,权重系数越大;反之则越小。最终组合预测模型中权重可以表示为: (15) 循环往复即可动态更新每个单一模型的权重,将权重系数与预测结果相乘得到最终的预测结果,预测模型流程如图1所示。 本文预测模型步骤如下: (1) 首先用VMD对原始风速序列分解,得到不同频率的分量。 (2) 采用SE评估各分量的复杂程度,根据结果分为复杂度较高和复杂度较低两类。 (3) 对分解之后的分量分别进行归一化处理。 (4) 针对2个分量的不同特点,建立合适的预测模型,对复杂度较高的采用组合预测,其余分量采用单一的预测模型。 (5) 将得到的所有分量风速预测值用BP神经网络来拟合,得到的风速值即为最终的风速预测值。 图1 预测模型流程 本文选取2002-03-20北京测风塔47、120 m处实测风速为研究对象,数据集的时间间隔为5 min,选取500个采样点。风速的序列图如图2所示,从图2可以看出,风速变化幅度较大,平稳性较差。选取前450个采样点作为训练样本,用于模型的训练;后50个采样点作为测试样本,用于检验不同模型的预测效果。 因为风速序列具有很强的非平稳性,所以使用VMD进行风速序列的分解,其中选取合适的分解层数K很重要,当K值太小时会导致出现模态混叠现象;当K值太大时,则会导致同一模态出现在不同的分量上,不利于后续的预测。本文VMD的分解数用SE值来判断,风速序列由VMD在不同K值下进行分解,计算每个子序列的SE值,进行比较,将SE值最小的序列作为趋势项,随着分解层数增加,SE值趋于稳定,因此,将SE值趋于稳定的转折点作为分解数。以47 m处风速序列为例建模,显示了在不同K值下趋势项的SE值的变化趋势[20-21],如图3所示。从图3可以看出,随着K值增大,SE值逐渐减小,当K值大于等于6时,SE值逐渐处于稳定状态,表明风速序列分解是适当的,因而本文选择K值等于6作为分解数。 图2 47 、120 m处风速序列图 图3 不同K下SE值 VMD分解结果如图4所示,风速序列被分解为6个分量,从上至下依次为IMF1~IMF6,结合时域图与频谱图,不同分量的主频率不同,对应时域的波动性也相差较大,说明VMD分解对风速序列逐层分解后可实现各个分量的准确分离。 本文采用SE计算分量的复杂程度,从而减少计算量,结果如图5所示。从图5可以看出,SE值先逐渐上升再降低,说明对应的IMF分量的复杂程度也是由难到易,其中IMF5的SE值明显高于其他子模态,说明IMF5是复杂程度最高的子模态,将其作为分量2,其余的作为分量1。本文针对不同复杂程度的分量采用不同的预测模型,对复杂程度较高的分量2则采用组合预测。 图4 VMD分解结果 图5 各分量SE值 组合模型的预测结果如图6所示。从图6可以看出,风速在变化较大的地方,即曲线的高峰和低谷处,单一预测模型达不到预期的效果,而组合模型则更接近实际值,更能捕捉到风速的变化规律,因此组合模型更适合预测复杂度较高的分量。 图6 各模型对分量2的预测结果 对于分量1,通过试验可以发现,单一的预测模型就能达到比较好的效果,本文采用SVM进行预测。运用BP神经网络来拟合各个分量的预测值,将分解后每个分量训练集的样本数据与对应的实测风速数据组成数据集,利用BP神经网络非线性的映射性能,代入并训练BP神经网络,测试集部分的预测结果代入训练好的BP神经网络,得到最终的预测值。 为了更加直观地观察各模型的预测结果,利于对比分析,本文采用均方根误差(root mean squared error,RMSE)ERMS、平均绝对误差(mean absolute error,MAE)EMA、均方误差(mean square error,MSE)EMS来量化预测误差。计算公式为: (16) (17) (18) 为了验证本文提出的基于VMD分解的组合模型的有效性,将120 m处风速序列也按照本文模型建模,并将本文模型与另外两类模型进行对比。第1类为单一预测模型,第2类为基于集合经验模态分解(ensemble empirical mode decomposition,EEMD)和互补集合经验模态分解(complementary ensemble empirical mode decomposition,CEEMD)分解后的预测模型,具体模型预测结果如图7所示,误差对比结果见表1、表2所列。 图7 47、120 m处风速预测结果 表1 47 m处各模型的预测误差对比 表2 120 m处各模型的预测误差对比 从图7、表1、表2可以看出,采用原始风速序列直接建立预测模型,包括RBF、BP、SVM预测模型,预测结果的各项误差指标均较大。与单一模型相比,采用不同方法进行数据分解后,预测误差有所降低,但在高峰和低谷处预测误差较大,没有达到理想的预测效果。而且从表1、表2可以看出,本文所提出模型的RMSE、MAE、MSE误差指标更小,该模型可以有效提高预测精度,更好地反映风速的变化规律。 本文针对风速序列的非平稳性和波动性,提出一种基于VMD和神经网络组合的预测模型,以北京测风塔数据为例建立预测模型,与其他6种预测模型的预测结果对比分析,得到如下结论: (1) VMD分解不仅能消除模态混叠现象,准确地分离各个分量,而且分解效果要比EMD、EEMD、CEEMD更好,可以降低风速序列的非平稳性,有利于进一步挖掘风速序列特性。 (2) 以SE为特征,判断各分量的复杂程度,然后根据SE值确定每个分量建立不同的预测模型,可以减少建模工作量。 (3) 组合预测模型综合不同模型的优点,以权重分析的方法得出权重系数,将各种模型进行组合,具有严格的理论基础,显著提升预测模型的鲁棒性效果,提高了运算效率和预测精度。 (4) 通过BP神经网络拟合各个分量,可以进一步提高预测精度。通过对比,本文提出的基于VMD和神经网络组合模型具有较好的预测效果和实用价值,建模思想不仅可以应用于风速预测,也能为其他方向的预测提供参考。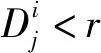
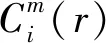
2 基于VMD和神经网络组合预测
2.1 RBF神经网络
2.2 BP神经网络
2.3 支持向量机
2.4 组合预测模型
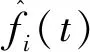
3 算例分析
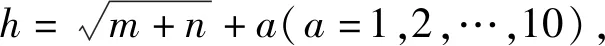
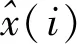
4 结 论
猜你喜欢
海洋通报(2020年5期)2021-01-14
当代陕西(2020年17期)2020-10-28
中国电业与能源(2020年5期)2020-06-16
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
人大建设(2018年5期)2018-08-16
英美文学研究论丛(2018年1期)2018-08-16
西南交通大学学报(2016年4期)2016-06-15
风能(2016年11期)2016-03-04
应用科技(2015年5期)2015-12-09
