
改进YOLOV3算法在零件识别中的应用
2022-11-07 02:20宋栓军侯中原王启宇倪奕棋黄乾玮
机械科学与技术 2022年10期
宋栓军,侯中原,王启宇,倪奕棋,黄乾玮
(1.西安工程大学 机电工程学院,西安 710600;2.西安工程大学 现代智能纺织装备重点实验室,西安 710600)
随着自动化和智能化的发展,机器人与视觉系统相结合,在零件识别、缺陷检测等领域发挥越来越重要的作用。在工业生产过程中存在着大量的零件识别定位的任务,传统目标检测方法基本采用人工设计特征进行提取的方法来处理图像信息[1],如基于尺度不变特征变换的SIFT算法[2]、基于图像梯度信息的HOG算法[3]、描述图像纹理特征的LBP算法[4],但该类方法易受到目标物体的形状、大小、位置、外部光照等因素的影响,对特征的多样性缺乏鲁棒性[5]。
基于卷积神经网络的深度学习目标识别算法不需要人为设计特征,而是利用卷积特征实现自学习功能。由于卷积神经网络具有较强的泛化能力,可以在一定程度上克服目标变化、光照等因素的影响。自深度学习的概念提出以来,很多学者提出了众多基于卷积神经网络的深度学习目标检测算法。在two-stage方法中,利用候选框进行分类和回归,提出R-CNN[6]、Fast R-CNN[7]、Faster R-CNN[8]等检测算法,极大的提升了目标检测准确率,但同时会导致训练时间长,检测速度慢。在one-stage方法中,去除了候选区域操作,直接采用端到端的方式直接进行分类与回归,如YOLO[9]、SSD[10],其优势是速度快,可以实现实时检测的目的,但对小物体检测效果不好,存在一定的漏检率。
零件识别是一类目标检测问题,余永维等[11]提出了一种融合Inception预测结构的SSD框架,并使用标准化模块和残差结构连接,增加检测鲁棒性,提高检测准确率;华南理工大学的陈冠琪使用融合模块实现深层与浅层网络的跨层连接的MDSSD网络,相较于原SSD提高了检测精度[12];司小婷[13]等人使用一种多轮廓的方法,结合轮廓的几何特征与形状特征对图像做定位识别。郭斐等在原Faster R-CNN网络结构基础上减少卷积层数,加入Inception结构层,提出一种改进Faster R-CNN网络的零件识别算法,提高了零件识别的精度[14]。
本文的研究主要针对工业生产中小型零件存在漏检及识别率不高等问题。工业生产中零件的识别要求检测速度快,准确率高,综合当前主流的目标识别方法,选择YOLOV3算法。由于one-stage方法中存在小物体检测效果不好,漏检率高的情况,故在YOLOV3算法基础上设计了新的特征融合机构来克服YOLOV3检测小目标准确率低的缺点,并通过K-means++算法对锚点框重新聚类,提高检测速度的同时增加识别检测的精度。
1 YOLOV3算法原理
YOLOV3是一种基于回归的目标检测算法。YOLOV3算法是以Darknet53为基础网络,其模型结构如图1所示,首先将输入图片的尺寸转化为416×416,再将其输入到YOLOV3网络的主干特征提取网络中,主干特征提取网络是以Darknet53为基础网络,同时取消池化层和最后的全连接层,采用步长为2的卷积进行下采样,减少计算量的同时,保留了图片的更多信息。经过一系列下采样、卷积等操作,可以获得图片不同层次的位置和语义信息。在卷积神经网络中,低层含有较多的位置信息,但含有较少的语义信息,高层含有较少的位置信息,较多的语义信息,所以YOLOV3网络采用FPN(特征金字塔网络)结构对不同层次的特征图相融合,以实现对不同尺度目标的预测。网络输出层采用三层特征图进行预测,并通过非极大值抑制获得最终的检测结果。
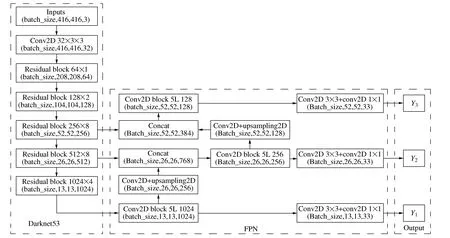
图1 YOLOV3网络结构
YOLOV3是基于直接回归的全卷积神经网络,不再产生区域候选框,在提高检测准确率的同时兼顾检测速度,在实际场景中应用较为广泛。
2 改进YOLOV3的零件识别定位方法
2.1 模型特征融合结构改进
YOLOV3采用FPN进行上采样和融合做法,融合了3个Anchor尺度(13×13、26×26、52×52),在多个尺度的融合特征图上分别独立做检测去改进目标检测的效果,但对于一些小目标而言,尤其是对于工厂生产中的螺母、垫片等微小型零件,存在准确度不高甚至漏检的情况。
YOLOV3的主干特征提取网络共进行了五次下采样,FPN部分利用8倍下采样、16倍下采样、32倍下采样的特征图通过卷积、上采样与对应的浅层特征图相融合,用融合后的特征层来检测目标。其用于检测的有效特征层分别为52×52、26×26、13×13,分别用于小目标、中目标、大目标的检测,若某一目标在原图像中的尺寸小于对应的8倍下采样特征图中的尺寸,则是无法检测到的,另外两种特征图检测小目标则会更加困难[15],YOLOV3的检测层如图2a)所示。本文提出的改进的检测层如图2b)所示,将52×52的特征层经过卷积和2倍上采样,将特征尺度由52×52提升到104×104,再将其与4倍下采样的104×104的特征图融合作为新的特征层,这样可以使高层特征具有更强的位置信息,低层的特征具有更强的语义信息,进一步加强定位的精度和小目标检测的准确度。

图2 原始FPN结构与本文提出的FPN结构
图3所示为改进的YOLOV3网络结构,在原先检测尺度的基础上增加了第4个特征尺度。输入图片经特征提取网络得到不同层级的图片信息,如图3所示。在FPN部分32倍下采样得到的13×13的特征图,经过一系列卷积后得到输出Y1;将32倍下采样特征图进行卷积和2倍上采样,与16倍下采样后的特征图进行匹配并融合,再经卷积后得到输出Y2;将16倍下采样特征图进行卷积和2倍上采样,同8倍下采样后的特征图进行匹配并融合,得到输出Y3;将8倍下采样特征图进行卷积和2倍上采样,同4倍下采样后的特征图进行匹配并融合,得到输出Y4。本文中YOLOV3输出了4种不同尺度的特征图来进行预测,如图中所示Y1、Y2、Y3、Y4,特征图进一步精细,可以检测出更精细的目标。
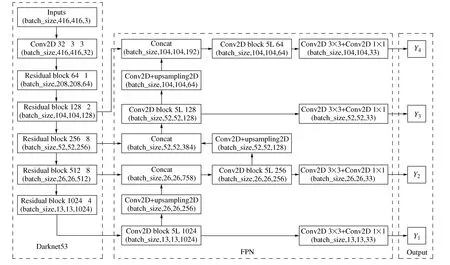
图3 改进的YOLOV3网络结构
2.2 K-means++实现锚点框聚类
在YOLOV3中,为高效地预测不同尺度与宽高比的物体边界框,采用Anchor(锚点框)机制,合适的Anchor值可以实现更快速、准确的定位,同时减少损失值与计算量,提高目标检测的速度与精度。YOLOV3原始的Anchor值是采用K-means算法在VOC数据集20类和coco数据集80类进行聚类而得,每个特征图对应的特征点采用3个不同比例(1∶2、1∶1、2∶1)的Anchor框,考虑到原YOLOV3有3个不同尺度的特征图,故聚类9个不同尺度Anchor框来预测不同大小的目标。
沿用YOLOV3中的Anchor思想,本文提出的改进YOLOV3通过4个不同尺度的特征图来实现预测,按照每个特征点需要聚类3个不同比例的Anchor框的原则,需聚类12个不同尺度的Anchor。原始的K-means聚类算法随机选取K个数据点作为原始的聚类质心,这种聚类方法对初值敏感,不利于寻找全局最优解,因此本文采用K-means++算法对原算法进行优化。K-means++算法让初始的聚类中心之间的距离尽可能远,而不是随机产生,具体步骤如下:
步骤1 首先令K=12,随机选取一个点作为第一个聚类中心;
步骤2 然后计算每一个点与当前已有聚类中心的最短距离(即与最近一个聚类中心的距离),这个值越大,表示其被选取作为聚类中心的概率值越大,采用轮盘赌法依据概率大小进行抽选,选出下一个聚类中心;
步骤3 重复步骤2,直到选出k个聚类中心;
步骤4 选出聚类中心后,继续使用K-means算法进行聚类。
其中聚类方法中距离公式定义如下
d(box,cen)=1-IOU(box,cen)
(1)
式中:Box为矩形框的大小;cen为矩形框的中心;IOU表示两个矩形框的交并比。
通过聚类最终选取的12个Anchor为(25,34)、(28,38)、(31,35)、(31,42)、(34,41)、(36,113),(36,47)、(57,80)、(66,87)、(78,62)、(79,97)、(84,42)。
2.3 损失函数构建
零件识别定位的损失函数由坐标误差、置信度误差及分类误差组成。坐标误差由中心坐标误差和宽高坐标误差组成。
中心坐标误差为
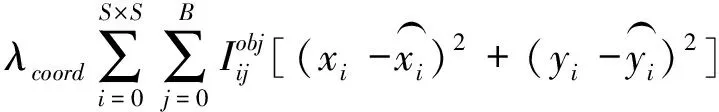
(2)
宽高坐标误差为
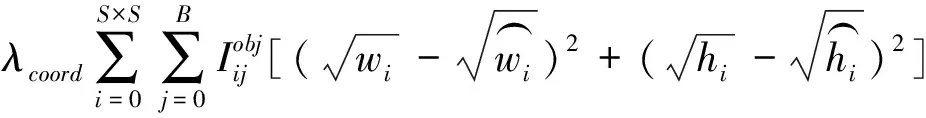
(3)
含有目标的bbox置信度误差为
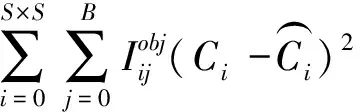
(4)
不含目标的bbox的目标置信度误差为
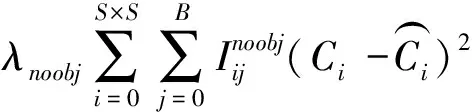
(5)
分类误差为

(6)
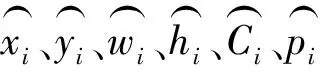
3 实验结果与分析
3.1 零件数据集与实验环境
深度学习网络需要大量数据集作为支撑。目前,在零件识别工业应用方面缺少完整的数据集,本文自行制作了一套数据集,包含螺栓、螺母、垫片、十字形管接头(shiJT)、T型管接头(tJT)、以及c型管接头(cJT)六类零件的数据集,通过变换光照、零件位姿、模拟实际情况中零件混合、堆叠等情况,一共采用3560张图片作为本次实验的训练集与测试集,以此增强数据集的可靠性。图4所示为采集的部分数据集。

图4 采集数据集部分样本
获得采集到的零件数据集后,采用LabelImg工具对图片进行标注工作,将图像中出现的6类目标标注出来,保存为xml文件,按照4∶1的比例划分训练集与测试集。
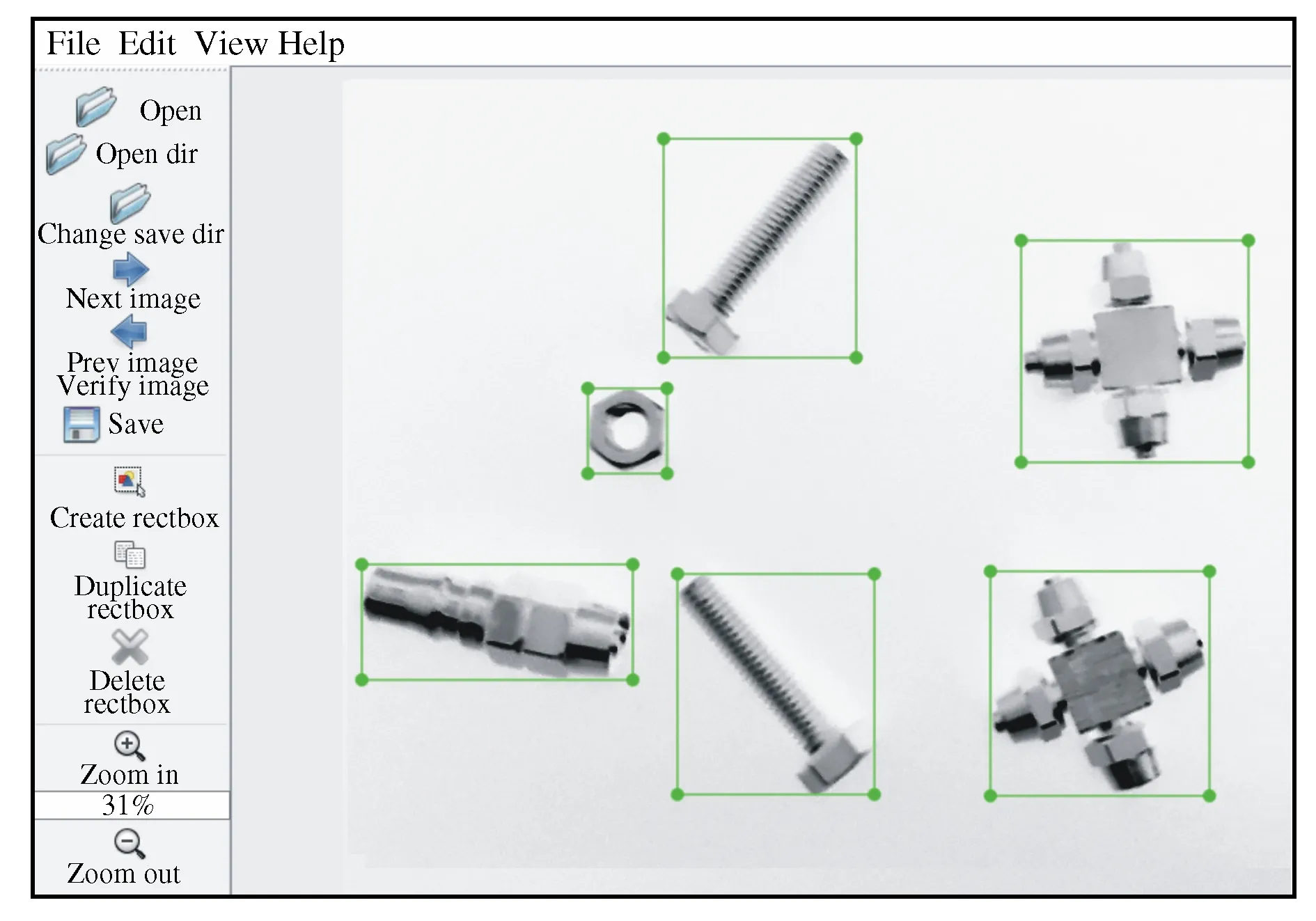
图5 零件标注状况
实验环境的配置如表1所示,本文所有实验均在该环境下进行。

表1 环境配置表
3.2 检测结果及分析
3.2.1 模型训练
调整好模型参数后,进入模型训练阶段,为了增强网络的稳定性,相关模型参数如表2所示。本文采用Adam优化器对网络进行优化,并采用自适应调整策略对学习率进行动态调整,共进行100个Epoch训练,step-size取30、gamma取0.1,即每隔30个epoch学习率下降10倍。
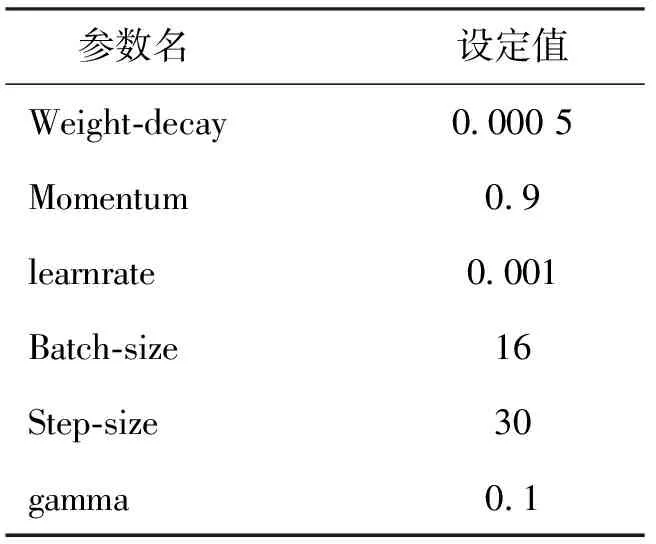
表2 相关训练参数
3.2.2 评价指标
本文采用的对模型的评价指标为mAP值,mAP值为为所有类的AP值的平均值,AP值为精确度(Precision)为纵坐标和召回率(Recall)为横坐标所围成曲线的面积[16]。准确度用来衡量目标检测的准确度,召回率用来衡量目标漏检率,计算公式如下:
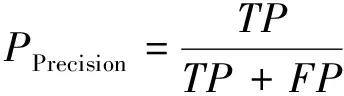
(7)
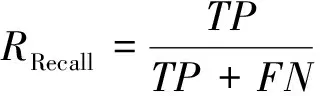
(8)
式中:TP表示被正确的分为了某类样本的数量;FP表示被错误的分为了某类样本的数量;FN表示样本被错误识别的数量。本文的检测结果采用mAP作为评价指标评估模型的效果。
本文提出的改进YOLOV3与原始YOLOV3部分检测结果对比如图6所示。
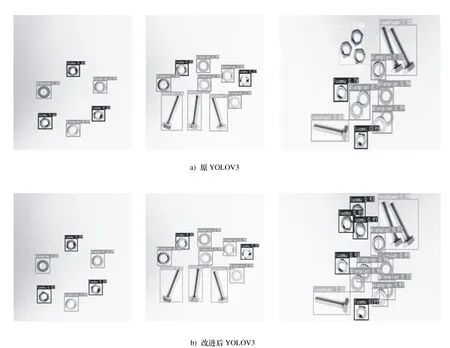
图6 检测效果对比图
考虑在实际场景中常出现零件混合、堆叠的情况,其检测效果如上图所示。原YOLOV3算法在检测相对较小的零件时存在漏检及准确率低的情况,而改进YOLOV3算法能够很好的解决这个问题,如图6所示。对于图片中多类零件,后者具有更高的置信度,分类更准确。两种算法的检测结果如表3所示。相较于原YOLOV3,改进后的YOLOV3在检测准确率上有了较大的提升,在小目标的检测准确度上提升更为明显。
如图7所示,原YOLOV3检测的平均精度为90.77%,改进YOLOV3算法检测的平均精度为95.64%,相较于YOLOV3提高了4.87%。从以上检测的结果来看,改进YOLOV3的性能要强于原YOLOV3,说明通过改进特征融合结构能在不同种类的零件识别尤其是小零件的识别上取得较好的效果。
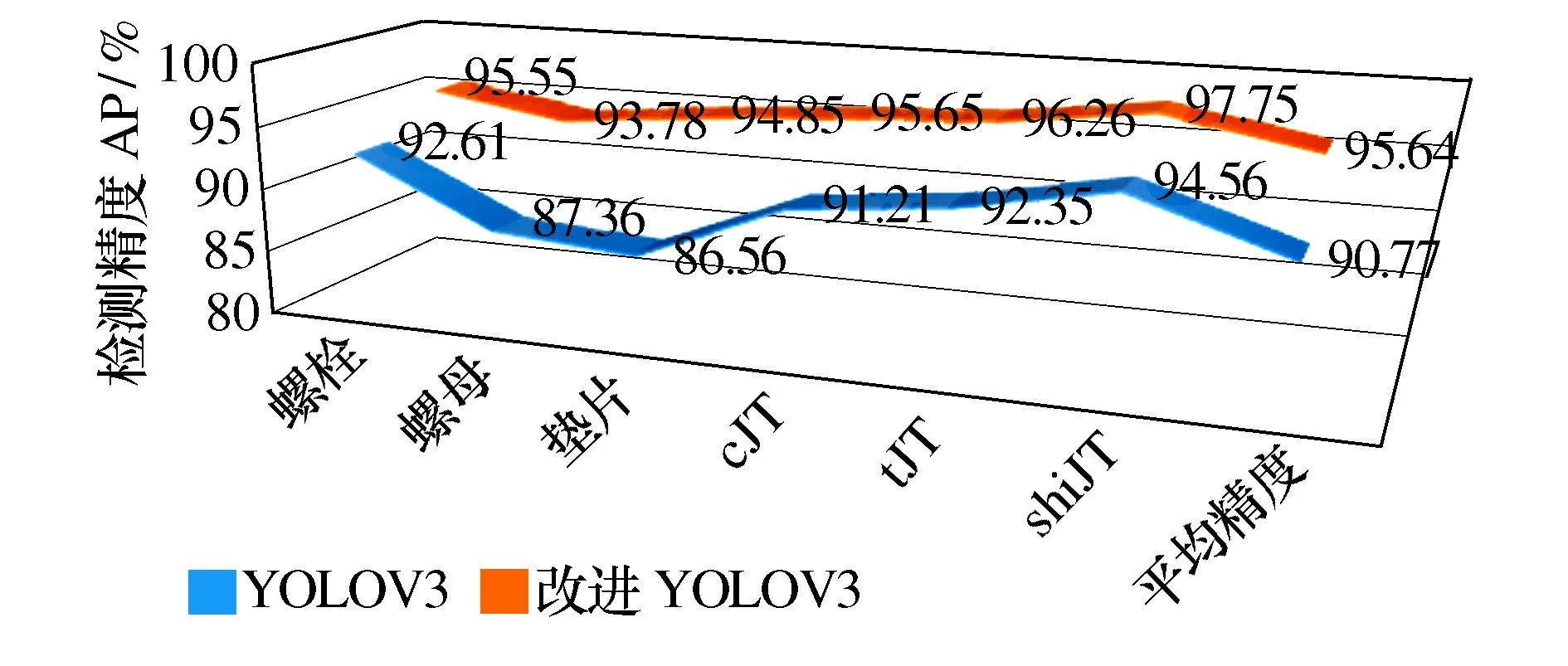
图7 改进YOLOV3与原YOLOV3方法检测效果
4 结论
本文对工业生产中常见零件尤其是小型零件识别中的漏检及识别准确率低的问题,提出了改进YOLOV3的目标识别算法。通过设计新的特征融合机构来增加新的特征层,克服YOLOV3检测小目标准确率低的缺点,并通过K-means++算法对Anchor重新聚类,提高检测速度的同时增加识别检测的精度。上述实验结果表明,相较于YOLOV3,本文方法在小型零件识别准确率上有较大提升,优化后算法的mAP提高了4.87%,符合实际生产中零件检测的需求。接下来的研究需进一步拓展数据集中零件的种类和数量,进一步提高检测模型的泛化能力。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
太空探索(2016年5期)2016-07-12
互联网天地(2016年1期)2016-05-04
