
基于SVM融合学习的电子档案资源自动化分类方法*
2022-11-28 09:28张君
自动化技术与应用 2022年10期
张君
(南方电网数字电网研究院有限公司,广东 广州510000)
1 引言
档案是记录个人、公司、国家机关以及各类集团组织的重要文件,在生产、生活及社会活动中具有关键性的地位[1]。当前社会已经进入云计算时代,在这个背景下,档案由传统的纸质版本,转变成电子版,当前大多数档案均采用云存储方式保管,形成存储在数据库中的电子档案,以此保障档案资源调取的便捷性、灵活性和全面性[2]。然而,根据档案的形式、性质、载体、所有制等,可以将档案分为多种类别,在存储电子档案时,却存在档案类别不清晰的问题,影响档案收录[3]。因此,电子档案资源分类已成为时下研究热点问题。
国内外都十分重视档案资源,针对档案资源管理模式和基础理论,进行了多方面的研究。然而,针对近期才发现的电子档案资源分类存在的问题,研究成果相对薄弱,缺乏系统的电子档案资源分类研究[4]。基于此,文献[5]将城市轨道交通建设项目档案作为研究对象,根据相关规范,设计档案资源分类方法,并与目前机构使用方法进行对比,验证设计方法的可行性,但该方法分类精度较低。文献[6]根据档案数据语义,分析档案内容,实现档案的全自动分类,但该方法受算法训练次数影响,分类精度偏低。文献[7]提出基于泊松分布的特征加权NB 文本分类算法。结合泊松分布模型和NB算法,将泊松随机变量引入特征词权重,在此基础上定义信息增益率对文本特征词加权,完成档案资源分类。但该方法难以划分档案资源非线性特征,导致档案资源分类精度低。
针对这一问题,此次研究采用SVM 融合学习技术,提高电子档案资源分类精度,提出基于SVM融合学习的电子档案资源自动化分类。
2 基于SVM融合学习的电子档案资源自动化分类
2.1 采集电子档案资源
电子档案资源分布较广,需要采集所有档案资源,形成完整的档案资源集,为此,将已标记的档案资源集,记为X1={(x1,y1),…,(xn,yn)},其中,yi表示第i个档案资源数据的标记,构建档案资源标记矩阵R,则有:
式(1)中,κ表示矩阵的特征值;p表示矩阵第j行档案资源节点vj标记概率。
如式(1)所示的档案资源标记矩阵[8],当R=0时,档案资源节点表示不完整档案资源,反之,R=1。此时,将档案资源标记矩阵R,作为采集少数档案资源数据边界的一个标记。
根据式(1)所示的标记矩阵R,将零散的档案资源,分为标记的少数档案资源R1和未标记的少数档案资源R2两种,从R2中寻找对应的标记样本的近邻样本,来合成完整的档案资源集,则档案数据资源边的权重lij计算公式为:
式(2)中,k表示以欧几里德距离为标准,寻找与标记的档案资源样本集[9],近邻连接档案资源;xi、xj表示相邻的档案资源,且成立。
根据式(2)所示的计算过程,将档案资源中的未标记资源记为X2={(xl+1,yl+1),…,(xl+m,yl+m)},其中,l表示档案资源采集边界,m表示未标记档案资源数量。按照上述过程,找到的档案资源,多位于档案资源标记矩阵R的附近。因此,将采集到的档案资源,与原档案资源集相结合,形成完整档案资源集X。
2.2 电子档案资源特征提取和选择
依据此次研究,采集到的档案资源集X,通过特征提取和选择的方式,对档案资源进行降维处理。假设,档案资源集X,具有的资源特征集为A={a1,a2,…,aN},其中,N表示档案资源集所具有的特征总数。由于档案资源集中,具有N个资源特征,一一提取每一个特征,所需计算量过大[10],因此,只能选择档案资源中的最优特征来提取,则档案资源特征选择的过程如图1所示。
图2中,获取到的档案资源最优特征子集为A1={a1,a2,…,aM},且
在图2的档案资源特征选择[11]过程,选择到的档案资源特征进行提取,其档案资源特征提取过程如图2所示。
图2中,newaM表示档案资源中的最优特征子集,其中,M表示最优特征子集个数,且M<N,ai≠newa,i=1,2,…,N,j=1,2,…,M。
依据上述的档案资源特征选择和提取过程,存在一定的不相关、冗余等档案资源特征属性,针对这些属性,进行删除处理,来降低自动化分类电子档案资源计算量。
2.3 基于SVM融合学习自动化分类电子档案资源
对于本次研究待提取和分类的档案资源特征,采用SVM融合学习技术,构建SVM融合学习分类器,自动化分类电子档案资源。SVM融合学习技术分类原理如图3所示。
图3中,分割点连接线,为电子档案资源,距离档案资源分割线L距离最近的两个点的连接线,将其分别记为L1和L2,则分割线与两条分割点连接线,存在平行关系。如图3所示,依据SVM 融合学习自动分类电子档案资源原理,按照该融合学习理论的风险最小化求解模型,让电子档案资源根据其特征,准确在分割线作用下,分割成两类电子档案资源,且在分割的过程中,还需保证被分割的电子档案资源具有足够的距离,形成最优分类面,则需要计算SVM分类器最优超平面。
假设,此次研究,采集到的电子档案资源数据集X,属于d维空间数据,在SVM分类器中,自动化分类电子档案资源的线性判别函数f(x)为:
式(3)中,w表示分类间隔;c表示截距[12]。当wx+c=0 成立时,则wx+c=0为电子档案类别之间的分界面表达式。
根据式(3)所示的电子档案资源划分线性判别函数f(x),需要满足(4)式所示的表达式,才能促使电子档案资源分类正确,其表达式如下式所示:
式(4)中,T表示矩阵转置[13]。依据式(3)和式(4),可以将电子档案资源划分在两个平面中,此时,需要让划分成两部分的电子档案资源中间,具有较大的分类间隔,即取的最小值:
式(6)中,sgn表示取整数值;x表示未分类电子档案资源。如式(6)所示的SVM融合学习分类器,只可以分类线性电子档案资源。为了分类电子档案资源中存在的非线性特征,在式(6)中,引入核函数Φ,将非线性特征分类,转化为线性特征分类,则核函数Φ的转化运算过程如下式所示:
式(7)中,υ表示核函数Φ将非线性特征分类,转化为线性特征分类运算符号。联立式(6)和式(7),最终得到的SVM融合学习分类器[15](x)为:
采用式(8)所示的SVM融合学习分类器,即可根据此次研究,选择提取的电子档案特征,将电子档案分成不同的类别。
此次研究将数据库中的电子档案资源整合成档案资源集,从档案资源集中选择提取电子档案资源重点特征,根据选择提取的电子档案特征,采用此次研究构建的分类器,自动化分类电子档案资源。
3 实验分析
选择文献[6]和文献[7]方法作为实验的对照组,与所提方法的实验结果进行对比。将某数据库中的电子档案资源,作为此次实验研究对象。比较三组方法的划分电子档案资源精度、召回率以及F1值。
3.1 实验准备
此次实验选择的电子档案资源数据集,共包含810个数据,其数据类别为9类,每个类别所包含的数据个数,如图4所示。
在如图4所示的档案资源类别分布基础上,选择当前分类通用评价标准--准确率、召回率、F1 值三个评价指标,评价此次实验选择的三组分类方法,分类图4所示的电子档案资源精度。其准确率、召回率、精确度三个评价指标的分类评价指标定义,如表1所示。
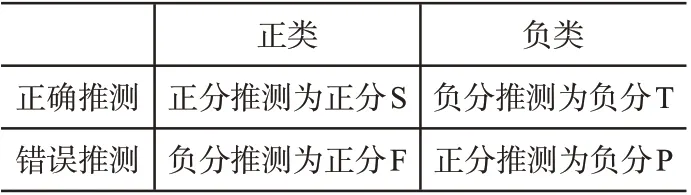
表1 分类评价指标定义
根据表1所示的分类评价指标定义,其准确率、召回率、精确度的参数公式,如下式所示:
采用式(9)所示的分类性能指标计算公式,计算此次实验选择三组分类方法,分类电子档案资源810个数据的准确率、召回率、精确度,其实验结果如下。
3.2 实验结果
3.2.1 第一组实验结果
根据此次实验选择的810个电子档案资源数据,采用三组分类方法,分别划分810 个电子档案资源类别,计算三组分类方法,类别划分准确率,其实验结果如图5所示。
从图5中可以看出,三组分类方法,分别将此次实验选择的810 个电子档案数据进行分类处理,其分类准确率,受每个类别所具有的档案数据个数影响,每个类别中,档案数据个数越少,电子档案资源分类准确率越高。其中,两组目前方法,划分810 个电子档案数据类别准确率相近,其平均准确率分别为79%和77.5%;研究方法划分810个电子档案数据类别,平均准确率为88.75%,较两组目前方法分别高9.75%和11.25%。可见,此次研究的分类方法,具有较高的分类精度。
3.2.2 第二组实验结果
在第一组实验基础上,计算三组分类方法,类别划分召回率,其实验结果如图6所示。
从图6中可以看出,三组分类方法,分别将此次实验选择的810 个电子档案数据进行分类处理,其分类召回率,受每个类别所具有的档案数据个数影响,每个类别中,档案数据个数越多,电子档案资源分类准确率越高。其中,两组目前方法,划分810 个电子档案数据类别召回率相近,其平均召回率分别为79.75%和79%;研究方法划分810个电子档案数据类别,平均召回率为89.95%,较两组目前方法分别高10.2%和10.95%。可见,此次研究的分类方法,具有较高的分类精度。
3.2.3 第三组实验结果
在前两组实验基础上,计算三组分类方法的类别划分F1值。F1值是对分类的准确率和精确度的调和值,其评价结果具有较高的客观性和准确性。其实验结果如图7所示。
从图7中可以看出,三组分类方法,分别将此次实验选择的810 个电子档案数据进行分类处理,得到的F1 值同样受每个类别所具有的档案数据个数影响,上下差值较大。其中,两组目前方法,划分810 个电子档案数据类别F1值相近,其F1值的平均值分别为81.95%和81%;研究方法划分810 个电子档案数据类别,F1 值的平均值为91%,较两组目前方法分别高9.05%和10%。可见,此次研究的分类方法,具有较高的分类精度。
4 结束语
综上所述,此次研究采用SVM 融合学习技术,构建自动化分类器,实现电子档案资源自动化分类。采用通用分类方法验证方式验证,此次研究的电子档案资源自动化分类,划分电子档案资源类别,具有较高的分类精度。
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
少儿画王(3-6岁)(2020年4期)2020-09-13
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
少儿科学周刊·少年版(2015年3期)2015-07-07
