
基于深度学习的邮件自动分类模型研究
2022-11-21 02:27:40张春玲向洪波杨新年秦春波孙世光
无线互联科技 2022年17期
张春玲,向洪波,杨新年,秦春波,孙世光
(黑龙江工业学院 电气与信息工程学院,黑龙江 鸡西 158100)
0 引言
秋冬季节,鸡西地区快递公司每日出口邮件约100万件,进口200~300万件。在鸡西邮件处理中心,转运人员需要将进口的所有车辆上的邮件按照地址分到所属区县,再由趟车将这些邮件运输到对应位置进行投递[1]。营投人员需将每日收寄的邮件按出口省份进行分拣,装上对应车辆。双11、双12期间邮件暴增,这使转运人员负载过重、不能及时处理邮件,导致客户反应时效性较差。另外,雨雪天气[2]、高速封路等原因也会导致在许多邮件在邮件处理中心积压[3]。为了解决上述问题,快速、准确地实现邮件的自动分拣已经成为亟须解决的问题。本文提出了基于图像的邮件分类模型,通过给定图像,机器就可以实现自动分类,从而实现对邮件分拣。该方法与传统手动分拣相比耗时少、成本低,有利于提高客户体验[4]。
1 图像采集
本文采集鸡西进口邮件900余件。进口邮件需要按所属区县进行分类,主要分为鸡冠区、恒山区、城子河区、滴道区、梨树区、麻山区、鸡东县、密山县、虎林9个区域。按地域随机提取每个区域邮件100个。在邮件上做好标注后,将电子面单撕下、带回。用打印机扫描得到每个区域电子面单图像100个,共计900个数字图像。建立9个地区的邮件面单文件夹,用于处理。
2 图像预处理
(1)环境准备:安装anoconda 3.7,pycharm 用于编译和集成的实验环境。安装 TensorFlow,requests,numpy,seaborn,pandas,keras等用于深度学习的包。
(2)样本均衡:样本平衡与否直接关系模型预测准确度。在训练时,如果某一类样本数量较多,会导致模型准确度不高。为了防止9个不同地域样本出现不均衡的情况,常用的解决数据不平衡问题的方法有上采样和下采样[5]。上采样是通过增加样本个数达到平衡的一种方法,增加少量的样本个数使样本数达到均衡。下采样是减少样本的个数,从较多的样本中抽取一部分,使其与少数类别的样本达到平衡的状态[6]。
(3)训练集和预测集构建:为了便于评估模型预测的性能,需要建立训练集和测试集。在处理时,保留原有图像文件。单独建立训练集和测试集文件夹。为了使抽取的图像具有随机性,将每个类别的图像文件名顺序打乱。选取前20%作为测试集,其余80%作为训练集。这样训练集和测试集下各有9个文件夹。
(4)数据增强:为了增加模型泛化能力,防止因图像模糊、方位变换等问题[7],导致在测试时,不能准确识别未知图像的问题。需要对训练集数据进行旋转、平移、缩放等处理,增加不同类别训练数据集泛化能力。
(5)图像剪切:将训练集、测试集及数据增强后图像调整至一致大小400 px×300 px。为了提高邮件分类准确率,对图像进行剪切。选取图像中间的有收件人位置的信息图像,裁剪位置为(width/2-112,height/2-112,width/2+112,height/2+112) px。剪切后的图像变成224 px×224 px大小图像,将剪切后图像重新存储。
(6)数据加标签:训练数据集和测试数据集下图片建成2个csv文件,csv文件中包含图像数据和标签数据。图像数据是读取的训练和测试文件夹下图像数据,而标签数据是根据分类好的文件夹进行人为设定,每个类别对应标签为1~9。
3 卷积模型及优化
3.1 VGG模型复杂度
Vgg16是卷积网络的一种,16是指含有权重的卷积层和全连接层层数,而不是全部层数。图像经过13个卷积层[9],2个全连接层,1个输出层,如表1所示。通过4个池化层,图像的维数从开始224 px×224 px变成7 px×7 px,虽然图像维数有所减少,但图像的通道数逐渐增加,用于提取图像的特征越来越多。VGG是深层网络,网络参数非常多,参数数量=图像像素大小×上层通道数×本层通道数。因为深度学习计算量大、内存占用较高、训练速度慢,所以一般采用训练好的模型进行预测或在训练好的模型上进行精调。卷积神经网络虽然准确率较高,但模型参数较多、训练起来难度大。VGG一共16层,参数达到96 M,极大浪费内存[10]。因此使用已经训练好的预定义模型来进行预测比较简单。

表1 VGG模型结构及参数
3.2 模型构建
迁移学习是将已经训练好的模型用于未知数据集上,主要是将已经训练好的网络前n层复制到目标网络中,剩下的层开始训练。但为了防止过拟合,通常根据目标数据集的大小选择是否冻结前n层的参数。
由于VGG模型参数较多,可以在训练时采用网络上已经训练好的模型权重进行初始化以减少训练时间。本文在电子面单分类时,对VGG模型结构进行调整。使调整后模型结构图含有卷积层、池化层、全连接层和输出层,如图1所示。调整结构时,保留用于提取图像特征的卷积和池化层 、删除原来1 000个类别的输出层。重新建立预测模型,在最后一个输出为4 096的全连接层上增加2个新的全连接层,分别是单通道输出为256的全连接层,单通道输出为9的输出层。随机丢弃比率dropout为设为0.5,调整后模型结构如图1所示。
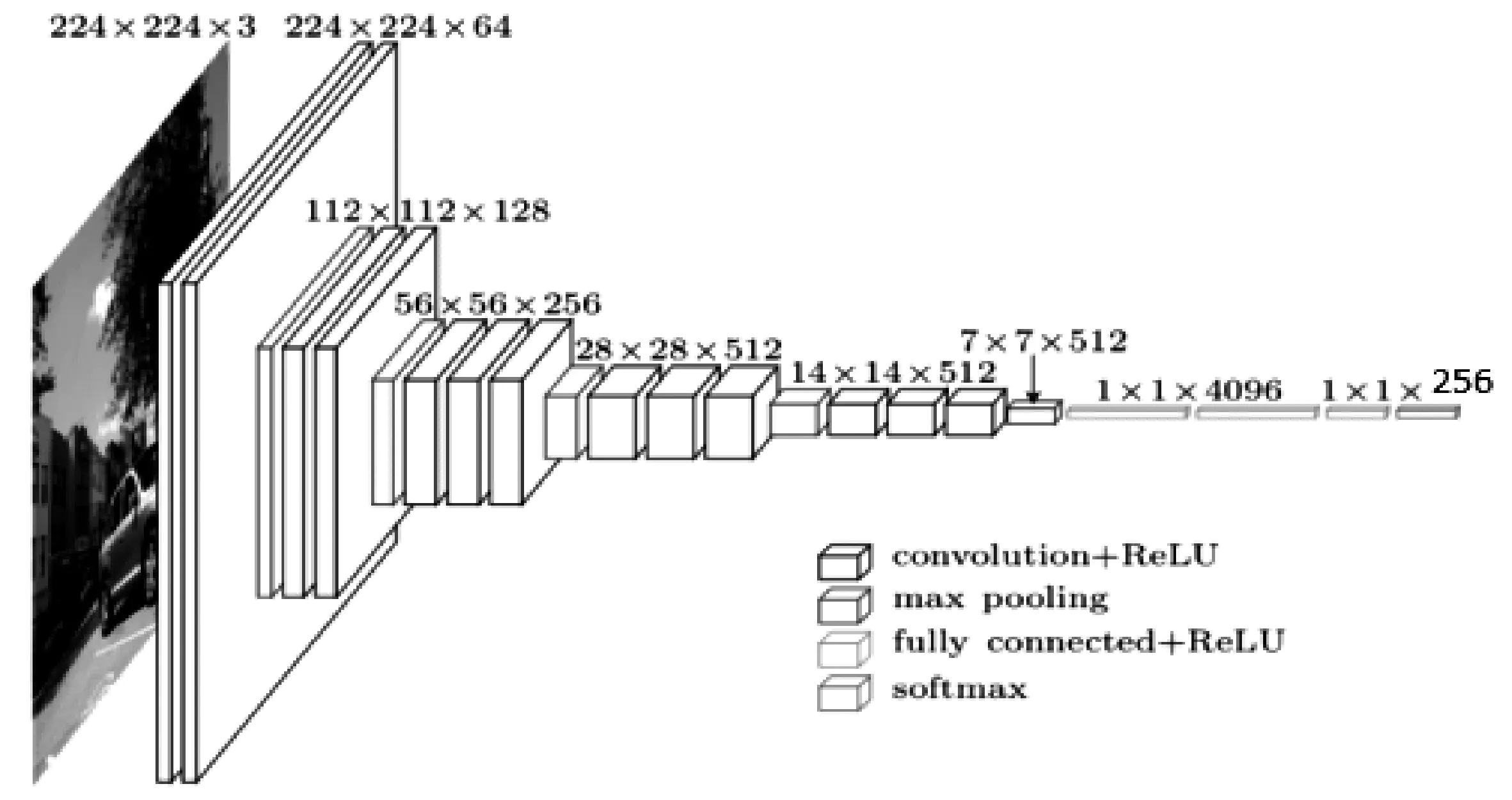
图1 调整后VGG模型结构
3.3 调整模型参数
3.3.1 调参步骤
卷积神经网络通过正向传播获得损失函数的值,反向传播更新参数。通过设定的轮数,来控制迭代的次数。具体求解过程如下:
(1)随机初始化所有卷积层和全连接层的权重。
(2)根据输入的图像和初始化的权重通过前向传播得到网络的输出,计算分类的概率,概率最大的类别为对应的图像类别。
(3)根据损失函数确定网络的损失,分类采用交叉熵损失。损失函数表示如下:
说明:i表示样本下标,j表示类别下标。p表示标签值,q表示预测概率,m为样本数900,n为类别数9。
(4)Adam算法是动量法与RMSprop算法的结合,动量法从方向上改进,而RMSprop从学习率上进行改进。具体如公式(1)所示:
v(t)=ρ1v(t-1)-(1-ρ1)g(t)
s(t)=ρ2+(1-ρ2)g(t)⊗g(t)
(1)
说明:g为通过反向传播求得,ρ1,ρ2,ε,w(0)为常数。
w(t+1)是根据w(t)计算的结果,通过迭代,对权重w进行更新,使得更新后模型的分类损失逐渐减小,直至最小,最终确定模型参数。
3.3.2 卷积层
卷积层为局部感受野范围内元素与卷积核的线性叠加,是对应元素先相乘后相加的结果。卷积层为线性变换,矩阵展开式如公式(2)所示:
net11=a11w11+a12w12+a21w21+a22w22
net12=a12w11+a13w12+a22w21+a23w22
net21=a21w11+a22w12+a31w21+a32w22
net22=a22w11+a23w12+a32w21+a33w22
(2)
根据输入图像按不同等级的分类输出,除了线性变换外,还需要非线性变换的激活函数relu,激活函数矩阵如公式(3)所示:
(3)
参数说明:a为正向传播上层计算结果,计算当前层时已经确定值,w为对应权重,net为线性叠加结果,σ为激活函数。
为方便计算权重w梯度,引入误差项,其含义为损失函数对当前净输入的偏导数,即损失函数对激活层之前的数值net求偏导。根据链式求导法则,得出对l层误差项=l+1层误差项×权重矩阵w×激活函数的导数,如公式(4)得到每层误差项的关系。
δ(l+1)W(l+1)σ′(net(l))
(4)
说明:反向传播,从后向前传递。求l层误差项,由l+1层误差项和l+1层w已经确定。
在卷积层中,卷积核中的每个权重都参与多个结果的输出,如公式(1)所示,一个权重w11参与net11,net12,net21,net224个结果的输出,因此对w11求偏导时,需要对与w11有关的4个结果net11,net12,net21,net22先求偏导,然后再对a求偏导,计算卷积核中4个权重的参数,如公式(5)所示。
(5)
梯度为误差项与对应输入的线性叠加,其中误差项已经由公式(4)求得。将求得的梯度(5)代入Adam算法公式(1),对学习率和梯度方向进行更新,求得卷积层参数值。
3.3.3 池化层
池化层也称降采样层是对提取到图像进行全局缩放,经过缩放后的图像可以更好地显示全局特征。通常的池化层包括最大池化和平均池化,因此在进行反向传播时,进行首先升维,然后将图像还原为原始图像。
如果采用2 px×2 px的池化层,则将图像升维成4 px×4 px的图像,在原始图像四周填0。如果是最大池化,根据标记位置,左上、右下、右上、左下还原原始图像。
3.3.4 输出层
softmax的导数:softmax属于多类分类输出层激活函数。输出结果为各个类别的概率。假设z1=w1x+b,z2=w2x+b,z3=w3x+b,…z9=w9x+b9个输入,经过softmax函数激活后,得到每个类别概率。

当k=i时,
sk(1-sk)
(6)
说明:正向传播时w,b均为已知,求得s。s为每个类别对应的输出概率。由输出概率得到损失L。
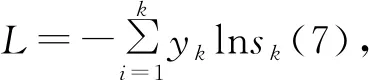
(8)
将(6)和(8)代入式(7)中,得到损失函数对z的偏导,推导如下:

说明:输出层损失函数对w的梯度=损失函数对输出类别s的偏导×s对z的偏导×a偏导,从而求得输出层权重参数。
3.4 模型优化方法
由于卷积神经网络参数较多,模型复杂度较高,当模型复杂度高于样本复杂度时会发生过拟合,而导致测试集准确率降低。通常采用优化方法对模型进行优化,常用优化方法有丢弃法和早停法。
(1)丢弃法:随机丢弃一定比例神经元。当丢弃一部分神经元后,每次训练时,模型结构完全不同。采用不同的模型结构进行训练,相当于bagging。根据多次预测结果,选取投票次数最多的类别作为最终类别,从而避免发生过拟合。
(2)早停法:合理的训练集准确度在83%~93%,当训练集准确度过高,在测试集上准确率反而会降低,相当于根据训练集绘制的图像,而没有学习能力,不能在未知数据集上进行预测。因此需要观测训练集的准确率,当训练集准确率达到某一数值时,提前停止训练。
3.5 模型测试结果
本文通过深度学习框架Keras进行编程,采用VGG预训练模型,对全连接层和输出层进行精调,对鸡西地区电子邮件面单进行分类,针对每个类别的数据,进行测试,得到预测值和真实值之间的差异。得到训练集和验证集上轮数和准确率评价图像,如图2所示。训练集准确率随迭代次数在不断提高,而验证集准确性刚开始随迭代次数增加而增加,但迭代次数到达6后,出现大幅度震荡,迭代次数达到8时,出现最优值。
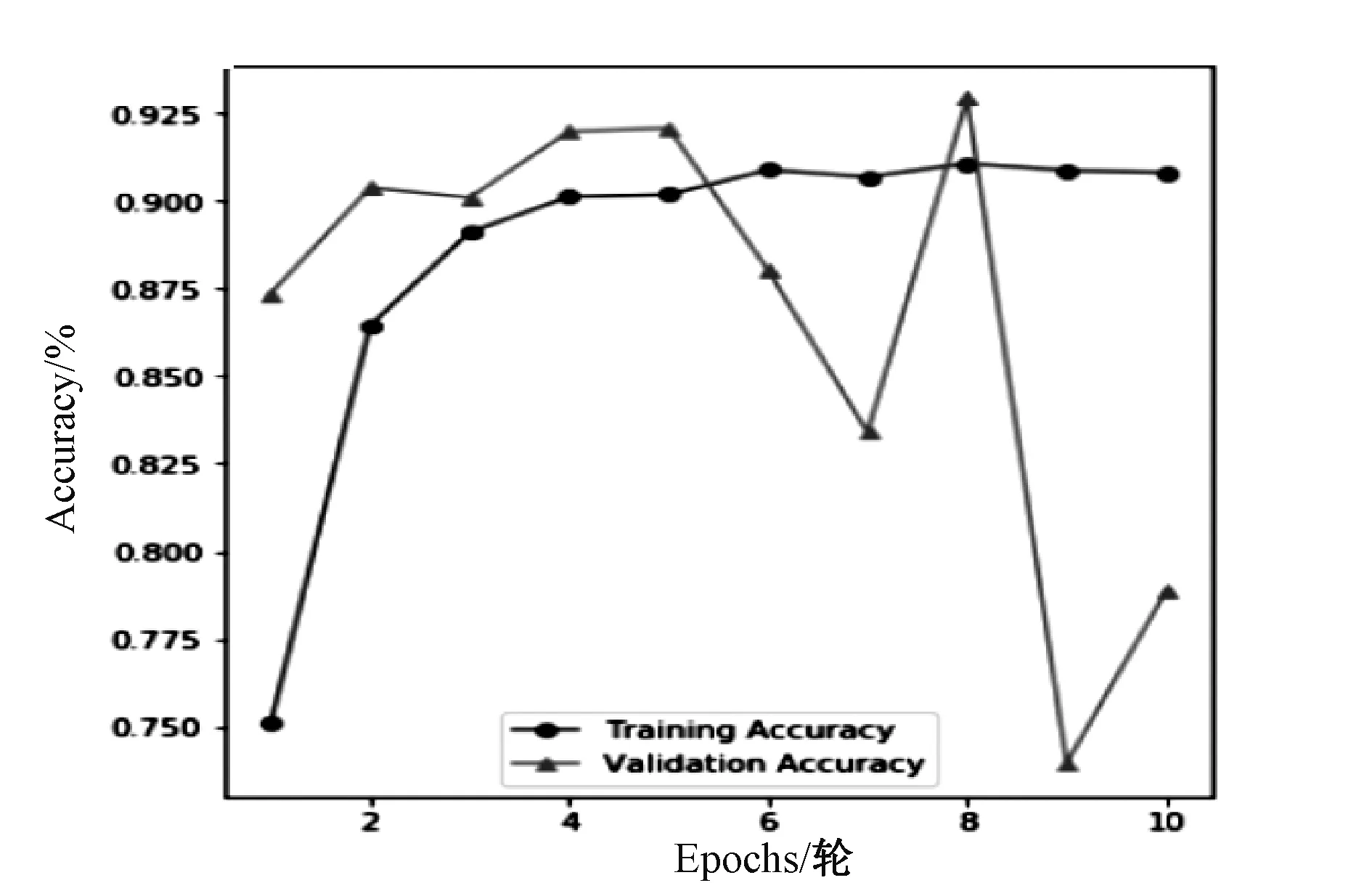
图2 训练效果
所以迭代次数达到8时模型分类效果较好达到92.5%,实现了邮件的自动分类。
猜你喜欢
承德医学院学报(2022年2期)2022-05-23 13:01:44
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·新阅版(2020年11期)2020-12-21 03:36:56
电子制作(2019年11期)2019-07-04 00:34:38
车迷(2018年12期)2018-07-26 00:42:32
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
电视技术(2014年19期)2014-03-11 15:38:20
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
