
改进的YOLOv3交通标志识别算法
2022-11-04 07:11林轶陈琳王国鹏盛余洋孙立超
科学技术与工程 2022年27期
林轶, 陈琳*, 王国鹏, 盛余洋, 孙立超
(1.长江大学计算机科学与技术学院, 荆州 434000; 2.三峡大学计算机与信息学院, 宜昌 443000)
近年来,随着目标检测技术的发展,交通标志的精准识别对高级辅助驾驶起着不可或缺的作用。而交通标志通常置于室外场景,在自然环境下受到雨淋、光照、老化等因素干扰,为确保到驾驶员的安全,在实际应用场景既要考虑检测的速率,也要注重识别精度。
传统目标检测遵循手工设计特征并结合滑动窗口实现目标识别与定位,此方法准确度低、鲁棒性差且无法实现实时检测。在计算机视觉领域中,深度学习凭借卷积神经网络逐步取代传统手工设计,并在目标检测、目标分类和目标分割等任务上有着良好的表现。目标检测主要分为One-stage和Two-stage检测算法,其中One-stage典型算法如SSD[1]、YOLO[2]、YOLOv2[3]、YOLOv3[4]等,直接回归目标的分类与坐标位置,相比Two-stage有更快的检测速度。Two-stage典型代表是R-CNN[5]、Fast R-CNN[6]、Faster R-CNN[7]等,通过利用区域生成网络[8](region proposal network, RPN)对候选区进行区域推荐,相比One-stage有更高的检测精度。
当前已有学者将目标检测算法应用到交通标志识别中。宋青松等[9]提出一种聚类残差单次多盒检测算法(single shot multibox detector ,SSD),在德国交通标志数据集(german traffic sign detection benchmark ,GTSDB)上准确率达到89.7%,检测速度仅为0.96 f/s。Song等[10]提出一种高效的卷积神经网络,在TT100K数据集上精准度高于Fast R-CNN及Faster R-CNN近10%。Cao等[11]在LeNet-5卷积神经网络模型基础上,采用Gabor作为初始核,选择Adam作为优化算法,在GTSDB数据集上检测精度达到99%。以上学者的方法具有高精度与通用性,但模型网络复杂致使计算量大识别速度慢,无法满足实时检测要求。
针对YOLOv3检测算法和一些卷积神经网络检测过程中,无法兼顾精度和速度的平衡,提出一种改进的S-YOLO算法。在实验部分,将S-YOLO与YOLOv3以及其他检测算法进行对比分析,S-YOLO实现了交通标志检测的有效性,同时在实时场景下达到理想的检测精度。
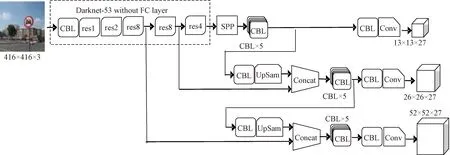
图2 S-YOLO实现图Fig.2 S-YOLO implementation diagram
1 YOLOv3检测模型
YOLOv3为One-stage目标检测算法,采用Darknet-53网络作为主干特征提取网络,替代了YOLOv2的Darknet-19,共有53个卷积层,整个结构无池化层和全连接层。该网络由5个残差块构成,每个残差块由CBL(Conv, Batch Normalization) LeakyRelu和残差组件组成,如图1(a)所示。其中,CBL是Darknet-53网络中最小组件,由卷积层、批归一化层和Leaky_relu激活层组成,如图1(b)所示。通过引入ResNet[12]残差结构,避免训练过程造成梯度爆炸和消失等问题,降低深层网络训练难度。

图1 Darknet-53组件结构Fig.1 Darknet-53 component structure
2 改进的S-YOLO检测算法
YOLOv3在通用场景下已取得良好的检测效果,但针对交通标志识的识别还存在一些不足:在CBL组件上多了一些层的计算,导致占用更多的显存,降低检测速度;初始先验框为COCO数据集聚类的结果,不适用于交通标志;网络结构对于小目标的交通标志检测效果不理想;使用交并比(intersection over union, IoU)作为损失函数,在一些特殊条件下会出现异常值。针对上述问题,提出一种改进的S-YOLO算法,主要改进思想:合并批归一化层[13](batch normalization,BN)到卷积层,减少一些层的计算,加快模型前向推理;使用二分K-means算法,对交通标志重新聚类确定初始先验框,实现精准定位;添加空间金字塔池化(spatial pyramid pooling,SPP)模块[14],有效地提取出交通标志的深度特征,提升模型检测精度;采用CIoU[15]损失函数,通过最小化预测框与真实框的中心距离并增加长宽比的惩罚,加快模型收敛,提升模型检测精度。
S-YOLO算法实现整体流程图如图2所示,将图像输入Darknet-53主干网络进行卷积等操作生成三种特征层,对第三个特征层进行空间金字塔池化操作,再进行上采样后和第二个特征层进行张量拼接,同理,将第二个特征层进行上采样后再与第三个特征层进行张量拼接,最后进行卷积等操作生成三种不同尺寸的特征图。
2.1 合并BN层到卷积层

图3 合并BN层到Conv层Fig.3 Merge BN layer to Conv layer
YOLOv3引入了批归一化BN层,位于卷积层后,在训练阶段加快网络收敛,解决了梯度爆炸和消失等问题,增强网络健壮性。将BN层参数合并到卷积层,减少计算量以达到模型前向推理速度的提升。如图3所示,图像经过卷积再到BN层进行归一化。计算过程为
(1)
xconv=xiwi+b
(2)
式中:xbn为BN计算结果;β为偏置;γ为缩放因子;μ为均值;为正则化参数,σ2为方差;xconv为卷积后结果;xi为输入特征图;wi为权重参数。
合并BN层到卷积层,将式(2)代入式(1)中得到新的卷积层为
(3)
合并后的权值参数为
(4)
偏置为
(5)
最终得到
xbn=xiwnew+bnew
(6)
BN层合并于卷积层后,新的卷积层参数只有权值wnew和偏置bnew,且少了BN层的计算,从而降低内存的使用,加快模型推理速度。
2.2 特征金字塔池化
引入空间金字塔池化模块,将特征图的局部与全局特征融合,丰富特征图的表达能力。融合过程如图4所示,原始图像经过Darknet-53后得到13×13×256特征图,将该特征图输入SPP模块后,进行4个分支操作,从输入直接到输出,分别在3种大小的池化核进行下采样,生成3个局部特征图,再将4个特征图进行张量拼接,得到13×13×1 024的特征图,增加了特征图的深度,丰富了交通标志的多尺度信息。
改进的S-YOLO网络结构如图5所示,Darknet-53网络对输入的图像进行下采样等操作,最终获得3种尺寸特征图,分别在3组特征图的基础上进行目标预测。网络实现的具体过程如下:首先将13×13×1 024特征层进行5次卷积后得到第一个中间层,再将该层进行分类和回归预测,得到预测层13×13×75;同时,将第一个中间层进行卷积和上采样,与Darknet-53生成的26×26×512特征层进行Concat操作,即特征金字塔搭建过程,得到第二个中间层,再将该层进行分类和预测,得到预测层26×26×75;同理,将中间层进行卷积和上采样,与Darknet-53生成的52×52×256特征层进行Concat操作,得到第三个中间层,再将该层进行分类和预测操作,最终得到预测层52×52×75。通过上述操作,得到3组不同尺度的预测层,能有效地提取到小目标的特征信息。
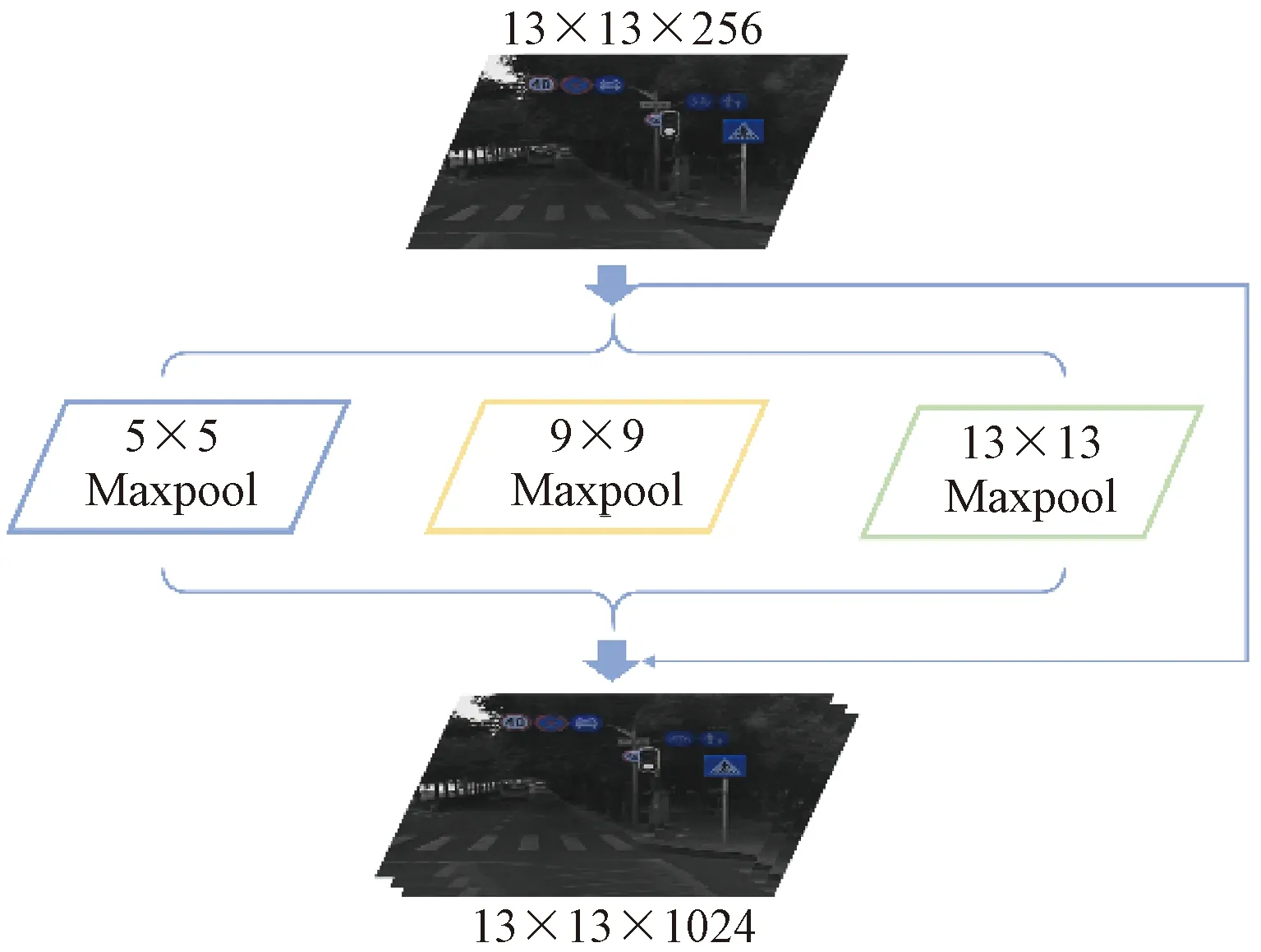
图4 张量拼接Fig.4 Tensor splicing

图5 S-YOLO网络结构Fig.5 The network structure of S-YOLO
2.3 二分K-means聚类算法
采用二分K-means对数据集进行聚类,相较于K-means,该算法减少相似度计算量以提高执行速度,并克服局部收敛的不足。其距离度量公式为
d(box,centroid)=1-IoU(box,centroid)
(7)
式(7)中:box表示先验框;centroid表示先验框的中心,IoU为两个先验框的交集与并集的比。
图6为使用二分K-means聚类得到先验框个数K与IoU关系。从图6可知,随着K的增大,IoU值逐渐递增,当K=9时,IoU增长趋于平稳,综合交通标志检测精度与速率,该点为最佳初始框框个数。最终得到的9个先验框为(9,15)(4,21)(19,28)(24,36)(31,43)(39,52)(50,69)(67,89)(91,116),分别对应13×13、26×26、52×52这三种尺度特征层。
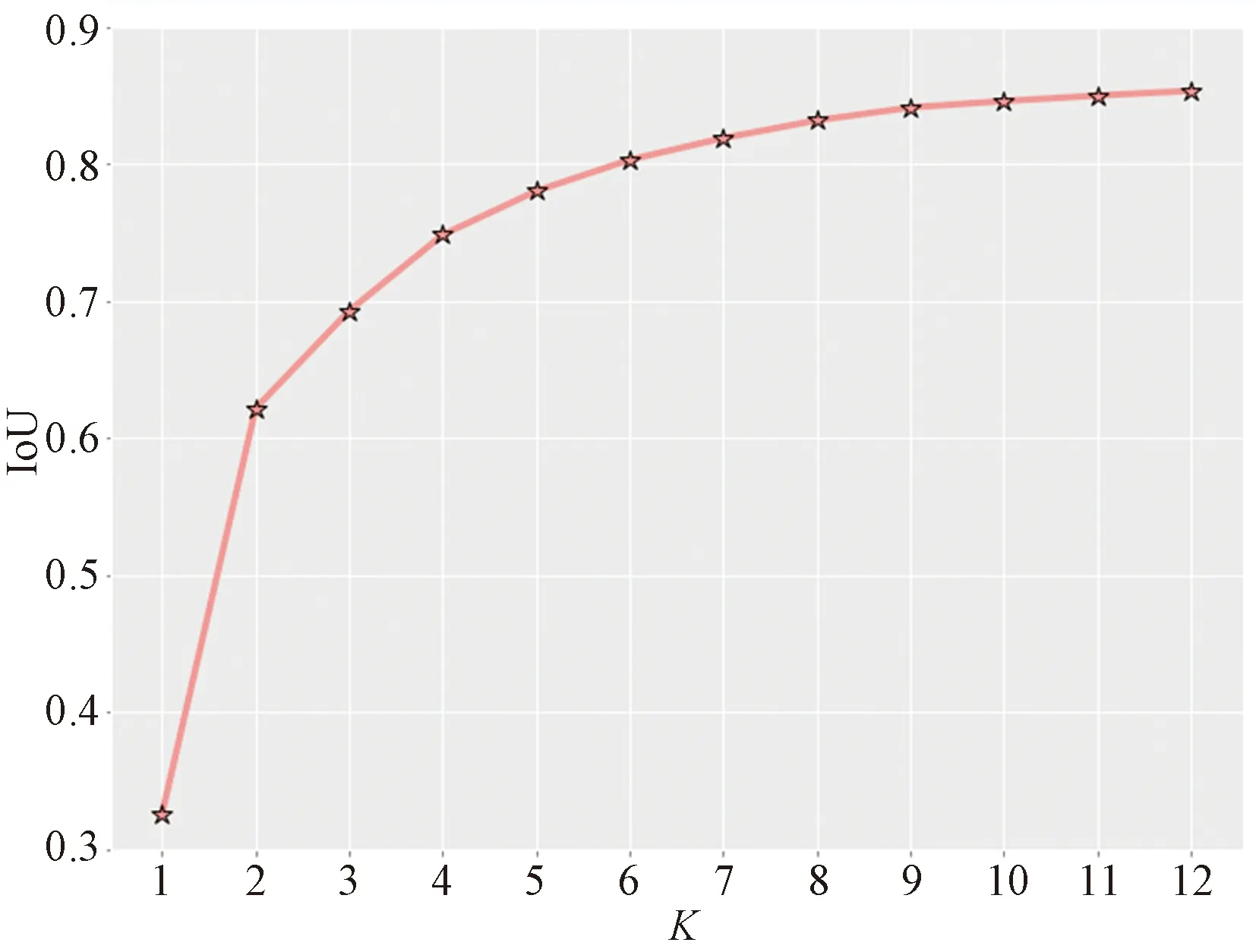
图6 先验框个数K与IoU关系Fig.6 The relationship between K and IoU
2.4 CIoU回归损失函数
IoU作为评价模型性能的一个重要指标,通过计算预测框与真实框交并比的值来衡量边界框的相似度。计算公式为
(8)
式(8)中:area(A)为预测框的面积;area(B)为真实框的面积。常见的计算IoU损失函数为
(9)
该损失函数反映出边界框的重合程度且具有尺度不变性,但存在两个缺陷:当预测框与真实框不相交时,如图7所示,IoU=0,LIoU=1,此时LossIoU不可导,无法反映边界框之间距离;当预测框与真实框的尺度相同且IoU也相同时,LossIoU无法区分两者相交的情况。

图7 预测框与真实框不相交Fig.7 Prediction box don’t intersect the ground-truth box
为弥补IoU损失函数的不足,采用CIoU作为目标框的坐标回归损失,其计算公式为
(10)
(11)
(12)
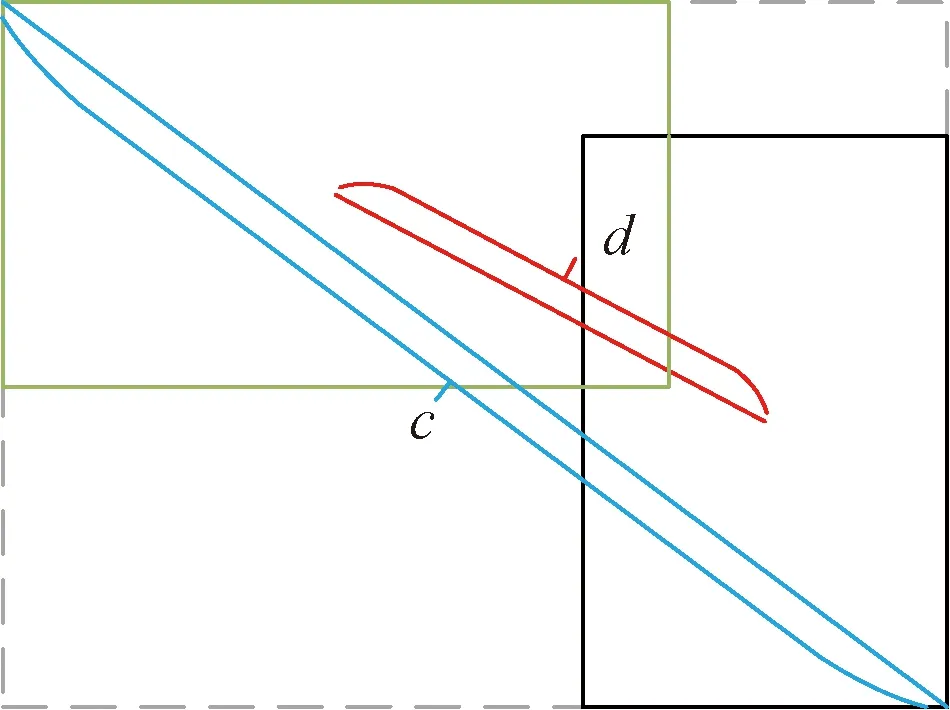
图8 CIoU实现图Fig.8 CIoU implementation diagram
3 实验与分析
精选部分CTSDB[16]数据集并网络爬取百度图库,为了提高数据集的泛化性,对样本进行旋转、压缩、添加噪声等图像增强方式,最终获得数据集6 218张,训练集与验证集按照3∶1分配,选取数量最多的4类交通标志作为检测对象,分别为限速(speedlimit)、禁止(prohibitory)、指示(mandatory)和行人(pedestriancrossing)。
3.1 实验环境与配置参数
本实验的软硬件环境配置如表1所示。在网络训练阶段,使用原始YOLOv3提供的参数作为初始化参数,选用迁移式学习方法,通过YOLOv3内置参数进行迭代调整,实验参数如表2所示。
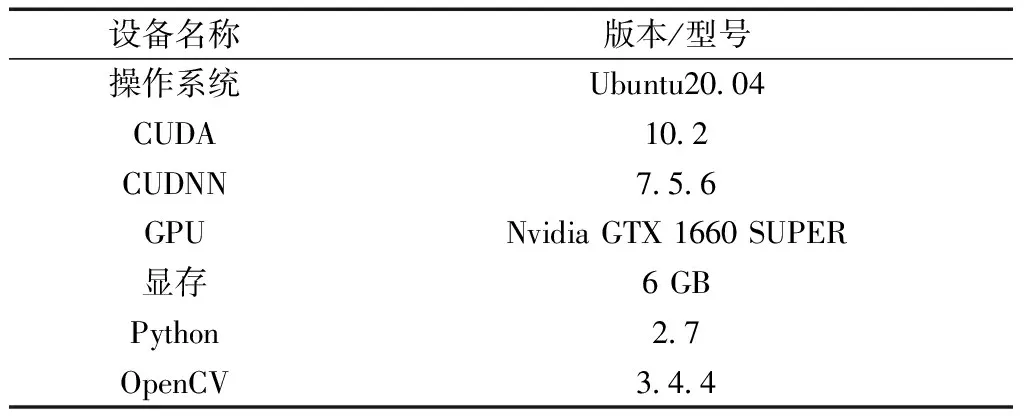
表1 实验环境配置Table 1 Experimental environment configuration

表2 S-YOLO参数配置Table 2 S-YOLO parameter configuration
3.2 评价指标
为了对不同模型进行性能评估,采用平均准确率(mean average precision, mAP)、准确率P(precision)、召回率R(recall)、F1值及检测速度每秒帧率(frame per sceond, FPS)作为衡量模型性能的指标,计算公式分别为
(13)
(14)
(15)
式中:TP为真正例;FP为假正例;FN假负例;m为类别;AP为类别平均精度。
3.3 实验对比与分析
3.3.1 消融实验
为验证所提方法的有效性,在重制的CTSDB交通标志数据集上进行消融实验,以mAP、R、FPS和F1四项作为算法的评价指标,通过替换或组合模块来对模型进行训练,再对训练完成的权重文件进行测试,验证各个模块对网络性能的提升,如表3所示。从表3可知,模型A相对Base模型,在不影响检测精度前提下仅提升了识别速度,表明合并BN层到卷积层只提升了模型的识别速度,但不影响检测精度;对比模型A与模型B、C、D可知,添加二分K-means、SPP、CIoU模块相对模型性能都有一定的提升,在mAP上分别提升了0.93%、1.3%、2.21%,而识别速度几乎一致;对比模型A与模型E、F、G可知,将每两个模块进行结合模型性依旧提升,在mAP上分别提升了2.18%、2.26%、3.51%;最后将四个模块相结合得到S-YOLO模型,在mAP上提升了4.26%,速度提升了15.19%。消融结果可知,合并BN层到卷积层、添加二分K-means、SPP、CIoU模块对于网络的性能均有一定的提升。

表3 重制的CTSDB数据集上消融实验结果Table 3 Ablation experimental results on the reproduced CTSDB dataset
3.3.2 其他算法比较
为更进一步验证所提算法的检测性能,将Tiny-YOLOv3、YOLOv3、SSD ReNet50[17]、Faster R-CNN[9]以及YOLOv4[18]与S-YOLO算法进行对比,以mAP和FPS作为评价指标,实验结果如表4所示。数据表明,S-YOLO的mAP和FPS分别达到94.33%和42.41 f/s,相对Tiny-YOLOv3和YOLOv3,在mAP上分别提升了5.36%和4.26%,虽然FPS不及Tiny-YOLOv3,但其检测精度明显高于Tiny-YOLOv3;对比Faster R-CNN算法,虽然在精度上略低,但其检测速率远高于Faster R-CNN;SSD算法在mAP和FPS两项指标上分别为89.7%和0.08 f/s,均不及S-YOLO算法;对于当前的YOLOv4算法,在mAP上高于本人提出的算法1.67%,但识别速度为26 f/s。
对兼顾精度与速度的检测环境而言,所提的S-YOLO算法在精度和速度兼顾的条件下有更好的检测性能,达到一个实时检测效果。
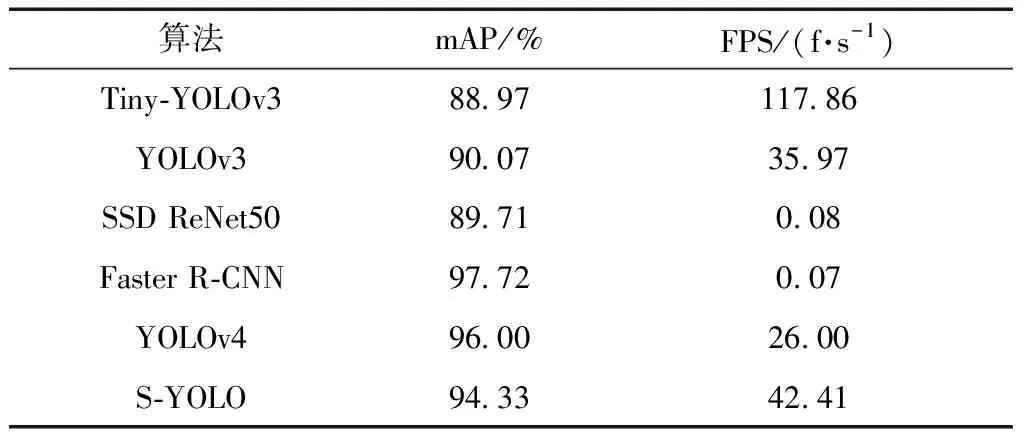
表4 其他模型对比实验Table 4 Comparative experiment of other models
3.3.3 权重测试
使用Loss-IoU和Loss-CIoU作为回归损失训练得到的权重文件,以IoU和CIoU作为评价度量进行比较,将阈值(threshold)设置为0.75,分别在IoU和CIoU下进行验证,统计结果见表5,Promote为提升度。数据表明,Loss-CIoU在测试数据集AP值较Loss-IoU分别提高了7.80%,并且Loss-CIoU的平均IoU阈值(AP)较Loss-IoU提高了3.40%,表明采用Loss-CIoU作为损失函数的模型性能得到优化。

表5 不同损失函数性能比较Table 5 Performance comparison of different loss functions
3.4 检测可视化

图9 S-YOLO检测效果Fig.9 S-YOLO detection visualization
图9为S-YOLO在不同环境场景下对交通标志的检测结果。由图可知,在目标密集、雨天、暗光等复杂场景下,S-YOLO具有良好的识别效果,并能精准地检测出相应的交通标志。
为进一步验证所提模型的泛化性,将原始YOLOv3与改进的S-YOLO在TT100K交通标志数据集中进行对比实验。如图10所示,图(a1)存在漏检,未能识别出2个较小尺寸的交通标志,但图(b1)能够检测出这2个较小的目标;图(a2)未能识别1个较小尺寸目标,而图(b2)正确检测出所有目标。实验表明,改进的S-YOLO能够有效地降低目标检测的漏检率,在交通标志检测上具有良好的泛化作用。

图10 S-YOLO与YOLOv3对比实验Fig.10 Comparative experiment of S-YOLO and YOLOv3
4 结论
针对原始YOLOv3算法在交通标志识别场景下存在精度低、速度慢问题,提出一种改进的S-YOLO目标检测算法。首先将CBL组件中的BN层合并到卷积层来提高模型前向推理速度,然后引入SPP模块来更有效获取图像特征,再使用二分K-means聚类算法确定适合交通标志的先验框使模型的收敛性更好,最后引入CIoU回归损失函数来提高模型检测精度。实验结果表明,改进的S-YOLO算法计算量少、精度高、泛化性强和实时性检测,并且mAP与召回率分别达到了94.33%和94%,较原始YOLOv3提升了4.26%和5%,速度达到了42.41 f/s,较YOLOv3提升了15.19%,整体性能得到一定的提升。
同时,本文所提算法还有诸多方面有待改进,在识别小目标效果上还未达到预期的结果,检测速度上也还有提升的空间。在实时检测情景下,如何更进一步地提高模型的检测精度,将是下一步的研究方向。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年9期)2022-05-20
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
小天使·一年级语数英综合(2016年8期)2016-05-14
小天使·一年级语数英综合(2014年7期)2014-06-26
