
基于BERT模型的指令集多标签分类研究
2022-11-05 07:45:12王淳睿何先波
智能计算机与应用 2022年10期
王淳睿,何先波,易 洋
(1 西华师范大学 电子信息工程学院,四川 南充 637009;2 西华师范大学 计算机学院,四川 南充 637009)
0 引言
研究可知,编译器作为芯片生态系统中的重要一环,对自主操作系统的研发起着非常关键的基础性作用。2021年4月,龙芯推出Loong Arch国产自主指令集(Instruction Set Architecture,ISA),一方面折射出国内芯片生态系统的发展潜力,同时也展示出了国内芯片生态系统的应用前景。然而面对全新的ISA、例如Loong Arch,构建出支持Loong Arch架构的编译器后端需要耗费大量人力以及时间。本文参考低级虚拟机(Low Level Visual Machine,LLVM)中指令描述的代码,将指令划分为13类,并以此为分类原则训练基于BERT的多标签分类模型。该模型对Mips、ARM指令集架构手册中指令的分类有着不错的表现,根据指令分类完成的类别可减少开发人员对编译器后端指令定义相关部分所花费的时间,从而有效提升编译器构建效率。
1 相关理论及方法
1.1 BERT训练模型
BERT(Bidirectional Encoder Representation from Transformers)是一种为不同自然语言处理任务提供支持的预训练语言表示模型。该模型基于2017年谷歌公司发布的Transformer架构,由Transformer的双向编码器构成。区别于ELMo和GPT等单向传统语言模型,BERT利用掩码语言模型(masked language model,MLM)进行预训练,并且采用深层的双向Transformer组件来构建整个模型,最终生成能融合左右上下文信息的深层双向语言表征,增加一个输出层,可以对预训练的BERT模型进行微调(Fine-Tuning),为各类执行任务创建先进的模型,无需针对特定任务的架构做实质性的修改。
BERT的模型架构采用了Transformer模型的编码部分,模型的输入由3种嵌入层累加构成,具体就是:词嵌入(Token embeddings),将各个词转换成固定维度的向量;分段嵌入(Segment embeddings),用于 区 分 不 同 的sentence;位 置 嵌 入(Position embeddings),用于表征词语位置关系。输入的编码如图1所示。

图1 输入编码示例图[4]Fig.1 Input coding example diagram[4]
BERT处理下游任务如多标签分类任务、采用的是微调的方式,一般而言,仅需要少量的改动,即可将BERT与下游任务融合,整体流程如图2所示。
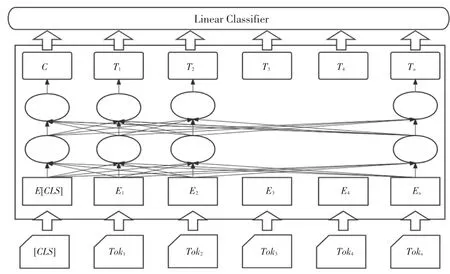
图2 fine-tuning架构图Fig.2 fine-tuning architecture diagram
作为一个预训练模型,BERT需要应对模型的输入序列变长问题。BERT提供了2种方法加以解决:
(1)使用分割token([])插入到每个句子中,来分开不同句子token序列。
(2)为每个token特征添加一个可学习的分割embedding来表示句子的分割点。
区别于ELMo和GPT等单向传统语言模型,BERT模型的优点是:
(1)采用MLM对双向的Transformers进行预训练,来生成深层的双向语言特征。
(2)在训练后,只需要额外的输出层进行微调,就能在多种任务中取得良好表现,在这个过程中不需要再对BERT的结构进行修改。
综合前述分析后可知,本文拟选择BERT作为实验的预训练模型。
1.2 指令分类原则
CPU架构是CPU产品制定的规范,旨在区分不同种类的CPU,目前市场上的CPU主要分为2类。一类是Intel、AMD为代表的复杂指令集CPU,另一类是以ARM、IBM为代表的精简指令集CPU。为了将不同品牌、不同类别架构的指令集进行统一的分类、从而提高构建编译器的效率,减少构建所需要的时间,本文参考了LLVM中描述指令的代码以及文献[6]中的方法,将指令共划分为13类,详见表1。需要指出的是,目前国内外多标签分类更多的是应用在医学、新闻等领域,应用BERT将计算机指令进行多标签分类的研究甚少,这是本文的研究亮点之一。

表1 指令类别划分Tab.1 Classification of instructions
2 相关工作
2.1 数据集制作
在已经推出的开源数据集平台中,指令集相关的数据集甚少,故本文将从Mips32、Mips64、ARM等指令集架构手册中手动提取出有关指令描述的文本,并且从LLVM的目标平台td文件中检索出每条指令的类别,如图3所示。

图3 数据集示例图Fig.3 Dataset example graph
实验共整理MIPS架构指令数据640条,通过随机采样的方式将数据按照8:1:1的比列划分为训练集、验证集与测试集。每一个Segment长度均小于512,类别包含:返回指令、条转指令、分支指令等共13类。和仅包含消极与积极两种类别的情感分类数据相比较,则更加清晰地展现了本文提出的模型的优越性。
由于本文的实验训练数据较少,所以增加了对BERT模型的预训练任务。预训练任务的数据集来自Mips32指令手册、ARMv8指令手册、RISCV指令手册等共计16本指令集手册,
本文首先使用训练集进行模型的训练,然后在验证集上对模型参数进行不断地调整,直至找到模型的最优参数,最后在测试集上进行测试。
2.2 文本预处理
本文运用了文本的预处理方法,对描述指令文本中的无效信息进行清洗,主要是对文本中的无用符号、停用词、非文本数据等进行处理。对预训练数据先将格式由PDF转换成TXT格式,再将TXT文件进行处理,每一行只保留一句文本,接着又将16本指令集手册合并为一个TXT格式,再将预训练数据处理成MLM(Mask Language Module)任务的数据,如图4所示。
在图4给出的整个MLM任务数据集的构建流程中,第一阶段和第二阶段是根据原始语料来构造MLM任务所需要的输入和标签;第三阶段是随机屏蔽掉部分来构造MLM任务的输入,并同时进行padding处理;第四阶段则是根据第三阶段处理后的结果来构造MLM任务的标签值,其中[]表示padding的含义,目的是为了忽略那些不需要进行预测的在计算损失时的损失值。
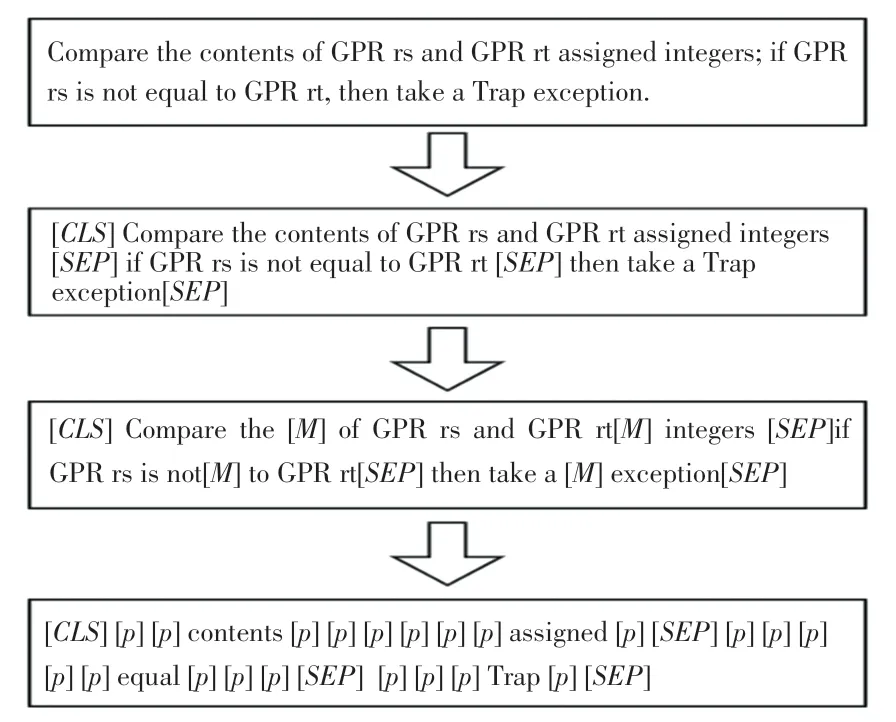
图4 MLM任务数据集构造流程图Fig.4 MLM task dataset construction flowchart
2.3 实验环境
本文实验使用PyTorch深度学习架构训练基于BERT的多标签分类模型,并配置好GPU在Ubuntu16.04系统上。实验环境配置具体见表2。

表2 环境配置Tab.2 Environmental configuration
2.4 实验内容
由于本文实验训练数据的数量有限,对于目标任务数据量少的情况下如果直接训练就可能无法获得足够多的特征,如此一来则难以较好地学习到特征和一些重要信息,所以本文使用相关领域的大量数据进行预训练就可以学习到本领域的更多的特征和信息,这样迁移到数据量小的任务上进行微调就可以达到更好的效果。
BERT预训练采用了2个训练任务,上文提到的Masked LM任务用来捕捉单词级的特征,Next Sentence Prediction任务用来捕捉句子级的特征。本文随机屏蔽掉语料中15%的,然后去预测被屏蔽掉的,将masked token位置的隐藏层向量输出即可得到预测结果。
本文首先在预训练数据集上对BERT进行预训练,下游任务在训练时会将已经训练好的模型参数加载到网络中,然后使用Mips32数据集进行下游任务训练,最后找出在测试集上最优模型在其他架构数据集上进行测试,本实验详细的模型参数见表3。

表3 模型参数设置表Tab.3 Model parameters setting table
2.5 评价指标
本文使用值作为评价本多标签分类实验的指标,值用于权衡和,可定义为精确率和召回率的调和平均数。本次研究中推导得出的各数学定义的公式表述分别如下。
(1)精确率。这里用到的数学公式可写为:

(2)召回率。这里用到的数学公式可写为:

(3)准确率。这里用到的数学公式可写为:

(4)值。这里用到的数学公式可写为:
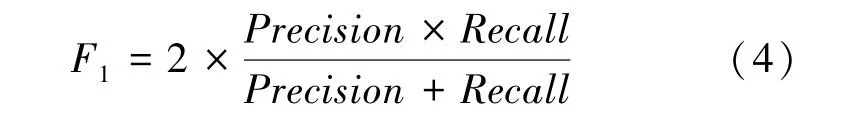
其中,(True Positive)表示预测为正,实际为正;(False Positive)表示预测为正,实际为负;(True Negative)表示预测为负,实际为负;(False Negative)表示预测为负,实际为负。通过统计、、、等数据可以计算出精确率和召回率[10]。
3 实验结果
实验结果见表4。由表4可见,本文提出的多标签分类模型经过在Mips32训练集上训练,准确率达到了96.4%,值达到92.5%。分析后发现,BERT语言模型经过训练,在Mips32架构指令集上有着不错的表现。再将训练后的模型使用Mips64和ARMv8架构指令集数据进行测试,准确率分别达到了94.7%和86.1%,值则分别达到了90.9%与27.9%。
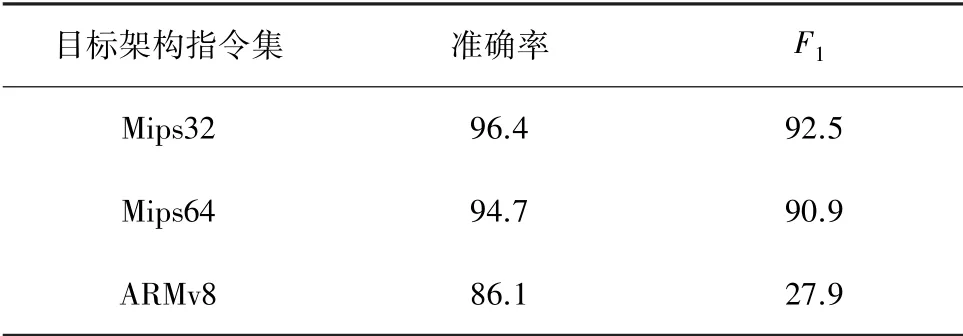
表4 实验结果Tab.4 Experimental results %
实验结果的柱状表示见图5。由图5可以看到,模型在Mips32指令数据集上的准确率与Mips64指令数据集上的准确率相近,并且高于ARMv8指令数据集上的准确率,一定程度上也表明了本文提出的分类方法在同种架构中有着不错的分类表现,在2种不同架构的指令集上分类能力要低于同种架构指令集。
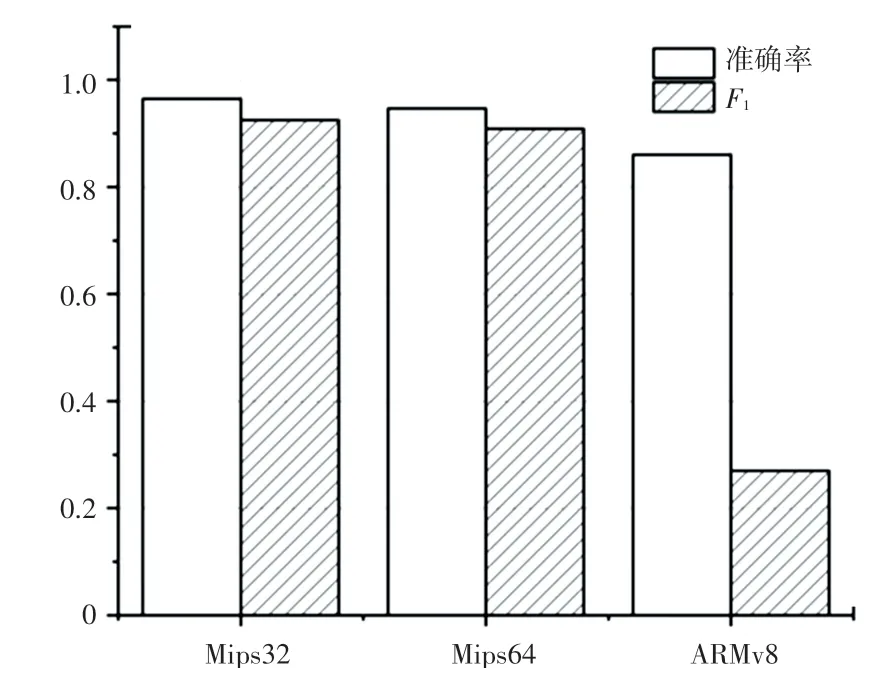
图5 实验结果柱状图Fig.5 Histogram of experimental results
4 结束语
本文根据LLVM编译器架构中对指令描述的代码对指令进行分类,从Mips32架构指令集手册中提取出指令的描述文本,并根据上述分类原则对文本数据进行手工标注,最后实现了对BERT模型的预训练和s下游多标签分类任务的训练。经过对Mips64与ARMv8架构指令集的分类测试结果表明了本文提出基于BERT模型的指令集多标签分类研究方法在指令多标签分类任务中的有效性。
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
电脑报(2021年49期)2021-01-06 18:36:55
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
数学物理学报(2017年5期)2017-11-23 07:51:31
电测与仪表(2016年21期)2016-04-11 12:42:34
中国信息化周报(2014年19期)2014-07-22 15:43:11
计算机工程(2014年6期)2014-02-28 01:28:03
