
改进的Siamese自适应网络和多特征融合跟踪算法
2022-11-15 16:17:46连继荣
计算机与生活 2022年11期
李 睿,连继荣
兰州理工大学 计算机与通信学院,兰州730050
目标跟踪是计算机视觉中一项基本但具有挑战性的任务[1-2]。给定视频序列初始帧中的目标状态,跟踪器需要预测每个后续帧中目标的位置和大小。尽管近年来取得了很大进展,但由于遮挡、尺度变化、背景杂波、快速运动、光照变化和形变等因素的影响[3],视觉跟踪仍然面临巨大挑战。
在现实生活中,目标的大小和宽高比例随着目标的移动、摄像机的移动和目标外观的变化而变化。在目标跟踪任务中能够快速、准确地确定目标的位置和大小是视觉跟踪领域一个难以解决的问题。近几年视觉跟踪方法都是基于Siamese 网络的架构来实现[4-7]。许多研究者对此提出了大量改进方法以实现准确的目标跟踪。
Siamese网络将目标跟踪看作目标匹配问题来处理,核心思想是学习目标模板和搜索区域的相似图,一个常见的策略是在搜索区域的多个尺度上进行匹配,以确定目标尺度的变化,这就是这些跟踪器耗费时间、耗费空间的原因。其中文献[5]引入区域建议网络以获取更加准确的目标边界框,通过联合一个分类分支和一个回归分支进行视觉跟踪,避免了由于目标尺度不变性而费时提取多特征的步骤,在许多基准上取得了较好的结果。但是为了处理不同的尺度大小和高宽比,他们基于启发式知识设计锚框,如此做将会引入大量的超参数以及计算复杂度很高。DaSiam[7]和SiamRPN++[8]针对以上问题对Siam-RPN 进行了改进。然而,由于为区域建议引入了锚点,这些跟踪器对锚盒的数量、大小和长宽比都很敏感,超参数调优技术对于成功地使用这些跟踪器进行跟踪至关重要[9]。
本文按照Siamese 网络的特点,将跟踪问题分解为两个子问题:一个分类问题和一个回归问题。其中分类任务是将每个位置预测为一个标签,而回归任务将每个位置回归为一个相对的边界框。通过这种分解,可以将跟踪任务进行按模块求解,设计一个简单有效的Siamese自适应网络用于特征提取,同时进一步进行分类和回归,以端到端的方式同时进行学习。
1 相关工作
近年来,随着大数据、机器学习等的快速发展,凭借计算机强大的计算能力极大地推动人工智能快速发展。目标跟踪成为计算机视觉领域最活跃的研究主题之一[10-13]。深度学习算法相比传统的相关滤波算法,在目标跟踪精确度和成功率方面得到巨大的改善和提高。本章主要回顾基于Siamese 网络设计的一系列跟踪器,因为近几年这些跟踪器在性能方面遥遥领先。
目标跟踪领域的研究者主要从特征提取[14-15]、模板更新[16-17]、分类器设计[18]、边界框回归[19]等不同方面,致力于设计更快、更准确的跟踪器。早期的特征提取主要使用颜色特征、纹理特征或其他手工制作的特征[20]。得益于深度学习的发展,卷积神经网络(convolutional neural network,CNN)的深度卷积特性被广泛采用。模板更新可以提高模型的适应性,但在线跟踪效率很低。
此外,模板更新的跟踪漂移问题还有待解决。相关滤波方法[14]的引入使得跟踪的效率和准确率都达到了前所未有的高度[21-22]。目前的研究表明,基于Siamese的在线训练和带有深度神经网络的离线跟踪方法在准确率和效率之间取得了最好的平衡。
作为开创性的工作之一,SiamFC[6]构建了一个完全卷积的Siamese 网络用于特征提取。由于SiamFC的结构简单,跟踪速度可以达到86 frame/s。受其成功的鼓舞,许多研究者认可了这项工作并基于Siam-FC提出了一些改进方法。
CFNet[23]在SiamFC 框架中引入相关滤波层,进行在线跟踪,提高精度。DSiam 学习了一个特征变换,用于解决目标外观变化以及背景干扰。通过动态的Siamese 网络,在可接受的速度损失的情况下,提高了跟踪精度[7]。SAsiam构建了一个双重Siamese网络,包括语义分支和外观分支,两个分支分开训练以保证输出特征的异质性,提高跟踪精度。为了解决目标尺度变化问题,这些跟踪器需要进行多尺度搜索,这会造成大量的时间消耗和空间浪费。
SiamRPN[5]通过联合训练一个分类分支和一个回归分支进行区域建议,避免了由于目标尺度不变性而费时提取多尺度特征图的步骤,取得了非常高效的结果。然而,它很难处理与物体外观相似的干扰物。至今,已对SiamFC 做了很多修改和改进,但是使用AlexNet[24]作为主干网络,跟踪器的性能无法进一步提高。针对这个问题,SiamRPN++通过使用ResNet[25]作为主干网络,优化了网络架构。为了消除中心位置偏差,在训练期间随机移动目标在搜索图像区域的位置。经过以上改进,可以使用非常深的网络结构实现更高精度的目标跟踪。
本文的主要创新点:
(1)设计了一个Siamese 自适应网络,即在Siamese 网络的每个分支同时构建AlexNet 浅层网络和改进的ResNet深层网络,用于特征提取。
(2)提出一种全新的跟踪策略,对浅层特征和深层特征进行自适应选择以及基于多特征融合进行识别和定位,增强网络判别力,提高目标跟踪精度。同时采用由局部到全局的搜索策略,减小计算复杂度,降低时间资源和空间资源的浪费。
(3)经实验比较,提出的算法能够达到较好的效果,与一些跟踪器比较,具有较好的性能改善。
2 研究方法
本章主要详细介绍提出的网络结构和实现方法。首先分析视觉目标跟踪的特点,需要说明的是,本文方法对于目标的快速运动不稳定,在此基础上提出一个假设:在视频序列中,物体在相邻帧之间的位移不大。
事实上,这个假设对于大多数数据集来说是成立的。因为对于一个视频序列而言,相邻帧之间的时间间隔极小,所以在极小的时间间隔里常规运动导致的位移很小。基于此假设,本文提出一种全新的目标跟踪策略。
2.1 网络结构
随着Siamese网络的提出,研究学者将该网络模型应用于视觉跟踪领域,得到很好的效果。首先是基于全卷积的Siamese网络,只有简单的几层就能够达到很好的效果。随后研究学者对其进行改进,将AlexNet 加入Siamese 网络中,得到一定的改善,但也遇到瓶颈。之后又将更深层次的ResNet替换浅层的AlexNet。
如图1所示,SiamFC网络结构由两个分支构成:一个是目标分支,输入数据为模板图像块(z:127×127×3);另一个是搜索分支,输入数据为搜索图像块(x:255×255×3)。

图1 SiamFC网络结构Fig.1 SiamFC network structure
两个分支的卷积神经网络共享参数,确保相同的变换应用于不同的两个图像块。分别输出两个特征图φZ和φX,为了结合两个分支的信息,对φZ和φX执行互相关操作,得到响应图R,为了后续获得目标的位置信息和比例信息,需要R包含大量的特征信息。因此,响应图R为:

根据Siamese网络的结构特点,将目标跟踪问题分为两个分支:分类分支、回归分支。
如图2 所示,本文在Siamese 网络的每个分支同时构建AlexNet 浅层网络和ResNet 深层网络。低层次特征如边缘、角、颜色、形状等代表较好的视觉属性,是定位不可或缺的特征,而高层次特征对语义属性具有较好的表征,对识别更为关键。
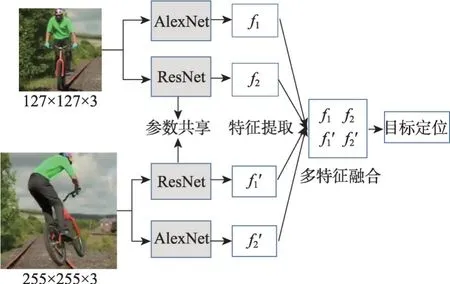
图2 改进的Siamese自适应网络结构Fig.2 Improved Siamese adaptive network structure
在Siamese自适应网络学习过程中,根据图像帧背景的复杂程度,对网络设置不同的权重。对于浅层的AlexNet网络设置权重为α,对于深层的ResNet网络设置权重为β。
当正样本数量大于负样本数量时,赋予α较大值。当图像帧背景复杂,负样本数量大于正样本数量时,赋予β较大值。则选择用于特征提取的神经网络为:

其中,CA表示选择AlexNet网络,Ck为该网络得分。CR表示选择ResNet网络,Cl为该网络得分。根据网络得分可以得知该帧图像背景复杂程度,进而选择两个网络得分较大值用于该图像帧特征提取的网络。
在本文算法中,为了适应提出的网络结构,需要对ResNet-50 作为主干网络并进行修改。基本的残差单元如图3所示。

图3 残差单元结构Fig.3 Residual unit structure
由图3可以看出,X为上一层特征图的输出。跳转连接,被称为Identity Function。G(X)=F(X)+X为深层输出。
原始的ResNet-50的总步长为32,与本文构建的网络结构不匹配,因此将conv4 和conv5 的步长改为1,使得总步长减少为8。并且对每个块添加步长为1的卷积层。将conv3-3、conv4-6、conv5-3 的特征图输出,用于计算分类和回归。
改进的残差网络结构如图4所示,以conv5为例。

图4 改进的残差单元结构Fig.4 Improved residual unit structure
2.2 多特征融合
在神经网络中,一般浅层特征如边缘、颜色、形状等,包含更多的位置信息,是用于定位不可或缺的特征。而深层特征鲁棒性好,包含更多的语义信息,对识别更为关键。
在本文算法中,提出两个多特征融合的方法:其一,两个分支含有完全相同的两个网络。对于不同的输入,提取更加完善、多样性的特征。最后对两个分支得到的特征进行相加融合。通过将浅层特征和深层特征共同使用,能够更好地进行识别。其二,对于不同的图像帧,由于其背景复杂程度不同,对于简单背景来说,浅层特征可以轻松识别、定位目标。但是如果选择使用深层特征则会造成大量的时间消耗,增加计算复杂度,降低目标跟踪速度。因此,进行自适应的特征选择和多特征融合,根据图像帧的复杂程度,自动选择使用浅层特征、深层特征还是浅层、深层混合使用。
给定图像Ij以及使用哪些特征进行组合的决策P(·),因此,每个特征上的响应图为:

其中,fj∈{Lj,Hj,Mj},L、H、M分别表示为浅层特征、深层特征、混合特征。
对于改进的ResNet网络提取的深层特征进行加权总和,最终融合得到的自适应特征图ψ为:

其中,αi、βi为每个图对应的权重,与网络一起参与训练,⊕表示特征融合操作。进一步为了确保网络自主学习每个特征图的重要性,运用Softmax函数规范化权重,表示每个特征图的重要性:

其中,wi和wj表示学习的权值,Ci表示第i层的特征。
通过以上方法,能够得到更加精确、更加精细的特征,用于特定的图像帧进行鲁棒、快速的识别和定位。
2.3 边界框回归
本文通过端到端的完全卷积来训练网络,直接对每个目标位置进行分类和回归,避免了人工干预和多余的参数调整。用交叉熵损失用于分类,用具有标准化坐标的Smooth L1 损失用于回归。对于跟踪数据集来说,每个图像帧都有已标注的真实边界框。因此,用Tw、Th、(x1,y1)、(x0,y0)、(x2,y2)分别表示真实边界框的宽度、高度、左上角坐标、中心点坐标、右下角坐标。则以(x0,y0)为中心,Tw/2、Th/2 为轴长,可以得到椭圆Q1:
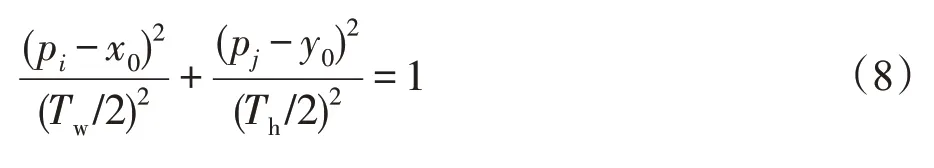
同理,以(x0,y0)为中心,Tw/4、Th/4 为轴长,可以得到椭圆Q2:
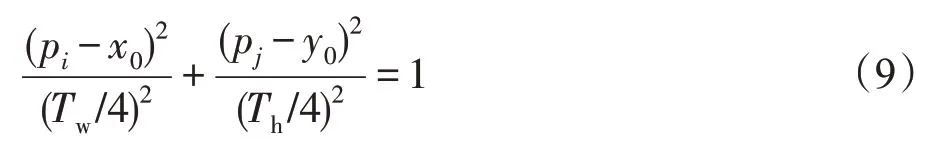
此时,如果目标位置(pi,pj)在椭圆Q2内,则将其标记为正。如果在椭圆Q1之外,则标记为负。如果位于椭圆Q2和Q1之间,则忽略不计。然后将标记为正的位置(pi,pj)用于边界框回归,回归目标可以公式化为:

其中,d1、d2、d3、d4分别表示目标位置(pi,pj)到边界框四条边的距离。为此,定义多任务损失函数:

其中,Lc为交叉熵损失,Lr表示Smooth L1损失。在训练期间,根据多次实验设定λ1=1,λ2=2。
Smooth L1损失函数如式(12)所示:
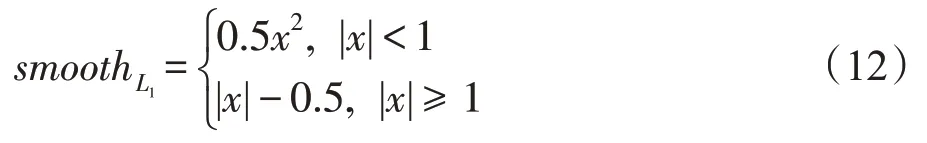
3 实验与分析
3.1 数据集与评价指标
本文实验使用的数据集为目标跟踪标准数据集VOT(visual object tracking)[26]和OTB(object tracking benchmark)[27],视频序列均经过精心标注,更具权威性。OTB数据集包括OTB50和OTB100。其中50和100 代表该数据集中视频序列的数目。VOT 是官方竞赛的数据集,有VOT2015、VOT2016 等,且每年均会更新。OTB 和VOT 数据集存在一定的差别,其中OTB 数据集含有25%的灰度图像,VOT 中均为彩色图像。
本文实验主要使用以下四种评价指标对提出的算法进行分析。
(1)中心位置误差
中心位置误差(center location error,CLE)是计算预测目标位置中心点和真实目标中心点之间的欧氏距离。假设真实目标的中心位置坐标为(xg,yg),预测的目标中心位置坐标为(xp,yp)。因此,中心位置误差计算如下:
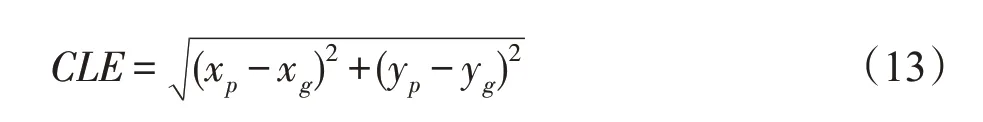
一般来说,计算视频序列中所有图像帧的平均中心位置误差,在一定程度上能够近似看作目标跟踪准确度。但是,跟踪算法在某些图像帧中难免会丢失目标,造成跟踪目标中心位置的预测具有随机性。因此,此时的平均中心位置误差值难以评价跟踪器的准确性。为此,在中心位置误差的基础上,通常采用准确率拟合曲线来反映跟踪器的准确度,统计不同阈值下,成功跟踪目标的中心位置误差的比例,使用误差阈值为20个像素点时所对应的数值,作为跟踪算法在各个测试视频序列中的准确率。
(2)精确度
精确性表示目标跟踪算法预测的目标框与真实目标框的重叠程度,数值越大,表示该算法的精确性更好,如式(14)所示。

其中,φt(i,k)表示经过k次重复后,第t帧图像的精确性,N表示重复的次数。则平均准确率为:

其中,M表示有效跟踪图像帧的数量。
(3)成功率
成功率用预测框和真实框之间的交并比表示。通过重叠率(overlap ratio,OR)表示预测目标区域和真实目标区域的重叠比率,即两个边界框的交并比,如式(16)所示。

其中,OR表示区域重叠比率;R表示预测目标区域;G表示真实目标区域。
(4)速度
在目标跟踪领域,跟踪速度通常指算法所用时间与视频序列帧数的比值,即平均每秒跟踪的视频帧数,值越大表示跟踪的速度越快。
3.2 实验
该方法基于PyTorch 框架在Python 中实现。实验设备硬件为一台装备NVIDIA Titan X 显示处理核心并配备i7-7700k处理器的计算机。
构建的网络在ImageNet[28]上进行了预训练,然后使用该参数作为初始化来重新训练本文构建的网络模型。在OTB-50 数据集上实现的一些具有代表性的跟踪效果如图5所示。

图5 跟踪效果比较Fig.5 Tracking performance comparison
由图5 可以看出,在各种影响因素下,本文算法能够稳定地跟踪目标。
将提出的算法与现有的跟踪器在标准数据集上进行公平比较。用一次性通过评估(one-pass evaluation,OPE)绘制精度曲线图和成功曲线图。由图6可以看出,本文方法比一些现有跟踪器的效果好,能够在一些影响因素下进行鲁棒跟踪。
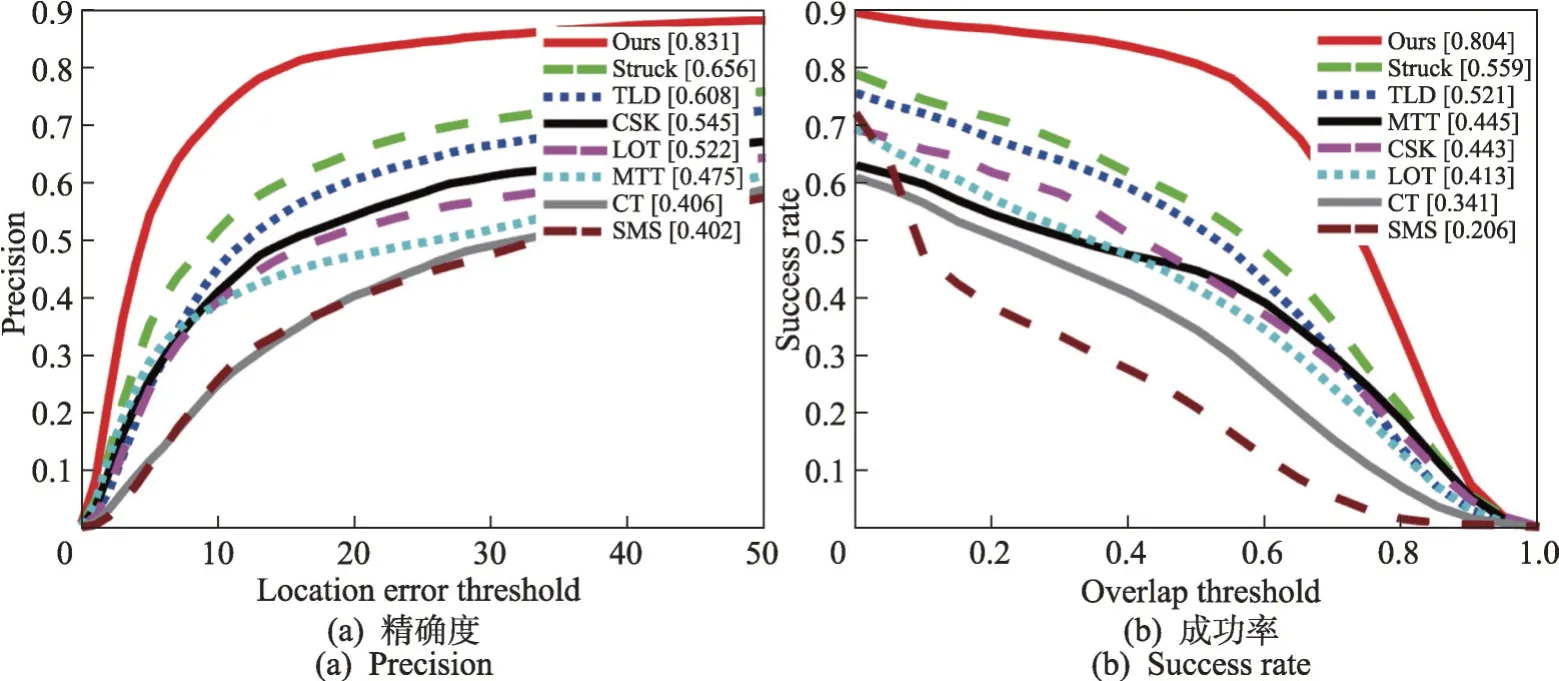
图6 精度和成功率曲线图Fig.6 Accuracy graph and success rate graph
在OTB数据集上对不同算法在形变、背景杂波、遮挡等影响因素下进行测试,绘制精度图和成功率图,如图7~图9所示。
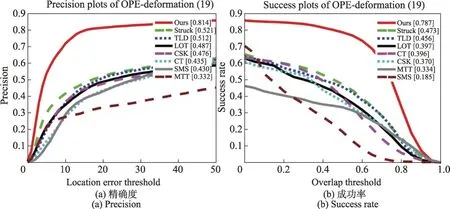
图7 形变影响下的精度和成功率曲线图Fig.7 Accuracy graph and success rate graph drawn under influence of deformation
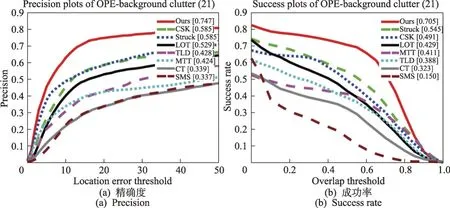
图8 背景杂波影响下的精度和成功率曲线图Fig.8 Accuracy graph and success rate graph drawn under influence of background clutter

图9 遮挡影响下的精度和成功率曲线图Fig.9 Accuracy graph and success rate graph drawn under influence of occlusion
将本文算法与已有跟踪器Struck(structured output tracking with kernels)[29]、LOT(locally orderless tracking)[30]、TLD[31]、CT(real-time compressive tracking)[32]、SMS(mean-shift blob tracking through scale space)[33]、MTT(robust visual tracking via multitask sparse learning)[34]、CSK(exploiting the circulant structure of tracking-by-detection with kernels)[35]在精确度、成功率、速度三项指标在OTB 数据集上进行详细评估,如表1所示。为了公平评估,均使用各指标的平均值。
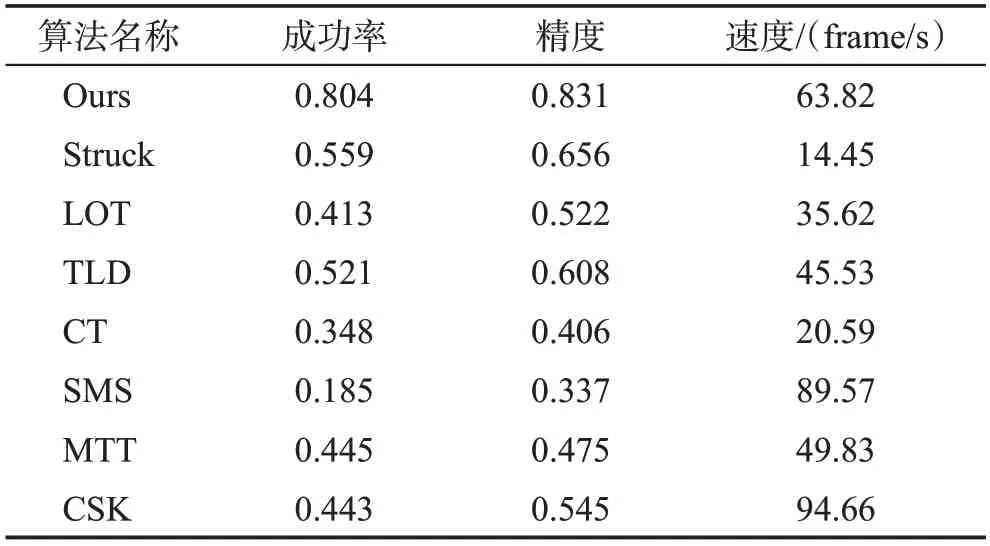
表1 提出的算法与已有跟踪器性能对比Table 1 Performance comparison between proposed algorithm and existing trackers
由表1 显示,本文算法在保证速度的前提下,能够实现较好的跟踪准确性和成功率。且对光照变化、形变、背景杂波、遮挡等影响较鲁棒。
3.3 消融研究
通过对提出的算法和已有的跟踪器进行实验比较,发现本文算法实现效果较好,提出的跟踪方法可行性较高。为此,本节从网络结构、特征图选择、跟踪方法等方面对提出的方法进行内部比较。用N表示网络结构,N1表示Siamese 网络每个分支仅使用AlexNet网络,N2表示每个分支同时使用AlexNet和ResNet,N3表示每个分支同时使用AlexNet 和改进的ResNet;F表示用于识别提取到的特征,其中F1表示仅用浅层特征,F2表示仅用深层特征,F3表示本文提出的多特征融合;M表示跟踪方法,M1表示全局搜索,M2表示本文提出的由局部到全局的搜索方法。实验结果如表2所示。
由表2数据可得,改进的网络结构和多特征融合的方法能够极大提高目标跟踪的精确度和成功率,但是跟踪速度会有所下降。提出的由局部到全局的搜索策略导致在准确度和成功率上效果不明显,但是在跟踪速度上有明显提升。
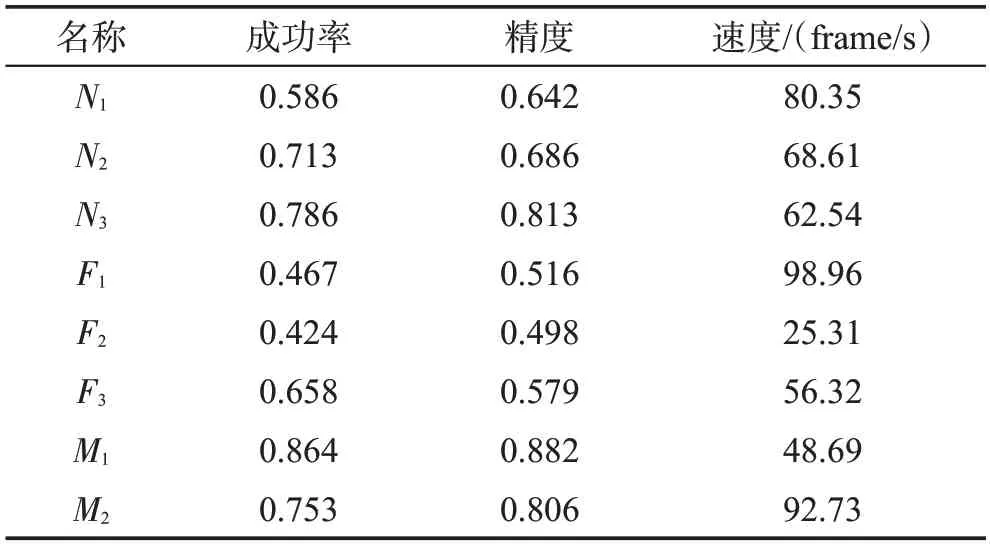
表2 算法内部比较Table 2 Algorithm internal comparison
4 结束语
本文针对目标跟踪领域存在的跟踪精度和跟踪速度不平衡问题,以Siamese 网络为基础,构建结合AlexNet网络和改进的ResNet网络的Siamese自适应网络。通过对提取到的特征进行多特征融合和自适应选择提高特征图的高效性,提高网络的识别和定位能力。进一步,通过加入一种由局部到全局的搜索策略,极大地降低网络计算复杂度,能够节约时间资源和空间资源。在目标跟踪标准数据集上进行实验对比,结果表明,本文算法能够实现较好的效果,同时在形变、背景杂波、遮挡等影响因素下具有较强的鲁棒性。下一步工作将对实现超高的跟踪精确度进行深入研究。
猜你喜欢
太阳能(2022年3期)2022-03-29 05:15:50
建材发展导向(2021年24期)2021-02-12 02:00:24
环境影响评价(2020年5期)2020-12-02 01:18:56
太阳能(2020年3期)2020-04-08 03:27:10
当代工人·精品C(2019年2期)2019-05-10 00:13:22
计算机应用与软件(2017年7期)2017-08-12 15:45:55
水利规划与设计(2016年10期)2017-01-15 14:01:14
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
