
基于词共现的方面级情感分析模型*
2022-11-17 11:56:10杨春霞姚思诚宋金剑
计算机工程与科学 2022年11期
杨春霞,姚思诚,宋金剑
(1.南京信息工程大学自动化学院,江苏 南京 210044;2.江苏省大数据分析技术重点实验室,江苏 南京 210044;3.江苏省大气环境与装备技术协同创新中心,江苏 南京 210044)
1 引言
互联网方便了用户发表自己对事件、产品的看法与评价,这些文本语料为情感分析提供了数据基础[1,2]。与篇章级情感分析相比,方面级情感分析任务ABSA(Aspect-Based Sentiment Analysis)旨在识别给定目标实体的方面以及对每个方面表达的情感进行判断,属于细粒度情感分析,也被称为基于特征的意见挖掘[3]。本文主要进行方面级情感判断,例如:“Great food but the service was dreadful”,在这里“food”或“service”都可以是方面词,如选定“food”作为方面词,它的意见词就是“great”,情感极性是积极的。
方面级情感分析分为文本表示与特征提取两部分。文本表示通常采用word2vec[4]将单词映射成向量,特征提取主要使用LSTM(Long Short-Term Memory)等序列结构模型。随着预训练模型的发展,以BERT(Bidirectional Encoder Representations from Transformer)[5]为代表的预训练模型越来越受到重视。BERT是一种在大型文本语料库上训练得到的通用语言理解模型。Jawahar等[6]通过10个句子级的探测任务证明了BERT在中高层可以学习到句法特征与语义特征。这意味着将方面级情感分析作为BERT的下游任务是可行的。
方面级情感分析数据集一般取自大众评论,表述偏口语,语法结构简单,很多样本中同时有多个方面词与多个意见词,模型可能错误地将与目标方面词无关的意见词作为判断情感极性的线索,而真正相关的意见词总是比不相关的意见词与目标方面词的距离更近。尽管序列结构的模型在自然语言处理各类任务上都有了很大的进展,但无法有效利用这种结构信息,而基于图神经网络的模型能在词共现图中捕获这种特殊的结构特征,且有更好的推理能力[7]。为此本文提出了BCGN(BERT Co- occurrence Gated graph neural Network)模型,主要贡献如下:(1)提出了一种新的意见词捕捉策略,改善了多方面词、多意见词混淆的问题;(2)将自注意力模型应用在图神经网络上,相比传统注意力模型能更有效地捕捉并融合每个节点多个特征空间的信息;(3)结合BERT预训练模型,在3个方面级情感分析数据集上进行实验并与主流模型进行比较,结果表明本文提出的模型在性能上优于主流模型。
2 相关工作
早期方面级情感分析主要基于统计与规则的方法,例如使用WordNet建立词与词的联系,采用情感词典和规则处理情感分析任务。Ding等[8]提出了一种基于词典的整体方法,利用预设的词典和自然语言表达的语言习惯来处理方面级情感分析问题,模型性能优于之前的词典模型。
随着词嵌入的发展,文本表示逐渐从独热表示(one-hot representation)转变为分布式表示(distribution representation),意思相近的词在映射成向量后有着较高的相似度,一定程度上解决了独热表示语义鸿沟与维度爆炸的问题,使用深度学习挖掘语义,并将方面级情感分析看成一个分类任务成了主流方法。Tang等[9]提出了基于LSTM的TC-LSTM(Target-Connection Long Short-Term Memory)模型与TD-LSTM(Target-dependent Long Short-Term Memory)模型,构建了上下文与方面词的联系,相较于标准的LSTM有更好的效果。Fan等[10]提出了一种新的多粒度注意力网络MGAN(Multi-Grained Attention Network),使用细粒度的注意力机制捕捉方面词与上下文之间的单词级交互关系,增强了上下文与方面词的联系。
在引入了BERT预训练模型后分类准确率有了更大的提升,Song等[11]将上下文与方面词作为句子对输入BERT,通过实验验证了BERT在方面级情感分析任务上的有效性。
也有研究人员对图结构的文本展开研究,Yao等[12]将整个语料库建模为异构图并通过图卷积网络学习单词和文档嵌入,文档与单词之间通过TF-IDF作为边的权重,单词与单词之间的关联权重基于全局词共现。这种结构的图有助于模型在半监督任务中学到几类不同的文档间差异,在文本分类任务上取得了较好的结果。陈俊杰等[7]将原始文本处理成词共现图与文本序列,词共现图上采用图卷积获得节点特征,文本序列输入双向LSTM获得隐层表示,最后将2部分拼接,有效地利用了结构信息。Liang等[13]提出了一种新的端到端ABSA多任务学习的依存句法知识增强交互体系结构,能够充分利用句法知识。Huang等[14]提出了一种目标相关图注意力网络TD-GAT(Target-Dependent Graph ATtention network)用于方面级情感分类,明确地利用了句法图中词与词之间的依赖关系,相比序列模型有更好的效果。
3 BCGN模型构建
本模型主要由4部分组成:BERT预训练模型、词共现图、门控图神经网络GGNN(Gated Graph Neural Network)及自注意力网络。网络结构如图1所示。
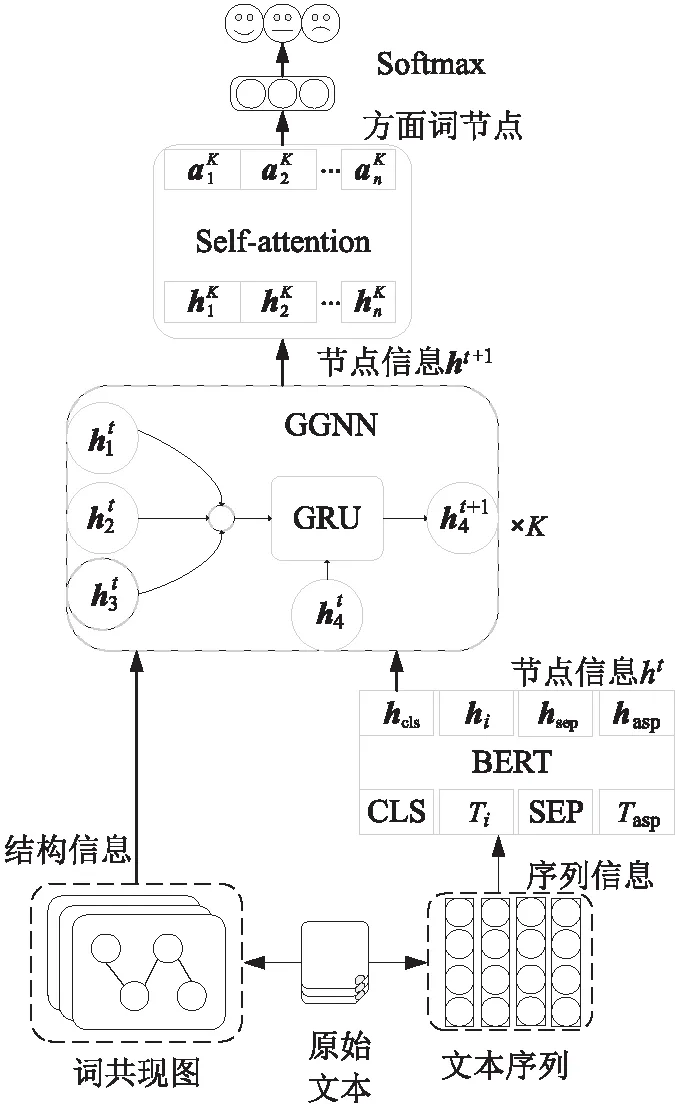
Figure 1 Diagram of BCGN model图1 BCGN模型图
(1)BERT预训练模型:输入序列文本,输出单词的节点信息向量h0。
(2)词共现图:根据词与词同时出现在一个窗口的次数构建图,作为门控层的邻接矩阵A。
(3)门控图神经网络:根据词共现图更新节点信息,从而捕捉特定方面词的情感,输出更新后的节点信息ht+1,t∈[0,K-1]用于区分不同层次的节点信息向量,图1中K表示执行的次数。
(4)自注意力网络:对更新后的节点信息ht+1进行自注意力计算,进一步捕捉全局特征信息。
3.1 BERT预训练模型
本文使用BERTbase对方面词与上下文交互建模,具体流程如图2所示。
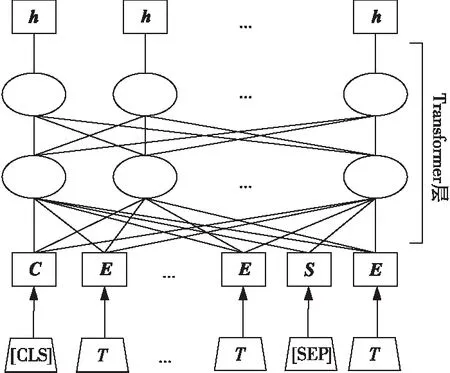
Figure 2 Pretraining model of BERT图2 BERT预训练模型
图2中的T代表输入的文本,[CLS]与[SEP]为BERT中的标记符。[CLS]可以作为整个句子的语义表示,因此通常用于分类任务;当下游任务输入的是句子对时,需要在2个句子间加入[SEP]分隔句子[5]。所以,本文模型在输入BERT预训练模型前将每条样本预处理成“x=[CLS]+上下文+[SEP]+方面词”的形式。C代表[CLS]经过嵌入后的分类向量,S代表[SEP]经过嵌入后的分隔向量,E代表经过BERT词嵌入得到的文本表示,之后通过Transformer层[15]提取上下文信息,得到包含上下文与方面词交互注意力的节点信息H,如式(1)所示:
H=BERT(x)
(1)
3.2 词共现图构建
词共现图的特点是能够快速且有效地表示文本结构信息,在增大窗口或加深图神经层数后也能捕捉远距离的单词关系。具体可以表示为G=(V,ε),V表示一个数据样本中所有不重复的单词集合,ε反映了2个单词之间的内在联系,这种联系是无向的。权重值取决于单词与单词出现在一个固定大小滑动窗口的次数。邻接矩阵A的构建如式(2)所示:
(2)
其中,*W表示2个单词出现在同一个窗口中的次数,i和j表示来自同一个样本的不同单词。
在处理文本时考虑去除包括“the”“was”在内的停用词,以增强单词连接的有效性。图3是以数据集Restaurant中的一个样本“Great food but the service was dreadful”为例构建的词共现图(窗口大小为3)。

Figure 3 Example of word co-occurrence graph construction图3 词共现图构建示例
可以看到,在这个例子中有2个方面词和2个情感极性不同的意见词,且每个相关意见词都在对应方面词的附近,满足“就近原则”。如图3中的“food”与“great”直接相连,第1层的门控图神经网络就能将“great”的语义信息融入“food”,而“dreadful”即使能在第2层门控图神经网络中融入“food”,但其权重也远低于“great”的。
3.3 门控图神经网络
门控图神经网络[16]是一种基于空间域GRU的模型,它将邻居节点信息作为输入,自身节点信息作为隐层状态。这里采用2层门控图神经网络使模型能够融合更多高阶邻居信息。
每个节点进入门控神经网络后根据邻接关系融合相邻节点信息,从而更新自身节点表示。具体计算如式(3)~式(7)所示:
at+1=AhtWa
(3)
zt+1=σ(Wzat+1+Uzht+bz)
(4)
rt+1=σ(Wrat+1+Urht+br)
(5)
h~t+1=tanh(What+1+Uh(rt+1⊙ht)+bh)
(6)
ht+1=h~t+1⊙zt+1+ht⊙(1-zt+1)
(7)
其中,at+1代表t+1层中根据词共现图融合的节点隐层向量,ht代表BERT中输出的节点信息向量,Wα代表对应的可训练的权重矩阵。式(4)和式(5)中rt+1与zt+1代表t+1层的重置门向量与更新门向量,σ(·)代表sigmoid函数,Wz和Uz代表重置门中的权重矩阵,bz代表重置门中的偏置向量,Wr和Ur代表更新门中的权重矩阵,br代表更新门中的偏置向量。这2个门是门控图神经网络的核心,决定每个节点是否要接受邻居节点的信息。在经过足够的训练后,这2个门能够识别一个词是否是相关意见词,是否在情感极性分类中起到了关键作用。本文的模型正是通过这个机制对方面词附近的意见词信息进行融合,强化局部信息,改善意见词混淆问题,从而得到更准确的节点表示。式(6)中通过更新门选择性更新ht,得到准更新节点h~t+1,其中,⊙代表对应元素相乘,Wh和Uh代表对应的权重矩阵,bh代表对应的偏置向量。最终将h~t+1选择性重置,得到更新后的节点信息ht+1。
3.4 自注意力层
门控图神经网络根据词共现图融合节点信息后,输出到自注意力层。自注意力层通过计算相似度的方式获得节点与节点之间的注意力,且能够捕捉不连续的、长距离依赖的语义信息。另一方面自注意力[15]可以通过多个注意力头学习到节点不同子空间的相关信息,以进一步融合全局信息,使得特征更平滑,计算公式如式(8)~式(11)所示:
(8)
(9)
(10)
Φ={φ1,φ2,…,φn}=concat(head1,…,headm)WO
(11)
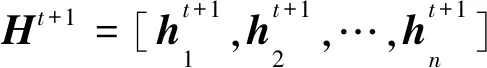
本文模型在池化时仅提取目标方面词对应的节点信息Φasp送入softmax函数,损失函数采用带正则的交叉熵损失函数,如式(12)和式(13)所示:
(12)
(13)
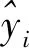
4 实验
4.1 数据集
本文在SemEval-2014任务4的2个数据集[17]与Twitter数据集[18]上评测本文所提模型的性能,并在REST15[19]、REST16[20]上验证本文所提模型的通用性。数据集相关信息如表1所示。
感情上的事,谁能说得清楚?风影开始看着红琴笑,他什么也不说,只是瞅着她笑,有点儿像佛拈花微笑。这种笑意味深长,是怜悯她?是鄙夷她?是睥睨她?是讥讽她?抑或是善意地劝导她,开悟她?
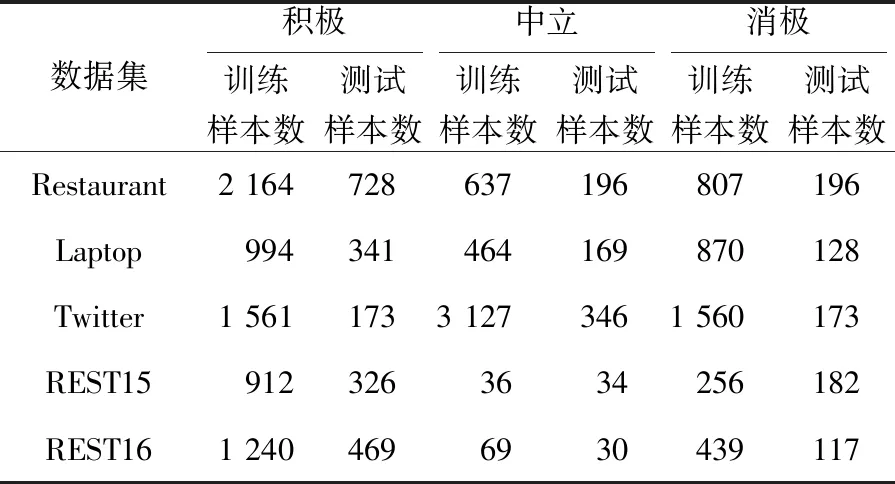
Table 1 Statistical information of datasets
4.2 基线模型
本文选取3类模型作为基线模型:(1)使用RNN与CNN的深度学习模型TNET-LF;(2)使用句法依存信息的模型CDT、TD-GAT和DREGCN;(3)基于BERT的模型BERT-SPC和BERT-AEN。
TNET-LF:该模型采用CNN层提取来自双向RNN层的词表示特征。在这2个层之间添加了一个组件来生成句子特定目标的单词表示,同时在RNN层还保留了原始的上下文信息[21]。
CDT:该模型使用双向LSTM对句子的依存树进行编码,再用图卷积网络对嵌入信息进行增强,最后输出到非线性层进行分类[22]。
TD-GAT:该模型使用依赖关系图直接从目标方面的句法上下文传播情感特征,并使用该特征进行分类[14]。
DREGCN:该模型采用了端到端ABSA多任务学习的依存句法知识来增强交互体系结构。利用设计良好的依赖关系嵌入图卷积网络来充分利用句法知识[13]。
BERT-SPC:该模型将方面级情感分析看成句子对任务输入BERT预训练模型,最后提取[CLS]标记对应的分类特征向量送入非线性层分类[11]。
BERT-AEN:该模型使用基于注意力的编码器对上下文和方面词进行建模,并引入了标签正则化,最后通过非线性层进行分类[11]。
4.3 实验环境与参数设置
4.3.1 实验环境
本文实验基于PyTorch深度学习框架,具体训练环境配置如表2所示。

Table 2 Experimental environment
为了提高模型的收敛速度,本文模型对BERT层与图神经网络层设置了不同的学习率,具体的超参数设置如表3所示。
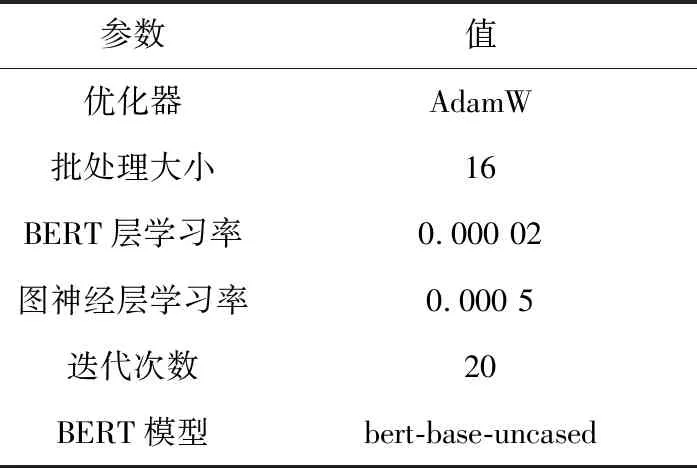
Table 3 Parameters setting
4.4 实验与结果分析
4.4.1 评价指标
准确率accuracy:预测正确的样本占全体样本的比例,即在所有类别中真正例(TP)和真假例(TN)占所有样本的比例,如式(14)所示:
(14)
宏平均F1值(MacroF1):在所有类别中求出平均精确率MacroP与平均召回率MacroR,再对精确率与召回率求调和平均值。这个指标综合考察了模型分类的精确率(查准率)与召回率(查全率),值的大小取决于二者中较小的值,属于综合评价指标,如式(15)所示:
(15)
4.4.2 实验结果
本文在SemEval-2014任务4中的2个数据集与Twitter数据集上进行实验,并对比6个基线模型,实验结果如表4所示。本文模型的分类结果的混淆矩阵如图4所示。
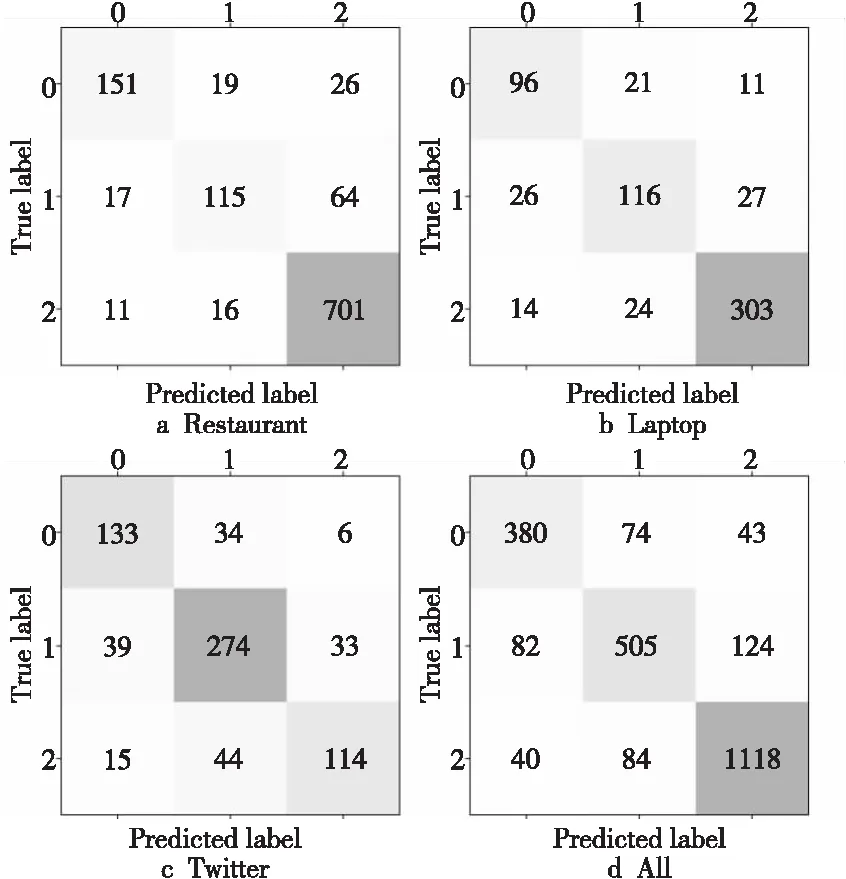
Figure 4 Confusion matrix图4 混淆矩阵
图4的混淆矩阵直观展示了模型在不同类别上的分类情况,4个子图分别展示了模型在Restaurant、Laptop、Twitter及总体数据上的混淆矩阵情况。其中0、1、2分别表示消极、中性、积极的情感极性。图4d总体数据混淆矩阵显示,被模型预测为积极的1 285个样本中(第3列),有124个数据样本实际为中性样本,仅有43个数据样本实际为消极样本,这表明本文模型在积极这个情感极性上有较好的分类性能。
从表4可以看出,本次实验中宏平均F1值相比准确率提升幅度更大,在3个数据集上分别提升了2.79%,0.93%和0.45%,说明本文模型在多个情感极性上既能查得准,也能查得全。
本文模型在Restaurant数据集上的分类效果最好,在Laptop上其次,原因是评论者在撰写餐厅评论时语法简单,更加遵循“就近原则”。另外,SemEval-2014任务4的2个数据集中的积极情感占比都超过了50%,更易区分,因此所有模型在其上面都有比较好的分类结果。所有模型在Twitter数据集上分类准确率都不高,这是由于Twitter数据集的方面词对应的实体不同,不同的样本句式差异较大,并包含了一些网络流行语、反讽等,因此分类准确率较低。
使用了句法依存树的模型CDT在前2个数据集上的分类效果相比于TNET-LF模型的有了较高的提升,说明在方面级情感分析任务上使用图神经网络以及对句法结构解析树进行编码是有效的。同时,BERT-SPC模型在2个数据集上也有较好的分类效果,原因是BERT在预训练阶段对大量通用文本语料进行过无监督学习,词表示的语义信息更加丰富。BERT-AEN采用的对方面词与上下文的建模有助于模型捕捉2个部分的内在联系,因此也有较高的准确率。TD-GAT与DREGCN都是在句法关系图上使用图神经网络,并通过BERT预训练模型增强分类性能,与本文模型在设计思路上类似,但本文模型在准确率上仍比二者高了1%~3%,这说明利用词共现图表示特殊的语法结构相比使用句法图表示有更好的效果。
4.4.3 对比分析
为了得到模型参数的最优值,本文选取了不同的参数进行对比分析,实验结果如图5、图6和表5所示。
如图5所示,词共现窗口大小在2到3时准确率会提升。当窗口大小大于3时,准确率会下降,这是因为节点间的连接过于紧密反而会增大模型收敛的难度。
图6展示了注意力头数与门控层数(step)的关联关系,以及它们对准确率的影响(在Restaurant数据集上)。通过实验可知,门控层数为1到2时,随着注意力头数的增加,模型的性能更好,这说明多个注意力头可以学习到节点不同子空间的相关信息,有助于提高模型的分类效果。另一方面,增加门控层层数与增加注意力头数能够提升模型分类准确率的本质原因是相同的,即提升网络的复杂度,使模型获得了更丰富的特征,但当门控层网络已经很复杂时,再增加注意力头数会使得整个模型难以收敛,因此在3层门控层时,随着注意力头数的增加,模型准确率反而下降了。
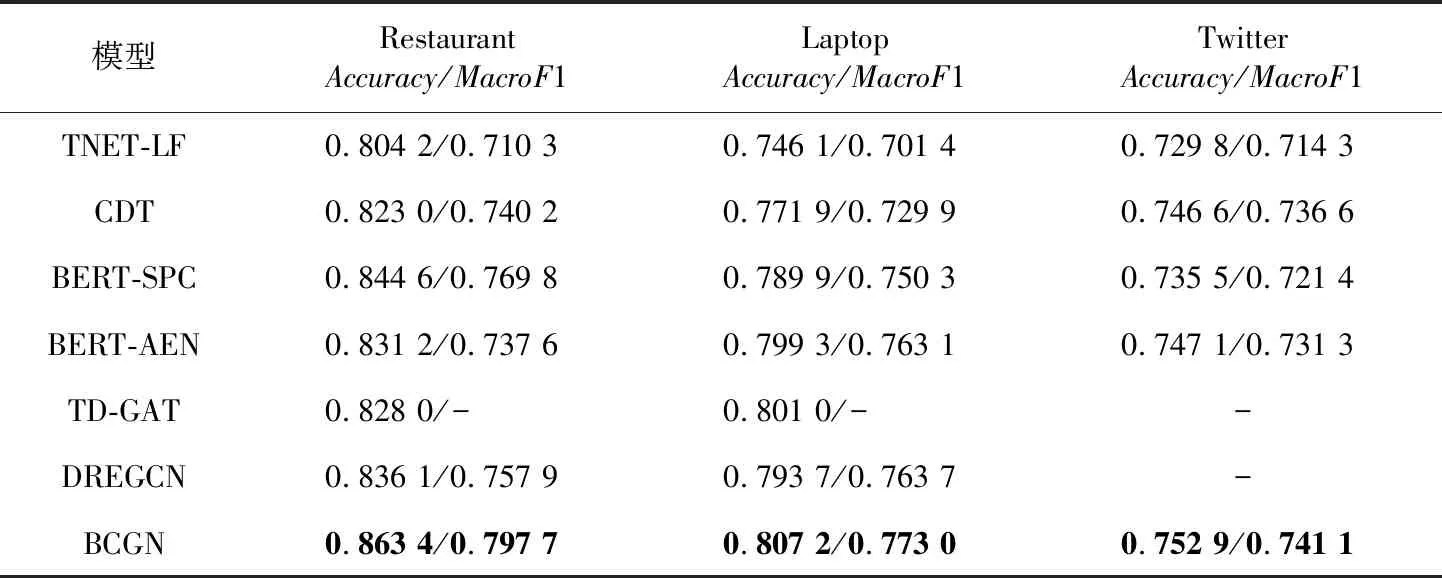
Table 4 accuracy and MacroF1 of models
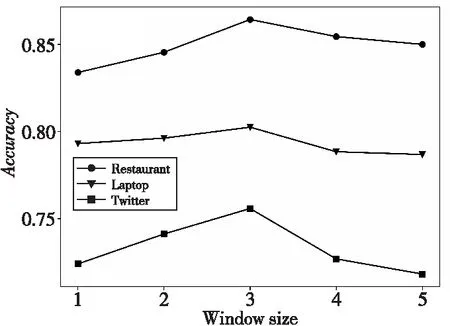
Figure 5 Relationship between window size and accuracy图5 窗口大小与准确率关系图
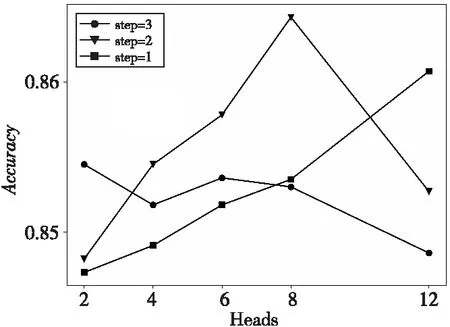
Figure 6 Relationship numbers of attention heads and gated layers图6 注意力头数量与门控层数关系图
从表5可以看出,提取方面词节点输入softmax层的准确率高于平均池化与最大池化的,原因是平均池化与最大池化会重新引入无关信息,使之在多意见词样本中引起误差,从而影响整体的分类准确率。
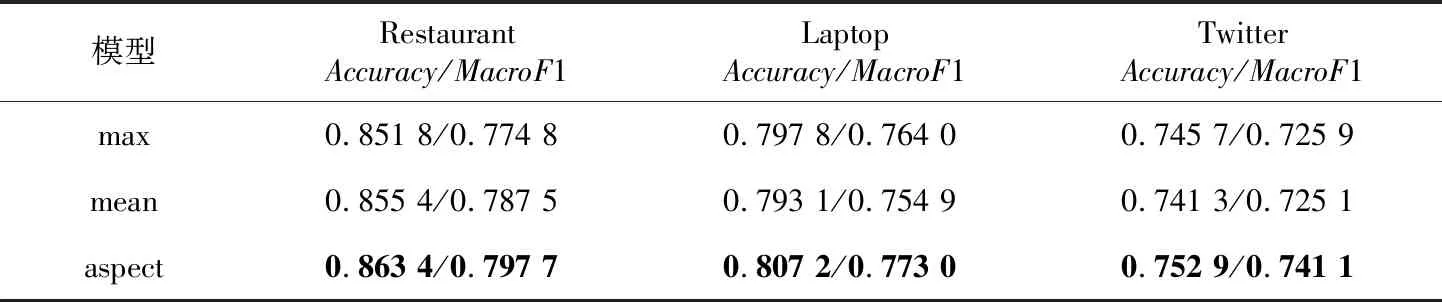
Table 5 Experimental results of different pooling methods
本文对模型的各个组件在Laptop数据集上进行了消融分析,结果如表6所示。
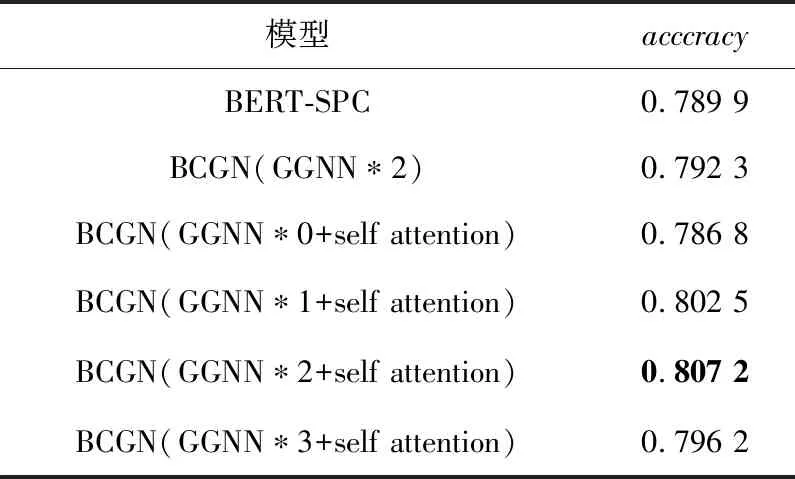
Table 6 Ablation results of different models
本文尝试了将门控层数设置为零的实验,此时本文模型退化为仅使用BERT与自注意力网络,即在BERT-SPC模型基础上增加一个自注意力层。模型的准确率与BERT-SPC的接近但低于本文模型的,这说明使用门控图神经网络对模型准确率的提高有一定帮助。此外,在BCGN中去除了自注意力层后模型准确率有一定下降,这是因为部分样本不满足“就近原则”,额外的一层自注意力层起到了特征平滑的作用。使用两层门控图神经网络在方面级情感分析任务上能取得最佳效果,因为单层的门控图神经网络无法捕捉高阶邻居节点信息。以Laptop数据集中的一个样本“Did not enjoy the new Win 8 and touchscreen functions”为例,预处理后的句子为[not enjoy new Win 8 touchscreen functions],“Win 8”是该样本的方面词,“enjoy”是意见词,在第1层GGNN时方面词“Win 8”会选择性融合包括“enjoy”在内的4个词,而“enjoy”会选择性融合包括“not”在内的3个词,这显然会误导分类结果,因为第1层时“not”未融入方面词,但在第2层GGNN时“not”已经融入“enjoy”进行修正从而正确融入方面词,随着多次迭代训练后模型能自动选择正确的意见词信息。
最后,本文从3个数据集中选取6条数据样本验证模型在多意见词样本上的分类性能,结果如表7所示。
从表7可以看出,当意见词有2种情感极性时,本文模型依靠结构信息能够捕捉正确的意见词,相比其它模型可靠性更高。
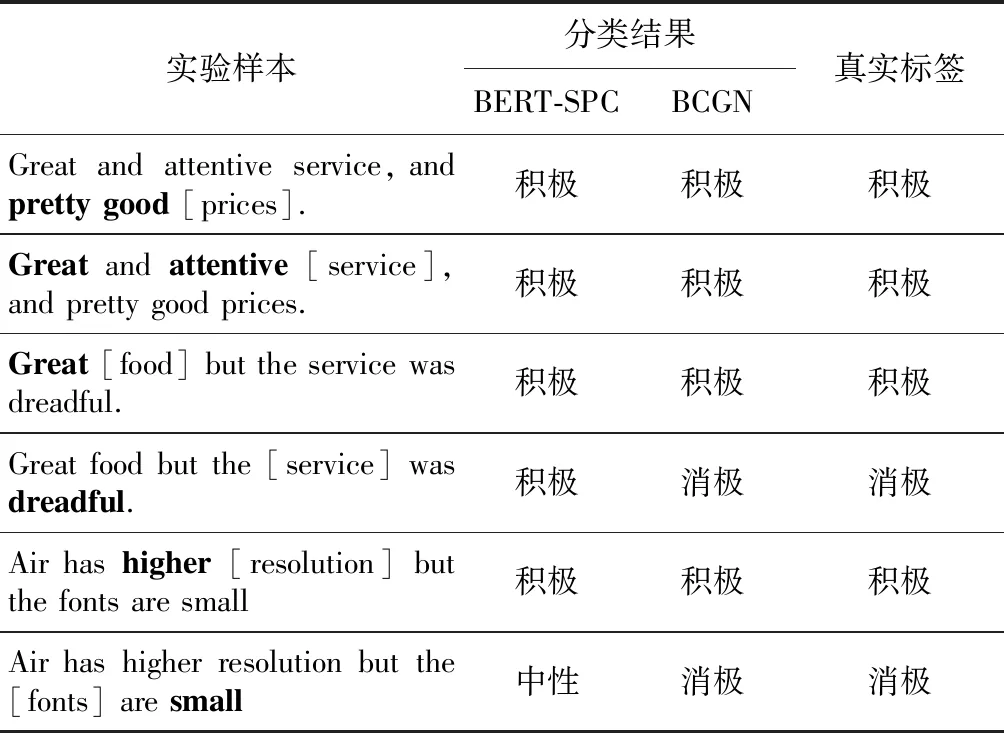
Table 7 Sample analysis
4.4.4 模型通用性验证
为了验证BCGN在方面级情感分析任务上的通用性,本文对数据样本进行扩充,在REST15与REST16数据集上进行测试,并和基线模型TNET-LF以及仅在Restaurant上训练的模型BCGN*进行对比分析,实验结果如表8所示。

Table 8 Experimental results of different models
实验结果表明,BCGN在新的样本集上仍有较高的分类准确率与宏平均F1值;直接迁移的模型BCGN*在未经训练的情况下也有不低的分类性能,这证明了BCGN能有效提取文本的特征,准确地判别给定方面词的情感极性,在方面级情感分析任务上有一定的通用性。
5 结束语
本文提出了一种基于词共现的方面级情感分析模型,一方面通过BERT捕捉方面词与上下文之间的语义关系,得到带有交互注意力的节点信息;另一方面引入图结构信息,并在构建图时为每个数据样本建立独立的图,通过门控图神经网络捕捉邻近方面词的意见词,改善了意见词混淆问题。在SemEval-2014的2个数据集与Twitter数据集上验证了模型的有效性。由于本文模型的结构信息是对所有数据样本构建图,而方面级情感分析的几个数据集样本量较小,文本长度也在80个词以内,因此运行成本较低,但在长文本或大数据集上运行时可能对设备有较高要求,因此在后续的工作中,需优化共现图的存储方式,减少内存占用。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年19期)2019-11-23 08:42:00
中国交通信息化(2018年5期)2018-08-21 03:37:40
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
