
基于机器学习的糖尿病肾病风险预测模型研究
2022-11-21 02:27:24徐澄,彭丹
无线互联科技 2022年17期
徐 澄,彭 丹
(徐州医科大学附属医院,江苏 徐州 221000)
0 引言
糖尿病肾病是糖尿病最常见的并发症之一,易引发终末期肾病,给患者的身体健康带来极大损害[1]。进行糖尿病肾病风险预测模型研究,实现对糖尿病肾病的早发现、早干预、早治疗,能够在诊疗活动中为医生提供帮助,减少患者的痛苦。机器学习即设计算法,通过对输入的数据自动学习,建立相关模型,实现对新的数据进行预测[2]。相关患者在就医过程中留下了海量数据,包括患者的基本信息、临床检查检验结果、治疗记录、医疗文书、病历等,为机器学习的研究提供了丰富的资料。本文从中收集、分析和筛选出糖尿病肾病的影响因素,建立临床数据集,利用机器学习算法建立风险预测模型,辅助医生进行糖尿病肾病诊断。
1 资料与方法
1.1 资料来源
数据来源于徐州医科大学附属医院内分泌科,时间跨度范围2020年4月至2021年11月,参阅病历4 231份,共纳入1 351个案例。分为糖尿病组682例和糖尿病肾病组669例。案例纳入标准:(1)患者符合2型糖尿病诊断标准,参照2020 版《中国2型糖尿病防治指南》中糖尿病诊断标准[3];(2)患者符合糖尿病肾病诊断标准,参照2019 版《中国糖尿病肾脏疾病防治临床指南》中糖尿病肾病诊断标准[4]。排除标准:(1)患者一年内重复入院只收集第一次入院数据;(2)患者病历不符合质量控制标准,有严重质量缺陷;(3)患者患有除糖尿病肾病以外其他严重肾脏损伤疾病。满足任何一项排除标准的患者被排除。通过查阅相关文献资料[4],结合专家访谈和临床实践经验,考虑到医院实际开展检验检测项目和患者临床诊疗情况,每个患者纳入55个风险因素。本研究已通过徐州医科大学附属医院伦理委员会审查,审查编号:XYFY2022-KL203-01。
1.2 统计方法

1.3 机器学习方法
近年来机器学习领域的研究与应用取得了巨大的进展。机器学习用于疾病预测诊断是使用机器学习领域有监督学习中分类方法,过程是将数据集划分为训练集和验证集,利用训练集建立模型,通过验证集评估模型[5]。机器学习的推理过程与医生对疾病的诊断过程是非常相似的,都是基于现有有限的信息,对未知的情况做出分析预测。本研究使用到的机器学习算法有:
(1)K近邻(K-Nearest Neighbor,KNN)。是一种基本分类方法,通过测量不同特征值之间的距离进行分类。思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
(2)逻辑回归(Logistic Regression,LR)。是一类比较特殊的分类算法,名字中带有“回归”,实际上用于解决分类的问题,其解决问题的思路还是参照回归的思路。逻辑回归算法的核心思想就是在空间中找到一条线(面),按照待定位点与分界线(分界面)的相对位置进行分类,其处理二分问题阶跃函数普遍使用Sigmoid函数。
(3)决策树(Decision Tree,DT)。是一种基本的分类方法,从根节点开始,对实例的某一特征进行测试,根据测试结果将实例分配到其子节点,此时每个子节点对应着该特征的一个取值,如此递归地对实例进行测试并分配,直到到达叶节点,最后将实例分到叶节点的类中。
(4)随机森林(Random Forest,RT)。随机森林由多个决策树组成,采用多个决策树的投票机制来改善决策树,是以决策树为估计器的Bagging算法。
(5)提升算法(AdaBoost)。是一种重要的集成学习技术,能够将预测精度仅比随机猜度略高的弱学习器增强为预测精度高的强学习器,这在直接构造强学习器非常困难的情况下,为学习算法的设计提供了一种有效的新思路和新方法。
(6)支持向量机(Support Vector Machine,SVM)。是寻找一个能最大化训练数据集中分类间距的超平面来给数据分类(超平面即n维空间中的n-1维空间)。当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性支持向量机,可以将训练样本从原始空间映射到一个更高维的空间,使得样本在这个空间中线性可分。
(7)朴素贝叶斯(Naive Bayes,NB)。是以贝叶斯定理为基础的分类算法,思路是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
(8)前馈神经网络,又称多层感知机(Multilayer Perceptron,MLP)。神经网络可以视为由一系列互相连接的层组成的网络,它的一端连接一个观察目标的特征值,另一端连接着对应的目标值(如分类标签),中间是隐藏层,其实质是线性模型的扩展和深化。
1.4 评价标准
评估模型性能的主要指标有准确率、精确度、召回率和F1分数(F1 score)等[6],此外通过受试者工作特征(Receiver Operating Characteristic,ROC)曲线可以直观观察模型性能,ROC曲线下的面积(Area Under Curve,AUC)被定义为ROC曲线下与坐标轴围成的面积,AUC的取值范围在0.5和1之间,AUC越接近1.0,检测方法真实性越高。将数据集拆分成训练集和测试集两部分,采用K-折交叉验证法,代入模型获取评分,选取预测能力最好的模型。
2 结果
2.1 数据预处理
依据患者资料整理生成数据集共包含1 351个样本,每个样本包含55个特征。数据集中数据存储方式为二维表形式,表中每一行对应一个样本(一个患者),每一列对应一个特征(如年龄、身高、体重等)。表结构满足数据库第一范式(1NF)。数据集中特征包括计量资料和计数资料。计量资料包括年龄、身高、体重、体重指数(BMI)、血压等有连续数值的数据,即数值变量;计数资料在本研究中可以认为是分类资料,包括性别、籍贯、婚姻史、是否患有糖尿病肾病等分组数据,即分类变量。对数据集进行预处理,包括重复数据删除、异常值校验纠正、缺项数据填充等,保证数据的完整性和一致性,提高数据集质量,减少因数据集自身问题对预测模型的影响。
2.2 特征筛选
糖尿病肾病的发生与许多因素有着潜在联系,而医院数据包含了患者详细信息,往往是高维的,通过特征筛选,可以去除掉对模型预测结果影响不大的特征,降低算法的计算开销,提高算法性能。
本文利用Logistic回归进行特征筛选。使用SPSS软件二元Logistic回归处理,结果如表1所示。

表1 Logistic回归结果分析

续表1
在所有特征中,糖尿病病程、视网膜病变、尿肌酐、尿免疫球蛋白G、尿微量白蛋白、a1-微球蛋白、尿酸、肾小球滤过率(eGFR)、中性粒细胞计数9个特征P<0.05,与糖尿病肾病的发生有显著性联系,纳入风险预测模型训练集中。
2.3 构建模型
本研究中,机器学习算法实现和建模使用Python语言编译。机器学习算法使用Python机器学习库Scikit-learn[7],Scikit-learn是基于 Python 语言的机器学习工具,是机器学习中的常用第三方模块。建模过程将数据集按照8-2比例拆分成训练集和测试集两部分,利用训练集训练机器学习模型,利用测试集进行验证,选取预测能力最好的模型。为减少偶然性,采用K-折交叉验证法,代入模型获取评分,计算模型评价指标平均值。建模过程建立算法管道模型,将数据预处理、模型训练、参数调优等过程链接在一起,形成流水线模式,减少代码复杂度,提高运行效率。
2.4 模型比较
研究使用K近邻、逻辑回归、决策树、随机森林、提升算法、支持向量机、朴素贝叶斯和前馈神经网络8种算法建模,对建立的模型经10折交叉验证,得到模型的准确率、精确度、召回率和F1分数作为评价标准,绘制其ROC曲线并计算AUC值,从中选择预测效果最好的模型。评价标准结果如表2所示。

表2 模型比较
同时绘制AUC较高的4种模型ROC曲线,如图1所示。
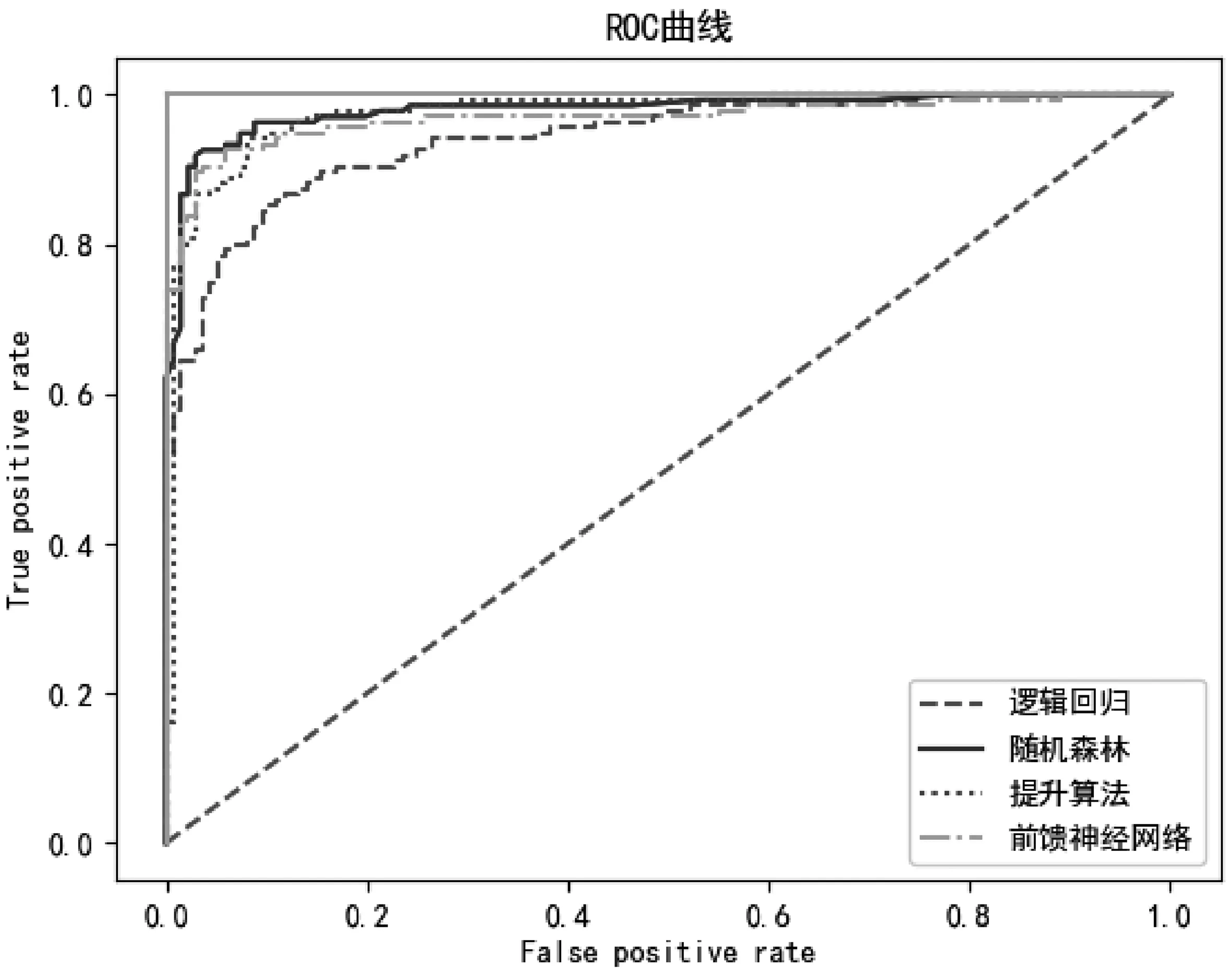
图1 模型ROC曲线
在所有算法中,准确率最高的是随机森林算法,达到92.74%,提升算法、决策树和前馈神经网络预测准确率也达到90%左右;精确度最高的是朴素贝叶斯算法,达到93.53%,随机森林、提升算法和前馈神经网络均达到90%以上;召回率最高的是提升算法,达到91.87%,随机森林和其接近,达到91.72%;F1分数最高的是随机森林算法,达到0.924 8,提升算法也达到0.917 4,其他算法有一定差距;AUC最高的是随机森林算法,达到0.980 2,逻辑回归、提升算法、支持向量机、朴素贝叶斯和前馈神经网络达到0.9以上。综合5个评价标准,可以得出利用随机森林算法建立的模型预测效果最好。
3 结语
本文研究了利用机器学习算法建立糖尿病肾病风险预测模型。数据来源于医院病历,基于患者就诊信息,建立了糖尿病-糖尿病肾病患者数据集,共纳入1 351个样本。使用Logistic回归进行特征筛选,从55个特征中筛选出糖尿病病程、视网膜病变、尿肌酐、尿免疫球蛋白G、尿微量白蛋白、a1-微球蛋白、尿酸、肾小球滤过率(eGFR)、中性粒细胞计数9个糖尿病肾病影响因素,并纳入模型训练集。使用K近邻、逻辑回归、决策树、随机森林、提升算法、支持向量机、朴素贝叶斯和前馈神经网络8种算法建立模型,进行10折交叉验证,从准确率、精确度、召回率、F1分数和AUC值5个方面进行比较,并绘制其ROC曲线,得出结论使用随机森林算法建立的模型预测效果最好。最终得到的模型预测准确率达到92.74%,在2型糖尿病患者人群中可以实现糖尿病肾病风险精准预测,对糖尿病肾病早期诊断提供帮助。许多算法具有超参数(如随机森林算法中决策树的数量、神经网络算法中层数和节点数),通过参数调优可以提高算法性能,下一步研究将对建立的模型进行参数调优和模型融合,进一步提升模型预测效能。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
中老年保健(2021年4期)2021-08-22 07:07:58
基层中医药(2020年11期)2021-01-18 06:55:30
保健医苑(2020年1期)2020-07-27 01:58:20
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
基层中医药(2018年7期)2018-12-06 09:25:32
电子制作(2018年16期)2018-09-26 03:27:06
电影(2018年8期)2018-09-21 08:00:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
