
基于大数据+AI机器学习的反诈模型研究
2022-11-15 08:28:00陆文红刘剑中国联通黑龙江省分公司黑龙江哈尔滨150001
邮电设计技术 2022年9期
陆文红,刘剑(中国联通黑龙江省分公司,黑龙江哈尔滨 150001)
0 前言
近年来,电信诈骗严重影响了人民群众获得感、幸福感、安全感。国家高度重视电信诈骗治理工作,运营商作为电信诈骗整个链条中的一个环节,亦投入大量人力物力、技术资金等开展电信诈骗专项治理。运营商如何利用技术手段进行反诈,一直以来都是研究重点。最初电信诈骗特征并不复杂,通过一些简单的行为分析与内容检测就可以达到不错的反诈效果。随着诈骗分子与反诈人员技术对抗不断升级,电信诈骗在通信网侧的行踪已经越来越隐蔽,技术手段越来越先进,因此,反诈工作亟需提升技术水平和能力,运用决策树、随机森林、贝叶斯分类器等典型的机器学习算法,结合LightGBM、人工智能、大数据等先进技术来综合判别诈骗电话,进而对诈骗电话进行关停、溯源和关联分析。
1 电话反诈需求分析
1.1 电话反诈现状
随着通信技术的发展和互联网的普及,诈骗分子频繁利用电信网和互联网对广大人民群众实施非接触式诈骗,并逐步呈现智能化、职业化的特点。诈骗分子利用电话、改号软件、短信、恶意程序(包括仿冒应用)、诈骗网址、伪基站等工具疯狂作案,“话术”多样,“套路”重重,影响面广,涉及金额巨大,成为国家和相关部委关注的重点。
1.2 电话反诈治理难点
在通信过程中,终端会因为开关机、路由区更新、呼叫业务、短消息业务触发鉴权向量消息,被叫和短消息业务会触发寻呼消息,针对用户漫入漫出诈骗特征分析的主要方法是通过正常用户的行为建立基线,发现非正常终端的通联关系。但是,电话反诈存在诈骗场景多变、举报样本不纯、数据不均衡、数据表现不一致等治理难点。
2 整体解决方案
2.1 平台整体架构
如图1 所示,从整体架构上,平台主要由5 个部分构成:应用展示层/系统管理/监控部分、数据源、机器建模层、数据接入层、接口。
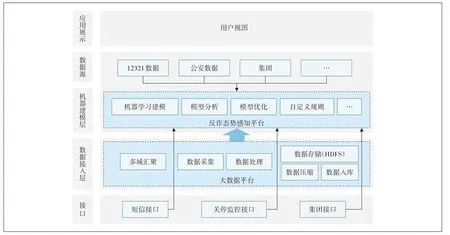
图1 整体架构图
各层功能如下。
a)应用展示层。提供综合展现、系统首页、检出号码列表、失信号码溯源、信息查询等展示全网涉诈电话的状态,通过一键处置对涉诈电话进行关停,提高处置效率。
b)数据源。通过各类接口技术,如FTP、SFTP、XML、API、JDBC等进行各类数据的收集。
c)机器建模层。通过特征筛选技术、机器学习技术对模型进行训练,对训练后的模型效果进行评估,评估通过的模型正式上线运行,后续通过自动+人工的方式不断对模型进行迭代升级来反诈新的诈骗场景。
d)数据接入层。对收集的数据进行规范化处理后压缩入库,通过大数据技术对入库数据进行抽取、清洗、转换、压缩、特征提取、数据探索等工作,为后续建模准备数据环境。
e)接口。通过运营商现有平台实现短信接口、关停监控接口、集团接口等功能对接,实现多环节功能自动完成。
2.2 反诈业务流程
2.2.1 大数据采集
大数据采集数据源包括移动网Mc 接口XDR 话单和信令话单(O域话单)以及计费话单(B域话单)。
2.2.2 数据预处理
为了确保分析数据的准确性,需要对数据进行加工处理,包括数据清洗、数据转换、数据关联,不规则数据需要进行数据补齐,满足数据的完整性和一致性。通过数据预处理组件可实现按照一定的规则,对已采集的数据进行清洗,对无用的数据进行过滤。将不合理或不满足数据结构要求的数据,进行字段取值、字段类型转换,以满足实际数据结构要求。
大数据处理层主要是对接大数据全域数据汇聚中心,完成数据清洗、转换、过滤、压缩、筛选、加密等处理与数据存储等功能。
2.2.3 诈骗电话数据处理流程
诈骗电话数据包括诈骗电话、鹰眼数据、省分数据和IQ 指标,从数据采集开始,将数据送到反欺诈引擎,再到分布式解析引擎后存储,最后送到Portal 分布式应用,处理流程如图2所示。
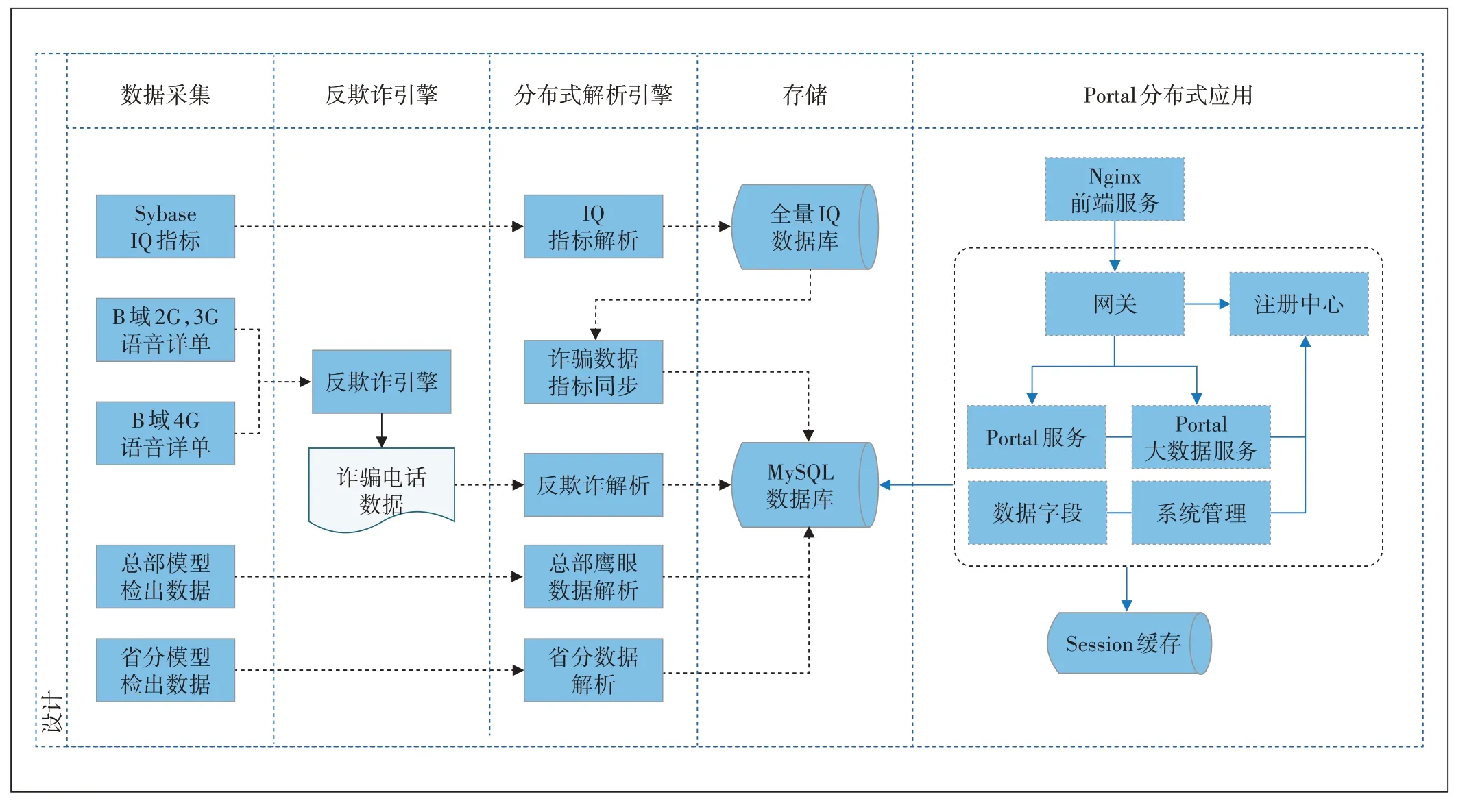
图2 诈骗电话数据处理流程图
2.3 算法及流程介绍
国际国内诈骗事件分析算法主要采用适用性优良、精确度高、理论基础佳、学术成果前沿的机器学习算法对通信行为模式进行挖掘和准确识别,如逻辑回归、随机森林、支持向量机、朴素贝叶斯、梯度提升决策树等。
本文为了解决诈骗场景多变、举报样本不纯、数据不均衡、数据表现不一致等治理难点,使用了上述机器学习算法的组合算法,引入公安涉案数据、用户举报数据增加正样本数量。同时使用LightGBM 框架,训练决策树时使用直方图算法,采用leaf-wise 生长策略,每次从当前所有叶子中找到分裂增益最大(一般也是数据量最大)的一个叶子,然后分裂,如此循环,但此过程会生长出比较深的决策树,产生过拟合。因此LightGBM 在leaf-wise 之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。从直方图获得分裂收益,选取最佳分裂特征、分裂阈值,根据最佳分裂特征、分裂阈值将样本切分。通过直方图做差,继续选取最佳分裂叶子、分裂特征、分裂阈值,切分样本,直到达到叶子数目限制或者所有叶子不能分割。本文选择LightGBM 是因为它支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更高的准确率、支持分布式、可以快速处理海量数据等优点。关于梯度提升树算法的流程如下。
首先,输入训练集样本T={(x1,y1),(x2,y2),…(xm,ym)},最大迭代次数T,损失函数L。
其次,输出强学习器f(x),过程如下。

b)对迭代轮数t=1,2,…T,进行以下操作。
(a)对样本i=1,2,…m,计算负梯度rti。

(b)利用(xi,rti),(i=1,2,…m),拟合1 颗CART 回归树,得到第t颗回归树,其对应的叶子节点区域为Rtj,j=1,2,…J。其中J是回归树t的叶子节点个数。
(c)对叶子节点区域j=1,2,…J,计算最佳拟合值ctj。
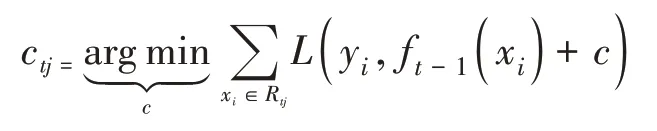
(d)更新强学习器。

c)得到强学习器表达式。

2.4 模型效果及创新点
经过近2年实验室模型训练,放宽初筛条件,结合现阶段诈骗涉案特征集,开展生产环境实践。
正样本:根据公安提供的警情涉案数据和用户举报数据,提取本场景的诈骗号码,选取其被报案日的历史前7 天及当天数据,将经初筛剩余的号码作为初始正样本,经过初筛条件的正样本为48个。由于正样本过少,样本不均衡,采取过采样,将正样本复制为3倍,为144个正样本。
负样本:随机选取2021 年5 月13 日的话单数据,通过初筛的号码查询网络标签,将去除诈骗标签剩余的样本作为负样本,经过初筛及过滤标签,最终负样本为5 805个。将数据分为训练集和测试集,进行5折的交叉验证,最终的混淆矩阵如下。
a)5 折训练集混淆矩阵展示。如表1 所示,其准确率为99.83%,AUC 为99.98%,召回率为95.83%,精准率为97.18%。

表1 5折训练集混淆矩阵展示
b)测试集混淆矩阵展示。如表2 所示,其AUC 为99.99%,召回率为100%,精准率为96.55%。

表2 测试集混淆矩阵展示
测试集上ROC曲线及AUC值如图3所示。
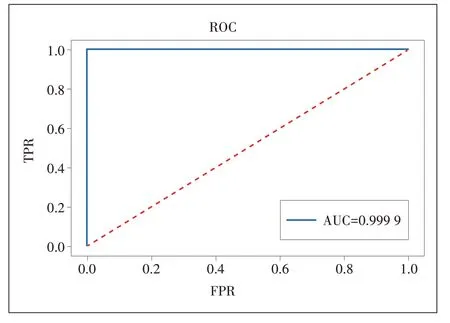
图3 测试集上ROC曲线及AUC值
模型创新点有2个,一是在正样本较少的情况下,正负样本极度不均衡,通过初筛对负样本进行随机欠采样(ROS),很好地解决了样本不均衡带来的问题;二是对模型的精准度要求很高的同时,对覆盖也有高要求,放宽了初筛的条件,让更多的数据能进入模型,迭代特征集合选取现阶段最优的特征集合。
3 系统功能介绍
3.1 外部接口功能
系统已具备标准的B 域基础数据接口,并采用SFTP进行加密传输,保证了数据的机密性。系统与集团鹰眼数据接口采用API 接口方式,获取鹰眼系统的检出结果,接口遵循《中国联通API接口规范》,避免其他系统直接操作数据库,降低系统数据库由于误操作带来的风险。
3.2 自定义规则及监控功能
系统从用户信息、状态信息、通话信息、漫游信息、开户信息等9 大维度,分析号码的50 多个指标,反欺诈工作人员可根据经验,灵活配置使用自定义的监控规则,预测新的不良号码。同时,还可新增支持更多指标阈值设置,支持指标的与或非逻辑、概率函数运算等。
业务实现处理流程见图4,具体说明如下。

图4 业务实现流程
a)指标展示。展示相关的指标项,设置指标的范围以及监控周期。
b)规则的校验和添加。规则添加时,使用昨日指标数据校验当前规则设置是否合适,合适则添加,不合适直接返回提示信息。
c)规则任务的拆分。将添加的规则,拆分成可以执行的任务。
d)规则匹配与结果数据的存储。从数据存储中心获取匹配的指标数据,并将结果数据存储至本地数据库。
e)关停。关停不良号码。
4 数据输出及结果验证
4.1 数据输出
根据上述规则输出模型数据,包括GOIP、漫游通用模型、仿冒公检法、仿冒领导熟人等每月输出检出数据,如表3所示。
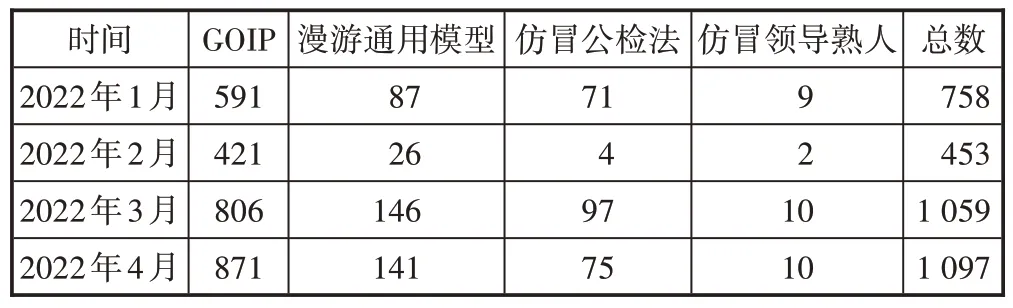
表3 月数据输出
4.2 核验方法
针对2022 年3 月份业务部门反馈的模型结果进行核验还不足以验证系统模型检出异常号码的准确性,所以本文引入集团鹰眼诈骗模型分布情况与平台检出结果进行对比,如表4 所示。命中率最高的模型规则为仿冒领导熟人,其命中率达到100%,命中率最低的模型规则为基于lac 的GOIP 模型(B 域)的模型规则,其命中率为4%。
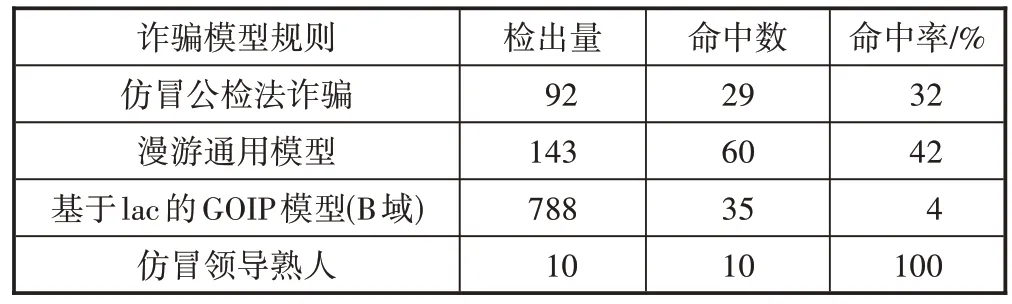
表4 数据检出验证
5 模型部署及应用
本文提出的基于大数据+AI 机器学习模式创新建立的反诈模型已应用于黑龙江反诈态势感知大数据平台。运营商反诈人员通过反诈监控获取整体反诈情况,如图5所示,该平台可以直观的呈现各类月度趋势及当日走势,实现反诈集中运营与监控。

图5 黑龙江反诈态势感知大数据平台
6 结束语
面对当前不断翻新的诈骗手段,变化多端的通信欺诈行为,运营商的管控任务艰巨。本文通过反诈态势感知大数据平台,针对常见的诈骗话务行为进行分析,借助反欺诈业务模型及机器学习模型的迭代调优,建立针对诈骗电话的事前风险预防、事中风险阻断、事后风险处理的全流程闭环反诈管控体系,降低了诈骗号码误判率,有效减少反诈人员工作量,提高劳动生产率,在实际应用中取得了良好的效果。此外,在反欺诈防控过程中,因为算法精度可能存在部分用户号码偏差。因此,未来可在以下2 个方面进一步提高反欺诈模型的精度:一是不断迭代新模型+社会工程学来适应各种欺诈场景;二是尝试通过贝叶斯、GBDT等算法,进一步优化模型,来提高准确性。
猜你喜欢
科学导报(2024年19期)2024-04-22 05:53:32
法人(2023年9期)2023-12-01 14:50:14
今日农业(2021年12期)2021-11-28 15:49:26
文萃报·周二版(2021年22期)2021-07-19 02:41:42
人民周刊(2021年11期)2021-07-09 08:28:38
中华养生保健(2020年3期)2020-11-16 00:52:28
小学生学习指导(低年级)(2020年6期)2020-07-25 02:31:36
故事会(蓝版)(2020年1期)2020-01-19 05:53:40
奥秘(创新大赛)(2019年10期)2019-10-24 11:36:38
World Journal of Clinical Cases(2019年6期)2019-04-17 02:25:08
