
基于注意力的工业物联网设备剩余寿命预测方法
2022-11-28 11:53李国瑞武雅君彭三城
工程科学与技术 2022年6期
李国瑞,武雅君,王 颖,彭三城,王 聪
(1.东北大学 计算机科学与工程学院,辽宁 沈阳 110169;2.秦皇岛职业技术学院 信息工程系,河北 秦皇岛 066100;3.广东外语外贸大学 语言工程与计算实验室,广东 广州 510006)
随着“工业4.0”与“中国制造2025”等概念的提出,工业物联网(Industrial Internet of Things,IIoT)已取得长足发展,并被广泛应用于智能制造、交通运输、能源管控等多个领域[1]。通过将具有感知和控制能力的传感器和执行器部署于机械装备和工业现场中,利用无线通信或现场总线技术传输监控数据,并采用机器学习方法实现数据驱动的智能化感知和控制,可以有效地提升工业生产效率,降低运维成本,提高产品质量,最终实现工业智能化[2]。
作为工业物联网的重要组成部分,故障预测与健康管理(prognostics health management,PHM)可基于设备的健康监测数据实现智能故障诊断和剩余使用寿命预测,并结合可用维修资源和设备使用需求制定最优的健康管理策略[3]。其中,设备剩余使用寿命预测可基于多种预测方法对工业物联网设备的未来性能进行预测,以获得设备在其丧失运行能力之前的剩余时间,并在设备出现故障前制定最优维修策略,改进维修计划,从而降低设备的维修成本,提高设备的可靠性、可用性和安全性[4]。
近年来,设备剩余使用寿命预测引起了学术界和工业界的极大关注,已广泛应用于工业物联网中的机械部件[5]、电子装置[6]、机电系统[7]的监控预测中。目前,主流的剩余使用寿命预测方法根据技术路线的差异可分为基于物理模型的预测方法和数据驱动的预测方法两类[8]。
基于物理模型的预测方法主要基于故障机理和经验知识来构建工业设备的退化模型并进行预测,典型的方法包括:基于Paris–Erdogan疲劳模型的预测方法[9],基于Forman–Kearney–Engle模型的预测方法[10],基于维纳过程、伽马过程或逆高斯过程[11]等随机过程的预测方法[12]等。该类预测方法适用于结构简单、工况单一的部件剩余寿命预测,而对于结构和工况较为复杂的工业物联网设备预测较为困难。
数据驱动的预测方法通过采集工业设备的各种监测数据,利用机器学习算法自动推断出隐藏在退化数据中的因果关系,从而构建复杂的机械设备退化模型。根据采用的学习方法不同,数据驱动的预测方法大致可分为基于回归的预测方法、基于人工神经网络的预测方法和基于相关向量机的预测方法等。其中,基于回归的预测方法通过利用差分消除数据波动,从而构建统计模型以拟合退化时序数据,代表性的预测模型包括自回归(autoregressive,AR)模型、自回归移动平均(auto-regressive integrated moving average,ARIMA)模型[13]和高斯过程回归(Gaussian process regression,GPR)模型[14]等。基于人工神经网络的预测方法通过利用神经网络的特征抽取和复杂系统建模能力,构建深度学习模型以表征设备的退化趋势,代表性的预测模型包括基于循环神经网络的数据预测模型[15]和基于长短期记忆网络(long short term memory,LSTM)的数据预测模型[16]等。基于相关向量机(relevance vector machine,RVM)的预测方法根据稀疏贝叶斯学习理论,通过约束隐变量分布可有效地对预测模型进行剪枝,从而提高预测模型的执行效率,降低对退化数据量的需求[17]。该类方法具有效率高、样本少、可提供概率化预测结果等优点,在设备剩余使用寿命预测中具有广泛的应用前景。
然而,在利用机器学习方法学习机械设备退化模型时,尽管可以获取大量的健康监测数据,但其中起关键作用的故障监测数据非常稀少。同时,快速的设备退化过程进一步加剧了有效数据的稀缺性。为了充分利用有限的故障监测数据,自适应地调整设备的状态预测模型,并提供具有置信度的数据预测能力,本文提出一种基于注意力机制的设备剩余使用寿命预测方法(attention-based remaining useful lifetime prediction,ARULP),通过在相关向量机的隐变量中引入局部注意力机制,并逐步更新注意力权重,从而更好地调整设备的状态预测模型,进一步提升设备的剩余使用寿命预测精度。基于西安交通大学滚动轴承加速寿命试验数据集的验证结果表明,所提出的设备剩余使用寿命预测方法(ARULP)在预测精度方面优于现有的其他同类预测方法。
1 基于注意力的剩余寿命预测方法
基于注意力的设备剩余使用寿命预测方法包括模型训练阶段和模型预测阶段。在模型训练阶段,基于训练数据计算局部注意力度量并构建相应的设备状态预测模型。在模型预测阶段,利用前一阶段所构建的预测模型进行设备状态预测,进而计算设备的剩余使用寿命。
1.1 模型训练阶段
假设 {x1,x2,···,xn}为模型训练数据,其中,前t个数据 {x1,x2,···,xt}被设置为历史序列,后n−t个数据{xt+1,xt+2,···,xn}被设置为目标序列。通过计算预测模型中隐变量的注意力度量,并学习预测模型参数,可基于历史序列对目标序列进行预测。
目前,注意力机制已广泛应用于计算机视觉、自然语言处理、动作识别和推荐系统等应用领域[18–19]。该技术的核心思想是从输入序列中挑选少量与目标较为相关的主要信息,通过为其分配较大的权重,从而使模型重点关注大量数据中的关键信息,进而提高模型处理长序列数据的能力[20–21]。本文所设计的局部注意力计算模型如图1所示。
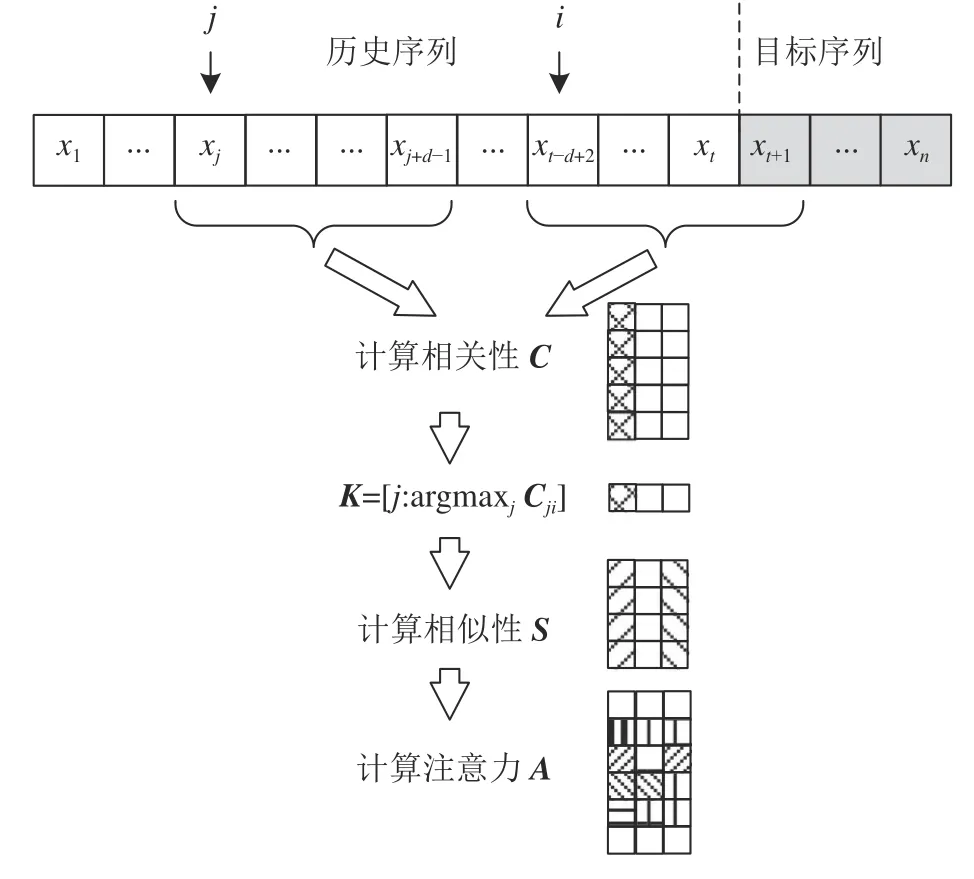
图1 局部注意力计算模型Fig.1 Local attention computation model
图1中,i和j分别为预测数据窗口和历史数据窗口的起始位置,d为窗口宽度。通过不断向前滑动历史数据窗口和预测数据窗口,可计算历史序列{xj,xj+1,···,xj+d−1} 和预测序列{xi,xi+1,···,xi+d−1}之间的相关性:
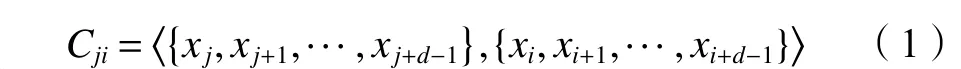
假设K=[j:argmaxjCji]为相关性矩阵C中每列最大元素的索引所构成的行向量,则与预测数据序列{xi,xi+1,···,xi+d−1} 最 相 关 的 历 史 序 列 为{xk,xk+1,···,xk+d−1} , 其中k=Ki。因此,两个数据序列间的相似性度量向量为:
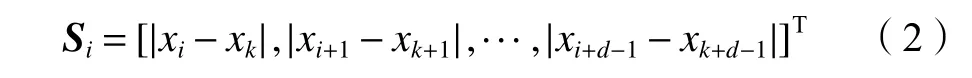
首先,将Si按列排列成相似性矩阵S;然后,利用sigmod函数将S逐列映射至[0,1]区间;最后,利用零填充将映射结果扩展至t行,即可获得所需的注意力度量矩阵A。综上所述,局部注意力计算算法如算法1所示。
算法1局部注意力计算算法
输 入:历 史 序 列 {x1,x2,···,xt} ,目 标 序 列{xt+1,xt+2,···,xn};
输出:注意力度量A;
1. Fori∈[t−d+2,n−d+1]
2. Forj∈[1,i−1]
3.利用式(1)计算Cji;
4.K=[j:argmaxjCji];
5. Fori∈[t−d+2,n−d+1]
6. 利用式(2)计算Si;
7.A=extend(sigmoid(S))。
相关向量机基于稀疏贝叶斯学习理论,具有稀疏表征、核函数不受Mercer条件限制、可提供概率化的预测结果等优点[22],其模型可表示为:
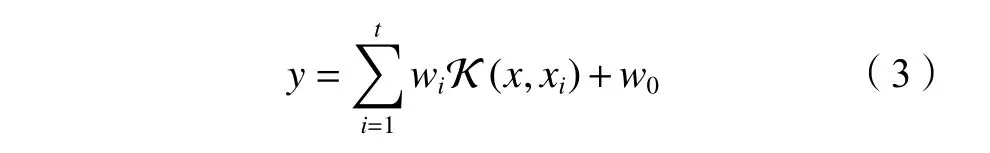
式中:y为预测值;w0为 偏置,wi(i=1,2,···,t)为模型参数,令w=[w0,w1,···,wi,···,wt]T为模型参数向量;K()为核函数。为方便描述,假设ϕ(x)=[1,K(x,x1),K(x,x2),···,K(x,xt)]。 因为w0服 从均值为0、方差为 β−1的正态分布,即w0∼N(0,β−1), 可知y∼N(ϕ(x)w,β−1)。因此,预测值y的条件概率分布为:
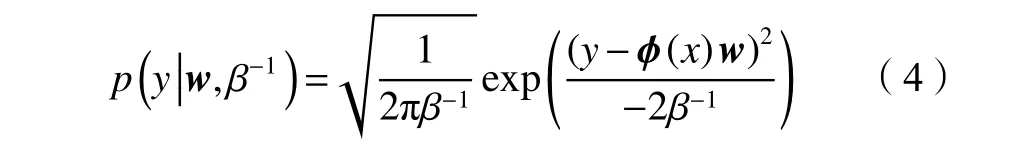
如果采用最大似然法直接对式(4)进行求解,极易出现过拟合现象[23]。为避免此问题产生,通过稀疏贝叶斯学习理论为模型参数w定义了先验分布,即假设wi∼N(0,)。故:

式中, α =[α0,α1,···,αt]T为模型参数,其元素与参数w的元素一一对应。通过在参数 α上增加注意力机制,可将式(5)改写为:
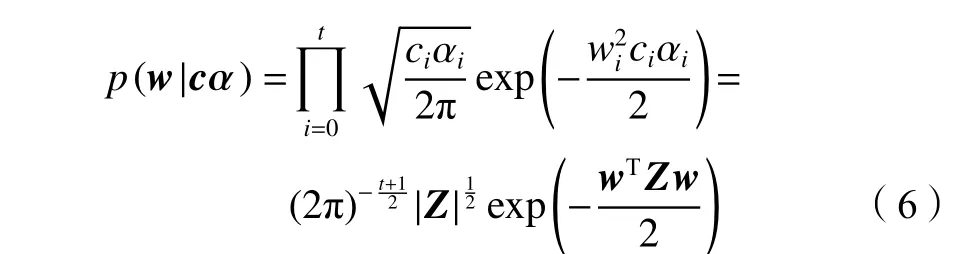
式中,c为注意力度量矩阵A的相应列,Z=diag(cα)为主对角线元素是cα的对角阵。
根据贝叶斯定理,由先验分布和似然估计,可得到参数w的后验分布为:
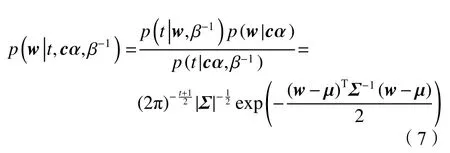
式中, µ=Σϕ(x)Ty/β−1为 后验均值,Σ=(Z+ϕ(x)Tϕ(x)/β−1)−1为后验方差。此时,预测值y的边缘概率密度函数可表示为:
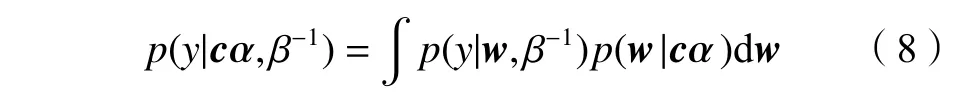
将式(4)和(6)代入式(8)后,对计算结果取对数可得:
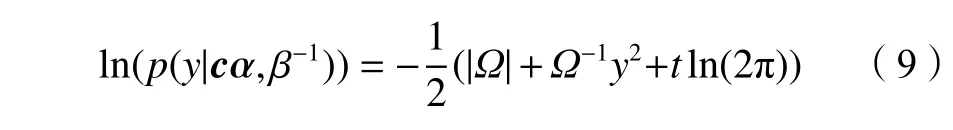
式中,Ω =β−1+ϕ(x)Z−1ϕ(x)T。
为求最优的预测模型参数 α 和 β−1,对式(9)分别求偏导可得:
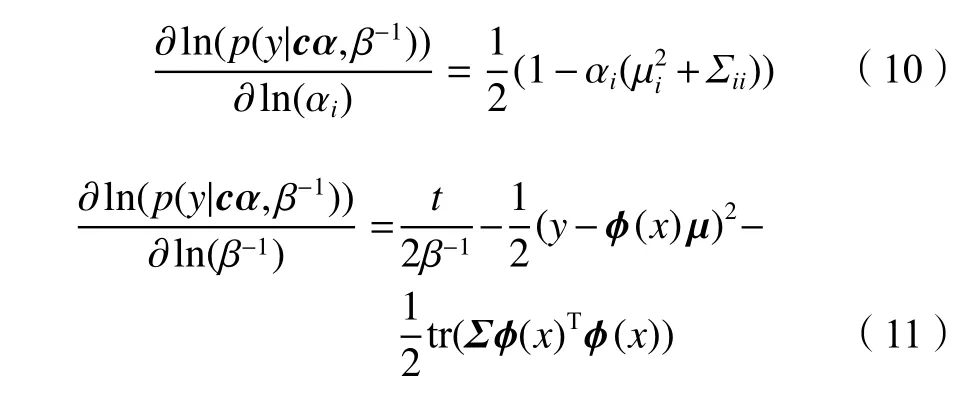
令式(10)和(11)等于零,参数 α 和 β−1的更新公式可表示为:
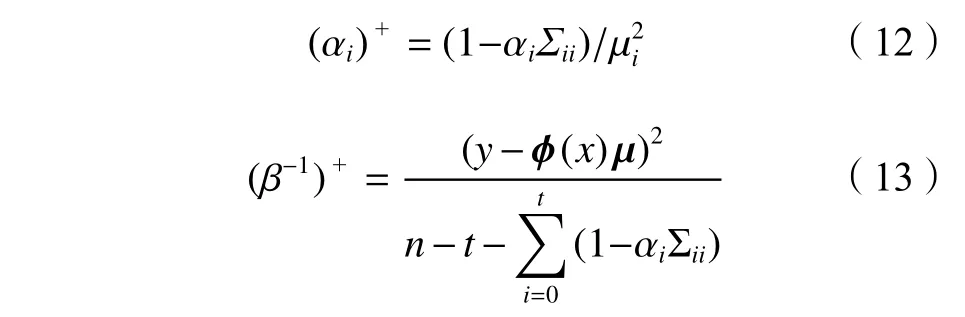
式中, Σii为 Σ的第i个对角线元素。
综上所述,基于局部注意力的相关向量机算法如算法2所示。
算法2基于局部注意力的相关向量机算法
输 入:历 史 序 列 {x1,x2,···,xt} ,目 标 序 列{xt+1,xt+2,···,xn},最大迭代次数I,收敛误差ε;
输出:模型参数 α 和 β−1;
1. 初始化 α为t+1维随机向量, β−1为[0,1]之间的随机标量;
2. 利用算法1计算注意力度量A;
3. While 迭代次数小于I或// α+−α//≥ε:
4. Σ =(Z+ϕ(x)Tϕ(x)/β−1)−1;
5. µ=Σϕ(x)Ty/β−1;
6. ( αi)+=(1−αiΣii)/;
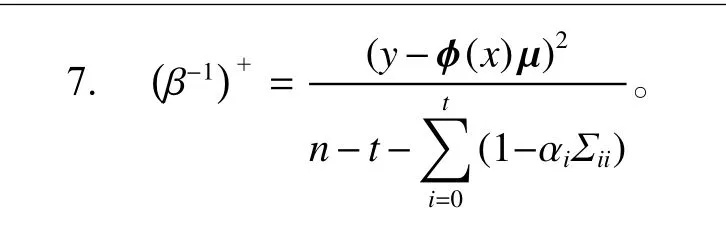
1.2 模型预测阶段
在模型预测阶段,对于新的退化数据x∗,其预测值y∗服从均值为 ϕ (x∗)µ 、方差为 β−1的高斯分布,即y∗∼N(ϕ(x∗)µ,β−1) ,因此预测结果为y∗=ϕ(x∗)µ。令zθ/2为置信水平为1 − θ的分位点, τL和 τU分别为相应的置信下限和置信上限,具体表示如下:

2 实验分析
为了分析ARULP方法的有效性,本文采用西安交通大学滚动轴承加速寿命试验数据集(XJTU–SY数据集)[24]进行验证。该数据集使用轴承加速退化测试平台对型号为LDK UER204的滚动轴承进行性能退化实验,其中包含了轴承的全寿命周期振动数据,收集工况分别为:工况1,频率35 Hz,径向力12 kN;工况2,频率37.5 Hz,径向力11 kN;工况3,频率40 Hz,径向力10 kN;测试轴承的失效部件涵盖了轴承的外圈、内圈、保持架等失效位置。典型的失效轴承类型包括轴承的内圈磨损、保持架断裂、外圈磨损、外圈断裂[25],具体情况如图2所示。

图2 轴承的失效类型Fig.2 Types of bearing failure
XJTU–SY数据集中不同测试轴承的失效位置如表1所示。

表1 测试轴承的失效位置Tab.1 Failure positions of test bearings
实验过程中所对比分析的方法包括:
1)相关向量机RVM。该方法基于稀疏贝叶斯学习理论,利用独立先验分布参数构建预测模型,可提供带置信区间的预测结果。
2)自回归模型AR。该方法利用历史退化数据构建具有随机误差的线性方程,从而表示设备退化状态的回归模型,并根据模型中的回归系数预测系统的状态。
3)自回归移动平均模型ARIMA。该方法包括自回归模型、移动平均模型和差分算子3个子部分,可处理非平稳时间序列数据,构建复杂回归模型并进行状态预测。
4)长短期记忆网络LSTM。该方法利用深度学习的特征抽象和表征能力,结合特殊门限设置可实现长序列数据的学习能力,从而实现对设备的未来状态预测。
实验中的性能度量指标采用相对均方误差(relative mean square error, RMSE)和平均绝对误差(mean absolute error,MAE),其定义分别为:
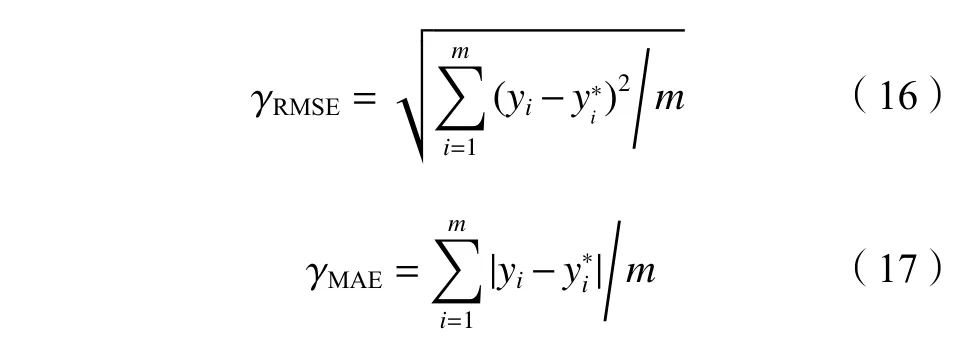
式中,yi和分别为真实数据和预测数据,m为预测数据量。实验过程中,将训练数据集与测试数据集按照7∶3的比例进行划分,历史序列长度t设置为训练数据集长度的1/4,注意力窗口宽度d设置为0.1t,置信水平设置为95%,核函数采用高斯核,故障阈值设置为实验对象正常工作时最大幅值的10倍。
表2和3分别给出了ARULP方法与基准方法在3组不同工况下针对具有不同失效位置的轴承进行预测时的RMSE和MAE结果。由表2和3可知,由于ARULP方法融入了注意力机制,使其具有更高的预测精度,在不同工况和不同故障时其表现都是最优的。
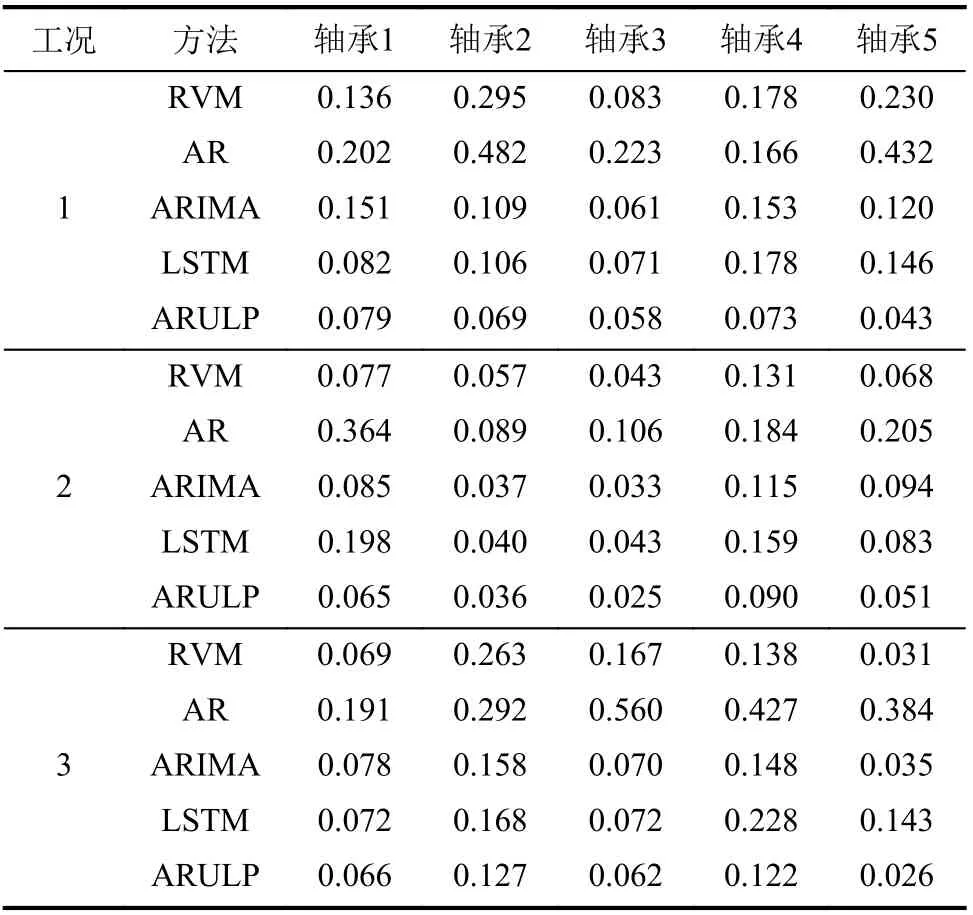
表2 不同预测方法对轴承振动数据预测的RMSE对比Tab.2 Comparison of RMSE for bearing vibration prediction by different methods
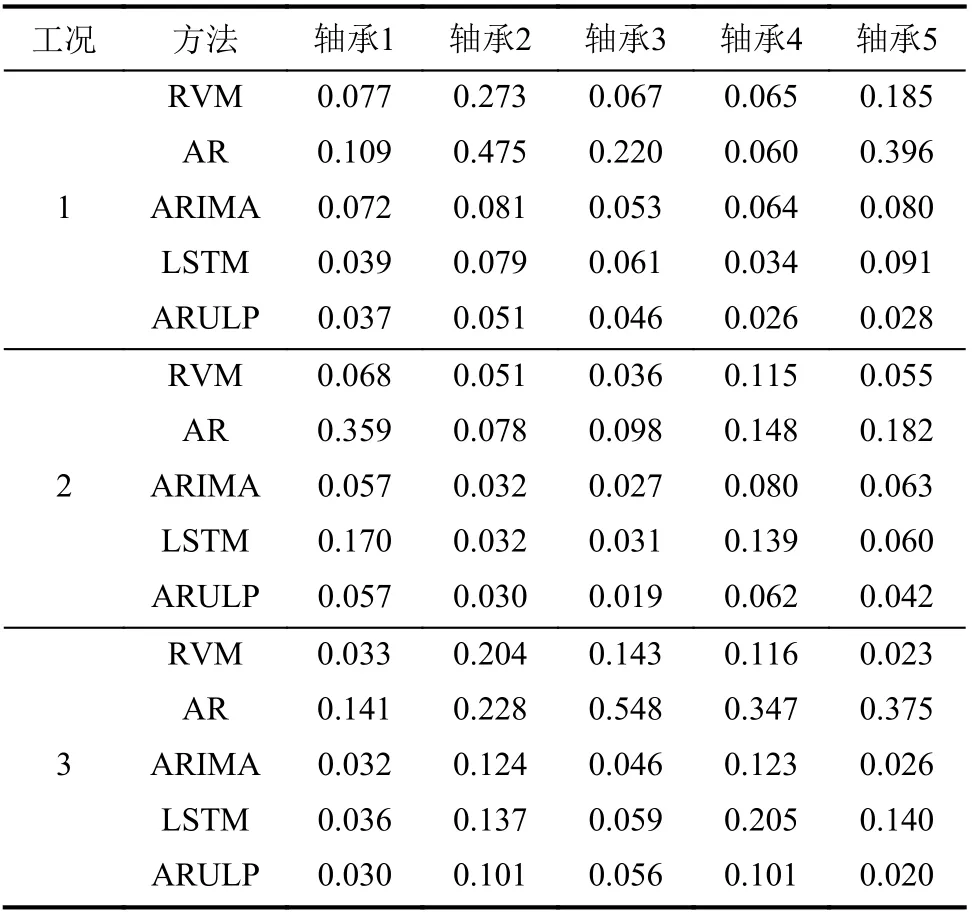
表3 不同预测方法对轴承振动数据预测的MAE对比Tab.3 Comparison of MAE for bearing vibration prediction by different methods
为了衡量不同预测方法针对不同类型的故障进行预测时的实际性能,针对轴承外圈故障、轴承内圈故障和轴承保持架故障使用上述5种预测方法进行了预测,其具体结果对比如图3~5所示。
从图3中可以看出:在轴承外圈故障预测时,本文所提出的ARULP方法的预测结果与轴承实际退化数据最为接近,能够较好地反映故障轴承的退化状态。相比之下,RVM方法的预测误差略高于ARULP方法;AR方法和ARIMA方法只能在一定程度上反映轴承的退化趋势;LSTM方法在预测过程中预测曲线过于平稳,因此会丢失较多的细节信息。
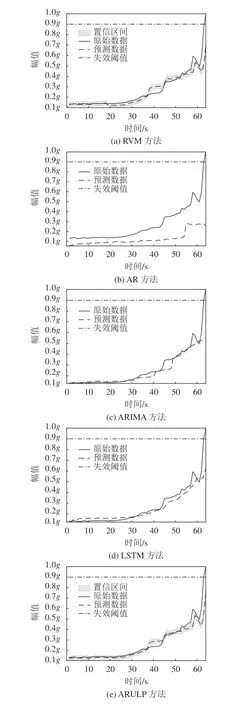
图3 轴承外圈故障不同方法预测结果对比Fig.3 Comparison of outer ring fault prediction results by different methods
从图4中可以看出:轴承内圈故障的振幅曲线比轴承外圈故障抖动得更加剧烈,因此在该类故障下进行数据预测时更加困难。在该故障下,ARULP方法的预测结果更加贴近实际数据。相比之下,RVM方法的预测结果稍逊于ARULP方法;AR方法在此故障模式下具有较差的预测结果,预测误差间隔较大;ARIMA方法和LSTM方法的预测曲线较为平缓,无法反映细节预测信息,最终的剩余寿命预测结果和实际情况出入较大。
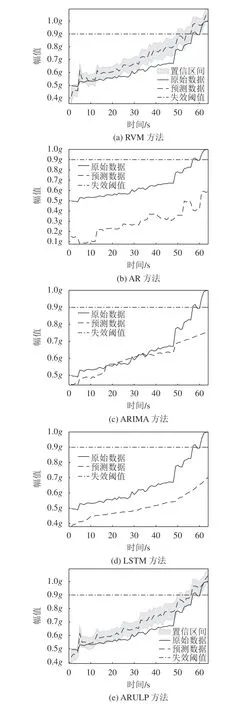
图4 轴承内圈故障不同方法预测结果对比Fig.4 Comparison of inner ring fault prediction results by different methods
从图5中可以看出:轴承保持架故障发生时,实际退化数据的曲线振幅抖动情况最为剧烈。本文所提出的ARULP方法在该故障模式下依然具有明显的预测精度优势。相比之下,RVM方法和AR方法的预测结果与轴承实际退化数据的差距较大,ARIMA方法和LSTM方法的预测细节丢失情况依旧显著。
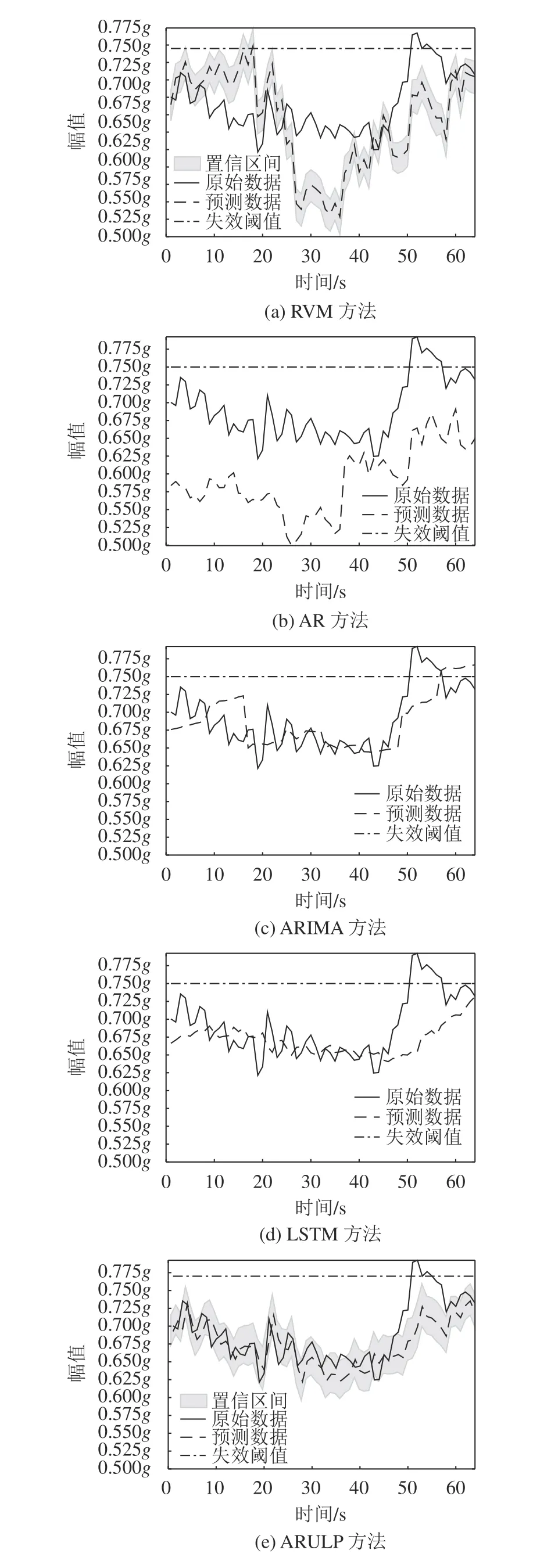
图5 轴承保持架故障不同方法预测结果对比Fig.5 Comparison of cage fault prediction results by different methods
3 结 论
针对如何预测工业物联网中的设备剩余使用寿命问题进行研究,采用局部注意力机制和相关向量机,提出一种有效的设备剩余使用寿命预测方法。通过分别设计局部注意力计算算法和基于局部注意力的相关向量机,并将局部注意力机制有效融入设备的状态预测模型,使其能对预测模型中的参数自适应学习,从而实现对设备剩余使用寿命高精度预测。通过与多种基准方法在XJTU–SY数据集上进行对比实验,表明了所提方法的有效性。下一步研究方向将重点考虑如何提高设备剩余使用寿命预测方法的效率。
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22
舰船科学技术(2022年10期)2022-06-17
哈尔滨轴承(2022年1期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
哈尔滨轴承(2021年2期)2021-08-12
哈尔滨轴承(2021年1期)2021-07-21
传媒评论(2017年3期)2017-06-13
电子制作(2017年8期)2017-06-05
中国自行车(2017年1期)2017-04-16
中国公路(2017年12期)2017-02-06
